
Appendix D. PostgreSQL features
In this appendix, we cover features and behaviors that are fairly distinctive to PostgreSQL, which make it a little different from working with other relational databases.
Useful PostgreSQL resources
Below you’ll find a list of key PostgreSQL resources that cover general PostgreSQL usage in addition to resources for add-on tools and performance.
General
- PostgreSQL wiki— User contributed articles about various PostgreSQL topics ranging from administration, performance tuning, and writing queries to using PostgreSQL in various application and programming environments. http://wiki.postgresql.org/wiki/Main_Page Check out the code snippets repository for lots of useful PostgreSQL functions you can copy and paste into your database. http://wiki.postgresql.org/wiki/ Category:Snippets
- Planet PostgreSQL— Blog roll of PostgreSQL-specific blogs. Learn from hard-core long-time PostgreSQL users how to get the most out of PostgreSQL. Also learn what’s new and hot in PostgreSQL. http://planet.postgresql.org/
- Our blog/journal— We try to cater to new PostgreSQL users, programmers, and database users coming from other database systems such as MySQL, SQL Server, or Oracle. http://www.postgresonline.com
- PostgreSQL main site— You can download the source from here as well as get flash news. You can also download the manual in PDF form or leaf through the HTML version online. The manual is huge and consists of five volumes. http://www.postgresql.org
- PostgreSQL 9.0 High Performance and PostgreSQL 9 Administration Cookbook— A fairly recent couple of books on PostgreSQL are written by 2ndQuadrant consultants who are major contributors to PostgreSQL. These books cover PostgreSQL 8.1–9.0. These and other PostgreSQL books are listed on http://www.postgresql.org/docs/books/.
- PostgreSQL Yum repository— If you’re a Centos, Fedora, or Red Hat Enterprise Linux user, this is a painless way of installing PostgreSQL service and keeping it up to date. There are Yum updates for even the latest beta versions of PostgreSQL. http://yum.pgsqlrpms.org/reporpms/repoview/letter_p.group.html
Performance
- Explaining EXPLAIN— Covers planner basics up through PostgreSQL 8.3 and some of PostgreSQL 8.4. http://wiki.postgresql.org/images/4/45/Explaining_EXPLAIN.pdf
PostgreSQL-specific tools
- Packaged with PostgreSQL are psql, pg_dump, pg_dump_all, and pg_restore— These are command-line utilities for querying, backing up, and restoring PostgreSQL databases. You can get them from your Linux or Mac OS X distribution or from EnterpriseDB one-click installers, or you can download the source from the PostgreSQL core site and compile them yourself.
- pgAdmin III— Comes packaged with PostgreSQL, but binaries and source can be downloaded separately if you need to install it on a workstation without a PostgreSQL server. http://www.pgadmin.org/ It’s also available via the common operating system distributions.
- phpPgAdmin— A PHP web-based database administration tool for PostgreSQL, patterned after phpMyAdmin. http://phppgadmin.sourceforge.net/
Connecting to a PostgreSQL server
Before you can even create a spatial database (or any database for that matter), you need to be able to log in to your PostgreSQL server via pgAdmin III or psql. In this section, we’ll cover the basics, the most common problems, and how to work around them.
Core configuration files
If you’re just starting out and have just installed your PostgreSQL server, you’ll want to pay attention to the following key files, which are all located in the data cluster of your installation.
Location of Data Cluster
- For Windows users, this is the data directory you are prompted for during install, which, if you don’t change it, for 32-bit systems is located in C:Program FilesPostgreSQL8.4data and for 64-bit systems is located in C:Program Files (x86)PostgreSQL8.4data.
- For other users, most likely you had to do an initdb and the path you gave to the -D is the location of the data cluster.
In PostgreSQL 9.0, native 64-bit for Windows OS was introduced. But as of this writing, no PostGIS 64-bit installers are available and 64-bit is not well tested for PostGIS on Windows, though some have claimed success compiling and running it. We hope to have native 64-bit PostGIS for Windows soon. For the time being, even if you’re on a 64-bit Windows platform, you should use the 32-bit PostgreSQL installers if you want to use PostGIS.
Postgresql.Conf
The postgresql.conf file is the most important file. It contains all the memory configurations and defaults as well as the listening addresses and ports. If you’re running multiple versions of PostgreSQL or just multiple instances, you need to have them listening on different ports or different addresses, otherwise the first one to start will prevent others from starting. But you can have multiple instances sharing the same binaries as long as they have a different data cluster. In practice that’s rarely done.
The two settings of most importance for getting started are listen_addresses and port.
If you want to be able to allow your server to be accessed by remote computers without need for SSH tunneling, then set it as follows:
listen_addresses = '*' # what IP address(es) to listen on;
# comma-separated list of addresses;
# defaults to 'localhost', '*' = all
# (change requires restart)
The port setting defaults to 5432, but if you want to run multiple PostgreSQL services, you’ll need to have each one set differently. For example, we run PostgreSQL 8.2, 8.3, and 8.4 on our servers for testing. We have our port for 8.4 set to something like this:
port = 5434
We discuss some of the other important settings in the postgresql.conf file in chapter 9, “Performance tuning.”
PG_HBA.Conf
The pg_hba.conf file controls which users on which IP address ranges can connect to the PostgreSQL service/daemon as well as which authentication scheme is allowed for them.
Launching psql
If you’re using a Linux server with just a command-line console (standard for most production web/app servers), you’ll need to use psql at least once on the server to get everything rolling.
From the server do the following
psql -h localhost -U postgres
to verify that you can connect. If you can’t, refer to the “Connection difficulties” section, which follows shortly.
Launching pgAdmin III
For new users, we highly recommend the pgAdmin III GUI. If you installed using one of the one-click desktop installers, pgAdmin III is usually included. On Windows you can find it under Start > Programs > PostgreSQL 8.4 > pgAdmin III.
For Linux distributions the path varies.
You can also install pgAdmin on a regular desktop PC that doesn’t have a PostgreSQL server installed. Download one of the available binaries from http://www.pgadmin.org/download/.
For versions of pgAdmin III 1.10 and above, you can also launch psql for that specific database within pgAdmin III.
This is useful for taking advantage of special features of psql, like redirecting output to files or importing data from files. To access psql from pgAdmin III, follow these steps:
1. Select the database.
2. Under the Plug-ins icon, choose psql. If the wrong version of psql launches, you can change it in the plugins.ini file in the pgAdmin III install folder or by changing the bin location in the Options tab. This is discussed briefly at http://www.postgresonline.com/journal/archives/145-PgAdmin-III-Plug-in-Registration-PostGIS-Shapefile-and-DBF-Loader.html.
In pgAdmin III 1.13 and above, the plug-in architecture has changed a bit to allow easier adding of more plug-ins without affecting prior or distributed ones. Instead of a single plugins.ini file, there’s a plugins.d folder where you would put all the INIs for your plug-ins. These INIs can be given descriptive names. We discuss this change at http://www.postgresonline.com/journal/archives/180-PgAdmin-III-1.13-change-in-plugin-architecture-and-PostGIS-Plugins.html, which also covers registering more custom plug-ins.
Connection difficulties
If you’re connecting to the server from a separate desktop PC, then the server needs to listen on one or more IP addresses and should allow remote connections. After making the required changes to configuration files, you must restart the PostgreSQL service. On Windows, you go into Services Manager and restart.
On Linux, if you did install it as a service, which is usually the case when you installed from YUM or a one-click installer, you can usually enter the following from a shell prompt:
service postgresql restart
Connection Refused
If you get an error in pgAdmin III like
could not connect to server: Connection refused (0x0000274D/10061) Is the server running on host "blah blah blah" and accepting TCP/IP connections on port 5432?
then most likely you have one of the following problems:
- Your PostgreSQL server is not started.
- Your PostgreSQL server service is only listening on localhost or a non-accessible IP.
- Your PostgreSQL server is not listening on the port you think it’s listening on.
- Your firewall is getting in the way. Generally for firewall issues you can set up an SSH tunnel, which we describe briefly here: http://www.postgresonline.com/journal/index.php?/archives/38-PuTTY-for-SSH-Tunneling-to-PostgreSQL-Server.html. Some third-party PostgreSQL tools also have SSH tunneling built in. pgAdmin III does not.
No Entry In PG_HBA.Conf
If you get a no-entry error, then it means your pg_hba.conf file isn’t configured right for remote connections or contains errors. We generally set our configuration to something like the example pg_hba.conf in listing D.1 and allow all local connections to be trusted. This means that if you connect from the local machine, you don’t need to provide a password, only a valid PostgreSQL username. If you’re very security conscious, you could leave this line out and require MD5 or some other security scheme. To make connecting a bit easier, you can set up a .pgpass file, which we’ll discuss shortly.
Listing D.1. Example pg_hba.conf—trust all local connections
# TYPE DATABASE USER CIDR-ADDRESS METHOD # IPv4 local connections: host all all 127.0.0.1/32 trust # IPv6 local connections: #host all all ::1/128 md5 host all all 0.0.0.0/0 md5
Keep in mind that the order of these statements is important because PostgreSQL will check each one in order and apply the first matching rule that meets the credentials of the person trying to connect. This means that if you accidentally put the 0.0.0.0/0 MD5 rule above all the others, then you’ll have to provide a password even when connecting locally.
Enabling advanced administration for pgAdmin III
Once you’re able to connect, you’ll be able to administer the postgresql.conf and pg_hba.conf configuration files and also to check server status and do other administrative tasks remotely from another computer using pgAdmin III. For that, you need to run adminpack.sql first, which is located in the contrib folder of your PostgreSQL install.
Do the following from the command line on the PostgreSQL server. The example uses the default Windows install path for PostgreSQL 8.4; if you’re on Linux or running a lower version of PostgreSQL, the installation path will be different and you may not even need to include the psql binary in your path, because it’s usually in the default bin folder.
"C:/Program Files/PostgreSQL/8.4/bin/psql" -h localhost U postgres -d postgres -p 5434 file="C:/Program Files/PostgreSQL/8.4/share/contrib/adminpack.sql"
If you have PostgreSQL installed on a 64-bit version of Windows, it gets installed by default in the Program Files (x86) directory because PostgreSQL as of this writing doesn’t yet run in 64-bit mode on Windows. It does, however, run fine in 64-bit mode on Linux and does use 64-bit memory in Windows because it delegates memory management to the server.
"C:/Program Files (x86)/PostgreSQL/8.4/bin/psql" -h localhost U postgres -d postgres -p 5432 file="C:/Program Files (x86)/PostgreSQL/8.4/share/contrib/adminpack.sql"
From then on, to access the administrative postgresql.conf, pg_hba.conf, from within pgAdmin from any desktop, do the following:
- Register the server in pgAdmin III.
- Choose Tools > Server Configuration (you should see both config files there).
Controlling access to data
There are two parts of access control in PostgreSQL. First is control of who can log in and how they can log in, which you saw a glimpse of earlier. Once a person is logged in, there is control of what kind of data can be accessed, created, deleted, and edited.
Connection rules
The connection rules are controlled by three files:
- postgresql.conf— Controls on what ports and IP addresses the server listens and whether a Secure Socket Layer (SSL) connection is required. For LDAP-like connectivity, it also holds information such as the Kerberos settings to use to connect to a Kerberos authenticating server.
- pg_hba.conf— Controls whether people can connect based on their IP range and what kind of authentication is required for each connection.
Common authentication schemes include the following:
- md5— MD5 encryption; what most people use, particularly for web apps.
- trust— Ignores the password. Never use this except in a tightly secured local network or on a local PC that has good firewall protection against IP spoofers or that listens only on a local port.
- ident— Trusts a user based on their local identity determined by the OS. Again, it’s generally used only for local authentication.
- reject— This kind of authentication doesn’t allow you to authenticate. You use this if you want to ban certain IP ranges or everyone who isn’t on your network but who would otherwise be allowed by a broader IP range rule. In such cases, you’d put this rule above the broader rule so that it’s resolved first.
- krb4/5— Kerberos connection. This is deprecated; don’t use it.
- sspi— Supported only on Windows and requires the PostgreSQL server to be running on Windows. It’s designed for connecting via Windows authentication or NT authentication. It sits on top of Kerberos.
- gss— Industry defined protocol similar to SSPI but doesn’t require a Windows server; it sits on top of Kerberos.
- ldap— authentication via an LDAP directory service such as Active Directory or Novell directory service. The user must exist in the PostgreSQL server, but the password verification uses LDAP.
- pg_ident.conf— Allows you to map an authenticated user to a database-defined user/login. For example, you might want root to log in as postgres.
- pgpass.conf, .pgpass— This is a local configuration file that stores the user-names, server, and passwords for the database that you connect with. If you’re using pgAdmin, then pgAdmin creates this for you automatically and you can export its contents using the File > Open pgpass.conf. Under Windows, this file generally exists in %APPDATA%postgresqlpgpass.conf, and on Linux/Unix systems, the file is called .pgpass and should be put in ~/.pgpass. This file will be used by psql, pg_dump, and pg_restore to automatically log you into a PostgreSQL server without prompting for a username or password. It’s useful to have if you don’t have trust enabled and you need to schedule backup jobs and such. Keep in mind that the file must exist under the account doing the work, so if you’re doing backup under a service account such as postgres or Administrator, then you need to copy the file into the respective home directory of these accounts.
Users and groups (roles)
The PostgreSQL security model from PostgreSQL 8.1+ is composed of roles, and roles sit on the server level, not the database level. Prior versions of PostgreSQL had groups and users instead of roles. Roles can inherit from each other, can have login rights, and can contain other member roles. A user is a role with login rights. Unlike most databases, PostgreSQL doesn’t make a distinction between a user and a group. You can easily morph a user into a group by adding members to the roles. Roles are all there is.
In a relational database system, you create users (roles) and grant rights using a kind of SQL called Data Control Language (DCL). DCL varies significantly from database product to database product because of the idiosyncrasies of how each database manages security. There do exist ANSI SQL standards dictating the syntax, but these are much less followed than those for Data Manipulation Language (DML) and Data Definition Language (DDL). PostgreSQL does try to follow the standard as much as possible, but it also deviates, like most relational databases. In this section, we’ll go over PostgreSQL security concepts and also demonstrate PostgreSQL’s specific dialect of DCL. In terms of roles, Oracle is probably closest in syntax to PostgreSQL.
Table D.1 lists general user database concepts and their equivalent in PostgreSQL.
Table D.1. PostgreSQL role concepts and parallels to other databases
|
General concept |
PostgreSQL equivalent |
|---|---|
| User (login) | A role with login rights and generally contains no member roles. |
| Group | A role with member roles (usually no login rights). |
| Database user | A user with grant rights to a database object. |
| Sys DBA | A role that has SUPERUSER rights. |
| Public | The built-in role that all authenticated users belong to. SQL Server has such a role too, and it coincidentally is also called Public. |
There also exist ANSI standard information_schema tables for interrogating roles, privileges, and so forth, but each database system we’ve worked on arbitrarily implements the ones they prefer in this regard, to the point of relying on any of the role/ privilege-based tables in information_schema is not very portable between database management systems.
Rights management
PostgreSQL roles can contain and be contained by many other roles. In other words, each role/user/group can have many parents or belong to many groups. Roles in PostgreSQL don’t necessarily inherit rights from their parent roles, which is a cause of confusion for many people. We’ll go over this shortly.
Core Server Rights
A role can have a couple of core rights that are granted at the server level. These rights are not inheritable, so if you add a user to a group role with these rights, then that user won’t by default be able to do these things even if you mark them as inheriting from their roles. To relinquish these, prefix them with NO, such as NOSUPER-USER, NOINHERIT.
- SUPERUSER— Has super powers (to relinquish superuser rights, use NOSUPER-USER).
- INHERIT— When marked as INHERIT, the role inherits the rights of its parent roles. In later versions of PostgreSQL, this is the default behavior.
- CREATEDB— This gives a role the ability to create a database.
- CREATEROLE— This gives a role the ability to create other roles that are not SUPERUSER roles and that it’s not a member of. Only a superuser can create other superusers.
- LOGIN— This gives the role rights to log in. Generally speaking, people create group roles by not giving the group role rights to log in, though in theory you can have a group role that has rights to log in. In practice, having group roles that can log in is confusing, so pgAdmin prevents you from doing this via the GUI interface.
The Power Without the Power Using Set Role
People often make the mistaken assumption that a member of a role with superpowers always has superpowers. This is never the case, as mentioned previously, because SUPERUSER rights and the like are never inheritable. It’s also useful to prevent yourself from shooting yourself in the foot or to appease a boss. You can add yourself or the boss to a SUPERUSER role but not cause damage casually. How? When the boss demands, “I need power to do everything,” as bosses often demand, you can nod and say, “Yes, I have added you to a group that has power to do everything,” and blissfully walk away. We’ll demonstrate this superuser without superuser powers with this simple exercise:
CREATE ROLE office_of_president SUPERUSER; CREATE ROLE regina INHERIT LOGIN PASSWORD 'queen'; GRANT office_of_president TO regina; CREATE ROLE leo LOGIN PASSWORD 'lion king' SUPERUSER;
Here we have a simple script that creates a group called office_of_president and two users, Leo and Regina. Leo has SUPERUSER rights, and Regina is a member of a group that has SUPERUSER rights. Leo is always omnipotent. Regina is only omnipotent when she summons her powers of omnipotence. We’ll demonstrate with these scenarios:
Leo logs in and creates a database called kingdom by running this command:
CREATE DATABASE kingdom;
He is successful.
Regina logs in and tries to create a database called fortress:
CREATE DATABASE fortress;
She gets a message:
ERROR: permission denied to create database
She’s frustrated. She’s a member of the mighty role of office_of_president and she’s marked as inheriting rights. She must be able to create a database, but how? First, recall that SUPERUSER rights are never inheritable, but they can be summoned. Regina summons her powers of office_of_president and then creates the database:
SET ROLE office_of_president; CREATE DATABASE fortress;
Now she succeeds.
Being dissatisfied with the state of affairs, she summons her powers to put things into order:
SET ROLE office_of_president; ALTER ROLE leo NOSUPERUSER; ALTER ROLE regina SUPERUSER;
And now Leo is powerless, and Regina is always omnipotent without the need to summon superpowers.
To Inherit or not to Inherit
One thing that makes PostgreSQL stand out from other databases is this idea of INHERIT and NOINHERIT as well as the fact, as we mentioned earlier, that some rights are never inheritable. You can define a user that belongs to many groups but does not inherit the permissions of those groups. This little idiosyncrasy dumbfounds people because they often accidentally mark their login roles as not inheriting rights from their parent roles and scratch their heads when the user complains that they can’t do anything.
Why would anyone ever create a user that doesn’t inherit rights of its membership groups?
One reason is for testing. Let’s imagine that you create a user that’s a member of every single group role under the sun, but that user (login role) doesn’t inherit rights from any role it’s a member of. What can this user do? It can for a specific session, promote itself to have rights of any role it’s a member of, much like Regina promoted herself to the rights of her powerful group. This can be useful for testing different membership rights or for giving a user only certain rights within an application. As we also demonstrated earlier, this prevents you from doing superuser damage without trying to deliberately do superuser damage.
Session Authorization
Session authorization is similar to SET ROLE but the distinction is that in SET ROLE you summon your powers as a member of a role, while with SET SESSION AUTHORIZATION you become that role. Basically you’re impersonating another user. Only a superuser can impersonate another user, but any member of a role can do a SET ROLE to the roles of which they’re a member. Impersonation is useful when you’re creating a bunch of objects that you want to be owned by a specific user without having to change owner to that person for each creation. Another example would be when you want to run commands but limit yourself to the rights that user has, just to verify what a user can do.
Granting Rights to Objects
As with other databases, PostgreSQL allows you to grant rights to specific objects in a database. The database owner or the owner of an object can grant rights to others, and in addition to granting rights to objects, they can give others the right to grant rights to objects using WITH GRANT OPTION. GRANT, as you saw in the previous examples, is also used to add a user to a group role. If a user is granted rights to a role WITH ADMIN OPTION, then the user can add or remove users to or from that role.
PostgreSQL 8.4 introduced column-level permissions, allowing granting read/write/ update permissions to individual columns of a table, largely thanks to the work of Stephen Frost, who is also a longtime contributor of the PostGIS project (TIGER geocoder).
In the following exercise, we list the common GRANT usages.
Listing D.2. Common GRANT options

![]() We grant all rights to Leo for our database and also allow him to give grant rights to whomever he chooses, but this only
means that Leo can connect to the database and create new schemas. It doesn’t give him the right to view existing tables,
for example, or to create objects in schemas for which he doesn’t have rights.
We grant all rights to Leo for our database and also allow him to give grant rights to whomever he chooses, but this only
means that Leo can connect to the database and create new schemas. It doesn’t give him the right to view existing tables,
for example, or to create objects in schemas for which he doesn’t have rights. ![]() We give Leo all rights to the world schema. This doesn’t allow him to view or edit existing data, but it does allow him to
create new objects in world.
We give Leo all rights to the world schema. This doesn’t allow him to view or edit existing data, but it does allow him to
create new objects in world. ![]() We give Leo the right to view and add data in geometry_columns but not to update or delete.
We give Leo the right to view and add data in geometry_columns but not to update or delete. ![]() We give everyone the right to view data in spatial_ref_sys and
We give everyone the right to view data in spatial_ref_sys and ![]() Leo the right to update the proj4text and srtext columns in spatial_ref_sys (works only for PostgreSQL 8.4+).
Leo the right to update the proj4text and srtext columns in spatial_ref_sys (works only for PostgreSQL 8.4+).
As you can see, the process of granting rights in PostgreSQL 8.4 or below is somewhat annoying. It’s annoying in the sense that you often want to grant rights to a whole database or schema, and there’s no one-liner in PostgreSQL for doing such a thing. To get around this annoyance, you can do one of the following:
- Use SQL to script desired rights, as we describe in this article: http://www.postgresonline.com/journal/index.php?/archives/30-DML-to-generate-DDL-andDCL--Making-structural-and-Permission-changes-to-multiple-tables.html.
- Use the pgAdmin III Grant Wizard, which allows you to select a list of objects and grant rights to specified roles. To use
the Grant Wizard, follow these steps:
- Select a schema.
- Select Tools > Grant Wizard.
- Select the objects you want, privileges, and roles.
PostgreSQL 9.0 introduced enhancements to the GRANT and REVOKE feature that allow you to GRANT ALL to all tables or functions and the like in a schema or across the database. This is described in http://www.depesz.com/index.php/2009/11/07/waiting-for-8-5-grant-all/.
If you’re using PostgreSQL 9.0 or above, life is much simpler as far as rights management is concerned.
Revoking Rights
You can revoke rights just as easily as you can grant rights. You revoke rights with the REVOKE command. In this section we’ll demonstrate common REVOKE statements.
The REVOKE command is used to revoke any kind of permission that’s granted with the GRANT command. We’ll demonstrate our favorite REVOKE command, revoking connection rights from the Public group. As we mentioned, the Public group is the group that everyone belongs to and that, in general, most databases allow connect access to when created. What this means is that any authenticated user can connect to the database and browse the structure of the tables. This isn’t always desirable. To prevent this, you can run the following command:
REVOKE CONNECT ON DATABASE postgis_in_action FROM public;
Now that we’ve covered the basics of security, we’ll cover something perhaps even more important, backup and restore.
Backup and restore
PostgreSQL has perhaps the richest backup and restore tools of any open source database, and they rival and often surpass those offered by the commercial relational database systems. Backup is accomplished with the following commands:
- pg_dump— This can do custom compressed backups, SQL backups, as well as selective backup of schemas and other objects all in a single command line. SQL backups are restored with psql, and compressed and tar backups are restored with pg_restore.
- pg_dumpall— This does only SQL backups and system server configuration backups, such as backups of users and tablespaces and the like. It can also do a whole backup of the server—all databases included. The backup is a regular SQL backup, so it doesn’t allow the selective restore that’s possible with pg_dump. Backups done with pg_dumpall are restored with psql.
For restoring data, PostgreSQL comes packaged with psql and pg_restore:
- pg_restore— This is used for restoring compressed and tar backups created with pg_dump. pg_restore will allow you to restore select objects and also to generate a list of objects backed up in a backup. You can then edit this list to fine-tune what you would like to restore from the backup.
- psql— This is used for restoring or running an SQL file such as those generated by pg_dumpall or pg_dump when SQL mode is chosen or by the PostGIS shp2pgsql shapefile import tool.
In PostgreSQL 8.4, pg_restore was enhanced to include a jobs= option. This option is particularly useful for large backups and defines the number of parallel threads used to do a restore. If you back up a database with PostgreSQL 8.4+ pg_dump, then you can specify jobs=2 or more. This does a parallel restore. Depending on your disk IO and CPU, setting this can halve or reduce even more the time of a restore. For example, a restore of a PostGIS 800 GB database would take about 12 hours in prior versions and only 6 hours or less in 8.4.
Backup
The pg_dump command-line tool packaged with PostgreSQL is our preferred tool for database backups. The main reason we prefer it is that it creates a nice compressed backup and allows for selective restore of objects. Most of the time a restore is needed because a user accidentally destroyed data, and in those cases you don’t want to have to restore the whole database. In this section we’ll go through some common pg_dump and pg_dumpall statements used for backing up data, as shown in the following listing.
Listing D.3. Common backup statements

![]() Dump the database in compressed format; include blob and show verbose progress (-v).
Dump the database in compressed format; include blob and show verbose progress (-v). ![]() Dump the database in Latin1 encoding, which is useful if you want to restore a database but want to use a different encoding
in the new database.
Dump the database in Latin1 encoding, which is useful if you want to restore a database but want to use a different encoding
in the new database. ![]() Back up pgagent schema or any schema of postgres DB in plain-text copy format, and maintain oids.
Back up pgagent schema or any schema of postgres DB in plain-text copy format, and maintain oids. ![]() Dump all databases—note that pg_dumpall can only output to plain text.
Dump all databases—note that pg_dumpall can only output to plain text. ![]() Back up users/roles and tablespaces.
Back up users/roles and tablespaces. ![]() Back up a single table in compressed format.
Back up a single table in compressed format.
Restore
In order to restore a backup of PostgreSQL, you use pg_restore to restore compressed and tar backups, and you use psql to restore SQL backups. If you have a compressed or tar backup, you can use pg_restore to restore select portions of a backup file. In this section, we’ll demonstrate some common examples, as shown in the following listing.
Listing D.4. Common restore statements
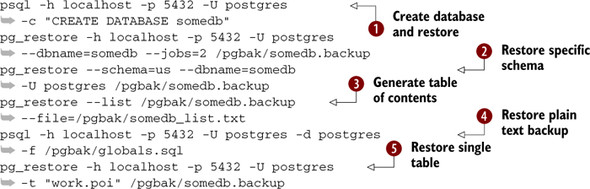
![]() Create a new database and restore the backup file to this new database using two threads for restore. (Remember, jobs works
only for PostgreSQL 8.4+.)
Create a new database and restore the backup file to this new database using two threads for restore. (Remember, jobs works
only for PostgreSQL 8.4+.) ![]() Restore only a specific schema, in this case the us schema.
Restore only a specific schema, in this case the us schema. ![]() Generate a table of contents for a backup file and store it in the file somedb_list.txt.
Generate a table of contents for a backup file and store it in the file somedb_list.txt. ![]() Restore user accounts and custom table spaces. You can specify any SQL file here, such as the one we created to back up all
databases.
Restore user accounts and custom table spaces. You can specify any SQL file here, such as the one we created to back up all
databases. ![]() Restore a single table from backup. In this case, we’re restoring the table poi in the schema work.
Restore a single table from backup. In this case, we’re restoring the table poi in the schema work.
In the next section we’ll provide some tips for automating the backup process.
Setting up automated jobs for backup
There are two common ways for automating backups for PostgreSQL, and they vary slightly depending on your OS:
- Use an OS-specific scheduling agent such as cronjob in Unix/Linux or Windows Scheduler in Windows.
- Use pgAgent, a free scheduling agent for PostgreSQL manageable from pgAdmin III.
We prefer the pgAgent way because it’s cross platform allows us to manage the same way we manage and view other parts of PostgreSQL (via the pgAdmin III tool), and is also designed for running SQL jobs. On the downside, it’s sometimes more finicky to set up. We describe the details of the setup and also how to define a backup script for Windows and Linux at http://www.postgresonline.com/journal/index.php?/archives/19-Setting-up-PgAgent-and-Doing-Scheduled-Backups.html.
Note that because the backup scripts use only shell commands of the respective Unix/Linux/Windows environment, you can also run them with your scheduling agent of choice.
Data structures and objects
PostgreSQL, like many sophisticated relational databases, has a rich collection of objects to accomplish different tasks. In addition to database objects, it has built-in data types, many of which you’ll find in other relational databases, as well as some data types that are unique to it. If that isn’t enough, PostgreSQL allows you to extend the system and define new data types to suit your needs. The PostGIS family of data types is an extension of the core set. In this section we’ll go over all this.
PostgreSQL objects
When we speak of objects, we’re not talking about data types but rather a class of objects of which a data type is one class. Data types are used to define columns in a table, but objects are part of the core makeup of PostgreSQL. They are tables, views, schemas, and so on. Some of these you’ve already been exposed to. In the following list, we give a brief synopsis of the core PostgreSQL objects and their function:
- Server service/daemon— This is PostgreSQL itself that houses everything.
- Tablespaces— These are physical locations of data that map to a named location in the server. When you run out of disk space, objects can be moved to different locations on disks by moving them to a different tablespace. You can define the default for these by setting the Global User Control (GUC) variables default_tablespace and temp_tablespace. These can even be set at the user level so that you can control disk space used by groups of users or use fast non-redundant disks for temporary tables and so forth. It’s also fast and easy to move even a single table to a different tablespace using pgAdmin or with the SQL command ALTER TABLE sometable SET TABLESPACE newtablespace, which we describe in http://www.postgresonline.com/journal/index.php?/archives/123-Managing-disk-space-using-table-spaces.html.
- Database— Both a physical and a logical entity, a database has a root folder in the filesystem, and database data in any tablespace is always stored in a folder, such as <tablespace path>/<databaseoid>/objectoid.
- Schemas— These are the logical location of tables, views, functions. They have no relation to physical location, but SQL statements reference the logical name, and you can control the default schemas at the server, database, or user level in versions of PostgreSQL 8.2+. In 8.3+ you can also control the default at the function level via the search_path configuration. This allows you to maintain a logical separation without having to schema qualify commonly used schemas. Think of a schema as a database within the database. The first schema in the search_path is the one where new objects are created by a user. If you have two objects with the same name in different schemas, and you reference them without qualifying the schema, then the first one in the search path will be chosen.
- Roles— These include users and groups. They sit at the database level and are granted rights to objects in a database.
- Rules— Rules rewrite SELECT, INSERT, and UPDATE statements. They are unique to PostgreSQL and serve a similar purpose as triggers. In some cases, such as the way PostgreSQL implements views, rules are the only option.
- Views— Views are virtual tables. They are windows to the real data and allow you to see summaries or a subset of data by selecting from an abstracted virtual table. A view generally consists of only an INSTEAD OF SELECT rule, which is a rule that defines the SELECT statement of the view. An updateable view will also have rules on the UPDATE, INSERT, and DELETE actions of a view.
- Triggers— Triggers are actions that are performed when data changes. They are often used to update additional data. A common example in PostGIS would be if you have an application that updates a lon lat field and uses a trigger to update the geometry field when these values change. You may have another trigger to store a line in a separate table when points are added to one table.
- Data types— Data types are the micro storage structure of data, and their definition can comprise other data types. Table columns are composed of things with the same data type. The rows of a table itself are implemented in PostgreSQL as a composite data type. You’ll notice in the types section of PostgreSQL that every PostgreSQL table has a corresponding data type with the same name as the table.
- Casts— Casts are the objects that allow you to implicitly or explicitly convert from one data type to another. PostgreSQL is fairly distinctive among relational databases in that it allows you to define casting behavior for your custom-created data types. If an implicit cast is in place (a cast with no qualification), then when data of a specific data type is fed to a function that expects a different data type, the data will be automatically cast for you if there’s an unambiguous autocast type. Take care when doing this. Because of the overloading features of PostgreSQL, it’s possible to have two functions with the same name but different data types. In this case, if an object that has an autocast for both is used without an explicit casting, you’ll get an “ambiguous” error. You do an explicit CAST by using the ANSI SQL–compliant CAST(mybox As geometry) or the PostgreSQL non-ANSI SQL–specific shorthand mybox::geometry.
- Operators— These are things like =, >, <, and again PostgreSQL allows you to define custom operator behavior for your custom types. Some operators have special meaning, such as = > <, that are used by internal SQL querying to define ORDER BY, GROUP BY DISTINCT ordering. These are useful to override if you’re building custom data types and want them to sort in a certain way. As you saw in earlier chapters, PostGIS overrides = to order by the bounding box of geometry/geographies.
- Functions— These are functions you can use within an SQL statement. PostgreSQL comes with a lot of built-in and contributed ones such as the soundex you saw earlier and those provided by PostGIS. You can also build your own. Functions can return simple data types, sets, or arrays. There are three core classes of functions: regular functions, aggregate functions, and trigger functions. We’ll touch on each of these with examples in this appendix.
- Sequences— If you’ve worked with Oracle, then a sequence object will be very familiar to you. It’s a counter that can be incremented and used to get the next ID for a column. MySQL folks will recognize this as AUTO_INCREMENT; except in PostgreSQL, a sequence object need not be tied to a single table. You can use it for multiple tables and increment it separately from a table. SQL Server people will recognize this as an IDENTITY field, which is tied to a specific table. SQL Server 2011 introduced support for sequences as well, which follow the same ANSI SQL standard as Oracle and PostgreSQL. If you wanted a sequence to be tied to a specific table in PostgreSQL, then you’d create the column as serial or serial8, which behind the scenes will create a sequence object and set the default of the column to the next value of the sequence.
Built-in data types
PostgreSQL comes packaged with a lot of built-in data types. Some of these are pretty standard across all relational databases:
- int4, int8— These go by more familiar names such as int, integer, and bigint.
- float, double precision— These are another class of number types that don’t necessarily exist in other databases but are common.
- serial, serial8— You can use this in the CREATE TABLE statement, but it’s not a true type. It’s shorthand for “give me an integer with a sequence object to increment it.” It’s still an integer. The parallel in MySQL would be marking the column as an AUTO_INCREMENT or in SQL Server setting the Identity property to Yes.
- numeric— This has a scale and precision and is named the same in other relational databases. It’s also often referred to as decimal in other databases.
- varchar, text— This means character varying. Unlike most other relational databases, PostgreSQL doesn’t put a limit on the maximum length of a varchar or a text variable. Varchar and text behave much the same, except that text has no maximum limit and varchar may or many not have a specified maximum limit. Some other databases decide on storage handling based on the specified size of a field. For example, in SQL Server if text is noted, then a pointer to the text field is stored and data is stored elsewhere outside the table. The closest parallel in SQL Server is the varchar(MAX) option. PostgreSQL doesn’t care about this and bases storage considerations on the size of data actually stored in the field. Only if a field goes beyond its allotted storage size is storage relegated to toast tables. This means, as many PostgreSQL people will argue, that there’s no penalty for using text over varchar with a limit. But if you care about interoperability, we argue that there’s a big penalty. For exporting purposes such as tab delimited and so forth, it’s important to have a limit on the size of a field, and if you export to another system often, you want your size limits to mirror those of the other side. For those using autogenerated screens with screen painters, such applications refer to the system tables to determine the width for fields on the screen, and if everything is text, you end up with big text boxes everywhere. If you use an ODBC driver, for example in MS Access, a varchar is treated very differently from a text. It will allow you to sort by varchar but not by text.
- char— These are padded characters. If you say it’s a char(8), then the field will always be of length 8. This is the same in almost all relational databases. This is more a presentation feature than a storage consideration in PostgreSQL because PostgreSQL presents padded eight characters but doesn’t actually store eight characters if the text is shorter. Most other relational databases store eight characters.
- date— This is a date without time. MySQL has this, Oracle has this, and SQL Server 2008+ has this (in prior versions of SQL Server you couldn’t have a date without time).
- timestamp, timestamp with timezone— Again, these are very similar in other relational databases although they may be called datetime or some other name. SQL Server introduced timezone in SQL Server 2008, so prior to that you had no timezone information stored.
- arrays— Arrays are not quite so common in other relational databases. As far as we know, only Oracle and IBM DB2 have them. Arrays in PostgreSQL are typed. For example, date[] would be an array of dates. Any custom type you build you can define a table column as an array of that type and use it in functions as well. Arrays play an important role in building aggregate functions, because many of the tricks for building aggregate functions involve wrapping data in an array to be processed by a terminal function. Some quick ways of building arrays are ARRAY(SELECT somefield FROM sometable WHERE something_is_true), ARRAY[1,2,3,4], or in PostgreSQL 8.4+ the array_agg ANSI SQL–compliant aggregate function that will create an array for each row in a (GROUP BY ...). Note that IBM DB2 also has an array_agg function as defined by the ANSI SQL 2003 specs.
- row— This is more of an abstract data type similar to an array. A typed row is a row in a table or a specific type. You can cast compatible rows to compatible types, as we’ll demonstrate shortly.
Anatomy of a database function
Stored functions and procedures are useful for compartmentalizing reusable nuggets of functionality and embedding them in SQL statements. Unlike most relational databases, PostgreSQL (even as of PostgreSQL 9.0) doesn’t make a distinction between a stored procedure and a stored function. In other databases, stored procedures are things that can update data and generally return a cursor or nothing for their output. In PostgreSQL, there only exist functions, and functions may return nothing (void) or something and can update data as well as return something at the same time.
PostgreSQL allows you to write stored functions in various languages. Its language offering is probably richer than that of any relational database system you’ll find, both commercial and open source. Common favorites are sql, plpgsql, and plperl, and for GIS users, plpython and plr are additional favorites. There are more esoteric ones that are designed more for a specific domain such as pl/sh (which allows you to write stored functions that run bash/shell commands) and pl/proxy (designed by Skype Corporation and freely provided and that’s designed to replicate commands between PostgreSQL servers).
The only languages preinstalled in all PostgreSQL databases are SQL and C. PostgreSQL allows you to bind a C function in a C library to a stored function wrapper so that it can be used in an SQL statement. Most PostGIS functions are C functions. PL/PgSQL isn’t always installed by default in versions of PostgreSQL prior to 8.4 but is always packaged with PostgreSQL and is required to run PostGIS.
A PostgreSQL database function has a couple of core parts regardless of what language the function is written in:
- The function argument declaration
- The RETURNS declaration—This dictates the return of the function; for functions that don’t return anything, it’s void.
- The body—This is the meat of the function. From PostgreSQL 8.1+ the general convention is to use what is referred to as $ quoting syntax to encapsulate the body. Dollar quoting has the form $somename$. Oftentimes people leave out the somename so it reduces down to $$ body goes here $$. This works for all languages. Prior versions required quoting with a single quote mark (‘), which required a lot of escaping of ’ if you had that in the function. $$ quoting is a much more readable and painless way of writing functions.
- The language—This is always LANGUAGE ‘somelanguage’.
- For PostgreSQL 8.3+ the ROWS expected and COST as a function of CPU cycles
- Cachability—Designated as IMMUTABLE, STABLE, or VOLATILE, this allows PostgreSQL to know under what conditions the results can be cached. IMMUTABLE means with the same inputs you can always expect the same output. STABLE within the same query means that you can expect the same inputs to result in the same outputs, and VOLATILE means never cache because it either updates data or the results vary even given the same function inputs.
- The security context—If not specified, the function is assumed to be run using the security rights of the user. If you denote a function as SECURITY DEFINER, that means the function is allowed to do anything that the owner of the function can do. This allows you, for example, to create logic that can be executed by a non-superuser that has logic that requires superuser rights, such as reading files from the file system.
In PostgreSQL 9.0+, the DO command was introduced. This allows you to write one-off anonymous functions that contain only a body and no name and can be run straight from the command line. It currently supports only plpgsql, plpython, and plperl.
Next we’ll demonstrate how to use these PostgreSQL objects.
Defining custom data types
Defining custom data types is fairly simple in PostgreSQL. As we mentioned earlier, when you create a new table, you create a new data type as well. The next listing is a simple example of a data type we’ll call vertex that contains x and y attributes. We then create instances of it and then pull out just one of its attributes.
Listing D.5. Create a simple type and use it

In ![]() we define a new type called vertex that has an x attribute and a y attribute. In
we define a new type called vertex that has an x attribute and a y attribute. In ![]() we create a query that returns two columns and then cast that to a vertex by first packaging each as an anonymous row. In
we create a query that returns two columns and then cast that to a vertex by first packaging each as an anonymous row. In
![]() we pull out the y attribute of our fictitious table. This is similar to what we do often with ST_Dump. You’ll recognize that
we often do a (ST_Dump(the_geom)).geom to grab just the geom attribute or a (ST_Dump(the_geom)).* to explode all the attributes
into separate columns.
we pull out the y attribute of our fictitious table. This is similar to what we do often with ST_Dump. You’ll recognize that
we often do a (ST_Dump(the_geom)).geom to grab just the geom attribute or a (ST_Dump(the_geom)).* to explode all the attributes
into separate columns.
Creating tables and views
Creating tables and views is done just like in any other relational database. The following listing shows some simple examples that create a table and view in the assets schema.
Listing D.6. Creating a table and a view

In ![]() we create a table with a geography field (requires PostGIS 1.5+) that is of type POINT and WGS 84 lon lat, with an autoincrement
primary key call poi_gid and an active flag that defaults to true for new entries. In
we create a table with a geography field (requires PostGIS 1.5+) that is of type POINT and WGS 84 lon lat, with an autoincrement
primary key call poi_gid and an active flag that defaults to true for new entries. In ![]() we create a view against this new table that will list only active records. In
we create a view against this new table that will list only active records. In ![]() we drop the table and include the CASCADE command, which will drop all dependent objects such as the view we created in
we drop the table and include the CASCADE command, which will drop all dependent objects such as the view we created in ![]() . When using CASCADE, proceed with caution because you could be dropping a lot of dependent objects. Without the CASCADE we’d
be informed that assets.vwpoi_ active depends on assets.poi and thus can’t be dropped. We’d then have to drop the view first
and then the table.
. When using CASCADE, proceed with caution because you could be dropping a lot of dependent objects. Without the CASCADE we’d
be informed that assets.vwpoi_ active depends on assets.poi and thus can’t be dropped. We’d then have to drop the view first
and then the table.
Now that we’ve covered the basic features of PostgreSQL, we’ll get into greater detail about functions and rules.
Writing functions in SQL
PostgreSQL is probably the only relational database system that allows you to write stored procedures in pure SQL. This is very different from the PL/SQL supported by IBM DB2 and MySQL in that the PostgreSQL SQL function language has no support for procedural control structures. What other databases call PL/SQL is closer in family to PostgreSQL’s PL/PgSQL.
It would seem on first glance that not allowing procedural control in a stored function language would be an undesirable thing, but the main benefit of this is that an SQL function can be treated like any other SQL statement and optimized by the SQL planner. In many cases very useful pieces of reusable code can be compartmentalized in such a simple structure.
When to use SQL functions
The most important attribute about SQL functions that makes them stand out from functions written in other procedural languages is that they are often inlined in the overall query. What does this mean? It means the query planner can see inside an SQL function and embed its definition in the query. Essentially, it treats it like a macro similar to the way C macros are expanded where they’re used. This means that if your function uses an indexable expression, then the planner can use an index, and if your SQL function contains a subexpression within a query, then the planner can collapse the expression. A common example is the && operator, which is used in many PostGIS functions. If you use two functions with &&, the planner will see && and &&, and it will collapse the two into a single &&.
As a general rule of thumb, here’s when to use an SQL function:
- When you use constructs that could benefit from an index.
- When logic is fairly simple and short.
- In a rule; you can only write rules with SQL. Rules aren’t really functions, but they serve a similar purpose.
There’s one situation where you absolutely can’t use SQL to write a function even if you wanted to, and that’s for a trigger function. This may change in later versions of PostgreSQL, but as of PostgreSQL 9.0, you can’t write triggers in the SQL language.
Creating an SQL function
An SQL function, like all other functions, contains an argument list, a return argument type, and a function body. Unlike other languages, SQL functions can’t have variables, and they can at most have only one SQL statement.
While it’s true that you can’t declare variables in an SQL function, for PostgreSQL 8.4+, you can significantly compensate for this by using CTEs to define sub work steps, as we’ve demonstrated throughout this book.
This makes them fairly limited but easy to fold into a larger SQL statement. The other disadvantage is that you can’t use the argument inputs by their names; you have to reference them by $1, $2. In other PL languages such as PL/PgSQL, PL/Perl, PL/Python, and PL/R, you can reference by position or name.
The next listing is a trivial function that returns a square of numbers starting with the first and ending with the last.
Listing D.7. Example SQL function returns square
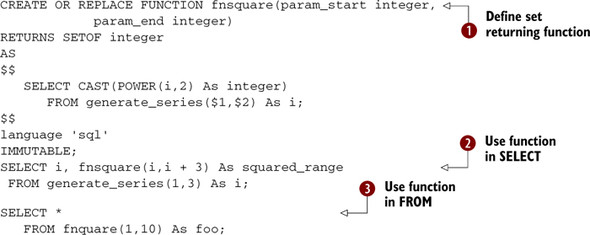
In ![]() we define our function that takes a range and returns the square of each number in the range.
we define our function that takes a range and returns the square of each number in the range. ![]() We use our function in the SELECT part of a query. This is only legal with SET-returning functions in PostgreSQL prior to
8.4, if written in SQL or C. For PostgreSQL 8.4+, you can do this with PL/PgSQL and other functions as well.
We use our function in the SELECT part of a query. This is only legal with SET-returning functions in PostgreSQL prior to
8.4, if written in SQL or C. For PostgreSQL 8.4+, you can do this with PL/PgSQL and other functions as well. ![]() This shows the standard way for calling SET-returning functions.
This shows the standard way for calling SET-returning functions.
Creating rules
Rules are objects that are bound to tables or views. They are often used in place of triggers, and for views in PostgreSQL 9.0 and below, you can only use rules. Rules don’t perform any action but help in rewriting SQL statements to do something in addition to or instead of what the SQL statement would normally do.
The classic use of rules is in defining views. When you create a view in PostgreSQL using standard ANSI syntax of the form
CREATE OR REPLACE VIEW assets.vwpoi_active AS SELECT poi.poi_gid, poi.the_geog, poi.poi_name, poi.is_active FROM poi WHERE poi.is_active = true;
PostgreSQL behind the scenes changes it to something that has a SELECT rule. If you were ever nosy enough to inspect your view, you’d see this curious thing attached to it:
CREATE OR REPLACE RULE "_RETURN" AS
ON SELECT TO vwpoi_active
DO INSTEAD
SELECT poi.poi_gid, poi.the_geog, poi.poi_name, poi.is_active
FROM poi WHERE poi.is_active = true;
In short, the concept of a view in PostgreSQL is really a packaging of a set of rules that has at least one DO INSTEAD SELECT rule and, if updateable, accompanying DO INSTEAD UPDATE, INSERT, or DELETE rules. Whenever someone calls for the virtual table vwmyview, the SELECT rule will rewrite the SQL statement to use (SELECT a.gid, a.the_geom FROM mytable As a) instead of the virtual table they were calling for.
How do you make a view updateable? You create an UPDATE rule that rewrites the update to update the raw tables, as shown here. Note that PostgreSQL 9.1+ supports binding insert/update/delete triggers to views, and using triggers for update/insert/ delete is generally the preferred way for making views updateable in PostgreSQL 9.1+.
Listing D.8. Making a view updateable

In a rule or trigger are two records called NEW and OLD. NEW exists when there’s an insert or update to an object. OLD exists when there’s an UPDATE or DELETE to an object. In the examples in listing D.8 we make our view updateable by pushing updates to the base tables the view is based on.
In PostgreSQL 9.1 triggers can be bound to views to update, insert, or delete data and can be used instead of rules for these events.
Creating aggregate functions
Aggregate functions are functions you can use just like MAX, MIN, and AVG. PostgreSQL allows you to create your own custom aggregate functions, even with a language as simple as SQL. This is one of the coolest features of PostgreSQL. Part of the power of doing this is because of the malleability of the PostgreSQL array model. We have a couple of examples of creating aggregate functions in PostgreSQL using plain SQL language.
To demonstrate the ease with which you can create an aggregate function in PostgreSQL, listing D.9 shows an example that simulates (but we think better), the MS Access First and Last aggregate functions. It’s excerpted from one of our articles titled “Who’s on first and who’s on last,” available at http://www.postgresonline.com/journal/index.php?/archives/68-More-Aggregate-Fun-Whos-on-First-and-Whos-on-Last.html.
Listing D.9. Creating first and last aggregate functions

As you can see in listing D.9, an aggregate function is composed of at least one state function (SFUNC) ![]()
![]() and one state type (SType). The FINALFUNC
and one state type (SType). The FINALFUNC ![]() is sometimes present and is needed if the result of each subsequent state is not enough or the data type of the final is
different from the data type of the state. In
is sometimes present and is needed if the result of each subsequent state is not enough or the data type of the final is
different from the data type of the state. In ![]() and
and ![]() we define our first and last aggregate functions with these elements, and in the next listing we take it for a test drive.
we define our first and last aggregate functions with these elements, and in the next listing we take it for a test drive.
Listing D.10. Putting our first and last to work
SELECT max(age) As oldest_age, min(age) As youngest_age,
count(*) As numinfamily, family,
first(name) As firstperson, last(name) as lastperson
FROM (SELECT 2 As age, 'jimmy' As name, 'jones' As family
UNION ALL SELECT 50 As age, 'c' As name, 'jones' As family
UNION ALL SELECT 3 As age, 'aby' As name, 'jones' As family
UNION ALL SELECT 35 As age, 'Bartholemu' As name,
'Smith' As family
) As foo
GROUP BY family;
We put our functions to work with a simple query. This example and the creation of aggregates work in most versions of PostgreSQL, even back to 8.1.
Writing functions in PL/PgSQL
The PostgreSQL PL/PgSQL procedural language is probably closest in form to Oracle’s PL/SQL. It, like Oracle PL/SQL and the other relational database procedural languages, is a language that allows you to declare variables, employ other control flow such as FOR and WHILE loops, cursors, RAISE errors, and so on and also write SQL. Unlike the pure SQL language, it’s not transparent to the planner and is treated like a black box. Inputs go in and outputs come out. It, like the SQL language and other PL languages, allows you to dictate attributes such as volatility, cost, and security so that the planner can decide whether a choice of order is allowed, how costly the function is to evaluate relative to other functions, and what kind of rights are allowed within the function.
When to use PL/PgSQL functions
PL/PgSQL is desirable for functions where using an outer index gives no benefit, for example, when the values that go into the function are already filtered by a where condition, or when very fine-grained step-by-step control is needed.
As a general rule of thumb, here’s when to use a PL/PgSQL function:
- No construct could benefit from an outer index check.
- Logic is complex and needs several breaks, or you need variables or the ability to raise errors.
- In a trigger. You can’t use SQL in a trigger. Although you can use other languages such as PL/Python, PL/R, or PL/Perl for writing triggers, PL/PgSQL tends to be more stable and also has more integration with PostgreSQL. Therefore, PL/PgSQL is generally a better language for writing triggers unless you need to leverage specific functionality only offered in the other languages.
As mentioned earlier, you can’t write rules with PL/PgSQL, and in earlier versions of PostgreSQL (pre 8.4), you can’t use a set-returning PL/PgSQL function in the SELECT clause of a statement, whereas you can with an SQL function.
Creating a PL/PgSQL function
The following listing is a simple PL/PgSQL function. This is the utmzone function we’ve used often in the book, and it offers a good example of when to use a PL/PgSQL function. Let’s study its parts.
Listing D.11. utmzone

![]() The first part of a PL/PgSQL function, like any function, is the envelope, which defines the parameters that go into the
function and the return type.
The first part of a PL/PgSQL function, like any function, is the envelope, which defines the parameters that go into the
function and the return type. ![]() Then there is the DECLARE, which is part of the body, the place where we declare the variables we’ll use through the rest
of the function. SQL functions don’t have this, though other languages may but specify it differently.
Then there is the DECLARE, which is part of the body, the place where we declare the variables we’ll use through the rest
of the function. SQL functions don’t have this, though other languages may but specify it differently. ![]() Then comes the meat of the function, which is encapsulated between BEGIN and END and generally ends with a RETURN that returns
the output.
Then comes the meat of the function, which is encapsulated between BEGIN and END and generally ends with a RETURN that returns
the output.
We haven’t gone through any of the control flow logic, but the BEGIN and END section uses FOR loops, while the RETURN statement may contain a RETURN NEXT loop when returning a set. For 8.3+ there’s also RETURN QUERY, which allows returning results of precompiled SQL, and 8.4 introduced RETURN QUERY EXECUTE, which allows returning results of dynamic SQL. An example of the 8.4 construct is demonstrated in Pavel Stehule’s blog: http://okbob.blogspot.com/2008/06/execute-using-feature-in-postgresql-84.html. These newer constructs are more efficient and shorter to write than the older RETURN NEXT. But if you need finer grained control of which records you return, RETURN NEXT will still be needed. The pros and cons are discussed in Andrew Dunstan’s “Experiments in Efficiency” at http://people.planetpostgresql.org/andrew/index.php?/archives/131-Experiments-in-efficiency.html.
Creating triggers
Triggers, like rules, have an available record called NEW or OLD or both and also have a variable called TG_OP, which holds the kind of operation that triggered the trigger. There are other TG_ variables provided. If you’re reusing the same trigger across multiple tables, TG_TABLE_NAME and TG_TABLE_SCHEMA are useful as well. The NEW and OLD objects have the same column structure as the table the trigger is being applied to. Trigger functions can be shared across tables. Triggers in PostgreSQL 8.4 and below can’t be written using SQL; they must be written in PL/PgSQL or some other language. Not all languages support triggers, but PL/Python, PL/Perl, and PL/R, to name a few, do. How the NEW and OLD data is referenced varies from language to language. The following list shows kinds of triggers and what data is available to each. A trigger is either a row-level or statement-level trigger and is triggered on the UPDATE/INSERT/DELETE event or a combination of those events.
- Statement trigger— Gets run for each kind of SQL statement on a table. No data is available to it, so the best you can do is log that a statement has been run and what kind of statement it is. It’s not often used.
- INSERT row-level trigger— Gets run on insert of data and once for each row. The NEW object is available to it and contains the new data. An INSERT trigger can be marked as BEFORE INSERT or AFTER INSERT. In a BEFORE INSERT you can change the values in the NEW object, and these will get propagated to the actual insert. In an AFTER INSERT PostgreSQL lets you still set values in the NEW, but this data gets thrown away and doesn’t get propagated to actually affect the insert. A common mistake is trying to set values of NEW.. in the AFTER INSERT trigger.
- UPDATE row-level trigger— You can think of an update as a delete followed by an insert. Therefore the UPDATE trigger has both OLD and NEW variables available to it. The OLD contains data that is deleted or to be deleted, and the NEW has data to be added or is added. Again, an UPDATE trigger can be marked as BEFORE or AFTER, and for BEFORE, changes to the NEW record will get propagated to the table, and for AFTER, your NEW changes go into a black hole when the trigger is completed.
- DELETE— Just the OLD object is available.
Listing D.12 shows an example trigger that will update a geography column whenever a longitude and latitude are updated or a new record is added. It will also log changes to a log table. Keep in mind that you can do other useful things such as geocode records when address information is updated. In PostgreSQL, triggers are a kind of function, and the function is separate from the actual trigger that the trigger function is bound to. The benefit of this approach is that a trigger function can be shared across many tables. The downside is that you can’t just write the trigger function as part of the table definition as you can in some other databases.
Listing D.12. Trigger function applied to geography table inPL/PgSQL


![]() We create a test table that we’ll later apply our trigger to.
We create a test table that we’ll later apply our trigger to. ![]() We create a trigger function, and the first part declares a state variable we initialize to false because we don’t want to
make any unnecessary updates.
We create a trigger function, and the first part declares a state variable we initialize to false because we don’t want to
make any unnecessary updates. ![]() We check to see what kind of event caused the trigger to fire; if it’s an insert we know we need to update if the longitude
and latitude values are not NULL. e If it’s an update, then we need to either update the geography column or wipe out the
contents. We use COALESCE here to set NULLs to -1000 so as to never compare NULLs. NULLs are tricky to compare because even
when two NULLs are compared, the comparison returns false. To shorten our code, we write the COALESCE hack.
We check to see what kind of event caused the trigger to fire; if it’s an insert we know we need to update if the longitude
and latitude values are not NULL. e If it’s an update, then we need to either update the geography column or wipe out the
contents. We use COALESCE here to set NULLs to -1000 so as to never compare NULLs. NULLs are tricky to compare because even
when two NULLs are compared, the comparison returns false. To shorten our code, we write the COALESCE hack. ![]() We then log the change to our log table. In general, logging should be done as an AFTER TRIGGER event so that the logging
sees the final record data. In this case, because we have only one trigger, it’s simpler to combine into our before event
with the assumption that represents the final data.
We then log the change to our log table. In general, logging should be done as an AFTER TRIGGER event so that the logging
sees the final record data. In this case, because we have only one trigger, it’s simpler to combine into our before event
with the assumption that represents the final data. ![]() We bind our trigger function to the INSERT and UPDATE events of the table. Note that a table can have multiple triggers,
and they run in alphabetical order based on the triggering event. Sometimes, especially if you have complex triggers shared
by many tables, it’s advantageous to categorize your triggers by functionality rather than writing a big body of logic. In
those cases you just have to keep track of the order in which the triggers are fired by naming them accordingly, say step01_...,
step02_..., and so on. Each subsequent BEFORE trigger will see the change of the previous if the previous makes sure to return
NEW; otherwise trigger execution stops.
We bind our trigger function to the INSERT and UPDATE events of the table. Note that a table can have multiple triggers,
and they run in alphabetical order based on the triggering event. Sometimes, especially if you have complex triggers shared
by many tables, it’s advantageous to categorize your triggers by functionality rather than writing a big body of logic. In
those cases you just have to keep track of the order in which the triggers are fired by naming them accordingly, say step01_...,
step02_..., and so on. Each subsequent BEFORE trigger will see the change of the previous if the previous makes sure to return
NEW; otherwise trigger execution stops. ![]() Then we test our trigger to make sure it’s working. Our select should show something like POINT(-72.555 41.3456), and we
should see two records in our log table, which includes the name of the table from the TG_TABLE_NAME variable.
Then we test our trigger to make sure it’s working. Our select should show something like POINT(-72.555 41.3456), and we
should see two records in our log table, which includes the name of the table from the TG_TABLE_NAME variable.
This example just scratches the surface of what you can do with triggers in PostgreSQL in general and PL/PgSQL in particular. Triggers are also capable of triggering other triggers so that you can have recursive triggers. Recursive triggers are particularly useful for maintaining the positioning of a parent object so that when you move a parent object, its child component parts move accordingly. We hope that we’ve demonstrated enough here for you to envision the potential it holds.
PostgreSQL 9.0 introduced ANSI SQL column-level triggers, which allow specifying a WHEN condition that can contain column names and will be executed only when the WHEN condition evaluates to true. This feature saves a bit of processing time because the body of the trigger doesn’t always need to be checked.
We’ll next cover some key elements for achieving optimal performance for your PostgreSQL database.
Performance
In chapter 9 we talked a bit about performance. Now, we’ll cover some of the loose ends we left out of that chapter.
Index
Just like in other databases, PostgreSQL uses indexes to improve performance. There are various flavors of indexes to choose from, as well as various additional options you can specify for an index that you may or may not find in other relational databases. The key ones are listed here:
- Partial indexes— These are indexes with a where clause where the WHERE constrains the data that’s actually indexed.
- Functional indexes— You can choose to index a function calculation such as UPPER, LOWER, SOUNDEX, or ST_Transform, where the arguments to the function can be any of the columns in a row. You can’t go across rows, but your function can take multiple columns. The function must also be marked immutable, which means given a set of inputs, the function is guaranteed to return the same output.
- Kinds of indexes— These include B-tree, Gist, GIN, and Hash. The most common is the B-tree index. The kind of index controls how the index leaves are structured.
B-Tree Index Gotchas
A B-tree index is the most commonly used of all index types in PostgreSQL. Under certain conditions where you’d expect it to be used, it’s not. These conditions are probably very unintuitive to people coming from databases that are not necessarily case sensitive.
- Trying to do a functional compare for example, UPPER/LOWER— Some people think that when you do a query upper(item_name) = ‘DETROIT’, then that condition should be able to use a B-tree
index of the form
CREATE INDEX idx_item_name ON items USING btree(item_name); Well, it can’t, because your compare upper(item_name) doesn’t match what is indexed. You need to change the index to
CREATE INDEX idx_item_name ON items USING btree(upper(item_name)); - The varchar_pattern_ops gotcha—If you want to do something like this
WHERE upper(item_name) LIKE 'D%' then you can’t use an unqualified B-tree. You need one with varchar_pattern_ ops. Prior to PostgreSQL 8.4 a varchar_pattern_ops was not able to service an equality like the previous one. To handle both, you needed two indexes in prior versions. Read Tom’s note in this thread of our article to get the gory details. http://www.postgresonline.com/journal/index.php?/archives/78-Why-is-my-index-not-being-used.html#c503
Functional Index Gotchas
Functional indexes (sometimes called expression indexes) are indexes that are built from a function rather than raw data. Common functional indexes are things like
CREATE INDEX idx_item_name ON items USING btree(upper(item_name));
The main gotcha with functional indexes is that you can only index functions marked as IMMUTABLE. This means the function outputs don’t change given the same arguments. The main reason for that is that once an index is calculated, the index value is changed only if the input fields to the functions change.
You can, of course, lie about a function being immutable by marking it as immutable to get around this restriction, and PostgreSQL, even as of 8.4, will not try to validate whether it demands dynamic things such as tables. We demonstrated that with doing an index on ST_Transform. If you do such a thing, you need to be careful to ensure that at least in most cases the function is immutable.
The other gotcha with functional indexes is that if you redefine a function to do something other than what it was doing before, namely changing the output value, PostgreSQL will not go back and reindex the affected tables. So if you change a function used in an index and you know that change will affect output, you need to go back and reindex the affected tables.
It’s fairly easy to determine which tables are affected, particularly in pgAdmin, using the dependents tab of a function.
Summary
In this appendix, we’ve given you a foretaste of the uniqueness and versatility of PostgreSQL that makes it stand apart from the other databases you may be familiar with. We’ve also demonstrated its less nice and cumbersome features such as the rights management in pre-PostgreSQL 9.0, which has been much alleviated in PostgreSQL 9.0. This is by no means the extent of what is offered by PostgreSQL, and we encourage you to reference its very detailed extensive volumes of manuals available when you need to learn more about a specific feature.