
There is one special reference-counted pointer that can be shared between threads that we already mentioned: std::sync::Arc. The main difference from the Rc is that the Arc counts the references with an atomic counter. This means that the kernel will make sure that all updates to the reference count will happen one by one, making it thread-safe. Let's see it with an example:
use std::thread;
use std::sync::Arc;
fn main() {
let my_vec = vec![10, 33, 54];
let pointer = Arc::new(my_vec);
let t_pointer = pointer.clone();
let handle = thread::Builder::new()
.name("my thread".to_owned())
.spawn(move || {
println!("Vector in second thread: {:?}", t_pointer);
})
.expect("could not create the thread");
println!("Vector in main thread: {:?}", pointer);
if handle.join().is_err() {
println!("Something bad happened :(");
}
}
As you can see, the vector is used both inside the second thread and in the main thread. You might be wondering what clone() means in the pointer. Are we cloning the vector? Well, that would be the easy solution, right? The real deal is that we are just getting a new reference to the vector. That's because the Clone trait is not a normal clone in the Arc. It will return a new Arc, yes, but it will also increase the reference count. And since both instances of Arc will have the same pointers to the reference counter and the vector, we will be effectively sharing the vector.
How is it possible to simply debug the vector pointer inside the Arc? This is an interesting trick. Arc<T> implements Deref<T>, which means that it will automatically dereference to the vector it's pointing to when calling the debug. Interestingly enough, there are two traits that allow that automatic dereference: Deref and DerefMut. As you might guess, the former gives you an immutable borrow of the contained value, while the latter gives you a mutable borrow.
Arc only implements Deref, not DerefMut, so we are not able to mutate what we have inside of it. But wait, we have cells that can mutate while being immutable, right? Well, there is an issue with them. The behavior we have seen from the Arc, of being able to be shared among threads, is only thanks to implementing the Sync trait, and it will only implement it if the inner value implements Sync and Send. Cells can be sent between threads, they implement Send, but they do not implement Sync. Vec, on the other hand, implements whatever the inside values implement, so in this case, it was both Send and Sync.
So, is that it? Can't we mutate anything inside an Arc? As you might have guessed, that's not the case. If what we want to share between threads is an integer or a Boolean, we can use any of the std::sync::atomic integers and Booleans, even though some are not stable yet. They implement Sync and they have interior mutability with their load() and store() methods. You will only need to specify the memory ordering of the operation. Let's see how that works:
use std::thread;
use std::sync::Arc;
use std::sync::atomic::{AtomicUsize, Ordering};
fn main() {
let my_val = AtomicUsize::new(0);
let pointer = Arc::new(my_val);
let t_pointer = pointer.clone();
let handle = thread::Builder::new()
.name("my thread".to_owned())
.spawn(move || {
for _ in 0..250_000 {
let cur_value = t_pointer.load(Ordering::Relaxed);
let sum = cur_value + 1;
t_pointer.store(sum, Ordering::Relaxed);
}
})
.expect("could not create the thread");
for _ in 0..250_000 {
let cur_value = pointer.load(Ordering::Relaxed);
let sum = cur_value + 1;
pointer.store(sum, Ordering::Relaxed);
}
if handle.join().is_err() {
println!("Something bad happened :(");
}
let a_int = Arc::try_unwrap(pointer).unwrap();
println!("Final number: {}", a_int.into_inner());
}
If you run this program multiple times, you will see that the final number will be different each time, and none of them will be 500,000 (it could happen, but it's almost impossible). What we have is similar to a data race:
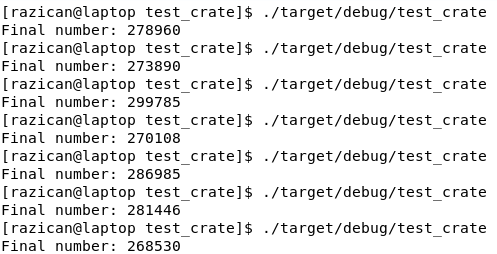
But wait, can't Rust prevent all data races? Well, this is not exactly a data race. When we save the integer, we don't check whether it has changed, so we are overriding whatever was written there. We are not using the advantages Rust gives us. It will make sure that the state of the variable is consistent, but it won't prevent logic errors.
The issue is that when we store it back, that value has already changed. To avoid it, atomics have the great fetch_add() function and its friends fetch_sub(), fetch_and(), fetch_or(), and fetch_xor(). They will perform the complete operation atomically. They also have the great compare_and_swap() and compare_exchange() functions, which can be used to create locks. Let's see how that would work:
use std::thread;
use std::sync::Arc;
use std::sync::atomic::{AtomicUsize, Ordering};
fn main() {
let my_val = AtomicUsize::new(0);
let pointer = Arc::new(my_val);
let t_pointer = pointer.clone();
let handle = thread::Builder::new()
.name("my thread".to_owned())
.spawn(move || {
for _ in 0..250_000 {
t_pointer.fetch_add(1, Ordering::Relaxed);
}
})
.expect("could not create the thread");
for _ in 0..250_000 {
pointer.fetch_add(1, Ordering::Relaxed);
}
if handle.join().is_err() {
println!("Something bad happened :(");
}
let a_int = Arc::try_unwrap(pointer).unwrap();
println!("Final number: {}", a_int.into_inner());
}
As you can see now, the result is 500,000 every time you run it. If you want to perform more complex operations, you will need a lock. You can do that with an AtomicBool, for example, where you can wait for it to be false, then swap it with true and then perform operations. You would need to make sure that all your threads only change values when the lock is set to true by them, by using some memory ordering. Let's see an example:
use std::thread;
use std::sync::Arc;
use std::sync::atomic::{AtomicBool, AtomicUsize, Ordering};
fn main() {
let my_val = AtomicUsize::new(0);
let pointer = Arc::new(my_val);
let lock = Arc::new(AtomicBool::new(false));
let t_pointer = pointer.clone();
let t_lock = lock.clone();
let handle = thread::Builder::new()
.name("my thread".to_owned())
.spawn(move || {
for _ in 0..250_000 {
while t_lock.compare_and_swap(
false, true, Ordering::Relaxed) {}
let cur_value = t_pointer.load(Ordering::Relaxed);
let sum = cur_value + 1;
t_pointer.store(sum, Ordering::Relaxed);
t_lock.store(false, Ordering::Relaxed);
}
})
.expect("could not create the thread");
for _ in 0..250_000 {
while lock.compare_and_swap(
false, true, Ordering::Relaxed) {}
let cur_value = pointer.load(Ordering::Relaxed);
let sum = cur_value + 1;
pointer.store(sum, Ordering::Relaxed);
lock.store(false, Ordering::Relaxed);
}
if handle.join().is_err() {
println!("Something bad happened :(");
}
let a_int = Arc::try_unwrap(pointer).unwrap();
println!("Final number: {}", a_int.into_inner());
}
If you run it, you will see that it works perfectly. But this only works because in both threads we only change the value between the lock acquisition and the lock release. In fact, this is so safe that we could avoid using an atomic integer altogether, even though Rust won't allow us to do so in safe code.
Now that we have seen how to mutate integers shared between threads, you might be wondering if something similar can be done with other types of bindings. As you can probably guess, it can. You will need to use std::sync::Mutex, and it will be much more expensive in performance terms than using atomic operations, so use them with caution. Let's see how they work:
use std::thread;
use std::sync::{Arc, Mutex};
fn main() {
let my_vec = Arc::new(Mutex::new(Vec::new()));
let t_vec = my_vec.clone();
let handle = thread::Builder::new()
.name("my thread".to_owned())
.spawn(move || {
for i in 0..50 {
t_vec.lock().unwrap().push(i);
}
})
.expect("could not create the thread");
for i in 0..50 {
my_vec.lock().unwrap().push(i);
}
if handle.join().is_err() {
println!("Something bad happened :(");
}
let vec_mutex = Arc::try_unwrap(my_vec).unwrap();
let f_vec = vec_mutex.into_inner().unwrap();
println!("Final vector: {:?}", f_vec);
}
It will output something similar to this:

If you analyze the output closely, you will see that it will first add all numbers from 0 to 49 and then do the same again. If both threads were running in parallel, shouldn't all numbers be randomly distributed? Maybe two 1s first, then two 2s, and so on?
The main issue with sharing information between threads is that when the Mutex locks, it requires synchronization from both threads. This is perfectly fine and safe, but it takes a lot of time to switch from one thread to another to write in the vector. This is why the kernel scheduler allows for one of the threads to work for some time before locking the Mutex. If it was locking and unlocking the Mutex for each iteration, it would take ages to finish.
This means that if your loops were more than 50 iterations, maybe something like 1 million per loop, you would see that after some time, one of the threads would stop to give priority to the second one. In small numbers of iterations, though, you will see that one runs after the other.
There is an extra issue we have to take into account when working with Mutexes: thread panicking. If your thread panics while the Mutex is locked, the lock() function in another thread will return a Result::Err(_), so if we call unwrap() every time we lock() our Mutex, we can get into big trouble, since all threads would panic. This is called Mutex poisoning and there is a way to avoid it.
When a Mutex is poisoned because a thread panicked while having it locked, the error result of calling the lock() method will return the poisoning error. We can recover from it by calling the into_inner() method. Let's see an example of how this would work:
use std::thread;
use std::sync::{Arc, Mutex};
use std::time::Duration;
fn main() {
let my_vec = Arc::new(Mutex::new(Vec::new()));
let t_vec = my_vec.clone();
let handle = thread::Builder::new()
.name("my thread".to_owned())
.spawn(move || {
for i in 0..10 {
let mut vec = t_vec.lock().unwrap();
vec.push(i);
panic!("Panicking the secondary thread");
}
})
.expect("could not create the thread");
thread::sleep(Duration::from_secs(1));
for i in 0..10 {
let mut vec = match my_vec.lock() {
Ok(g) => g,
Err(e) => {
println!("The secondary thread panicked, recovering…");
e.into_inner()
}
};
vec.push(i);
}
if handle.join().is_err() {
println!("Something bad happened :(");
}
let vec_mutex = Arc::try_unwrap(my_vec).unwrap();
let f_vec = match vec_mutex.into_inner() {
Ok(g) => g,
Err(e) => {
println!("The secondary thread panicked, recovering…");
e.into_inner()
}
};
println!("Final vector: {:?}", f_vec);
}
As you can see in the code, the second thread will panic after inserting the first number in the vector. I added a small 1-second sleep in the main thread to make sure that the secondary thread would execute before the main one. If you run it, you will get something similar to this:

As you can see, once a Mutex has been poisoned, it will stay poisoned for all of its life. You should therefore try to avoid any behavior that could lead to a panic once you get the lock in a Mutex. In any case, you can still use it and as you can see, the final vector will contain values from both threads; only the 0 from the secondary thread, until the panic, and then the rest from the main thread. Make sure not to unwrap() a Mutex in a critical application, as it will make all your threads panic if you do it in all your threads after the first panic.