
If you search online for information on how to benchmark in Rust, you will probably see a bunch of guides on how to do it in nightly Rust, but not many on how to do it in stable Rust. This is because the built-in Rust benchmarks are only available on the nightly channel. Let's start by explaining how the built-in benchmarks work, so that we can then find out how to do it in stable Rust.
First of all, let's see how to create benchmarks for a library. Imagine the following small library (code in lib.rs):
//! This library gives a function to calculate Fibonacci numbers.
/// Gives the Fibonacci sequence number for the given index.
pub fn fibonacci(n: u32) -> u32 {
if n == 0 || n == 1 {
n
} else {
fibonacci(n - 1) + fibonacci(n - 2)
}
}
/// Tests module.
#[cfg(test)]
mod tests {
use super::*;
/// Tests that the code gives the correct results.
#[test]
fn it_fibonacci() {
assert_eq!(fibonacci(0), 0);
assert_eq!(fibonacci(1), 1);
assert_eq!(fibonacci(2), 1);
assert_eq!(fibonacci(10), 55);
assert_eq!(fibonacci(20), 6_765);
}
}
As you can see, I added some unit tests so that we can be sure that any modifications we make to the code will still be tested, and checked that the results were correct. That way, if our benchmarks find out that something improves the code, the resulting code will be (more or less) guaranteed to work.
The fibonacci() function that I created is the simplest recursive function. It is really easy to read and to understand what is going on. The Fibonacci sequence, as you can see in the code, is a sequence that starts with 0 and 1, and then each number is the sum of the previous two.
As we will see later, recursive functions are easier to develop, but their performance is worse than iterative functions. In this case, for each calculation, it will need to calculate the two previous numbers, and for them, the two before, and so on. It will not store any intermediate state. This means that, from one calculation to the next, the last numbers are lost.
Also, this will push the stack to the limits. For each computation, two functions have to be executed and their stack filled, and, in each of them, they have to recursively create new stacks when they call themselves again, so the stack usage grows exponentially. Furthermore, this computation could be done in parallel since, as we discard previous calculations, we do not need to do them sequentially.
In any case, let's check how this performs. For this, we'll add the following code to the lib.rs file:
/// Benchmarks module
#[cfg(test)]
mod benches {
extern crate test;
use super::*;
use self::test::Bencher;
/// Benchmark the 0th sequence number.
#[bench]
fn bench_fibonacci_0(b: &mut Bencher) {
b.iter(|| (0..1).map(fibonacci).collect::<Vec<u32>>())
}
/// Benchmark the 1st sequence number.
#[bench]
fn bench_fibonacci_1(b: &mut Bencher) {
b.iter(|| (0..2).map(fibonacci).collect::<Vec<u32>>())
}
/// Benchmark the 2nd sequence number.
#[bench]
fn bench_fibonacci_2(b: &mut Bencher) {
b.iter(|| (0..3).map(fibonacci).collect::<Vec<u32>>())
}
/// Benchmark the 10th sequence number.
#[bench]
fn bench_fibonacci_10(b: &mut Bencher) {
b.iter(|| (0..11).map(fibonacci).collect::<Vec<u32>>())
}
/// Benchmark the 20th sequence number.
#[bench]
fn bench_fibonacci_20(b: &mut Bencher) {
b.iter(|| (0..21).map(fibonacci).collect::<Vec<u32>>())
}
}
You will need to add #![feature(test)] to the top of the lib.rs file (after the first comment).
Let's first understand why we created these benchmarks. We are testing how long it takes for the program to generate the numbers with index 0, 1, 2, 10, and 20 of the Fibonacci sequence. But, the issue is that if we directly provide those numbers to the function, the compiler will actually run the recursive function itself, and directly only compile the resulting number (yes, Low Level Virtual Machine (LLVM) does this). So, all benchmarks will tell us that it took 0 nanoseconds to calculate, which is not particularly great.
So, for each number we add an iterator that will yield all numbers from 0 to the given number (remember that ranges are non-inclusive from the right), calculate all results, and generate a vector with them. This will make LLVM unable to precalculate all the results.
Then, as we discussed earlier, each benchmark should run multiple times so that we can calculate a median value. Rust makes this easy by giving us the test crate and the Bencher type. The Bencher is an iterator that will run the closure we pass to it multiple times.
As you can see, the map function receives a pointer to the fibonacci() function that will transform the given u32 to its Fibonacci sequence number. To run this, it's as simple as running cargo bench. And, the result is:
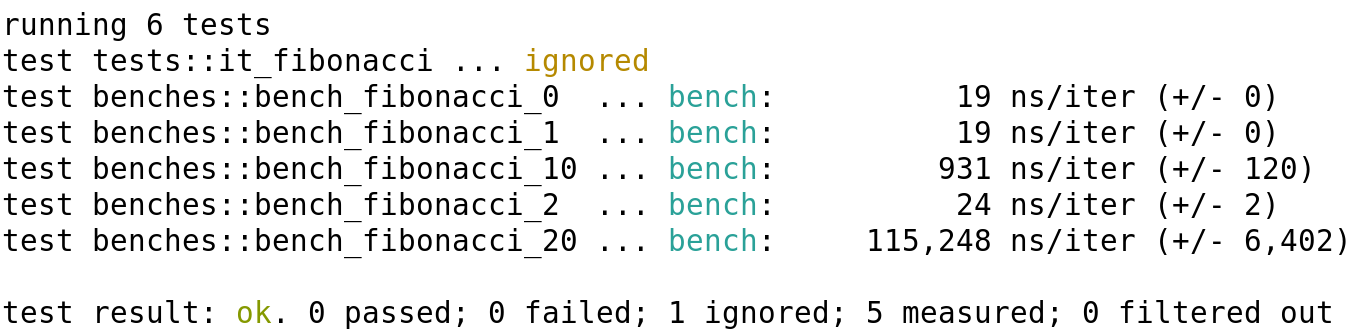
So, this is interesting. I selected those numbers (0, 1, 2, 10 and 20) to show something. For the 0 and the 1 numbers the result is straightforward, it will just return the given number. From the second number onward, it needs to perform some calculations. For example, for the number 2, it's just adding the previous two, so there is almost no overhead. For the number 10 though, it has to add the ninth and the eighth, and for each of them, the eighth and the seventh, and the seventh and the sixth respectively. You can see how this soon gets out of hand. Also, remember that we discard the previous results for each call.
So, as you can see in the results, it gets really exponential for each new number. Take into account that these results are on my laptop computer, and yours will certainly be different, but the proportions between one another should stay similar. Can we do better? Of course we can. This is usually one of the best learning experiences to see the differences between recursive and iterative approaches.
So, let's develop an iterative fibonacci() function:
pub fn fibonacci(n: u32) -> u32 {
if n == 0 || n == 1 {
n
} else {
let mut previous = 1;
let mut current = 1;
for _ in 2..n {
let new_current = previous + current;
previous = current;
current = new_current;
}
current
}
}
In this code, for the first two numbers, we simply return the proper one, as before. For the rest, we start with the sequence status for the number 2 (0, 1, 1), and then iterate up to number n (remember that the range is not inclusive on the right). This means that for the number 2, we already have the result, and for the rest, it will simply add the two numbers again and again until it gets the result.
In this algorithm, we always remember the previous two numbers, so we do not lose information from one call to the next. We also do not use too much stack (we only need three variables for the number 2 onward and we do not call any function). So it will require less allocation (if any), and it should be much faster.
Also, if we give it a much bigger number, it should scale linearly, since it will calculate each previous number only once, instead of many times. So, how much faster is it?
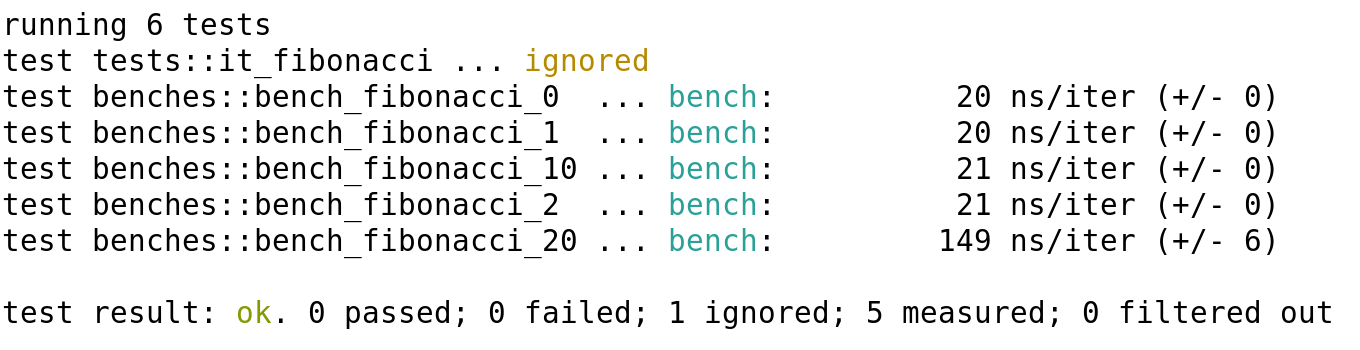
Wow! The results have really changed! We now see that, at least until the 10th number, the processing time is constant and, after that, it will only go up a little bit (it will multiply by less than 10 for calculating 10 more numbers). If you run cargo test, you will still see that the test passes successfully. Also, note that the results are much more predictable, and the deviation from test to test is much lower.
But, there is something odd in this case. As before, 0 and 1 run without doing any calculation, and that's why it takes so much less time. We could maybe understand that for the number 2, it will not do any calculations either (even though it will need to compare it to see if it has to run the loop). But, what happens with number 10?
In this case, it should have run the iteration seven times to calculate the final value, so it should definitely take more time than not running the iteration even once. Well, an interesting thing about the LLVM compiler (the compiler Rust uses behind the scenes) is that it is pretty good at optimizing iterative loops. This means that, even if it could not do the precalculation for the recursive loop, it can do it for the iterative loop. At least seven times.
How many iterations can LLVM calculate at compile time? Well, it depends on the loop, but I've seen it do more than 10. And, sometimes, it will unroll those loops so that if it knows it will be called 10 times, it will write the same code 10 times, one after the other, so that the compiler does not need to branch.
Does this defeat the purpose of the benchmark? Well, partly, since we no longer know how much difference it makes for the number 10, but for that, we have the number 20. Nevertheless, it tells us a great story: if you can create an iterative loop to avoid a recursive function, do it. You will not only create a faster algorithm, but the compiler will even know how to optimize it.