
By this chapter, you've learned how to create and manage your infrastructure with Terraform. However, all topics we discussed apply only to a single-person operations department. If you are the only one using Terraform in your team, then you have all the knowledge already. Eventually, operations teams will reduce in size, and what required dozen of system admins in the past will require only a couple of them, the ones that are experienced in both operations and software development. Even then, it's not a single person, but at least a couple of them: having just one infrastructure engineer in the company is an example of a single point of failure.
And when you have multiple colleagues working on Terraform templates, you have a whole new package of problems to solve. How do you store your templates? How do you organize and split them? Where do you store them? And where do you store the state file? How do you roll out changes to production? And how do you test these changes?
That's what this chapter is going to be about. We will start from the basic setup. You will learn a bit of version control with Git, in case you are not familiar with it. We will proceed to different strategies for organizing templates. You will learn how to avoid conflicts when working with the state file and different approaches and tools in order to store it. We will also take a deep dive into Continuous Integration pipelines for templates, taking the whole Infrastructure as Code approach to its maximum. By the end of this chapter, you will be completely ready to introduce Terraform to your organization.
Version Control System (VCS) simplifies work with constantly changing information, such as code. It allows us to store multiple versions of the same file, easily switch between them, and check who is responsible for which change. The most popular VCS today is Git, initially created to support Linux kernel development.
VCS such as Git has many benefits:
- You have access to all versions of all files in the Git repository at any time; it's almost impossible to lose any part of a code or a previous state of the code.
- Multiple developers can work on one project at the same time without interfering with each other's code and without fear of losing any changes made by colleagues. In Git, the possibilities of collaborative work are unlimited.
To create a repository, you've got to run git init in the project folder. To add files in it, first use git add file_name (or git add . to add all the files at once) and then git commit -m 'description_of_changes_made'. Any further changes in the files can also be done with git add and then you use commit. You can consider using commit to be the same thing as saving a version of the file.
Git has branches. You can work in a separate branch after creating it on the basis of the current one. By default, the main branch is the master. It is a best practice for big projects to develop a new feature in an individual branch, and when it's done, merge the changes into the main branch.
A git repository may have a remote copy. You can send commits there using git push repository_name branch_name and get them back with git pull repository_name branch_name.
This is how developers work on their computers and synchronize all the changes using a remote repository. In one picture, the simplified workflow looks as follows:
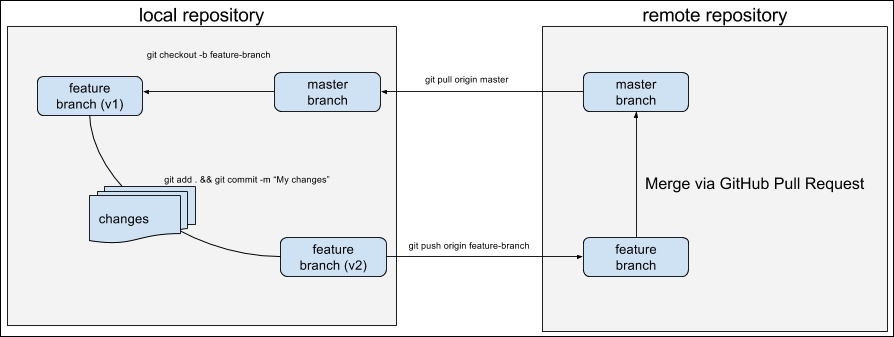
There are two repositories in sync on this image: the local repository and the remote repository. All work is done inside the local repository as follows:
- The developer creates a new branch from a master branch.
- Commits changes to a new feature branch.
- Pushes this branch to the remote repository.
- After code review, this branch is merged into the master branch in the remote repository.
- Finally, changes to the master branch are pulled to the local repository's master branch, and the cycle starts again.
There are multiple services, available in the form of Software as a Service, as well as sold as enterprise-hosted software, that dramatically simplify all Git-related operations. Services like this provide remote hosting of Git repositories, mechanisms to collaborate on changes, and hundreds of integrations with other tools.
Undoubtedly, the most famous service like this is GitHub, where lots of open source projects are stored and maintained, including all HashiCorp products. GitHub revolutionized the way people work on open source, but it has a strong competition today in the form of BitBucket (widely used in enterprise environments) and GitLab.