
The purpose of this chapter is to take the basic building blocks, usage scenarios, features, and benefits of SSI that we introduced in part 1 and place them into an overarching picture of SSI architecture. As we will keep repeating, SSI is young, and many facets are still evolving. Still, the basic layering has emerged, along with several of the key underpinning standards, so the main questions are about how these standards will be implemented and how much interoperability will depend on specific design choices. In this chapter, Daniel Hardman, former chief architect and CISO at Evernym, now principal ecosystem engineer at SICPA—and a contributor to most of the core standards and protocols discussed here—walks you through four layers of SSI architecture, the key components and technologies at each layer, and the critical design decisions facing architects and implementers throughout the stack. This chapter sets the stage for the rest of the chapters in part 2 that dive deeper into specific SSI technologies.
In chapter 2, we discussed the basic building blocks of self-sovereign identity (SSI). Those building blocks represent important commonality—all approaches to the problem agree on them. However, like automobile design in the early 1900s, the young market is producing much innovation and divergence in the details. Some are inventing with two wheels, some with four or three. Some favor steam, while others favor internal combustion engines powered by gasoline or diesel.
In this chapter, we identify important decision points in decentralized digital identity architectures, notable choices for each, and the benefits and challenges they entail.
5.1 The SSI stack
Some types of divergence are irrelevant; others are fundamental. Separating the two is an important topic among identity architects because it affects interoperability. The first attempt to describe all the key choices in SSI stacks was made at the Internet Identity Workshop (IIW) in October 2018 [1]. Conference participants listed 11 layers of technology that are likely to appear in SSI solutions and described their dependencies.
However, subsequent experience has shown this was more granular than necessary to describe the fundamental architectural dependencies in SSI. SSI architects from various backgrounds collaborated under the umbrella of the Hyperledger Aries project in 2019 to produce the four-layer paradigm shown in figure 5.1 that we use throughout this chapter. The bottom layers, while important, are essentially invisible plumbing; the top layers embody concepts visible to ordinary users. They tie directly into business processes, regulatory policies, and legal jurisdictions.

Figure 5.1 The SSI stack as a four-layer model, where the bottom two layers are primarily about achieving technical trust and the top two layers are about achieving human trust
Each of these layers embodies key architectural decisions, and each has significant consequences for interoperability. In the balance of this chapter, we discuss the details of each layer, building from the bottom up.
5.2 Layer 1: Identifiers and public keys
Layer 1 is the bottom of the stack, where identifiers and public keys are defined and managed. These are often called trust roots, and like real trees, the stronger the roots, the stronger the tree. This layer needs to guarantee that all stakeholders agree to the same truth about what an identifier references and how control of this identifier may be proved using cryptographic keys. It must also allow every party in the ecosystem to read and write data without reliance on or interference from central authorities—a property widely referred to in the blockchain community as censorship resistance.
There is broad consensus among the SSI community that the best way to provide these features is to expose a verifiable data registry (also called a DID registry or DID network because it a decentralized source of truth for decentralized identifiers (DIDs, introduced in chapter 2 and described in detail in chapter 8). Each DID registry uses a DID method that defines a specific protocol for interacting with that particular type of DID registry. While this standardizes the overall abstraction needed for Layer 1, this approach still allows much to vary in the particulars.
-
What’s the best way to implement a decentralized system? Should it be permissioned or permissionless? How should it be governed? How well does it scale?
-
How, exactly, should DIDs be registered, looked up, and verified on this decentralized system to ensure they are secure while still protecting privacy?
-
What other data needs to be stored on the decentralized system to support the higher layers of the SSI stack?
As chapter 8 discusses, over 80 DID methods are defined in the DID method registry maintained by the W3C DID Working Group (https://www.w3.org/TR/did-spec-regis tries)—and more are likely in the future. That reflects the great diversity of DID methods developed so far. In this section, we discuss the major architectural categories into which they fall.
5.2.1 Blockchains as DID registries
As noted at the beginning of this book, SSI was born because blockchain technology introduced an exciting new option for implementing a decentralized public key infrastructure (DPKI), explained in more detail in chapter 6. This, in turn, could unlock the power of verifiable credentials (VCs), explained in chapter 7. So naturally, blockchains in their many forms have been the first option for Layer 1. Indeed, as of the writing of this book, more than 90% of the DID methods in the W3C DID specification registry are based on blockchains or distributed ledger technology (DLT).
Besides the well-known public blockchains that support cryptocurrencies (for example, Bitcoin and Ethereum), this family of technologies includes permissioned ledgers (such as Hyperledger Indy), distributed directed acyclic graphs (e.g., IOTA), and distributed hashtables (e.g., IPFS). Blockchain has become a general umbrella term for the entire family, although experts argue about exactly how to apply these definitions [2]. In principle, it is expected that, following the architecture choices we outline in this chapter, all of these technologies should be able to achieve the SSI design goals of strong security, censorship resistance, and self-service without central administration.
However, these blockchains also differ in important ways, including
-
How much, if at all, they integrate with cryptocurrencies and payment workflows as an identity concern
-
Whether identity operations are a first-class feature of the blockchain or a generic feature (for example, smart contracts) that intersects with identity only in certain cases
-
How they address regulatory compliance and censorship resistance
In summary, it is best to look at blockchain as one option for meeting the requirements of Layer 1, but not the only option—and not necessarily a good option, depending on the design and implementation of the blockchain and the design and implementation of a specific DID method for using that blockchain. For example:
-
A blockchain that’s prohibitively expensive to use may put SSI out of reach for many of the world’s disadvantaged.
-
A blockchain that is permissioned may not adequately address concerns about censorship resistance.
-
A blockchain whose codebase is tightly controlled by a small group may not be considered trustworthy enough for broad adoption.
Since this category is so broad, let’s next look specifically at two major subdivisions within it: general-purpose public blockchains and special-purpose SSI blockchains.
5.2.2 Adapting general-purpose public blockchains for SSI
Although blockchain technology is less than a decade old, it already has two “granddaddies”: Bitcoin and Ethereum. Collectively, their market capitalization at the start of 2021—measured in terms of the total value of their respective cryptocurrencies—is more than four times that of all other cryptocurrencies combined [3]. So they are obviously strong candidates for the stability and broad developer support needed to engender trust in public infrastructure. This explains why some of the first SSI implementations—by Learning Machine (Bitcoin) and uPort (Ethereum)—targeted these blockchains. It also explains why over a dozen of the DID methods registered in the W3C DID Specification Registries are designed to work with either Bitcoin or Ethereum [4].
The common theme among these methods is that they use the cryptographic address of a transaction on the ledger—a payment address—as the DID. Payment addresses are already opaque strings, globally unique, and governed by cryptographic keys. Although it predates the W3C standards for verifiable credentials and DIDs, the Blockcerts (https://www.blockcerts.org) standard for educational credentials, championed by Learning Machine, is built on this approach, and credential issuance and verification (Layer 3) work nicely on top of it.
However, payment addresses don’t have rich metadata or provide an obvious way to contact the address holder. This limits interactions to a “don’t call us, we’ll call you” model. Payment addresses are also global correlators, which raises privacy concerns. Law enforcement identified the operators of Silk Road (an online black market and the first modern darknet market, best known as a platform for selling illegal drugs) because payment addresses were traceable. While that case resulted in shutting down a market in illegal goods, the same techniques could be used to harass, find dissidents, or surveil legitimate actors. Some interesting technical solutions have been proposed to mitigate this effect with payment addresses, but implementations are still pending, and more technical and legal measures may be required.
Some blockchains are also designed so that payment addresses are retired as funds move or keys rotate. Without workarounds, this can complicate the stability of reference required by a good user experience (UX) for SSI.
5.2.3 Special-purpose blockchains designed for SSI
By 2016, developers were creating the first blockchains designed explicitly to support SSI. The first came from Evernym, which developed an open source codebase for a public permissioned ledger, where all the nodes would be operated by trusted institutions. Evernym helped organize the Sovrin Foundation to become the non-profit governance authority for the blockchain and then contributed the open source code to the Foundation (https://sovrin.org).
The Sovrin Foundation subsequently contributed the open source code to the Hyperledger project hosted by the Linux Foundation, where it became Hyperledger Indy (https://wiki.hyperledger.org/display/indy). It joined other Hyperledger business-oriented blockchain operating systems, including Fabric, Sawtooth, and Iroha. As the only Hyperledger project designed expressly for SSI, the Hyperledger Indy codebase is now being run by other public permissioned SSI networks, including those implemented by Kiva, the non-profit operator of the world’s largest microlending platform [5].
The next entrant in purpose-built SSI blockchains was Veres One (https://veres.one), created by Digital Bazaar. It is a public permissionless blockchain optimized to store DIDs and DID documents in JSON-LD, a rich semantic graph format based on the Resource Description Framework (RDF). The Veres One blockchain is being used for multiple SSI pilots involving verifiable credentials for supply chains and provenance [6].
Blockchains that are purpose-built for SSI, such as Veres One and Hyperledger Indy, have transaction and record types that make DID management easy. However, there is more to Layer 1 than just DIDs. In particular, the Hyperledger Indy codebase supports the zero-knowledge proof (ZKP) credential format supported by the W3C Verifiable Credential Data Model 1.0 standard and the Hyperledger Aries open source codebase (discussed in the sections on Layers 2 and 3). ZKP credentials require several other cryptographic primitives at Layer 1 [7]:
-
Schemas—This is how issuers define the claims (attributes) that they wish to include on a verifiable credential. By putting schema definitions on a public blockchain, they are available for all verifiers to examine to determine semantic interoperability (a critical point for data sharing across silos).
-
Credential definitions—The difference between a credential definition and a schema is that the credential definition is published on the ledger to declare the specific claims, public key, and other metadata that will be used by a specific issuer for a specific version of a verifiable credential.
-
Revocation registries—This is a special data structure called a cryptographic accumulator used for privacy-respecting revocation of verifiable credentials. See chapter 6 for more details.
-
Agent authorization registries—This is a different type of cryptographic accumulator used to add additional security to SSI infrastructure. It can authorize and de-authorize specific digital wallets on specific devices—for example, if they are lost, stolen, or hacked.
note Semantic interoperability is the ability of computer systems to exchange data with unambiguous, shared meaning. Semantic interoperability is concerned not just with the packaging of data (syntax), but also with the simultaneous transmission of the meaning with the data (semantics). This is accomplished by adding data about the data (metadata), linking each data element to a controlled, shared vocabulary.
Equally important is what does not go on the ledger: any private data. Although early experiments in blockchain-based identity had the notion of putting an individual’s credentials and other personal data directly on the blockchain as encrypted data objects, subsequent research and analysis have concluded that this is a bad idea. First, all encryption has a limited lifespan, so writing private data to an immutable public ledger has the risk that it may eventually be cracked even if the cryptography used for the ledger itself is upgraded. Second, even encrypted data has privacy implications just by watching who writes and reads it. Third, it presents massive issues with the EU General Data Protection Regulation (GDPR) and other data protection regulations worldwide that provide a “right of erasure” to data subjects (see the Sovrin Foundation’s white paper on GDPR and SSI for a detailed analysis: https://sovrin.org/data-protection).
5.2.4 Conventional databases as DID registries
Although it may seem antithetical to a decentralized approach, the user databases of internet giants have shown that modern web-ready database technologies can achieve the robustness, global scale, and geographical dispersion needed by a DID registry. Some have even proposed that a massive social network database like Facebook’s, or a comprehensive government identity database like India’s Aadhaar, could be the basis for rapid adoption of DIDs—citing broad coverage, proven ease-of-use, and existing adoption as a rationale.
However, such databases are neither self-service nor censorship-resistant. Trust in these databases is rooted in centralized administrators whose interests may not align with those of the individuals they identify. Privacy is questionable when a third party mediates every login or interaction. This is true whether the organization that runs them is a government, a private enterprise, or even a charity. Such centralization undermines one of the most important design goals of SSI (and also of the internet): eliminating single points of control and failure. For this reason, most practitioners of SSI discount traditional databases as a viable implementation path for Layer 1.
5.2.5 Peer-to-peer protocols as DID registries
As DID methods have matured, SSI architects have realized that there is an entire category of DIDs that do not need to be registered in a backend blockchain or database. Rather, these DIDs and DID documents can be generated and exchanged directly between the peers that need them to identify and authenticate each other.
The “DID registry” in this case is the digital wallet of each of the peers—each is the “root of trust” for the other—along with trust in the protocol used to exchange these peer DIDs. Not only does this approach have massively better scalability and performance than blockchain- or database-based DID methods, but it also means the DIDs, public keys, and service endpoints are completely private—they never need to be shared with any external party, let alone on a public blockchain.
The primary peer-to-peer DID method, called did:peer:, was developed under the auspices of the Hyperledger Aries project and then moved to the sponsorship of the Decentralized Identity Foundation. It is defined in the Peer DID Method Specification (https://identity.foundation/peer-did-method-spec). Peer DIDs are generated directly in the digital wallets of the two peers involved and exchanged using their digital agents, so in reality, Peer DID is a Layer 1 solution that’s implemented entirely at Layer 2 of the SSI stack. However, the Peer DID method is developing fallback solutions for situations where one or both of the peers (such as two people represented by their mobile phones) move to new service endpoints (such as new mobile phone carriers) and lose touch with one another. Some of these require clever triangulation against a public blockchain at Layer 1.
Triple-Signed Receipts is an example of another protocol that also solves this problem without any blockchain. It was originally described as an evolution to standard double-entry accounting but can also be used to solve double-spend problems in identity (for example, claiming to one party that a key is authorized while claiming to another party that a key is not). Each party in the protocol signs a transaction description that includes not just the inputs but also the outputs (resulting balance). An external auditor signs as well. Once all three signatures have accumulated, there is no question about the truth of a transaction—and because the signed data includes the resulting balance in addition to the inputs, no previous transactions need be consulted to know the effect of the transaction.
Key Event Receipt Infrastructure (KERI) is a complete architecture for portable DIDs developed around the concept of self-certifying identifiers at the heart of peer DIDs. KERI goes further to define a corresponding decentralized key management architecture. For details, see chapter 10.
Given the rich possibilities, we anticipate that additional peer-based protocol solutions to Layer 1 functionality will be developed over the coming years, all of which will add to the overall strength of this foundational layer of the SSI stack.
5.3 Layer 2: Secure communication and interfaces
If Layer 1 is about establishing decentralized trust roots—either publicly verifiable or peer-to-peer—then Layer 2 is about establishing trusted communications between the peers relying on those trust roots. This is the layer where the digital agents, wallets, and encrypted data stores we introduced in chapter 2 live and where their secure DID-to-DID connections are formed.
Even though actors of all kinds—people, organizations, and things—are represented by these digital agents and wallets at Layer 2, the trust established between those actors at this layer is still only cryptographic trust—in other words, trust that
These are all conditions that are necessary but not sufficient to establish human trust because they don’t yet establish anything about the person, organization, or thing identified by the DID. For example, a DID-to-DID connection doesn’t care whether a remote party is ethical or honest or qualified—only whether talking back and forth can be done in a way that’s tamper-proof and confidential. For that, we have to move up to Layers 3 and 4.
The architectural issues at this layer fall into two main categories: protocol design and interface design. This section discusses the two main protocol design options and then the three main interface design options.
5.3.1 Protocol design options
Of course, protocols are the heart of the internet itself—the TCP/IP protocol stack is what made the internet possible, and the HTTP and HTTPS protocols are what made the web possible. With SSI, protocol design is critical because it defines the rules by which agents, wallets, and hubs communicate.
Two main protocol design architectures are being pursued in the SSI community:
-
Web-based protocol design follows the same basic HTTP protocol patterns detailed in the W3C’s classic “Architecture of the World Wide Web” document (widely considered the “bible” of web architecture; https://www.w3.org/TR/webarch). This approach has a special reliance on the Transport Layer Security (TLS) standard used in the HTTPS protocol.
-
Message-based protocol design uses the DIDComm protocol for peer-to-peer communications between agents—an architectural approach more similar to email.
5.3.2 Web-based protocol design using TLS
The first approach is rooted in a simple observation: we already have a ubiquitous, robust mechanism for secure web communication in the form of Transport Layer Security (TLS). Why reinvent the wheel?
Proponents of this view are building systems where parties talk to one another by making RESTful web service calls (representational state transfer [REST] is a software architectural style that defines a set of constraints to be used for creating web services). The tooling and libraries for such mechanisms are well understood, and millions of developers are comfortable with them. Progress is relatively easy.
-
Although TLS can be applied to other protocols, its primary adoption success has been with HTTP. This means TLS is only an immediate answer when at least one of the parties runs a web server.
-
It requires a relatively direct request-response interaction, with both parties being online at the same time.
-
The server is passive; it reacts when called and can trigger webhooks or callback URLs—but it can’t reach out to the other party on its own unless the other party is also running a web server.
-
The security model for TLS is asymmetric: servers use X.509 digital certificates (introduced in chapter 2 and discussed in more detail in chapter 8); clients use passwords, API keys, or OAuth tokens. This tends to perpetuate a power imbalance, where organizations having high-reputation server certificates dictate the behavior of low-reputation clients. It is antithetical to the peer-to-peer philosophy of decentralization in SSI. It also makes the control of DIDs and their cryptographic keys a secondary (or even redundant) concern.
-
Its privacy and security guarantees are imperfect. SSL visibility appliances are well-known hacking tools that insert a man-in-the-middle for each TLS session that runs through an institutional LAN. X.509 certificate authorities are operated by humans and can be gamed. And TLS has no story for securing communications data at rest or outside the secured channel.
For all these reasons, although there is a great deal of SSI code development following the conventional web architecture path of using HTTPS, at least as much, if not more, development effort is going into a more inclusive approach.
5.3.3 Message-based protocol design using DIDComm
This second approach is called DID communication (DIDComm for short). It conceives of Layer 2 as message-oriented, transport-agnostic, and rooted in interactions among peers. In this paradigm, communications between agents are similar in concept to email: it is inherently asynchronous, it may involve broadcasting to multiple parties at the same time, delivery is best-effort, and replies may arrive over different channels or not at all.
note From an architectural perspective, DIDComm has much in common with proprietary protocols used by many secure messaging apps today. It even supports analogous grouping constructs. However, it also differs in important ways. Its DID foundation lets it work peer-to-peer rather than needing all traffic to route through centralized servers. It focuses on the delivery of machine-readable rather than human-readable messages; this makes its problem domain far broader than just secure chat. Software uses DIDComm messages to facilitate interactions of every conceivable kind between institutions and IoT devices as well as people. This means some users of DIDComm may not perceive the interactions to resemble conventional secure messaging apps.
However, DIDComm differs from SMTP email in that
-
Recipients are identified by a DID rather than an email address.
-
All communication is secured (either encrypted, signed, or both) by the keys associated with DIDs. This is true even of data at rest.
-
Messages may be delivered over any transport: HTTP, Bluetooth, ZMQ, file system/sneakernet, AMQP, mobile push notifications, QR codes, sockets, FTP, SMTP, snail mail, etc.
-
Security and privacy guarantees are the same regardless of transport. A single route may use more than one of these transports.
-
Because of the transport independence, security is also portable. That is, two parties may interact partly over email using proprietary tools from vendors A and B, partly over social-media-based chat controlled by vendor C, and partly over SMS that uses multiple mobile providers. However, only two sets of keys (the keys for each party’s DID) are needed to secure all of these contexts, and the interaction history is tied to the DIDs, not the channels. Vendors that own channels cannot force lock-in by owning the security.
-
Routing is adapted for privacy; it is designed so no intermediary knows a message’s ultimate origin or its final destination—only the next hop. This allows for (but does not require) the use of mixed networks and similar privacy tools.
DIDComm can easily use HTTP or HTTPS in a request-response paradigm, so this approach to protocol design is a superset of the web-based approach. However, DIDComm provides flexibility for other situations, including those where a party is connected only occasionally or channels contain many untrusted intermediaries.
DIDComm’s most important technical weakness is its novelty. Although tools used by the world’s web developers (CURL, Wireshark, Chrome’s Developer Tools, Swagger, etc.) are relevant and somewhat helpful with DIDComm, tools that understand DIDComm natively are immature. This makes DIDComm a more expensive choice in the early days of the SSI ecosystem.
Nevertheless, DIDComm is gaining momentum rapidly. Although it was originally incubated within the Hyperledger developer community (Indy and Aries; https://github.com/hyperledger/aries-rfcs/tree/master/concepts/0005-didcomm), in Dece-mber 2019, the growing interest beyond Hyperledger led to the formation of the DIDComm Working Group at the Decentralized Identity Foundation (DIF) [8]. Already there are roughly a dozen implementations of various parts of DIDComm for different programming languages (https://github.com/hyperledger/aries).
5.3.4 Interface design options
From an architectural standpoint, interface design is about how SSI infrastructure becomes available for programmatic use by developers who want to solve real-world problems for individuals and institutions. The approaches here depend to some degree on protocol design. For web-based client/server protocols, Swagger-style API interfaces are a natural complement; with DIDComm, peer-to-peer protocols are a more natural model. However, both underlying protocols can be paired with either style of interface, so the question is somewhat orthogonal.
SSI solutions tend to emphasize one of these three answers to the interface question:
-
API-oriented interface design favors using decentralized web or mobile wallet decentralized apps (Dapps) with APIs.
-
Data-oriented interface design uses encrypted data stores to discover, share, and manage access to identity data.
-
Message-oriented interface design uses digital agents (edge-based or cloud-based) that route the messages and interactions they share.
However, these answers are not mutually exclusive; all approaches overlap. What differs is the focus [9].
5.3.5 API-oriented interface design using wallet Dapps
The API-based approach stems from the philosophy that SSI features are best exposed through decentralized web and mobile apps (Dapps) and associated Web 2.0 or Web 3.0 APIs on complementary server-side components. Here, the prototypical SSI Dapp for an individual is a mobile wallet that holds all cryptographic material and provides a simple UX for requesting and providing credential-based proof about identity. This wallet also interfaces directly or indirectly with a blockchain to verify data.
The Blockcerts app and the uPort app are examples of this model. These apps interface with Learning Machine’s server-side Issuing System or with uPort’s Ethereum-based backend, respectively. Programmers are encouraged to write their own apps or automation to call these backend APIs and use the identity ecosystem. Because the approach is conceptually straightforward, the learning curve is not steep, aiding adoption.
This paradigm works well for SSI use cases where individuals want to prove things to institutions because individuals carry mobile devices and institutions operate servers with APIs. However, when individuals are the receivers rather than the givers of proof, and when identity owners are IoT devices or institutions instead of people, there is some impedance with the overall model. How can an IoT device hold a wallet and control a Dapp, for example? Perhaps we will see clever extensions of this model in the future.
5.3.6 Data-oriented interface design using identity hubs (encrypted data vaults)
Digital Bazaar, Microsoft, and various other players in the Decentralized Identity Foundation (DIF) and W3C CCG communities have championed a data-centric view of identity. In this paradigm, the primary task of actors using SSI infrastructure is to discover, share, and manage access to identity data.
In this view, management’s focus is an identity hub (or, in W3C parlance, an encrypted data vault)—a cloud-based point of presence through which a web API accesses identity data. Hubs are services configured and controlled by an identity controller. In the case of individuals, they are usually imagined to be sold as a SaaS subscription, providing a sort of personal API. Institutions or devices can also use hubs. Importantly, hubs are not necessarily conceived of as directly representing a particular identity controller; they can be independent services that manage data on behalf of any number of identity controllers, as directed by each individual controller. Figure 5.2 illustrates the role an identity hub plays in the SSI ecosystem envisioned by the DIF.
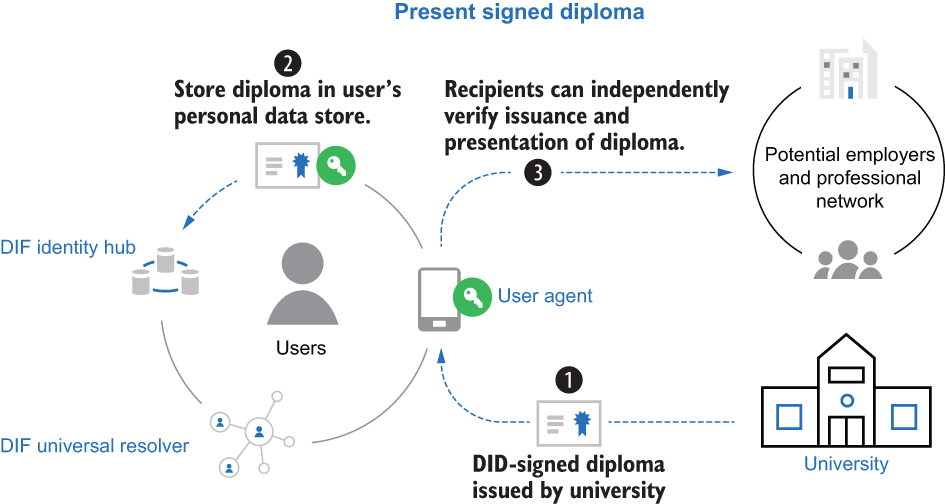
Figure 5.2 An identity hub shown as part of the SSI ecosystem envisioned by DIF
Although hubs, in theory, can execute code on a schedule or trigger, most design documents focus on the hub as a passive responder to external clients. Most examples assume they are always online to provide a stable portal for interaction and behave like a specialized web server. Thus, they were originally imagined as HTTP-oriented and RESTful, with service endpoints defined in a DID document (https://github.com/decentralized-identity/identity-hub/blob/master/explainer.md). However, as DIDComm has evolved, some hub APIs have been recast as message-based and capable of using Bluetooth, NFC, message queues, or other transport mechanisms besides HTTP. Still, the architectural center of hub design remains fundamentally rooted in data sharing.
Security for hubs is provided by encryption of messages, using keys declared in a DID document. Early discussions of encryption approaches centered on the JSON Web Token (JWT) format, part of the JavaScript Object Signing and Encryption (JOSE) stack, but the particulars are still in development. As of early 2021, the DIF’s Secure Data Storage Working Group is busy unifying the various efforts to specify interoperable identity hubs and encrypted data vaults (https://identity.foundation/working-groups/secure-data-storage.html).
The data hub model is attractive for companies that want to sell hosting services to consumers and enterprises. It is also convenient for institutions that want to contract with consumers to generate value from their data. On the plus side, programming against hubs is likely to be very easy for developers. On the minus side, it is not clear whether consumers want to manage their identity as a service in the cloud. There are also privacy, security, and regulatory issues with hosting providers that need to be explored. This is one area where market validation is particularly needed.
5.3.7 Message-oriented interface design using agents
The Hyperledger Aries project and the Sovrin community have championed an SSI interface paradigm that focuses most heavily on active agents and the messages and interactions they share. Agents are direct representatives of identity, rather than being indirect or external representatives like hubs. When you interact with an agent, you interact as directly as possible with the entity whose identity the agent represents.
As introduced in chapter 2 and explored in depth in chapter 9, an SSI digital agent can be hosted anywhere: on mobile devices, IoT devices, laptops, servers, or anywhere in the cloud. Architectural diagrams for agent ecosystems don’t put a blockchain at the center, and words like client and API are generally absent. The mental model might be best visualized as shown in figure 5.3.

Figure 5.3 An example of a Layer 2 Hyperledger Aries ecosystem: a loose mesh of peer agents interspersed with some acting as validator nodes for DIDs at Layer 1
Here, a loose collection of agents—the circular nodes—is interconnected in various ways. The dotted lines between the agent nodes are connections: Alice to Acme as an employee, Faber College to Bob as school, Alice to Bob as an acquaintance. Some agents have many of these connections; others have few. Some agents may even connect to the same peer more than once (Alice to Carol as coworker, Alice to Carol as ham radio buddy).
Connections are constantly forming, and new agent nodes are constantly appearing. Each connection requires a private, pairwise peer DID for each party. As explained earlier in this chapter, these DIDs and their DID documents are not written to any blockchain but are stored in each agent’s wallet. The entire mesh is fluid and fully decentralized; connections are direct between peers, not filtered through any interposed authority.
The mesh of nodes is horizontally scalable, and its performance is a function of the nodes’ collective capacity to interact and store data. Thus it scales and performs in the same way the internet does. The overwhelming majority of protocol exchanges and meaningful interactions that produce business or social value take place directly between the agent nodes. Once a peer DID connection is formed through an exchange of DIDs and DID documents, the resulting channel (the dotted and solid lines in figure 5.3) can be used for anything the respective agents need: issuing credentials, presenting/proving credentials, exchanging data, securely messaging between humans, and so on.
Mingled with the circular agent nodes in figure 5.3 are a few five-sided shapes. These are validator nodes that provide public blockchain services as a utility to the rest of the ecosystem. They maintain connections with one another to facilitate consensus as the blockchain is updated. Any agent node can reach out to the blockchain to test a community truth (such as check the current value of a public key in a DID document). They can also write to the blockchain (for example, create a schema against which credentials can be issued). Because most DIDs and DID documents are not public in this ecosystem, the bulk of traffic between agent nodes doesn’t need to involve the blockchain, thus avoiding attendant scalability, privacy, and cost issues. However, blockchains are still very useful for establishing public trust roots—for example, the DIDs and public keys for institutions that issue (and revoke) credentials that can be broadly trusted.
The interface to this world is decentralized n-party protocols. These are recipes for sequences of stateful interactions (a core concept of REST—representational state transfer—architecture) representing the business problems solved by applications. Because agents are not assumed to be steadily connected like servers, and because data sharing is only one of an agent’s concerns, protocols unfold as encrypted JSON messages that are exchanged, not as APIs that are called (although underlying APIs may be called to trigger specific messages).
To support these protocols, a developer just has to produce and consume JSON over whichever set of transports the target population of agents support. Specific protocols are in various stages of standardization and implementation for many popular interaction patterns, including the verifiable credential exchange protocols we discuss in the next section.
In conclusion, agent-oriented architecture (AOA) is designed to model the variety and flexibility of interactions in the real world while still providing the security, privacy, and trust guarantees necessary to perform transactions that otherwise require direct human intervention at an order of magnitude higher cost and slower speed. On the downside, since the AOA model focuses on loosely coordinated actors with behavior guided by convention, it is more complicated than alternative approaches, more sensitive to network effects, and harder to build and debug. It is also more emergent and, therefore, harder to characterize with confidence. So only time will tell whether AOA will be successful in the market.
5.4 Layer 3: Credentials
If Layers 1 and 2 are where cryptographic trust—trust between machines—is established, Layers 3 and 4 are where human trust enters the picture. Specifically, Layer 3 is the home of the verifiable credential trust triangle introduced in chapter 2. For convenience, we reproduce it in figure 5.4.

Figure 5.4 The verifiable credential trust triangle that is at the heart of all credential exchange (physical or digital)
This trust triangle is where humans can answer questions like these:
-
Is the person digitally signing this contract really an employee of X company?
-
Is the seller of the product I want to buy really based in Z country?
-
Does the person who wants to buy my car hold a valid passport?
-
Is the device I am plugging into my wall socket really approved by Underwriter Laboratories?
-
Is the coffee in this bag really sustainably grown in Nicaragua?
Of course, questions like these are endless—they encompass everything we as humans need to know to make trust decisions, whether in our personal capacity, our business capacity, our governmental/citizen capacity, or our social capacity. The goal of Layer 3 is to support interoperable verifiable credentials that can be used in all of these capacities—from any issuer, for any holder, to any verifier.
Given all the capabilities we have described at Layers 1 and 2, interoperability at Layer 3 comes down to two straightforward questions:
Unfortunately, the answers to these questions are anything but straightforward. The SSI community has significant divergence on the answers, meaning Layer 3 is at risk of not being interoperable.
In this section, we dive into the details of the different answers—first concerning credential formats (what credentials look like on the wire and on disk) and then with regard to the protocols used to exchange them. We cover the three main credential formats:
5.4.1 JSON Web Token (JWT) format
One approach to a credential format is to use the well-established JWT specification (RFC 7519, https://tools.ietf.org/html/rfc7519). JWTs (often pronounced “jots”) were designed as a carrier of authentication and authorization grants; they are used extensively in OAuth, Open ID Connect, and other modern web login technology. JWTs have good support in various programming languages (search for “JOSE JWT library”). For example, the uPort SSI ecosystem is JWT-centric.
One challenge of JWT tooling is that it provides no help for interpreting the rich metadata that is desirable in a credential. A JWT library can confirm that a college transcript is signed—but it has no idea what a college transcript is or how to interpret it. Thus, a JWT solution to credentials must add additional layers of semantic processing, or it must defer all such work to proprietary, non-interoperable software or human judgment.
Another drawback of using JWT for verifiable credentials is that it reveals everything in the signed document. There is no option for selective disclosure—the credential holder’s ability to only reveal certain claims on the credential or to prove facts about those claims without revealing the claim value (such as proving “I am over 21” without revealing my birthdate).
note The term selective disclosure is used in both the privacy community and the financial community. In the privacy community, it has the positive meaning discussed in this section. See https://www.privacypatterns.org/patterns/Support-Selective-Disclosure. In the financial community, it has a negative meaning (a publicly traded company disclosing important information to a single person or a group instead of all investors).
JWTs were originally conceived as short-lived tokens to authenticate or authorize moments after creation. Using them as long-lived credentials is possible, but without any predefined mechanism for credential revocation, it is not obvious how to test the validity of a JWT driver’s license months after issuance. It is possible to build such revocation mechanisms—perhaps with revocation lists, for example—but currently, there is no standard for this and thus no tooling to support it.
5.4.2 Blockcerts format
Blockcerts is an open source proposed standard for machine-friendly credentials and the mechanisms that allow those credentials to be verified. It can use multiple blockchains—notably Bitcoin and Ethereum—as an anchor for credentials. Blockcerts was designed and is championed by Learning Machine. (In 2020, Learning Machine was acquired by Hyland and is now Hyland Credentials: https://www.hylandcredentials .com.)
Blockcerts are digitally signed JSON documents that encode the attributes describing the credential holder. They are issued to a payment address that must be controlled by the holder, and the payment address is embedded in the signed JSON. The holder can then prove that the credential belongs to them by demonstrating that they control the private key for the payment address. Work to adapt blockcerts to use DIDs is underway but has no announced schedule.
Blockcerts are typically issued in batches. Each blockcert is hashed, and hashes of all the certificates in the batch are then combined in a Merkle tree, with the root hash of the batch recorded on a blockchain as shown in figure 5.5. Merkle trees are explained in more detail in chapter 6.
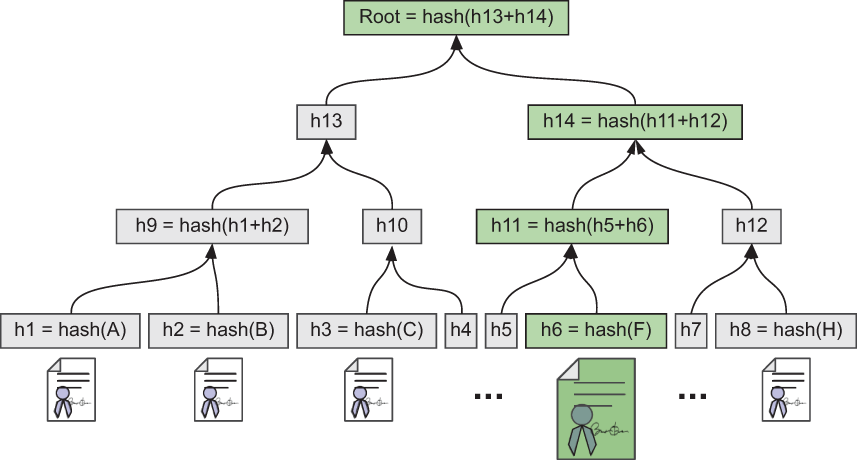
Figure 5.5 A Merkle tree of blockcert hashes, where the root hash is anchored to a public blockchain such as Bitcoin or Ethereum
DEFINITION A Merkle tree is a data structure that holds hashes of data, then hashes of those child hashes, then hashes of those parent hashes, and so forth. These hashes enable efficient proofs that data has not been modified.
Verifying a blockcert proves the following for a credential:
Verification involves evaluating a Merkle proof, which means the hash of the credential is shown to map to a chain of hashes that ends with the hash stored on the ledger. The hash stored on the ledger must be a transaction recorded by the issuer (meaning digitally signed by a key that’s also claimed by the issuer) at a uniform resource identifier (URI) that is also embedded in the credential. Revocation is tested by calling the issuer at another URI where revocation lists are stored. (A smart-contract-based revocation feature that improves privacy has been described but is not yet in production [10].)
5.4.3 W3C verifiable credential formats
The need to establish a worldwide standard for interoperability of verifiable credentials was one of the primary reasons for the formation first of the Verifiable Claims Task Force and then the Credentials Community Group at the W3C (https://www.w3.org/community/credentials). The incubation work resulted in the formation of the Verifiable Claims Working Group in 2017 and, finally, the publication of the Verifiable Credentials Data Model 1.0 as a full W3C Recommendation (official standard) in November 2019 (https://www.w3.org/TR/vc-data-model).
Verifiable credentials are so central to SSI infrastructure that they are covered in their own chapter (chapter 7). For our purposes in this chapter, we can summarize that the Verifiable Credentials Data Model is an abstract data model that uses JavaScript Object Notation for Linked Data (JSON-LD—another W3C standard, http://www.w3.org/TR/json-ld) to describe credentials that can have different schemas and digital signature formats. Two general styles of W3C verifiable credential usage are contemplated: one that focuses on simple credential sharing and one that uses specialized cryptographic signatures to facilitate zero-knowledge proofs.
In the simple credential-sharing model, advocated by uPort, Digital Bazaar, Microsoft, and others, credentials contain the DID of the holder (e.g., the person to whom they are issued). When the credential is presented, the holder reveals the whole credential, including this DID. The holder can then prove that the credential belongs to them because they possess the cryptographic keys that control this DID. Revocation for such credentials uses revocation lists.
One challenge with the simple credential-sharing model is that it is inherently non-repudiable. Once shared, a credential can be reshared without the holder’s permission to any number of parties. Perhaps legislation will clarify how consent for such resharing could be managed.
Another challenge is that revealing a credential in its entirety, including either the hash of the credential or the DID in the credential, provides an extremely easy and strong way to correlate the holder across all verifiers with whom the credential is shared. The extensive privacy risks of this approach are noted in the Verifiable Credentials Data Model specification (https://www.w3.org/TR/vc-data-model/#pri vacy-considerations). Advocates of simple credential sharing point out that these privacy concerns do not, in general, apply to credentials for businesses or business assets (like IoT devices). While this is true, privacy engineers have very serious concerns that if the simple credential model is extended to people, it will become the strongest correlation technology in history. So it’s fair to say that this is one of the most vigorous debates in all of SSI architecture.
The zero-knowledge proof (ZKP) model seeks to address these privacy concerns. The best-known implementation of the ZKP model for VCs is in the Hyperledger Indy project. Microsoft has recently announced plans for a ZKP model of its own, and work has also begun on a JSON-LD-ZKP hybrid approach that Hyperledger Aries and Hyperledger Indy may end up sharing.
ZKP-oriented credentials are not presented directly to a verifier. Instead, they are used to generate ZKP of whatever data a verifier needs to be proved—no more, no less. (ZKP technology is explained in more detail in chapter 6.) A proof is essentially a derived credential that exactly matches the proof criteria. The proof is generated just in time, only when a verifier requests it. Furthermore, a unique proof is generated each time proof is requested—and the resharability of the proof can be controlled by the holder’s cryptography. Because each presentation of a proof is unique, trivial correlation from using the same credential is avoided.
For example, suppose Alice lives in a city that provides free electric car-charging services to its residents. Alice could prove her residency to the charging station day after day, for years, without the station being able to track Alice’s movements through the city’s charging stations. Each presentation of proof is different and discloses nothing correlatable.
It is important to note that this technique does not eliminate correlation in all cases. For example, if the verifier requires Alice to disclose her real name or mobile phone number in the proof, it will become easy to correlate her. However, Alice’s agent can warn her if a proof is asking for highly correlatable personal data so she can make an informed decision.
ZKP-oriented credentials can also take a unique approach to revocation. Instead of revocation lists, they can use privacy-preserving cryptographic accumulators or Merkle proofs rooted on a blockchain. (See chapter 6 for more details.) This allows any verifier to check in real-time for the validity of a credential while not being able to look up a specific credential hash or identifier in a way that leads to correlation.
The primary criticism of ZKP models is the complexity of implementation. ZKPs are an advanced area of cryptography and are not as widely understood as more conventional encryption and digital signature technologies. However, ZKP adoption is gaining ground rapidly as its advantages are being recognized across many different technical fields. A number of newer blockchains, including ZCash and Monero, are based on ZKP technology. ZKP support is also being built into the next generation of Ethereum [11]. ZKP support is built into the core of Hyperledger Ursa (https://wiki.hyperledger.org/display/ursa), an industrial-strength crypto library that is now the standard for all Hyperledger projects. Just as support for the then-new TCP/IP protocol was hampered until hardened libraries became available to developers, the same will be true of ZKPs.
5.4.4 Credential exchange protocols
Regardless of the format of a verifiable credential, interoperability still depends on how that credential is exchanged. This involves any number of complex protocol questions. For example:
-
Should potential verifiers reach out to holders proactively, or should they wait to challenge them when holders attempt to access protected resources?
-
How do verifiers ask for claims that may be in different credentials?
-
Can verifiers add filters or qualifications to their proof requests, such as only accepting claims from specific issuers or only if a credential was issued before or after a specific date?
-
Can verifiers contact a party other than the holder to get credential data?
This is where Layer 3 has a direct dependency on Layer 2. For example, if you think of credentials primarily as inert data and believe the best way to distribute identity data is through hubs, then a natural way to exchange that data might be to call a web API and ask that the data be served to you. A credential holder could leave the credential on the hub, with a policy that tells the hub what criteria must be met before serving it to anyone who asks. This is the general paradigm embodied in the approach taken by credential-serving APIs being incubated for DIF identity hubs (https://identity.foun dation/hub-sdk-js).
On the other hand, if you place a higher emphasis on disintermediation and privacy, and you want proofs of credential data to be generated dynamically in the context of a specific connection, a more natural answer would be to use a peer-to-peer credential exchange protocol using agents and DIDComm. This has been the approach of the Hyperledger Indy, Hyperledger Aries, and Sovrin communities. (The protocols are specified in Aries RFC 0036: Issue Credential Protocol 1.0, and Aries RFC 0037: Present Protocol Proof 1.0. Multiple implementations of these protocols are already in production.)
Again, this is the layer where, as of the writing of this book, there is the most divergence in architectures and protocol philosophies. Standardization efforts are active, but so far, consensus is elusive. However, from the “glass half-full” perspective, this is also the area where real-world adoption drives convergence most quickly, as happened with earlier “protocol wars” such as the OSI-vs.-TCP/IP struggle that eventually birthed the internet. An encouraging example of this is DIF’s Presentation Exchange spec (https://identity.foundation/presentation-exchange), which describes how verifiers can ask for credential-based proof regardless of which credential technologies are in play.
5.5 Layer 4: Governance frameworks
Layer 4 is not just the top of the stack; it is also where the emphasis moves almost entirely from machines and technology to humans and policy. When we introduced governance frameworks in chapter 2, we used the diagram shown in figure 5.6 because it shows how directly governance frameworks build on verifiable credentials.
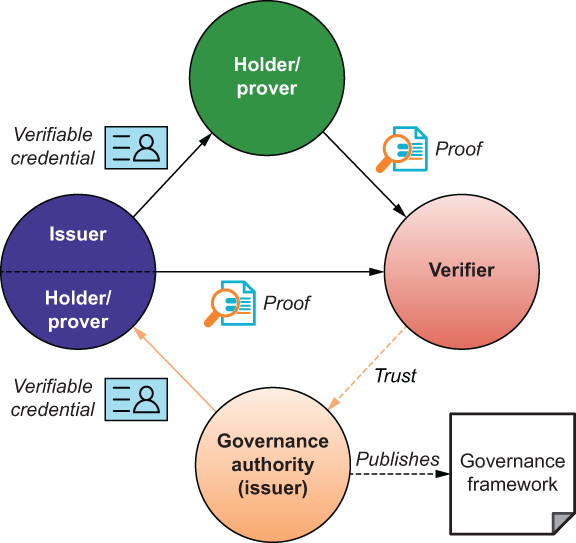
Figure 5.6 Governance frameworks are another trust triangle and solve specification, adoption, and scalability challenges of verifiable credentials.
Governance frameworks enable verifiers to answer an entirely different—but equally relevant—set of questions about verifiable credentials. For example:
-
How do I know this driving license was issued by a real government agency?
-
How do I know the claims on this credit card came from a real bank or credit union?
-
How do I know this diploma was issued by a Canadian university?
-
How do I discover what types of credentials are issued by high schools in Austria?
-
Was KYC required by the Brazilian lender that issued this mortgage credential?
-
Can I rely on a proof based on the birthdate in a Japanese health insurance credential?
Governance frameworks are such a core component of many SSI solutions that we devote an entire chapter to them (chapter 11). Because they are also among the SSI stack’s newer components, not many SSI-specific governance frameworks have been created yet. This is in contrast to trust frameworks designed for federated identity systems, of which there are quite a few around the world (https://openidentityexchange.org).
However, early work on SSI governance frameworks has convinced many SSI architects that these frameworks will be essential to broad adoption of SSI because they are where the rubber meets the road. In other words, they are the bridge between the technical implementations of the SSI stack and the real-world business, legal, and social requirements of SSI solutions. Furthermore, these architects realized governance frameworks apply at all four levels of the SSI stack. John Jordan, executive director of emerging digital initiatives at the Province of British Columbia in Canada, christened this combination of technology and governance the Trust over IP (ToIP) stack. The full ToIP stack, shown in figure 5.7, is a “dual stack” where the left side represents technology layers and the right side represents governance layers. See chapter 10 for more details.
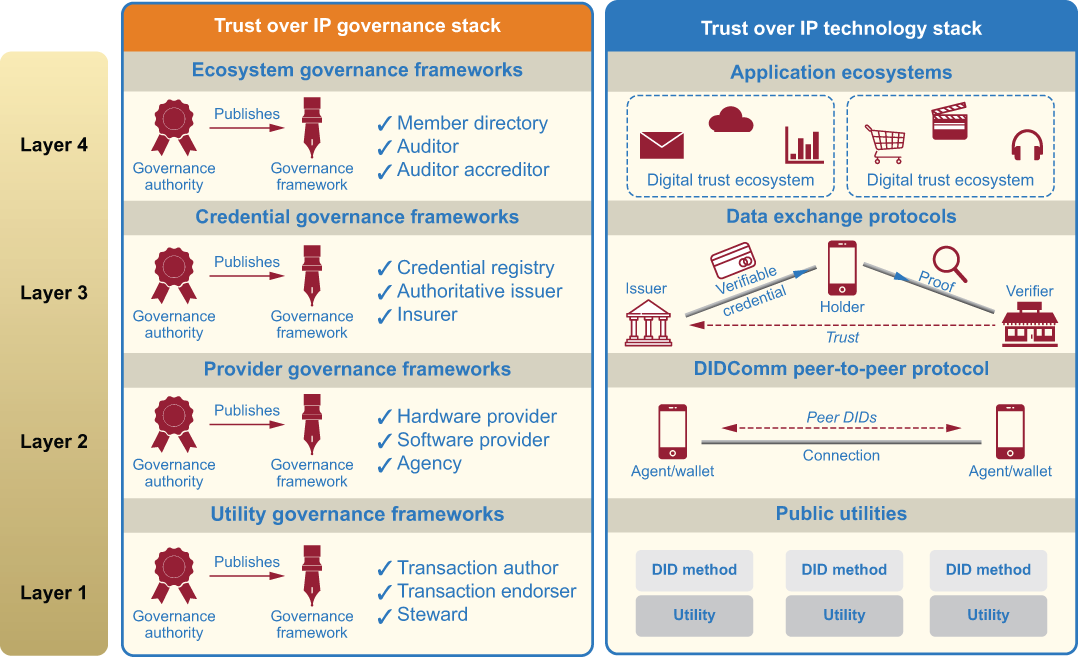
Figure 5.7 The Trust over IP stack illustrates that different types of governance frameworks apply to all four levels of the SSI stack.
During the writing of this book, support for the ToIP stack gained enough momentum that the Linux Foundation launched a new project called the ToIP Foundation (https://trustoverip.org) as a sister project to Hyperledger and the Decentralized Identity Foundation. It grew from 27 founding member organizations in May 2020 to over 140 members by the end of 2020. It now has seven working groups actively working on fully defining, hardening, and promoting the ToIP stack as a model for decentralized digital trust infrastructure.
Despite the fact that governance is where different trust networks and ecosystems within the SSI universe are likely to vary most significantly, the promise of the ToIP stack is that they can use an interoperable metamodel to define those governance frameworks. This can enable both humans and digital agents to much more easily make transitive trust decisions across different trust communities, such as many of the questions listed at the start of this section.
As of the writing of this book, work is very actively going on by governance authorities of all kinds around the world to produce ToIP-compliant governance frameworks at all four levels. These are discussed in greater detail in chapter 11.
5.6 Potential for convergence
The field of SSI is young enough that the market is generating many variations in architecture. In this chapter, we have tried to provide a big-picture overview of where the market stands as of the writing of this book. We have been realistic that there are many areas of divergence. This is true at all four levels: different DID methods at Layer 1, different protocols and interfaces at Layer 2, different credential formats and protocols at Layer 3, and different approaches to governance and digital trust ecosystems at Layer 4.
However, at each level, there is also the potential for convergence. The good news is that this is what market forces want. With automobiles in the early 1900s, market forces drove the industry to standardize on four wheels and internal combustion engines. With the internet, they drove us to standardize on the TCP/IP stack. With the web, they drove us to standardize on HTTP-based browsers and web servers.
We are hopeful the same market forces will drive convergence in SSI so that it, too, can rise to ubiquitous adoption. However, it also seems likely that more surprises await us. Digital identity architecture is likely to remain a fertile field for innovation for a long time to come.
In the next chapter, we provide some baseline cryptographic knowledge that will help with understanding the rest of the chapters in part 2, especially VCs and DIDs. If you already have a deep cryptographic understanding, you can skip chapter 6 or just skim through it to learn how these cryptographic techniques are applied in SSI.
References
1. Terbu, Oliver. 2019. “The Self-sovereign Identity Stack.” Decentralized Identity Foundation. https://medium.com/decentralized-identity/the-self-sovereign-identity-stack-8a2cc95f2d45.
2. Voshmgir, Shermin. 2019. “Blockchains & Distributed Ledger Technologies.” https://block chainhub.net/blockchains-and-distributed-ledger-technologies-in-general.
3. CoinMarketCap. 2021. “Today's Cryptocurrency Prices by Market Cap.” https://coinmarketcap .com (as of 02 January 2021).
4. W3C. 2020. “DID Methods.” https://w3c.github.io/did-spec-registries/#did-methods (as of 19 January 2021).
5. Krassowski, Alan. 2019. “Kiva Protocol: Building the Credit Bureau of the Future Using SSI.” SSI Meetup. https://www.slideshare.net/SSIMeetup/kiva-protocol-building-the-credit-bureau-of-the -future-using-ssi.
6. Annunziato, Vincent. n.d. “Blockchain: A US Customs and Border Protection Perspective. Enterprise Security. https://blockchain.enterprisesecuritymag.com/cxoinsight/blockchain-a-us-cus toms-and-border-protection-perspective-nid-1055-cid-56.html.
7. Tobin, Andrew. 2017. “Sovrin: What Goes on the Ledger?” Evernym. https://sovrin.org/wp-con tent/uploads/2017/04/What-Goes-On-The-Ledger.pdf.
8. Terbu, Oliver. 2020. “DIF starts DIDComm Working Group.” Medium. https://medium.com/decentralized-identity/dif-starts-didcomm-working-group-9c114d9308dc.
9. Hardman, Daniel. 2019. “Rhythm and Melody: How Hubs and Agents Rock Together.” Hyperledger. https://www.hyperledger.org/blog/2019/07/23/rhythm-and-melody-how-hubs-and -agents-rock-together.
10. Santos, João and Kim Hamilton Duffy. 2018. “A Decentralized Approach to Blockcerts Credential Revocation.” Rebooting Web of Trust 5. http://mng.bz/w9Ga.
11. Morris, Nicky. 2019. “EY Solution: Private Transactions on Public Ethereum.” Ledger Insights. https://www.ledgerinsights.com/ey-blockchain-private-transactions-ethereum.