
Transferring Control
In a Scott Adams cartoon, Dilbert complains to Dogbert that he is embarassed to work at a company where even paying a simple invoice takes 6 months. The invoice first comes into the mail room for aging, spends some time at the secretary’s desk, goes to the desk of the main decision maker, and finally ends up in accounts payable. When processing an invoice in Dilbert’s company, the flow of control works its way through layers of command, each of which incurs significant overhead.
A management consultant might suggest that Dilbert’s company streamline the processing of an invoice by eliminating mediating layers wherever possible and by making each layer as responsive as possible. However, each layer has some reason for existence. The mailroom aggregates mail delivery service for all departments in the company. The secretary protects the busy boss from interrupts and weeds out inappropriate requests. The boss must eventually decide whether the invoice is worth paying. Finally, the mundane details of disbursing cash are best left to accounts payable.
A modern CPU processing a network message also goes through similar layers of mediation. The device, for example, an Ethernet adaptor, interrupts the CPU, asking somewhat stridently for attention. Control is passed to the kernel. The kernel batches interrupts wherever possible, does the network layer processing for the packet, and finally schedules the application process (say, a Web server) to run. As always, the reception of a single packet provides too limited a picture of the overall processing context. For instance, a Web server will parse the request (such as a GET) in the network packet, look for the file, and institute proceedings to retrieve the file from disk. When the file gets read into memory, a response containing the requested file is sent back, prepended with an HTTP header.
While Chapter 5 concentrated on reducing the overhead of operations that touch the data in a packet (e.g., copying, checksumming), this chapter concentrates on reducing the control overheads involved in processing a packet. As in Chapter 5, we start by examining the control overheads involved in sending or receiving a packet. We then broaden to our canonical network application, a Web server.
This chapter is organized as follows. Section 6.1 starts by describing the control flow costs involved in a computer: interrupt overheads (involved when a device asks asynchronously for attention), system calls (involved when a user asks the kernel for service, thus moving the flow of control across a protection boundary), and process-context switching (allowing a new process to run when the current process is stymied waiting for some resource or has run too long). Thus the rest of this chapter is organized around reducing these control overhead costs, from the largest (context switching) to the smallest (interrupt overhead).
Accordingly, Section 6.2 concentrates on reducing process-context switching by describing how to structure networking code (e.g., TCP/IP) to avoid context switching. Section 6.3 then describes how to structure application code (e.g, a Web server) to reduce context-switching costs. Sections 6.4 and 6.5 focus on reducing or eliminating system call overhead. Section 6.4 shows how to reduce overhead in the implementation of a crucial system call used by event-driven Web servers to decide which of the connections they are handling are ready to be serviced. Section 6.5 goes further and describes user-level networking that bypasses the kernel in the common case of sending and receiving a packet. Finally, Section 6.6 briefly describes simple ideas to avoid interrupt overhead.
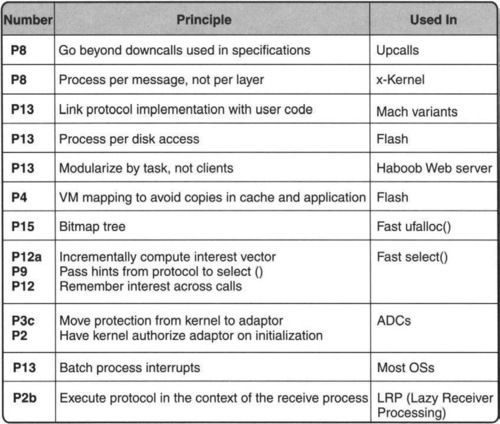
The techniques described in this chapter (and the corresponding principles invoked) are summarized in Figure 6.1.
6.1 WHY CONTROL OVERHEAD?
Chapter 5 started with a review of the copying overhead involved in a Web server by showing the potential copies (Figure 5.2) involved in responding to a GET request at a server. By contrast, Figure 6.2 shows the potential control overhead involved in a large Web server that handles many clients. Note that in comparison with Figure 5.2 for Web copies, Figure 6.2 ignores all aspects of data transfer. Thus Figure 6.2 uses a simplified architectural picture that concentrates on the control interplay between the network adaptor and the CPU (via interrupts), between the application and the kernel (via system calls), and between various application-level processes or threads (via scheduler invocations). The reader unfamiliar with operating systems may wish to consult the review of operating systems in Chapter 2. For simplicity, the picture shows only one CPU in the server (many servers are multiprocessors) and a single disk (some servers use multiple disks and disks with multiple heads). Assume that the server can handle a large number (say, thousands) of concurrent clients.
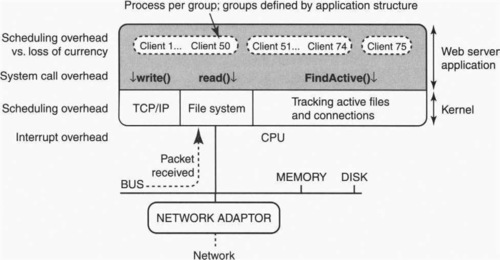
For the purposes of understanding the possible control overhead involved in serving a GET request, the relevant aspects of the story are slightly different from that in Chapter 5. First, assume the client has sent a TCP SYN request to the server that arrives at the adaptor from which it is placed in memory. The kernel is then informed of this arrival via an interrupt. The kernel notifies the Web server via the unblocking of an earlier system call; the Web server application will accept this connection if it has sufficient resources.
In the second step of processing, some server process parses the Web request. For example, assume the request is GET File 1. In the third step, the server needs to locate where the file is on disk, for example, by navigating directory structures that may also be stored on disk. Once the file is located, in the fourth step, the server process initiates a Read to the file system (another system call). If the file is in the file cache, the read request can be satisfied quickly; failing a cache hit, the file subsystem initiates a disk seek to read the data from disk. Finally, after the file is in an application buffer, the server sends out the HTTP response by writing to the corresponding connection (another system call).
So far the only control overhead appears to be that of system calls and interrupts. However, that is because we have not examined closely the structure of the networking and application code.
First, if the networking code is structured naively, with a single process per layer in the stack, then the process scheduling overhead (on the order of hundreds of microseconds) for processing a packet can easily be much larger than a single packet arrival time. This potential scheduling overhead is shown in Figure 6.2 with a dashed line to the TCP/IP code in the kernel. Fortunately, most networking code is structured more monolithically, with minimal control overhead, although there are some clever techniques that can do even better.
Second, our description of Web processing has focused on a single client. Since we are assuming a large Web server that is working concurrently on behalf of thousands of clients, it is unclear how the Web server should be structured. At one extreme, if each client is a separate process (or thread) running the Web server code, concurrency is maximized (because when client 1 is waiting for a disk read, client 2 could be sending out network packets) at the cost of high process scheduling overhead.
On the other hand, if all clients are handled by a single event-driven process, then contextswitching overhead is minimized, but the single process must internally schedule the clients to maximize concurrency. In particular, it must know when file reads have completed and when network data has arrived.
Many operating systems provide a system call for this purpose that we have generically called FindActive() in Figure 6.2. For example, in UNIX the specific name for this generic routine is the select() system call. While even an empty system call is expensive because of the kernel-to-application boundary crossing, an inefficient select() implementation can be even more expensive.
Thus there are challenging questions as to how to structure both the networking and server code in order to minimize scheduling overhead and maximize concurrency. For this reason, Figure 6.2 shows the clients partitioned into groups, each of which is implemented in a single process or thread. Note that placing all clients in a single group yields the event-driven approach, while placing each client in a separate group yields the process- (or thread-) per-client approach.
Thus an unoptimized implementation can incur considerable process-switching overhead (hundreds of microseconds) if the application and networking code is poorly structured. Even if process-structuring overhead is removed, system calls can cost tens of microseconds, and interrupts can cost microseconds. To put these numbers in perspective, observe that on a 10-GB Ethernet link, a 40-byte packet can arrive at a PC every 3.2 μsec.
Given that 10-Gbps links are already arriving, it is clear that careful attention has to be paid to control overhead. Note that, as we have seen in Chapter 2, as CPUs get faster, historically the control overheads associated with context switching, system calls, and interrupts have not improved at the same rate. Some progress has been made with more efficient operating systems such as Linux, but the progress will not be sufficient to keep up with increasing link speeds.
We now begin attacking the bottlenecks described in Figure 6.2.
6.2 AVOIDING SCHEDULING OVERHEAD IN NETWORKING CODE
One of the major difficulties with implementing a protocol is to balance modularity (so you implement a big system in pieces and get each piece right, independent of the others) and performance (so you can get the overall system to perform well). As a simple example, consider how one might implement a networking stack. The “obvious modularity” would be to implement the transport protocol (e.g., TCP) as a process, the routing protocol (e.g., IP) as a process, and the applications as a separate process. If that were the case, however, every received packet would take at least two process-context switches, which are expensive. There are, however, a number of creative alternatives that allow modularity as well as efficiency. These were first pointed out by Dave Clark in a series of papers.
Figure 6.3 provides an example that Clark [Cla85] used to illustrate his ideas. It consists of a simple application that reads data from a keyboard and sends it to the network using a reliable transport protocol. When the data is received by some receiver on the network, the data is displayed on the screen. The vertical slices show the various protocol layers, with the topmost slice (routines such as display-get-data and display-receive) being the application protocol, the second slice (routines such as transport-receive and transport-send) being the transport protocol, and the bottom slice (routines such as net-receive and net-dispatch) being the network protocol. The naive way to implement this protocol would be to have a process per slice, which would involve three processes and two full-scale context switches per received or sent packet.
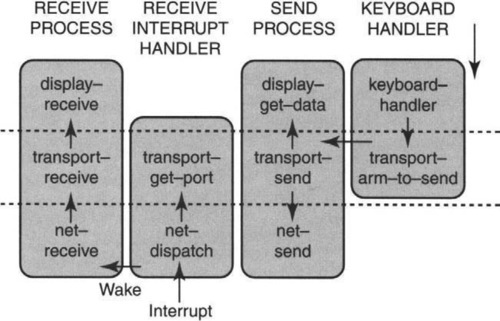
Instead, Clark suggests using only two processes each at the sender and two processes at the receiver (shown as boxed vertical sections) to implement the network protocol stack. In Figure 6.3 the leftmost two sections correspond to receiver processes and the rightmost two sections correspond to sender processes. Thus the sender has a Keyboard Handler process that gathers data coming in from the keyboard and calls transport-arm-to-send when it has got some data. Notice that transport-arm-to-send is a transport-layer function that is exported to the Keyboard Handler process and is executed by the Keyboard Handler process. At this point the Keyboard Handler can suspend itself (a context switch). Transport-arm-to-send only tells the transport protocol that this connection wished to send data; it does not transfer data.
However, the transport-send process may not send data immediately because of flow control limitations. When the flow control limits are removed (because of acks arriving), the Send Process will execute the transport-send routine for this connection. The send call will first upcall the application protocol, which exports a routine called display-get-data that actually provides the transport protocol with the data for the application. This is advantageous because the application may have received more keyboard data by the time the transport protocol is ready to send, and one might as well send as much data as possible in a packet. Finally, within the context of the same process, transport adds a transport-layer header and makes a call to the network protocol to actually send the packet.
At the receiving end, the packet is received by the receive interrupt handler using a network-layer routine called net-dispatch that needs to find which process to dispatch the received packet to. To find out, net-dispatch makes an upcall to transport-get-port. This is a routine exported by the transport layer that looks at port numbers in the header to figure out which application (e.g., FTP) must handle the packet. Then a context switch is made and the Receive Handler relinquishes control and wakes up the Receive Process, which executes network-layer functions, transport-layer functions, and finally the application-level code to display the data. Note that a single process is executing all the layers of protocol.
The idea was a bit unusual at the time because the conventional dogma until that point was that layers should only use services of layers below; thus calls between layers had, historically, been “downcalls.” However, Clark pointed out that downcalls were perhaps required for protocol specifications but were not the only alternative for protocol implementations. In our example in particular, upcalls are used to obtain data (e.g., the upcall to display-get-data) and for advice from upper layers (upcall to transport-get-port).
While upcalls are commonly used in real implementations, there is probably no difference between an upcall and a standard procedure call except for its possible novelty in the context of a networking layered implementation. However, the more important idea, which is perhaps more lasting, is the idea of using only one or two processes to process a message, each process consisting of routines from two or more protocol layers. This idea found its way into systems like the x-kernel [HP91] and into user-level networking, which is described in the next section.
More generally, the idea of considering alternative implementation structures that preserve modularity without sacrificing performance is a classic example of Principle P8, which says that implementors should consider alternatives to reference implementations described in specifications. Notice that each protocol layer can still be implemented modularly but the upcalled routines can be registered by upper layers when the system starts up.
6.2.1 Making User-Level Protocol Implementations Real
Most modern machines certainly do not implement each protocol layer in a separate process. Instead, in UNIX all the protocol code (transport, network, and data link) is handled as part of a single kernel “process.” When a packet arrives via an interrupt, the interrupt handler notes the arrival of the packet, possibly queues it to memory, and then schedules a kernel process (via what is sometimes called a software interrupt) to actually process the packet.
The kernel process does the data link, network, and transport-layer code (using upcalls); by looking at the transport port numbers, the kernel process knows the application. It then wakes up the application. Thus every packet is processed using at least two context switches: one from the interrupt context to the kernel process doing protocol handling, and one from the kernel process to the process running the application code (e.g., the Web, FTP).
The idea behind user-level protocol implementation is to realize the aspect of Clark’s idea shown in the receive process of Figure 6.3, where the protocol handlers execute in the same process as the application and can communicate using upcalls. User-level implementations have two possible advantages: We can potentially bypass the kernel and go directly from the interrupt handler to the application, as in the Clark model, saving a context switch. Also, the protocol code can be written and debugged in user space, which is a far friendlier place to implement protocols (debugging tools work in user space and do not work well at all in the kernel).
One extreme way to do this was advocated in Mach, where all protocols were implemented in user space. Also, protocols were allowed to be significantly more general than in Clark’s example of Figure 6.3. Thus when a receiving interrupt handler received a packet, it had no way of easily telling to which process it should dispatch the packet (since the network-layer implementations done in the final process contained the demultiplexing code). In particular, one can’t just call transport to examine the port number (as in Clark’s example) since we can have lots of possible transport protocols and lots of possible network protocols.
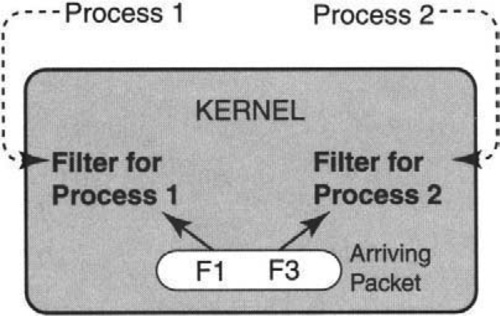
A naive method was initially used, as shown in Figure 6.4. This involved a separate demultiplexing process that received all packets and examined them to determine the final destination process, which is then dispatched to. This is quite sad, because our efforts so far have been to reduce context switches, but the new demultiplexing process is actually adding back the missing context switch.

The simple idea used to remedy this situation is to pass extra information (P9) across the application–kernel interface so that each application can pass information about what kinds of packets it wants to process. This is shown in Figure 6.5. For example, a mail application may wish for all packets whose Ethernet-type field is IP, whose IP protocol number specifies TCP, and whose TCP destination port number is 25.
Recall that we are talking about the mail application implementing all of IP, TCP, and mail. To do so, the kernel defines an interface, which is typically some form of programming language. For example, the earliest one was the CSPF (CMU Stanford packet filter), which specifies the fields for packets using a stack-based programming language. A more commonly used language is BPF (Berkeley packet filter), which uses a stack-based language; a more efficient language is PathFinder. These demultiplexing algorithms are described in Chapter 8.
Note that one has to be careful about passing information from an application to a kernel; any such information should be checked so that malicious or wrong applications cannot destroy the kernel. In particular, one has to prevent applications from providing arbitrary code to kernels, which then causes havoc. Fortunately, there are software technologies that can “sandbox” foreign code so it can do damage only within its own allotted space of memory (its sandbox). For example, a stack-based language can be made to work on a specified size of stack that can be bounds checked at every point. This form of technology has culminated recently in execution of arbitrary Java applets received from the network.
Clearly, if packets are dispatched from the kernel interrupt handler (using the collection of packet filters) to the receiving process, the receiving process should implement the protocol stack. However, replicating the TCP/IP code in every application would cause a lot of code redundancy. Thus TCP/IP is generally (in such systems) implemented as a shared library that is linked in (a single copy is used to which the application has a pointer, but with the code written in a so-called reentrant way, to allow reuse).
This is not as easy as it looks because there is some TCP state that is common to all connections, though most are TCP state connection specific. There are other problems because the last write done by an application should be retransmitted by TCP, but the application may exit its process after its last write. However, these problems can be fixed. User-level implementations have been written [TNML93, MB93] to provide excellent performance. Fundamentally, they exploit a degree of freedom (P13) in observing that protocols do not have to be implemented in the kernel.
6.3 AVOIDING CONTEXT-SWITCHING OVERHEAD IN APPLICATIONS
The last section concentrated on removing process-scheduling overhead for processing a single packet received by the network by effectively limiting the processing to fielding one interrupt (which, as we discuss in Section 6.6, can also be removed or amortized over several packets) and dispatching the packet to the final process in which the application (that processes the packet) resides. If the destination process is currently running, then there is even no processscheduling overhead. Thus after all optimizations there can be close to no control overhead for processing a packet.
This is analogous to Chapter 5, in which the first few sections showed how to process a received packet with zero copies. However, in that chapter after broadening one’s viewpoint to see the complete application processing, it became apparent that there were further redundant copies caused by interactions with the file system.
In a similar fashion, this section broadens beyond the processing of a single packet to consider how an application processes packets. Once again, as in Chapter 5, we consider a Web server (Figure 6.2) because it is a canonical example of a server that needs to be made more efficient and because of its importance in practice.
In what follows, we will use a Web server as an example of a canonical server that may require the handling of a large number of connections. In another example, Barile [Bar04] describes a TCP-to-UDP proxy server for a telephony server that can handle 100,000 concurrent connections.
How should a Web server be structured? Before tackling this question, it helps to understand the potential concurrency within a single Web server. Readers familiar with operating systems may wish to skim over the next three paragraphs. These are included for readers not as familiar with the secret life of a workstation.1
Even with a single CPU and a single disk head, there are opportunities for concurrency. For example, assume that in processing a read for File 1, File 1 is not in cache. Thus the CPU initiates a disk read. Since this may take a few milliseconds to complete, and the CPU can do an instruction almost every nanosecond, it is obvious waste to idle the CPU during this read. Thus a more sensible strategy is to have the CPU switch to processing another client while Client 1 ’s disk read is in progress. This allows processing by the disk on behalf of Client 1 to be overlapped with processing by the CPU for Client 2.
A second example of concurrency between the CPU and a device (that is relevant to a Web server) is overlapping between network I/O (as performed by the adaptor) and the CPU. For example, after a server accepts a connection, it may do a Read to an accepted connection for Client 1. If the CPU waits for the Read to complete it may wait a long time, potentially also several milliseconds. This is because the remote client has to send a packet that has to make its way through the network and finally be written by the adaptor to the socket corresponding to Client 1 at the server.
By switching to another client, processing by the network on behalf of Client 1 is overlapped with processing by the CPU on behalf of some other client. Similarly, when doing a Write to the network, the Write may be blocked because of the lack of buffer space in the socket buffer. This buffer space may be released much later when acknowledgments arrive from the destination.
The last three paragraphs show that for a Web server to be efficient, every opportunity for concurrency must be exploited to increase effective throughput. Thus a CPU in a Web server must switch between clients when one client is blocked waiting for I/O. We now consider various ways to structure a server application and their effects on concurrency and scheduling overhead.
6.3.1 Process per Client
In terms of programming, the simplest way to implement a Web server is to structure the processing of each client as a separate process. In other words, every client is in a separate group by itself in Figure 6.2. In Chapter 2, we saw that the operating system scheduler juggles between processes, assigning a new process to a CPU when a current process is blocked. Most modern operating systems also can take into account multiple CPUs and schedule the CPUs such that all CPUs are doing useful work wherever possible.
Thus the Web server application need not do the juggling between clients; the operating system does this automatically on the application’s behalf. For example, when Client 1 is blocked waiting for the disk controller, the operating system may save all the context for the Client 1 process to memory and allow the Client 2 process to run by restoring its context from memory.
This simplicity, however, comes at a cost. First, as we have seen, process-context switching and restoring is expensive. It requires reads and writes from memory to registers to save and restore context. Recall that the context includes changing the page tables being used (because page tables are per process); thus any virtual memory translations cached within the TLB need to be cached. Similarly, the contents of the data cache and the instruction cache are likely to represent the tastes and preferences of the previously resident process; thus much of it may be useless to the new process. When all caches fail, the initial performance of the switched-in process can be very poor.
Further, spawning a new process when a new client comes in, as was done by some initial Web servers, is also expensive.2 Fortunately, the overhead to create and destroy processes when clients come and go can be avoided by precomputation and/or lazy process deletion (P2, shifting computation in time). When a client finishes its request processing and the connection is terminated, rather than destroy the process, the process can be returned to a pool of idle processes. The process can then be assigned to the next new client that needs a process to shepherd its request through the server.
A second issue is the problem of matchmaking between new arriving clients and processes in the process pool. A naive way to do this is as follows. Each new client is handed to a well-known matchmaking process, which then hands off each new client to some available process in the pool. However, operating system designers have realized the importance of matchmaking. They have invented system calls (for instance, the Accept call in UNIX) to do matchmaking at the cost of a system call invocation, as opposed to requiring a process-context switch.
When a process in the pool is done it makes an Accept call and waits in line in a kernel data structure. When a new client comes in, its socket is handed off to the idle process that is first in line. Thus the kernel provides matchmaking services directly.
6.3.2 Thread per Client
Even after removing the overheads of creating a process on demand and the overhead of matchmaking, processes are an expensive solution. Since slow wide-area connections to servers are very common and the rate of arrivals to popular Web servers can easily exceed 2000 per second, it is not unusual for a Web server to have 6000 concurrent clients being served at once.
As we have seen, even if the processes are already created, switching between processes incurs TLB and cache misses and requires effort to save and restore context. Further, each process requires memory to store context. This can take away from the memory needed by the file cache.
An intermediate stance is to use threads, or lightweight processes. Note that threads generally trust each other, as is appropriate for all the threads processing different clients in a Web server. Thus in Figure 6.6, we can replace the processing of each client with a separate thread per client, all within the protection of a single process. Note that the threads share the same virtual memory. Thus TLB entries do not have to be flushed between threads.
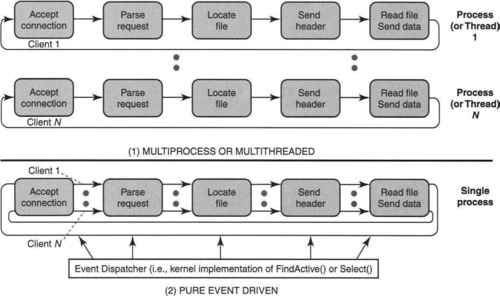
Further, the fact that threads can share memory implies that all threads can use a common cache to share file name translations and even files. Implementing a process per client, on the other hand, implies that file caches can often not be shared efficiently across processes, because each process uses a separate virtual memory space. Thus application caches for Web servers, as described in Chapter 5, will suffer in performance because files common to many clients are replicated.3 Thus a popular Web server, the Apache Web server, is implemented using a thread per client in Windows.
However, when all is said and done, the overhead for switching between threads, while smaller than that for switching between processes, is still considerable. Fundamentally, the operating system must still save and restore per-thread context such as stacks and registers. Also, the memory required to store per-thread or per-process state takes away from the file cache, which then leads to potentially higher miss rates.
6.3.3 Event-Driven Scheduler
If a general-purpose operating system facility is too expensive, the simplest strategy is to avoid it completely. Thus while thread scheduling provides a facility for juggling between clients without further programming, if it is too expensive, the application may benefit from doing the juggling itself. Effectively, the application must implement its own internal scheduler that juggles the state of each client.
For example, the application may have to implement a state machine that remembers that Client 1 is in Stage 2 (HTTP processing) while Client 2 is in Stage 3 (waiting for disk I/O) and Client 3 is in Stage 4 (waiting for a socket buffer to clear up to send the next part of the response).
However, the kernel has an advantage over an application program because the kernel sees all I/O completion events. For example, if Client 1 is blocked waiting for I/O, in a per-thread implementation, when the disk controller interrupts the CPU to say that the data is now in memory, the kernel can now attempt to schedule the Client 1 thread.
Thus if the Web server application is to do its own scheduling between clients, the kernel must pass information (P9) across the API to allow a single threaded application to view the completion of all I/O that it has initiated. Many operating systems provide such a facility, which we generically called FindActive() in Figure 6.2. For example, Windows NT 3.5 has an I/O completion port (IOCP) mechanism, and UNIX provides the select() system call.
The main idea is that the application stays in a loop invoking the FindActive() call. Assuming there is always some work to do on behalf of some client, the call will return with a list of I/O descriptors (e.g., file 1 data is now in memory, connection 5 has received data) with pending work. When the Web server processes these active descriptors, it loops back to making another FindActive() call.
If there is always some client that needs attention (typically true for a busy server), there is no need to sleep and invoke the costs of context switching (e.g., scheduler overhead, TLB misses) when juggling between clients. Of course, such juggling requires that the application keep a state machine that allows it to do its own context switching among the many concurrent requests. Such application-specific internal scheduling is more efficient than invoking the general-purpose, external scheduler. This is because the application knows the minimum set of context that must be saved when moving from client to client.
The Zeus server and the original Harvest/Squid proxy cache server use the single-process event-driven model. Figure 6.6 contrasts the multiprocess (and multithreaded) server architectures with an event-driven architecture. The details of a generic event-driven implementation using a single process can be found in Barile [Bar04], together with pointers to source code. Barile [Bar04] describes generic code that is abstracted to work across platforms (a crucial requirement for today’s server environments), including Windows and UNIX.
6.3.4 Event-Driven Server with Helper Processes
In principle, an event-driven server can extract as much concurrency from a stream of client operations as a multiprocess or multithreaded server. Unfortunately, many operating systems, such as UNIX, do not provide suitable support for nonblocking disk operations.
For example, if an event-driven server is not to waste opportunities to do useful work, then when it issues a read() to a file that is not in cache, we wish the read() to return immediately saying it is unavailable so that the read() is nonblocking. This allows the server to move on to other clients. Later, when the disk I/O completes, the application can find out using the next invocation of the FindActive() call. On the other hand, if the read() call is blocking, then the server main loop would be stuck waiting for the milliseconds required for disk I/O to complete.
The difficulty is that many operating systems, such as Solaris and UNIX, allow nonblocking read() and write() operations on network connections but may block when used on disk files. These operating systems do allow other asynchronous system calls for disk I/O, but these are not integrated with the select() call (i.e., the UNIX equivalent of FindActive()). Thus in such operating systems one must choose between the loss of concurrency incurred by blocking on disk I/O and going beyond the single-process model.
The Flash Web server [PDZ99a] goes beyond the single-process model to maximize concurrency. When a file is to be read, the main server process first tests if the file is already in memory using either a standard system call4 or by locking down the file cache pages so that the server process always knows which files are in the cache.5 If the file is not in memory, the main server process instructs a helper process to perform the potentially blocking disk read. When the helper is done, it communicates to the main server process via some form of interprocess communication such as a pipe.
Note that unlike the multiprocess model, helpers are needed only for each concurrent disk operation and not for each concurrent client request. In some sense, this model exploits a degree of freedom (P13) by observing that there are interesting alternatives between a single process and a process per client.
Besides file reads, helper processes can also be used to do directory lookups to locate the file on disk. While Flash maintains a cache that maps between directory path names and disk files, if there is a cache miss, then there is a need to search through on-disk directory structures. Since such directory lookups can also block, these are also relegated to helper processes. Increasing the pathname cache does increase memory consumption, but the reduced cache miss rate may reduce the number of helper processes required and so decrease memory overall.
Clearly, helper processes should be prespawned to avoid the latency of creating a process each time a helper process is invoked. How many helper processes should be spawned? Too few can cause concurrency loss, and too many results in wasted memory. The solution in Flash [PDZ99a] is to dynamically spawn and destroy helper processes according to load.
6.3.5 Task-Based Structuring
The top of Figure 6.7 depicts the event-driven approach augmented with helper processes. Notice the similarity to the simple event-handler approach shown at the bottom of Figure 6.6, except for the addition of helper processes.
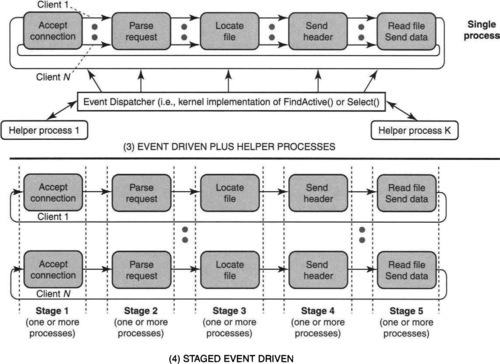
There are some problems with the event-driven architecture with helper processes.
• Complexity: The application designer must manage the state machine for juggling client requests without help.
• Modularity: The code for the server is written as one piece. While Web servers are popular, there are many other Web services that may use some similar pieces of code (e.g., for accepting connections). A more modular approach could allow code reuse.
• Overload control: Production Web servers have to deal with wide variations of load from huge client populations. Thus it is crucial to continue to make some progress during overload (without thrashing) and to be as fair as possible across clients.
The main idea in the staged event-driven architecture [WCB01] is to exploit another degree of freedom (P13) in decomposing code. Instead of decomposing into threads horizontally by client, as in a multithreaded architecture, the server system is decomposed vertically by tasks within each client request cycle, as shown on the bottom of Figure 6.6. Each stage can be handled by one or more threads. Thus the staged model can be considered a refinement of the simple event-driven model. This is because it assigns a main thread and a potential thread to each stage of server processing. Once that is done, the stages communicate via queues, and more refined overload control can be done at each stage.
6.4 FAST SELECT
To motivate the fast-selection problem, Section 6.4.1 presents a mysterious performance problem found in the literature. Section 6.4.2 then describes the usage and implementation of the select() call in UNIX. Section 6.4.3 describes an analysis of the overheads, and applies the implementation principles to suggest ideas for improvement. Based on the analysis, Section 6.4.4 describes an improvement, assuming that the API cannot change. Finally, Section 6.4.5 proposes an even better solution that involves a more dramatic change to the API.
6.4.1 A Server Mystery
The previous section suggested that avoiding process-scheduling overheads was important in a Web server. For example, an event-driven server completely reduces process scheduling overhead by using a single thread for all clients and then using a FindActive() call such as select(). Now, the CERN Web proxy used a process per client, and the Squid (formerly Harvest) Web server [CDea96] used an event-driven implementation. Measurements done in a LAN environment indeed showed [CDea96] that the Squid Web proxy performed an order of magnitude better than the CERN server.
A year later another group repeated these tests in a WAN (i.e., wide area network) environment [MRG97] and found that in the WAN environment there was no difference in performance between the CERN and Squid servers. The problem is to elucidate this mystery.
The mystery was finally solved by Banga and Mogul [BM98]. A key observation is that given the same throughput (in terms of connections per second), the higher round-trip delays in a WAN environment lead to a larger number of concurrent connections in a WAN setting. For example, in a WAN environment with mean connection times of 2 seconds [BMD99] and a Web server throughput of 3000 connections per second, Little’s law (from queuing theory) predicts that the average number of concurrent connections is the product, or 6000.
On the other hand, in a LAN environment with a round-trip delay of 2 msec, the average number of concurrent connections drops to six. Note that if the throughput stays the same, in the wide area setting a large fraction of the connections must be idle (waiting for replies) at any given time.
Given this, the two main causes of overhead were two system calls used by the event-driven server. The standard UNIX implementation of both these calls scales poorly with a large number of connections. The two calls were:
• select(): Event-driven servers running on UNIX use the select() call for the FindActive() call. Experiments by Banga and Mogul [BM98] show that more than half of the CPU is used for kernel and user-level select() functions with 500 connections.
• ufalloc(): The server also needs to allocate the lowest unallocated descriptor for new sockets or files. This seemingly simple call took around a third of the CPU time.
ufalloc() performance can easily be explained and fixed. Normally, finding a free descriptor can be efficiently implemented using a free list of descriptors. Unfortunately, UNIX requires choosing the lowest unused descriptor. For example, if the currently allocated descriptor list has the elements (in unsorted order) 9,1,5,4,2, then one cannot determine that the lowest unallocated number is 3 without traversing the entire unsorted list. Fortunately, a simple change to the kernel implementation (P15, use efficient data structures) can reduce this overhead to nearly zero.6
6.4.2 Existing Use and Implementation of select()
Assuming that ufalloc() overhead can easily be minimized by changing the kernel implementation, it is important to improve the remaining bottleneck caused by the select() implementation in an event-driven server. Because the causes of the problem are more complex, this section starts by reviewing the use and implementation of select() in order to understand the various sources of overhead.
PARAMETERS
Select() is called as follows:
• Input: An application calls select() with three bitmaps of descriptors (one for descriptors it wishes to read from, one for those it wishes to write from, and one for those it wishes to hear exceptions from) as well as a timeout value.
• Interim: The application is blocked if there is no descriptor ready.
• Output: When something of interest occurs, the call returns with number of ready descriptors (passed by value as an integer) and the specific lists of descriptors of each category (passed by reference, by overwriting input bitmaps).
USAGE IN A WEB SERVER
Having understood the parameters of the select() call, it is important to understand how select() could be used by an event-driven Web server. A plausible use of select() is as follows [BM98], The server application thread stays in a loop with three major components:
• Initialize: The application first zeroes out bitmaps and sets bits for descriptors of interest for read and write. For example, the server application may be interested in reading from file descriptors and writing and reading from network sockets open to clients.
• Call: The application then calls select() with bitmaps it built in the previous step, and it blocks if no descriptor is ready at the point of call; if a timeout occurs, the application does exception processing.
• Respond: After the call returns, the application linearly walks through returned bitmaps and invokes appropriate read and write handlers for descriptors corresponding to set bit positions.
Note that the costs of building the bitmaps in Step 1 and scanning the bitmaps in Step 3 are charged to the user, though they are directly attributable to the costs of preparing for and responding to a select() call.
IMPLEMENTATION
Having understood the parameters of the select() call, it is important to understand how select() is implemented in the kernel of a typical UNIX variant [WS95]. The kernel does the following (annotated with sources of overhead):
• Prune: The kernel starts by using the bitmaps passed as parameters to build a summary of descriptors marked in at least one bitmap (called the selected set).
This requires a linear search through bitmaps of size N regardless of how many descriptors the application is currently interested in.
• Check: Next, for each descriptor in the selected set, the kernel checks if the descriptor is ready; if not, the kernel queues the application thread ID on the select queue of the descriptor. The kernel puts the calling application thread to sleep if no descriptors are ready.
This requires investigation of all selected descriptors, independent of how many are actually ready. This step is more expensive than simply scanning a bitmap.
• Resume: When I/O occurs to make a descriptor ready (i.e., a packet arrives to a socket that the server is waiting for data from), the kernel I/O module checks its select queue and wakes up all threads waiting for a descriptor.
This requires scheduler overhead, which seems fundamentally unavoidable without polling or busy waiting.
• Rediscover: Finally, select() rediscovers the list of ready descriptors by making a scan of all selected descriptors to see which have become ready between the time select() was put to sleep and was later awakened. This requires repeating the same expensive checks made in Step 2.
They are repeated despite the fact that the I/O module knew which descriptors became ready but did not inform the select() implementation.
6.4.3 Analysis of Select()
We start by describing opportunities for optimization in the existing select() implementation and then use our principles to suggest strategies to improve performance.
OBVIOUS WASTE IN Select() IMPLEMENTATION
Principle P1 seeks to remove obvious waste. In order to apply Principle P1, it helps to catalog the sources of “obvious waste” in the select() implementations. With each source of waste, we also attach a scapegoat that can be blamed for the waste.
1. Recreating interest on each call: The same bitmap is used for input and output. This overloading causes the application to rebuild the bitmaps from scratch, though it may be interested in most of the same descriptors across consecutive calls to select(). For example, if only 10 bits change in a bitmap of size 6000 on each call, the application still has to walk through 6000 bits, to set each if needed.
Blame this on either the interface (API) or on the lack of incremental computing in the application.
2. Rechecking state after resume: No information is passed from a protocol module (that wakes up a thread sleeping on a socket) to the select() call that is invoked when the thread resumes. For example, if the TCP module receives data on socket 9, on which thread 1 is sleeping, the TCP module will ensure that thread 1 is woken up. However, no information is passed to thread 1 as to who woke up thread 1; thus thread 1 must again check all selected sockets to determine that socket 9 indeed has data. Clearly, the TCP module knew this when it woke up thread 1.
Blame the kernel implementation.
3. Kernel rechecks readiness for descriptors known not to be ready: The Web server application is typically interested in a socket until connection failure or termination. In that case, why repeat tests for readiness if no change in state has been observed? For example, assume that socket 9 is a connection to a remote client with a delay of 1 second to send and receive network packets. Assume that at time t a request is sent to the client on socket 9 and the server is waiting for a response, which arrives at t + 1 seconds. Assume that in the interval from t to t + 1, the server thread calls select() 15,000 times. Each time select() is called the kernel makes an expensive check of socket 9 to determine that no data has arrived. Instead, the kernel can infer this from the fact that the socket was checked at time t and no network packet has been received for this socket since time t. Thus 15,000 expensive and useless checks can be avoided; when the packet finally arrives at time t + 1, the TCP module can pass information to reinstate checking of this socket.
Blame the kernel implementation.
4. Bitmaps linear with descriptor size: Both kernel and user have to scan bitmaps proportional to the size of possible descriptors, not to the amount of useful work returned. For example, if there are 6000 possible descriptors a Web server may have to deal with at peak load, the bitmaps are of length 6000. Suppose during some period there are 100 concurrent clients, of which only 10 are ready during each call to select(). Both kernel and application are scanning and copying bitmaps of size 6000, though the application is only interested in 200 bits and only 10 bits are set when each select() returns.
Blame the API.
STRATEGIES AND PRINCIPLES TO FIX SELECT
Given the sources of waste just listed, some simple strategies can be applied using our algorithmic principles.
• Recreate interest on each call: Consider changing the API (P9) to use separate bitmaps for input and output. Alternatively, preserve the API and use incremental computation. (P12a)
• Recheck state after resume: Pass information between protocol modules that know when a descriptor is ready and the select module. (P9)
• Have kernel recheck readiness for descriptors known not to be ready. Kernel keeps state across calls so that it does not recheck readiness for descriptors known not to be ready. (P12a, use incremental computation)
• Use bitmaps linear with ready size, not descriptor size: Change the API in a fundamental way to avoid the need for state-based queries about all descriptors represented by bitmaps. (P9)
6.4.4 Speeding Up Select() without Changing the API
Banga and Mogul [BM98] show how to eliminate the first three (of the four) elements of waste listed earlier.
1. Avoid rebuilding bitmaps from scratch: The application code is changed to use two bitmaps of descriptors it is interested in. Bitmap A is used for long-term memory, and bitmap B is used as the actual parameter passed by reference to select(). Thus between calls to select(), only the (presumably few) descriptors that have changed have to be updated in bitmap A. Before calling select(), bitmap A is copied to bitmap B. Because copy can proceed a word at a time, the copy is more efficient than a laborious bit-by-bit inspection of the bitmap. In essence, the new bitmap is being computed incrementally. (P12a)
2. Avoid rechecking all descriptors when select() wakes up: To avoid this overhead, the kernel implementation is modified such that each thread keeps a hints set H that records sockets that have become ready since the last time the thread called select(). The protocol or I/O modules are modified such that when new data arrives (network packet, disk I/O completes), the corresponding descriptor index is written to the hints set of all threads that are on the select queue for that descriptor. Finally, after a thread wakes up in select(), only the descriptors in H are checked. The essence of this optimization is passing hints between layers. (P9)
3. Avoid rechecking descriptors known not to be ready: The fundamental observation is that a descriptor that is waiting for data need not be checked until asynchronous notification occurs (e.g., the descriptor is placed in hints set H described earlier). Clearly, however, any newly arriving descriptors (e.g., newly opened sockets) must be checked. A third, subtle point is that even after network data has arrived for a socket (e.g., 1500 bytes), the application may read only 200 bytes. Thus a descriptor must be checked for readiness even after data first arrives, until there is no more data left (i.e., application reads all data) to signify readiness.
To implement these ideas, besides the hints set H for each thread, the kernel implementation keeps two more sets. The first is an interested set I of all descriptors the thread is interested in. The second is a set of descriptors R that are known to be ready. The interested set I reflects long-term interest; for example, a socket is placed in I the first time it is mentioned in a select() call and is removed only when the socket is disconnected or reused. Let the set passed to select() be denoted by S. Then I is updated to Inew = Iold ∪ S. Note that this incorporates newly selected descriptors without losing previously selected descriptors.7
Next, the kernel checks only those descriptors that are in Inew but are either (i) in the hints set H or (ii) not in Iold or (iii) in the old ready set Rold Note that these three predicates reflect the three categories discussed two paragraphs back. They represent either recent activity, newly declared interest, or unconsumed data resulting from prior activity. The descriptors found by the check to be ready are recorded in Rnew. Finally, the select() call returns to the user the elements in Rnew ∩ S. This is because the user only cares about the readiness of descriptors specified in the selecting set S.
As an example, socket 15 may be checked when it is first mentioned in a select() call and so enters I; socket 15 may be checked next when a network packet of 500 bytes arrives, causing socket 15 to enter H; finally, socket 15 may be checked repeatedly as part of R until the application consumes all 500 bytes, at which point socket 15 leaves R. The basis of this optimization is P12, adding state for speed. The optimization maintains state across calls (P12) to reduce redundant checks.
6.4.5 Speeding Up Select() by Changing the API
The technique described in Section 6.4.4 improves performance considerably by eliminating the first three (and chief) sources of overhead in select(). However, it does so by maintaining extra state (P12) in the form of three more sets of descriptors (i.e., H, I, and R) that are also maintained as bitmaps. This, taken together with the selection set S passed in each call, requires the scanning and updating of four separate bitmaps.
In a situation where a large number of connections are present but only a few are active at any instant, this fundamentally still requires paying some small overhead, proportional to the total number of connections as opposed to the number of active connections. This is the fourth source of “waste” enumerated earlier, and it appears unavoidable given the present API.
Further, as we saw earlier, even the modified fast select() potentially checks a descriptor multiple times for each event such as a packet arrival (if the application does not consume all the data at once). Such additional checks are unavoidable because select() provides the state of each descriptor.
If one looks closely at the interface, what the application fundamentally requires is to be notified of the stream of events (e.g., file I/O completed, network packet arrived) that causes changes in state. Event-based notifications appear, on the surface, to have some obvious drawbacks that may have prevented them from being used in the past.
• Asynchronous Notification: If the application is notified as soon as an event occurs, this can take excessive overhead and be difficult to program. For example, when an application is servicing socket 5, a packet to socket 12 may arrive. Interrupting the application to inform it of the new packet may be a bad idea.
• Excessive Event Rate: The application is interested in the events that cause state change and not in the raw event stream. For a large Web transfer, several packets may arrive to a socket and the application may wish to get one notification for a batch, and not one for every packet. The overhead for each notification is in terms of communication costs (CPU) as well as storage for each notification.
Principle P6 suggests designing efficient specialized routines to overcome bottlenecks. In this spirit, Banga, Mogul, and Druschel [BMD99] describe a new event-based API that avoids both these problems.
• Synchronous Inquiry: As in the original select() call, the application can inquire for pending events. For example, in the previous example, the application continues to service socket 5 and all other active sockets before asking for (and being told about) events such as packet arrival on socket 5.
• Coalescing of Events: If a second event occurs for a descriptor while a first event has been queued for notification, the second notification is omitted. Thus there can be at most one outstanding event notification per descriptor.
The use of this new API is straightforward and roughly follows the style in which applications use the old select() API. The application stays in a loop in which it asks synchronously for the next set of events and goes to sleep if there are none. When the call returns, the application goes through each event notification and invokes the appropriate read or write handlers. Implicitly, the setting up of a connection registers interest in the corresponding descriptor, while disconnection removes the descriptor from the interest list.
The implementation is as follows. Associated with each thread is a set of descriptors in which it is interested. Each descriptor (e.g., socket) keeps a reverse mapping list of all threads interested in the descriptor. On I/O activity (e.g., data arrival on a socket), the I/O module uses its reverse mapping list to identify all potentially interested threads. If the descriptor is in the thread’s interested set, a notification event is added to a queue of pending events for that thread.
A simple per-thread bitmap, one bit per descriptor, is used to record the fact that an event is pending in the queue and is used to avoid multiple event notifications per descriptor. Finally, when the application asks for the next set of events, these are returned from the pending queue.8
6.5 AVOIDING SYSTEM CALLS
For now forget about the intervening discussion of select(), and recall the discussion of user-level networking. We seem to have gotten the kernel out of the picture on the receipt or sending of a packet, but sadly that is not quite the case. When an application wants to send data, it must somehow tell the adaptor where the data is.
When the application wants to receive data, it must specify buffers where the received packet data should be written to. Today, in UNIX this is typically done using system calls, where the application tells the kernel about data it wishes to send and buffers it wishes to receive to. Even if we implement the protocol in user space, the kernel must service these system calls (which can be expensive; see Chapter 2) for every packet sent and received.
This appears to be required because there can be several applications sending and receiving data from a common adaptor; since the adaptor is a shared resource, it seems unthinkable for an application to write directly to the device registers of a network adaptor without kernel mediation to check for malicious or erroneous use. Or is it?
A simple analogy suggests that alternatives may be possible. In Figure 6.8 we see that when an application wants to set the value of a variable X equal to 10, it does not actually make a call to the kernel. If this were the case, every read and write in a program would be slowed down very badly. Instead, the hardware determines the virtual page of X, translates it to a physical page (say, 10) via the TLB, and then allows direct access as long as the application has Page 10 mapped into its virtual memory.
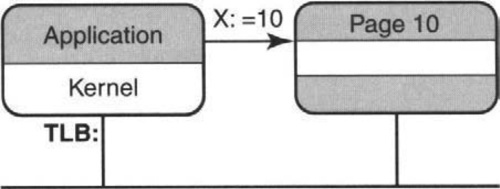
If Page 10 is not mapped into the application’s virtual memory, the hardware generates an exception and causes the kernel to intervene to determine why there is a page access violation. Notice that the kernel was involved in setting up the virtual memory for the application (only the kernel should be allowed to do so, for reasons of security) and may be involved if the application violates its page accesses that the kernel set up. However, the kernel is not involved in every access. Could we hope for a similar approach for application access to adaptor memory to avoid wasted system calls (P1)?
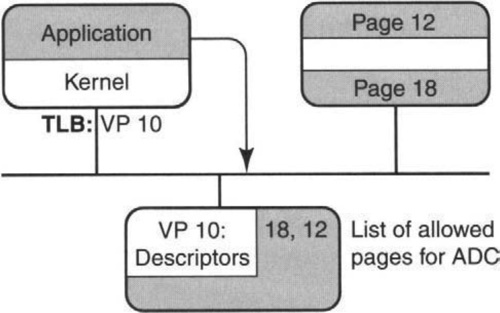
To see if this is possible we need to examine more carefully what information an application sends and receives from an adaptor. Clearly, we must prevent incorrect or malicious applications from damaging other applications or the kernel itself. Figure 6.9 shows an application that wishes to receive data directly from the adaptor. Typically, an application that does so must queue a descriptor. A descriptor is a small piece of information that describes the buffer in main memory where the data for the next packet (for this application) should be written to. Thus we should consider carefully and separately both descriptor memory as well as the actual buffer memory.
We can deal with descriptor memory quite easily by recalling that the adaptor memory is memory mapped. Suppose that the adaptor has 10,000 bytes of memory that is considered memory on the bus and that the physical page size of the system is 1000 bytes. This means that the adaptor has 10 physical pages. Suppose we allocate two physical pages to each of five high-performance applications (e.g., Web, FTP) that want to use the adaptor to transfer data. Suppose the Web application gets two physical pages, 9 and 10. Then the kernel maps the physical pages 9 and 10 into the Web application’s page table and the physical pages 3 and 4 into the FTP application’s page table.
Now the Web application can write directly to physical pages 9 and 10 without any danger; if it tries to write into pages 3 and 4, the virtual memory hardware will generate an exception. Thus we are exploiting existing hardware (P4c) in the form of the TLB to protect access to pages. So now let us assume that Page 10 is a sequence of free buffer descriptors written by the Web application; each buffer descriptor describes a page of main memory (assume this can be done using just 32 bits) that will be used to receive the next packet described for the Web application.
For example, Page 10 could contain the sequence 18, 12 (see Figure 6.9). This means that the Web application has currently queued physical pages 18 and 12 for the next incoming packet and its successor. We assume that pages 18 and 12 are in main memory and are physically locked pages that were assigned to the Web application by the kernel when the Web application first started.
When a new packet arrives for the Web application, the adaptor will demultiplex the packet to the descriptor Page 10 using a packet filter, and then it will write the data of the packet (using DMA) to Page 18. When it is done, the adaptor will write the descriptor 18 to a page of written page descriptors (exactly as in fbufs), say, Page 9, that the Web application is authorized to read. It is up to the Web application to finish processing written pages and periodically to queue new free buffer descriptors to the adaptor.
This sounds fine, but there is a serious security flaw. Suppose the Web application, through malice or error, writes the sequence 155, 120 to its descriptor page (which it can do). Suppose further that Page 155 is in main memory and is where the kernel stores its data structures. When the adaptor gets the next packet for the Web application it will write it to Page 155, overwriting the kernel data structures. This causes a serious problem, at least causing the machine to crash.
Why, you may ask, can’t virtual memory hardware detect this problem? The reason is that virtual memory hardware (observe the position of the TLB in Figure 6.8) only protects against unauthorized access by processes running on the CPU. This is because the TLB intercepts every READ (or WRITE) access done by the CPU and can do checks. However, devices like adaptors that do DMA bypass the virtual memory system and access memory directly.
This is not a problem in practice because applications cannot program the devices (such as disks, adaptors) to read or write to specific places at the application’s command. Instead, access is always mediated by the kernel. If we are getting rid of the kernel, then we have to ensure that everything the application can instruct the adaptor to do is carefully scrutinized.
The solution used in the application device channel (ADC) [DDP94] solution promoted by Druschel, Davy, and Peterson is to have the kernel pass (P9, pass hints in interfaces) the adaptor a list of valid physical pages that each application using the adaptor can access directly. This can be done once when the application first starts and before data transfer begins. In other words, the time-consuming computation involved in authorizing pages is shifted in time (P2) from the data transfer phase to application initialization. For example, when the Web application first starts, it can ask the kernel for two physical pages, say, 18 and 12, and then ask the kernel to authorize the use of these pages to the adaptor.
The kernel is then bypassed for normal data operation. However, if now the Web application queues the descriptor 155 and a new packet arrives, the adaptor will first check the number 155 against its authorized list for the application (i.e., 18, 12). Since 155 is not in the list, the adaptor will not overwrite the kernel data structures (phew!).
In summary, ADCs are based on shifting protection functions in space (P3c) from the kernel to the adaptor, using some precomputed information (list of allowed physical pages, P2a) passed from the kernel to the adaptor (P9), and augmented with the normal virtual memory hardware (P4c).
The architecture community has, in recent years, been promoting the use of active messages[vECea92], for similar reasons. An active message is a message that carries the address of the user-level process that will handle the packet.9
An active message (such as the ADC approach) avoids kernel intervention and temporary buffering by using preallocated buffers or by using small messages that are responded to directly by the application, thus providing low latency. Low latency, in turn, allows computation and communication to overlap in parallel machines. The active messages implementation [vECea92] allowed only small messages or (large) block transfer. The fast messages implementation [PKC97] goes further to combine user-level scatter–gather interfaces and flow control to enable uniform high performance for a continuum from short to long messages.
WHAT ARE KERNELS GOOD FOR?
It is important to consider this question because the ADC and active message approaches bypass the kernel. Kernels are good for protection (protecting the system and good users from malice or errors) and for scheduling resources among different applications. Thus if we remove the kernel from the run-time data path, it is up to the solution to provide these services in lieu of the kernel. For example, ADCs do protection using the virtual memory hardware (to protect descriptors) and adaptor enforcement (to protect buffer memory).
It also must multiplex the physical communication link (especially on the sending side) among the different application device channels and provide some sort of fairness. To do this in every device would require replicating traditional kernel code in every device; however, it can be argued that some devices, such as the disk and the network adaptor, are special in terms of their performance needs and are worth giving special treatment. There is a movement afoot to make some of these ideas commercial based on the ADC idea and the UUNet solution (similar to ADCs and proposed concurrently) advocated at Cornell [vEBea95], We now briefly describe this proposal, known as virtual interface architecture (VIA).
6.5.1 The Virtual Interface Architecture (VIA) Proposal
Virtual interface architecture (VIA [CIC97]) is a commercial standard that advocates the ideas in ADCs. The term virtual interface makes sense because one can think of an application device channel as providing each application with its own virtual interface that it can manipulate without kernel intervention. The virtual interfaces are, of course, multiplexed on a single physical interface. VIA was proposed by an industry consortium that includes Microsoft, Compaq, and Intel.
VIA uses the following terminology that can easily be understood based on the earlier discussion.
• Registered Memory: These are regions of memory that the application uses to send and receive data. These regions are authorized for the application to read and write from; they are also pinned down to avoid paging.
• Descriptor: To send or receive a packet, the application uses a user-level library (libvia) to construct a descriptor that is just a data structure with information about the buffer, such as a pointer. VIA allows a descriptor to refer to multiple buffers in registered memory (for scatter-gather) and allows different memory protection tags. Descriptors can be added to a descriptor queue.
• Doorbells: These represent an unspecified method to communicate descriptors to the network interface. This can be done via writing part of the interface card’s memory or by triggering an interrupt on the card; it varies from implementation to implementation. Doorbells are pointers to descriptors, thus leading to a second level of indirection.
The VIA standard has a few problems that are partly addressed in Dittia et al. [DPJ97] and Buonadonna et al. [BGC02]. These problems (with some sample solutions) are:
• Small message performance: To actually send data requires following a doorbell to a descriptor (quite large, around 45 bytes [BGC02]) to the data. For small messages, this can be high overhead. (One way to fix this problem suggested in Buonadonna et al. [BGC02] is to combine the descriptor and the data for small messages.)
• Doorbell memory: Just as registered memory is protected, so must doorbells be protected (as in the ADC proposal). Thus the VIA specification requires that each doorbell be mapped to a separate user page, which is a waste of the virtual address space for small descriptors. (One way to avoid this is to combine multiple descriptors into a single page, as suggested in Dittia et al. [DPJ97], However, this requires some additional machinery.)
The VIA specifications [CIC97] are somewhat vague. For more details the reader may wish to consult more complete system implementations (such as Refs. BGC02 and DPJ97).
6.6 REDUCING INTERRUPTS
We have worked our way down the hierarchy of control overheads from process scheduling to select call implementations to system calls. At the bottom of the list is interrupt overhead. While involving less overhead than process scheduling or system calls, interrupt overhead can be substantial. Each time a packet arrives, fielding the corresponding interrupt from the device disrupts processor pipelines and requires some context switching to service the interrupt. There is no way to avoid interrupts completely. However, one can reduce interrupt overhead using the following tricks.
• Interrupt only for significant events: For example, in the ADC solution, the adaptor does not need to interrupt the processor on every packet reception but only for the first packet received in a stream of packets (we can assume the application will check for more packets received) and when the queue of free buffer descriptors becomes empty. This can reduce interrupt overhead to 1 in N packets received, if N packets are received in a burst. This is just an application of batching, or expense sharing (P2c).
• Polling: The idea here is that the processor (CPU) keeps checking to see if packets have arrived and the adaptor never interrupts. This can be more overhead than interrupt-driven processing if the number of packets received is low, but it can become more efficient for high throughput data streams. Another variation is clocked interrupts [ST]: The CPU periodically polls when a timer fires.
• Application controlled: An even more radical idea, once proposed by Dave Clark, is that the sender be able to control when the receiver interrupts by passing a bit in the packet header. For example, a sending FTP could set the interrupt bit only for the last data packet in a file transfer. This is another example of P10, passing hints in protocol headers. It is probably too radical for use. However, a more recent paper [DPJ97] proposes implementing a refinement of this idea in an ATM chip that was indeed fabricated.
In general, the use of batching works quite well in practice. However, in some implementations, such as the first bridge implementation (described in Chapter 10), the use of polling is also very effective. Thus more radical ideas, such as clocked or application-controlled interrupts, have become less useful. Note that the RDMA ideas described in Chapter 5 also have the great potential advantage of removing the need for both per-packet system calls and per-packet interrupts for a large data transfer.
6.6.1 Avoiding Receiver Livelock
Besides inefficiencies due to the cost of handling interrupts, interrupts can interact with operating system scheduling to drive end-system throughput to zero, a phenomenon known as receiver livelock. Recall that in Example 8 of Chapter 2 we showed that in BSD UNIX the arrival of a packet generates an interrupt. The processor then jumps to the interrupt handler code, bypassing the scheduler, for speed. The interrupt handler copies the packet to a kernel queue of IP packets waiting to be consumed, makes a request for an operating system thread (called a software interrupt), and exits.
Recall also that under high network load, the computer can enter what is called receiver livelock[MR97], in which the computer spends all its time processing incoming packets, only to discard them later because the applications never run. If there is a series of back-to-back packet arrivals, only the highest-priority interrupt handler will run, possibly leaving no time for the software interrupt and certainly none for the browser process. Thus either the IP or socket queues will fill up, causing packets to be dropped after resources have been invested in their processing.
One basic technique that seems necessary [MR97] is to turn off interrupts when too little application processing is occurring. This can be done by keeping track of how much time is spent in interrupt routines for a device and masking off that device if the fraction spent exceeds a specified percentage of total time. However, merely doing so can drop all packets that arrive during overload, including well-behaved and important packet flows.
A very nice solution to this problem is described by Druschel and Banga [DB96],10 who suggest combating this problem via two mechanisms. First, they suggest using a separate queue per destination socket instead of a single shared queue. When a packet arrives, early demultiplexing (Chapter 8) is used to place the packet in the appropriate per-socket queue. Thus if a single socket’s queues fill up because its application is not reading packets, other sockets can still make progress.
The second mechanism is to implement the protocol processing at the priority of the receiving process and as part of the context of the received process (and not a separate software interrupt). First, this removes the unfair practice of charging protocol processing for application X to the application, Y, that was running when the packet for X arrives. Second, it means that if an application is running slowly, its per-socket queue fills up and its particular packets will be dropped, allowing others to progress. Third, and most importantly, since protocol processing is done at a lower priority (application processing), it greatly alleviates the livelock problem caused by the partial processing (i.e., protocol processing only) of many packets without the corresponding application processing required to remove these packets from the socket queue.
This mechanism, called lazy receiver processing (LRP), essentially uses lazy evaluation (P2b), not so much for efficiency but for fairness and to avoid livelock. Solutions that require less drastic changes are described in Mogul and Ramakrishnan [MR97].
6.7 CONCLUSIONS
After the basic restructuring to avoid copying, control overhead is probably the next most important overhead to attack in a networking application. From reducing the overhead of process scheduling to limiting system calls to reducing interrupt overhead, fast server implementations must reduce unnecessary overheads due to these causes. Newer operating systems, such as Linux, are making giant strides in reducing the inherent control overhead costs. However, modern architectures are getting faster in the processing of instructions using cached data without a commensurate speedup in context switching and interrupt processing.
This chapter started by surveying basic techniques for reducing process-scheduling overhead for networking code. These lessons have been taken to heart by the networking community. Hardly any implementor worth his or her salt will do something egregious, such as structuring each layer as a separate process, and not resort freely to upcalls. However, the deeper lesson of Figure 6.3 is not the seemingly arcane structure, but the implicit idea of user-level networking. User-level networking was not developed at the time Clark presented his paper, and it is still not very well known. Note that user-level networking, together with application device channels, makes possible technologies such as VIA, which may become part of real systems in order to avoid system calls when sending and receiving packets.
On the other hand, the art of structuring processing in the application context — for example, a Web server — has received attention only more recently. While event-driven servers (augmented with helper processes) satisfactorily balance the need to maximize concurrency and minimize context-switching overhead, the software engineering aspects of such designs still leave many questions unanswered. Will the event-driven approach suffice in a production environment with rapid changes and facilitate debugging? The staged event-driven approach is a step in this direction, but the engineering of large Web servers will surely require more work.
The event-driven approach also relies on the fast implementation of equivalents of the select() call. While the UNIX approaches have fundamental scalability problems, it is reassuring that other popular operating systems, such as Windows [BMD99], have much more efficient APIs.
Allowing applications to communicate directly with network devices using a protected virtual interface is an idea that seems to be gaining ground through the VIA standard. Ideally, adaptors are designed to enable VIA or similar mechanisms. Finally, while interrupts are fundamentally unavoidable, their nuisance value can be greatly mitigated by the use of batching and the use of polling in appropriate environments.
Figure 6.1 shows a list of the techniques used in this chapter, with the corresponding principles. In summary, while Epicetus urged his readers to control their passions, we feel it is equally important for implementors of networking code to be passionate about control.
6.8 EXERCISES
1. Packet Filters and Upcalls: In the description on upcalls (Figure 6.3), we showed that the system figured out which application the packet was for by upcalling a transport routine. But if you can do that, who needs packet filters anyway? What hidden assumption is being made here?
2. Comparing Web Server Structuring Models: In the text we compared various server structuring mechanisms with respect to simple metrics such as scheduling efficiency and CPU concurrency. Consider the following other metrics for comparison.
• Disk Concurrency: Some systems employ multiple disks and do disk scheduling. Why might the event-driven approach have problems in such an environment, compared to a multithreaded approach? Does the event-driven approach with helper processes have the same problems?
• Gathering Statistics: Web servers need to keep statistics on usage patterns for accounting. Why might gathering statistics be more complex in process-per-client and thread-per-client architectures? Why is it simpler in an event-driven architecture?
3. Algorithms versus Algorithmics in ufalloc() Reimplementation: In this exercise we will consider how to efficiently reimplement ufalloc() to find the lowest unallocated descriptor.
• First consider using a binary heap. For N identifiers, how many memory accesses are required? How much space is required, in bits?
• Assume that the machine has a W-bit (e.g., for the Alpha, W = 64) word and that there is an efficient instruction (or set of instructions) to find the rightmost zero in a W-bit word. Suppose the allocated descriptors are represented as set bits in a large bitmap (P14) of size N. Show how to augment this bitmap with some extra state (P12) to efficiently compute the lowest unallocated descriptor.
• What are the space and time costs of this scheme compared to a simple heap? Can a simple heap be made faster by the (standard) trick of increasing the radix of the heap to have K > 1 elements in every heap node?
4. Modified Implementation of Fast select(): The text explains how elements are added to the sets I, H, and R but does not specify completely how they are removed. Explain how elements are removed, especially with respect to the hints set H.
5. Modified Implementation of Fast select(): In the fast select implementation of Banga and Mogul [BM98], consider changing the implementation as follows:
(a) First, Inew is set equal to S (and not to Iold ∪ S as before).
(b) Rnew is computed as before.
(c) What is returned to the user is Rnew (and not Rnew ∩ S) as before.
Answer the following questions.
• Explain in words what is different from this implementation and the one proposed by Banga and Mogul.
• Explain why this implementation may require one to be careful about how it removes elements from the hints set H in order not to miss state changes due to newly arriving packets.
• Explain how this scheme can be inferior to the existing implementation, assuming no application changes. Find a worst-case scenario.
• Explain why this implementation can sometimes be better than the existing implementation if the application is smart enough not to choose a socket in its selecting set as long as it still has unread data. (In other words, if a socket has unconsumed data, the application is smart enough not to select it until all data has been consumed.)
6. Comparing the APIC Approach to the ADC Approach: In the text we described the ADC approach to application-level networking, thereby bypassing the kernel and avoiding system calls. We want to compare this approach to an approach used in the APIC chip. First use a search engine to locate and print out a paper called “The APIC Approach to High-Performance Network Interface Design: Protected DMA and Other Techniques” [DPJ97]. Read the paper carefully, and then answer the following questions about its particular twists to the ADC design for a practical system.
• There are two types of memory the ADC approach protects: the device registers on the adaptor, and the buffer memory containing the data. The first is protected by overloading the virtual memory scheme; the second is protected by having the kernel hand the adaptor a list of pages that an application can read/write from. Contrast this to the APIC approach to protecting the device registers. Why is an access mask helpful? Why is each connection register mapped both into the application and kernel memory?
• In the APIC, the buffer memory is protected by having the APIC read (from memory) a kernel descriptor that contains validation information about the buffer. In the ADC approach, the validating information is already in the adaptor. Why add this extra complexity?
• In the APIC, there is a third kind of memory that needs to be protected: Buffer descriptors contain links to other other descriptors, and this link memory needs to be validated. Why is this not needed in the ADC approach?
• A different way to do link notarization is to have the kernel create an array of pointers to real buffers, one for each application. Only the kernel can read or write this array. The applications queue buffer descriptors as offsets into this array. This is a standard approach in systems called using one level of indirection. Compare this approach to the APIC link notarization approach.
• A disadvantage of the APIC approach is that the adaptor has to do a number of READs to main memory to do all its checks. How many such READs are required in the worst case for a received packet? Why might this be insignificant?
• The paper describes splitting a packet into two pieces. Why is this needed? What assumption does this method make about protocols (that an approach based on packet filters does not need)?