
Now that your host is providing you services, it is important that it continue to do so. As your business grows, so will the workload on your servers. In this chapter, we will show you how to monitor resources such as disk space and processor and RAM usage. This will help you identify performance bottlenecks and make better use of the resources you have.
A small amount of tuning can alleviate the need to purchase additional hardware, so monitoring performance can help you save money as well as time.
Basic Health Checks
In this section, we look at some basic tools that help you determine the status of your hosts.
CPU Usage
When applications are running slow, the first thing you should check is whether the system is in fact busy doing anything. The quickest way to find out is via the uptime command , as shown in Listing 17-1.
Listing 17-1. The uptime Command
$ uptime12:51:04 up 116 days, 7:09, 3 users, load average: 0.01, 0.07, 0.02
This command prints a short overview of the system status, including the current time, the amount of time the system has been on (or up), the number of logged-in users, and three numbers representing the system’s workload.
In our example, the system was last booted 116 days, 7 hours, and 9 minutes ago. If you lose connectivity with a remote server, this allows you to easily determine whether the system was rebooted once you can log back in.
The number of logged-in users is the total number of current logins via the terminal console, in X, and via SSH. If you are logged in twice, you will be counted as two users. Users connected to a service like Samba or Apache are not counted here.
Finally, the system load is displayed in three numbers. These numbers form an index that indicates the average ratio of work scheduled to be done by a CPU versus the work actually being done, over the past 1-minute, 5-minute, and 15-minute periods.
A load of 1.00 means the amount of work being scheduled is identical to the amount of work a CPU can handle. Confusingly, if a host contains multiple CPUs, the load for each CPU is added to create a total; on a host with four CPU cores, a load of 4.00 means the same as a load of 1.00 on a single-core system.
In our example, the average workload over the past minute was about 1 percent. Some extra tasks were running and probably completed a few minutes ago, as the average workload over the past 5 minutes was 7 percent.
Though these numbers should by no means be taken as gospel, they do provide a quick way to check whether a system is likely to be healthy. If the system load is 6.00 on a host with eight CPU cores, a lot of tasks may have just finished running. If the load is 60, a problem exists.
This problem can be that the host is running a few processes that monopolize the CPU, not allowing other processes enough cycles. We’ll show you how to find these processes with the top utility a bit later. Alternatively, your host might be trying to run far more processes than it can cope with, again not leaving enough CPU cycles for any of them. This may happen if a badly written application or daemon keeps spawning copies of itself. See the “Fork Bomb” sidebar for more information. We’ll show you how to prevent this using the ulimit command later.
Finally, it’s possible that a process is waiting for the host to perform a task that cannot be interrupted, such as moving data to or from disk. If this task must be completed before the process can continue, the process is said to be in uninterruptible sleep. It will count toward a higher load average but won’t actually be using the CPU. We’ll show you how to check how much the disk is being used in the “Advanced Tools” section a bit later.
Memory Usage
Another cause of reduced performance is excessive memory use. If a task starts using a lot of memory, the host will be forced to free up memory for it by putting other tasks into swap memory. Accessing swap memory , which after all is just a piece of disk that is used as if it were memory, is very slow compared to accessing RAM.
You can quickly check how much RAM and swap memory a host is using via the free command. We’ll pass it the -h (human-readable) option so it displays the sizes in gigabytes (-g), megabytes (-m), or kilobytes (-k), as in Listing 17-2.
Listing 17-2. The free Command
$ free -htotal used free shared buff/cache availableMem: 3.1G 59M 2.7G 13M 350M 2.8GSwap: 1.5G 0B 1.5G
This listing gives you an instant overview of whether the system is running low on available memory. The first line tells you the status of RAM use. The total is the amount of RAM that is available to this host. This is then divided into RAM that is in use and RAM that is free. Different versions of the free program may show different memory values on the same system.
The shared refers to shared memory, mainly tmpfs. This matches the /proc/meminfo Shmem value (space used by the kernel).
The buffers column tells you the amount of memory the kernel is using to act as a disk write buffer. This buffer allows applications to write data quickly and have the kernel deal with writing it to disk in the background. Data can also be read from this buffer, providing an additional speed increase. The last column, cached, tells you how much memory the kernel is using as a cache to have access to information quickly.
Both the buffer and cache are resized as needed. If an application needs more RAM, the kernel will free up part of the cache or buffer space and reallocate the memory. If swap space is available, the kernel can move inactive memory to the swap space.
Finally, the last line tells us how much swap space the host is using. Over time, this number will rise slightly, as services that aren’t being used can be parked in swap space by the kernel. Doing this allows it to reclaim the otherwise idle RAM and use it as buffer or cache.
This means that having your host use swap space is not necessarily a bad thing. However, if all memory and all swap space are in use, there is obviously a problem. In our case, we are not using any swap space and so it is showing as 0s out of a possible 1.5GB available to us.
Note
On Linux, free memory means wasted memory, as it is not being utilized, not even as buffer or cache.
We’ll show you how to find out how much memory individual tasks are using in the “Advanced Tools” section.
Disk Space
The other finite resources a computer system has are disk space and disk speed. Generally speaking, a system won’t slow down when a disk becomes full, but services may crash and cause your users grief, so it pays to keep an eye on usage and make more storage available when needed.
We’ll show you how to check for disk speed problems in the next section.
Note
We covered the df and du tools for checking available and used disk space in Chapter 9.
Logs
Finally, if something untoward has occurred with an application or the kernel, you’ll likely find a log entry in your system or kernel log. You will of course want to restart any service that crashed, but checking the logs for the cause of the problem will help you prevent the same thing from happening again.
If the log daemon itself has stopped, you can still check the kernel log buffer via the dmesg command.
Note
We will cover logging in detail in Chapter 18.
Advanced Tools
The basic tools give you a quick overview but don’t provide any information to help you determine the cause of a problem, if there is one. To this end, we’ll show you some tools that can help you pinpoint bottlenecks.
CPU and Memory Use
To list details about currently running tasks, Linux provides the top utility. This is similar to the Task Manager you may be used to from Windows or Activity Monitor on macOS, but it runs in a terminal window, as shown in Figure 17-1. It provides a sortable and configurable listing of running processes and threads on the host. You access it with the following command:
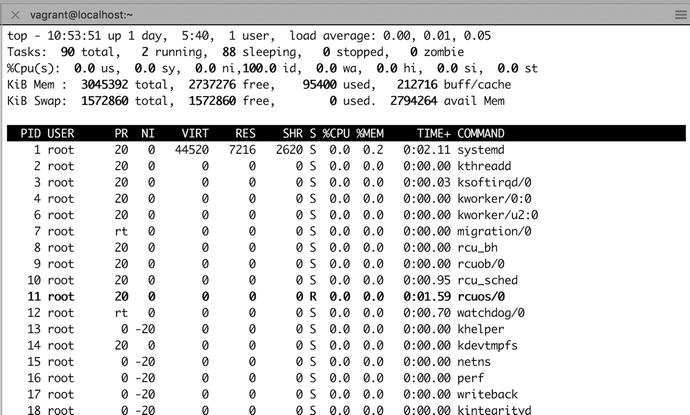
Figure 17-1. The top utility
$ topThe top of the output gives you a few header lines, which includes the information from uptime, as well as some aggregated data from the free and vmstat commands, which we’ll discuss in the “Swap Space Use” and “Disk Access” sections a bit later. You can toggle these headers on and off. The L key toggles the display of the load average line. You can toggle the task summary via the T key and memory information via M.
The rest of the display consists of several columns of information about running processes and threads. The columns you see here are shown by default, but you can enable or disable others as well. We’ve listed their headers and meaning in Table 17-1.
Table 17-1. top Column Headers
Header | Meaning |
|---|---|
PID | Task’s process ID. This unique identifier allows you to manipulate a task. |
USER | The username of the task’s owner; the account it runs as. |
PR | The task priority. |
NI | The task niceness; an indication of how willing this task is to yield CPU cycles to other tasks. A lower or negative niceness means a high priority. |
VIRT | The total amount of memory allocated by the task, including shared and swap memory. |
RES | The total amount of physical memory used by the task, excluding swap memory. |
SHR | The amount of shared memory used by the task. This memory is usually allocated by libraries and also is usable by other tasks. |
S | Task status. This indicates whether a task is running (R), sleeping (D or S), stopped (T), or zombie (Z). |
%CPU | Percentage of CPU cycles this task has used since the last screen update. |
%MEM | Percentage of available RAM used by this task. |
TIME+ | Total CPU time the task has used since it started. |
COMMAND | The name of the task being monitored. |
You can obtain full descriptions for these and all other available fields in the man top manual page.
By default, the tasks are displayed in descending order and sorted by %CPU. The process consuming the most CPU time will be at the top of the list, which is immediately useful for problem solving.
We can sort on many columns in top. To sort on CPU usage, we will need to sort the %CPU column. We can choose a column to sort by pressing the F key, which brings up a list of available columns, as shown in Figure 17-2.
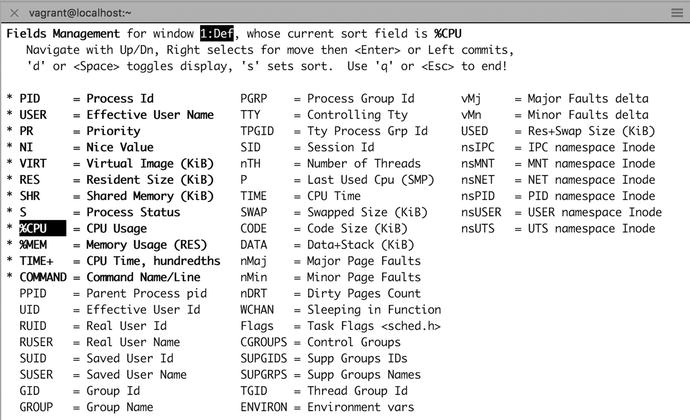
Figure 17-2. Choosing a sort field
The first line tells us the current sort field, %CPU. Below that we have instructions on how to choose a different sort field. The up and down arrows navigate to the different fields. If you press s, you will see that that field is now selected. The d key and spacebar toggle whether that field will be displayed. You can use q or the Escape key to go back to the top screen with your selection. We can press s to make the %CPU column our sort field and then press q to go back to the task list. All processes are now sorted by the number of CPU cycles they use, so if a process is running amok, you’ll be able to spot it easily.
Note
It is possible to select more fields than will fit onscreen. If this happens, you will need to unselect some other fields to make space.
Many more display options are available in top, and you can find them on the help menu. Press ? to access it. When you have customized the way top displays information to your liking, you can save the configuration by pressing W. This will write the settings to a file called .toprc in your home directory.
If you find a misbehaving task, you can use top to quit it. To do this, press k and enter the PID of the task in question. You will then be asked for the signal to send to the process. The signal to make a process terminate normally is 15. If this doesn’t work, you might want to try sending signal 3, which is a bit sterner, or signal 9, which is akin to axe-murdering the process.
To find out more about signals, read the “Killing Is Not Always Murder” sidebar.
Note
You need to be the process owner or root user to be allowed to send signals to a process.
If you have a process that is using too much CPU time and interrupting more important processes, you can try making it nicer, by lowering its priority. This means it will yield more easily to other processes, allowing them to use some of the CPU cycles that were assigned to it. You can change process niceness by pressing the R key. top will ask you for the process ID and then the new niceness value.
Unless you run top as root or via sudo, you can only make processes nicer. You cannot raise their priority, only lower it.
When done, press q to quit top.
Note
You can also use the renice utility to change niceness and priority without using top. For instance, to change the niceness of process 8612, you would run renice +5 8612.
Swap Space Use
If you see a lot of swap space in use, it may indicate the system is running low on memory. Swap space and RAM make up the total allocatable memory available to your system. The kernel will swap out less used memory pages into the swap space when it requires memory for a particular process and does not have that immediately available. This isn’t necessarily a bad thing, but if the system is “heavily swapping” (that is, moving memory pages in and out of swap space frequently, then because swap is much slower than RAM, it can lead to poor performance).
You can check whether this is the case via the vmstat utility. You normally want to tell this utility to print information every few seconds so you can spot any trends. Pass the -n option to prevent the headers from being reprinted and tell it to redisplay statistics every 5 seconds, as shown in Figure 17-3. Press Ctrl+C to quit vmstat.
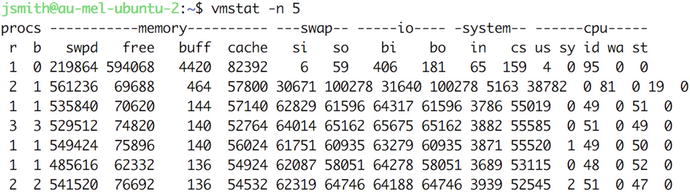
Figure 17-3. vmstat output on heavily swapping host
This rather impressive jumble of numbers gives us an indication of how much data is moving through the system. Each line consists of sets of numbers in six groups, which provide information on processes, memory, swap, input/output, system, and CPU.
Reduced performance due to excessive swap space usage will show up in two of these groups: swap and cpu.
The si and so columns in the swap group display the amount of swap memory that is being read from (si—swap in) and written to (so—swap out) your swap space. The wa and sy columns in the cpu group tell you the percentage of time the CPU is waiting for data to process system (or kernel) requests—and thus not processing system instructions.
If a host is spending most of its CPU cycles moving applications from and to swap space, the si and so column values will be high. The actual values will depend on the amount of swapping that is occurring and the speed of your swap device. The wa column will usually display values in the high 90s as well, indicating the CPU is waiting for an application or data to be retrieved from swap space.
You can solve this problem by using top to find out which application is using too much RAM and possibly changing its configuration to use less. Mostly you will see your main application is the one using the most memory. In that case, either allocate or install more memory to your system.
Note
top itself is fairly resource hungry, so if a system is unresponsive and under extremely heavy load, it might be easier and quicker to reboot it than to wait for top to start.
procs - ---------memory------------- ---swap-- ---io--- --system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st0 0 422336 750352 8252 130736 0 0 0 0 27 56 0 0 100 0 00 0 422332 750352 8252 130736 1 0 1 0 27 55 0 0 100 0 0
In the previous example, this is an example of a host under light load. This host has low swap space, and the CPU spends most of its time idle.
Disk Access
The vmstatutility will also give us information on how much data is being read from and written to disk. We’ve highlighted the bi (blocks in) and bo (blocks out) columns in the io group in Figure 17-4. By passing a second number as a parameter, we’ve told vmstat to quit after five intervals.
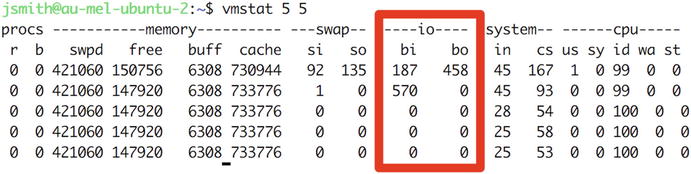
Figure 17-4. vmstat with low disk I/O
These two numbers tell you exactly how many blocks of data are being read from (bi) and written to (bo) your disks during each interval. In our case, the system is reading more data from disk than it is writing back, but both numbers are low. Because the block size on our disks is 4KB, this means they aren’t very heavily loaded.
Tip
If you have forgotten the block size of your disk or partition, you can issue the following: blockdev –getbsz <partition>.
What constitutes a heavy load will depend on the block size and the speed of the disks. If a large file is being written, this number will go up for the duration of the write operation but drop down again later.
You can get an idea of what your host is capable of by checking the numbers you get when creating a large file on an otherwise idle system. Run a dd command to create a 1Gb file containing only zeroes in the background, while running vmstat simultaneously, as shown in Figure 17-5.
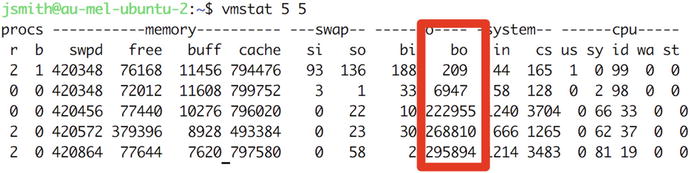
Figure 17-5. vmstat with high disk I/O
On the same host we will run the following command:
$ dd if=/dev/zero of=./largefile bs=1M count=1024Then when we run the vmstat command at the same time, you will see something similar to Figure 17-5.
The bo column is low for the two runs, as the file data is still in the kernel buffer. At the next interval, however, you can see it spike to more than 222,000 blocks. Keep in mind that this is over 5 seconds, though, so we can calculate the peak write rate on this particular host to be around 45,000 blocks per second.
If you notice degraded performance and vmstat shows a bo value that is up near the maximum rate that the system could manage when you tested it for a long time, you have an application or service that is trying very hard to write a lot of data. This usually indicates a problem, so you should find out which application is the culprit and rectify the problem.
Deeper with dstat
How could you find out which application might have a problem? The vmstat command is great to see a problem, but it doesn’t allow you to go deeper in your investigations. The dstat command, on the other hand, is a great tool at digging.
You can install dstat via the dstat package on both Ubuntu and CentOS using the package manager YUM or Apt. Once one is installed, you can issue the output shown in Figure 17-6.
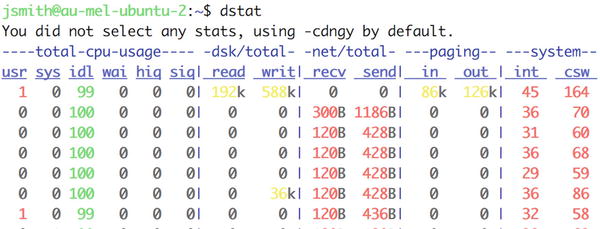
Figure 17-6. dstat output
So far it’s not that much different from vmstat, except that we have disk reads and writes calculated for us, and we also we have network send and receive information. The CPU, paging, and system are the same as vmstat.
Let’s suppose that we have noticed that our application is performing poorly and we think it is due to disk performance. When we look at vmstat, we see the results in Figure 17-7.

Figure 17-7. Checking I/O with vmstat
We can see that we have a fair bit of data being written (bo), but we have no idea to what disk. With our pretend application, we have three partitions that are mounted to /app/log, /app/sys, and /app/data. The partitions are sdc1, sdb1, and sdb2 respectively. We will use this information to see what dstat says.
In Figure 17-8 we can see that we have used the –D switch to dstat to pass in the partitions we want to monitor. We have a significant amount of data being written to sdc1, which is our application logging. In our pretend world I would suspect that our application has been started with debug logging.
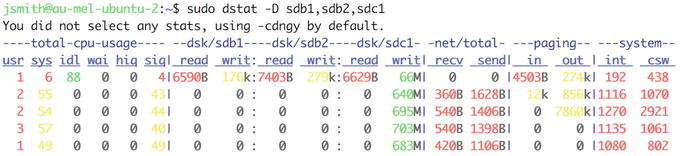
Figure 17-8. dstat disk access
Similarly, you can use the –N switch to supply network interfaces to dstat (-N em1,em2) to report network traffic per interface. The –C will do a similar job for CPUs. You should check the help or man page for more information.
We’ll come back to how you can get notifications when system performance degrades when we cover Nagios in Chapter 18.
Continuous Performance Monitoring
Now that you have the basic tools to diagnose where a performance bottleneck is, we will show you how to automate ongoing monitoring. This will give you access to longer-term performance and resource usage data, which in turn allows you to make a better determination on whether and when to upgrade hardware or migrate services to other hosts. We are going to introduce you to the following tools:
Collectd: System statistics collection daemon
Graphite: A store to collect and graph metrics
Grafana: A nice front-end interface for presenting graphs of metrics
Collectd
Collectd is a robust system metrics collection daemon that can collect information about your system and various applications and services. It is highly configurable and works out of the box to collect metrics for you.
We are going to use Collectd to gather metrics from our hosts and send them to Graphite, a metrics collection store. However, you can write metrics to many other back ends using the Write HTTP or Network plug-in.
You can install Collectd on both Ubuntu and CentOS via your package manager. For CentOS you will need to have the epel-release package installed as the Collectd packages aren’t available in the standard repositories.
The Ubuntu version available from the standard Ubuntu repositories is slightly behind the current version, but the CentOS version is fairly recent; depending on the features you require, this may affect your install decisions.
Installation is simple. On CentOS you would issue the following to install Collectd and the mysql plug-in:
$ sudo yum install collectd collectd-mysqlThere are several plug-in packages that you can install in the same way, depending on your requirements (use yum search collectd for a list). On Ubuntu it is simply as follows:
$ sudo aptitude install collectdCollectd Configuration
The Collectd service is configured from the main collectd.conf file. Of course, there is a slight difference where these are installed. On Ubuntu it is installed into the /etc/collectd directory, and on CentOS it is installed into the /etc/ directory.
You can also drop in configuration files into the collectd.d directory. This of course is different on Ubuntu (/etc/collectd/collectd.conf.d/) compared to CentOS (/etc/collectd.d/).
There is a required format for the configuration files used with Collectd. It is as follows:
global options# plugin without optionsLoadPlugin plugin_name# loading a plugin and overriding options<LoadPlugin plugin_name>...plugin options...</LoadPlugin># provide an option block to plugins without a LoadPlugin stanza (requires AutoLoadPlugin true)<Plugin plugin_name>... plugin options...</Plugin>
There are two types of plug-ins: read plug-ins and write plug-ins (some can be read and write plug-ins). Read plug-ins will collect data, and write plug-ins will put collected data somewhere. Each plug-in can be placed in its own configuration file; however, if there are duplicates that LoadPlugin calls, the first that is read in will be executed, and any other configuration for that plug-in will be silently ignored. The configuration is similar to Apache web server configuration files. Configuration blocks are enclosed in <>...</>.
In this example, we will collect the basic system metrics , such as CPU, memory, and disk space, and we will measure some database stats with the mysql plug-in. Our database server happens to be CentOS, and the installation of the mysql collectd plug-in has placed a mysql.conf file in the /etc/collectd.d directory. The Collectd configuration is the same no matter which distribution you are using.
We will first look at the collectd.conf file (Listing 17-3).
Listing 17-3. collectd.conf Configuration Global Options
#Hostname "localhost"FQDNLookup true#BaseDir "/var/lib/collectd"#PluginDir "/usr/lib/collectd"#TypesDB "/usr/share/collectd/types.db" "/etc/collectd/my_types.db"#AutoLoadPlugin false#CollectInternalStats false#Interval 10#MaxReadInterval 86400#Timeout 2#ReadThreads 5#WriteThreads 5#WriteQueueLimitHigh 1000000#WriteQueueLimitLow 800000
The Global options for Collectd apply to the Collectd service itself and define things like the base directory, plug-in directory, interval and read/write threads, and queue limits. These can mostly remain as the defaults. The FQDNLookup line means that it will look up the hostname of the computer this is running on, or you can force this via the Hostname setting.
LoadPlugin syslog<Plugin syslog>LogLevel info</Plugin>
We load our first plug-in, and it is used to direct our logs to the syslog service with the LogLevel of info. The debug value is available only if Collectd has been compiled with debugging support, notice, warning, and err are acceptable also.
LoadPlugin cpuLoadPlugin dfLoadPlugin diskLoadPlugin interfaceLoadPlugin loadLoadPlugin memoryLoadPlugin mysqlLoadPlugin swapLoadPlugin rrdtool
In this section we are loading in our plug-ins that we will use for metrics collection. We are covering the basics of cpu, df, disk, interface, load, memory, and swap. These should be fairly self-explanatory to you by now. The mysql plug-in will be used to collect some InnoDB statistics from our MariaDB database. Finally, we have the rrdtool plug-in that will be used to output the metrics as RRD files.
RRD stands for “round-robin database ” files, which are normally used to hold time-series data. Time-series databases hold db record types such as counts, gauges, and histograms. They can hold these records at different granularities. You might have records that are collected every second, and they can be stored at that granularity in the RRD files. Or we might choose a granularity of 5 minutes for those metrics, and 1-second metrics are rolled up as 5-minute averages.
There are other options for storing your metrics, and we will show you how they can be configured in the next section.
<Plugin cpu>ReportByCpu trueReportByState trueValuesPercentage false</Plugin>
When we declare our configuration options for our CPU , we are giving the options to report by CPU and report by state, and we are not showing values as percentages. This will give us an accurate picture of our CPU workloads.
<Plugin df>FSType rootfsFSType sysfsFSType procFSType devtmpfsFSType devptsFSType tmpfsFSType fusectlFSType cgroupIgnoreSelected true</Plugin>
The df plug-in shows another example of how to refine the metrics we want to select. In this example we are listing the values we do not want to collect in our metrics, and then we use IgnoreSelected true to exclude them from our collection. The file types listed are pseudo-filesystems that just add noise.
<Plugin disk>Disk "/^(xv)?[hs]?d[a-z]d?$/"IgnoreSelected falseUseBSDName falseUdevNameAttr "DEVNAME"</Plugin>
With the disk plug-in, we are doing the opposite of what we did with the df plug-in. Here we are selecting the devices we want to monitor and naming them via a regular expression. We may have disks that are named in the following ways:
/dev/sda2/dev/hdb4/dev/xvda3
We need to be able to match on any of these disk naming conventions. First, we look for the x and v together (^(xv)?) and match this pattern zero or more times at the start of string (^). Next, we may have an h or an s zero or more times ([hs]?). Then we anchor around the d, followed by any a to z disk ([a-z]). Then, we expect zero or more partition numbers (d?). Finally, the end of the line is also matched ($).
When we match with IgnoreSelected false, we should be able to match on our disk names. UseBSDName false is used only on Macs, and UdevNameAttr "DEVNAME" means we try to use the Udev name for the disk device.
<Plugin interface>Interface "localhost"IgnoreSelected true</Plugin>
Again, with the interface configuration, we make use of the IgnoreSelected option. We want to collect metrics for each network interface except the localhost or loopback interface.
<Plugin load>ReportRelative true</Plugin><Plugin memory>ValuesAbsolute trueValuesPercentage false</Plugin>
The previous are the defaults for memory and load and are similar to other system metrics we are gathering.
<Plugin mysql><Database no_db>Host "localhost"Port "3306"User “monitor"Password “monitorpasswd"ConnectTimeout 10InnodbStats true</Database></Plugin>
The mysql plug-in will work just as good with our MariaDB server. It requires a user with USAGE privileges only and will gather internal metrics the equivalent of the mysql SHOW STATUS; command. If you are after query metrics, you can look at the dbi plug-in, which you can use to run metrics against your database.
In the mysql plug-in, you can specify the database or several databases in <Database> </Database> blocks.
<Plugin rrdtool>DataDir "/var/lib/collectd/rrd"CacheTimeout 120CacheFlush 900WritesPerSecond 30CreateFilesAsync falseRandomTimeout 0</Plugin>
The rrdtool plug-in is a write plug-in and is used to write rrd files to local disk. Once you start your Collectd service, you will see many files being created in /var/lib/collectd/rrd. While this works fine for small systems, it does not scale very well and, under heavy system usage, can task disk performance. This is why many people have moved away from this to other metric storage and collection systems, like Graphite, which will use to replace this shortly.
<Include "/etc/collectd/collectd.conf.d">Filter "*.conf"</Include>
Lastly we have an include statement that says, include any files ending with the .conf suffix in the /etc/collectd/collectd.conf.d directory.
Starting and Stopping Collectd
Starting and stopping Collectd is again very straightforward. On both Ubuntu and CentOS you would issue the following commands:
$ sudo systemctl start collectd$ sudo systemctl status collectd$ sudo systemctl enable collectd
In the previous lines, we have started Collectd, checked the status, and enabled it on bootup. Successful status output will look like this:
-- Unit collectd.service has begun starting up.Nov 15 21:55:26 backup collectd[8000]: plugin_load: plugin "syslog" successfully loaded.Nov 15 21:55:26 backup collectd[8000]: plugin_load: plugin "cpu" successfully loaded.Nov 15 21:55:26 backup collectd[8000]: plugin_load: plugin "interface" successfully loaded.Nov 15 21:55:26 backup collectd[8000]: plugin_load: plugin "load" successfully loaded.Nov 15 21:55:26 backup collectd[8000]: plugin_load: plugin "memory" successfully loaded.Nov 15 21:55:26 backup collectd[8000]: plugin_load: plugin "mysql" successfully loaded.Nov 15 21:55:26 backup collectd[8000]: plugin_load: plugin "rrdtool" successfully loaded.Nov 15 21:55:26 backup collectd[8000]: Systemd detected, trying to signal readyness.Nov 15 21:55:26 backup collectd[8000]: Initialization complete, entering read-loop.Nov 15 21:55:26 backup systemd[1]: Started Collectd statistics daemon.-- Subject: Unit collectd.service has finished start-up-- Defined-By: systemd-- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel---- Unit collectd.service has finished starting up.---- The start-up result is done.Nov 15 21:55:26 backup collectd[8000]: mysql plugin: Successfully connected to database <none> at server Localhost via UNIX socket with cipher <none> (server version: 5.5.50-MariaDB, protocol version: 10)
You can see that we have successfully connected to our database. You should check the systemctl status or syslog if you have any issues.
Now that we have this successfully set up, we will look at setting up Graphite so we can collect metrics and store them centrally.
Graphite
According to the web site, Graphite does only three things: kicks arse, chews bubble gum, and makes it easy to store and graph metrics. We are unqualified to verify the first two statements, but the third statement is correct.
There are four components to Graphite.
Carbon: A high-performance listener for receiving time-series data
Whisper: A time-series database for metrics data
Graphite-web: A web UI that renders graphs and dashboards
Graphite-API: An API that fetches JSON data from the time-series Whisper database
In this exercise we are going to be installing Carbon, the time-series Whisper database and the Graphite-API. We will be using Grafana to display our metrics (in the next section) and so do not need install Graphite-web.
The Carbon components are comprised of carbon-relays and carbon-aggregators and carbon-cache. We are interested in installing the carbon-cache and a carbon-relay. All three components help to scale the Carbon service to enable the collection of thousands of metrics per second.
The carbon-cache is a required component and forms the basic collection model, carbon-cache, Whisper, and Graphite-API. It is able to listen on UDP or TCP ports (2003, 2004, 2007) and supports Python pickle and newline-delimited formats. The carbon-cache also configures how data will be stored in the Whisper databases. You can store different retention periods based on certain metric patterns. These are referred to as the storage-schema.
The carbon-relay is used to send metrics to certain back-end servers based on metric patterns. There are two ways a carbon-relay can be used, for sharding requests (using consistent hashing) to multiple backends and for replication, sending metrics to any number of different carbon-cache servers or aggregators.
Carbon-aggregators are used to buffer metrics that are destined for the carbon-cache to help reduce I/O. Averages or sums can be made of the metrics and pushed into Whisper as a single metric, reducing I/O on the carbon-cache and Whisper database.
Whisper is a time-series database for long-term storage of your metrics data. It is written in Python and allows for high-precision data resolution to degrade over time. When data degrades, the data points are “rolled up” or aggregated. You can choose to aggregate using the following functions:
Average (default)
Sum
Max
Min
Last
You can find more information on Whisper here:
Note
There are a number of back-end time-series databases that can be used instead of Whisper. Some are listed here: https://graphite.readthedocs.io/en/latest/tools.html#storage-backend-alternates .
Graphite-web is one of the ways you can view your data. It is a Python app that requires the backing of a database, either SQLite (for very small deployments), MariaDB, or PostgreSQL. It also supports LDAP authentication.
If you want to present your metrics via a different graphical presentation service, you can just install Graphite-API , which will return JSON responses to metric queries. This provides a lighter, stateless interface into your metrics from any number of third-party graphical web UIs.
Graphite Installation
The Graphite components are easily installed using the common packaging tools, YUM and Apt, or via Pip (the Python packaging tool).
On CentOS you can install Graphite with the following:
$ sudo yum install -y python-carbonThis will install carbon-cache and the Whisper database (python-whisper). Graphite-API is installed via the graphite-api package.
$ sudo yum install –y graphite-apiOn Ubuntu you need to install the following to install carbon-cache and Whisper:
$ sudo aptitude install -y graphite-carbonAgain, to install the Graphite-API component, you need to issue the following:
$ sudo aptitude install –y graphite-apiAn alternative exists to install and experiment with Graphite. The developers of Graphite have provided a quick way to install and configure it.
At the time of writing, this will spin up a Vagrant Ubuntu 14.04 and install version 0.9.5 of the Graphite software. You will have an environment up and running quickly to begin testing it.
Configuring Carbon-Cache
Most of the configuration for Graphite is in how we configure the carbon-cache. We use the same file for configuring the carbon-cache, aggregator, and relay. To achieve this, the file can be divided up into sections: [cache], [aggregator], and [relay]. This configuration file is well commented and is the source of truth for options available to you.
Carbon-cache and carbon-relays can be run on the same instance; aggregators should be one separate hosts. In this exercise, we are going to configure the carbon-cache and a carbon-relay.
To begin with, we will configure the carbon-cache. We can configure generic, or global, options under the [cache] section.
[cache]STORAGE_DIR = /var/lib/graphite/LOCAL_DATA_DIR = /var/lib/graphite/whisper/CONF_DIR = /etc/carbon/LOG_DIR = /var/log/carbon/PID_DIR = /var/run/ENABLE_LOGROTATION = FalseUSER = _graphite
Here we are describing the general configuration of where we will store or retrieve data and service housekeeping. The important note here is that USER will be carbon on CentOS and _graphite on Ubuntu. These must be set for the [relay] and [aggregator] sections as well. The next section further describes the service. In Listing 17-4 are the default settings that are installed with package; these are the same for both distributions.
Listing 17-4. Default Carbon-Cache Settings
ENABLE_UDP_LISTENER = FalseUDP_RECEIVER_INTERFACE = 0.0.0.0MAX_CACHE_SIZE = infMAX_UPDATES_PER_SECOND = 500MAX_CREATES_PER_MINUTE = 50CACHE_WRITE_STRATEGY = sortedWHISPER_AUTOFLUSH = FalseWHISPER_FALLOCATE_CREATE = TrueUSE_FLOW_CONTROL = TrueLOG_LISTENER_CONNECTIONS = TrueLOG_UPDATES = FalseLOG_CACHE_HITS = FalseLOG_CACHE_QUEUE_SORTS = TrueUSE_INSECURE_UNPICKLER = False
First, the UDP listener is disabled by default, leaving the TCP listener as the default. Then we have some settings for our cache writing. MAX_CACHE_SIZE is set to inf, or infinite. You should limit this if you are seeing a lot of swapping or CPU-bound processes. As the cache size grows, the more expensive sorts and queries of the cache become. MAX_UPDATES_PER_SECOND and MAX_CREATES_PER_MINUTE are set to limit high disk I/O contention.
CACHE_WRITE_STRATEGY can have three possible settings.
sorted (default): Data points are flushed to disk as an ordered list.
max: Frequently updated data points are flushed to disk, and infrequent data points will be flushed at shutdown or low disk I/O periods (if there are any).
naive : Data points are flushed in an unordered list.
There is further detail on these settings in comments of the carbon.conf file. WHISPER_AUTOFLUSH and WHISPER_FALLOCATE_CREATE are related to kernel options. WHISPER_AUTOFLUSH set to True will cause Whisper to write synchronously, handled by the carbon-cache, and WHISPER_FALLOCATE_CREATE (Linux only) can speed up file creation (and therefore allow you to increase MAX_CREATES_PER_MINUTE).
Setting USE_FLOW_CONTROL to True (default) means that if MAX_CACHE_SIZE is reached, carbon-cache will stop accepting connections until the cache is below 95 percent.
Next we have a set of logging options. Setting these to True can produce high I/O and should be turned on and off if you need to further investigate issues; we have left the default settings.
Finally, in Listing 17-4 there is an option to allow the older and less secure version of unpickler, USE_INSECURE_UNPICKLER = False. Unless you have a really strong need, leave this as it is.
In this next section we define the interfaces and ports for our carbon-cache service:
LINE_RECEIVER_INTERFACE = 0.0.0.0PICKLE_RECEIVER_INTERFACE = 0.0.0.0CACHE_QUERY_INTERFACE = 0.0.0.0LINE_RECEIVER_PORT = 2003PICKLE_RECEIVER_PORT = 2004CACHE_QUERY_PORT = 7002
Here you can target your listeners to listen on certain IP addresses (IPv4); you should leave the ports as the defaults here. The line receiver supports the newline-delimited format (which means a newline signals the end of the metric). The pickle receiver supports the Python pickle object serialization ( https://docs.python.org/3/library/pickle.html ).
You can improve carbon-cache performance by having multiple cache declarations. A declaration like [cache:1] with different receiver ports specified looks like so:
[cache:1]LINE_RECEIVER_PORT = 2103PICKLE_RECEIVER_PORT = 2104
You can have one carbon-cache per CPU if you are running on a host with several CPUs.
The last piece of a carbon-cache is the way we store our metric data in our Whisper database. We do this by the file /etc/carbon/storage-schemas.conf. The file can look like this:
[carbon]pattern = ^carbon.retentions = 60s:90d[default_1min_for_1day]pattern = .*retentions = 60s:1d
Different metrics can have different retentions periods. You define them after giving them a [name]. You can see that we can match metrics that match the pattern ^carbon. (that is, metrics starting with the word carbon). Metrics generated by carbon itself can look like this:
carbon.agents.host1.cache.queriesFor this pattern we can see that they have a 60-second resolution and are stored at this resolution for 90 days (frequency:retention). As a default, we will record all metrics at a minute resolution for 1 day as a catchall collector.
Suppose we wanted to collect metrics from our databases. Collecting metrics from something like a database can produce a significant amount, so we can change the frequency and retention accordingly. As an example, you might choose something like this:
[database_metrics]pattern = ^collectd_(db|backup)_*retentions = 15s:7d,1m:90d,15m:180d
Here we are selecting metrics based on the pattern collectd_ followed by either db_ or backup_, and we will retain that for 15-second frequency for 7 days, 1 minute for 90 days, and 15 minutes for 180 days. That means, by default, our 15-second metrics will be averaged over a minute after 7 days, losing that precise resolution. That will continue until 90 days when they will again be averaged over a 15-minute period.
You may need to update your firewalls to allow access to ports 2003 and 2004. That is all you need to configure a basic carbon-cache .
Configuring Carbon-Relay
In this section we are going to configure the carbon-relay. In small networks you won’t need to do this as a single Graphite carbon-cache can manage a significant number of metrics per host. In this scenario our hosts will send their metrics to our relay.example.com host on port 2013 (which is a line-delimited receiver). From there we will send the metrics on to our monitor.example.com host, which has a carbon-cache daemon listening on port 2004.
Configuring a carbon-relay requires a carbon.conf file and a file called relay-rules.conf. Taking a look at carbon.conf you will see that we have a [cache] section that is similar to our carbon-cache configuration seen previously.
[cache]STORAGE_DIR = /var/lib/graphite/LOCAL_DATA_DIR = /var/lib/graphite/whisper/CONF_DIR = /etc/carbon/LOG_DIR = /var/log/carbon/PID_DIR = /var/run/ENABLE_LOGROTATION = FalseUSER = carbonLOG_LISTENER_CONNECTIONS = TrueUSE_INSECURE_UNPICKLER = FalseUSE_FLOW_CONTROL = TrueCACHE_WRITE_STRATEGY = sorted
Next we are going create a [relay] section.
[relay]LINE_RECEIVER_INTERFACE = 0.0.0.0PICKLE_RECEIVER_INTERFACE = 0.0.0.0LINE_RECEIVER_PORT = 2013PICKLE_RECEIVER_PORT = 2014DESTINATIONS = monitor.example.com:2004LOG_LISTENER_CONNECTIONS = TrueRELAY_METHOD = rulesMAX_DATAPOINTS_PER_MESSAGE = 500MAX_QUEUE_SIZE = 10000QUEUE_LOW_WATERMARK_PCT = 0.8USE_FLOW_CONTROL = True
It has similar settings to a carbon-cache. We will listen on the ports 2013 (line-delimited metrics) and 2014 (pickle format). With a carbon-relay we need to provide a destination (or destinations) for our metrics. If using RELAY_METHOD rules, like we are, then you need to specify each carbon-cache you have listed in your relay-rules.conf file. The relay-rules.conf file is an ordered list of relay destinations based on particular matching patterns. We will discuss this shortly, but for now we will include the monitor.example.com destination, and because we are talking carbon-relay to carbon-cache, we will use the pickle port.
MAX_DATAPOINTS_PER_MESSAGE, MAX_QUEUE_SIZE, QUEUE_LOW_WATERMARK_PCT, and USE_FLOW_CONTROL are options for flow control. MAX_QUEUE and MAX_DATAPOINTS should be adjusted with caution. LOW_WATERMARK means that if the queue exceeds 80 percent, we will stop accepting metrics.
The relay-rules.conf file enables us to direct certain metrics to particular carbon-cache destinations. Each rule requires a unique name, a pattern, a destination, and whether we continue processing after this rule. In our example we have gone with a simple relay-rules.conf file like the following:
[default]default = truedestinations = monitor.example.com:2004
There can be only one rule with default = true. By default we are sending all metrics to monitor.example.com on port 2004. Pretending that we want to send metrics from backup.example.com to a different carbon-cache, we could do the following:
[backup_example]pattern = ^collectd_backup_example_com.*destination = 192.168.0.250:2004continue = true
We would need to add 192.168.0.250 to the DESTINATIONS field in the carbon.conf file.
You can start and stop your carbon-relay service like this on CentOS:
$ sudo systemctl start carbon-relayand like this for Ubuntu where we pass the instance name to the systemd service:
$ sudo systemctl start carbon-relay@defaultUpdating Collectd Configuration
Now we need to make our changes to the Collectd configuration to send metrics to our carbon-relay. There is a plug-in called write_graphite, which will send Collectd metrics to a Graphite carbon-cache or relay.
The configuration is simple and looks like the following:
LoadPlugin write_graphite<Plugin write_graphite><Node "monitor">Host "relay.example.com"Port "2013"Protocol "tcp"ReconnectInterval 0LogSendErrors truePrefix "collectd_"StoreRates trueAlwaysAppendDS falseEscapeCharacter "_"</Node></Plugin>
This is the same plug-in format we saw earlier. In the Node block we are setting the relay host and port. We can add prefixes to our metrics and suffixes as well. Here we are adding collectd_ as a prefix to each metric to more easily track the metric origins.
We can now restart the Collectd, service and metrics should begin to be sent via the relay to the monitor server. However, if you are running CentOS, you will not be able to send metrics to port 2013 without modifying SELinux.
You can issue the following to allow Collectd to connect to the network using tcp:
$ sudo getsebool collectd_tcp_network_connectcollectd_tcp_network_connect --> off$ sudo setsebool collectd_tcp_network_connect on
You should also check /var/log/audit/audit.log for any denied messages.
Checking Logs
Once we have restarted our carbon-cache, carbon-relay, and collectd service, you should see them making connections to the services in the logs.
Collectd will log to syslog in our configuration, and Graphite will log into the /var/log/carbon directory. Taking a look at Collectd, we want to see the following in our logs:
Nov 22 23:19:06 backup collectd[5999]: plugin_load: plugin "write_graphite" successfully loaded.On our relay host, we want to see our hosts connecting to us in the /var/log/carbon/listener.log.
22/11/2016 12:29:56 :: MetricLineReceiver connection with 192.168.0.30:38309 establishedThen on our monitor host, we want to see this in the /var/log/carbon/listener.log.
20/11/2016 10:19:03 :: MetricPickleReceiver connection with 192.168.0.251:52146 establishedSo, we can see from our logs that our connections are being established between our Collectd service running on our backup host to our relay to our monitor. Now we will quickly check that metrics are being created for our backup host. The /var/log/carbon/creates.log file on the monitor host will show us if we are getting metrics from our backup hosts.
21/11/2016 11:35:48 :: new metric collectd_backup_example_com.cpu-0.cpu-user matched schema default_1min_for_1dayHere you can see that we have a metric being created for our CPU . Alright, now we have metrics being generated on our backup host and being sent to our monitor via the relay. Let’s now set up our Graphite-API service so that we can use Grafana to view them.
Configuring Graphite-API
As we have said, Graphite-API is the lightweight front end for Graphite. It allows applications to query metrics from our carbon-cache. To run it, we need to other components, Gunicorn and Nginx.
Gunicorn is a Python fork of the unicorn project, a web server gateway interface that powers many Ruby on Rails applications. We will use this to glue the Nginx web server requests to the Graphite-API application.
Nginx we have spoken of briefly. It is a very fast, low-resource web server that will sit in front of Gunicorn and pass web requests to it. We will use Nginx as a proxy service for our application.
Setting Up Gunicorn
We are going to set up Gunicorn to serve our Graphite-API application. To do that, we will get it to start our application listening on a loopback interface and listening on a particular port. This will allow Nginx to proxy requests to this port and serve the responses.
We can install Gunicorn via the pip command, which is the Python package manager. On Ubuntu we need to use pip3, or version 3 of pip, to install Gunicorn as Graphite-API is a Python 3 install. On CentOS the standard pip command will suffice as it is a Python 2.7 install.
$ sudo pip3 install gunicornAgain, specifically for Ubuntu, we are going to create a symlink for /usr/local/bin/gunicorn to be /usr/bin/gunicorn. This will enable us to write one systemd service file for both Ubuntu and CentOS.
$ ln –s /usr/local/bin/gunicorn /usr/bin/gunicornNow we will create the systemd file to start the Gunicorn service. We will create a service file and socket file as we expect to run a socket for Nginx to connect in to. As you may recall, local systemd files live in /etc/systemd/system. We will create the file /etc/systemd/system/graphite-api.socket.
[Unit]Description=graphite-api socket[Socket]ListenStream=/run/graphite-api.sockListenStream=127.0.0.1:8881[Install]WantedBy=sockets.target
Here we are saying to systemd, create a socket /run/graphite-api.sock that listens on the loopback address on port 8881. The WantedBy will mean that this will be started when the socket.target is activated.
Looking now at the service file, /etc/systemd/system/graphite-api.service, we can see the following details:
[Unit]Description=Graphite-API serviceRequires=graphite-api.socket[Service]ExecStart=/usr/bin/gunicorn -b 127.0.0.1:8881 -w2 graphite_api.app:appRestart=on-failureExecReload=/bin/kill -s HUP $MAINPIDExecStop=/bin/kill -s TERM $MAINPIDPrivateTmp=true[Install]WantedBy=multi-user.target
Here you can see that we call the gunicorn command to start graphite_api.app. We ask it to connect to 127.0.0.1 on port 8881. We also require graphite-api.socket. The –w2 says to start two worker processes to handle requests.
We can now use the systemctl command to start and stop the service and the socket.
$ sudo systemctl start graphite-api.serviceYou can read more about Gunicorn here:
Setting Up Nginx
While Gunicorn is a web server, it is recommended to deploy behind a proxy server. The proxy server can handle thousands of connections and acts as a buffer between the clients and the Gunicorn processes.
All that is required is for us to put the following graphite.conf file in a place where the Nginx server can find it:
upstream graphite {server 127.0.0.1:8881 fail_timeout=0;}server {server_name monitor;listen 80;root /var/www;location / {try_files $uri @graphite;}location @graphite {proxy_pass http://graphite;}}
With Nginx , a proxy server is declared as an upstream server. That is declared in the upstream <name> { .. } section. In this section we tell Nginx to direct any requests for Graphite upstream servers to server 127.0.0.1:8881 where our Gunicorn server will be listening. If you have more than one back-end server listed, Nginx will round-robin between the two.
The server { ... } section is the front-end server declaration. We provide a server name, port we listen on, and root path. The root does not need to exist as all requests will be passed off to the back-end servers. We do this with the location / { ... } directive. When we make a request to any URI, we try first to return the URI, and then, if it is not found, we send the request to the @graphite location. The location @graphite { ... } then sends the request to the upstream server at http://graphite (which is the upstream server we have declared at the top of the file).
Depending on your distribution, you will do either one of the following. On Ubuntu you place graphite.conf in the /etc/nginx/sites-available/ directory. We then need to make the symlink to sites-enabled and start Nginx like so:
$ sudo ln –s /etc/nginx/sites-available/graphite.conf /etc/nginx/sites-enabled/graphite.conf$ sudo systemctl start nginx
On CentOS we need to place graphite.conf in the following directory, /etc/nginx/conf.d/. Then we can start Nginx like normal.
$ sudo systemctl start nginxBy default both distributions will log to /var/log/nginx. We can test that our API is working correctly with the following:
$ curl -H 'Host: monitor' http://127.0.0.1:80/metrics/find?query=*[{"text": "carbon", "expandable": 1, "allowChildren": 1, "id": "carbon", "leaf": 0}, {"text": "relay", "expandable": 1, "allowChildren": 1, "id": "relay", "leaf": 0}]
This shows that we can contact the Nginx web server, and that will make a request to the back-end Gunicorn service that will return our query request for our metrics.
Grafana
Grafana is a visualization web application for graphing time-series data. It can talk to a variety of data sources including Graphite-API. With your newly created metrics, you can now create dashboards and display those metrics.
Grafana supports LDAP authentication and can use a database to store users’ dashboards. It has a stand-alone web service that you interact with. You can install it on your localhost or a central server; it does not store metric data locally but will make request to back-end storage services, in our case Graphite.
Installing Grafana
We are going to install Grafana on our Ubuntu server. We are going to follow the instructions from here: http://docs.grafana.org/installation/debian . You can follow the instructions here for CentOS: http://docs.grafana.org/installation/rpm/ . You can also install Grafana on macOS or Windows.
First we will add the Grafana repository.
$ sudo bash -c 'echo "deb https://packagecloud.io/grafana/stable/debian/ jessie main" > /etc/apt/sources.list.d/grafana.list'$ curl https://packagecloud.io/gpg.key | sudo apt-key add -$ sudo aptitude update$ sudo aptitude install –y grafana
Once it is installed, we can start the Grafana service. This is the same for both Ubuntu and CentOS:
$ sudo systemctl start grafana-serverNow we can access Grafana on the following URL: http://monitor:3000. By default the username and password are admin (Figure 17-9).

Figure 17-9. Logging into Grafana
Adding Storage Back End
Before we can graph any of our newly Collectd metrics, we need to add our Graphite back end. We need to add it as a data source (Figure 17-10).

Figure 17-10. Selecting data sources
From the Data Sources screen we click the green “Add data source ” button and fill in the details (Figure 17-11).
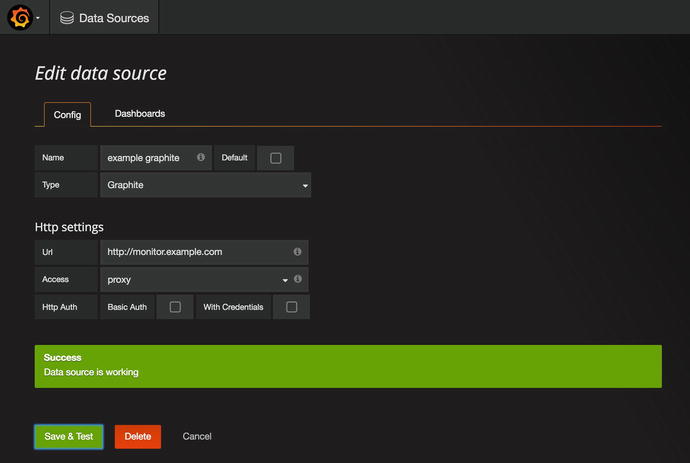
Figure 17-11. Adding Graphite as our data source
Clicking Save & Test will try to make a request to our Graphite host and test that it can get appropriate data back. If we click the Dashboards tab, we will import the Graphite metrics dashboard (Figure 17-12).

Figure 17-12. Clicking Import
After you have imported the dashboard, you can click Graphite Carbon Metrics and you will be shown Figure 17-13.
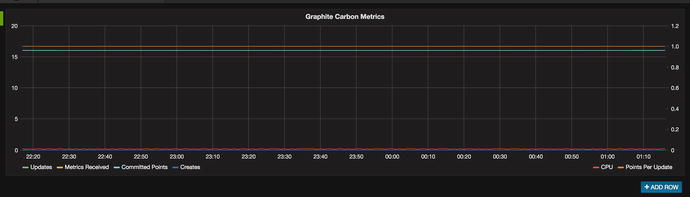
Figure 17-13. Carbon Metrics graph
Let’s create a new dashboard by selecting Create New , as shown in Figure 17-14.
Figure 17-14. Creating a new graph
When you create a dashboard, a green bar will appear on the left side. Then select Add Panel and Graph, as shown in Figure 17-15.
Figure 17-15. From the left drop-down, select Graph
When you add a panel, you get a test metric graph based on fake data (Figure 17-6).
Figure 17-16. Test metric
To create our own graphs, we have to select the data source first. Let’s do that, as in Figure 17-17.
Figure 17-17. Selecting the Panel data source
Once we select the data source , the test data will disappear. You can click “select metric” and choose the origin of the metric you want to graph. We have selected “collectd_backup_example_com,” and then we can select the metrics we interested in. We will choose “load” out of the list. We then select all the metrics available (*) and then again (*). In Figure 17-18 you can see we have tracked the host’s load over 15 minutes. You can see more about Grafana in this YouTube tutorial by Grafana: https://youtu.be/1kJyQKgk_oY .
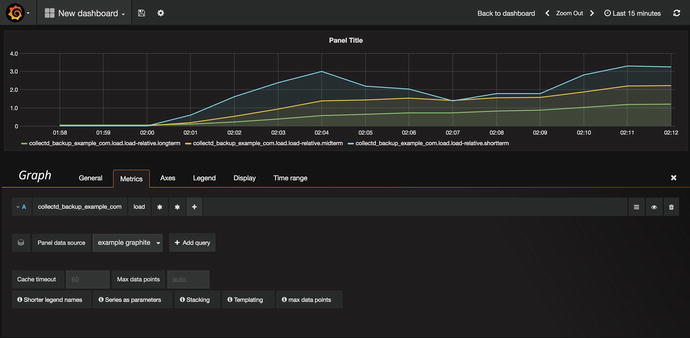
Figure 17-18. Seeing load metrics on backup host
Now that you have your metrics being collected and discoverable, you look at making performance tweaks and be able to measure their effect.
Performance Optimization
When your host was installed, it was set up with defaults that offer reasonable performance for most configurations. However, since each host is different, you can usually tweak settings to make the configuration more optimal for a specific workload.
In this section, we’ll show you some tips and tricks that should help speed up your host for most server-related tasks.
Resource Limits
Linux allows you to enforce resource limits on users via the ulimit command . This is actually a built-in function of the Bash shell . Any limits you set via this command apply only to the current shell and the processes it starts.
To report current limits, run ulimit with the -a option, as shown in Figure 17-19.
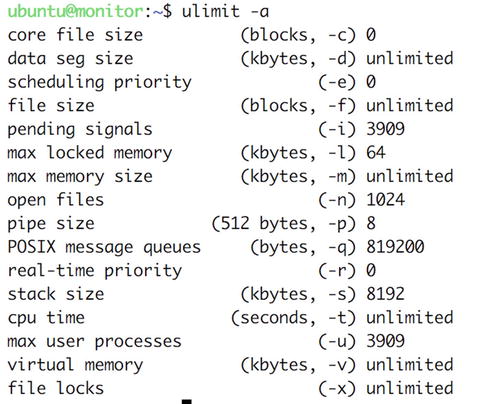
Figure 17-19. ulimit -a
To prevent a fork bomb from being run by this shell user, you can change the maximum number of running processes, for instance, from 3909 to 1, using the -u option. If you then try to run a new process, the system will prevent you from doing so.
$ ulimit -u 1$ lsbash: fork: Resource temporarily unavailable
You receive an error to indicate the shell could not fork the command you tried to run. We are not suggesting that you manage users in this way but instead demonstrating the effect of this command.
Caution
If you are logged in via SSH or X, you will already have several running processes.
The other useful limits are the maximum memory size, which can be set via the -m option, and the number of open files, which you set via -n. The most common change you may make when tuning for resource limits is the number of open files a user can have.
You can obtain a full listing of options and their functions in the ulimit section of the man bash page.
Setting Limits for All Users
The ulimit command sets limits for the current shell, so you can add limits via /etc/profile or /etc/bashrc for users who log in. However, most daemons don’t use shells, so adding limits to the shell configuration files won’t have any effect.
You can instead use the limits module for PAM. This module is invoked when a user creates a new process, and it sets limits that you can define in /etc/security/limits.conf. This file defines both soft and hard limits for users and groups. We’ve included the sample limits.conf from CentOS in Figure 17-20.

Figure 17-20. Setting limits for all users
Each line specifies a domain that the limit applies to. This domain can be a wildcard, a username, or a group name. Next comes the limit type, which can be either soft or hard. A hard limit can be set only by the root user, and when a user or process tries to break this limit, the system will prevent this. The soft limit can be adjusted by the user using the ulimit command, but it can be increased only to the value of the hard limit.
Next is the resource that is being limited. A full listing of available resources is included in the sample file, and it also available on the man limits.conf page. Last on each line is the value that the limit should be set to. Lines beginning with # are comments or examples.
In the case of the sample file, the @faculty group is allowed to run 20 concurrent processes (nproc) according to their soft limit. However, any member of this group is allowed to change that limit to any value up to 50 but no higher than that.
sysctl and the proc File System
We briefly mentioned the proc file system in Chapter 9 as a way to obtain system information directly from the kernel. It also provides a way to tweak a running kernel to improve system performance. To this end, you can change values in virtual files under the /proc/sys directory.
The virtual files are grouped in subdirectories, based on the parts of the system they affect, as listed in Table 17-2.
Table 17-2. /proc/sys Subdirectories
Directory | Used By |
|---|---|
abi | System emulation (e.g., running 32-bit applications on a 64-bit host). |
crypto | Cryptography-related information, like ciphers, modules, and so on. |
debug | This is an empty directory; it’s not used. |
dev | Device-specific information. |
fs | File system settings and tuning. |
kernel | Kernel settings and tuning. |
net | Network settings and tuning. |
sunrpc | Sun Remote Procedure Call (NFS) settings. |
vm | Memory, buffer, and cache settings and tuning. |
We won’t go into detail on every single file, but we’ll give you an idea of the kinds of tweaking that can be done.
Each of the virtual files contains one or more values that can be read via cat or the sysctlutility. To list all current settings, we can use the following:
$ sysctl –aabi.vsyscall32 = 1crypto.fips_enabled = 0debug.exception-trace = 1debug.kprobes-optimization = 1dev.hpet.max-user-freq = 64dev.mac_hid.mouse_button2_keycode = 97...vm.percpu_pagelist_fraction = 0vm.stat_interval = 1vm.swappiness = 30vm.user_reserve_kbytes = 29608vm.vfs_cache_pressure = 100vm.zone_reclaim_mode = 0
To read a particular value, pass its key as a parameter to sysctl.
$ sudo sysctl vm.swappinessvm.swappiness = 30
The key is the full path to the file, with /proc/sys/ removed and the slashes optionally replaced with full stops. For instance, to check how likely your host is to use swap memory, you can check the contents of /proc/sys/vm/swappiness.
$ cat /proc/sys/vm/swappiness30
This particular value is an indication of how likely the kernel is to move information from RAM into swap space after it hasn’t been used for a while. The higher the number, the more likely this is. The value in this case can range from 0 to 100, with 60 being the default. If you wanted to ensure your host is less likely to use swap memory, you could set the value to 20 instead via the sysctl utility and the -w option. You would need to then pass the key whose value you want to change and the new value.
$ sudo sysctl -w vm.swappiness=20Another example is the number of files and directories that can be open at any single moment on the system. This is defined in /proc/sys/fs/file-max, and you can read the value via the command sysctl fs.file-max. To increase the maximum number of open files to half a million, run sudo sysctl -w fs.file-max=500000.
Caution
Changing kernel variables in the proc filesystem can have not only a positive impact but also a large adverse impact on system performance. We recommend you do not change anything unless you have a good reason to. A good approach for tuning is measure, change, measure. If you can’t measure, be very careful.
When the system is rebooted, these variables are reset to their default values. To make them persist, you can add an appropriate entry in the /etc/sysctl.conf file. When the system boots, all settings in this file are applied to the system via the sysctl -p command.
On Ubuntu , instead of directly editing /etc/sysctl.conf, you can create a file in /etc/sysctl.d/<number>-<option-name>.conf, and they will be read in at boot.
On CentOS you will find the default system settings in /usr/lib/sysctl.d. You can override these in /etc/systctl.conf or by placing a file like on Ubuntu in /etc/sysctl.d/.
More information on sysctl settings can be found with man sysctl.d. A comprehensive list of available variables, with documentation, is available at https://www.kernel.org/doc/Documentation/sysctl/ .
Storage Devices
In Chapter 9 you saw that in the event of a disk failure, the kernel needs to rebuild the RAID array once a replacement disk is added. This task generates a lot of I/O and can degrade performance of other services that the machine may be providing. Alternatively, you might want to give priority to the rebuild process, at the expense of services.
While a rebuild occurs, the kernel keeps the rebuild speed between set minimum and maximum values. We can change these numbers via the speed_min_limit and speed_max_limit entries in the /proc/sys/dev/raid directory.
A more acceptable minimum speed would be 20,000K per second per disk, and you can set it using sysctl.
$ sudo sysctl -w dev.raid.speed_limit_min=20000Setting the minimum too high will adversely affect performance of the system, so make sure you set this number lower than the maximum throughput the system can handle, divided by the number of disks in your RAID array.
The maximum, which can be changed by setting the dev.raid.speed_limit_max variable, is fairly high already. If you want a RAID rebuild to have less of a performance impact, at the cost of a longer wait, you can lower this number.
To make these changes permanent, add these key-value pairs to /etc/sysctl.conf.
File System Tweaks
Each time a file or directory is accessed, even if it’s only for reading, its last accessed time stamp (or atime) needs to be updated and written to the disk. Unless you need this timestamp, you can speed up disk access by telling your host to not update these.
By default, your system should mount your disks with the relatime option. This option means that each file access does not initiate an update to the file metadata, which increases performance by not issuing unnecessary operations. It is synonymous with noatime.
If it is not set, you simply add the noatime option to the options field in the /etc/fstab file for each filesystem on which you want to enable this option.
UUID=f87a71b8-a323-4e8e-acc9-efb0758a0642 / ext4 defaults,errors=remount-ro,relatime 0 1
This will enable the option the next time the filesystem is mounted. To make it active immediately, you can remount the filesystem using the mount command.
$ sudo mount -o remount,relatime /In addition to mount options, filesystems themselves provide some features that may improve performance; these vary depending on what a particular file system is used for. The main one of these is dir_index, and it applies to the ext2, ext3, and ext4 file systems. Enabling this feature causes the file system to create internal indexes that speed up access to directories containing a large number of files or subdirectories. You can use the tune2fs utility to check whether it’s enabled.
$sudo tune2fs -l /dev/md0 | grep featuresFilesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bgsparse_super large_file huge_file uninit_bg dir_nlink extra_isize
If you need to change features, and you rarely do, you could use tune2fs to enable a particular feature.
sudo tune2fs -O dir_index /dev/md0Alternatively, features can be turned off by prefixing their name with a caret.
sudo tune2fs -O ^dir_index /dev/md0You can set which options should be enabled on the various ext file systems by changing the defaults in the /etc/mke2fs.conf file.
I/O Schedulers
I/O schedulers, also called I/O elevators, are algorithms that kernel will use to order I/O to disk subsystems. Schedulers can be changed to improve the efficiency of this process. Three schedulers are available to the kernel.
Cfq: This is the default scheduler for SATA devices and tries to implement completely fair queues for processing I/O.
Deadline: This is the default scheduler for block devices. It preferences read requests and tries to provide certainty to requests by imposing a deadline on the start time.
Noop: This is a first in/first out queue, where the I/O is left to lower subsystems to order; it is suitable for virtual machines.
You can find the scheduler on your device by executing a command similar to this:
$ cat /sys/block/sda/queue/schedulernoop deadline [cfq]
The scheduler in [] is the current setting. You can change it with the following command:
$ sudo bash -c 'echo deadline > /sys/block/sda/queue/scheduler'$ cat /sys/block/sda/queue/schedulernoop [deadline] cfq
You can set the scheduler at boot time by making an edit to GRUB. You will need to edit the following file by adding this:
$ vi /etc/default/grubGRUB_CMDLINE_LINUX="console=tty0 ... rhgb quiet elevator=deadline"
This sets deadline as the default scheduler across the whole server. You then need to remake GRUB with the following:
$ sudo grub2-mkconfig -o /boot/grub2//grub.cfgNow when you reboot your host, the default scheduler is deadline.
$ cat /sys/block/sda/queue/schedulernoop [deadline] cfq
Remember that on Ubuntu grub2-mkconfig needs to be like this:
$ sudo grub2-mkconfig -o /boot/grub/grub2.cfgNow your changes will persist across reboots.
Summary
In this chapter, we showed you simple tools that allow you to easily determine the basic health of a running host. You learned how to do the following:
Check CPU usage
Check memory and swap space usage
We also introduced more advanced system metric collection tools such as Collectd and Graphite, which will help you monitor resource usage and performance on an ongoing basis. You learned how to do the following:
Install and configure Collectd
Install and configure Graphite
Use Grafana to monitor and visualize the health of your hosts
We also gave a little information on some common performance tunings and how to change the kernel settings using sysctl.
In the next chapter, you’ll see how to configure some monitoring of your hosts and services. We’ll also show you how to configure logging and monitor the logs for unusual or suspicious activity.