
![]()
Defining Your SharePoint Service and Service Tiers
It is not enough to be busy. So are the ants. The question is: what are we busy about?
—Henry David Thoreau
Throughout this chapter, I emphasize the idea of operating SharePoint as a service that you offer to internal customers within your organization. I discuss the need for explicitly defining the service you offer in order to operate in an intentional manner rather than constantly responding to issues and requests in a reactionary way.
I provide considerations to guide an initiative you can take to establish different service levels that target different organizational needs. Next, I discuss how to organize your service request tickets, from how to prioritize them to how to set expectations on what the different priority levels mean. Finally, I discuss different techniques and tips for designing and implementing a chargeback-funding model for your SharePoint service.
One essential concept I want you to take away from this chapter is that by treating your SharePoint deployment as a service that you offer to your internal customers, you will find that you will more naturally focus on the value your SharePoint service provides to your organization. This focus will help you determine boundaries for the service and identify priorities for responding to issues and enhancement service requests.
After reading this chapter, you will know how to:
- Make the scope of the SharePoint service explicit and intentional
- Establish different service levels to target different needs
- Organize and prioritize service request tickets
- Design a chargeback funding model
- Establish and schedule maintenance windows
Why Define Your Service?
When I managed a global SharePoint deployment, there were times when it seemed like I was always playing catch-up with SharePoint. My users had a remarkable ability to dream up all the magical things they thought SharePoint should do for them, and they were not shy about requesting more features and new functionality. To add to the complication, users from different business units or departments each wanted different features, and each believed they should be the highest priority.
Who were my internal customers and what was it that I was offering them? This question is different in every situation. To answer it I had to put a box around what SharePoint currently did for our organization and what it did not do. Essentially, I found a solution in treating SharePoint as a service my team offered to the organization, a service the organization could consume if what the service offered met their needs.
This shift in perspective laid the groundwork for a defined, intentional focus – not just for my team, but also for our internal customers who were consuming the service that we were providing. Once we began with defining what we offered and we started associating times and performance levels around the service, we could show how we divided and balanced our limited capacity across our customers. Our operational attention then moved from a reactionary sense, one always under pressure and jumping around between requests, shifting instead into an intentional focus.
Defining the service makes what you offer through SharePoint explicit and intentional. It provides structure and focus, not only for the delivery and operations team, but also for those using the service. A defined service sets and manages expectations, because users will not have to wonder what the purpose of SharePoint is or wonder about all the other magical things that SharePoint can do for them. They can see the strategy and the scope of what the SharePoint service provides, and this gives them a context to frame their expectations. Later in the book, I discuss topics such as how to expand your SharePoint service and how to design a roadmap for it. These topics will build on and expand your SharePoint service description, and this will further help to manage expectations. For now, let’s start with a baseline to establish scope and define SharePoint as a service you offer to your internal customers.
By defining SharePoint as a service and what that service entails, you can use this scope to set expectations with system users. In the process, you begin to move from chaos into cosmos. Your first step in this process is to adopt a service focus.
Adopting a Service Focus
When you adopt a service focus, you shift your perspective to consider what your purpose is with your SharePoint deployment. Rather than SharePoint for the sake of SharePoint, a service focus looks at what SharePoint accomplishes, or in other words, its outcomes. You can build a service focus by basing your view of SharePoint on the value it delivers or will deliver to your organization. More specifically, you can adopt a service focus by thinking about SharePoint as the value it delivers to your users.
Your users do not want to constantly face the IT department and hear “no” in response to their ideas or needs. They might prefer to just have the tools they need available or be empowered enough to make adjustments to fit the service to how they want to work. Supporting this can seem overwhelming on the surface. You might wonder how users could survive making their own decisions. You might imagine the possibility and shudder: users running wild, doing whatever they want. I am not talking about opening the floodgates and handing over the keys to your farm, but there are sections in this book that address the degrees that you may want to empower your users to do things on their own.
Whether you are empowering your users with control of their own sites or you are limiting what they can do to manage that control for them, you are still providing a SharePoint service to your internal customers. In both situations, you define a service you offer to the users: one is more lenient and allows users greater control over their own experience, and the other is stricter and standardizes the user experience within a limited range. Of course, your service can be somewhere in between, or even more extreme, depending on your needs and your organization. There is no one correct way to offer a SharePoint service, as long as it is meeting the needs of your organization. The important point is to define what that service looks like.
You can take a few different approaches as you define your SharePoint service. For an existing deployment, conduct a usage audit where you analyze how users are using the system and identify where they are receiving value from SharePoint. Who uses SharePoint and why are they using it? These are your customers, your internal customers who receive value from the SharePoint service you offer them. Through the process of identifying your customers and the SharePoint service you provide them, you will naturally align their needs with the service you provide.
YOUR SHAREPOINT SERVICE AND COMPETING SERVICES
You have competition for your SharePoint service. Sometimes internal customers can simply outsource their need or use an alternative product such as an open source wiki. Even if you mandate and try to block alternative products, you will still face competition. Users seem to have a knack for finding workarounds to any constraints you try to implement. Your users will find creative ways to use things such as using network shares, free email services, outside survey services, and file sharing services. Make no mistake: the workarounds your users find and depend on are your competition.
It may not seem like a big deal on the surface; after all, those alternatives that users find seem to be working for them. The challenge is that through these workarounds, these users are using outside services that are probably not a part of your IT strategy. Do you support any of these free cloud solutions on the market? Are you confident all the data is secure and accessible? What happens when a user leaves the organization? Is there a process to take control of their content stored in these services and protect any intellectual property?
As you can see, this can be a very big deal. You probably do not have the luxury of ignoring these outside systems simply because they are “not supported” or you assume users use them at their own risk. These kinds of things always seem to have a way to come back and bite you – sometimes it is just a nuisance, but other times the bite can happen in the middle of a catastrophe.
This is why I look at these alternative systems as my competition rather than dismiss them with a chancy attitude that IT does not officially support them, and therefore they are not my problem because we do not support them. They are my problem, or typically, they will eventually become my problem. The easiest way to stay in front of them is to focus on providing a SharePoint service that meets your users’ needs. It involves offering a better product: a better service.
To provide your SharePoint service, you must also consume services from other groups that underlie or support SharePoint. These other services are things like consuming SQL Server as a database service that the SharePoint infrastructure can utilize. I will come back to this idea of identifying the inputs that run a SharePoint environment, particularly when I discuss roles and responsibility in Chapter 4. For now, just think of those other components of the environment that SharePoint relies on to provide services that support and enable SharePoint to provide its service.
I look at SharePoint as a service that meets the needs of an organization’s users in the course of performing their duties. I do not say that it will be everything to everyone, because it will not, at least not all at once. I come back to this idea of your limited capacity to enable SharePoint to be all things to all people, particularly in Chapter 7 when I discuss the process of creating a SharePoint roadmap. In the meantime, you will still need to put a box around what SharePoint service you offer and what the service will entail.
Determining the Scope of Your SharePoint Service
What is the SharePoint service that you are offering your internal customers? What capabilities does your SharePoint service include? I have noticed these can be difficult questions to answer, because SharePoint offers so much to its users that it can be tempting to not want to limit it.
The vastness of the features and capabilities that SharePoint offers can be both a blessing and a curse at times. It is a blessing because SharePoint packs a lot of punch; it provides a single platform for a significant number of solutions. Rather than a hodgepodge of different products and different vendors, SharePoint provides an arsenal of functionality. You might say the curse is also that it offers so much; it taunts you with all the solutions it can deliver. I often find customers in a common situation where so many capabilities in SharePoint entice them, and they end up torn between them all and just do not know where to start.
Often times, the reality is you have to draw the line somewhere. If you are already up and running, there is a chance that you have defined the scope, whether or not it is a desirable scope. Discovering this scope involves looking at the system to determine a list of all the enabled features, observing actual usage to determine what the users use it for, and interpreting this information to understand the nature and scope of your SharePoint service. This information will provide you with an as-is state of your SharePoint service, and you can use this as a baseline for all your other governance actions and decisions.
New projects are a little different. Sometimes someone funds a specific scope and the project has a statement of work associated with it. Perhaps you have a project like this and you reached for this book to help you through your project. I hope that you have not bitten off more than you can chew, but if you have, consider breaking down that project into phases or mini projects.
Now how do you put a box around one of those pieces? My friend Cat once used a saying that I think applies here: “it’s hard to only turn the tap on a little bit.” Indeed, as I have already mentioned, SharePoint is a wonderfully feature-rich product, and it is hard not to want it all. You need incredible discipline to hold yourself back and remain focused on delivering an initial set of capabilities.
There are several reasons people might want a large scope for their first SharePoint release. The following lists some popular reasons I often see:
- Consulting firms want a large scope so they can secure their own delivery pipeline;
- Project sponsors often want to make a big splash with a wow-factor in a release that they can attach their name to;
- Users are excited about all the different SharePoint features and cannot prioritize between which ones they want first;
There is no shortage of pressure to make your first release huge. I like to think of it as a death by a thousand paper cuts. Each marginal addition to the project in itself does not seem too big, and the value it would add feels desirable. So, what is the harm in allowing these additions? They bloat and delay the project, and that adds risk and slows down the process. Each paper cut might only come with a small sting, but they all add up and work against you. With a regular delivery cycle, you can avoid loading up any individual delivery cycle.
You should deliver quickly, deliver frequently, and deliver incrementally. One of the things I love the most about SharePoint is how it can grow and adapt over time. It is not like other systems that require you to decide on everything upfront. SharePoint does not force you to release the majority in the first pass. You can release the core infrastructure, with a baseline and barebones deployment, and then rapidly and regularly enhance your deployment with very little risk and minimal interruptions.
An evolving approach to your SharePoint initiative carries much less risk than a titanic-type of project. Think of the Titanic for a second: it was huge, well-funded, and supposed to be unsinkable. Even still, there are things you cannot predict, you just do not see them coming until the iceberg is dead ahead. If your ship is too big and you are trying to sail too fast, you practically assure yourself that you will hit the iceberg. Smaller ships might not carry as much, but without all that weight, they can get going quicker and are much more maneuverable when hazards appear in their path. Aim for your SharePoint projects to be less like the Titanic and instead to more closely resemble a speedboat.
Okay, assuming I have succeeded at convincing you to set a scope, how do you set the scope of the SharePoint service? It is a moving target, as I hinted, and you are going to grow and evolve it over time. Therefore, from a big-picture perspective, the grander scope is what SharePoint will eventually become at a point in time, but your initial scope is the first step in that direction. You might start with something easy, something that could deliver a lot of value to your customers in a short period.
![]() Note Please see Chapter 3 where I discuss strategies for expanding your SharePoint service by adding features over time.
Note Please see Chapter 3 where I discuss strategies for expanding your SharePoint service by adding features over time.
I use the metaphor of low-hanging fruit: what is on those lower metaphorical SharePoint branches that I could reach quickly and easily? There is no one-size-fits-all answer, as with any kind of design activity, since your choice depends on your unique situation and individual priorities. However, I do not use that as an excuse to brush you off; I am here to give you answers.
Say, for example, that team sites turn out to be that low-hanging fruit for you. Your users currently use file shares, but their file sharing experience is not as rich or collaborative as it could be. You want to offer them the ability to check out documents for editing, to track versions, to comment on changes, and even to set notification alerts when there are changes. SharePoint does this very well, and this scenario makes for excellent low-hanging fruit to pick off.
Now, how do you draw a box around delivering team sites to provide a richer document collaboration experience for your users? First, you need to get servers deployed and SharePoint installed, then you need to generate a website with a URL the users will enjoy, and then you need to decide whether the users can provision their own sites or whether they will request them and have the service desk create sites for them. There you have it: low-hanging fruit that you can deliver quickly and that will provide immediate value to your users.
There is no branding, no site templates, no development, no workflows, and no bells and whistles. You only have the core of SharePoint team sites, and you would have made these sites available to your users in almost no time. Default team sites are already overflowing with bells and whistles built in to them that will excite users who are used to using file shares. Users can assign tasks, create discussions, and they can even blog and send out surveys! There are plenty of features already available to keep them excited, so you do not need to bloat your initial SharePoint service project scope and delay making this value available to your users.
Deliver the value as quick as you can, and then extend and enhance it in a follow-on phase. A phase two for this example might include the following:
- A designer can design the user interface colors and logos, and all that glossy eye-candy that makes users feel good.
- A developer can attach a master page and themes to new sites by using feature stapling.
As you can see, it is very easy to apply branding after the fact when SharePoint sites are already in production. I assure you, you will not damage users of those sites because they have seen their SharePoint site without your custom branding. Instead, you can send out an e-mail to let them know the exciting news that their already excellent SharePoint site is about to get even better – better looking!
The bottom line is the scope you set for your SharePoint offering is going to grow over time. I discuss this growing scope in more detail in Chapter 6 when I discuss how to create a SharePoint roadmap. In these early days, you just need to capture either what your service already offers or the initial low-hanging fruit you plan to offer. For some, that low-hanging fruit can be team sites as in the example I gave earlier. For others, it might be enterprise search or intranets or whatever fits your situation and priority. The concepts are the same whichever SharePoint capability you choose to deliver first.
After you have a scope, you will know what it is you offer. Part of knowing what you offer requires you to understand your customers and to know what they need from your service. What if your customers are diverse in their needs and this diversity makes it difficult to set a scope that works for everyone? In those cases, you might consider designing multiple scopes that essentially provide multiple service-levels to address multiple needs.
Identifying Different Service-Levels for Different Needs
Every customer is different, and that is true whether your customer is an external customer or whether they are your internal users. They all have different needs, different abilities, and different priorities. Each has a unique combination of the three that they bring with them as they consume your SharePoint service, and they have their own expectations that they want the service to accommodate.
Trying to individualize the service to please each of these needs can quickly overwhelm you. If you try to be everything to everybody, you end up risking not being much to anybody. You simply cannot scale the service if you consume yourself with focusing on every individual user, and so you need a way to group users into groups with common needs. At the same time, you do not want to walk away from these customers or develop a militant attitude where they have to conform to whatever you offer. No, you still want to meet the needs of your customers and provide a valuable service that will support them in their daily roles and job functions. Instead of individualizing the service that you offer and making it specific to each person, you can merely give the impression of an individualized service.
How can you give the impression of addressing different needs? You can offer a few flavors of the service where you group together common functionality and usage characteristics into a service tier. This allows you to focus on the heaviest usage to get the biggest returns for the time you invest, while you also provide a repeatable and low-maintenance set of offerings that would satisfy the majority of the needs with the least amount of involvement from you. You can then divide and prioritize your customers by grouping them in appropriate service tiers.
Of course, a typical customer will want to be a tier one customer, because who does not want all the bells and whistles, and who would want to be a lower priority? There are costs associated with this, where the greater the number of customers receiving tier one service, the greater the overall costs. If you have an infinite budget, or at least you have a budget that is sizable enough to accommodate this, then this might not be an issue for you. On the other hand, if you want to limit the scope of your service to fill only a basic need for everybody, considering different service levels might not be an issue for you. However, if you have to squeeze every available means of efficiency out of your budget, then offering different service levels may be a solution for you.
How do you encourage customers to accept an appropriate service tier for their usage? One approach is to charge them through chargebacks based on their usage and their level of service. Later in this chapter, I discuss approaches and considerations for implementing chargebacks. If you charge your customers directly for services they consume, they will naturally gravitate to the most appropriate service tier that meets their needs. Unless, of course, they are the ones with the large budget and they would prefer to subscribe to the whole package rather than invest the time to decide what they actually need. In either case, your service level is funded and sustainable.
I typically find when chargebacks are involved, customers become much more sensible about their needs for the system, and their expectations become grounded within the service definition. For me, keeping their expectations aligned with the service definition provides one of the most significant benefits. Otherwise, they may not realize the costs associated with their requests, which would put the obligation on me to determine if the business value derived from the request outweighs its costs. When you use chargebacks, the customer evaluates and makes their business value decisions directly based on their needs and available budget. Of course, you need to anticipate what types of value to make available and help articulate that value to your customers, because you are the expert that they rely on to provide the service.
![]() Note Please see Chapter 3 where I discuss how to map SharePoint features to business value.
Note Please see Chapter 3 where I discuss how to map SharePoint features to business value.
Another approach to defining service levels if chargebacks are not an option involves monitoring usage and identifying those heavy users. I typically consider these heavy users of the SharePoint service as my top customers. If I do not have a chargeback model where customers can subscribe and self-identify to their most appropriate service tier, then I identify them based on their actual usage and adoption rates. I use a number of measures to identify these customers. Primarily, I look at the number of active users that use their site and the amount of content they store in the site. These two metrics give me a reasonable indicator on who my biggest and most active customers are. I would identify them by running a script on the server that lists sites by size or activity, ordered with my best customers on top.
In SharePoint 2003, I used a C# console application I wrote that used the SharePoint API to gather site data and produce a list of sites in the farm. By SharePoint 2010, I switched to using PowerShell and began to use some of the built-in analytics reports for this purpose as well. I have been analyzing SharePoint farms like this for ten years now, where I produce a list of the largest and most active sites on which I focus my attention. I typically do not spend my time on any of the other sites until they grow to a size and level of usage to warrant my attention, unless of course a support issue comes up that a first responder escalates to me or if I want to analyze why adoption rates may be lacking. This strategy serves me well and allows me to get the biggest return on my time investment because I spend my time impacting the largest customers.
If I do not have a chargeback model, I start off all my customers with the same basic offering. Usually this means providing a basic SharePoint team site with the core functionality. Then, as their adoption rates grow and they look to expand to consume more features within the service, I increase their site quota and enable more features. This sounds obvious, because that is how any SharePoint site would grow. The keyword in that description was quota and how I use it may not have been as obvious. I do not consider quotas as a constraint or a means of limiting my customers. I think of quotas as merely a yardstick to identify what stage a site is at in its growth, or what a site’s service tier is. I do not use quotas as a means to restrict users; I use them as a growth signifier and a tool that allows me to adapt to increasing usage. Sometimes I might also use them to alert me where to intervene and provide guidance when a site is growing in an inefficient manner.
The following PowerShell script lists SharePoint 2013 sites in a farm and sorts them from the largest to smallest based on the amount of content they store. I use this as a quick and easy method to get a list of all site collections on a server and their size. Using the output, I can direct my attention to the sites at the top of the list, those sites storing the largest amount of content. I can use this in different scenarios, for example, if I want to audit storage to identify opportunities to reduce any wasted content storage space.
Get-SPSite | Select Url, @{Label="Size";Expression={$_.usage.Storage/1MB}} | Sort-Object -Descending -Property "Size" | ConvertTo-Html -Title "Site Collection List" | Set-Content SiteCollectionSizeReport.html
Designing Your Service Levels
You can name your services levels based on numbers, such as tier one, tier two, and so on. I find numbering becomes pretty generic and boring; but even worse, I find when you number your service levels you constrain yourself within the numbering system. I feel constrained in this numbering system in two ways: numbers imply a hierarchy or order, and this becomes problematic when you want to include parallel tiers that offer the same service level with different feature sets; and the second way is that numbering makes it difficult to insert additional service tiers later on, such as offering tier 1B.
I much prefer names for service tiers, and the most common names seem to be platinum, gold, silver, and bronze. You might use other names that you find more descriptive of their services, such as: basic, extranet, portal, and repository. Alternatively, you might use other names that you find descriptive of their server resource requirements, such as: shared, semiprivate, isolated service applications, private web application, and dedicated farm. You might even mix and match between these naming strategies. All these naming strategies are descriptive and can be meaningful to customers, so pick one that resonates with your organization and the type of service tiers you want to offer.
I generally start with a basic service tier, and this typically includes a default SharePoint team site with my most restrictive site quota applied. I use this service tier to include all the team sites that users create using the self-service site creation built-in to SharePoint. This allows users to self-provision a generic site on demand. SharePoint provisions these sites under a managed path and they share the service applications associated with their web application. Users can grow these sites to several gigabytes in size, customize the visual design, and add additional functionality. They might add custom functionality using a user solution package or a SharePoint 2013 App from the SharePoint Store or from an internal Apps catalog. Depending on how I breakdown the service tiers, I may offer enough in this basic tier to accommodate these types of needs so that I can meet the needs of a majority of my users, particularly if I have a user base who is reasonably self-sufficient and who wants to be empowered to manage their own sites.
The basic service tier can offer a lot of bells and whistles, but in order for it to scale and be largely self-service driven, user sites on the basic service tier need to share the root URL and provision their sites under a managed path. Most users will not care and probably will not even think about this, but some will prefer an easy and short URL. I often call these vanity URL requests. On its own, it is probably not reason enough to break up sites at the basic service tier to start offering individual host names, but you can still satisfy the majority of your customers who do ask about a vanity URL. In my response to these requests, I recommend provisioning the site with a normal URL under a managed path, and then offer a redirector service that uses DNS, IIS, or a simple ASP.NET application that receives requests made to the shorter vanity URL and then redirects them to the site collection’s actual URL.
VANITY URLS AND A CENTRALIZED REDIRECTION SERVICE
One option for redirecting vanity URLs to a site collection’s longer URL under a managed path involves adding a redirect rule using the IIS URL Rewrite tool. I create the rules to do a redirect to the URL and pass the request on to the SharePoint web frontend server. You can download and learn more about the IIS URL Rewrite tool from the following URL: www.iis.net/download/urlrewrite.
I have also seen customers implement a centralized URL redirection service where they create a DNS entry for a simple URL, such as http://go. They then build a URL redirection application on the site where they host this Go URL. They design it much like how a public URL shortening service would work and they use it for site or page references, people profile references, map references, and the like. They can advertise a posting in an elevator or a hallway with a short and easy URL like http://go/102, and use that to redirect requests to the longer URLs.
You can host this centralized Go URL redirector application in IIS using asimple ASP.NET application. I would create an ASP.NET application to provide a form where users could create their own Go URLs, and store the URL redirection list in a Microsoft SQL Server database to maintain a dynamic list of URLs.
You might be wondering, if the basic service tier covers almost everything, why even have different service tiers? I like to think of the basic tier as the cruise control of the SharePoint service, that part of the service that takes no marginal extra effort to add an extra customer because they just use what is there and it just works for them. We can meet the majority of the demand with the basic service tier while it consumes a minority of our time and service delivery resources. It can deliver a majority of the demand, but it might not deliver a majority of the potential business value. It may keep day-to-day operations running smoothly, but being a basic service offering, it does not go for the gold. For that, a customer needs to opt for a gold service tier.
I find common examples of what a gold service tier could offer would include things such as a dedicated web application to host a custom portal, isolated service applications, a higher content backup frequency, a larger user audience for content, and the like. These higher service tiers are typically for those internal customers who want to build a department portal site or some other type of custom application hosted on SharePoint. They could be for a portal that hosts the expense report forms and processes any workflows, a travel approval and booking portal, or an enterprise learning management system. One could host a Human Resources department portal that contains several custom built applications such as those related to performance reviews and career planning. These are all applications that add rich business value on SharePoint and they might require more of your involvement.
You free up some of your availability to focus on these higher value service offerings by meeting a lot of the more operational or standard demand in the basic service tier. Your basic service tier can consist of those features that SharePoint delivers with ease through its core team site capabilities and the services that support them. This basic service tier can enable your users to receive value consuming the capabilities in their sites – capabilities that can often meet most of their needs. With many of their needs met, you can then focus your attention on opportunities to expand the service.
As your internal customers adopt the SharePoint service, some will have very straightforward requirements, while others will have more complex or more involved service needs. You can provide your customers with a basic service to start, and then offer them different options so they can increase the range of capabilities available and the degree with which they can build a custom application. As Figure 2-1 shows, the service level increases for a particular site based on increases in the following areas:
- A higher number of users using the site
- A larger amount of content in the site
- A wider range of features available for the site
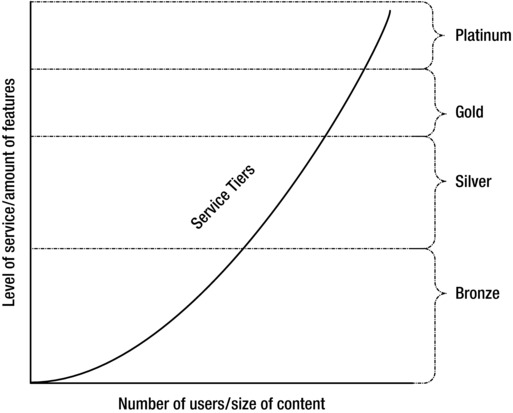
Figure 2-1. An example of the service tier relationship
Organizing Your Service Requests
One issue people face with service requests involves a client’s service request ticket handling, or lack of handling to be more precise. For example, when a user experiences something or an inkling for something that he or she wants to experience comes to mind, they will open a service request ticket. Of course, a user thinks their service request is important, otherwise, the user would not have bothered to open the ticket, and so they assign a high priority to the ticket. Then the process assigns someone to the ticket, but that resource does not change the priority level, likely because the support resource did not want to insult the requestor. Now you have a high-priority ticket that is active and assigned to a resource, but maybe it is something that is a nice-to-have feature or a request for functionality that is outside the scope of the service you offer.
How do you get around this? Service requests are going to come as people run into issues with the system, and as users imagine all sorts of things that they would like the system to do to support their job functions. If an issue affects a user, he or she is naturally going to perceive it as having a high impact. The user just does not have a global view of the SharePoint service and is typically not aware of the costs behind their request. In the case of requesting new functionality, a user might not even know whether the functionality will solve their problem or even be feasible, as he or she may have just seen a demo and jumped to the conclusion that what they saw would benefit your organization as well. On the other hand, a user may request new functionality that is not the optimum solution for the problem they are trying to solve. If an expert does not analyze the user’s actual problem and the team just jumps to whatever functionality the user requested, then the team trusts a user to play the role of a solution architect; yet an ordinary user does not have the same SharePoint expertise as an actual solution architect.
I hate to sound too cynical about service requests that users submit, but I do think users become a little irrational when it comes to filling out request tickets. Whether that comes from their limited perspective of the enterprise SharePoint service or their ignorance toward the costs associated with their requests, I do not know. On the other hand, I do not think those issues should even be user problems, because they have their own jobs to do and they should rely on us to respond to their requests by taking an enterprise view of the system and its costs. We are there to make sense of their requests as the IT professionals, to analyze and understand the business function that they are trying to achieve, and then to design a solution or provide guidance in a way that helps then perform their duties.
I am digressing a little and drifting off into talking about feature requests, which are one aspect of service requests, but service requests also encompass errors with the system and troubles that your users face. The idea I am getting at is the same for all these types of tickets. Specifically, users rely on IT support professionals to properly prioritize these tickets and to consider them from a perspective of the whole system and all its users rather than having an automatic reaction for each request. The users rely on the service desk to manage the demand and to coordinate all the requests. As such, the service desk needs to be bold and manage the priority level associated with a ticket.
![]() Note Please see Chapter 9 where I discuss strategies to manage enhancement requests and prioritize them through a funnel to match your delivery capacity.
Note Please see Chapter 9 where I discuss strategies to manage enhancement requests and prioritize them through a funnel to match your delivery capacity.
Be bold: if a ticket is not actually a high priority, then assign the appropriate priority level to the ticket. This seems so obvious, but it is not as obvious as you might think. You might be surprised at the number of tickets that just automatically go through using the default priority level or whatever level the requestor assigned. A functional service request process includes a triage step where a resource assesses, prioritizes, and routes the ticket to the appropriate group.
Figure 2-2 illustrates an example of a service request workflow for a ticket handling and escalation process. This example uses the frontline service desk to triage tickets and attempt to resolve them if possible. It then routes the ticket to a support team for the application involved and escalates to an escalation team if necessary.
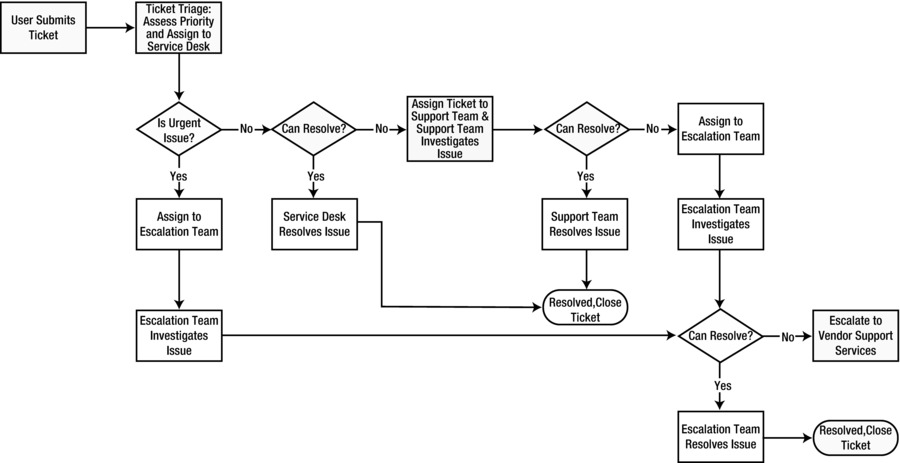
Figure 2-2. An example of a service request ticket workflow process
![]() Note For SharePoint vendor escalations, my customers use Microsoft Services Premier Support. When they have an issue that they cannot resolve internally, they escalate the issue to a Microsoft support resource by opening an incident with Premier Support. For more information on Premier Support, see the following Microsoft Services website: www.microsoft.com/microsoftservices/en/us/premier_support.aspx.
Note For SharePoint vendor escalations, my customers use Microsoft Services Premier Support. When they have an issue that they cannot resolve internally, they escalate the issue to a Microsoft support resource by opening an incident with Premier Support. For more information on Premier Support, see the following Microsoft Services website: www.microsoft.com/microsoftservices/en/us/premier_support.aspx.
If you are an existing Premier Support customer, you can submit and manage your incidents online through the following Premier Support website: https://premier.microsoft.com.
Prioritizing a Service Request Ticket’s Priority
If you cannot trust users to prioritize their own tickets, how then can you trust first responders and frontline service desk staff to prioritize a ticket properly? How do you ensure consistency across the team? You need a rubric that defines what each of the priority levels are and the threshold criteria the ticket must fit within in order to assign it to a certain priority level. Your rubric needs precise thresholds for indicators you measure, and of course, those indicators have to be measurable.
One indicator that I find telling of a ticket’s priority is measuring the number of people affected by the issue. It could be just the one individual submitting the service request, a small workgroup they are collaborating with consisting of eight people, their department consisting of one hundred people, or the entire organization. When you consider these different thresholds, they should illustrate for you the different impacts a service request has from an enterprise point of view, and therefore provide a consistent way to assign a valid priority to the ticket.
Determining the number of people affected by an issue provides a reliable measure to determine a priority level to assign to a service request during its initial triage. This also takes a global perspective, as its thresholds will be in proportion to the size of the organization. For example, in a smaller organization with fewer than 1,000 users, the thresholds may range from a single user to all 1,000. In contrast, a larger organization with 100,000 users or more will spread those same thresholds over a much larger range. I have found that these proportions also represent the organization’s own perception of the priority for a given number of users. That smaller organization would feel the effects of 500 people affected by an outage, half of their total users, and they would prioritize a resolution with much more urgency. The same number of users for the much larger organization would still be important, but the criticality would not be to the same degree because the affected number of users only represents just one half of one percent of their total user population, rather than half like it did for the smaller company.
Another metric I use to determine the priority of a ticket is the potential revenue loss when the service request is in relation to an outage affecting external customers, such as in an example of an ecommerce website. In a similar process as determining measurable thresholds for affected users, I would determine the thresholds of potential revenue loss ranging from none through to having all revenue halted. Any revenue loss is important, so I am not suggesting that you go golfing if there is anything less than a 20 percent revenue loss, but you do need a way to capture the degree of impact. Having these types of reasoned measures and thresholds will help you keep the incident in perspective so you can react appropriately.
It may sound counter to what I have been saying about avoiding subjective or arbitrary measures, but another factor I consider in determining the priority of a service request is the importance of the requestor or the group affected by the issue. I do like to have a list of VIP customers, and these customers typically consist of executive sponsors who provide funding and support to the SharePoint service, other executives who have significant influence over the service, and generally other heavy influencers. The politics of an organization do not stop with SharePoint, so I always try to be conscious of any politics that may affect our service delivery. So if a VIP opens a ticket for a document that he or she accidently deleted, and recovering that document will have a higher cost involved than it would for them to simply re-create it, I would probably still prioritize this higher than if they were an ordinary knowledge worker who was not on my VIP list.
That leads to another measure for priority: comparing the cost to re-create versus the cost to recover content. In a more general sense beyond the production cost of content, you could measure the value of the content’s availability. I like to consider both the cost and value, depending on the circumstances. I use cost as a measure for content generated in the daily operations where users can easily re-create it or for content that is not truly mission critical and time sensitive. This provides a straightforward decision metric to use in prioritizing the service request. On the other hand, the content may be mission critical for competitive or other time-sensitive reasons. This type of content fits better with measuring the value it provides rather than the cost to produce, because it is providing ongoing value.
After you have determined the value that the more critical content provides, you can use this in determining the priority of the service request. Now ideally, you have identified that content before an outage or before a user submits an urgent service request, so the triage process does not stall the ticket. Some examples would include disaster recovery or major incident response plans and procedures. These are valuable pieces of content when the users need them, and in the event of a major incident, they will be critical to make available rather than consider re-creating. You can identify that type of content and possibly store it in a designated database for critical content, and this could be the first database you restore in the event of a major incident.
Another case you may use to classify content is by considering the sensitivity of the content itself, and you could use that to help determine the priority of a service request ticket. For example, knowing an incident exposed sensitive content containing personally identifiable information provides an indicator that you might use to determine the priority in responding to the related service request. Content cost, critical value, sensitivity, security, and urgency provide measures you might use to determine the service request ticket’s priority, and most importantly, you can measure them all without relying on a lot of subjectivity.
Now that you can prioritize your tickets with a valid priority, you can prioritize your response. When you know the thresholds of ticket priorities and the rubrics that define what constitutes each priority, then you can have confidence in your ticketing system and you will have the right expectations for how it functions. Your users can have confidence in the process, and once you have the priority levels well defined with all the metrics that go into them, you might share this information with your users to help set their expectations as well. However, knowing the priority levels and how they are determined will mean little to your users if you do not also associate what they should expect with those priorities.
![]() Note You may also use your service request tickets to capture feedback. That feedback might be direct, such as when a customer submits a ticket specifically to offer feedback on the service, or it could be indirect and accessed by analyzing the service requests and their trends. Please see Chapter 8, where I discuss how you can promote a feedback process and use this to capture customer feedback.
Note You may also use your service request tickets to capture feedback. That feedback might be direct, such as when a customer submits a ticket specifically to offer feedback on the service, or it could be indirect and accessed by analyzing the service requests and their trends. Please see Chapter 8, where I discuss how you can promote a feedback process and use this to capture customer feedback.
Using Service Request Priorities
It is nice to have a high-priority ticket and to acknowledge it is high priority, but what do you do with it then? What does classifying a ticket as a high priority even mean? Does it mean you are going to halt production and bring in whatever outside help is available to resolve the issue? Does it mean you are going to slot it into the queue and get to it when you get to it, whenever that is?
When I first considered this idea of associating some response protocol to a priority level, I decided to include response times and targets for the first responders to respond to the incident. This was a good start, but it still did not resolve the issue. One of my stakeholders, Doug, showed me the limitation of only focusing on a response. He was an operations director, with whom I was negotiating through the details of this new service request process as part of a service-level agreement he would be accepting for the business. The issue, as he expressed, was that it offered him no assurances of when an issue would be resolved, and therefore, did not offer him much at all. “I got it!” an escalation engineer could exclaim, and then they could go to lunch. The response measure only measured how quickly the process would assign a ticket to someone’s queue, and not how quickly a resource would work to resolve it.
Measuring how quickly the process assigned a ticket was still an important measure in the overall process, so it is something I include. In order to set expectations on when a ticket would be resolved, or at least what the targets for a resolution are, I found it is also important to include these ticket resolution targets as part of the process. Now, it is hard to predict how long a resolution will take without investigating an issue and understanding the impact, but I can set targets. I cannot always hit the targets, for the same reason it is hard to predict the resolution in the first place, but if I set generally achievable targets for each priority level then I can meet most of them. The ones I cannot bring to a resolution within the target are often indicators of deeper underlying issues the incident has uncovered.
![]() Note Please see Chapter 6 where I discuss topics related to measuring targets in more detail.
Note Please see Chapter 6 where I discuss topics related to measuring targets in more detail.
My first goal was to have the service request ticket assigned to a resource and have them review the issue within the target time window. When team members felt a sense of importance to take ownership of a ticket in the queue and quickly review the request, the triage process became very efficient. The tickets were no longer getting lost in the queue among a pile of incorrectly designated high-priority tickets. Instead, support resources read the tickets right away, and if the issue had a quick and simple resolution, they were resolved and closed. If the ticket was a valid high-priority or a critical incident, the support resource was immediately active with a response and they would add an initial investigation and resolution plan to the ticket’s notes.
With a valid and well-defined priority ranking system, team members know where to focus their attention and when to drop what they are doing when they need to respond to a critical incident. This is what makes the system flow, and without an effective system to process them, the tickets can easily just pile up.
I still treat my e-mail the same way I used to handle service request tickets. I like to process my e-mail as quickly as possible. For many of my e-mail messages I can delete them right away, and I do. Some need a quick response, so I quickly respond and then probably delete them too. Some require more time to plan a response, so I flag them to follow-up later and then get to them in the next day or two. As you might be able to tell, I am a bit of an e-mail-minimalist: I like my inbox to contain very few e-mails, so I delete messages relentlessly and I will quickly file the very few records I need to save. If I still responded to service requests, I would want to close them as quickly as I delete e-mail so I could keep my request queue as empty as my inbox. The only way I can achieve that is with an efficient priority and processing system (and of course, effective routing rules for automated processing when possible).
In Table 2-1, I provide an example of priority levels I have used along with their definitions. I also include the target responses and target resolution times that I set for each priority level. This example comes from an actual service request process I designed as part of a service level agreement I created for a client. You should keep in mind that in this example I have omitted the measurable metrics such as the number of affected users.
Table 2-1. An example of service request priority levels with target times
.jpg)
.jpg)
The escalation team receives notification from the system for Urgent issues. The actual resolution time varies depending on the complexity of the issue, and number of other higher priority issues that are active. The time targets do not cover weekends except for Urgent issues.
As you can see, there are several types of service requests, and it makes the process complex. Yet with a well-defined rubric, you can avoid things such as having the loudest requestor bully their request to the top of the queue, cutting ahead of the patient users. That will still happen, of course, if your place is like most of the places I have engaged. Politics happen in organizations, but using defined measures that take the subjectivity out of your service request process should help make this manageable.
Designing a Chargeback System
If you do not formally have a chargeback-funding model in place, then you have an informal one. After all, someone pays your department to operate. The big difference between a formal and informal funding model is that formal chargebacks bring the decision-making for how the money is allocated down to the department or workgroup level. This can be good and bad. For starters, we already considered how everyone has their own priorities, so this could pull you in different directions if you are not careful. Whereas having the funding come from the top naturally lends itself to distributing it with an enterprise view in mind, rather than having the customer who has the largest budget making the decisions for everyone.
Chargebacks are not as simple and straightforward as they might seem, or at least as how they should seem to me. Every customer is unique and puts a different load on the service. One group may require a document repository to archive scans of their proposals and contracts, and then retain them for up to 15 years. Another group may need minimal storage, yet they may require analytic reporting to slice and analyze their data mart. The first customer requires a significant amount of archival storage space for their repository of document scans, while the second customer requires heavy CPU processing to calculate and process their reports. These are very different needs and would be difficult to group in the same service tier, and likely, they would not even group in the same web application.
Knowing this, what do you base a chargeback on, and how do you enforce it? The amount of disk space and the amount of system resources are certainly good starts. My point is more to illustrate that a chargeback typically has multiple dimensions to it. Some of these dimensions include things such as system resource usage, but others can include the number of users, the degree of customizations that is available to the users, the number and type of features that are available on the site, and the degree of dedicated system resources available to a site.
In addition to the actual functional dimensions that can factor into a chargeback model, you might also factor in offering different degrees of available support resources for different service tiers. Chargebacks can charge for resource usage and feature usage, but they can also charge for support services. Using chargebacks can influence the priority levels you offer to assign to service requests beyond what I already discussed. For instance, an internal customer could subscribe to a higher tier of service to assure their users that they will receive a higher priority from support responding to their service request tickets.
You can base a chargeback model on multiple dimensions. You can base one dimension on the number of features and capabilities available in a tier, and another dimension on the amount of system resources available for consumption within a service tier. You can factor in the number of users using the service and the degree of customization they have available to customize their site. You can also factor in the service level you provide a service tier, ranging from things such as the frequency of backups to the priority assigned to service request tickets. Chargebacks and service tiers are complex because they attempt to address the common needs for groups of users with unique priorities and diverse requirements. How do you address such various needs and priorities among your users if you have groups who both want a premium service level tier, yet one requires a vast amount of archival disk space while the other requires significant amounts of CPU resources? Either you can accept the costs associated with this, or you can offer a means for users to customize their service tier to fit their needs.
You can go to one extreme and offer a generic service in a fashion similar to the famous Ford saying related to their early T-model cars, “You can have any color, as long as it’s black.” On the other hand, you can adopt a mass-customization strategy. In this strategy, think about a process similar to how Dell handles their customers ordering computers online. Their customers can customize their computers to fit their needs, but there are only a finite number of customization options available. There is the base product, such as the computer tower itself, and then there are customization options available to tailor the computer to the customer’s needs, such as the amount of RAM or the CPU processing power. Offering a finite number of customization options is part of what allows Dell to mass-customize computers for their customers, or in other words, they can provide these customizations very efficiently. Dell can be efficient in their manufacturing and supply chain processes, and their customers can benefit from getting a computer tailored to meet their needs. Mass-customization enables both of them to benefit. Now how does mass-customization translate to SharePoint service tiers and chargebacks? Essentially in the same way: design a base service offering, and then design a selection of options your customers can mass-customize to tailor a service that meets their needs.
One option for a base service level could involve the different types of sites available. For example, you might designate a generic team site with the core collaborative functionality for the entry-level tier. The service level behind this site may involve less frequent backups, no customization support, and the default site quota. Other service levels for the site may include limiting it to authenticated users without any external access. Another example might provide additional functionality from a wider set of SharePoint service applications available in the farm, more frequent backups, and end-user customization support that allows them to deploy user solution packages. These are just examples, but I hope they give you a sense of how you can begin to define the base service tiers in your chargeback model. The challenge is to define the tiers with generic and common functionality that you can use as a baseline service offering.
These different baseline service offerings should cover the range of your customer’s core needs. Similar to how Dell has several personal computer towers to choose from for their base product, your service tiers should also provide a base to meet the core needs of your different types of customers. In addition, similar to how Dell offers options for their customers to mass-customize their computer, you can offer a variety of options available for your customers to mass-customize their service tier to fit their needs better. You can make these options available à la carte, and they can include things such as additional disk space, premium features, and additional support.
Once you have made all these decisions and have defined your different service tiers with their mass-customization options, you can assign chargeback prices to them. You can provide this as a sort of shopping catalog in which your customers can shop for services. Each service tier has a base price, one you set depending on your internal cost structures, and then each mass-customization option has an additional price. Your customers can then select what they need for their desired level of service, and your catalog will provide the chargeback price associated with their tailored service.
Table 2-2 provides an example of base service tiers. This is an actual example of service tiers that Microsoft IT used internally.
Table 2-2. An example of service tiers provided by Microsoft IT
| Service | Description |
|---|---|
| Standard (Utility) | The primary SharePoint service that most employees utilize Includes My Sites and team collaboration sites Offered at no cost to end users/groups Employees use a self-provisioning tool to quickly create sites Storage above quota limits can be purchased at cost Employees can do small customizations for a charge (limited to SharePoint Designer) Shares a single host name Best for business-critical (not mission-critical) business needs |
| Custom | Targeted at groups that need more than the Standard service Includes vanity URLs and dedicated hardware Customizations permitted in addition to SharePoint Designer Offered at cost to sponsor; charged quarterly Single tenant isolated hosting Used for mission-critical LOB applications Used by the major portals |
| Extranet | Service offering for Microsoft partners |
![]() Note For more details on this service tier example, please see the Microsoft IT showcase Quick Reference Guide on Microsoft IT SharePoint Infrastructure and Governance Policies: www.microsoft.com/en-us/download/details.aspx?id=15531
Note For more details on this service tier example, please see the Microsoft IT showcase Quick Reference Guide on Microsoft IT SharePoint Infrastructure and Governance Policies: www.microsoft.com/en-us/download/details.aspx?id=15531
You might notice that my focus for service tiers and mass-customization options centers on measuring the available resource and available features rather than the actual usage. In other words, I have found the best chargeback model involves a customer subscribing to a service tier and issuing chargebacks base on the tier they subscribed to rather than their actual usage. I find trying to measure actual usage in calculating a chargeback involves too much overhead, such as measuring actual disk usage in a period to determine a chargeback level. Instead, I prefer to base a chargeback on the available resources a customer has subscribed to, regardless of their actual usage. In the case of disk space, I would measure the quota available to the customer rather than the actual disk usage for the period. Quotas provide different levels of disk availability for a customer, but having standard quota levels to use in measuring a chargeback level also offers mass-customization because they are standardized.
Essentially, this chargeback model resembles a service in the cloud, but your cloud is an internal cloud. If you ever wanted to use a cloud such as Microsoft Office 365, either for all your services or to augment existing on-premises services, your chargeback model should work well for these scenarios also. Cloud offerings provide software as a service to multiple organizations, in a similar fashion to how your SharePoint service offering will provide SharePoint capabilities to multiple departments and workgroups within your organization. You might even provide the service to enable collaboration with external organizations through an extranet. Whether you are hosting the infrastructure yourself or you are consuming parts or all of it from a cloud service provider, this chargeback model still works.
When you set the price of your chargeback for the different service tiers and the different mass-customization options, you have to factor in the cost of providing the service. If you are hosting everything on-premises, you have to calculate what those fixed costs are and how to spread them out across your different customers, as well any variable costs involved with providing different parts of the service. If you are providing your service through a cloud solution, the cloud provider and the subscription you choose will have already worked out the majority of the costs for you. If your team provides end-user support rather than outsourcing that to the cloud provider, then these will be some extra variable costs to factor in to your chargeback pricing, for example.
I use Office 365 for small business for my own consulting practice, because I do not have an internal IT department and I want to keep my own time available for the core of my business, delivering value consulting with my clients. Not only that, but their pricing enables me to use Lync, Exchange, and SharePoint, whereas for a one-person organization, the costs in licensing and hosting those products myself would be much higher and make them cost-prohibitive. My monthly subscription, or what you might think of as my chargeback, works out to seven dollars and some change every month, in Canadian dollars. For this reasonable chargeback, I can use the same tools that large enterprise and government organizations use, the same tools that my clients use.
Ultimately, the goal of chargebacks is to enable business units and departments to allocate their funding to align directly with their priorities. Its extra accounting overhead comes with the benefit of controlling costs: you can identify granular costs involved with providing the service and factor them in to the pricing of a chargeback model. It gives transparency into the underlying costs associated with different feature areas, and it delegates the cost-benefit decisions directly to the business users who will derive those benefits.
Chargebacks can make for an efficient funding process that has its own natural checks and balances to encourage aligning costs with business value, and they help to guard against run-away costs. Yet, they are not the only option, because funding can still come from above, where finance allocates an overall IT budget that you manage within your group to provide services. I understand many organizations are entrenched with this traditional funding model, and this makes the idea of chargebacks a longer process before you can introduce the change. The first step toward this model is to define the service and its service tiers, and if you can start reporting on the granular costs associated with providing the service, then you are well on your way.
I personally like using chargebacks because of the discipline they offer and the insight they provide into the underlying operational costs. I may be influenced based on all the accounting courses I took in business school, and in particular I am thinking back on my management accounting class that focused on breaking down all the costs, but I do see a lot of value in a chargeback funding model. For this reason, I recommend consulting with a management accountant if you have any who are available within your organization or if you can engage a management accountant from a consulting firm, and use them to help you determine your underlying costs involved with providing the service and what your optimum chargeback pricing should be.
I can offer you no silver bullet pricing levels, because everybody’s costs will be different. Understanding your costs will help you determine your pricing levels, because a need for cost recovery largely drives chargebacks. Good management accountants will have expertise in the area of analyzing and understanding costs and they can help guide you as you design your chargeback model.
Identifying Your Maintenance Windows and Availability Needs
I used to have a job as the lead for a global SharePoint deployment, and one of my biggest challenges was finding a window to perform maintenance – apply patches, deploy custom solutions, rebuild database indexes, whatever. The thing about supporting users around the world is that there is always someone working, always someone using SharePoint, always someone whom I would interrupt. Even at bizarre hours like early on a Sunday morning when I thought that finally people would be asleep or taking a day off.
One of the first things that I needed to do was write a schedule of all the activities in a week at each location and for each SharePoint farm. When dealing with a global schedule, I found it best to have two columns for the time of day: one for the corporate head office time, my time zone, and the other for the server’s local time zone. This made it easier to layer on the different activities, especially for those servers located overseas. Then I worked in standard operational scheduled tasks on the local servers, such as database backups and search indexing. Finally, I worked in the global operational scheduled tasks, such as crawling for the global search index. Ensuring no overlap was critical, because some of these tasks are very CPU intensive and can quickly starve a farm of its resources.
My outcome from this activity was having the core operational scheduled tasks captured, including having the global tasks coordinated with the local tasks. I layered all the tasks for a complete picture of activities over a bi-weekly timeline. On the timeline, I then highlighted core operating hours for the high-priority locations around the world. The result was a visual timeline that made all the constraints clear, and it highlighted what windows I had to fit in planned routine maintenance. Eventually I found a small window on Thursday nights for routine and low-risk maintenance. Having the schedule on a visual timeline with all the scheduled tasks made this possible.
Having discussions with the business, I could also determine what their needs were for availability. These needs changed depending on the time of the year. Early in a cycle, they did not have much of a tolerance for downtime. No feature enhancement or upgrade mattered to them as much as being uninterrupted from the work they needed to do during certain months. During other months, their tolerance was the polar opposite.
This certainly depends on the nature of the business, but for my retail clients I have noticed the months leading up to Christmas typically are the months where they have the least tolerance for downtime, while February or March is around the time that they have the highest tolerance. Knowing this makes planning easy: I go into a change freeze for those periods that my internal customers have a low tolerance for change, and plan upgrades or major enhancements for those other periods when they have the highest tolerance. When will making changes to SharePoint have the least amount of negative impact on people’s daily life and their daily work? This is when they will have the highest tolerance for interruptions.
You can get into a good routine with regular maintenance windows. Your infrastructure resources can test patches on a regular schedule after Microsoft’s patch Tuesday, and then plan to patch the servers during the next maintenance window cycle. I like to have tasks like this become reasonably systematic and operational, so if I can have a regularly recurring maintenance window, I can be more consistent and orderly with my maintenance tasks.
Figure 2-3 illustrates an example of a visual timeline you might use to capture a daily schedule of all the activities that occur on your farm. I typically use a timeline similar to the one illustrated in Figure 2-3 for each day of the week, and then I layer on scheduled tasks for each day and highlight the core operating hours. For my busiest farms, my schedule may differ slightly on alternate weeks, particularly for tasks related to full crawls of large repositories of content. In these cases, I build out a fourteen-day schedule of timelines; otherwise, I build a seven-day schedule. In the Figure 2-3, I added backup, crawl, and Active Directory import schedules. You can start with these and layer on the rest of your farm’s scheduled activities to get a complete picture of your farm’s activities.
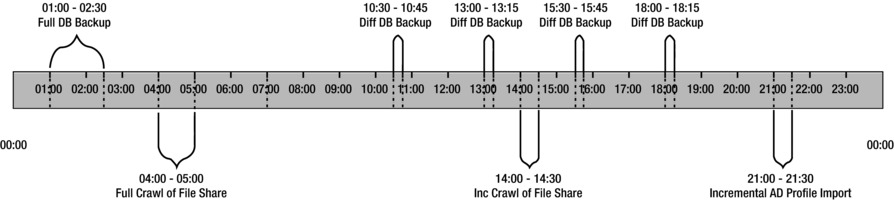
Figure 2-3. An example of a visual timeline of scheduled tasks
Consultant Comrade
I often find it easier to establish a service description for an existing SharePoint service already in production. In those cases, I can define the service by analyzing how a client uses their SharePoint environment and what capabilities they have available. They have already made decisions about what services their SharePoint deployment offers, even if they made these decisions implicitly through how their SharePoint deployment has evolved. A service description gives the service order, and the description can help provide a baseline and focus for the rest of our efforts. This also helps me to understand how they are using SharePoint and where they are receiving the greatest value.
Your clients may have SharePoint in production already, and they might bring you in to consult with them on how they could best govern their SharePoint deployment. Although I often find establishing a service description as a good first step in a new deployment, sometimes I have to circle back and help a client to catch up if they have not addressed this yet.
For those new deployments where you are starting fresh, starting with a service description can be a valuable tool to help keep your project delivery on target. I find clients often get excited as they begin to learn about all the capabilities that SharePoint offers while the project delivery progresses. This can be both a blessing and a curse. Their enthusiasm helped drive the SharePoint initiative to begin with, so you do not want that to fizzle out. You want to use their enthusiasm to build momentum and continue delivering SharePoint value beyond an initial delivery. It is a delicate balance though, for if you open the floodgates and try to accommodate every whim that grabs their attention, you risk being overwhelmed with an increasing scope that bloats and drags down the initial delivery.
I like to think of this scenario as having your scope slowly erode away with the addition of all those wonderful extra features that each on their own should not take much for the team to include, but the sum of them all grows to be significant. I call this a slow death by a thousand paper cuts, as I mentioned earlier in the “Determining the Scope of Your SharePoint Service” section.
For this reason, I find helping my clients define their service description before beginning the actual delivery of a SharePoint project enables us to set the baseline and scope for what I am there to deliver. I am extra vigilant at encouraging them to stick with this scope and refrain from getting distracted with all the other little things that come up. My strategy to guide them largely centers on a parking lot list, a list of future items we will prioritize and get to in a future phase and a place where we can capture things as they come up. I remind my clients that our success depends on us all staying focused and committed to our current phase.
We do not want to become inflexible and resist changing requirements. I understand this perspective. Yet, at the same time, if we let ourselves get distracted with every shiny little thing that wows them in SharePoint, the momentum will begin to unravel and the project will be at risk. The reality is that SharePoint is overflowing with great features, so they constantly come up. That is what makes SharePoint so great. I stress this point because I see it constantly and every time I see it, I see it slip into a death by a thousand paper cuts. If the phase is small enough, the changes that come up will be insignificant and probably will not even affect the delivery. For those larger projects that you could not break down into quick phases for whatever reason, your best bet is still to stick with the initial service definition and scope, and allocate everything else that comes up to a follow-up phase.
If you are like most of the consultants I come across in the field, you are probably reading this and can still come up with plenty of reasons to allow scope creep. From my experience, when the consultants are unable to help the client stay disciplined with scope, the project is probably in trouble. They may still deliver, eventually, but these types of projects always seem to wind up being the ones that are like pulling teeth, with no end in sight, with everyone just floating along while no one really owns anything or has any firm commitments. Maybe it is just my experience, where it can feel like I am the only one on the project team who realizes the paper cuts are beginning to add up. At that point, I have to trust my instincts and bring everyone together to give an ultimatum that either we commit to the scope and delivery, or perhaps I am just not the right fit for the project and need to roll off it.
You can avoid this situation, and the solution lies in defining the service. If it is arbitrary or ambiguous, there is more room for paper cuts. If you start with a well-defined scope and have a shared understanding that there will be another phase to deliver more value, but that for this phase everyone is committed to the service definition, then you have a nice chance at guiding your client to success. A strong service definition provides value beyond the initial delivery as well. Therefore, even if your client already has SharePoint deployed, this is still a great place to start.
You can take your client’s service description and use that to guide them in planning their service tiers and service request process. It provides that baseline that puts everything else in context, for your clients and for your consulting team.
Inside Story: Notes from the Field
Several years ago, I was working for a company and I took the responsibility to establish a service level agreement for our SharePoint service. It can be a bit of a daunting task, as every little detail needs attention and consideration. I honestly thought that we could quickly document it, make some quick decisions, and establish our service level agreement quickly. I certainly was a little green with service levels from that perspective. I learned right away that they take time, and that everyone involved needs time to process items we were considering before they came back with new ideas and additional perspectives.
As I went along in the process, the process constantly revealed more information to me. It proved to be an invaluable exercise. They say that the best way to learn something is to teach it to someone else. Well, I will take that same idea and say, to best understand a complex SharePoint service with all the different perspectives and priorities for its users, you should work on establishing a service level agreement for it. You would be amazed at how much you learn when you negotiate with all the different areas of the business and try to abstract aspects of the service so that they are generic enough to find common ground among all the stakeholders. I find these to be valuable exercises every time, and every time I learn a little more about how people use SharePoint and what they find valuable.
My involvement with defining service levels and service descriptions helps expand my perspective and provides insights that all help to make me stronger in my role as a solution architect. My experience as a solution architect also helps to make me a better governance advisor. The two complement each other well. You will notice my governance attitude considers the overall solution, because I believe governance is only valuable if it drives the overall solution, if it is scalable, and if it is practical. I feel governance will only truly work if it is adoptable and it will naturally support users in their core job functions. Conversely, I feel solution architectures will only work if they are manageable over time and if users can govern them. My point is that governance efforts will make you a stronger SharePoint resource, because it will increase your other SharePoint skills and broaden your perspective.
While I built out the service level agreement, I started with defining the service itself. We had multiple SharePoint farms with a variety of needs and degrees of cooperation between administrators, so the process of defining a service description for each farm helped identify the focus and purpose of each. This exercise also revealed the politics and the people involved with the farms, from internal competition between groups to gaps in their support coverage. All this was valuable knowledge and it helped to shape the rest of the service level design.
As part of defining the service, I also defined the underlying infrastructure that the service depended on. In some cases, the SharePoint service consumed other infrastructure services from a centralized IT group, such as a centralized SQL Server database cluster or a centralized SAN storage service. Some groups managed their own farm and infrastructure within the farm, while still other groups had a combination of hosting their own and consuming centralized services. I handled this in the service description by listing the service components in a table, and I broke them down into rows to display them in a granular level. I then designated columns for each farm to identify who provided the service of each of those components for a farm. I took what seemed to be complex relationships and I standardized them in a table that captured who provided the service for each component in each farm.
After I standardized the details of each farm and I simplified their relationships to a number of components that resources provided as a service to the farm, I then continued with the service description to define those components and the service expectations around each. For example, with the SQL Server component, I defined a standard for full backups and the minimum frequency they needed to occur to comply with the service level agreement. Once all the farm administrators agreed to the minimum, I then used another table to capture any variances for any farms that require backups more frequently. I broke down each of the components in this way and worked with each of the groups to establish a minimum standard that they would all agree to meet, and then I captured each of their requirements for a higher standard if one was specific to a farm.
The service description took a lot of involvement to analyze processes and standards, and then to abstract and generalize them to find common standards among all the farms. From there I could define a global service definition that encompassed ten SharePoint farms spread around the world; SharePoint farms that six different, and in some cases, competing IT groups within the organization managed. Yet, despite the political challenges and the complexity of so many non-standardized farms, this process still worked, and we were able to agree on a common service description.
The service request ticketing processes varied almost as much between these farms as their service descriptions. Some farms had their own support process, others used a global service desk, and others used a hybrid of their own and the global service desk. My approach to standardize service requests was the same as how I standardized the service description: break down the business process into a set of standardized steps and identify each farm’s process for a particular step.
Ultimately, I took a global deployment of disparate SharePoint farms that several different groups managed, and I created a common service description to cover them all. I took a deployed service that we ran in a reactionary manner without a lot of coordination, and I established a set of common standards and minimum commitments among the farms. I navigated some political situations and I helped to reduce some of the service overlap. I also identified gaps in support and coverage, which provided one of the biggest benefits I experienced from the process of defining a service level agreement. This exercise was not just an exercise for my group to come in as the corporate worldwide IT team who wanted to standardize and make everyone conform to the head office way of providing a SharePoint service. Instead, I analyzed each farm at a granular enough level to find commonality among them all, and from there, I built consensus on what would be our minimum standard. In the process, I helped transform their operations to have an intentional focus that we could use to set expectations with our users.
GUEST Q&A: MAXIME BOMBARDIER, MICROSOFT
As I discussed the concept of governance with Maxime Bombardier, a senior consultant in Microsoft Consulting Services, he stressed the relationship between business users consuming the SharePoint service and the IT operations team providing the service as a primary component for SharePoint governance. For him, you can facilitate this relationship between the business and IT if you create a service catalogue that defines the service and its service levels.
He pointed out that the typical IT policies that he sees in common governance templates are simply one of the small outputs of a larger governance process. For him, governance is an ongoing process, not a document. He finds that governance templates and documents are not sufficient on their own, because governance activities need to go beyond infrastructure policies, they need to address the relationship with the business.
His advice is to “build small and build often” as you approach your governance initiative.
Maxime Bombardier works for Microsoft Canada as a Senior Consultant in Microsoft Consulting Services. He is also a Microsoft Certified Master (MCM) for SharePoint. You can follow more of Maxime’s SharePoint insights on his blog: http://blogs.msdn.com/maximeb.
Wrapping Up
In this chapter, I discussed how to treat SharePoint as a service that you provide for your internal customers. I considered how to make the scope of the SharePoint service explicit and intentional, and how to set up and define different service levels based on different dimensions for different customers. From there, I discussed how to prioritize and triage service requests. Finally, I discussed approaches you can take to design a chargeback-funding model.
Now that you have looked at defining your SharePoint service description, your service request process, and a chargeback model, we will expand and build on these concepts by considering different SharePoint features. In the next chapter, I discuss the core SharePoint functional capabilities at a macro-level. I look at how you can limit features to stay within the scope you define for your service description. I also share some approaches on how to map SharePoint features to business value, through which you may return to expand parts of the service description we looked at in this chapter to include a business case and business value. In the next chapter, I also discuss strategies on how to expand your SharePoint service by enabling additional features over time, and you can use these strategies to expand your SharePoint service definition over time as well.