
Chapter 15: Decoding HTTP
At some point, most of us have accessed a web page to download information. But just what's involved when retrieving a web page? In this chapter, we'll take a closer look at the HyperText Transfer Protocol (HTTP). We'll start with an overview and review some of the objects and elements that we can obtain when requesting content. We'll then compare the available HTTP versions, 1.0, 1.1, and 2.0, along with the methods used, such as GET, POST, and HEAD. HTTP has three versions, each with a default method to establish and maintain a connection. So that you understand the mechanics of the different methods, we'll compare the differences between a non-persistent and persistent connection.
HTTP is a stateless protocol. You'll learn how HTTP uses cookies to maintain state by keeping track of the details of each transaction. To help you troubleshoot a web connection, we'll review what takes place during a transaction and examine the general format of request and response messages. We'll dissect the HTTP header and fields for both the client and the server. We'll then summarize this by following an HTTP stream, and then break down each of the elements when examining a transaction.
This chapter will address all of these by covering the following topics:
- Describing HTTP
- Keeping track of the connection
- Comparing request and response messages
- Following an HTTP stream
Describing HTTP
HTTP is an application-layer protocol responsible for exchanging data between a client browser and a web server. HTTP allows us to gather, distribute, collaborate, and disseminate a wide range of data. Although a stateless protocol, HTTP has several request methods, error codes, and headers that allow us to access resources from many different types of applications.
Note
HTTP is used to transport data across the network. Two other protocols that transport data include File Transfer Protocol (FTP) and Simple Mail Transfer Protocol (SMTP). All are essential in providing an efficient way to exchange data.
In this section, we'll begin by outlining the definition of a web page and describe HTTP's function in retrieving objects from a website. We'll compare the role of client and server, outline the versions in use today, and then summarize with a review of the different types of HTTP methods.
Let's start by reviewing the elements of a web page.
Dissecting a web page
Using a browser, such as Firefox or Chrome, a client requests a page by clicking on a hyperlink. The link directs the client to a website, which is a set of linked web pages, and the server sends the requested data to the client.
The first page we hit is called index or default, and that's where most of us start when searching for content. Once at the website, each page contains objects, such as a HyperText Markup Language (HTML) file, Joint Photographic Experts Group (JPEG) images, text, applications, and/or JavaScript. Most websites have many linked pages that are hyperlinked to other content within the site, along with a variety of information and objects that can be extracted.
At a high level, HTTP will retrieve a web page that can contain elements, as shown in the following graphic:

Figure 15.1 – A standard web page
Prior to downloading any objects, the client must first access the web page. Next, let's review how resources are located when requesting data from a website.
Finding the target
When a client requests a web page, the user will click on a link to request an object using a Uniform Resource Identifier (URI), which is used to identify an object (or resource) on the internet. Two subsets of a URI are a Uniform Resource Locator (URL) and a Uniform Resource Name (URN).
In some cases, the client will request a specific page from the server. For example, if requesting https://www.nist.gov/blogs/cybersecurity-insights, the URL will break down in the following manner:
- Hostname: The name of the host is www.nist.gov.
- Path: The path to the specific resource is /blogs/cybersecurity-insights.
Once the request reaches the target, the next step is to interact with the server using either a standard or encrypted connection.
Making the connection
When a client initiates a connection with a web server, they will use either Transmission Control Protocol (TCP) port 80 or port 443, depending on the type of connection, as described here:
- TCP port 80 is used for a standard, unencrypted connection.
- TCP port 443 is used for a secure, encrypted connection.
Note
In some cases, the server may be reached using an alternate port, such as http-alt 8080 or http-alt 8008.
Using a secure connection is common today, as most websites use encryption to protect data transactions. When accessing a secure site, the URL will be identified using the HTTP Secure (HTTPS) preface. HTTPS uses Transport Layer Security (TLS) to secure all transactions between the client and the server. Even if someone were able to obtain the data stream, they would not be able to read the contents without the appropriate key to decrypt the data.
Once the target is located, the client will make a request to the server. Each party has a specific role in a web transaction, as discussed next.
Comparing client and server roles
HTTP is a client-server model, whereby the client makes a request to the server, and the server responds to the client, as shown in the following illustration:
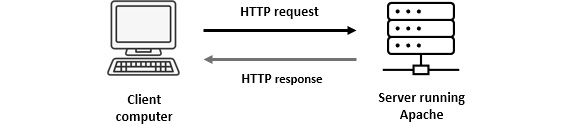
Figure 15.2 – HTTP request and response
A client is a host that initiates each session using a browser to interface with a server and retrieve objects.
A server is an always-on host with a fixed Internet Protocol (IP) address that uses dedicated web server software. Although there are several web server applications, the top three are listed as follows:
- Apache is one of the most popular open source web server applications in use today. Apache has a full library of modules that enable a rich set of features that can power even the largest sites.
- nginx (or engine X) is the second most popular open source web server application and is robust, scalable, and easy to configure.
- Cloudflare is a popular option used to host websites and help prevent malicious attacks such as distributed denial-of-service (DDoS) attacks.
Whenever requesting a web page, the version will be either HTTP version 1.0, 1.1, or 2.0, as discussed next.
Understanding HTTP versions
HTTP has three versions in use today. Each has an associated Request for Comments (RFC), as follows:
- HTTP 1.0, outlined in RFC 1945, was written in 1996. This was the original version, developed when we were just beginning to see the benefits the internet could potentially offer. This stripped-down version offered limited functionality, only had 16 response codes, and didn't have a secure method to authenticate users when interacting with the site.
- HTTP 1.1, outlined in RFC 2068, was written in 1996, shortly after version 1.0. This version had numerous improvements, including authentication, improved performance, the ability to reuse sessions, and expanded status codes, along with granular error reporting.
- HTTP 2.0, outlined in RFC 7540, was written in 2015 and evolved from an experimental protocol developed by Google called SPeeDY (SPDY). Version 2 reduces latency and improves efficiency by compressing the HTTP headers to reduce overhead, multiplexes requests and responses, and proactively pushes content to the client.
All three versions are in use; however, you will most likely see versions 1.1 and 2.0 for most of today's web traffic, as these versions offer improved performance.
When doing an analysis, you will see a method listed in the HTTP header that will indicate the type of action that is requested.
Recognizing HTTP methods
HTTP is primarily used to obtain objects and interact with a web server using various methods to exchange information. Some of the most common methods are described in the following table:

Table 15.1 – Common HTTP methods
While there are several HTTP request methods, the two most commonly used are GET and POST.
In the next section, we'll compare connection methods and cover how cookies are used to keep track of transactions.
Keeping track of the connection
Every version of HTTP has evolved in methods to transport and process data, with techniques such as using persistent connections with a pipelining goal to optimize the connection. In addition, because HTTP is a stateless protocol, cookies are used to maintain client information about the connection, such as shopping cart elements and pages the client has visited.
In this segment, we'll compare the different methods of making and maintaining a connection, along with how cookies are used to preserve state information. Let's start by comparing connection types.
Evaluating connection types
When HTTP version 1.0 was developed, it had minimal functionality and used a non-persistent connection. With the introduction of version 1.1, several enhancements were added. One of the improvements was the ability to keep the data moving by using a persistent connection.
Let's start by understanding the mechanics of a non-persistent connection.
Using a non-persistent connection
A non-persistent connection is one of the original ways to retrieve content from a web page. This method works in the following manner:
- The client requests content from a web server.
- The server returns the content to a client.
- The connection is closed.
If the client wants to obtain any more content from the web server, a new connection must be made, resulting in one round trip per request and response. As you can imagine, all of the round trips and connections can add to latency.
There are two approaches in a non-persistent connection, as outlined here:
- A non-parallel (or serial) connection uses one connection at a time.
- A parallel connection uses multiple concurrent connections.
If possible, a parallel connection is used, as this will improve the overall efficiency of obtaining objects.
When using HTTP version 1.0, the default is to use a non-persistent connection. HTTP version 1.1 improved the method to connect by offering a persistent connection, as outlined next.
Offering a persistent connection
To optimize a connection, HTTP version 1.1 introduced the idea of using a persistent connection to keep a session alive until all objects are retrieved. This type of connection is also referred to as an HTTP keep-alive, as it prevents having to reestablish a new connection every time a request is made.
Note
Although the idea of a keep-alive was made official in version 1.1, version 1.0 adopted an unofficial method to keep the session alive as well. That is why you might see HTTP 1.0 traffic using a keep-alive during a transaction.
When used, the HTTP header can set a timeout and define the maximum number of requests the client can make.
Keep-alive packets are sent between the client and the server to keep the session active and to verify that both sides are still responding. A keep-alive packet doesn't have any data; it has the acknowledgment (ACK) flag set and the sequence number is set to one less than the current sequence number.
HTTP version 2.0 improves this option and permits multiple concurrent transactions to be combined in a single connection.
HTTP 1.1 made persistent connections the default mode. Next, let's see how a persistent connection can benefit from using a concept called pipelining.
Pipelining the data transfer
To optimize a data transfer using a persistent connection, HTTP can employ pipelining, which maintains the connection to the server until all objects are obtained. Pipelining improves the efficiency of a data transaction, as the client can continue to request objects immediately without waiting for the server to send previous requests.
Instead of closing each connection after a request-response transaction, the server will keep the connection open and wait for further requests. A persistent connection using pipelining is the default connection method in HTTP 1.1. This type of connection requires a bit more overhead in terms of setting up the connection. In addition, because the server is waiting for multiple requests, it might be idle for short segments of time. However, this type of connection is preferred as it improves overall efficiency when obtaining objects from a web server.
Because HTTP is a stateless protocol, cookies are used to keep track of the details of each transaction.
Maintaining state with cookies
When using HTTP, neither the server nor the client natively maintains information on the state of the transaction. To overcome this, HTTP uses the concept of a cookie.
A cookie is a string of characters created by the server that can be placed on a user's system and then managed by the user's browser to interact with the server. Once the user accepts a cookie, the information contained in the cookie can be used for the following reasons:
- Authentication: After a user provides login information, the data can be used as a form of single sign-on (SSO) to interact with the website.
- Personalize the user experience (UX): A cookie can collect data on shopping patterns. This will then improve the shopping experience by retaining previously accessed objects and periodically presenting the information to the client.
For a closer look at a cookie being used in an HTTP conversation, go to http://tcpreplay.appneta.com/wiki/captures.html#bigflows-pcap. Once there, download bigFlows.pcap so that you can follow along.
Go to Frame 912 and then expand the HTTP header. Once there, you will see the cookie and cookie pair, as shown in the following screenshot:

Figure 15.3 – Viewing cookies in an HTTP header
In most cases, cookies are designed to be helpful; however, they can pose a privacy risk as they can gather marketing statistics and personal information. That is why, in most cases, a user will have the ability to opt out of allowing cookies on their system.
In some cases, a cookie is sent to the server to be maintained and retrieved for future visits by the client. However, if a cookie is not sent to the server, it is said to be non-persistent, and one of the following scenarios will take place:
- The cookie will expire.
- The cookie will be removed when the user shuts down the browser.
- The user will remove (or delete) the cookie.
During an HTTP transaction, there are a series of requests and responses between the client and the server. In the next section, we'll examine the general format of request and response messages.
Comparing request and response messages
When interacting with a web page, a client will request objects from a server. In most cases, a standard transaction involves a request from the client and then a response from the server. Because the client and the server both convey a different message, the headers are slightly different. In this segment, we'll take a high-level view of the HTTP header and fields for both the client and the server.
Let's start by examining the elements of an HTTP request.
Viewing an HTTP request
When viewing a client request, you will most likely see a request line followed by header lines, as shown in the following diagram:
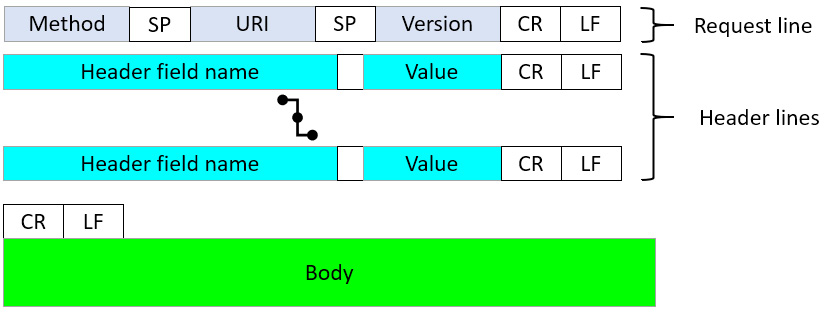
Figure 15.4 – HTTP request format
Each request message will indicate the method (such as GET or POST) and the URL, along with additional parameters. It's also common to see the following:
- The symbol, which is used to indicate a carriage return
- The symbol, which is used to indicate a newline
Both symbols in the header provide formatting guidance that represents the end of the content for that particular line. To see an example, return to bigFlows.pcap and select Frame 183. Then, expand the HTTP header, as shown here:

Figure 15.5 – HTTP GET request
An HTTP request is used to retrieve objects. Most web servers provide rich, interactive content. As a result, the headers must indicate the types of content that the client can support. Within an HTTP request, you will see a reference to the Multipurpose Internet Mail Extensions (MIME) header. Let's explore this next.
Viewing the MIME header
MIME is designed to present data in a variety of formats that include text, images, audio, applications, and video. Originally developed to support email, MIME headers became a part of the evolution of HTTP.
When the server receives the HTTP request, the request line will list what the client wants, along with the HTTP version that the browser supports. After that, the MIME header contains fields that relate to the type of content that the client can support. An example is shown here:

Figure 15.6 – HTTP request with a MIME header
The MIME header holds values such as the browser version, along with character encoding and objects that the client will accept.
Once the server receives the request, it will send the response to the client. The header format is much the same as the HTTP request; however, this contains details that are specific to the server response.
Responding to the client
The HTTP response from the server begins with the status line, indicating the version, status code, and reason. After the status line, the structure is similar to the HTTP request, as we find header lines, as shown in the following diagram:
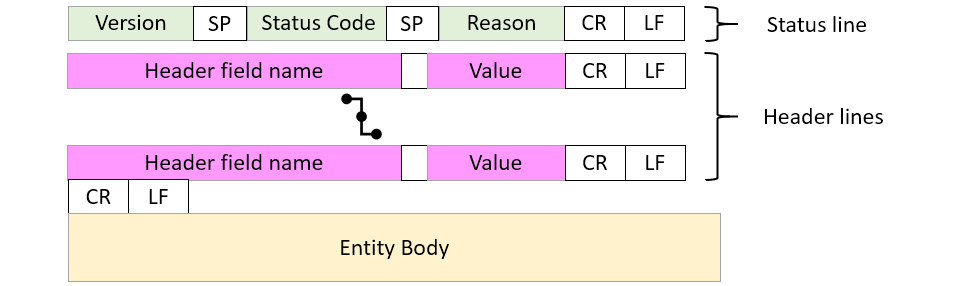
Figure 15.7 – HTTP response format
Following the status code and header lines, you will see the message body, which can contain client-requested items, along with details of the transaction.
One of the main elements of an HTTP response is the status of the message. HTTP indicates the status by using a specific code, as outlined next.
Understanding status codes
A status code is shown in the first line of a web server to the client response message. Status codes are grouped by category, as follows:
- 1xx Informational: Provides general notes about the transaction, such as the request has been received and/or the process is moving forward
- 2xx Success: Indicates that the server was able to positively receive and process the request
- 3xx Redirection: Indicates the client must be redirected to another resource to complete the request
- 4xx Client Error: Means that the request contains invalid syntax or could not be satisfied for some reason
- 5xx Server Error: Occurs when there is a failure on the server's part to complete an action or request
While many status codes are available, some of the most common codes include the following:
- 200 OK: This is the most common status code and represents that the server is able to successfully return the requested object.
- 301 Moved Permanently: This indicates that the requested object is no longer available at the URL and has moved permanently to a new location.
- 400 Bad Request: This status means the HTTP client request was invalid and was unable to be processed by the server.
- 404 Not Found: This status is returned if the requested object is not found on the server.
After the status line, you will see various elements within the MIME header related to the response, as outlined next.
Describing the MIME header
Whenever you retrieve data from a web page, your browser will properly format the request. In turn, the server will respond to the request and deliver the data. The browser will then present the results to the client.
When a server returns objects to a client, there are various elements within the MIME header, as shown here:

Figure 15.8 – MIME fields in an HTTP response
The field values define details such as the type of content, where it originated, and length.
In the next section, let's explore the process from making a request, to displaying an object, to closing a connection.
Following an HTTP stream
To get a solid understanding of what happens when requesting and receiving a web page, we'll step through the process by following an HTTP stream. We'll then further break down each of the elements when examining an HTTP transaction.
Note
Keep in mind that each HTTP session is different. This example will provide a sampling of what you can expect when viewing an HTTP conversation. In a true analysis exercise, you will most likely have to research the meaning of some of the various field values.
For this example, we'll use HTTP.pcap, as it is a complete conversation. To obtain a copy, go to https://www.cloudshark.org/captures/0012f52602a3, then download the file and open it in Wireshark. Once open, expand Frame 1 under the TCP header, where you will see the following:
[Conversation completeness: Complete, WITH_DATA (31)]
This is a small capture with only 40 packets, so it isn't difficult to see all elements of the complete conversation. However, one way to view the activity between hosts is by running a flow graph. To view the entire conversation, go to the Statistics menu choice and then select Flow Graph. Wireshark will then run the graph, as shown in the following screenshot:
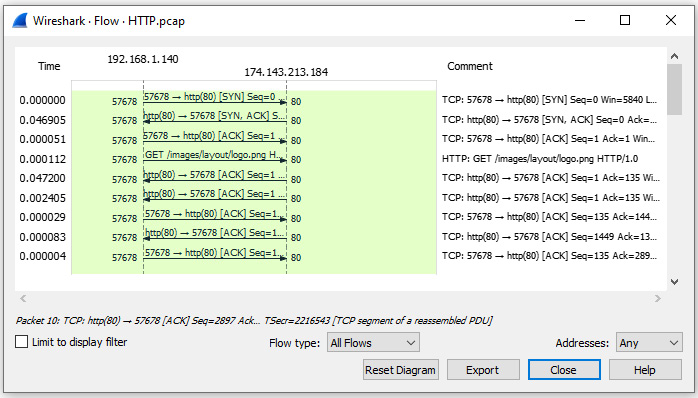
Figure 15.9 – Viewing the HTTP flow
Once in the Flow Graph setting, you can select Limit to display filter, as shown on the left-hand side of the graph. However, because this capture only contains one conversation, this isn't necessary.
After viewing the flow graph, exit the window so that we can focus on the capture. To see the dialog between the client and the server, place your cursor on Frame 4, right-click, and select Follow | TCP Stream, as shown in the following screenshot:

Figure 15.10 – Following the TCP stream
Once selected, Wireshark will present a window with the following conversation:

Figure 15.11 – Viewing Follow TCP Stream
Within the window, you will see the following:
- The client request at the top of the window, as shown in Figure 15.11 using red font
- The server response, which starts in the middle of the window, as shown in Figure 15.11 using blue font
Now that we have seen the entire conversation, let's go through the process. The first step is for the client to establish contact with the server by using a three-way handshake.
Beginning the conversation
Before any data is exchanged, the process begins with a three-way handshake, which we see in Frames 1, 2, and 3 of HTTP.pcap, as shown in the following screenshot:

Figure 15.12 – Viewing a three-way handshake
A three-way handshake is an exchange of synchronization (SYN) and ACK packets between the client (192.168.1.140) and the server (174-143.213.184), as described in more detail here:
- The client begins the process by sending a SYN packet to the server.
- The server responds by sending a SYN-ACK to the client.
- The client responds by sending an ACK to the server.
No data is exchanged as the handshake simply establishes the connection. Once established, the next step is for the client to make a request to the server.
Requesting data
Frame 4 begins the conversation as the client makes a request to the server for an image. The HTTP header is shown in the following screenshot:

Figure 15.13 – Client-side HTTP request
When examining the client request, we see several values in the HTTP header. The first line is the GET method requesting data from the server. Here are the parameters of this request:
- Request Method: GET, which is used by the client to obtain information from the server.
- Request URI: The client is requesting the logo.png image using the images/layout/logo.png path.
- Request Version: The client is using HTTP/1.0.
Following the GET method, you will see these values:
- User-Agent: The user agent listed is Wget/1.12: (linux-gnu), which is a simple non-interactive browser used to obtain files using methods such as HTTP and FTP.
- Accept: Lists */*, which is a wildcard value that means the client will accept any MIME-type object.
- Host: The requested host is packetlife.net.
- Connection: Keep-Alive is listed as the connection method, which tells the server to continue to send data without having to open new connection requests.
Following the field values, we see three Wireshark-generated details, as outlined next:
- [Full request URI: http://packetlife.net/images/layout/logo.png]: This is a hyperlink to the exact location of the requested object.
- [HTTP request 1/1]: This indicates that this request is the first out of one (1) HTTP request.
- [Response in frame: 36]: This is a hyperlink to the frame containing the HTTP response.
After the client request is sent to the server, data is then sent to the client. From Frame 5 to Frame 35, you will see a series of ACK packets, from both the client and the server as they acknowledge the data is being transferred and received.
Once complete, the server will respond to the client and indicate that all data has been sent.
Responding to the client
In Frame 36, we see the server returning a Status Code: 200 OK response, meaning the data has successfully been delivered.
Unlike the request packet, we see more information contained in the HTTP response, as shown in the following screenshot:
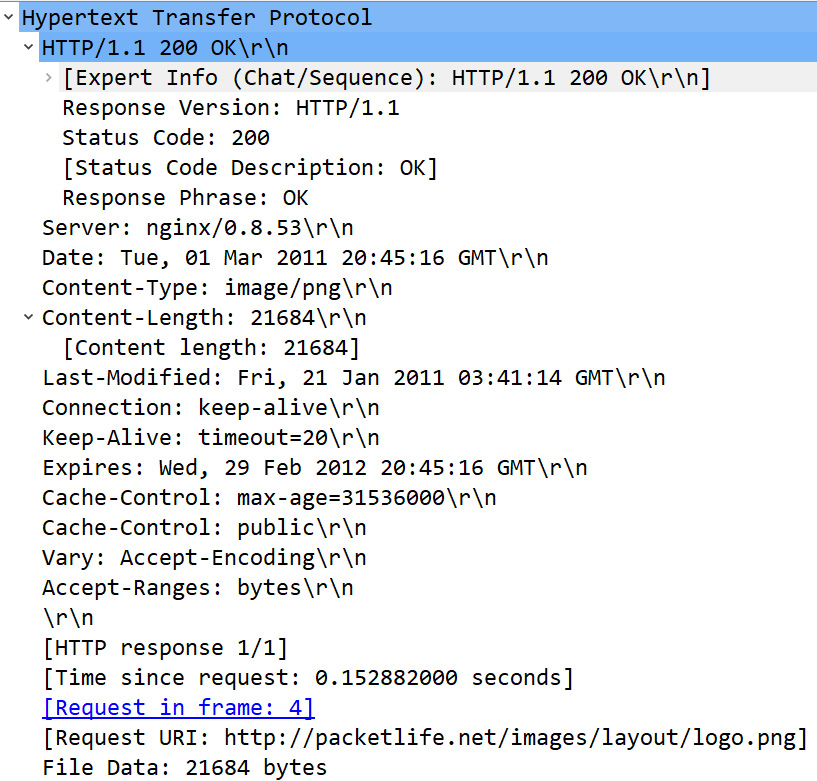
Figure 15.14 – Server-side HTTP response
When examining the server response, we see several values in the HTTP header. The first line of the data transfer is a Wireshark-generated value that indicates the status of the response, as shown here:
[Expert Info (Chat/Sequence): HTTP/1.1 200 OK ]
This line defines that HTTP/1.1 200 (PNG) falls under the Chat severity in the Expert Information console. To view this, select the cyan Expert Info icon in the lower left-hand corner of the Wireshark interface. Once open, expand the second Chat entry, which will display the following information:

Figure 15.15 – Viewing Expert Information entries
After the Wireshark-generated values, you will see the following:
- Response Version: This value shows the server is using HTTP version 1.1.
- Status Code: In this case, the data transfer was successful, so the server returned a Status Code 200 response.
- [Status Code Description: OK]: This line is a Wireshark-generated value indicating that there were no issues with the response.
- Response Phrase: This field value is OK, which indicates a successful data transfer.
After the details of the transaction, you will see the following values:
- Server: This field lists the web server as nginx/0.8.53. nginx is a popular open source web server that is an alternative to Apache.
- Date: This field marks the date and time the object was accessed and is used to monitor the age of a resource for caching calculations. Frame 35 lists Tue, 01 Mar 2011 20:45:16 GMT as the date.
- Content-Type: This field provides a reference as to what type of object is being returned to the client. Frame 35 lists the Content-Type as image/png, which is an image in the Portable Graphics Format (PNG) format.
- Content-Length: This field lists the length of the image, which is 21684 bytes. Below the field value, you will see a [Content length: 21684] Wireshark-generated value. This value will match the Portable Network Graphics header, found at the bottom of the HTTP header. If you place your cursor on the header, you will see the value reflected in the status bar, as shown in the following screenshot:

Figure 15.16 – Content length of the image
- Last-Modified: This field value will indicate when the page was last modified, which is listed as Fri, 21 Jan 2011 03:41:14 GMT.
- Connection: This value is listed as a keep-alive (or persistent) connection.
- Keep-Alive: This field value lists timeout=20, which is a value (in seconds) set by the server indicating how long to keep the conversation going before closing the connection.
On a network, the concept of cache is important as, in most cases, the requesting host wants to receive the freshest copy possible. Cache values are used to identify the age of the page.
Controlling the cache
Most objects on the network typically have a timeout value. The next few values provide a method to monitor the age of a page. Entries include the following:
- Expires: This value specifies when an object will expire. In Frame 35, the expiration date is listed as Wed, 29 Feb 2012 20:45:16 GMT.
- Cache-Control: This value is listed as max-age=31536000.
Note
On assets that rarely change, it's customary to set the Cache-Control value to max-age=31536000, which represents the number of seconds in 1 year.
- Cache-Control: This field value is listed as public, which means the values can be stored in a shared cache. Other values can include private or no-cache.
- Vary: This field represents the type of content supported by the caching server. In this case, the value is Accept-Encoding. If this indicator is not present, the formatting might not be stored appropriately, and when the client retrieves the page, it might render the page in an unreadable format.
- Accept-Ranges: This field value indicates which unit the server will use when responding to the client's request for data. The field value is listed as bytes, which is common.
At the end of the HTTP field values, we see the Portable Graphics Format header, which indicates that the object is a PNG file. Next, let's investigate the image.
Exporting the object
If there are unencrypted objects in the capture, you can export them in Wireshark. To see what's in the HTTP.pcap file, go to the File menu choice and then Export Objects | HTTP…, which will bring up the following window:
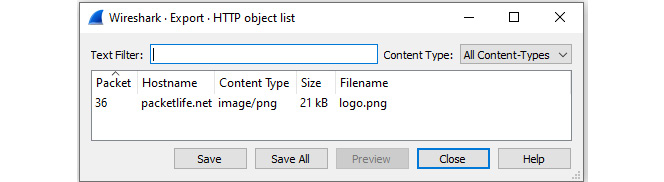
Figure 15.17 – Viewing Export HTTP object list
If you would like to view the contents, click on the image and select Save, which will bring up a dialog box giving you a choice as to where you would like to save the file. Once saved, you can open the image, as shown here:

Figure 15.18 – The extracted image
Once the data is transferred and the client is no longer requesting objects, the next step is to end the conversation.
Ending the conversation
At the end of the transaction, the client and server exchange a series of finish (FIN) and ACK packets, as shown here:

Figure 15.19 – Exchange of FIN-ACK packets
While this was a simple example of a data transaction, it provides a solid way to understand the mechanics of a client interacting with a web server.
Summary
HTTP is a rich protocol, and during a transaction, data will travel across several networks, along with encountering different clients and servers. As a result, there are numerous rules and variables. For this discussion, we focused on the key elements of an HTTP request-response session between a client and server.
We began by stepping through the key elements of a web page, and the role of the client and the server when retrieving data and objects. We reviewed the different HTTP versions, along with briefly touching on the available HTTP methods. We then moved on to learn about the different types of connections and how cookies help maintain state during a transaction. Finally, we summarized with a simple example of a complete HTTP conversation.
In the next chapter, we'll review Address Resolution Protocol (ARP) and begin with an overview of the role and purpose of this essential protocol. So that you understand how ARP works, we will cover an ARP transaction and take a closer look at the header and field values. We will see the importance of a gratuitous ARP and briefly mention some other types of ARP traffic that you might encounter. Finally, we will look at ARP attacks and how to identify and defend against these types of threats.
Questions
Now, it's time to check your knowledge. Select the best response to the following questions and then check your answers, which can be found in the Assessment appendix:
- The two main HTTP request methods are GET and _____.
- PUT
- DELETE
- POST
- STATE
- _____ is one of the most popular open source web server applications in use today, as it has a full library of modules and can power even the largest sites.
- Cloudflare
- Microsoft IIS
- LiteSpeed
- Apache
- HTTP version _____ reduces latency and improves efficiency by compressing headers to reduce overhead, multiplexes requests and responses, and proactively pushes content to the client.
- 1.0
- 1.1
- 1.2
- 2.0
- When transferring data from a web server, a persistent connection keeps the session alive until all objects are retrieved. This type of connection is also referred to as an HTTP _____.
- Flare state
- Parallel connection
- Keep-alive
- Cookie state
- In the HTTP header, you see the value 3600 listed in the Cache-Control field. This means the content can live in cache for _____.
- 1 day
- 1 hour
- 1 year
- 1 month
- Originally developed to support email, _____ is designed to present data in a variety of formats that include text, images, audio, applications, and video.
- LiteSpeed
- MIME
- Cookie Art
- nginx
- Most objects on the network typically have a timeout value. _____ values provide a method to monitor the age of a page.
- Cache
- MIME
- Cookie
- State
Further reading
Please refer to the following links for more information:
- Visit https://www.w3schools.com/tags/ref_httpmethods.asp to learn more about HTTP request methods.
- Learn more about nginx by visiting https://nginx.org/en/.
- Cache control for objects that rarely change will default at a value of 1 year. See why this is the default by going to https://ashton.codes/set-cache-control-max-age-1-year/.
- To discover the most popular web server software in use today, visit https://digitalintheround.com/what-is-the-most-popular-web-server/.
- Learn about safe methods of requesting data from a server by visiting https://datatracker.ietf.org/doc/html/rfc7231#section-4.2.
- For a detailed list of HTTP methods, visit https://www.tutorialspoint.com/http/http_methods.htm.
- Visit https://www.iana.org/assignments/http-status-codes/http-status-codes.xhtml to see a complete list of HTTP response codes.
- Visit https://svn.apache.org/repos/asf/trafficserver/site/branches/2.0.x/docs/sdk/HTTPHeaders.html for a discussion on HTTP headers.
- Visit https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cache-Control to learn more about cache control.