
Conclusions
We began the book by setting up the rules of the network algorithmics game. The second part of the book dealt with server implementations and the third part with router implementations. The fourth and last part of the book dealt with current and future issues in measurement and security.
The book covers a large number of specific techniques and a variety of settings — there are techniques for fast server design versus techniques for fast routers, techniques specific to operating systems versus techniques specific to hardware. While all these topics are part of the spectrum of network algorithmics, there is a risk that the material can appear to degenerate into a patchwork of assorted topics that are not linked together in any coherent way.
Thus as we draw to a close, it is appropriate to try and reach closure by answering the following questions in the next four sections.
• What has the book been about? What were the main problems, and how did they arise? What are the main techniques? While endnode and router techniques appear to be different when considered superficially, are there some underlying characteristics that unite these two topics? Can these unities be exploited to suggest some cross-fertilization between these areas? (Section 18.1)
• What is network algorithmics about? What is the underlying philosophy behind network algorithmics, and how does it differ from algorithms by themselves? (Section 18.2)
• Is network algorithmics used in real systems? Are the techniques in this book exercises in speculation, or are there real systems that use some of these techniques? (Section 18.3)
• What is the future of network algorithmics? Are all the interesting problems already solved? Are the techniques studied in this book useful only to understand existing work or to guide new implementations of existing tasks? Or are there always likely to be new problems that will require fresh applications of the principles and techniques described in this book? (Section 18.4)
18.1 WHAT THIS BOOK HAS BEEN ABOUT
The main problem considered in this book is bridging the performance gap between good network abstractions and fast network hardware. Abstractions — such as modular server code and prefix-based forwarding — make networks more usable, but they also exact a performance penalty when compared to the capacity of raw transmission links, such as optical fiber. The central question tackled in this book is whether we can have our cake and eat it too: retain the usability of the abstractions and yet achieve wire speed performance for the fastest-transmission links.
To make this general assertion more concrete, we review the main contents of this book in two sub-sections: Section 18.1.1 on endnode algorithmics and Section 18.1.2 on router algorithmics. This initial summary is similar to that found in Chapter 1. However, we go beyond the description in Chapter 1 in Section 18.1.3, where we present the common themes in endnode and router algorithmics and suggest how these unities can potentially be exploited.
18.1.1 Endnode Algorithmics
Chapters 5–9 of this book concentrate on endnode algorithmics, especially for servers. Many of the problems tackled under endnode algorithmics involve getting around complexities due to software and structure — in other words, complexities of our own making as opposed to necessarily fundamental complexities. These complexities arise because of the following characteristics of endnodes.
• Computation versus Communication: Endnodes are about general-purpose computing and must handle possible unknown and varied computational demands, from database queries to weather prediction. By contrast, routers are devoted to communication.
• Vertical versus Horizontal Integration: Endnodes are typically horizontally integrated, with one institution building boards, another writing kernel software, and another writing applications. In particular, kernels have to be designed to tolerate unknown and potentially buggy applications to run on top of them. Today, routers are typically vertically integrated, where the hardware and all software is assembled by a single company.
• Complexity of Computation: Endnode protocol functions are more complex (application, transport) as compared to the corresponding functions in routers (routing, data link).
As a consequence, endnode software has three important artifacts that seem hard to avoid, each of which contributes to inefficiencies that must be worked around or minimized.
1. Structure: Because of the complexity and vastness of endnode software, code is structured and modular to ease software development. In particular, unknown applications are allowed using a standard application programming interface (API) between the core operating system and the unknown application.
2. Protection: Because of the need to accommodate unknown applications, there is a need to protect applications from each other and to protect the operating system from applications.
3. Generality: Core routines such as buffer allocators and the scheduler are written with the most general use (and the widest variety of applications) in mind and thus are unlikely to be as efficient as special-purpose routines.
In addition, since most endnodes were initially designed in an environment where the endnode communicated with only a few nodes at a time, there is little surprise that when these nodes were retrofitted as servers, a fourth artifact was discovered.
4. Scalability: By scalability, we often mean in terms of the number of concurrent connections. A number of operating systems use simple data structures that work well for a few concurrent connections but become major bottlenecks in a server environment, where there is a large number of connections.
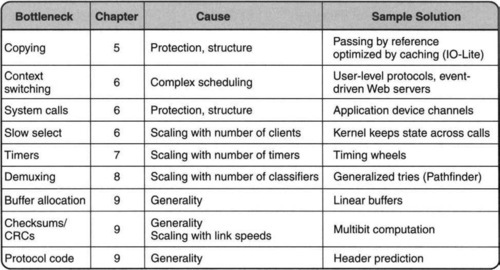
With this list of four endnode artifacts in mind, Figure 18.1 reviews the main endnode bottlenecks covered in this book, together with causes and workarounds. This picture is a more detailed version of the corresponding figure in Chapter 1.
18.1.2 Router Algorithmics
In router algorithmics, by contrast, the bottlenecks are caused not by structuring artifacts (as in some problems in endnode algorithmics) but by the scaling problems caused by the need for global Internets, together with the fast technological scaling of optical link speeds. Thus the global Internet puts pressure on router algorithmics because of both population scaling and speed scaling.
For example, simple caches worked fine for route lookups until address diversity and the need for CIDR (both caused by population scaling) forced the use of fast longest-matching prefix. Also, simple DRAM-based schemes sufficed for prefix lookup (e.g., using expanded tries) until increasing link speeds forced the use of limited SRAM and compressed tries. Unlike endnodes, routers do not have protection issues, because they largely execute one code base. The only variability comes from different packet headers. Hence protection is less of an issue.
With the two main drivers of router algorithmics in mind, Figure 18.2 reviews the main router bottlenecks covered in this book together with causes and workarounds. This picture is a more detailed version of the corresponding figure in Chapter 1.

While we have talked about routers as the canonical switching device, many of the techniques discussed in this book apply equally well to any switching device, such as a bridge (Chapter 10 is devoted to lookups in bridges) or a gateway. It also applies to intrusion detection systems, firewalls, and network monitors who do not switch packets but must still work efficiently with packet streams at high speeds.
18.1.3 Toward a Synthesis
In his book The Character of Physical Law, Richard Feynman argues that we have a need to understand the world in “various hierarchies, or levels.” Later, he goes on to say that “all the sciences, and not just the sciences but all the efforts of intellectual kinds, are an endeavor to see the connections of the hierarchies … and in that way we are gradually understanding this tremendous world of interconnecting hierarchies.”
We have divided network algorithmics into two hierarchies: endnode algorithmics and router algorithmics. What are the connections between these two hierarchies? Clearly, we have used the same set of 15 principles to understand and derive techniques in both areas. But are there other unities that can provide insight and suggest new directions?
There are differences between endnode and router algorithmics. Endnodes have large, structured, and general-purpose operating systems that require work arounds to obtain high performance; routers, by contrast, have fairly primitive operating systems (e.g., Cisco IOS) that bear some resemblance to a real-time operating system. Most endnodes’ protocol functions are implemented (today) in software, while the critical performance functions in a router are implemented in hardware. Endnodes compute, routers communicate. Thus routers have no file system and no complex process scheduling.
But there are similarities as well between endnode and router algorithmics.
• Copying in endnodes is analogous to the data movement orchestrated by switching in routers.
• Demultiplexing in endnodes is analogous to classification in routers.
• Scheduling in endnodes is analogous to fair queuing in routers.
Other than packet classification, where the analogy is more exact, it may seem that the other correspondences are a little stretched. However, these analogies suggest the following potentially fruitful directions.
1. Switch-based endnode architectures: The analogy between copying and switching, and the clean separation between I/O and computation in a router, suggests that this may also be a good idea for endnodes. More precisely, most routers have a crossbar switch that allows parallel data transfers using dedicated ASICs or processors; packets meant for internal computation are routed to a separate set of processors. While we considered this briefly in Chapter 2, we did not consider very deeply the implications for endnode operating systems.
By dedicating memory bandwidth and processing to I/O streams, the main computational processors can compute without interruptions, system calls, or kernel thread, because I/O is essentially serviced and placed in clean form by a set of I/O processors (using separate memory bandwidth that does not interfere with the main processors) for use by the computational processors when they switch computational tasks. With switch-based bus replacements such as Infiniband, and the increasing use of protocol offload engines such as TCP chips, this vision may be realizable in the near future. However, while the hardware elements are present, there is need for a fundamental restructuring of operating systems to make this possible.
2. Generalized endnode packet classification: Although there seems to be a direct correspondence between packet classification in endnodes (Chapter 8) and packet classification in routers (Chapter 12), the endnode problem is simpler because it works only for a constrained set of classifiers, where all the wildcards are at the end. Router classifiers, on the other hand, allow arbitrary classifiers, requiring more complicated algorithmic machinery or CAMs.
It seems clear that if early demultiplexing is a good idea, then there are several possible definitions of a path (flow in router terminology), other than a TCP connection. For example, one might want to devote resources to all traffic coming from certain subnets or to certain protocol types. Such flexibility is not allowed by current classifiers, such as BPF and DPF (Chapter 8). It may be interesting to study the extra benefits provided by more general classifiers in return for the added computational burden.
3. Fair queuing in endnodes: Fair queuing in routers was originally invented to provide more discriminating treatment to flows in times of overload and (later) to provide quality of service to flows in terms of, say, latency. Both these issues resonate in the endnode environment. For example, the problem of receiver livelock (Chapter 6) requires discriminating between flows during times of overload. The use of early demultiplexing and separate IP queues per flow in lazy receiver processing seems like a first crude step toward fair queuing. Similarly, many endnodes do real-time processing, such as running MPEG players, just as routers have to deal with the real-time constraints of, say, voice-over-IP packets.
Thus, a reasonable question is whether the work on fair schedulers in the networking community can be useful in an operating system environment. When a sending TCP is scheduling between multiple concurrent connections, could it use a scheduling algorithm such as DRR for better fairness? At a higher level, could a Web server use worst-case weighted fair queuing to provide better delay bounds for certain clients? Some work following this agenda has begun to appear in the operating system community, but it is unclear whether the question has been fully explored.
So far, we have suggested that endnodes could learn from router design in overall I/O architecture and operating system design. Routers can potentially learn the following from endnodes.
1. Fundamental Algorithms: Fundamental algorithms for endnodes, such as selection, buffer allocation, CRCs, and timers, are likely to be useful for routers, because the router processor is still an endnode, with very similar issues.
2. More Structured Router Operating Systems: While the internals of router operating systems, such as Cisco’s IOS and Juniper’s JunOS, are hidden from public scrutiny, there is at least anecdotal evidence that there are major software engineering challenges associated with such systems as time progresses (leading to the need to be compatible with multiple past versions) and as customers ask for special builds. Perhaps routers can benefit from some of the design ideas behind existing operating systems that have stood the test of time.
While protection may be fundamentally unnecessary (no third-party applications running on a router), how should a router operating system be structured for modularity? One approach to building a modular but efficient router operating system can be found in the router plugins system [DDPP98] and the Click operating system [KMea00].
3. Vertically Integrated Routers: The components of an endnode (applications, operating system, boxes, chips) are often built by separate companies, thus encouraging innovation. The interface between these components is standardized (e.g., the API between applications and operating system), allowing multiple companies to supply new solutions. Why should a similar vision not hold for routers some years from now when the industry matures? Currently, this is more of a business than a technical issue because existing vendors do not want to open up the market to competitors. However, this was true in the past for computers and is no longer true; thus there is hope.
We are already seeing router chips being manufactured by semiconductor companies. However, a great aid to progress would be a standardized router operating system that is serious and general enough for production use by several, if not all, router companies.1 Such a router operating system would have to work across a range of router architectures, just as operating systems span a variety of multiprocessor and disk architectures.
Once this is the case, perhaps there is even a possibility of “applications” that run on routers. This is not as far-fetched as it sounds, because there could be a variety of security and measurement programs that operate on a subset of the packets received by the router. With the appropriate API (and especially if the programs are operating on a logged copy of the router packet stream), such applications could even be farmed out to third-party application developers. It is probably easy to build an environment where a third-party application (working on logged packets) cannot harm the main router functions, such as forwarding and routing.
18.2 WHAT NETWORK ALGORITHMICS IS ABOUT
Chapter 1 introduced network algorithmics with the following definition.
Definition: Network algorithmics is the use of an interdisciplinary systems approach, seasoned with algorithmic thinking, to design fast implementations of network processing tasks.
The definition stresses the fact that network algorithmics is interdisciplinary, requires systems thinking, and can sometimes benefit from algorithmic thinking. We review each of these three aspects (interdisciplinary thinking, systems thinking, algorithmic thinking) in turn.
18.2.1 Interdisciplinary Thinking
Network algorithmics represents the intersection of several disciplines within computer science that are often taught separately. Endnode algorithmics is a combination of networking, operating systems, computer architecture, and algorithms. Router algorithmics is a combination of networking, hardware design, and algorithms. Figure 18.3 provides examples of uses of these disciplines that are studied in the book.

For example, in Figure 18.3 techniques such as header prediction (Chapter 9) require a deep networking knowledge of TCP to optimize the expected case, while internal link striping (Chapter 15) requires knowing how to correctly design a striping protocol. On the other hand, application device channels (Chapter 6) require a careful understanding of the protection issues in operating systems.
Similarly, locality-driven receiver processing requires understanding the architectural function and limitations of the instruction cache. Finally, in router algorithmics it is crucial to understand hardware design. Arbiters like iSLIP and PIM were designed to allow scheduling decisions in a minimum packet arrival time.
Later in this chapter we argue that other disciplines, such as statistics and learning theory, will also be useful for network algorithmics.
18.2.2 Systems Thinking
Systems thinking is embodied by Principles P1 though P10. Principles P1 through P5 were described earlier as systems principles. Systems unfold in space and time: in space, through various components (e.g., kernel, application), and in time, through certain key time points (e.g., application initialization time, packet arrival time). Principles P1 through P5 ask that a designer expand his or her vision to see the entire system and then to consider moving functions in space and time to gain efficiency.
For example, Principle P1, avoiding obvious waste, is a cliché by itself. However, our understanding of systems, in terms of separable and modular hierarchies, often precludes the synoptic eye required to see waste across system hierarchies. For example, the number of wasted copies is apparent only when one broadens one’s view to that of a Web server (see I/O-Lite in Chapter 5). Similarly, the opportunities for dynamic code generation in going from Pathfinder to DPF (see Chapter 8) are apparent only when one considers the code required to implement a generic classifier.
Similarly, Principle P4 asks the designer to be aware of existing system components that can be leveraged. Fbufs (Chapter 5) leverage off the virtual memory subsystem, while timing wheels (Chapter 7) leverage off the existing time-of-day computation to amortize the overhead of stepping through empty buckets. Principle P4 also asks the designer to be especially aware of the underlying hardware, whether to exploit local access costs (e.g., DRAM pages, cache lines), to trade memory for speed (either by compression, if the underlying memory is SRAM, or by expansion, if memory is DRAM), or to exploit other hardware features (e.g., replacing multiplies by shifts in RED calculations in Chapter 14).
Principle P5 asks the designer to be even bolder and to consider adding new hardware to the system; this is especially useful in a router context. While this is somewhat vague, Principles 5a (parallelism via memory interleaving), P5b (parallelism via wide words), and P5c (combining DRAM and SRAM to improve overall speed and cost) appear to underlie many clever hardware designs to implement router functions. Thus memory interleaving and pipelining can be used to speed up IP lookups (Chapter 11), wide words are used to improve the speed of the Lucent classification scheme (Chapter 12), and DRAM and SRAM can be combined to construct an efficient counter scheme (Chapter 16).
Once the designer sees the system and identifies wasted sequences of operations together with possible components to leverage, the next step is to consider moving functions in time (P2) and space (P3c). Figure 18.4 shows examples of endnode algorithmic techniques that move functions between components. Figure 18.5 shows similar examples for router algorithmics.

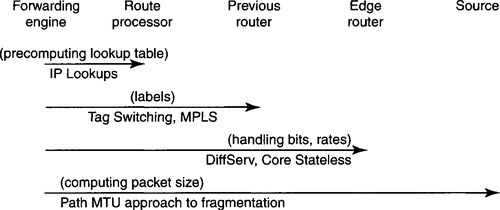
Besides moving functions in space, moving functions in time is a key enabler for efficient algorithms. Besides the more conventional approaches of precomputation (P2a), lazy evaluation (P2b), and batch processing (P2c), there are subtler examples of moving functions to different times at which the system is instantiated. For example, in fbufs (Chapter 5), common VM mappings between the application and kernel are calculated when the application first starts up. Application device channels (Chapter 6) have the kernel authorize buffers (on behalf of an application) to the adaptor when the application starts up. Dynamic packet filter (DPF) (Chapter 8) specializes code when a classifier is updated. Tag switching (Chapter 11) moves the work of computing labels from packet-forwarding time to route-computation time.
Finally, Principles P6 through P10 concern the use of alternative system structuring techniques to remove inefficiences. P6 suggests considering specialized routines or alternative interfaces; for example, Chapter 6 suggests that event-driven APIs may be more efficient than the state-based interface of the select() call. P7 suggests designing interfaces to avoid unnecessary generality; for example, in Chapter 5, fbufs map the fbuf pages into the same locations in all processes, avoiding the need for a further mapping when moving between processes. P8 suggests avoiding being unduly influenced by reference implementations; for example, in Chapter 9, naive reference implementations of checksums have poor performance.
Principles P9 and P10 suggest keeping existing interfaces but adding extra information to interfaces (P9) or packet headers (P10). For example, efficiently reimplementing the select() call (Chapter 6) requires passing information between the protocol module and the select module. Passing information in packet headers, on the other hand, has a huge array of examples, including RDMA (Chapter 5), MPLS (Chapter 11), DiffServ, and core stateless fair queuing (Chapter 14).
18.2.3 Algorithmic Thinking
Algorithmic thinking refers to thinking about networking bottlenecks the way algorithm designers approach problems. Overall, algorithmic approaches are less important than other systems approaches, as embodied by Principles P1 through P10. Also, it is dangerous to blindly reuse existing algorithms.
The first problem that must be confronted in using algorithmic thinking is how to frame the problem that must be solved. By changing the problem, one can often find more effective solutions. Consider the following problem, which we avoided in Chapter 11.
Example: Pipelining and Memory Allocation. A lookup engine is using a trie. The lookup engine must be pipelined for speed. The simplest solution is to pipeline the trie by level. The root is at the first stage, the children of the root are assigned to the second stage, the nodes at height 2 to the third stage, etc. Unfortunately, the memory needs for each stage can vary as prefixes are inserted and deleted. There are the following spectrum of approaches.
• Centralized memory: All the processing stages share a single memory. Memory allocation is easy, but the centralized memory becomes a bottleneck.
• One memory per stage: Each processing stage has its own memory, minimizing memory contention. However, since the memory is statically allocated at fabrication time, any memory unused by a stage cannot be used by another stage.
• Dynamically allocate small 1-port memories to stages: As suggested in Chapter 11, on-chip memory is divided into M SRAMs, which are connected to stage processors via a crossbar. As a processor requires more or less memory, crossbar connections can be changed to allocate more or fewer memories to each stage. This scheme requires large M to avoid wasting memory, but large M can lead to high capacitive loads.
• Dynamically allocate medium-size 2-port memories to stages: The setting is identical to the last approach, except that each memory is now a 2-port memory that can be allocated to two processors. Using this it is is possible to show that N memories are sufficient for N processors, with almost no memory wastage.
• Dynamically change the starting point in the pipeline: In a conventional linear pipeline, all lookups start at the first stage and leave at the last. Florin Baboescu has suggested an alternative: Using a lookup table indexed on the first few bits, assign each address to a different first processor in the pipeline. Thus different addresses have different start and end processors. However, this gives considerably more flexibility in allocating memory to processors by changing the assignment of addresses to processors.
• Pipeline by depth: Instead of pipelining a tree by height, consider pipelining by depth. All leaves are assigned to the last stage, K, all parents of the leaves to stage K – 1, etc.
These approaches represent the interplay between principles P13 (optimizing degrees of freedom) and P5 (add hardware). However, each approach results in a different algorithmic problem! Thus a far more important skill than solving a hard problem is the skill required to frame the right problems that balance overall system needs.
Principles P11 and P13 help choose the right problem to solve. The pipelining example shows that choosing the degrees of freedom (P13) can change the algorithmic problem solved.
Similarly, Principle P11, optimizing the expected case, can sometimes help decide what the right measure is to optimize. This in turn influences the choice of algorithm. For example, simple TCP header prediction (Chapter 9) optimizes the expected case when the next packet is from the same connection and is the next data packet or ack. If this is indeed the expected case, there is no need for fancy connection lookup structures (a simple one-element cache) or fancy structures to deal with sequence number bookkeeping. However, if there are several concurrent connections, as in a server, a hash table may be better for connection lookup. Similarly, if packets routinely arrive out of order, then more fancy sequence number bookkeeping schemes [TVHS92] may be needed.
Principle P12, adding state for speed, is a simple technique used often in standard algorithmic design. However, it is quite common for just this principle by itself (without fancy additional algorithmic machinery) to help remove systems bottlenecks. For example, the major bottleneck in the select() call implementation is the need to repeatedly check for data in network connections known not to be ready. By simply keeping state across calls, this key bottleneck can be removed. By contrast, the bottlenecks caused by the bitmap interface can be removed by algorithmic means, but these are less important.
Having framed the appropriate problem using P11, P12, and P13, principles P14 and P15 can be used to guide the search for solutions.
Principle P14 asks whether there are any important special cases, such as the use of finite universes, that can be leveraged to derive a more efficient algorithm. For example, the McKenney buffer-stealing algorithm of Chapter 9 provides a fast heap with O(1) operations for the special case when elements to the heap change by at most 1 on each call.
Finally, principle P15 asks whether there are algorithmic methods that can be adapted to the system. It is dangerous to blindly adapt existing algorithms because of the following possibilities that can mislead the designer.
• Wrong Measures: The measure for most systems implementations is the number of memory accesses and not the number of operations. For example, the fast ufalloc() operation uses a selection tree on bitmaps instead of a standard heap, leveraging off the fact that a single read can access W bits, where W is the size of a word. Again, the important measure in many IP lookup algorithms is search speed and not update speed.
• Asymptotic Complexity: Asymptotic complexity hides constants that are crucial in systems. When every microsecond counts, surely constant factors are important. Thus the switch matching algorithms in Chapter 13 have much smaller constants than the best bipartite matching algorithms in the literature and hence can be implemented.
• Incorrect Cost Penalties: In timing wheels (Chapter 7), a priority heap is implemented using a bucket-sorting data structure. However, the cost of strolling through empty buckets, a severe cost in bucket sort, is unimportant because on every timer tick, the system clock must be incremented anyway. As a second example, the dynamic programming algorithm to compute optimal lookup strides for multibit tries (Chapter 11) is O(N * W2), where N is the number of prefixes and W is the address width. While this appears to be quadratic, it is linear in the important term N (100,000 or more) and quadratic in the address width (32 bits, and the term is smaller in practice).
In spite of all these warnings, algorithmic methods are useful in networking, ranging from the use of Pathfinder-like tries in Chapter 8 to the use of tries and binary search (suitably modified) in Chapter 11.
18.3 NETWORK ALGORITHMICS AND REAL PRODUCTS
Many of the algorithms used in this book are found in real products. The following is a quick survey.
Endnode Algorithmics: Zero-copy implementations of network stacks are quite common, as are implementations of memory-mapped files; however, more drastic changes, such as I0-Lite, are only used more rarely, such as by the iMimic server software. The RDMA specification is well developed. Event-driven Web servers are quite common, and many operating systems other than UNIX (such as Windows NT) have fast implementations of select() equivalents. The VIA standard avoids system calls using ideas similar to ADCs.
Most commercial systems for early demultiplexing still rely on BPF, but that is because few systems require so many classifiers that they need the scalability of a Pathfinder or a DPF. Some operating systems use timing wheels, notably Linux and FreeBSD. Linux uses fast buffer-manipulation operations on linear buffers. Fast IP checksum algorithms are common, and so are multibit CRC algorithms in hardware.
Router Algorithmics: Binary search lookup algorithms for bridges were common in products, as were hashing schemes (e.g., Gigaswitch). Multibit trie algorithms for IP lookups are very common; recently, compressed versions, such as the tree bitmap algorithm, have become popular in Cisco’s latest CRS-1 router. Classification is still generally done by CAMs, and thus much of Chapter 12 is probably more useful for software classification.
In some chapters, such as the chapter on switching (Chapter 13), we provided a real product example for every switching scheme described (see Figure 13.2, for example). In fair queuing, DRR, RED, and token buckets are commonly implemented. General weighted fair queuing, virtual clock, and core stateless fair queuing are hardly ever used. Finally, much of the measurement and security chapters is devoted to ideas that are not part of any product today.
It is useful to see many of these ideas come together in a complete system. While it is hard to find details of such systems (because of commercial secrecy), the following two large systems pull together ideas in endnode and router algorithmics.
SYSTEM EXAMPLE 1: FLASH WEB SERVER
The Flash [PDZ99a] Web server was designed at Rice University and undoubtedly served as the inspiration (and initial code base) for a company called iMimic. A version of Flash called Flash-lite uses the following ideas from endnode algorithmics.
• Fast copies: Flash-lite uses IO-Lite to avoid redundant copies.
• Process scheduling: Flash uses an event-driven server with helper processes to minimize scheduling and maximize concurrency.
• Fast select: Flash uses an optimized implementation of the select() call.
• Other optimizations: Flash caches response headers and file mappings.
SYSTEM EXAMPLE 2: CISCO 12000 GSR ROUTER
The Cisco GSR [Sys] is a popular gigabit router and uses the following ideas from router algorithmics.
• Fast IP lookups: The GSR uses a multibit tree to do IP lookups.
• Fast switching: The GSR uses the iSLIP algorithm for fast bipartite matching of VOQs.
• Fair queuing: The GSR implements a modified form of DRR called MDRR, where one queue is given priority (e.g., for voice-over-IP). It also implements a sophisticated form of RED called weighted RED and token buckets. All these algorithms are implemented in hardware.
18.4 NETWORK ALGORITHMICS: BACK TO THE FUTURE
The preceding three sections of this chapter talked of the past and the present. But are all the ideas played out? Has network algorithmics already been milked to the point where nothing new is left to do? We believe this is not the case. This is because we believe network algorithmics will be enriched in the near future in three ways: new abstractions that require new solutions will become popular; new connecting disciplines will provide new approaches to existing problems; and new requirements will require rethinking existing solutions. We expand on each of these possibilities in turn.
18.4.1 New Abstractions
This book dealt with the fast implementation of the standard networking abstractions: TCP sockets at endnodes and IP routing at routers. However, new abstractions are constantly being invented to increase user productivity. While these abstractions make life easier for users, unoptimized implementations of these abstractions can exact a severe performance penalty. But this only creates new opportunities for network algorithmics. Here follow some examples of such abstractions.
• TCP offload engines: While the book has concentrated on software TCP implementations, movements such as iSCSI have made hardware TCP offload engines more interesting. Doing TCP in hardware and handling worst-case performance at 10 Gbps and even 40 Gbps is very challenging. For example, to do complete offload, the chip must even handle out-of-order packets and packet fragments (see Chapter 9) without appreciable slowdown.
• HTML and Web server processing: There have been a number of papers trying to improve Web server performance that can be considered an application of endnode algorithmics. For example, persistent HTTP [Mog95] can be considered an application of P1 to the problem of connection overhead. A more speculative approach to reduce DNS lookup times in Web accesses by passing hints (P10) is described in Chandranmenon and Varghese [CV01].
• Web services: The notion of Web services, by which a Web page is used to provide a service, is getting increasingly popular. There are a number of protocols that underly Web services, and standard implementations of these services can be slow.
• CORBA: The common object request broker architecture is popular but quite slow. Gokhale and Schmidt [GS98] apply to the problem four of the principles described in this book (eliminating waste, P1, optimizing the expected case, P11, passing information between layers, P9, and exploiting locality for good cache behavior, P4a). They show that such techniques from endnode algorithmics can improve the performance of the SunSoft Inter-Orb protocol by a factor of 2–4.5, depending on the data type. Similar optimizations should be possible in hardware.
• SSL and other encryption standards: Many Web servers use the secure socket layer (SSL) for secure transactions. Software implementations of SSL are quite slow. There is an increasing interest in hardware implementations of SSL.
• XML processing: XML is rapidly becoming the lingua franca of the Web. Parsing and converting from XML to HTML can be a bottleneck.
• Measurement and security abstractions: Currently, SNMP and NetFlow allow very primitive measurement abstractions. The abstraction level can be raised only by a tool that integrates all the raw measurement data. Perhaps in the future routers will have to implement more sophisticated abstractions to help in measurement and security analysis.
• Sensor networks: A sensor network may wish to calculate new abstractions to solve such specific problems as finding high concentrations of pollutants and ascertaining the direction of a forest fire.
If history is any guide, every time an existing bottleneck becomes well studied, a new abstraction appears with a new bottleneck. Thus after lookups became well understood, packet classification emerged. After classification, came TCP offload; and now SSL and XML are clearly important. Many pundits believe that wire speed security solutions (as implemented in a router or an intrusion detection system) will be required by the year 2006. Thus it seems clear that future abstractions will keep presenting new challenges to network algorithmics.
18.4.2 New Connecting Disciplines
Earlier we said that a key aspect of network algorithmics is its interdisciplinary nature. Solutions require a knowledge of operating systems, computer architecture, hardware design, networking, and algorithms. We believe the following disciplines will also impinge on network algorithmics very soon.
• Optics: Optics has been abstracted away as a link layer technology in this book. Currently, optics provides a way to add extra channels to existing fiber using dense wavelength- division multiplexing. However, optical research has made amazing strides. There are undoubtedly exciting possibilities to rethink router design using some combination of electronics and optics.2
• Network processor architecture: While this field is still in its infancy as compared to computer architecture, there are surely more imaginative approaches than current approaches that assign packets to one of several processors. One such approach, described in Sherwood et al. [SVC03], uses a wide word state machine as a fundamental building block.
• Learning theory: The fields of security and measurement are crying out for techniques to pick out interesting patterns from massive traffic data sets. Learning theory and data mining have been used for these purposes in other fields. Rather than simply reusing, say, standard clustering algorithms or standard techniques such as hidden Markov models, the real breakthroughs may belong to those who can find variations of these techniques that can be implemented at high speeds with some loss of accuracy. Similarly, online analytical processing (OLAP) tools may be useful for networking, with twists to fit the networking milieu. An example of a tool that has an OLAP flavor in a uniquely network setting can be found in Estan et al. [ESV03].
• Databases: The field of databases has a great deal to teach networking in terms of systematic techniques for querying for information. Recently, an even more relevant trend has been the subarea of continuous queries. Techniques developed in databases can be of great utility to algorithmics.
• Statistics: The field of statistics will be of even more importance in dealing with large data sets. Already, NetFlow and other tools have to resort to sampling. What inferences can safely be made from sampled data? As we have seen in Chapter 16, statistical methods are already used by ISPs to solve the traffic matrix problem from limited SNMP data.
18.4.3 New Requirements
Much of this book has focused on processing time as the main metric to be optimized while minimizing dollar cost. Storage was also an important consideration because of limited on-chip storage and the expense of SRAM. However, even minimizing storage was related to speed, in order to maximize the possibility of storing the entire data structure in high-speed storage.
The future may bring new requirements. Two important such requirements are (mechanical) space and power. Space is particularly important in PoPs and hosting centers, because rack space is limited. Thus routers with small form factors are crucial. It may be that optimizing space is mostly a matter of mechanical design together with the use of higher and higher levels of integration. However, engineering routers (and individual sensors in sensor networks) for power may require attention to algorithmics
Today power per rack is limited to a few kilowatts, and routers that need more power do so by spreading out across multiple racks. Power is a major problem in modern router design. It may be possible to rethink lookup, switching, and fair queuing algorithms in order to minimize power. Such power-conscious designs have already appeared in the computer architecture and operating systems community. It is logical to expect this trend to spread to router design.
18.5 THE INNER LIFE OF A NETWORKING DEVICE
We have tried to summarize in this chapter the major themes of this book in terms of the techniques described and the principles used. We have also tried to argue that network algorithmics is used in real products and is likely to find further application in the future because of new abstractions, new connecting disciplines, and new requirements. While the specific techniques and problems may change, we hope the principles involved remain useful.
Besides the fact that network algorithmics is useful in building better and faster network devices, we hope this book makes the case that network algorithmics is also intellectually stimulating. While it may lack the depth of hard problems in theoretical computer science or physics, perhaps what can be most stimulating is the breadth, in terms of the disciplines it encompasses.
An endnode, for instance, may appear as a simple processing state machine at the highest level of abstraction. A more detailed inspection would see a Web request packet arriving at a server interface, the interrupt firing, and the protocol code being scheduled via a software interrupt. Even within the protocol code, each line of code has to be fetched, hopefully from the i-cache, and each data item has to go through the VM system (via the TLB hopefully) and the data cache. Finally, the application must get involved via a returned system call and a process-scheduling operation. The request may trigger file system activity and disk activity.
A router similarly has an interesting inner life. Reflecting the macrocosmos of the Internet outside the router is a microcosmos within the router consisting of major subsystems, such as line cards and the switch fabric, together with striping and flow control across chip-to-chip links.
Network algorithmics seeks to understand these hidden subsystems of the Internet to make the Internet faster. This book is a first attempt to begin understanding — in Feynman’s phrase — this “tremendous world of interconnected hierarchies” within routers and endnodes. In furthering this process of understanding and streamlining these hierarchies, there are still home runs to be hit and touchdowns to be scored as the game against networking bottlenecks continues to be played.