
![]()
Continuous Delivery
In the previous chapters we’ve looked at development and testing practices and seen how the tools in Visual Studio help us to be more productive in each practice. In the chapters to come we will take our set of practices and implement a process where it all comes together to form one continuous flow. We will refer to this process as a continuous delivery process as it can be implemented to help us deliver features to our customers in an efficient and deterministic way. Many steps (perhaps all) in this process can and should be automated if we want to fulfill the ALM vision but automation is not important in itself. Instead, the work we do to improve the delivery process is what makes us successful. Analyzing how we release our software will give us insight into what steps in the process has dependencies to other steps, which steps are handled manually, which steps are error-prone, and so on. This knowledge is then used to help us focus on the most important parts first.
To enable continuous delivery we will look at some important techniques we can use as tools to support this process.
“Continuous integration is a software development practice where members of a team integrate their work frequently; usually each person integrates at least daily—leading to multiple integrations per day.”
—Martin Fowler
The term continuous integration (CI) was introduced by Martin Fowler and is now the defacto standard in agile projects. Having worked in a project with a CI process in place it is really hard to imagine how a project could actually work without it. Of course it can, but an agile project requires new ways of working and just like Scrum is said to be all about common sense, so is also CI. But there are several problems with agile development from a deployment perspective, such as
- Testing. We’ve seen in earlier chapters the need to do testing earlier and more often in an agile project because software is built incrementally in short iterations.
- Cross functional teams. Ideally the team should be self-organized, meaning more people need to be able to deploy software.
- Shippable product in every iteration. Manual routines used to work, but now it is not okay to spend one week on installation tasks if the sprint is two weeks.
Continuous integration can help to resolve these issues. In fact, Scrum has a solution for this—use the retrospective to find ways to improve. How you can get going with improvement is what we will look at next.
Why Should We Implement Continuous Integration?
Even if the all the above makes sense it can still be hard to justify the work to implement it. So instead of just having a good gut feeling that this is a good practice worth the time required to set it up, we have listed our favorite reasons here. Continuous integration can
- Reduce risks
- Reduce manual routines
- Create shippable software
- Improve confidence in the product
- Identify deficiencies early
- Reduce time
- Improve project visibility
Still even with the good arguments for why CI makes sense we occasionally hear concerns such as the following:
- Maintenance overhead. We will need to maintain the build environment and the CI solution. Hard to argue against this one. But show us any factory that will work without maintenance; why should a software factory be any different?
- Effort to introduce. Sure it will take some time to get the process started. For a new project not so much, for an existing solution we may need to add CI capabilities incrementally for a good return on investment.
- Quality of current solution. Some may argue that the current process is too poor to automate. If we ever hear that argument we must make sure to get CI in place.
- Increased cost. New hardware for the build infrastructure will need to be purchased. But think about the savings we will get by raising quality and identifying problems much earlier in the process.
- Duplicates work. With CI we need to automate what we already do manually. Well, yes initially we do but the goal should be to share as much as possible of the work that developers and testers do anyway. For instance the build system can use the same solution files the developers use and the developers can use the deployment script to update their machines when a new version needs to be installed locally. In fact how could we possibly manage to do manually what the CI process can do for us many times every day?
Finally to get continuous integration working the team needs to agree on the rules around the process. If the rules are not followed there is a potential risk the quality of the result will degrade and people will lose confidence in the process. We recommend using at least the following rules as a starting point
- Check in often. The CI process needs changes to work, the smaller changes we can commit and the more specific the changes are the quicker it will be for us to react on things that go wrong.
- Do not check in broken code. Checking in often is great but don’t overdo it. Don’t check in code until it works and never check in broken code. If you need to switch context, use the shelve or suspend feature in TFS to put things aside for a while (see Chapter 15 for details on these features).
- Fix broken build immediately. If you happen to break something, it is your responsibility to fix it.
- Write unit tests. The system needs to know what works and what doesn’t. Unit tests and other inspection tools should be used to make sure the code does more than just compile.
- All tests and inspections must pass. With inspections in place you must pay attention to the result. Use feedback mechanisms to make people aware when something is broken.
- Run private builds. If you can do a test build before checking in you can avoid committing things that don’t work. TFS can build from a shelveset using a feature called Gated Checkin.
- Avoid getting broken code. Finally, if the build is broken, don’t get the latest code. Why go through the problem to work on code that doesn’t work? Instead use the version control system and specifically get the latest version that worked.
Components in Continuous Integration
So now we know what continuous integration is all about. Or do we? What actually does a CI process contain? Compiling code to a set of deployable files? Running unit tests? We think build automation with integrated running of unit tests is a great start but the CI process can be more than that. Figure 25-1 shows a process we consider a complete CI solution and should be what we strive to achieve.

Figure 25-1. Components in the continuous integration process
Let’s drill down into each of these components in more detail.
Build Automation
Build automation is the core step in the CI process. The automated build system is typically used to drive the CI process and not only do compilation and execute unit tests. An automated build should be possible to trigger by anyone (having permissions to do so) at any time and it should be possible to set up a schedule for the builds (such as nightly builds). The build process should also publish the build results at a central location so people can go and get builds easily, as well as look at the build status.
Automating the build process is of course not always a trivial task but the benefits it gives are many, including
- Saves time
- Reduces errors
- Predictable results
- Helps us learn about problems early
- Reduces dependency on individuals
Any new project should implement an automated build skeleton because having the foundation in place from the start makes it so much easier to just do the right thing.
When implementing automated builds we also need to think about what kind of build we need in which scenario. It is common for development teams to not just have one build setup for a branch, but instead more likely all of the following:
- Continuous integration builds. Lightweight to give feedback quickly, often incremental with limited testing.
- Private builds. Test the changes to be committed before actually checking them in.
- Nightly builds. Complete builds with more exhaustive testing.
- Release builds. Complete builds with release notes.
Database Integration
Another activity that often takes a lot of time in the deployment process is database integration. Traditionally updating databases as part of a change is a manual process where either the developer writes database change scripts or a DBA performs a comparison between two known database versions and then runs the upgrade manually.
There are, however, ways to do this as part of the continuous integration process. For instance if we can run a tool that performs a comparison and generates a change script we should be able to tweak the build process to do that automatically. If we are afraid that if the process fails we will have an environment that doesn’t work we can protect that by automatically running a backup before the upgrade and should something fail we have the build process restore the database to its previous state.
Deployment
To use the build result for manual or automated testing we need to deploy the build onto a test lab. The deployment process can be as simple as just copying over a set of files to the target environment or it may require local installations on multiple machines. But there are tools and techniques to solve any of these challenges; we simply have to spend time learning about the steps involved in getting a release installed.
Testing
Now when the software has been deployed, we can run tests on it. The core compile phase of the build process typically runs the core unit tests but for other automated tests such as regression tests, build verification tests, or smoke tests, we want to run those tests on a realistic environment with proper test data available. Ideally we want to have a process where we can run automated build verification tests after every deployment to verify that the software works well enough for our testers to spend time testing it. After that we can add more automated regression tests as we find value for, the process of running them as part of the continuous integration process will be the same.
Inspection
Having all these steps integrated is great but how do we know whether something goes wrong? Compiler errors and failing tests can easily be trapped and visualized. But what about code quality? Can we for instance fail a build if the code coverage for unit tests is below the level we agreed on? Or if the code has become more difficult to maintain over time can we get notified of that? The continuous integration process is often thought of as the heartbeat of the project and this is something we can take advantage of for inspection. Some inspections should lead to immediate action, such as compiler errors should fail the build. Others can be reported to a central location so that we can look at the trends later on, like for instance code metrics and overall build status.
Feedback
The last step in the process is to have a good way to notify the team about what works and what needs to be looked at. A good feedback system will give us ways to know about an issue immediately so that we can fix it before it grows to a big problem. We can try to be as creative as possible here to make the build result visible to the team in a good way like on a build monitor or by sending out email alerts.
In fact, wouldn’t it be great to have this kind of information available as part of the project status on the team’s home page? Figure 25-2 shows how builds can be pinned to the home page in the TFS Web Access.

Figure 25-2. Continuous feedback from the build process using a TFS Web Access favorite
Figure 25-3 shows how we add a build definition to the team favorites from the build explorer view in the TFS Web Access.

Figure 25-3. Adding a build definition as a TFS Web Access team favorite
Now we know what we can do but how does this fit into the overall delivery process? To take advantage of continuous integration we should also think about continuous delivery.
Continuous Delivery
The problem with continuous integration is not that is not a good solution. It’s just that it can be a solution to a non-existing problem. Deployment as part of the CI flow is not just about automating the build, test, and release processes. We need to think about delivery to really add value to the deployment process.
Continuous integration is great and it gives us a framework for efficiently producing software in a controlled fashion. But to get the most out of it we need to look at how it fits into the overall process of delivering software. In an agile project we want to deliver working software in every iteration. Unfortunately this is easier said than done; it often turns out that even if we implement CI and get the build process to produce a new installation package in a few minutes it takes several days to get a new piece of software tested and released into production. So, how can we make this work better?
Let’s start by asking the following simple question:
“How long does it take to release one changed line of code into production?”
The answer is most likely much longer then we would want to. So what stops us from improving? First we must know more about how we release our product. Even in organizations that follow good engineering practices the release process is many times neglected. A common reason why this happens is simply because releasing software needs collaboration across different disciplines in the process. To improve the situation we need to sit down as a team and document the steps required to go from a code change to the software released into production. Figure 25-4 shows a typical delivery process and in practice work happens sequentially just like in the picture.

Figure 25-4. A typical delivery process
When we have come this far we now know a lot more about the delivery process, which means we can start optimizing the process.
- Look at what steps in the process take the most time and see what can be done to improve.
- Look at the steps in the process that most often go wrong and understand what is causing it.
- Look at the sequence of the steps and think about how they need to be run in sequence.
Having looked at the process and asked the questions, we now have a better process as shown in Figure 25-5.
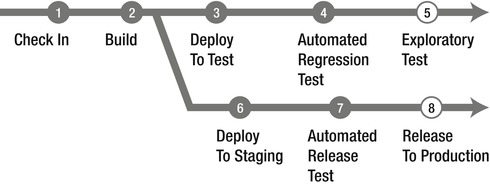
Figure 25-5. An optimized delivery process
In this model we have changed the process so that most steps are automated by implementing automated tests as well as automated build and deployment. Releasing to production automatically is not for the faint-hearted so this would be done manually but using the same automated scripts as the automated deployment to test and staging environments. We do however believe it can be possible to automate even release to production, especially if we have had this working from the first iteration of the project. By doing so we would build up confidence for the process and having seen it work throughout the development cycle should make us trust the process even in this critical stage. We have also parallelized the acceptance test and preparation of the production environment. By doing this in parallel we can push the release to production as soon as the acceptance tests are green instead of the traditional stage to production first after the acceptance tests have passed.
Release Management
Continuous delivery gives us a great practice to produce updates in a controlled and effective manner. But without an intentional release management discipline we can lose much of its value. What we need to add to the picture is how the release planning ties into the deployment process and ensure we know what features we want to deploy where and when.
In a Scrum project we have a good situation when it comes to release management because the first thing we do is create a product backlog and continuously groom the backlog as part of the project cycle. In other words, the backlog is our release plan. If we don’t work with Scrum we need to use other means to create the release plan so that we have knowledge of which features we are going to deliver when.
With a release plan in place we can now design our delivery process to support the difference phases in the project. If we have need for concurrent development we can implement a branch strategy to support this. With multiple branches we can add continuous integration builds to keep the code clean and our environments up to date and so on. Based on the release plan and the continuous integration process we can even automate the release notes for every release we do.
Summary
Proven practices are good; best-practices in a streamlined process can make your development work really stand out against the competition. In this chapter we’ve looked at continuous delivery and seen how practices such as automated build, deployment, and testing give us a framework for delivering new software quickly. With inspection and feedback actively built in to the process we get complete control and can always know what part of our software works and what does not.
The following chapters give us the details to set up a continuous delivery process. We will start by automating the development practices using the TFS build system and implement a continuous integration process. With CI in place we can take the work further and use automated deployment and testing to implement a complete delivery process. Finally, we are going to look at how we can use TFS to support the release process and give us full control over the delivery flow. All this together will really make our delivery stand out!