
Using an Index for Efficient WHERE Processing
Overview
When processing a WHERE expression, SAS determines which
of the following access methods is likely to be most efficient:
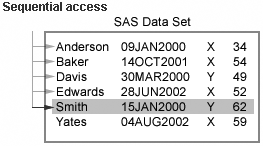 |
SAS examines all observations
sequentially in their physical order.
|
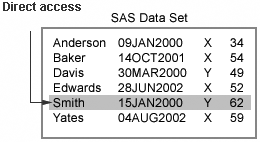 |
SAS uses an index to
access specific observations directly. Using an index to process a
WHERE expression is referred to as optimizing the WHERE expression.
|
Using an index to process
a WHERE expression improves performance in some situations but not
in others. For example, it is more efficient to use an index to select
a small subset than a large subset. In addition, an index conserves
some resources at the expense of others.
After
SAS decides whether to create an index, you also play a role in determining
which access method SAS can use. When your program contains a WHERE
expression, you should review your program to see if you agree that
direct access is likely to be more efficient. If it is, you can make
sure that an index is available by creating a new index or by maintaining
an existing index.
To help you make a more
effective decision about whether to create an index, this topic and
the next few topics provide you with a closer look at the following:
-
steps that SAS performs for sequential access and direct access
-
benefits and costs of index usage
-
steps that SAS performs to determine which access method is most efficient
-
factors affecting resource usage for indexed access
-
guidelines for deciding whether to create, use, and maintain an index
Note: You should already know how
to create and maintain indexes by using the INDEX= data set option
in the DATA statement, the DATASETS procedure, and the SQL procedure.
To review these SAS elements, see
Creating and Managing Indexes Using PROC SQL and
Creating Indexes.
Note: SAS can also use an index
to process a BY statement. BY processing enables you to process observations
in a specific order according to the values of one or more variables
that are specified in a BY statement. Indexing a data file enables
you to use a BY statement without sorting the data file. When you
specify a BY statement, SAS checks the value of the Sorted indicator.
If the Sorted indicator is set to NO, then SAS looks for an appropriate
index. If an appropriate index exists, the software automatically
retrieves the observations from the data file in indexed order. Using
an index to process a BY statement might not always be more efficient
than simply sorting the data file. Therefore, using an index for a
BY statement is generally for convenience, not for performance.
Example
Suppose you want to
create a new data set, Company.D02jul2000, that contains a subset
of observations from the data set Company.Dates. The following DATA
step uses a WHERE statement to select all observations in which Date_ID
is
02JUL2000: data company.d02jul2000;
set company.dates;
where date_id='02JUL2000'd;
run;The data set Company.Dates
does not contain an index that is defined on the variable Date_ID,
so SAS must use sequential access to process the WHERE statement.
Note: If the data set company.dates
has been sorted by date_id, SAS searches the data sequentially until
the WHERE criterion (
date_id='02JUL2000'd)
has been satisfied.
Example
Suppose you
have defined an index on the variable Date_ID in the Company.Dates
data set. This time, when you submit the following DATA step, SAS
uses the index to process the WHERE statement:
data company.d02jul2000;
set company.dates;
where date_id='02JUL2000'd;
run;The
process of retrieving data via an index (direct access) is more complicated
than sequential access, so direct access requires more CPU time per
observation retrieved than sequential access. However, for a small
subset, using an index can decrease the number of pages that SAS loads
into input buffers, which reduces the number of I/O operations.
Note: When the values in the data
set are sorted in the order in which they occur in the index, the
qualified observations are adjacent to each other. In this situation,
SAS loads fewer pages into the input buffer than if the data is randomly
distributed throughout the data set. Therefore, fewer I/O operations
are required when the data set is sorted.
Benefits and Costs of Using an Index
As the
preceding examples show, both benefits and costs are associated with
using an index. Weighing these benefits and costs is an important
part of deciding whether using an index is efficient.
The main benefits of
using an index include the following:
-
provides fast access to a small subset of observations
-
returns values in sorted order
-
can enforce uniqueness
The main costs of using
an index include the following:
-
requires extra CPU cycles and I/O operations for creating and maintaining an index
-
requires increased CPU time and I/O activity for reading the data
-
requires extra disk space for storing the index file
-
requires extra memory for loading index pages and extra code for using the index
Note: SAS
requires additional buffers when an index file is used. When a data
file is opened, SAS opens the index file, but not the indexes. Buffers
are not required unless SAS uses an index, but SAS allocates the buffers
to prepare for using the index. The number of levels of an index determines
the number of buffers that are allocated. The maximum number of buffers
is three for data files that are open for input. The maximum number
is four for data that is open for update. These buffers can be used
for other processing if they are not used for indexes.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.