
Introducing Network Algorithmics
What really makes it an invention is that someone decides not to change the solution to a known problem, but to change the question.
—DEAN KAMEN
Just as the objective of chess is to checkmate the opponent and the objective of tennis is to win matches, the objective of the network algorithmics game is to battle networking implementation bottlenecks.
Beyond specific techniques, this book distills a fundamental way of crafting solutions to internet bottlenecks that we call network algorithmics. This provides the reader tools to design different implementations for specific contexts and to deal with new bottlenecks that will undoubtedly arise in the changing world of networks.
So what is network algorithmics? Network algorithmics goes beyond the design of efficient algorithms for networking tasks, though this has an important place. In particular, network algorithmics recognizes the primary importance of taking an interdisciplinary systems approach to streamlining network implementations.
Network algorithmics is an interdisciplinary approach because it encompasses such fields as architecture and operating systems (for speeding up servers), hardware design (for speeding up network devices such as routers), and algorithm design (for designing scalable algorithms). Network algorithmics is also a systems approach, because it is described in this book using a set of 15 principles that exploit the fact that routers and servers are systems, in which efficiencies can be gained by moving functions in time and space between subsystems.
The problems addressed by network algorithmics are fundamental networking performance bottlenecks. The solutions advocated by network algorithmics are a set of fundamental techniques to address these bottlenecks. Next, we provide a quick preview of both the bottlenecks and the methods.
1.1 THE PROBLEM: NETWORK BOTTLENECKS
The main problem considered in this book is how to make networks easy to use while at the same time realizing the performance of the raw hardware. Ease of use comes from the use of powerful network abstractions, such as socket interfaces and prefix-based forwarding. Unfortunately, without care such abstractions exact a large performance penalty when compared to the capacity of raw transmission links such as optical fiber. To study this performance gap in more detail we examine two fundamental categories of networking devices, endnodes and routers.
1.1.1 Endnode Bottlenecks
Endnodes are the endpoints of the network. They include personal computers and workstations as well as large servers that provide services. Endnodes are specialized toward computation, as opposed to networking, and are typically designed to support general-purpose computation. Thus endnode bottlenecks are typically the result of two forces: structure and scale.
• Structure: To be able to run arbitrary code, personal computers and large servers typically have an operating system that mediates between applications and the hardware. To ease software development, most large operating systems are carefully structured as layered software; to protect the operating system from other applications, operating systems implement a set of protection mechanisms; finally, core operating systems routines, such as schedulers and allocators, are written using general mechanisms that target as wide a class of applications as possible. Unfortunately, the combination of layered software, protection mechanisms, and excessive generality can slow down networking software greatly, even with the fastest processors.
• Scale: The emergence of large servers providing Web and other services causes further performance problems. In particular, a large server such as a Web server will typically have thousands of concurrent clients. Many operating systems use inefficient data structures and algorithms that were designed for an era when the number of connections was small.
Figure 1.1 previews the main endnode bottlenecks covered in this book, together with causes and solutions. The first bottleneck occurs because conventional operating system structures cause packet data copying across protection domains; the situation is further complicated in Web servers by similar copying with respect to the file system and by other manipulations, such as checksums, that examine all the packet data. Chapter 5 describes a number of techniques to reduce these overheads while preserving the goals of system abstractions, such as protection and structure. The second major overhead is the control overhead caused by switching between threads of control (or protection domains) while processing a packet; this is addressed in Chapter 6.
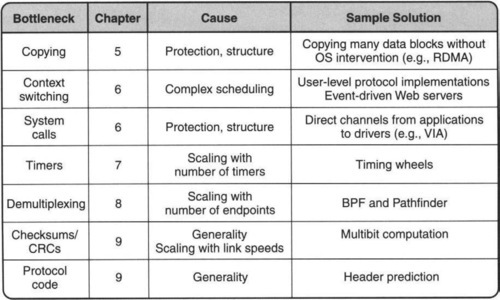
Networking applications use timers to deal with failure. With a large number of connections the timer overhead at a server can become large; this overhead is addressed in Chapter 7. Similarly, network messages must be demultiplexed (i.e., steered) on receipt to the right end application; techniques to address this bottleneck are addressed in Chapter 8. Finally, there are several other common protocol processing tasks, such as buffer allocation and checksums, which are addressed in Chapter 9.
1.1.2 Router Bottlenecks
Though we concentrate on Internet routers, almost all the techniques described in this book apply equally well to any other network devices, such as bridges, switches, gateways, monitors, and security appliances, and to protocols other than IP, such as FiberChannel.
Thus throughout the rest of the book, it is often useful to think of a router as a “generic network interconnection device.” Unlike endnodes, these are special-purpose devices devoted to networking. Thus there is very little structural overhead within a router, with only the use of a very lightweight operating system and a clearly separated forwarding path that often is completely implemented in hardware. Instead of structure, the fundamental problems faced by routers are caused by scale and services.
• Scale: Network devices face two areas of scaling: bandwidth scaling and population scaling. Bandwidth scaling occurs because optical links keep getting faster, as the progress from 1-Gbps to 40-Gbps links shows, and because Internet traffic keeps growing due to a diverse set of new applications. Population scaling occurs because more endpoints get added to the Internet as more enterprises go online.
• Services: The need for speed and scale drove much of the networking industry in the 1980s and 1990s as more businesses went online (e.g., Amazon.com) and whole new online services were created (e.g., Ebay). But the very success of the Internet requires careful attention in the next decade to make it more effective by providing guarantees in terms of performance, security, and reliability. After all, if manufacturers (e.g., Dell) sell more online than by other channels, it is important to provide network guarantees —delay in times of congestion, protection during attacks, and availability when failures occur. Finding ways to implement these new services at high speeds will be a major challenge for router vendors in the next decade.
Figure 1.2 previews the main router (bridge/gateway) bottlenecks covered in this book, together with causes and solutions.
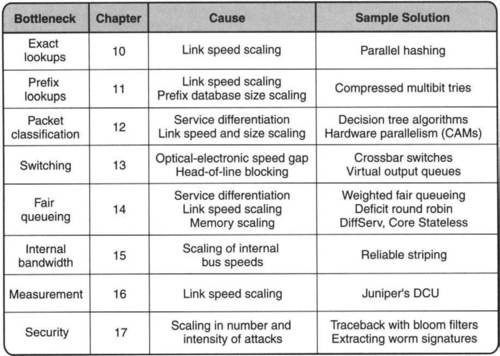
First, all networking devices forward packets to their destination by looking up a forwarding table. The simplest forwarding table lookup does an exact match with a destination address, as exemplified by bridges. Chapter 10 describes fast and scalable exact-match lookup schemes. Unfortunately, population scaling has made lookups far more complex for routers.
To deal with large Internet populations, routers keep a single entry called a prefix (analogous to a telephone area code) for a large group of stations. Thus routers must do a more complex longest-prefix-match lookup. Chapter 11 describes solutions to this problem that scale to increasing speeds and table sizes.
Many routers today offer what is sometimes called service differentiation, where different packets can be treated differently in order to provide service and security guarantees. Unfortunately, this requires an even more complex form of lookup called packet classification, in which the lookup is based on the destination, source, and even the services that a packet is providing. This challenging issue is tackled in Chapter 12.
Next, all networking devices can be abstractly considered as switches that shunt packets coming in from a set of input links to a set of output links. Thus a fundamental issue is that of building a high-speed switch. This is hard, especially in the face of the growing gap between optical and electronic speeds. The standard solution is to use parallelism via a crossbar switch. Unfortunately, it is nontrivial to schedule a crossbar at high speeds, and parallelism is limited by a phenomenon known as head-of-line blocking. Worse, population scaling and optical multiplexing are forcing switch vendors to build switches with a large number of ports (e.g., 256), which exacerbates these other problems. Solutions to these problems are described in Chapter 13.
While the previous bottlenecks are caused by scaling, the next bottleneck is caused by the need for new services. The issue of providing performance guarantees at high speeds is treated in Chapter 14, where the issue of implementing so-called QoS (quality of service) mechanisms is studied. Chapter 15 briefly surveys another bottleneck that is becoming an increasing problem: the issue of bandwidth within a router. It describes sample techniques, such as striping across internal buses and chip-to-chip links.
The final sections of the book take a brief look at emerging services that must, we believe, be part of a well-engineered Internet of the future. First, routers of the future must build in support for measurement, because measurement is key to engineering networks to provide guarantees. While routers today provide some support for measurement in terms of counters and NetFlow records, Chapter 16 also considers more innovative measurement mechanisms that may be implemented in the future.
Chapter 17 describes security support, some of which is already being built into routers. Given the increased sophistication, virulence, and rate of network attacks, we believe that implementing security features in networking devices (whether routers or dedicated intrusion prevention/detection devices) will be essential. Further, unless the security device can keep up with high-speed links, the device may miss vital information required to spot an attack.
1.2 THE TECHNIQUES: NETWORK ALGORITHMICS
Throughout this book, we will talk of many specific techniques: of interrupts, copies, and timing wheels; of Pathfinder and Sting; of why some routers are very slow; and whether Web servers can scale. But what underlies the assorted techniques in this book and makes it more than a recipe book is the notion of network algorithmics. As said earlier, network algorithmics recognizes the primary importance of taking a systems approach to streamlining network implementations.
While everyone recognizes that the Internet is a system consisting of routers and links, it is perhaps less obvious that every networking device, from the Cisco GSR to an Apache Web server, is also a system. A system is built out of interconnected subsystems that are instantiated at various points in time. For example, a core router consists of line cards with forwarding engines and packet memories connected by a crossbar switch. The router behavior is affected by decisions at various time scales, which range from manufacturing time (when default parameters are stored in NVRAM) to route computation time (when routers conspire to compute routes) to packet-forwarding time (when packets are sent to adjoining routers).
Thus one key observation in the systems approach is that one can often design an efficient subsystem by moving some of its functions in space (i.e., to other subsystems) or in time (i.e., to points in time before or after the function is apparently required). In some sense, the practitioner of network algorithmics is an unscrupulous opportunist willing to change the rules at any time to make the game easier. The only constraint is that the functions provided by the overall system continue to satisfy users.
In one of Mark Twain’s books, a Connecticut Yankee is transported back in time to King Arthur’s court. The Yankee then uses a gun to fight against dueling knights accustomed to jousting with lances. This is an example of changing system assumptions (replacing lances by guns) to solve a problem (winning a duel).
Considering the constraints faced by the network implementor at high speeds — increasingly complex tasks, larger systems to support, small amounts of high-speed memory, and a small number of memory accesses — it may require every trick, every gun in one’s arsenal, to keep pace with the increasing speed and scale of the Internet. The designer can throw hardware at the problem, change the system assumptions, design a new algorithm — whatever it takes to get the job done.
This book is divided into four parts. The first part, of which this is the first chapter, lays a foundation for applying network algorithmics to packet processing. The second chapter of the first part outlines models, and the third chapter presents general principles used in the remainder of the book.
One of the best ways to get a quick idea about what network algorithmics is about is to plunge right away into a warm-up example. While the warm-up example that follows is in the context of a device within the network where new hardware can be designed, note that Part 2 is about building efficient servers using only software design techniques.
1.2.1 Warm-up Example: Scenting an Evil Packet
Imagine a front-end network monitor (or intrusion detection system) on the periphery of a corporate network that wishes to flag suspicious incoming packets — packets that could contain attacks on internal computers. A common such attack is a buffer overflow attack, where the attacker places machine code C in a network header field F.
If the receiving computer allocates a buffer too small for header field F and is careless about checking for overflow, the code C can spill onto the receiving machine’s stack. With a little more effort, the intruder can make the receiving machine actually execute evil code C. C then takes over the receiver machine. Figure 1.3 shows such an attack embodied in a familiar field, a destination Web URL (uniform resource locator). How might the monitor detect the presence of such a suspicious URL? A possible way is to observe that URLs containing evil code are often too long (an easy check) and often have a large fraction of unusual (at least in URLs) characters, such as #. Thus the monitor could mark such packets (containing URLs that are too long and have too many occurrences of such unusual characters) for more thorough examination.
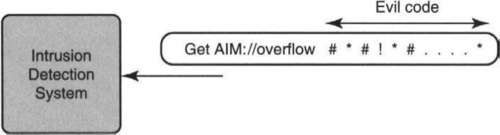
It is worth stating at the outset that the security implications of this strategy need to be carefully thought out. For example, there may be several innocuous programs, such as CGI scripts, in URLs that lead to false positives. Without getting too hung up in overall architectural implications, let us assume that this was a specification handed down to a chip architect by a security architect. We now use this sample problem, suggested by Mike Fisk, to illustrate algorithmics in action.
Faced with such a specification, a chip designer may use the following design process, which illustrates some of the principles of network algorithmics. The process starts with a strawman design and refines the design using techniques such as designing a better algorithm, relaxing the specification, and exploiting hardware.
1.2.2 Strawman Solution
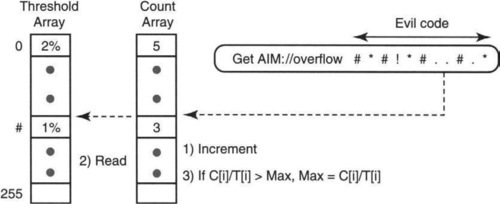
The check of overall length is straightforward to implement, so we concentrate on checking for a prevalence of suspicious characters. The first strawman solution is illustrated in Figure 1.4. The chip maintains two arrays, T and C, with 256 elements each, one for each possible value of an 8-bit character. The threshold array, T, contains the acceptable percentage (as a fraction of the entire URL length) for each character. If the occurrences of a character in an actual URL fall above this fraction, the packet should be flagged. Each character can have a different threshold.
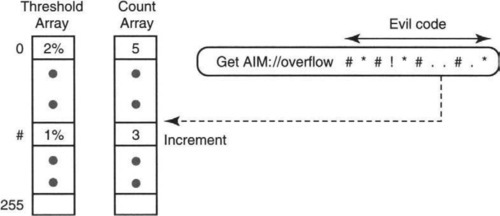
The count array, C, in the middle, contains the current count C[i] for each possible character i. When the chip reads a new character “i” in the URL, it increments C[i] by 1. C[i] is initialized to 0 for all values of i when a new packet is encountered. The incrementing process starts only after the chip parses the HTTP header and recognizes the start of a URL.
In HTTP, the end of a URL is signified by two newline characters; thus one can tell the length of the URL only after parsing the entire URL string. Thus, after the end of the URL is encountered, the chip makes a final pass over the array C. If C[j] ≥ L · T[j] for any j, where L is the length of the URL, the packet is flagged.
Assume that packets are coming into the monitor at high speed and that we wish to finish processing a packet before the next one arrives. This requirement, called wire speed processing, is very common in networking; it prevents processing backlogs even in the worst case. To meet wire speed requirements, ideally the chip should do a small constant number of operations for every URL byte. Assume the main step of incrementing a counter can be done in the time to receive a byte.
Unfortunately, the two passes over the array, first to initialize it and then to check for threshold violations, make this design slow. Minimum packet sizes are often as small as 40 bytes and include only network headers. Adding 768 more operations (1 write and 1 read to each element of C, and 1 read of T for each of 256 indices) can make this design infeasible.
1.2.3 Thinking Algorithmically
Intuitively, the second pass through the arrays C and T at the end seems like a waste. For example, it suffices to alarm if any character is over the threshold. So why check all characters? This suggests keeping track only of the largest character count c; at the end perhaps the algorithm needs to check only whether c is over threshold with respect to the total URL length L.
This does not quite work. A nonsuspicious character such as “e” may well have a very high occurrence count. However, “e” is also likely to be specified with a high threshold. Thus if we keep track only of “e” with, say, a count of 20, we may not keep track of “#” with, say, a count of 10. If the threshold of “#” is much smaller, the algorithm may cause a false negative: The chip may fail to alarm on a packet that should be flagged.
The counterexample suggests the following fix. The chip keeps track in a register of the highest counter relativized to the threshold value. More precisely, the chip keeps track of the highest relativized counter Max corresponding to some character k, such that C[k]/T[k] = Max is the highest among all characters encountered so far. If a new character i is read, the chip increments C[i]. If C[i]/T[i] > Max, then the chip replaces the current stored value of Max with C[i]/T[i]. At the end of URL processing, the chip alarms if Max ≥ L.
Here’s why this works. If Max = C[k]/T[k] ≥ L, clearly the packet must be flagged, because character k is over threshold. On the other hand, if C[k]/T[k] < L, then for any character i, it follows that C[i]/T[i] ≤ C[k]/T[k] < L. Thus if Max falls below threshold, then no character is above threshold. Thus there can be no false negatives. This solution is shown in Figure 1.5.
1.2.4 Refining the Algorithm: Exploiting Hardware
The new algorithm has eliminated the loop at the end but still has to deal with a divide operation while processing each byte. Divide logic is somewhat complicated and worth avoiding if possible — but how?
Returning to the specification and its intended use, it seems likely that thresholds are not meant to be exact floating point numbers. It is unlikely that the architect providing thresholds can estimate the values precisely; one is likely to approximate 2.78% as 3% without causing much difference to the security goals. So why not go further and approximate the threshold by some power of 2 less than the exact intended threshold? Thus if the threshold is 1/29, why not approximate it as 1/32?
Changing the specification in this way requires negotiation with the system architect. Assume that the architect agrees to this new proposal. Then a threshold such as 1/32 can be encoded compactly as the corresponding power of 2 — i.e., 5. This threshold shift value can be stored in the threshold array instead of a fraction.
Thus when a character j is encountered, the chip increments C[j] as usual and then shifts C[j] to the left — dividing by 1/x is the same as multiplying by x — by the specified threshold. If the shifted value is higher than the last stored value for Max, the chip replaces the old value with the new value and marches on.
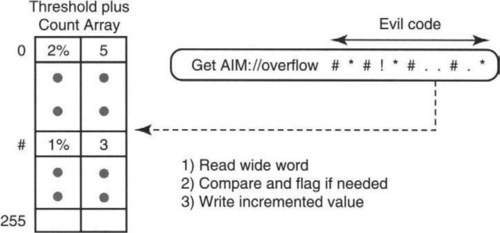
Thus the logic required to implement the processing of a byte is a simple shift-and-compare. The stored state is only a single register to store Max. As it stands, however, the design requires a Read to the Threshold array (to read the shift value), a Read to the Count array (to read the old count), and a Write to the Count array (to write back the incremented value).
Now reads to memory — 1–2 nsec even for the fastest on-chip memories but possibly even as slow as 10 nsec for slower memories — are slower than logic. Single gate delays are only in the order of picoseconds, and shift logic does not require too many gate delays. Thus the processing bottleneck is the number of memory accesses.
The chip implementation can combine the 2 Reads to memory into 1 Read by coalescing the Count and Threshold arrays into a single array, as shown in Figure 1.6. The idea is to make the memory words wide enough to hold the counter (say, 15 bits to handle packets of length 32K) and the threshold (depending on the precision necessary, no more than 14 bits). Thus the two fields can easily be combined into a larger word of size 29 bits. In practice, hardware can handle much larger words sizes of up to 1000 bits. Also, note that extracting the two fields packed into a single word, quite a chore in software, is trivial in hardware by routing wires appropriately between registers or by using multiplexers.
1.2.5 Cleaning Up
We have postponed one thorny issue to this point. The terminal loop has been eliminated while leaving the initial initialization loop. To handle this, note that the chip has spare time for initialization after parsing the URL of the current packet and before encountering the URL of the next packet.
Unfortunately, packets can be as small as 50 bytes, even with an HTTP header. Thus even assuming a slack of 40 non-URL bytes other than the 10 bytes of the URL, this still does not suffice to initialize a 256-byte array without paying 256/40 = 6 more operations per byte than during the processing of a URL. As in the URL processing loop, each initialization step requires a Read and Write of some element of the coalesced array.
A trick among lazy people is to postpone work until it is absolutely needed, in the hope that it may never be needed. Note that, strictly speaking, the chip need not initialize a C[i] until character i is accessed for the first time in a subsequent packet. But how can the chip tell that it is seeing character i for the first time?
To implement lazy evaluation, each memory word representing an entry in the coalesced array must be expanded to include, say, a 3-bit generation number G[i]. The generation number can be thought of as a value of clock time measured in terms of packets encountered so far, except that it is limited to 3 bits. Thus, the chip keeps an additional register g, besides the extra G[i] for each i, that is 3 bits long; g is incremented mod 8 for every packet encountered. In addition, every time C[i] is updated, the chip updates G[i] as well to reflect the current value of g.
Given the generation numbers, the chip need not initialize the count array after the current packet has been processed. However, consider the case of a packet whose generation number is h, which contains a character i in its URL. When the chip encounters i while processing the packet the chip reads C[i] and G[i] from the Count array. If G[i] ≠ h, this clearly indicates that entry i was last accessed by an earlier packet and has not been subsequently initialized. Thus the logic will write back the value of C[i] as 1 (initialization plus increment) and set G[i] to h. This is shown in Figure 1.7.

The careful reader will immediately object. Since the generation number is only 3 bits, once the value of g wraps around, there can be aliasing. Thus if G[i] is 5 and entry i is not accessed until eight more packets have gone by, g will have wrapped around to 5. If the next packet contains i, C[i] will not be initialized and the count will (wrongly) accumulate the count of i in the current packet together with the count that occurred eight packets in the past.
The chip can avoid such aliasing by doing a separate “scrubbing” loop that reads the array and initializes all counters with outdated generation numbers. For correctness, the chip must guarantee one complete scan through the array for every eight packets processed. Given that one has a slack of (say) 40 non-URL bytes per packet, this guarantees a slack of 320 non-URL bytes after eight packets, which suffices to initialize a 256-element array using one Read and one Write per byte, whether the byte is a URL or a non-URL byte. Clearly, the designer can gain more slack, if needed, by increasing the bits in the generation number, at the cost of slightly increased storage in the array.
The chip, then, must have two states: one for processing URL bytes and one for processing non-URL bytes. When the URL is completely processed, the chip switches to the “Scrub” state. The chip maintains another register, which points to the next array entry s to be scrubbed. In the scrub state, when a non-URL character is received, the chip reads entry s in the coalesced array. If G[s] ≠ g, G[s] is reset to g and C[s] is initialized to 0.
Thus the use of 3 extra bits of generation number per array entry has reduced initialization processing cycles, trading processing for storage. Altogether a coalesced array entry is now only 32 bits, 15 bits for a counter, 14 bits for a threshold shift value, and 3 bits for a generation number. Note that the added initialization check needed during URL byte processing does not increase memory references (the bottleneck) but adds slightly to the processing logic. In addition, it requires two more chip registers to hold g and s, a small additional expense.
1.2.6 Characteristics of Network Algorithmics
The example of scenting an evil packet illustrates three important aspects of network algorithmics.
a. Network algorithmics is interdisciplinary: Given the high rates at which network processing must be done, a router designer would be hard pressed not to use hardware. The example exploited several features of hardware: It assumed that wide words of arbitrary size were easily possible; it assumed that shifts were easier than divides; it assumed that memory references were the bottleneck; it assumed that a 256-element array contained in fast on-chip memory was feasible; it assumed that adding a few extra registers was feasible; and finally it assumed that small changes to the logic to combine URL processing and initialization were trivial to implement.
For the reader unfamiliar with hardware design, this is a little like jumping into a game of cards without knowing the rules and then finding oneself finessed and trumped in unexpected ways. A contention of this book is that mastery of a few relevant aspects of hardware design can help even a software designer understand at least the feasibility of different hardware designs. A further contention of this book is that such interdisciplinary thinking can help produce the best designs.
Thus Chapter 2 presents the rules of the game. It presents simple models of hardware that point out opportunities for finessing and trumping troublesome implementation issues. It also presents simple models of operating systems. This is done because end systems such as clients and Web servers require tinkering with and understanding operating system issues to improve performance, just as routers and network devices require tinkering with hardware.
b. Network algorithmics recognizes the primacy of systems thinking: The specification was relaxed to allow approximate thresholds in powers of 2, which simplified the hardware. Relaxing specifications and moving work from one subsystem to another is an extremely common systems technique, but it is not encouraged by current educational practice in universities, in which each area is taught in isolation.
Thus today one has separate courses in algorithms, in operating systems, and in networking. This tends to encourage “black box” thinking instead of holistic or systems thinking. The example alluded to other systems techniques, such as the use of lazy evaluation and trading memory for processing in order to scrub the Count array.
Thus a feature of this book is an attempt to distill the systems principles used in algorithmics into a set of 15 principles, which are catalogued inside the front cover of the book and are explored in detail in Chapter 3. This book attempts to explain and dissect all the network implementations described in this book in terms of these principles. The principles are also given numbers for easy reference, though for the most part we will use both the number and the name. For instance, take a quick peek at the inside front cover and you will find that relaxing specifications is principle P4 and lazy evaluation is P2a.
c. Network algorithmics can benefit from algorithmic thinking: While this book stresses the primacy of systems thinking to finesse problems wherever possible, there are many situations where systems constraints prevent any elimination of problems. In our example, after attempting to finesse the need for algorithmic thinking by relaxing the specification, the problem of false positives led to considering keeping track of the highest counter relative to its threshold value. As a second example, Chapter 11 shows that despite attempts to finesse Internet lookups using what is called tag switching, many routers resort to efficient algorithms for lookup.
It is worth emphasizing, however, that because the models are somewhat different from standard theoretical models, it is often insufficient to blindly reuse existing algorithms. For example, Chapter 13 discusses how the need to schedule a crossbar switch in 8 nsec leads to considering simpler maximal matching heuristics, as opposed to more complicated algorithms that produce optimal matchings in a bipartite graph.
As a second example, Chapter 11 describes how the BSD implementation of lookups blindly reused a data structure called a Patricia trie, which uses a skip count, to do IP lookups. The resulting algorithm requires complex backtracking.1 A simple modification that keeps the actual bits that were skipped (instead of the count) avoids the need for backtracking. But this requires some insight into the black box (i.e., the algorithm) and its application.
In summary, the uncritical use of standard algorithms can miss implementation breakthroughs because of inappropriate measures (e.g., for packet filters such as BPF, the insertion of a new classifier can afford to take more time than search), inappropriate models (e.g., ignoring the effects of cache lines in software or parallelism in hardware), and inappropriate analysis (e.g., order-of-complexity results that hide constant factors crucial in ensuring wire speed forwarding).
Thus another purpose of this book is to persuade implementors that insight into algorithms and the use of fundamental algorithmic techniques such as divide-and-conquer and randomization is important to master. This leads us to the following.
Definition: Network algorithmics is the use of an interdisciplinary systems approach, seasoned with algorithmic thinking, to design fast implementations of network processing tasks at servers, routers, and other networking devices.
Part I of the book is devoted to describing the network algorithmics approach in more detail. An overview of Part I is given in Figure 1.8.
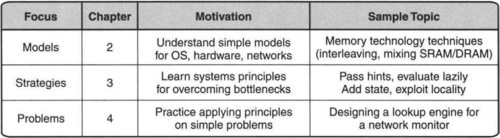
While this book concentrates on networking, the general algorithmics approach holds for the implementation of any computer system, whether a database, a processor architecture, or a software application. This general philosophy is alluded to in Chapter 3 by providing illustrative examples from the field of computer system implementation. The reader interested only in networking should rest assured that the remainder of the book, other than Chapter 3, avoids further digressions beyond networking.
While Parts II and III provide specific techniques for important specific problems, the main goal of this book is to allow the reader to be able to tackle arbitrary packet-processing tasks at high speeds in software or hardware. Thus the implementor of the future may be given the task of speeding up XML processing in a Web server (likely, given current trends) or even the task of computing the chi-square statistic in a router (possible because chi-square provides a test for detecting abnormal observed frequencies for tasks such as intrusion detection). Despite being assigned a completely unfamiliar task, the hope is that the implementor would be able to craft a new solution to such tasks using the models, principles, and techniques described in this book.
1.3 EXERCISE
1. Implementing Chi-Square: The chi-square statistic can be used to find if the overall set of observed character frequencies are unusually different (as compared to normal random variation) from the expected character frequencies. This is a more sophisticated test, statistically speaking, than the simple threshold detector used in the warm-up example. Assume that the thresholds represent the expected frequencies. The statistic is computed by finding the sum of
![]()
for all values of character i. The chip should alarm if the final statistic is above a specified threshold. (For example, a value of 14.2 implies that there is only a 1.4% chance that the difference is due to chance variation.) Find a way to efficiently implement this statistic, assuming once again that the length is known only at the end.