
Copying Data
Copy from one, it’s plagiarism; copy from two, it’s research.
— WILSON MIZNER
Imagine an office where every letter received is first sent to shipping and receiving. Shipping and receiving opens the letter, figures out which department it’s meant for, and makes a photocopy for their records. They then hand it to the security department, which pores over every line of the letter, looking for signs of industrial esponiage. To maintain an audit trail for possible later use, the security department also makes a photocopy of the letter, for good measure. Finally, the letter, somewhat the worse for wear, reaches the intended recipient in personnel.
You would probably think this a pretty ludicrous state of affairs, worthy to be featured in a Charlie Chaplin movie. But then you might be surprised to learn that most Web servers, and computers in general, routinely make a number of extra copies of received and sent messages. Unlike photocopies, which take up only a small amount of paper, power, and time, extra copying in a computer consumes two precious resources: memory bandwidth and memory itself. Ultimately, if there are k copies involved in processing a message in a Web server, the throughput of the Web server can be k times slower.
Thus this chapter will focus on removing the obvious waste (P1) involved in such unnecessary copies. A copy is unnecessary if it is not imposed by the hardware. For example, the hardware does require copying bits received by an adaptor to the computer memory. However, as we shall see, there is no essential reason (other than those imposed by conventional operating system structuring) for copying between application and operating system buffers. Eliminating redundant copies allows the software to come closer to realizing the potential of the hardware, one of the goals of network algorithmics.
This chapter will also briefly talk about other operations (such as checksumming and encryption) that touch all the data in the packet and other techniques to more closely align protocol software to hardware constraints, such as bus bandwidths and caches. While we will briefly repeat some of the relevant operating systems and architectural facts, it will help the reader to be familiar with endnode architecture and operating system models of Chapter 2. In summary, this chapter surveys techniques for reducing the costs of data manipulation without sacrificing modularity and without major changes to operating system design.
This chapter is organized as follows. Section 5.1 describes why and how extra data copies occur. Section 5.2 describes a series of techniques to avoid copies by local restructuring of the operating system and network code at an endnode. Section 5.3 shows how to avoid both copy and control overhead for large transfers, using remote DMA techniques that involve protocol changes.
Section 5.4 broadens the discussion to consider the file system in, say, a Web server, and it shows how to avoid wasteful copies between the file cache and the application. Section 5.5 broadens the discussion to consider other operations that touch all the data, such as checksumming and encryption, and introduces a well-known technique called integrated layer processing. Section 5.6 broadens the discussion beyond copying to show that without careful consideration of cache effects, instruction cache effects can swamp the effects of copying for small messages.
Although this is the first chapter of the book that is devoted to techniques for overcoming a specific bottleneck, the techniques are based on the principles described in Part I of the book. The techniques and the corresponding principles are summarized in Figure 5.1.

5.1 WHY DATA COPIES
In Figure A.1 in the Appendix, we describe how TCP works in the context of a Web server. Figure A.1 only shows the sending of the GET request for a file, followed by the file data itself in two TCP segments. What Figure A.1 does not show is how the Web server processes the GET request. In this chapter, we ignore the control transfer required to transfer the request to some application server process. Instead, Figure 5.2 shows the sequence of data transfers involved in reading file data from the disk (in the worst case) to the sending of the corresponding segments via the network adaptor.

The main hardware players in Figure 5.2 are the CPU, the memory bus, the I/O bus, the disk, and the network adaptor. The main software players are the Web server application and the kernel. There are two main kernel subsystems involved, the file system and the networking system. For simplicity, the picture shows only one CPU in the server (many servers are multiprocessors) and focuses only on requests for static content (many requests are for dynamic content that is served by a computer-generated imagery (CGI) process).1
Intuitively, the story is simple. The file is read from disk into the application buffer via, say, a read() system call. The combination of the HTTP response and the application buffer is then sent to the network over the TCP connection to the client by, say, a write() system call. The TCP code in the network subsystem of the kernel breaks up the response data into bite-size segments and transmits them to the network adaptor after adding a TCP checksum to each segment.
In practice, the story is often more messy in the details. First, the file is typically read into a piece of kernel memory, called the file cache, in what we call Copy 1. This is a good idea because subsequent requests to a popular file can be served from main memory without slow disk I/O. The file is then copied from the file cache into the Web server application buffer in Copy 2 shown in Figure 5.2. Since the application buffer and the file cache buffer are in different parts of main memory, this copy can only be done by the CPU’s reading the data from the first memory location and writing into the second location across the memory bus.
The Web server then does a write() to the corresponding socket. Since the application can freely reuse its buffer (or even deallocate it) at any time after the write(), the network subsystem in the kernel cannot simply transmit out of the application buffer. In particular, the TCP software may need to retransmit part of the file after an unpredictable amount of time, by which time the application may wish to use the buffer for other purposes.
Thus UNIX (and many other operating systems) provides what is known as copy semantics. The application buffer specified in the write() call is copied to a socket buffer (another buffer within the kernel, at a different address in memory than either the file cache or the application buffer). This is called Copy 3 in Figure 5.2. Finally, each segment is sent out to the network (after IP and link headers have been pasted) by copying the data from the socket buffer to memory within the network adaptor. This is called Copy 4.
In between, before transmission to the network, the TCP software in the kernel must make a pass over the data to compute the TCP checksum. Techniques for efficiently implementing the TCP checksum are described in Chapter 9, but for now it suffices to think of the TCP checksum as essentially computing the sum of 16-bit words in each TCP segment’s data.
Each of the four copies and the checksum consume resources. All four copies and the checksum calculation consume bandwidth on the memory bus. The copies between memory locations (Copies 2 and 3) are actually worse than the others because they require one Read and one Write across the bus for every word of memory transferred. The TCP checksum requires only one Read for every word and a single Write to append the final checksum. Finally, Copies 1 and 4 can be as expensive as Copies 2 and 3 if the CPU does the heavy lifting for the copy (so-called programmed I/O); however, if the devices themselves do the copy (so-called DMA), the cost is only a single Read or Write per word across the bus.
The copies also consume I/O bus bandwidth and ultimately memory bandwidth itself. A memory that supplies a word of size W bits every x nanoseconds has a fundamental limit on throughput of W/x bits per nanosecond. For example, even assuming DMA, these copies ensure that the memory bus is used seven times for each word in the file sent out by the server. Thus the Web server throughput cannot exceed T/7, where T is the smaller of the speed of the memory and the memory bus.
Second, and more basically, the extra copies consume memory. The same file (Figure 5.2) could be stored in the file cache, the application buffer, and the socket buffer. While memory seems to be cheap and plentiful (especially when buying a PC!), it does have some limits, and Web servers would like to use as much as possible for the file cache to avoid slow disk I/O. Thus triply replicating a file can reduce the file cache by a factor of 3, which in turn can dramatically reduce the cache hit rate and, hence, overall server performance.
In summary, redundant copies hurt performance in two fundamental and orthogonal ways. First, by using more bus and memory bandwidth than strictly necessary, the Web server runs slower than bus speeds, even when serving documents that are in memory. Second, by using more memory than it should, the Web server will have to read an unduly large fraction of files from disk instead of from the file cache.
Note also that we have only described the scenario in which static content is served. In reality the SPECweb benchmarks assume that 30% of the requests are for dynamic content. Dynamic content is often served by a separate CGI process (other than the server application) that communicates this content to the server via some interprocess communication mechanism, such as a UNIX pipe, which often involves another copy.
Ideally, all these pesky extra bus traversals should be removed. Clearly, Copy 1 is not required if the data is in cache and so we can ignore it (if it’s not in cache, the server runs at disk speed, which is too slow anyway). Copy 2 seems unnecessary. Why can’t the data be sent directly from the file cache memory location to the network? Similarly, Copy 3 seems unnecessary. Copy 4 is unavoidable.
5.2 REDUCING COPYING VIA LOCAL RESTRUCTURING
Before tackling the full complexity of eliminating all redundant copies in Figure 5.2, this section starts by concentrating on Copy 3, the fundamental copy made from the application to kernel buffers (or vice versa) when a network message is sent (received). This is a fundamental issue for networking, independent of file system issues. It also turns out that general solutions that eliminate all redundant I/O copies (Section 5.4) build on the techniques developed in this section.
This section assumes that the protocol is fixed but the local implementation (at least the kernel) can be restructured. The goal, of course, is to perform minimal restructuring in order to continue to leverage the vast amount of investment in existing kernel and application software. Section 5.2.1 describes techniques based on exploiting adaptor memory. Section 5.2.2 describes the core idea behind copy avoidance (by remapping shared physical pages) and its pitfalls. Section 5.2.3 shows how to optimize page remapping using precomputation and caching based on I/O streams; however, this technique involves changing the application programming interface (API). Finally, Section 5.2.4 describes another technique, one that uses virtual memory but does not change the API.
5.2.1 Exploiting Adaptor Memory
The simple idea here is to exploit a degree of freedom (P13) by realizing that memory can be located anywhere on the bus in a memory-mapped architecture. Recall from Chapter 2 that memory mapping means that the CPU talks to all devices, such as the adaptor and the disk, by reading and writing to a portion of the physical memory space that is located on the device.
Thus while kernel memory is often resident on the memory subsystem, there is no reason why part of the kernel memory cannot be on the adaptor itself, which typically contains some memory. By leveraging off the existing adaptor memory (P4) and utilizing this degree of freedom in terms of placement of kernel memory, we can place kernel memory on the adaptor. The net result is that once the data is copied from application to kernel memory it is already in the adaptor and so does not need to be copied again for transmission to the network. This is shown in Figure 5.3.

Compare Figure 5.3 to Figure 5.2. Notice that Figure 5.3 ignores any disk-to-memory transfer. Essentially, the useless Copy 3 in Figure 5.2 is now combined with the essential Copy 4 in Figure 5.2 to form a single copy in Figure 5.3.
What about the checksum? We will see this in more general form in Section 5.5, but the main idea is to use principle P2c, expense sharing. When data is being moved from the application buffer to the adaptor resident kernel memory by the processor (using so-called programmed I/O, or PIO, which is I/O under processor control), the CPU is reading every word of the packet anyway. Since such bus reads are expensive, the CPU might as well piggyback the checksum computation with the copy process by keeping a register that accumulates the running sum of words that are transferred.
This idea, first espoused by Van Jacobson and called the Witless (or simple-minded) approach, was never built. Later this approach was used by Banks and Prudence [BP93] at Hewlett-Packard labs and called the Afterburner adaptor. In the Afterburner approach, the CPU did not transfer data from memory to the adaptor. Instead, the adaptor did so, using so-called direct memory access, or DMA. Thus since the CPU is no longer involved in the copy process, the adaptor should do the checksum. The Afterburner adaptor had special (but simple) checksum hardware that checksummed words as the DMA transfer takes place.
While the idea is a good one, it has three basic flaws. First, it implies that the network adaptor needs lots of memory to provide support for many high-throughput TCP connections (which require large window sizes); the memory required may make the adaptor more expensive than one wishes. Second, in the Witless approach, where the checksum is calculated by the CPU, doing the checksum while copying a received packet to the application buffer can imply that corrupted data can be written to application buffers. Though this can be discovered at the end, when the checksum does not compute, it does cause some awkwardness to prevent applications from reading incorrect data. A third problem with delayed acknowledgments is explored in the exercises.
5.2.2 Using Copy-on-Write
While the basic idea in the Witless approach can be considered to be eliminating the kernel- to-adaptor copy, the alternate idea pursued in the next three subsections is to eliminate the application-to-kernel copy (in most cases) using virtual memory remappings. Recall that one reason for the separate copy was the possibility that the application would modify the buffer and hence violate TCP semantics. A second reason is that the application and kernel use different virtual address spaces.
Some operating systems (notably Mach) offer a facility called copy-on-write (COW) that allows a process to replicate a virtual page in memory at low cost. The idea is to make the copy point to the original physical page P from which it was copied. This only involves updating a few descriptors (a few words of memory) instead of copying a whole packet (say, 1500 bytes of data). However, the nice thing about copy-on-write is that if the original owner of the data modifies the data, the OS will detect this condition automatically and generate two separate physical copies, P and P′. The original owner now points to P and can make modifications on P; the owner of the copied page points to the old copy, P′. This works fine if the vast majority of times pages are not modified (or only a few pages are modified) by the original owner.
Thus in a copy-on-write system, the application could make a copy-on-write copy for the kernel. In the hopefully rare event that the application modifies its buffer, the kernel makes an (expensive) physical copy. However, that should be uncommon. Clearly, we are using lazy evaluation (P2b) to minimize overhead in the expected case (P11). Finally, in Figure 5.4 the checksum can be piggybacked either with the copy to or from adaptor memory or by using CRC hardware on the adaptor.

Unfortunately, many operating systems, such as UNIX2 and Windows, do not offer copy-on-write. However, much of the same effect can be obtained by understanding the basis behind the copy-on-write service, which is the use of virtual memory.
IMPLEMENTING COPY-ON-WRITE
Recall from Chapter 2 that most modern computers use virtual memory. Recall that the programmer works with an abstraction of infinite memory that is a linear array into which she (or more accurately her compiler) assigns variable locations, so, say, location X would be location 1010 in this imaginary (or virtual) array. These virtual addresses are then mapped into physical memory (which can reside on disk or in main memory) using a page table (Chapter 2).
For any virtual address, the high-order bits (e.g., 20 bits) form the page number, and the low-order bits (e.g., 12 bits) form the location within a page. Main memory is also divided into physical pages such that (say) every group of 212 memory words is a physical page. Recall that a virtual address is mapped to a physical address by mapping the corresponding virtual page to a physical page number by looking up a page table indexed by the virtual page number. If the desired page is not memory resident, the hardware generates an exception that causes the operating system to read the page from disk into main memory. Recall also that the overhead of reading page tables from memory can be avoided in the common case using a TLB (translation look-aside buffer), which is a processor resident cache.
Looking under the hood, virtual memory is the basis for the copy-on-write scheme. Suppose virtual page X is pointing to a physical memory–resident page P. Suppose that the operating system wishes to replicate the contents of X onto a new virtual page, Y. The hard way to do this would be to allocate a new physical page, P′, to copy the contents of P to P′, and then to point Y to P′ in the page table. The simpler way, embodied in copy-on-write, is to map the new virtual page, Y, back to the old physical page, P, by changing a page table entry. Since most modern operating systems use large page sizes, changing a page table entry is more efficient than copying from one physical page to another.
In addition, the kernel also sets a COW protection bit as part of the page table entry for the original virtual page, X. If the application tries to write to page X, the hardware will access the page table for X, notice the bit set, and generate an exception that calls the operating system. At this point the operating system will copy the physical page, P, to another location, P′ and then make X point to P′, after clearing the COW bit. Y continues to point to the old physical page, P. While this is every bit as expensive as physical page copying, the point is that this expense is incurred only in the (hopefully) rare case when an application writes to a COW page.
The explanation of how COW works should present the following opportunity. While operating systems such as UNIX and Windows do not offer COW, they still offer virtual memory. Virtual memory (VM) presents a level of indirection that can be exploited by changing page table entries to finesse physical copying. Thus much of the core idea behind Figure 5.4 can be reused in most operating systems. All that remains is to find an alternate way to protect against application Writes in place of COW protection.
5.2.3 Fbufs: Optimizing Page Remapping
Even ignoring the aspect of protecting against application writes, Figure 5.5 implies that a large buffer can be transferred from application to kernel (or vice versa) with a Write to the page table. This simplistic view of page remapping is somewhat naive and misleading.

Figure 5.5 shows a concrete example of page remapping. Suppose the operating system wishes to make a fast copy of data of Process 1 (say, the application) in Virtual Page (VP) 10 to some virtual page (e.g., VP 8) in the page table of Process 23’s (say, the kernel). Naively, this seems to require only changing the page table entry corresponding to Virtual Page 8 in Process 2 to point to the packet data to which that Virtual Page table entry 10 in Process 1 already points. However, there are several additional pieces of overhead that are glossed over by this simple description.
• Multiple-level page tables: Most modern systems use multiple levels of page table mappings because it takes too much page table memory to map from, say, 20 bits of a virtual page. Thus the real mapping may require changing mappings in at least a first- and a second-level page table. For portability, there are also both machine-independent and machine-dependent tables. Thus there are several Writes involved, not just one.
• Acquiring locks and modifying page table entries: Page tables are shared resources and thus must be protected using locks that must be acquired and released.
• Flushing translation look-aside buffers (TLBs): As we said earlier, to save translation time, commonly used page table mappings are cached in the TLB. When a new virtual page location for VP 8 is written, any TLB entries for VP 8 must be found and flushed (i.e., removed) or corrected.
• Allocating VM in destination domain: While we have assumed that virtual memory location 8 was the location for the destination page, some computation must be done to find a free page table entry in the destination process before the copy can take place.
• Locking the corresponding pages: Physical pages can be swapped out to disk to make room for other virtual pages currently on disk. To prevent pages from being swapped out, pages have to be locked, which is additional overhead.
All these overheads are exacerbated in multiprocessor systems. The net result is that while the page table mapping can seem very good (the mapping seems to take a constant time, independent of the size of the packet data), the constant factors (see Q4 in the discussion of caveats) are actually a big overhead. This was experimentally demonstrated by experiments performed by Druschel and Peterson [DP93] in the early 1990s. In the decade that followed, if anything, page mapping overheads have only increased.
Druschel and Peterson, however, did not stop with the experiments but invented an operating system facility called fbufs (short for “fast buffers”), which actually removes most or all of the four sources of page remapping overhead. Their idea can be described as follows in terms of the principles used in this book.
FBUFS
The main idea in fbufs is to realize that if an application is sending a lot of data packets to the network through the kernel, then a buffer will probably be reused multiple times, and thus the operating system can precompute (P2a) all the page mapping information for the buffer ahead of time and then avoid much of the page mapping overhead during the actual data transfer. Alternatively, the mappings can be computed lazily (P2b) when the data transfer is first started (causing high overhead for the first few received packets) but can be cached (P11a) for the subsequent packets. In this version, page remapping overheads are eliminated in the common case.
The simplest way to do this would be to use what is called shared memory. Map a number of pages P1,…,Pn into the virtual memory tables of the kernel as well as all sending applications A1,…, Ak. However, this is a bad idea, because we now can have (say) application A1 reading the packets sent by application A2.3 This would violate security and fault-isolation goals.
A more secure notion would be to reserve (or lazily establish) mapped shared pages for each application-to-kernel transfer, and vice versa. For example, there could be one set of buffers (pages) for FTP, one set for HTTP, and so on. More generally, some operating systems define multiple security subsystems besides kernel and application. Thus the fbuf designers call a path a sequence of security domains. For our simple examples described earlier, it suffices to think of a path as either kernel, application or application, kernel (e.g., FTP, kernel or kernel, HTTP). We will see why paths are unidirectional — that is, why each application needs two paths in both directions — in a minute.
Figure 5.6 shows a more complex example of paths, where the Ethernet software is implemented as a kernel-level driver, the TCP/IP stack is implemented as a user-level security domain, and, finally, the Web application is implemented at the application layer. Each security domain has its own set of page tables. The receiving paths are Ethernet, TCP/IP, Web and Ethernet, OSI, FTP.

To implement the fbuf idea the operating system could take some number of physical pages P1,…, Pk and premap them onto the page tables of the Ethernet driver, the TCP/IP code, and the Web application. The same operation could be performed with a different set of physical pages for Ethernet, OSI, and FTP. Thus we are using Principle 2a to precompute mappings. Reserving physical pages for each path could be wasteful, because traffic is bursty; instead, a better idea is to lazily establish (P2b) such mappings when a path becomes busy.
Lazy establishment avoids the overheads of updating multiple levels of page tables, acquiring locks, flushing TLBs, and allocating destination virtual memory after the first few data packets arrive and are sent. Instead, all this work is done once, when the transfer first starts. To make fbufs work, it is crucial that when a packet arrives, the lowest-level driver (or even the adaptor itself) be able to quickly figure out what the complete path the packet will be mapped to when receiving a packet from the network. This function, called early demultiplexing, is described in detail in Chapter 8. Intuitively, in Figure 5.6 this is done by examining all the packet headers to determine (for instance) that a packet with an Ethernet, IP, and HTTP header belongs to Path 1.
The driver (or the adaptor) will then have a list of free buffers for that path, which will be used by the adaptor to write the packet to; when the adaptor is done it will pass the buffer descriptor to the next application in the path. Note that a buffer descriptor is only a pointer to a shared page, not the page itself. When the last application in the path finishes with the page, it passes it back to the first application in the path, where it again becomes a free buffer, and so on.
At this point, the reader may wonder why paths are unidirectional. Paths are made unidirectional because the first process on each path is assumed to be a writer and the remaining processes are assumed to be readers. This can be enforced during the premapping by setting a write-allowed bit for the first application in its page table entry, and a read-only bit in the page table entries of all the other applications. Clearly, this is asymmetric in both directions and requires unidirectional paths. But this does ensure some level of protection.
This is shown in Figure 5.7 with just two domains in a path. Note that the writer writes packets into buffers described by a queue of free fbufs and then puts the written descriptor on to a queue of written fbufs that are read by the next application (only one is shown in Figure 5.7).

So far, it is possible that premapped page 8 in the first application on a path is mapped to page 10 in the second application. This is painful because when the second application reads a descriptor for page 8, it must somehow know that it corresponds to its own virtual page 10. Instead, the designers used the principle of avoiding unnecessary generality (P7) and insisted that the fbuf get mapped to the same virtual page in all applications on the path. This can be done by reserving some number of initial pages in the virtual memory of all processes to be fbuf pages.
At this point, we may feel that we are finished, but there are still a few thorny problems. To achieve protection, we allowed only a single writer and had multiple readers. However, that means that pages are immutable; only the writer can touch them. But what about adding headers when one goes down the stack. The solution to this problem is shown in Figure 5.8, where a packet is really an aggregate data structure with pointers to individual fbufs so that headers can be added by adding an ordinary buffer or an fbuf to the aggregate.
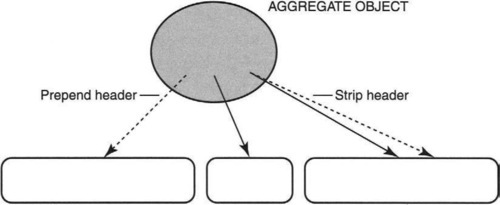
This is not as big a deal as it sounds because the commonly used UNIX mbufs (see Chapter 9) are also composites of buffers strung together.4
So far, the fbuf scheme has used the underlying VM mapping ideas in Figure 5.4 except that it has made them more efficient by amortizing the mapping costs over (hopefully) a large number of packet transfers. Page table updates are removed in the common case. This can be done in ordinary operating systems. In fact, after the fbufs paper, Thadani and Khalidi [TK95] extended the idea and implemented it in Sun’s Solaris operating system. But this begs the question: How are standard copy semantics preserved? What if the application does a Write? A standard operating system such as UNIX cannot depend on copy-on-write as in Figure 5.4.
The ultimate answer in fbufs is that standard copy semantics are not preserved. The API is changed. Application writers must be careful not to write to an fbuf when it has been handed to the kernel until the fbuf is returned by the kernel in a free list. To protect against buggy or malicious code, the kernel can briefly toggle the write-enable bit when an fbuf is transferred from the application to the kernel; the bit is set again when the fbuf is given back. If the application does a Write when it does not have write permission, an exception is generated and the application crashes, leaving other processes unaffected.
Since the toggling of the write-enable bits requires some of the overhead that fbufs worked hard to avoid, the fbuf facility also allows another form of fbufs, called volatile. Observe that if the writer is a trusted entity (such as the kernel), then there is no point enforcing write protection. If the kernel has a bug that causes it to make unexpected writes, the whole system will crash anyway.
Changing the API in this way sounds dramatic. Does this mean that the huge amount of existing UNIX application software (which uses the networking stack) must be rewritten? Since this is infeasible, there are several ways out. First, the existing API can be augmented with new system calls. For example, the Solaris extensions in Thadani and Khalidi [TK95] add a uf_write() call in addition to the standard write() call. Applications interested in performance can be rewritten using these new calls.
Second, the extensions can be used in implementing common I/O substrates (such as the UNIX stdio library) that are a part of several applications. Applications that are linked to this library do not need to be changed and yet can potentially benefit in performance.
Eventually, the pragmatic consideration is not whether the API changes but how hard it is to modify applications to benefit from the API changes. The experiences described in Thadani and Khalidi [TK95] and Pai et al. [PDZ99b] for a number of applications indicate that the changes required in an application to migrate to an fbuf-like API are small and localized.
5.2.4 Transparently Emulating Copy Semantics
One reaction to the new fbuf API is simply to modify applications to gain performance. It is worth pointing out that while the changes may be simple and localized, the mental model that a programmer has of a buffer changes in a fairly drastic way. In the standard UNIX API, the application assigns buffer addresses; in fbufs, the buffers are assigned by the kernel from the fbuf address space. In the standard UNIX API, the programmer can design the buffer layout anyway he pleases, including the use of contiguous buffers. In fbufs, data received from the network can be arbitrarily scattered into pieces linked together by a buffer aggregate, and the application programmer must deal with this new buffer model chosen by the kernel.
Thus a reasonable question is whether many of the benefits of fbufs can be realized without modifying the UNIX API. Theoretically, application software will continue to run, and one might get performance without recoding applications.
In a series of papers, Brustoloni and Steenkiste (e.g., Ref. BS96) showed that there is a clever mechanism, which they call TCOW (for transient copy-on-write), that makes this possible. While preserving the API theoretically allows unmodified applications to enjoy better performance, there is no experimental confirmation of this possibility. Thus in practice, it is likely that applications have to be modified (perhaps in more intuitive ways) to take advantage of the underlying kernel implementation changes. Nevertheless, the idea is simple and clever and worth pointing out.
Recall that the standard API requires allowing an application to write or deallocate a buffer passed to the kernel at any time. The fbuf design changes the API by making it illegal for an application to do this. Instead, to preserve the API while doing only virtual memory mappings, the operating system must deal with these two potential threats, application writes and application deallocates, during the period the buffer is being used by the kernel to send or retransmit a packet. In the Genie system [BS96], VM mapping is used, as in fbufs, but these two threats are dealt with as follows.
Countering Write Threats by Modifying the VM Fault Manager: First, when an application does a Write, the buffer is marked specially, as Read Only. Thus if the application does a Write, the VM fault manager is invoked. Normally, this should cause an exception. But, of course, if the OS is preserving copy semantics, this should not be an error. Thus Genie modifies the exception handler as follows. First, for each such page/buffer, Genie keeps track of whether there are outstanding sends (sends to the network) using a simple counter that is incremented when the Send starts and decremented when the Send completes. Second, the fault handler is modified to make a separate copy of the page for the application (which incorporates the new Write) if there is an outstanding Send. Of course, this makes performance suffer, but it does preserve the standard copy semantics of APIs such as UNIX. This technique, called transient copy-on-write protection, is invoked only when needed — when the buffer is also being read out by the network subsystem.
Countering Deallocate Threats by Modifying the Pageout Daemon: In a standard virtual memory system, there is a process that is responsible for putting deallocated pages into a free list from which pages may be written to disk. This pageout daemon can be modified not to deallocate a page when the page is being used to send or receive packets.
Interestingly these two ideas are both instances of Principle P3c, shifting computation in space. The work of checking for unexpected writes is moved to the VM fault handler, and the work of dealing with deallocates is moved to the page deallocation routine.
These two ideas are sufficient for sending a packet but not for receiving. On receiving, Genie needs to depend, like fbufs, on hardware support5 in the adaptor to split a packet’s headers into one buffer and the remaining data into a page-size buffer that can be swapped to the application’s buffer.
To do so without a physical copy, the kernel’s data buffer must start at the same offset within the page as the application’s receive buffer. For a large buffer, the first and last pages (which can be partially filled) are probably most efficiently handled by a physical copy; however, the intermediate pages that are full can simply be swapped from the kernel to the application by the right page table mappings. There is a cute optimization called reverse copyout that is explored in the exercises.
Given the complexity that underlies page table remapping, it is unclear how page remapping is done efficiently in Genie. One possibility is that Genie uses the same fbuf idea of caching VM mappings on a path basis6 to avoid the overhead of TLB flushing, dealing with multiple page tables, and so on.
When all is said and done, can the TCOW idea benefit legacy applications? There is no experimental confirmation of this in Brustaloni and Steenkiste [BS96] and Brustoloni [Bru99] because the experiments use a simple copy benchmark and not an existing application such as a Web server. Fundamentally, it seems hard for an existing legacy application to benefit from the new kernel implementation of the existing API.
Consider an application running over TCP that supplies a buffer to TCP. Since there is no feedback to the application (unlike fbufs), the application does not know when it can safely reuse the buffer. If the application overwrites the buffer too early while TCP is holding the buffer for retransmission, then safety is not compromised, but performance is compromised because of the physical copy involved in copy-on-write. It appears improbable that an unmodified application could choose the times to modify buffers in accordance with TCP sending times and would have aligned its buffers well enough to allow page swapping to work well.
Thus applications do need to be modified to take full advantage of the Genie system. Even if they do, there is still the hard problem of knowing when to reuse a buffer, because of the lack of feedback. The application could monitor TCOW faults and accordingly modify its reuse pattern. But if applications need to be modified in subtle ways to take full advantage of the new kernel, it is unclear what benefit was gained from preserving the API. Nevertheless, the ideas in Genie are fun to study, and they fall nicely within the general area of network algorithmics.
5.3 AVOIDING COPYING USING REMOTE DMA
While fbufs provide a reasonable solution to the problem of avoiding redundant application-to-kernel copies, there is a more direct solution that also removes an enormous amount of control overhead. Normally, if a 1-MB file is transferred between two workstations on an Ethernet, the file is chopped up into 1500-byte pieces. The CPU is involved in processing each of these 1500-byte pieces to do TCP processing and copying each packet (possibly via a zero-copy interface such as fbufs) to application memory.
On the other hand, recall from Chapter 2 how a CPU orchestrates a direct memory access (DMA) operation between, say, disk and memory for, say, a 1-MB transfer. The CPU sets up the DMA, tells the disk the range of addresses into which the data must be written, and goes about its business. One megabyte of data later, the disk interrupts the CPU to essentially say, “Master, your job is done.” Note that the CPU does not micromanage every piece of this transfer, unlike in the earlier case of the corresponding network transfer.
This analogy suggests the vision of doing DMA across the network, or RDMA as it is sometimes called. In fact, it is hardly surprising that this networking feature was first proposed in VAX Clusters by a group of computer architects [KLS86]. It is said that breakthroughs often come via outsiders to an area. There is an apocryphal story about how one of the inventors of VAX Clusters came to the networking people at DEC and asked to learn about networking. They laughed at him and gave him a copy of the standard undergraduate text at that time. He came back 6 months later with the RDMA design.
The intent is that data should be transferred between two memories in two computers across the network without per-packet mediation by the two CPUs. Instead, the two adaptors conspire to read from one memory and to write to the other: DMA across the network. To realize this vision two problems must be solved: (1) how the receiving adaptor knows where to place the data — it cannot ask the host for help without defeating the intent; (2) how security is maintained. The possibility of rogue packets coming over the network and overwriting key pieces of memory should make one pause.
This section starts by describing this very early idea and then moves on to describe modern incarnations of this idea in the Fiber Channel and RDMA [Cona] proposals.
5.3.1 Avoiding Copying in a Cluster
In the last few years, clusters of workstations have become accepted as a cheaper and more effective substitute for large computers. Thus many Web servers are really server farms. While this appears to be recent technology, 20 years ago Digital Equipment Corporation (DEC) introduced a successful commercial product called VAX Clusters to provide a platform for scalable computing for, say, database applications. The heart of the system was a 140-Mbit network called the computer interconnect, or CI, which used an Ethemet-style protocol. To this interconnect, customers could connect a number of VAX computers and network-attached disks. The issue of efficient copying was motivated by the need to transfer large amounts of data between the remote disk and the memory of a VAX. RDMA was born from this need.
RDMA requires that packet data containing part of a large file go into its final destination when it gets to the destination adaptor. This is trickier than it sounds. In traditional networking, when the packet arrives the processor is involved in at least examining the packet and deciding where the packet is to go. Even if the CPU looks at headers, it can only tell based on the destination application which queue of receive buffers to use.
Suppose the receiving application queues Pages 1, 2, and 3 to the receiving adaptor for Application 1. Suppose the first packet arrives and is sent to Page 1, the third packet arrives out of order and is put in Page 2 instead of Page 3. Assume that Pages 1, 2, and 3 should store the receiving file. The CPU can always remap pages at the end, but remapping all the pages at the end of the transfer for a large file can be painful. Out-of-order arrival can always happen, even on a FIFO link, because of packet loss.
Instead, the idea in VAX Clusters is first to have the destination application lock a number of physical pages (such as Pages 11 and 16 in Figure 5.9) that comprise the destination memory for the file transfer. The logical view presented, however, is a buffer of consecutive logical pages (e.g., Pages 1 and 2 in Figure 5.9) called, say, B. This buffer name B is passed to the sending application.
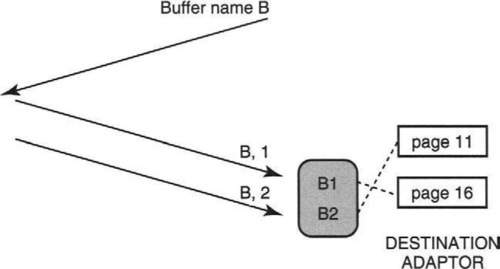
The source now passes (P10, pass information in protocol headers) the buffer name and offset with each packet it sends. Thus when sending Packet 3 out of order in our last example, Packet 3 will contain B and Page 3 and so can get stored in Page 3 of the buffer even though it arrives before Packet 2. Thus after all packets arrive there is no need for any further page remapping. This is an example of P10: passing information, such as a buffer name, in message headers.
To realize the ideal of not bothering the processor on every packet arrival, there are several additional requirements. First, the adaptor must implement the transport protocol (and do all the checking for duplicates, etc.), as in TCP processing. Second, the adaptor must be able to determine where the data begins and where the headers stop so as only to copy the data into the destination buffer.
Finally, it is somewhat cavalier to allow any packet carrying a buffer ID from the network to be written directly into memory. This could be a security hole. To mitigate against this, the buffer IDs contain a random string that is hard to guess. More importantly, VAX Clusters are used only between trusted hosts in a cluster. It is more difficult to imagine scaling this approach to Internet data transfers.
5.3.2 Modern-Day Incarnations of RDMA
VAX Clusters introduced a very early storage area network. Storage area networks (SANs) are back-end networks that connect many computers to shared storage, in terms of network-attached disks. There are several recent successors to VAX Clusters that provide SAN technology. These range from the venerable Fiber Channel [Ben95] technology to modern upstarts such as InfiniBand [Assa] and iSCSI [SSMe01].
FIBER CHANNEL
In 1988, the American National Standards Institute (ANSI) Task Group X3T11 began work on a standard called Fiber Channel [Ben95]. One of the goals of Fiber Channel was to take the standard SCSI (small computer system interface) between a workstation and a local disk and extend it over larger distances. Thus in many Fiber Channel installations, SCSI is still used as the protocol that runs over Fiber Channel.
Fiber Channel goes further than VAX Clusters in the underlying network, using modern network technology such as point-to-point fiber links connected with switches. This allows speeds of up to 1 Gbps and allows a larger distance span than in the Vax Cluster network. Switches can even be remotely connected, allowing a trading firm to have backup storage of all trades at a remote site. The use of switches requires attention to such issues as flow control, which is done very carefully to avoid dropping packets where possible.
Finally, Fiber Channel makes slightly more concession to security than VAX Clusters. In VAX Clusters, any device with the right name can overwrite the memory of any other device. Fiber Channel allows the network to be virtualized into zones. Nodes in a zone cannot access the memory of nodes in other zones. Some recent products go even further and propose techniques based on authentication.
However, other than these differences in the underlying technology, the underlying ideas are the same. RDMA via named buffers is still a key enabling idea.
INFINIBAND
Infiniband starts with the observation that the internal I/O bus used within many workstations and PCs, the PCI bus, is showing its age and needs replacement. With a maximum bandwidth of 533 MB/sec, the PCI bus is being overwhelmed by modern high-speed peripherals, such as Gigabit Ethernet interface cards. While there are some temporary alternatives, such as the PCI-X bus, the internal computer interconnect needs to scale in the same way as the external Internet has scaled from, say, 10-Mbit Ethernet to Gigabit Ethernet.
Also, observe that there are three separate networking technologies within a computer: the network interface (e.g., Ethernet), the disk interface (e.g., SCSI over Fiber Channel), and the PCI bus. Occam’s razor suggests substituting these three with one network technology. Accordingly, Compaq, Dell, HP, IBM, and Sun banded together to form the Infiniband Trade Association.
The Infiniband specifications use many of the ideas in Fiber Channel’s underlying network technology. The interconnect is also based on switches and point-to-point links. Infiniband has a few additional twists. It uses the proposal for 128-bit IP addresses in the next-generation Internet as a basis for addressing. It allows individual physical links to be virtualized into separate virtual links called lanes. It has features for quality of service and even multicast. Once again, RDMA is the key technology to avoid copies.
ISCSI
At the time of writing, Fiber Channel parts appear to be priced higher than equivalent-speed Gigabit Ethernet parts. Given that IP has invaded various other networking spaces, such as voice, TV, and radio, a natural consequence is to invade the storage space. This, the argument goes, should drive down prices (while also opening up new markets for network vendors). Further, Fiber Channel and Infiniband are being extended to connect remote data centers over the Internet. This involves using transport protocols that are not necessarily compatible with TCP in terms of reacting to congestion. Why not just adapt TCP for this purpose instead of trying to modify these other protocols to be TCP-friendly?
For the purposes of this chapter, the most interesting thing about iSCSI is the way it must emulate RDMA over standard IP protocols. In particular, recall that in all RDMA implementations, the host adaptor implements the transport protocol in hardware. In the Internet world, the transport protocol is TCP. Thus adaptors must implement TCP in hardware. This is not too hard, and chips that perform TCP offload are becoming widely available.
The harder parts are as follows. First, as we saw in Case Study 1 of Chapter 2, TCP is a streaming protocol. The application writes bytes to a queue, and these bytes are arbitrarily segmented into packets. The RDMA idea, on the other hand, is based on messages, each of which has a named buffer field. Second, RDMA over TCP requires a header to hold named buffers.
The RDMA [Cona] proposal solves both these problems by logically layering three protocols over TCP. The first protocol, MPA, adds a header that defines message boundaries in the byte stream. The second and third protocols implement the RDMA header fields but are separated as follows. Notice that when a packet carries data, all that is needed is a buffer name and offset. Thus this header is abstracted out into a so-called DDA (for direct data access) header together with a command verb (such as READ or WRITE).
The RDMA protocol that is layered over DDA adds a header with a few more fields. For example, for an RDMA remote READ, the initial request must specify the remote buffer name (to be read) and the local name (to be written to). One of these two buffer names can be placed in the DDA header, but the other must be placed in the RDMA header. Thus, except for control messages such as initiating a READ, all data carries only a DDA header and not an RDMA header.
During the evolution from VAX Clusters to the RDMA proposal, one interesting generalization was to replace a named buffer with an anonymous buffer. In this case, the DDA header contains a queue name, and the packet is placed in a buffer corresponding to the buffer at the head of the free queue at the receiver.
5.4 BROADENING TO FILE SYSTEMS
So far this chapter has concentrated only on avoiding redundant copies that occur while sending data between an application (such as a Web server) and the network. However, Figure 5.2 shows that even after removing all redundant overhead due to network copying, there are still redundant copies involving the file system. Thus in this section, we will cast our net more widely. We leverage our intellectual investment by extending the copy-avoidance techniques discussed so far to the file system.
Recall from Figure 5.2 that to process a request for File X, the server may have to read X from disk (Copy 1) into a kernel buffer (representing the file cache) and then make a copy from the file cache to the application buffer (Copy 2). Copy 1 goes out of the picture if the file is already in cache, a reasonable assumption for popular files in a server with sufficient memory. The main goal is to remove Copy 2. Note that in a Web server, unnecessarily doubling the number of copies not only halves the effective bus bandwidth but potentially halves the size of the server cache. This in turn reduces server performance by causing a larger miss rate, which implies that a larger fraction of documents is served at disk speeds and not bus speeds.
This section surveys three techniques for removing the redundant file system copy (Copy 2). Section 5.4.1 describes a technique called shared memory mapping that can reduce Copy 2 but is not well integrated with the network subsystem. Section 5.4.2 describes IO-Lite, essentially a generalization of fbufs to include the file system. Finally, Section 5.4.3 describes a technique called I/O splicing that is used by many commercial Web servers.
5.4.1 Shared Memory
Modem UNIX variants [Ste98] provide a convenient system call known as mmap() to allow an application such as a server to map a file into its virtual memory address space. Other operating systems provide equivalent functions. Conceptually, when a file is mapped into an application’s address space, it is as if the application has cached a copy of the file in its memory. This seems redundant because the file system also maintains cached files. However, using the magic of virtual memory (P4, leverage off system components), the cached file is really only a set of mappings, so other applications and the file server cache can gain common access to one set of physical pages for the file.
The Flash Web server [PDZ99a] avoids Copy 1 and Copy 2 in Figure 5.2 by having the server application map frequently used files into memory. Given that there are limits on the number of physical pages that can be allocated to file pages and limits on page table mappings, the Flash Web server has to treat these mapped files as a cache. Instead of caching whole files, it caches segments of files and uses an LRU (least recently used) policy to unmap files that have not been used for a while.
Note that such cache maintenance functions are duplicated by the file system cache (which has a more precise view of resources such as free pages because it is kernel resident). However, this can be looked on as a necessary evil to avoid Copies 1 and 2 in Figure 5.2. While Flash uses mmap() to avoid file system copying, it runs over the UNIX API. Hence, Flash is constrained to make an extra copy in the network subsystem (Copy 3 in Figure 5.2). Just when progress is being made to eliminate Copy 2, pesky Copy 3 reappears again!
Copy 3 can be avoided by combining emulated copying using TCOW [BS96] with mmap(). However, this has some of the disadvantages of TCOW mentioned earlier. It is also not a complete solution that generalizes to avoid copying for interaction with a CGI process via a UNIX pipe.
5.4.2 IO-Lite: A Unified View of Buffering
While combining emulated copy with mmap() does away with all redundant copying, it still has some missing optimizations. First, it does nothing to avoid the copying between any CGI application generating dynamic content and the Web server. Such an application is typically implemented as a separate process7 that sends dynamic content to the server process via a UNIX pipe. But pipes and other similar interprocess communication typically involve copying the content between two address spaces.
Second, notice that none of our schemes so far has done anything about the TCP checksum, an expensive operation. But if the same file keeps hitting in the cache, other than the first response containing the HTTP header, all subsequent packets that return the file contents stay the same for every request. Why can’t the TCP checksums be cached? However, that requires a cache that can somehow map from packet contents to checksums. This is inefficient in a conventional buffering scheme.
This section describes a buffering scheme called IO-Lite that generalizes the fbuf ideas to include the file system. IO-Lite not only eliminates all redundant copies in Figure 5.2, but also eliminates redundant copying between the CGI process and the server. It also has a specialized buffer-numbering scheme that lets a subsystem (such as TCP) efficiently realize that it is resending an earlier packet.
IO-Lite is the intellectual descendant of fbufs, though integration with the file system adds significantly more complexity. It is first worth noting that fbufs cannot be combined with mmap, unlike TCOW, which is combined with mmap in Brustoloni [Bru99]. This is because in mmap the application picks the address and format of an application buffer, while in fbufs the kernel picks the address and format of a fast buffer. Thus if the application has mapped a file using a buffer in the application virtual address space, the buffer cannot be sent using an fbuf (kernel address space) without a physical copy.
Since fbufs cannot be combined with mmap, IO-Lite generalizes fbufs to include the file system, making mmap unnecessary. Also, IO-Lite is implemented in a a general-purpose operating system (UNIX), as opposed to fbufs. But setting aside these two differences, IO-Lite borrows all the main ideas from fbufs: the notion of read-only sharing via immutable buffers (called slices in IO lite), the use of composite buffers (called buffer aggregates), and the notion of a lazily created cache of buffers for a path (called an I/O stream in IO-Lite).
Despite the core similarities, IO-Lite requires solving difficult problems to integrate with the file system. First, IO-Lite must deal with complex sharing patterns, where several applications may have buffers pointing to the IO-Lite buffer together with the TCP code and the file server. Second, an IO-Lite page can be both a virtual memory page (backed up by the paging backup file on disk) and at the same time a file page (backed up by the actual disk copy of the file). Thus IO-Lite has to implement a complex replacement policy that integrates both the standard page replacement rules together with file cache replacement policies [PDZ99b]. Third, the goal of running over UNIX requires careful thought to find a clean way to integrate IO-Lite without major surgery throughout UNIX.
Figure 5.10 shows the steps in responding to the same GET request pictured in Figure 5.2. When the file is first read from disk into the file system cache, the file pages are stored as IO-Lite buffers. When the application makes a call to read the file, no physical copy is made, but a buffer aggregate is created with a pointer to the IO-Lite buffer. Next, when the application sends the file to TCP for transmission, the network system gets a pointer to the same IO-Lite pages. To prevent errors, the IO-Lite system keeps a reference count for each buffer and reallocates a buffer only when all users are done.

Figure 5.10 also shows two more optimizations. The application keeps a cache of HTTP responses for common files and can often simply append the standard response with minimal modifications. Second, every buffer is given a unique number (P12, add redundant state) by IO-Lite, and the TCP module keeps a cache of checksums indexed by buffer number. Thus when a file is transmitted multiple times, the TCP module can avoid calculating the checksum after the first time. Notice that these changes eliminate all the redundancy in Figure 5.2, which speeds up the processing of a response.
IO-Lite can also be used to implement a modified pipe program that eliminates copying. When this IPC mechanism is used between the CGI process and the server process, all copying is eliminated without compromising the safety and fault isolation provided by implementing the two programs as separate processes. IO-Lite can also allow applications to customize their buffer-caching strategy, allowing fancier caching strategies for Web servers based on both size and access frequency.
It is important to note that IO-Lite manages these performance feats without completely eliminating the UNIX kernel and without closely tying the application with the kernel. The Cheetah Web server [EKO95] built over the Exokernel operating system takes a more extreme position, allowing each application (including the Web server) to completely customize its network and file system. The Exokernel mechanisms allow such extreme customization from each application without compromising safety. By dint of these customiza- tions, the Cheetah Web server can eliminate all the copies in Figure 5.2 and also eliminate the TCP checksum calculation using a cache.
While Cheetah does allow some further tricks (see the Exercises), the enormous software engineering challenge of designing and maintaining custom kernels for each application makes approaches such as IO-Lite more attractive. IO-Lite comes close to the performance of customized kernels like Cheetah with a much smaller set of software engineering challenges.
5.4.3 Avoiding File System Copies via I/O Splicing
In the commercial world, Web servers are measured by commercial tests such as the SPECweb tests [Conb] for Web servers and the Web polygraph tests [Assb] for Web proxies. In the proxy space, there is an annual cache-off, in which all devices are measured together to calculate the highest cache hit rate, normalized to the price of the device. The SPECweb benchmarks use a different system, in which manufacturers submit their own experimental results to the benchmark system, though these results are audited. In the Web polygraph tests at the time of writing, a Web server technology based on I/O-Lite ideas was among the leaders.
However, in the SPECweb benchmarks, a number of other Web servers also show impressive performance. Part of the reason for this is just faster (and more expensive) hardware. However, there are two simple ideas that can avoid the need for complete model shifts as is the case in IO-Lite.
The first idea is to push the Web server application completely into the kernel. Thus in Figure 5.2, all copies can be eliminated because the application and the kernel are part of the same entity. The major problem with this approach is that such in-kernel Web servers have to deal with the idiosyncrasies of operating system implementation changes. For example, for a popular high-performance server that runs over Linux, every internal change to Linux can invalidate assumptions made by the server software and cause a crash. Note that a conventional user-space server does not have this problem because all changes to the UNIX implementation still preserve the API.
The second idea keeps the server application in user space but relies on a simple idea called I/O splicing to eliminate all the copying in Figure 5.2. I/O splicing, shown in Figure 5.11, was first introduced in Fall and Pasquale [FP93]. The idea is to introduce a new system call that combines the old call to read a file with the old call (P6, efficient specialized routines) to send a message to the network. By allowing the kernel to splice together these two hitherto-separate system calls, we can avoid all redundant copies. Many systems have system calls such as sendfile(), which are now used by several commercial vendors. Despite the success of this mechanism, mechanisms based on sendfile do not generalize well to communication with CGI processes.

5.5 BROADENING BEYOND COPIES
Clark and Tennehouse, in a landmark paper, suggested generalizing Van Jacobson’s idea (described earlier) of integrating checksums and copying. In more detail, the Jacobson idea is based on the following observation. When copying a packet word from a location (say, W10 in adaptor memory in Figure 5.12) to a location in memory (say, M9 in memory in Figure 5.12), the processor has to load W10 into a register and then store that register to M9. Typically, most RISC processors require that, between a load and a store, the compiler insert a so-called delay slot, or empty cycle, to keep the pipeline working correctly (never mind why!). That empty cycle can be used for other computation. For example, it can be used to add the word just read to a register that holds the current checksum. Thus with no extra cost the copy loop can often be augmented to be the checksum loop as well.

But there are other data-intensive manipulations, such as encrypting data and doing format conversions. Why not, Clark and Tennehouse [CT90] argued, integrate all such manipulations into the copy loop? For example, in Figure 5.12 the CPU could read W10 and then decrypt W10 and write the decrypted word to M9 rather than have that done in another loop. They called this idea integrated layer processing, or ILP. The essential idea is to avoid obvious waste (P1), in terms of reading (and possibly) writing the bytes of a packet several times for multiple data-manipulation operations on the same packet.
Thus ILP is a generalization of copy-checksum integration to other manipulations (e.g., encryption, presentation formatting). However, it has several challenges.
• Challenge 1: Information needed for manipulations is typically at different layers (e.g., encryption is at the application layer, and checksumming is done at the TCP layer). Integrating the code from different layers without sacrificing modularity is hard.
• Challenge 2: Each manipulation may operate on different-size chunks and different portions of the packet. For example, TCP works in 16-bit quantities for a 16-bit checksum, while the popular DES encryption works in 64-bit quantities. Thus while working with one 32-bit word, the ILP loop has to deal with two TCP checksum words and half a DES word.
• Challenge 3: Some manipulations may be dependent on each other. For example, one should probably not decrypt a packet if the TCP checksum fails.
• Challenge 4: ILP can increase cache miss rate because it can reduce locality within a single manipulation. If we did TCP separately and DES separately instead of in a single loop, the code we’d use at each instant is smaller for the two single loops as opposed to the single loop. This makes it more likely that the code will be found in the instruction cache in the more naive implementation. Increasing integration beyond a certain point can destroy code locality so much that it may even have adverse effects. Some studies have shown this to be a major issue.
The first three challenges show that ILP is hard to do. The fourth challenge suggests that integrating more than a few operations can possibly even reduce performance. Finally, if the packet data is used multiple times, it could well reside in the data cache (even in a naive implementation), making all the bother about integrating loops unnecessary. Possibly for these reasons, ILP has remained a tantalizing idea. Beyond the copy-checksum combination, there has been little follow-up work in integrating other manipulations in academic or commercial systems.
5.6 BROADENING BEYOND DATA MANIPULATIONS
So far this chapter has concentrated on reducing the memory (and bus) bandwidth caused by data-manipulation operations. First, we concentrated on removing redundant data copying between the network and the application. Second, we addressed redundant copying between the file system, the application, and the network. Third, we looked at removing redundant memory reads and writes using integrated layer processing when several data-manipulation operations operate over the same packet. What is common to all these techniques is an attempt to reduce pressure on the memory and the I/O bus by avoiding redundant reads and writes.
But once this is done, there are still other sources of pressure that appear within an endnode architecture as shown in Figure 5.2. This is alluded to in the following excerpt from e-mail sent after the alpha release of a fast user-level Linux Web server [Ric01]:
With zero-copy sendfile, data movement is not an issue anymore, asynchronous network IO allows for really inexpensive thread scheduling, and system call invocation adds a very negligible overhead in Linux. What we are left with now is purely wait cycles, the CPUs and the NICs are contending for memory and bus bandwidth.
In essence, once the first-order effects (such as eliminating copies) are taken care of, performance can be improved only by paying attention to what might be thought of as second-order effects. The next two subsections discuss two such architectural effects that greatly impact the use of bus and memory bandwidth: the effective use of caches and the choice of DMA versus PIO.
5.6.1 Using Caches Effectively
The architectural model of Figure 5.2 avoids two important details that were described in Chapter 2. Recall that the processor keeps one or more data caches (d-caches), and one or more instruction caches (I-caches). The data cache is a table that maps from memory addresses to data contents; if there are repeated reads and writes to the same location L in memory and L is cached, then these reads and writes can be served directly out of the data cache without incurring bus or memory bandwidth. Similarly, recall that programs are stored in memory; every line of code executed by the CPU has to be fetched from main memory unless it is cached in the instruction cache.
Now, packet data benefits little from a data cache, for there is little reuse of the data and copying involves writing to a new memory address, as opposed to repeated reads and writes from the same memory address. Thus the techniques already discussed to reduce copies are useful, despite the presence of a large processor data cache. However, there are two other items stored in memory that can benefit from caches. First, the program executing the protocol code to process a packet must be fetched from memory, unless it is stored in the I-cache. Second, the state required to process a packet (e.g., TCP connection state tables) must be fetched from memory, unless it is stored in the d-cache.
Of these two other possible contenders for memory bandwidth, the code to be executed is potentially a more serious threat. This is because the state, in bytes, required to process a packet (say, one connection table entry, one routing table entry) is generally small. However, for a small, 40-byte packet, even this can be significant. Thus avoiding the use of redundant state (which tends to pollute the d-cache) wherever possible can improve performance, as was described in Problem 11 of Chapter 4.
However, the code required to execute all of the networking stack (Data Link, TCP, IP, socket layer, and kernel entry and exit) can be much larger. For example, measurements in Blackwell [Bla96] show a total code size of 34 KB using a 1995 NetBSD TCP implementation. Given that even large packets on an Ethernet are at most 1.5 KB, the effort to load the code from memory can easily dwarf the effort to copy the packet multiple times.
In particular, if the I-cache is 8 KB (typical for older machines, such as the early Alpha machines used in Blackwell [Bla96]), this means that at most a quarter of the networking stack can fit in the cache. This in turn could imply that all or most of the code has to be fetched from memory every time a packet needs to be processed. Modern machines have not improved their I-cache sizes significantly. The Pentium III uses 16 KB. Thus effective use of the I-cache could be a key to improved performance, especially for small packets.
We now describe two techniques that can be used to improve I-cache effectiveness: code arrangement and locality-driven-layer processing.
CODE ARRANGEMENT
It is hard to realize when one is writing networking code that the actual layout of code in memory (and hence in the I-cache) is a degree of freedom that can be exploited (P13) with some effort. The key idea in code arrangement [MPBM96] is to lay out code in memory to optimize the common case (P11) such that commonly used code fits in the I-cache and the effort of loading the I-cache is not wasted.
At first glance, this seems to require no extra work. Since a cache should favor frequently used code over infrequently used code, this should happen automatically. Unfortunately, this is incorrect because of the following two aspects of the way I-caches are implemented.
• Direct mapping: An I-cache is a mapping of memory addresses to contents; the mapping is usually implemented by a simple hash function that optimizes for the case of sequential access. Thus most processors use direct-mapped I-caches, where the low-order bits of a memory address are used to index the I-cache array. If the high-order bits match, the contents are returned directly from cache; otherwise, a Read to memory is done across the bus, and the new data value and high-order bits are stored in the same location.
Figure 5.13 shows the effect of this implementation artifact. The figure on the left shows the memory layout of code for two networking functions, with black code denoting infrequently used code. Since the I-cache size is only half the total size of the code, it is possible for two frequently accessed lines of code (such as X and Y, with addresses that are the same modulo the I-cache size) to map to the same location in the I-cache. Thus if both X and Y are used to process every packet, they will keep evicting each other from the cache even though they are both frequently used.

• Multiple instructions per block: Many I-caches can be thought of as an array of blocks, where multiple instructions (say, eight) are stored in a block. Thus when an instruction is fetched, all eight instructions in the same block are also fetched on the assumption of spatial locality: With sequential access, it seems probable that the other seven instructions will also be fetched, and it is cheaper to read multiple instructions from memory at the same time.
Unfortunately, much of networking code contains error checks such as “If error E do X, else do Z.” Z is hardly ever executed, but a compiler will often arrange the code for Z immediately after X. For example, in Figure 5.13 imagine that code for Z immediately follows X. If X and Z fall in the same block of eight instructions, then fetching frequently accessed X also results in fetching infrequently used Z. This makes loading the cache less efficient (more useless work) and makes the cache less useful after loading (less useful code in cache).
Note that both of these effects are caused by the fact that real caches imperfectly reflect temporal locality. The first is caused by an imperfect hash function that can cause collisions between two frequently used addresses. The second is caused by the fact that the cache also optimizes for spatial locality.
Both effects can be mitigated by reorganizing networking code [MPBM96] so that all frequently used code is contiguous (see right of Figure 5.13). For example, in the case “If error E do X, else do Z,” the code for Z can be moved far away from X. This does require an extra jump instruction to be added to the code for Z so that it can jump back to the code that followed Z in the unoptimized version. However, this extra jump is taken only in the error case, and so it is not much of a cost.
This is an example of realizing that the memory location of code is a degree of freedom that can be optimized (P13) and an example of optimizing the expected case (P11) despite increasing the code path for infrequently used code.
LOCALITY-DRIVEN LAYER PROCESSING
Code reorganization can help up to a point but fails if the working set (i.e., the set of instructions actually accessed for almost every packet) exceeds the I-cache size. For example, in Figure 5.13, if the size of the white, frequently used instructions is larger than the I-cache, code reorganization will still help (fewer loads from memory are required because each load loads only useful instructions). However, every instruction will still have to be fetched from memory.
While the working set of the networking stack may fit into a modern I-cache (which is getting bigger), it is possible that more complicated protocols (that run over TCP/IP) may not. The idea behind locality-driven layer processing [Bla96] is to be able to use the I-cache effectively as long as the code for each layer of the networking stack fits into the I-cache. By repeatedly processing the code for the same layer across multiple packets, the expense of loading the I-cache is shared (P2c) over multiple packets.
Consider the top timeline in Figure 5.14. In a conventional processing timeline (shown from left to right in the figure), all the networking layers of packet P1 are processed before those of packet P2. Imagine that two packets P1 and P2 arrive at a server. In a conventional implementation, all the processing of P1 is finished, starting with the data link layer (e.g., Ethernet driver) and ending with the transport (e.g., TCP) layer. Only then is the processing of packet P2 started.

The main idea in locality-driven processing is to exploit another degree of freedom (P13) and to process all the layer code for as many received packets as possible before moving on to the next layer. Thus in the bottom timeline, after the data link layer code for P1 is finished, the CPU moves on to execute the data link layer code for P2, not the network layer code for P1. This should not affect correctness because code for a layer should not depend on the state of lower layers. By contrast, integrated layer processing has more subtle dependencies and failure cases.
Thus if the code for each layer (e.g., the data link layer) fits into the I-cache while the code for all layers does not, then this optimization amortizes the cost of loading the I-cache over multiple packets. This is effectively using batch processing (P2c, expense sharing). The larger the size of the batch, the more effective the use of the I-cache.
The implementation can be made to tune the size of the batch dynamically [Bla96]. The code can batch-process up to, say, k packets from the queue of arrived packets, where k is a parameter that limits the latency. If the system is lightly loaded, then only one message at a time will be processed. On the other hand, if the system is heavily loaded, the batch size increases to make more effective use of memory bandwidth when it is most needed.
SOFTWARE ENGINEERING CONSIDERATIONS
Optimizations such as code restructuring (Figure 5.13) and locality-driven processing (Figure 5.14) also need to be evaluated by their effects on code modularity and maintenance. After all, one could rewrite the kernel and all applications using assembly language to more perfectly optimize for memory bandwidth. But it would be difficult to get the code to work or be maintainable.
Code restructuring is best done by a compiler. For example, error-handling code can be annotated with hints [MPBM96] suggesting which branches are more frequently taken (generally obvious to the programmer), and a specially augmented compiler can restructure the code for I-cache locality. Algorithms for this purpose are described in Mosberger et al. [MPBM96].
On the other hand, locality-driven processing preserves modularity within layers. Communication between layers must be changed as follows. If each layer code passes a packet to the code for a higher layer with a procedure call, this code must be modified to add packets to a queue for the higher layer. Similarly, when a layer is called, it removes packets from its read queue until the queue is exhausted; after processing each packet, it places it on the queue for its next-higher layer. This strategy works well when each layer can reuse buffers from other layers, as is the case for UNIX mbufs. Overall, the code changes may not be severe.
5.6.2 Direct Memory Access versus Programmed I/O
Earlier sections stated that the Witless scheme uses programmed I/O, or PIO (i.e., the processor or CPU is involved on every word transferred between memory and adaptor), while other schemes, such as VAX Clusters, use DMA (where the adaptor copies data directly to memory). It may seem that DMA is always better than PIO. However, comparisons between DMA and PIO are tricky because each method has subtle implications for the overall memory bandwidth used.
For instance, PIO has one advantage in that the data flows through the processor and thus ends up in the processor cache. This can be useful to prevent loss of memory bandwidth for subsequent access. Also, with PIO it is easy to integrate other functions, such as checksums, without requiring adaptor hardware to do the same function.
However, some studies have shown that if data arrives and is used much later (e.g., one scheduling quantum later) by the application, then placing data in the d-cache too early is wasteful of the d-cache and lowers rather than raises d-cache hit rate. On the other hand, DMA can steal cycles from the CPU and also requires some careful cache invalidation when data is written into a memory location (that could also be cached). So the jury is still out. The choice between the two is best decided on a case-by-case basis, taking into account architectural considerations and the application at hand. A more detailed study of the issues involved can be found in Mogul and Ramakrishnan [MR97].
5.7 CONCLUSIONS
As networks get faster, links today, such as Gigabit Ethernet, are often faster than the buses and memories within desktop computers and servers. Thus memory and bus bandwidth are crucial resources. This chapter describes techniques to optimize the use of memory and bus bandwidth for processing IP and Web packets, the dominant traffic streams found today in the Internet.
To this end, the chapter started by showing how to remove redundant copies involved in processing an IP packet using adaptor memory or virtual memory remapping. We then showed how to remove redundant copies involved in processing Web requests at a server by generalizing virtual memory remapping to include the file system or by combining file system and network I/O in a single system call. We then showed how to combine various data manipulations in one fell swoop. All of these techniques require changes to the application and kernel, but the changes are fairly localized and mostly preserve modularity.
We finally showed that, without care, protocol processing can dwarf copy overhead, and we described techniques to optimize the instruction cache. Comments such as Riccardi’s [Ric01] indicate that modern Web servers may already be optimized for zero-copy implementations using sendfile()-style system calls. However, Riccardi [Ric01] indicates that such servers still burn processor cycles waiting for memory. Thus, techniques to improve I-cache efficiency may provide the next round of optimizations for Web servers. Figure 5.1 presents a summary of the techniques used in this chapter, together with the major principles involved.
It is important to state that all the performance problems involved in building a modern Web server have not been eliminated. Complex Web sites, such as amazon.com, often use several tiers of processing to respond to Web requests, including an application server, a Web server, and a database server. Such database-driven Web servers introduce new bottlenecks that may require new techniques beyond those described in this chapter. However, the underlying principles should hopefully remain the same.
In terms of principles, this chapter is about the repeated use of P1 avoiding obvious waste, where the waste is unnecessary reads and writes that consume precious memory and bus bandwidth. At first glance, principle P1 seems vacuous or at best a cliché. What makes this principle deeper is that the waste is not apparent unless one broadens one’s vision to see as much of the system as possible.
Within each local subsystem (e.g., application to kernel, kernel to network, disk to file system) there is no wasted memory bandwidth. It is only when one follows the adventures of a received packet that one discovers the redundancy between application-to-kernel and kernel-to-network copies. It is only when one broadens one’s view even further to see the contortions involved in responding to a Web request that one notices the further redundancies involving the file system. Only when one broadens one’s view further still does one see all the manipulations involved in processing a packet and the wasted reads to memory. Finally, it is only when one examines the loading of instructions that one sees the alarming possibility that the protocol code can be several times larger than the packet size.
Thus the use of the first principle of network algorithmics requires a synoptic eye, one that sees the whole system, from HTTP and its headers, to the file system, and down to the instruction caches. While this seems daunting in complexity, Chapter 2 has already argued that simple models of hardware, architecture, operating systems, and protocols can make such a holistic viewpoint possible. For example, I-caches have a number of complex variants, but a simple model of a direct-mapped I-cache with multiple instructions per block is not hard for an operating system designer to keep in mind.
Finally, compared to the beauty and complexity of theoretical techniques such as the ellipsoid algorithm for linear programming and the theory of rapidly mixing Markov chains, techniques in systems such as copy avoidance seem drab and shallow. However, one can argue that the complexity of systems is not in depth (i.e., the complexity of each component by itself) but in breadth (i.e., the complex relationships between components). Perhaps the breadth of understanding (HTTP, file system, networking code, instruction cache implementation) required to optimize memory bandwidth in a Web server provides some evidence for this thesis.
5.8 EXERCISES
1. Data caches and copies: A normal data cache is a mapping from a memory location address to a piece of content. If the content is frequently accessed, then the content can be accessed directly from the fast cache instead of making a memory access. Assuming the cache is a write-back cache, even writes can be written to the cache instead of memory and only written to memory when the cache is overwritten. A modern cache block is fairly large (128 bits), with a mapping from a 32-bit address to 128 bits of data starting at that address.
We want to address the copying problem where various modules (including the network and file system) copy data via intermediate buffers that are soon overwritten (e.g., socket buffer, application buffer). The chapter did so with software changes. Here we consider whether changing the hardware architecture can help without software changes such as IO-Lite, fbufs, and mmap.
• Even an ordinary data cache may help remove some of the overhead when copying data from location L to location M. Explain why. (Assume that location M is a temporary buffer that is soon overwritten, as in a socket buffer. Assume that if only a single word is written in a large cache block, the remaining words can be marked invalid.) Intuitively, this problem is asking whether there is an equivalent of copy-on-write (used to reduce copying between virtual address spaces) in the world of data caches.
• Now assume a different data cache design, where a cache is a mapping from one or more addresses to the same content. Thus a cache has changed from a one-to-one mapping to a many-to-one mapping. For example, assume a cache where two locations can point to the same content. Thus a cache entry may be (L, M, C), where L and M are addresses and C is the common contents of L and M. A memory access to either L or M will return C. What is the advantage over the previous scheme in the previous item?
• This is all very speculative and wild. Comment on the disadvantages of the idea in the previous item. In particular, many caches use a technique called set associativity, where a simple hash function (e.g., low-order bits) is used to select a small set of cache entries that the hardware searches in parallel. Why might the multiple address per cache entry interact poorly with the set associative search?
2. Application-level optimizations for Web servers: Operating systems such as the Exokernel [EKO95] take an even more extreme viewpoint and allow the application to customize kernel features for its benefit without compromising safety for other applications. One interesting optimization is to combine the final TCP FIN with the read of the last data segment (an optimization allowed by TCP).
• Why does this optimization help small Web transfers (which are quite common)?
• Why is this optimization hard to do in a regular Web server, and why is it easier if the application is integrated with the kernel, as in the Exokernel?
• Explain how this optimization can be migrated to an ordinary Web server by passing information across the interface (P9) without compromising safety.
3. Reverse copyout: The emulated copy-on-write paper [BS96] describes an interesting degree of freedom (P13) for copying page-aligned data between two modules (say, system and application). Imagine that you wish to copy a partial page from an application page, X, to a system page, Y. If the page is full, assume that you can swap the two pages efficiently. Assume the partial page has useful data D and some remainder R.
• If the amount of data D is small compared to R, it is simpler to copy D to the destination page in Y. On the other hand, if D is large (say, almost all of the page) compared to R, devise a simple strategy to minimize copying. Note that if the destination page, Y, has some other data in the remainder of the page, that data must remain after the copy.
• What is a simple threshold you would use to choose between these two strategies?