
Drummond Reed and Markus Sabadello
Decentralized identifiers (DIDs) are the cryptographic counterpart to verifiable credentials (VCs). Together these are the “twin pillars” of SSI standardization. In this chapter, you learn how DIDs evolved from the work started with VCs, how they are related to URLs and URNs, why a new type of cryptographically verifiable identifier is needed for SSI, and how DIDs are being standardized at World Wide Web Consortium (W3C). Your guides are two of the editors of the W3C Decentralized Identifier 1.0 specification: Markus Sabadello, founder and CEO of Danube Tech, and Drummond Reed, chief trust officer at Evernym.
At the most basic level, a decentralized identifier (DID) is simply a new type of globally unique identifier—not that different from the URLs you see in your browser’s address bar. But at a deeper level, DIDs are the atomic building block of a new layer of decentralized digital identity and public key infrastructure (PKI) for the internet. This decentralized public key infrastructure (DPKI, https://github.com/WebOf TrustInfo/rebooting-the-web-of-trust/blob/master/final-documents/dpki.pdf) could eventually have as much impact on global cybersecurity and cyberprivacy as the development of the SSL/TLS protocol for encrypted web traffic (currently the largest PKI in the world).
This means you can understand DIDs at four progressively deeper levels (figure 8.1). In this chapter, we travel all the way down through these four levels to provide a much deeper understanding of DIDs.
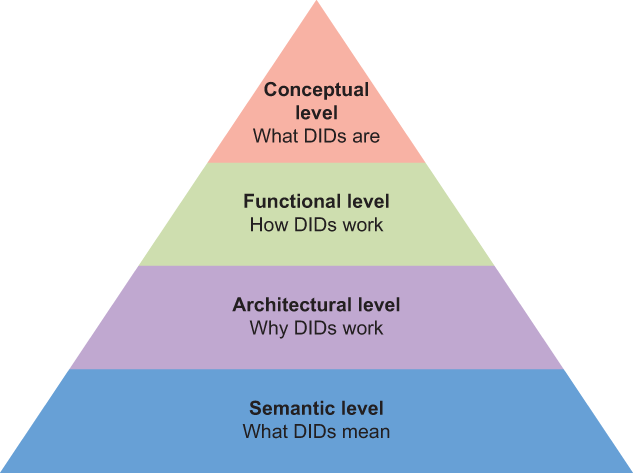
Figure 8.1 The progression of four levels at which we can understand DIDs—from a basic definition to a deep understanding of how and why they work and what they mean for the future of the internet and the web
8.1 The conceptual level: What is a DID?
As defined by the W3C DID Core 1.0 specification (https://www.w3.org/TR/did-core) published by the W3C DID Working Group (https://www.w3.org/2019/did-wg), a DID is a new type of globally unique identifier: a string of characters that identifies a resource.
(Resource is the term used by the W3C across all web standards. The digital identity community generally uses the term entity. For the purposes of this book, the two terms can be considered equivalent.) A resource is anything that can be identified, from a web page to a person to a planet. This string of characters (figure 8.2) looks very much like any other web address, except instead of http: or https:, it begins with did.

Figure 8.2 The general format of a DID: the scheme name followed by a DID method name followed by the method-specific string, the syntax for which is defined by the DID method
8.1.1 URIs
In terms of technical standards, a DID is a type of Uniform Resource Identifier (URI). URIs are an IETF standard (RFC 3986, https://tools.ietf.org/html/rfc3986) adopted by the W3C to identify any type of resource on the World Wide Web. A URI is a string of characters in a specific format that makes the string globally unique—in other words, no other resource has that same identifier. Of course, this is very different from human names where many people can have exactly the same name.
8.1.2 URLs
A Uniform Resource Locator (URL) is a URI that can be used to locate a representation of that resource on the web. A representation is anything that describes the resource. For example, for a website URL, the resource is a specific page on that site. But if the resource is a person, they obviously can’t be “on the web” directly. So the representation needs to be something describing that person, such as a résumé, blog, or Linked-In profile.
Every resource representation available on the web has a URL—web page, file, image, video, database record, and so on. It’s not “on the web” if it doesn’t have a URL. The addresses that appear in your browser’s address bar are generally URLs; figure 8.3 is an example of the URL for this book on the Manning website.

Figure 8.3 An example of a browser address bar displaying the URL for the web page about this book
Why do we need the distinction between URIs and URLs if everything on the web has a URL? Because we also need to identify resources that are not on the web: people, places, planets—all the things we had names for long before the internet even existed. All of these are resources that we often need to refer to on the web without the resource actually being represented on the web. A URI that is not a URL is often called an abstract identifier.
NOTE The question of whether a DID by itself serves as a URL—while sounding trivial—is actually quite deep. We will have to go all the way down to the semantic layer before we can answer it completely.
8.1.3 URNs
If URLs are the subclass of URIs that point to the location of a representation of a resource of the network—which can always change—then what about the subclass of URIs that identify the abstract resource itself and thus are designed never to change? It turns out there are many uses for this kind of persistent identifier (also called a permanent identifier). This is exactly what you want when you need to be able to refer to the resource:
In web architecture, the subclass of URIs reserved for persistent identifiers are called Uniform Resource Names (URNs). They are defined by RFC 8141 (https://tools.ietf.org/html/rfc8141), which goes into great detail about both the syntax and the policies necessary to manage namespaces for identifiers that are meant never to change. (Think about how complex it would get if every phone number, email address, and human name could be assigned only once and never reused for another person ever again for the rest of time.) Figure 8.4 shows how URLs and URNs are both subclasses of URIs.

Figure 8.4 URLs and URNs are subclasses of URIs. URLs always point to representations of resources on the web, whereas URNs are persistent names for any resource, on or off the web.
8.1.4 DIDs
Having described URIs, URLs, and URNs, we can now be more precise about the definition of a DID. A DID is a URI that can be either a URL or a URN and that can be looked up (resolved) to get a standardized set of information (metadata) about the resource identified by the DID (as described in the next section). If the identified resource has one or more representations on the web, the metadata can include one or more of those URLs.
But that definition captures only two of the four properties of a DID: persistence and resolvability. The other two properties—cryptographic verifiability and decentralization—most strongly distinguish a DID from other URIs or any other globally unique identifiers. At the first meeting of the W3C DID Working Group in September 2019 at Fukuoka, Japan, one presenter summarized the four properties as shown in figure 8.5.

Figure 8.5 A summary of the four core properties of a DID presented at the first meeting of the W3C DID Working Group
What is special about the third and fourth properties is that they both depend on cryptography (chapter 6). In the first case—cryptographic verifiability—cryptography is used to generate the DID. Since the DID is now associated with exactly one public/private key pair, the controller of the private key can prove that they are also the controller of the DID. (See section 8.3 for more details.)
In the second case—decentralized registration—cryptography eliminates the need for centralized registration authorities—the kind needed for almost every other globally unique identifier we use, from postal addresses to telephone numbers to domain names. The centralized registries run by these authorities can determine if a particular identifier is unique—and allow it to be registered only if it is.
By contrast, cryptographic algorithms for public/private key pairs are based on random number generators, large prime numbers, elliptic curves, or other cryptographic techniques for producing globally unique values that do not require a central registry to effectively guarantee uniqueness. We say “effectively guarantee” because there is an infinitesimally small chance of a collision with someone else using the same algorithm. But this chance of collision is mathematically so small that for all practical purposes, it can be ignored.
As a result, anyone with the proper software can generate a DID according to a particular DID method (discussed in the following sections) and begin using it immediately without requiring the authorization or involvement of any centralized registration authority. This is the same process used to create public addresses on the Bitcoin or Ethereum (or other popular) blockchains—it is the essence of what makes a DID decentralized.
8.2 The functional level: How DIDs work
We now go down to the second level of detail to explain how DIDs function.
8.2.1 DID documents
Identifiers can, of course, be useful by themselves, as strings of text characters that can be used to refer to a resource. This string can be stored in a database or a document, attached to an email, or printed on a t-shirt or business card. But for digital identifiers, the usefulness comes not just from the identifier but also from how it can be used by applications designed to consume that particular type of identifier. For example, a typical web address that starts with http or https is not very interesting as a string by itself. It only becomes useful once you type it into a web browser or click a hyperlink to access a representation of the resource behind the identifier (such as a web page).
This is similar with DIDs: although it is not yet possible to type a DID into a web browser and have it do anything meaningful, you can give it to a specialized piece of software (or hardware) called a DID resolver that will use it to retrieve a standardized data structure called a DID document. This data structure is not like a web page or an image file—it is not designed to be viewed directly by end users in a web browser or similar software. (In the future, “DID navigators” may be able to let you travel across a “trust web,” but most likely this will be done using conventional web pages associated with DIDs.) Instead, it is a machine-readable document designed to be consumed by digital identity applications or services such as digital wallets, agents, or encrypted data stores, all of which use DIDs as fundamental building blocks.
Every DID has exactly one associated DID document. The DID document contains metadata about the DID subject, which is the term for the resource identified by the DID and described by the DID document. For example, a DID for a person (the DID subject) has an associated DID document that typically contains cryptographic keys, authentication methods, and other metadata describing how to engage in trusted interactions with that person. The entity that controls the DID and its associated DID document is called the DID controller. In many cases, the DID controller is the same as the DID subject (figure 8.6), but they can also be different entities. An example is when a parent controls a DID that identifies their child—the DID subject is the child, but the DID controller (at least, until the child comes of age) is the parent.

Figure 8.6 Relationships between the DID, DID document, and DID subject (in the case where the DID subject is also the DID controller)
Theoretically, a DID document can contain any arbitrary information about the DID subject, even personal attributes such as a name or an email address. In practice, however, this is problematic for privacy reasons. Instead, the recommended best practice is for a DID document to contain only the minimum amount of machine-readable metadata required to enable trustable interaction with the DID subject. Typically, this includes the following:
-
One or more public keys (or other verification methods) that can be used to authenticate the DID subject during an interaction. This is what makes interactions involving DIDs trustable, and this is also the essence of the DPKI enabled by DIDs.
-
One or more services associated with the DID subject that can be used for concrete interaction via protocols supported by those services. This can include a wide range of protocols from instant messaging and social networking to dedicated identity protocols such as OpenID Connect (OIDC), DIDComm, and others. See chapter 5 for more details about these protocols.
-
Certain additional metadata such as timestamps, digital signatures, and other cryptographic proofs, or metadata related to delegation and authorization.
The following is an example of a very simple DID document using a JSON-LD representation. The first line is the JSON-LD context statement, required in JSON-LD documents (but not in other DID document representations). The second line is the DID being described. The authentication block includes a public key for authenticating the DID subject. The final block is a service endpoint for exchanging verifiable credentials.
Listing 8.1 DID document with one public key for authentication, and one service
{
"@context": "https://www.w3.org/ns/did/v1",
"id": "did:example:123456789abcdefghi",
"authentication": [{
"id": "did:example:123456789abcdefghi#keys-1",
"type": "Ed25519VerificationKey2018",
"controller": "did:example:123456789abcdefghi",
"publicKeyBase58" : "H3C2AVvLMv6gmMNam3uVAjZpfkcJCwDwnZn6z3wXmqPV"
}],
"service": [{
"id":"did:example:123456789abcdefghi#vcs",
"type": "VerifiableCredentialService",
"serviceEndpoint": "https://example.com/vc/"
}]
}
This metadata associated with every DID, especially public keys and services, is the technical basis for all interaction between different actors in an SSI ecosystem.
8.2.2 DID methods
As we explained in the previous sections, DIDs are not created and maintained in a single type of database or network like many other types of URIs. There is no authoritative centralized registry—or a hierarchy of federated registries like DNS—where all DIDs are written and read. Many different types of DIDs exist in today’s SSI community—see section 8.2.7. They all support the same basic functionality, but they differ in how that functionality is implemented, e.g. how exactly a DID is created or where and how a DID’s associated DID document is stored and retrieved.
These different types of DIDs are known as DID methods. The second part of the DID identifier format—between the first and second colons—is called the DID method name. Figure 8.7 shows examples of DIDs created using five different DID methods: sov (Sovrin), btcr (Bitcoin), v1 (Veres One), ethr (Ethereum), and jolo (Jolocom).

Figure 8.7 Example DIDs generated using five different DID methods
note In 2021, the Sovrin DID method is planned to evolve into the Indy DID method, and the prefix will become did:indy:sov:. See https://wiki.hyperledger.org/display/indy/Indy+DID+Method+Specification.
As of early 2021, more than 80 DID method names have been registered in the DID Specification Registries (https://www.w3.org/TR/did-spec-registries) maintained by the W3C DID Working Group (https://www.w3.org/2019/did-wg). Each DID method is required to have its own technical specification, which must define the following aspects of the DID method:
-
The syntax that follows the second colon of a DID. This is called the method-specific identifier. It is typically a long string generated using random numbers and cryptographic functions. It is always guaranteed to be unique within the DID method namespace (and is recommended to be globally unique all by itself).
-
The four basic “CRUD” operations that can be executed on a DID:
-
Security and privacy considerations specific to the DID method.
It is difficult to make generic statements about the four DID operations since DID methods can be designed in very different ways. For example, some DID methods are based on blockchains or other distributed ledgers. In this case, creating or updating a DID typically involves writing a transaction to that ledger. Other DID methods do not use a blockchain; they implement the four DID operations in other ways (see section 8.2.7).
One consequence of the technological variety of DID methods is that some may be better suited for certain use cases than others. DID methods may differ in how “decentralized” or “trusted” they are, as well as in factors of scalability, performance, or cost of the underlying technical infrastructure. The W3C DID Working Group charter includes a deliverable called a “rubric” document whose purpose is to help adopters evaluate how well a particular DID method will meet the needs of a particular user community (https://w3c.github.io/did-rubric).
8.2.3 DID resolution
The process of obtaining the DID document associated with a DID is called DID resolution. This process allows DID-enabled applications and services to discover the machine-readable metadata about the DID subject expressed by the DID document. This metadata can be used for further interaction with the DID subject, such as the following:
-
To look up a public key to verify a digital signature from the issuer of a verifiable credential
-
To authenticate the DID controller when the controller needs to log in to a website or app
-
To discover and access a well-known service associated with the DID controller, such as a website, social network, or licensing authority
The first three of these scenarios are illustrated in figure 8.8.

Figure 8.8 Common scenarios requiring DID resolution. The first is using a DID to identify the issuer of a verifiable credential, the second to log in to a website, and the third to discover a service associated with the DID.
The DID-resolution process is based on the Read operation defined by the applicable DID method. As we have noted, this can vary considerably depending on how the DID method is designed. This means DID resolution is not confined to a single protocol in the same way as DNS (the protocol for resolving domain names to IP addresses) or HTTP (the protocol for retrieving representations of resources from web servers).
For example, no assumption should be made that a blockchain, distributed ledger, or database (centralized or decentralized) is used for resolving DIDs—or even that interaction with a remote network is required during the DID-resolution process. Furthermore, a DID document is not necessarily stored in plain text in a database or for download from a server. Although some DID methods may work like this, others may define more complex DID-resolution processes that involve on-the-fly construction of virtual DID documents. Therefore, rather than thinking of DID resolution as a concrete protocol, it should be considered an abstract function or algorithm that takes a DID (plus optional additional parameters) as its input and returns the DID document (plus optional additional metadata) as its result.
DID resolvers can come in several architectural forms. They can be implemented as a native library included in an application or even an operating system—the same way as DNS resolvers are included in all modern operating systems. Alternatively, a third party can provide a DID resolver as a hosted service, responding to DID resolution requests via HTTP or other protocols (called bindings). Hybrid forms are also possible—for example, a local DID resolver could delegate part or all of the DID-resolution process to a preconfigured, remotely hosted DID resolver (figure 8.9). This is similar to how DNS resolvers in our local operating systems typically query a remote DNS resolver hosted by an internet service provider (ISP) to perform the actual DNS resolution work.

Figure 8.9 An example of a local DID resolver querying a remote DID resolver, which then retrieves the DID document according to the applicable DID method
Of course, reliance on an intermediary service during the DID-resolution process introduces potential security risks and potential elements of centralization, each of which can impact the security and trust properties of other layers in the SSI stack that rely on DIDs. Therefore, whenever possible, DID resolution should be integrated directly into a DID-enabled application in such a way that the application can independently verify that the DID-resolution result is correct (in other words, the correct DID document has been returned).
8.2.4 DID URLs
DIDs are powerful identifiers by themselves, but they can also be used as the basis for constructing more advanced URLs rooted on a DID. This is similar to the http: and https: URLs used on the web: they can consist not only of a domain name but also of other syntactic components appended to the domain name, such as an optional path, optional query string, and optional fragment, as shown in figure 8.10.

With web URLs, these other syntactic components enable identifying arbitrary resources under the domain name’s authority. The same is true for DIDs. So even though the primary function of a DID is to resolve to a DID document, it can also serve as a root authority of a set of DID URLs that enable an identifier space for additional resources associated with the DID.
DID URLs can be used for many different purposes. Some will be well-known and standardized, whereas others will depend on the DID method or application. See table 8.1 for examples of DID URLs and their meanings:
Table 8.1 Example DID URLs and their meanings
Processing a DID URL involves two stages. The first stage is DID resolution: calling a DID resolver to retrieve the DID document. The second stage is DID dereferencing. Whereas resolution only returns the DID document, in the dereferencing stage, the DID document is further processed to access or retrieve the resource identified by the DID URL—which can be either a subset of the DID document itself (such as the public key example given earlier) or a separate resource identified by the DID URL, such as a web page. These two terms—resolution and dereferencing—are defined by the URI standard (RFC 3986), and they apply not only to DIDs but to all types of URIs and the resources they identify. Figure 8.11 is an example of how these two processing stages differ.

Figure 8.11 The process of first resolving a DID and then dereferencing a DID URL containing a fragment. The result is a specific public key inside the DID document.
8.2.5 Comparison with the Domain Name System (DNS)
We have already used domain names and the Domain Name System (DNS) as an analogy when explaining certain aspects of DIDs and how they are different from other identifiers. Table 8.2 summarizes the similarities and differences between DIDs and domain names.
Table 8.2 Comparison of DIDs and domain names
8.2.6 Comparison with URNs and other persistent Identifiers
As we explained previously, DIDs can meet the functional requirements of URNs: they have the capability of being used as persistent identifiers that always identify the same entity and are never reassigned. There are many other types of persistent identifiers that differ from DIDs in ways that make them generally less suitable for SSI applications. Table 8.3 lists other types of persistent identifiers and how they compare to DIDs.
Table 8.3 Comparison of DIDs with other types of persistent identifiers
Figure 8.12 is a visual way of depicting how most of the other URIs in use today compare to DIDs. Note that it does not include a circle for cryptographic verifiability because DIDs are the only identifiers that offer that property. However, it does include a circle for one property DIDs do not explicitly have: delegatability—the ability for one identifier authority to delegate a sub-namespace to another identifier authority. An example is a domain name like maps.google.com, where the .com registry delegates to Google, and Google delegates to its maps service.

Figure 8.12 Compared to other identifiers, DIDs are persistent, resolvable, and decentralized (cryptographic verifiability is not shown since it does not apply to any of the other identifiers).
8.2.7 Types of DIDs
Since their invention, interest in DIDs has grown exponentially (see the next section). Although the first DID methods were closely tied to blockchains and distributed ledgers, as DIDs started evolving, many more types of DIDs have been developed. At the first meeting of the W3C DID Working Group in September 2019 in Fukuoka, Japan, a set of presentations described the various DID methods developed to that point as falling into the broad categories in table 8.4.
Table 8.4 The broad categories of DID methods developed as of August 2020
|
The original category of DID methods involves a blockchain or other distributed ledger technology (DLT), which serves the purpose of a registry that is not controlled by a single authority. This registry is typically public and globally accessible. A DID is created/updated/ deactivated by writing a transaction to the ledger, which is signed with the DID controller’s private key: did:sov:WRfXPg8dantKVubE3HX8pw did:ethr:0xE6Fe788d8ca214A080b0f6aC7F48480b2AEfa9a6 did:v1:test:nym:3AEJTDMSxDDQpyUftjuoeZ2Bazp4Bswj1ce7FJGybCUu |
|
|
An improvement to classic ledger-based DID methods, this category adds an additional storage layer such as a distributed hash table (DHT) or traditional replicated database system on top of the base layer blockchain. DIDs can be created/updated/deactivated at this second layer without requiring a base layer ledger transaction every time. Instead, multiple DID operations are batched into a single ledger transaction, increasing performance and decreasing cost: |
|
|
This special category of DID method does not require a globally shared registration layer such as a blockchain. Instead, a DID is created and subsequently shared with only one other peer (or a relatively small group of peers). The DIDs that are part of the relationship are exchanged via a peer-to-peer protocol, resulting in private connections between the participants (see https://identity.foundation/peer-did-method-spec/index.html): |
|
|
There is a category of DID methods that are “static”, i.e. they enable a DID to be created and resolved, but not updated or deactivated. Such DID methods tend to not require complex protocols or storage infrastructure. For example, a DID may simply be a “wrapped” public key, from which an entire DID document can be resolved algorithmically, without requiring any data other than the DID itself: |
|
|
A number of other innovative DID methods have been developed that do not fall into any of the previous categories. They demonstrate that DID identification architecture is flexible enough to be layered on top of existing internet protocols, such as Git, the Interplanetary File System (IPFS), or even the web itself: did:git:625557b5a9cdf399205820a2a716da897e2f9657 |
8.3 The architectural level: Why DIDs work
Having explained what DIDs are and how they work, let’s now go a step deeper into why they work. Why is there so much interest in this new type of identifier? To answer this, we must delve more deeply into the core problems they solve, which are less problems of identity and more problems of cryptography.
8.3.1 The core problem of Public Key Infrastructure (PKI)
Since it was first conceived, PKI has had one hard problem at its very core. It is not a problem with cryptography per se, i.e., with the math involved with public/private keys or encryption/decryption algorithms. Rather, it is a problem with cryptographic infrastructure: how we can make public/private key cryptography easy and safe for people and organizations to use at scale.
This is not an easy problem. It has vexed PKI ever since the term was invented. The reason lies in the very nature of how public/private key cryptography works. To
understand this, let’s take a look at the basic PKI trust triangle (figure 8.13). It shows that it’s not enough to think about public/private key pairs. You have to see each key pair in relation to its controlling authority (controller), be that a person, an organization, or even a thing (if the thing has the capacity to generate key pairs and store them in a digital wallet).

Figure 8.13 The basic trust triangle at the heart of all public/private key cryptography
Public and private keys are bound to each other mathematically such that neither can be forged—each can be used only for a specific set of functions defined by a specific cryptographic algorithm. But both types of keys are intrinsically related to the controller. Regardless of the algorithm, these two fundamental roles are highlighted in figure 8.14. The private key must be reserved for the controller’s exclusive use (or its delegates) and must never be revealed to anyone else. By contrast, the public key is just the opposite: it must be shared with any party that wishes to communicate with the controller securely. It is the only way to encrypt messages to—or verify messages from—that controller.

Figure 8.14 The fundamental roles of public keys vs. private keys in PKI
Although the task of keeping a private key private is not trivial by any means, that is not the hard problem at the heart of PKI. Rather, the hard problem is on the other side of the PKI trust triangle, as shown in figure 8.15.
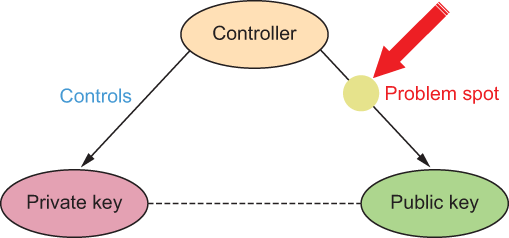
Figure 8.15 The core problem at the heart of PKI: how do you bind a public key to its controller?
The problem is simply this: how do you strongly bind a public key to its controller so that any party relying on that public key (the relying party) can be sure they are dealing with the real controller? After all, if you can fool a relying party into accepting the public key for controller B when the relying party thinks it is the public key for controller A, then for all intents and purposes, controller B can fully impersonate controller A. The cryptography will work perfectly, and the relying party will never know the difference—until they become the victim of whatever cybercrime controller B is perpetrating.
Therefore, as a relying party, it is essential to know you have the correct public key at the correct point in time for any controller you are dealing with. That is indeed a challenging problem because whereas public keys are purely digital entities whose cryptographic validity can be verified in milliseconds, controllers are not. They are real people, organizations, or things that exist in the real world. So the only way to digitally bind a public key to a controller is to add one more piece of the puzzle: a digital identifier for the controller.
This means the real PKI trust triangle is the triangle shown in figure 8.16. The additional piece of the puzzle is an identifier for the controller that can be bound to the public key in such a way that relying parties can be confident the public key belongs to the controller and nobody else.

Figure 8.16 The real PKI trust triangle includes a digital identifier for the controller.
What figure 8.16 reveals is that this identifier-binding problem has two parts:
These two problem spots are called out in figure 8.17.
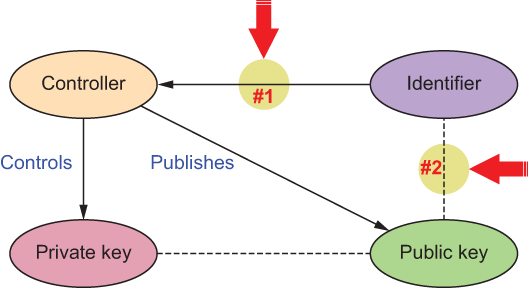
Figure 8.17 The two problem spots when it comes to strongly binding an identifier to a controller
These are the two problem areas that PKI has struggled with since it was born in the 1970s. In the balance of this section, we’ll look at four different solutions to these two problems:
8.3.2 Solution 1: The conventional PKI model
The first solution is the conventional PKI model for issuing digital certificates (certs). This is the predominant model that has evolved over the last 40 years. Probably the best-known example is the SSL/TLS PKI, which uses X.509 certs to provide secure connections in browsers using the HTTPS protocol (the lock you see in your browser address bar).
The conventional PKI solution to the first problem—identifier-to-controller binding—is to use one of the most suitable existing identifiers and then follow industry best practices to strongly bind this identifier to the controller. Figure 8.18 summarizes the potential choices of identifiers for conventional PKI and highlights the ones used most often in X.509 certificates.

Figure 8.18 The different identifier choices for conventional PKI. The highlighted choices are those typically used in X.509 digital certificates.
The primary advantage of a URL (based on a domain name or IP address) is that automated tests can be performed to ensure that the public key controller also controls the URL. However, these tests cannot detect homographic attacks (using look-alike names or look-alike characters from different international alphabets) or DNS poisoning.
The primary advantage of an X.500 distinguished name (DN) is that it can be administratively verified to belong to the controller. However, this verification must be performed manually and thus is always subject to human error. Furthermore, it is not easy to register an X.500 DN—it is certainly not something the average internet user can be expected to undertake.
The conventional PKI approach to the second problem—public-key-to-identifier binding—seems obvious in the context of cryptography: digitally sign a document containing both the public key and the identifier. That is the origin of the public key certificate (a specific kind of digital certificate). This solution is illustrated in figure 8.19.

Figure 8.19 Conventional PKI solves the public-key-to-identifier binding problem using digital certificates signed by some type of certificate authority.
The question, of course, is who digitally signs this digital certificate? This introduces the whole notion of a trusted third party (TTP)—someone the relying party must trust to sign the digital certificate, or else the whole idea of PKI falls apart. The conventional PKI answer is a certificate authority (CA)—a service provider whose entire job is to follow a specified set of practices and procedures to confirm the identity of a controller and the authenticity of its public key before issuing a digital certificate that binds the two of them and signing it with the CA’s private key.
Different PKI systems use different certification programs for CAs; one of the best known is the WebTrust program originally developed by the American Institute of Certified Public Accountants and now run by the Chartered Professional Accountants of Canada (https://www.cpacanada.ca/en/business-and-accounting-resources/audit-and -assurance/overview-of-webtrust-services). WebTrust is the certification program used for the SSL/TLS certificates that indicate a secure connection in your browser. Certification is obviously critical for CAs because acting as a TTP is inherently a human process—it cannot be automated (if it could, a TTP would not be needed). And unfortunately, humans make mistakes.
But being human is only one issue with TTPs. Table 8.5 lists the other drawbacks.
Table 8.5 The drawbacks of using the TTPs required in conventional PKI to solve the identifier binding problem
Despite all these drawbacks, conventional PKI has so far been the only commercially viable solution to the identifier binding problem. But as the internet has climbed in usage and commercial value—and cybercrime rates have climbed with it—so has the demand for a better solution.
8.3.3 Solution 2: The web-of-trust model
One alternative to the conventional PKI model was formulated by one of the pioneers in public/private key cryptography, Phillip Zimmermann, inventor of Pretty Good Privacy (PGP). He coined the term web of trust for this model because it didn’t rely on centralized CAs, but rather on individuals who knew each other directly and therefore could individually sign each other’s public keys—effectively creating peer-to-peer digital certificates. Figure 8.20 is a visual depiction of how the web-of-trust model works.
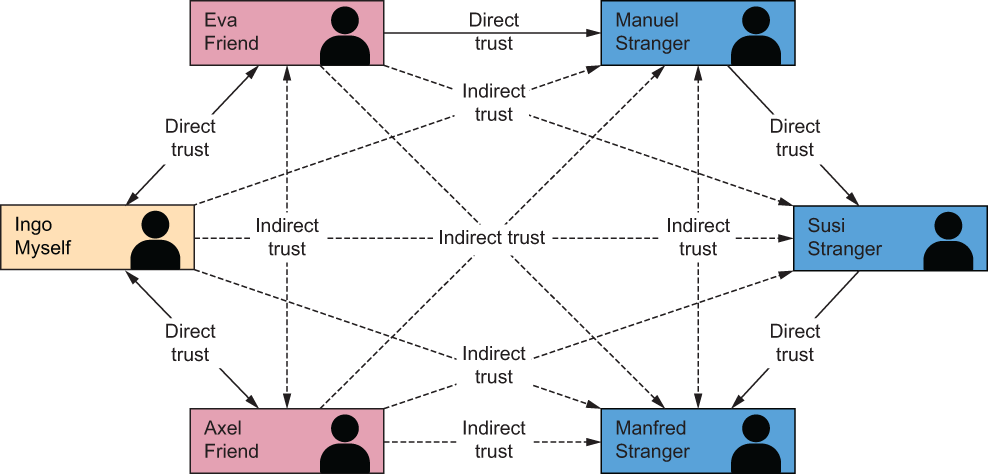
Figure 8.20 A diagram of how a web of trust can be constructed
Since the original formulation, hundreds of academic papers have been written exposing issues with and proposing improvements for the web-of-trust model. However, the primary challenge is that the only thing it really changes in the conventional PKI model is who signs the digital certificate. It turns the problem of “Who do you trust?” (the TTP problem) into the problem of “Who do you trust who knows someone else you can trust?” That is, how do you discover a “trusted path” to the digital certificate you want to verify? So far, no one has developed a reasonably secure, scalable, adoptable solution to this problem.
8.3.4 Solution 3: Public key-based identifiers
The drawbacks of both the conventional and web-of-trust PKI models ultimately led to a very different approach: removing the need for a TTP by replacing it with yet another clever use of cryptography. In other words, rather than trying to reuse an existing identifier for the controller (e.g., domain name, URL, X.500 DN) and then binding it to the public key, reverse the whole process and generate an identifier for the controller based on the public key (either directly or via a transaction with a blockchain, distributed ledger, or similar system). This new approach to constructing the PKI trust triangle is illustrated in figure 8.21.

Figure 8.21 Public key-based identifiers take a completely different approach to the identifier binding problem by generating the identifier for the controller from the public key.
There are two basic approaches to generating a globally unique identifier from a public key:
-
With the transactional approach, the controller uses the public/private key combination to perform a transaction with a blockchain, distributed ledger, or other algorithmically controlled system to generate a transaction address (such as a Bitcoin or Ethereum address). This transaction address becomes the identifier because it is globally unique and provably controlled by the controller.
-
With the self-certifying approach, the controller performs a cryptographic operation, such as a one-way hash function, on the public key (and potentially other metadata) to produce a globally unique value that, by definition, only the controller can prove they control.
The significant difference between the two approaches is whether they require an external system. Transaction addresses require an external system such as a blockchain, distributed ledger, distributed file system, and so on. This external system essentially replaces a TTP run by humans (the CA required with conventional PKI) with a TTP run by machines. The argument is that the latter is more secure (no humans in the loop), is more decentralized (depending on the design and implementation of the blockchain), and has a dramatically lower cost.
Self-certifying identifiers have the advantage of not requiring any external system—they can be verified by anyone in milliseconds using cryptography alone. This also should make them the most decentralized and lowest cost of all options. See chapter 10—in particular, section 10.8 on Key Event Receipt Infrastructure (KERI)—for much more about this approach.
Regardless of the specific architecture, there are two obvious benefits of using public key-based identifiers to solve the public-key-to-identifier binding problem. First, they remove humans from the loop. Second, they also solve the identifier-to-controller binding problem because only the private key controller can prove control of the identifier. In other words, with public key-based identifiers, the controller controls all three points of the real PKI trust triangle because all three values are generated cryptographically using key material that only the controller possesses.
As powerful as public key-based identifiers appear, by themselves they have one major Achilles heel: the controller’s identifier changes every time the public key is rotated. As we explain further in chapter 10, key rotation—switching from one public/private key pair to a different one—is a fundamental security best practice in all types of PKI. Thus the inability for public key-based identifiers alone to support key rotation has effectively prevented their adoption as an alternative to conventional PKI.
8.3.5 Solution 4: DIDs and DID documents
What if there was a way to generate a public key-based identifier once and then be able to continue to verify it after every key rotation? Enter the DID and DID document.
First, the controller generates the original public key-based identifier—the DID—once, based on the genesis public/private key pair, as shown in figure 8.21. Next, the controller publishes the original DID document containing the DID and the public key, as shown in figure 8.22.

Figure 8.22 The controller publishes the DID and the original public key in the original DID document.
At this point, anyone with access to the DID document can cryptographically verify the binding between the DID and the associated public key—either by verifying the transaction address or by verifying the self-certifying identifier.
Now, when the controller needs to rotate the key pair, the controller creates an updated DID document and signs it with the previous private key, as shown in figure 8.23. Note that if a transactional DID method is used, the controller has to make a new transaction with an external system (such as a blockchain) to register the updated DID document. But there is no human in this loop—the controller can perform this transaction at any time, provided the controller controls the associated private key.

Figure 8.23 The controller publishes an updated DID document containing the original DID and the new public key and then digitally signs it with the original private key, creating a chain of trust between the DID documents.
This chain of trust between DID documents can be traced back through any number of updates to the original DID document with the original public key-based identifier. Essentially each DID document serves as a new digital certificate for the new public key as shown—but without the need for a CA or any other human-based TTP to certify it.
8.4 Four benefits of DIDs that go beyond PKI
So DIDs allow us to finally achieve broad adoption of public key-based identifiers and still enjoy key rotation and other essential features of conventional PKI—without the drawbacks. But the benefits of DIDs do not stop there. In this section, we cover four benefits of DIDs that go beyond what is offered by PKI as we know it today.
8.4.1 Beyond PKI benefit 1: Guardianship and controllership
DIDs provide a clean way to identify entities other than the DID controller. Conventional PKI generally assumes the registrant of the digital certificate (the controller of the private key) is the party identified by the digital certificate. However, there are many situations where this is not the case. Take a newborn baby. If the baby were to need a DID—for example, to be the subject of a birth certificate issued as a verifiable credential—the newborn is in no position to have a digital wallet. The baby would need a parent (or another guardian) to issue this DID on their behalf. In this case, the entity identified by the DID—the DID subject—is explicitly not the controller, as shown in figure 8.24.
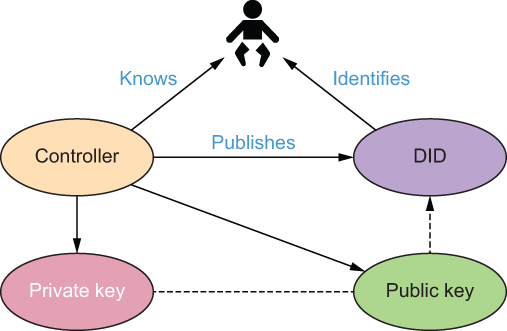
Figure 8.24 An example of a DID used to identify a DID subject (a newborn baby) that is not the controller of the DID
Of course, newborns are just one example of when a DID subject cannot be its own controller. There are dozens more just among humans: elderly parents, dementia patients, refugees, people experiencing homelessness, anyone without digital access. All of these need the concept of digital guardianship (https://sovrin.org/guardian ship/)—a third party who accepts the legal and social responsibility to manage a digital wallet on behalf of a DID subject called the dependent. SSI digital guardianship is a very broad, deep, and rich subject that is explored separately in chapter 11 on governance frameworks.
Digital guardianship only applies to humans, however. What about all the non-human entities in the world? The vast majority are not in a position to issue DIDs either. For example:
-
Organizations of all kinds—Every legal entity in the world that’s not an individual human needs some form of identifier to operate within the law. Today they have business registration numbers, tax ID numbers, domain names, and URLs. Tomorrow they will have DIDs.
-
Human-made things—Virtually everything in the Internet of Things (IoT) can benefit from having one or more DIDs, but relatively few connected things (e.g., smart cars, smart drones) will be smart enough to have their own digital agents and wallets generating their own DIDs (and even then, they will still be controlled by humans). So these human-made entities will have “digital twins” that can be the subject of verifiable credentials. Goods moving through supply chains—especially across borders—are already being assigned verifiable credentials. (See the discussion of VCs in supply chains at https://www.cyber forge.com/attestation-patterns/.)
-
Natural things—Animals, pets, livestock, rivers, lakes, geological formations: not only do these have identities, but in many jurisdictions, they also have at least a limited set of legal rights. So they too can benefit from DIDs.
These represent categories of entities that need third-party controllers—a relationship that has been called controllership to differentiate it from the guardianship of a human being. With guardianship and controllership, we can now extend the benefits of SSI and DPKI to every entity that can be identified.
8.4.2 Beyond PKI benefit 2: Service endpoint discovery
The second added benefit of DIDs is their capacity to enable discovery: i.e., to determine how to interact with a DID subject. To do this, the DID controller publishes one or more service endpoint URLs in a DID document (see listing 8.1 for an example). This three-way binding is shown in figure 8.25.
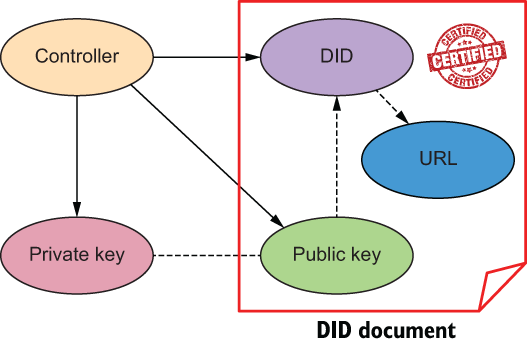
Figure 8.25 The three-way binding between DIDs, public keys, and service endpoint URLs
While this makes DID documents generally useful for many types of discovery, it is essential for discovering the agent endpoints necessary to remotely establish DID-to-DID connections (discussed next) and communicate via the DIDComm protocol (chapter 5). We could say that DID-based discovery of agent endpoint URLs is as essential to SSI as DNS-based discovery of IP addresses is to the web.
8.4.3 Beyond PKI benefit 3: DID-to-DID connections
SSL/TLS is the largest PKI in the world because the public key in an X.509 digital certificate can be used to secure an HTTPS connection between a web server and a browser. In other words, demand for secure e-commerce, e-banking, e-health, and other online transactions drove the growth of the SSL/TLS PKI.
The same will be true for SSI. Because DID documents can include both public keys and service endpoint URLs, every DID represents the opportunity for its controller to create an instant, secure, private, peer-to-peer connection with any other DID controller. Even better, unlike static public key certificates that must be obtained in advance from a CA, DIDs can be generated immediately, locally, on-the-fly as they are needed for new connections. In fact, in table 8.4, we cited one DID method—peer DIDs—created exclusively for this purpose (https://identity.foundation/peer-did-method-spec/index.html).
Originally developed by Daniel Hardman and the Hyperledger Aries community—and now being standardized by a working group at the Decentralized Identity Foundation (https://identity.foundation/working-groups/identifiers-discovery.html)—peer DIDs do not need a blockchain, a distributed ledger, or any other external database. They are generated locally in the DID controller’s digital wallet and exchanged directly, peer-to-peer, using a protocol based on Diffie-Hellman key exchange. This creates a connection between the two parties that is not like any other connection in traditional network architecture. Table 8.6 highlights the five special properties of DID-to-DID connections.
Table 8.6 The five special properties of DID-to-DID connections
Whether between peer DIDs (the default) or public DIDs, DID-to-DID connections are the centerpiece of Layer 2 of the Trust over IP stack described in chapter 5. Agents at this layer communicate using the secure DIDComm protocol in much the same way web browsers and web servers communicate over the secure HTTPS protocol. DIDs “democratize” the SSL/TLS PKI plumbing, so now secure connections can be available to anyone, anytime, anywhere.
8.4.4 Beyond PKI benefit 4: Privacy by design at scale
At this point, it should be obvious how much DIDs can help increase security on the internet. But while security is necessary for privacy, it is not sufficient. Privacy is more than just preventing private information from being snooped or stolen. It ensures that parties with whom you choose to share your private information (doctors, lawyers, teachers, governments, companies from whom you buy products and services) protect that information and do not use or sell it without your permission. So how can DIDs help with that?
The answer may surprise you. Conventional identifiers for people are assigned one time by third parties: government ID numbers, health ID numbers, driving license numbers, mobile phone numbers. When you share these as part of your personal data, they make it easy for you to be tracked and correlated across many different relying parties. They also make it easy for those parties to share information and compile digital dossiers about you.
DIDs turn that whole equation upside down. Rather than you sharing the same ID number with many different relying parties, you can generate and share your own peer DID each time you form a relationship with a new relying party. That relying party will be the only one in the world that knows that DID (and its public key and service endpoint URL). And that relying party will do the same for you.
So rather than you having a single DID, similar to a government-issued ID number, you will have thousands of DIDs—one per relationship. Each pairwise-unique peer DID gives you and your relying party your own permanent private channel connecting the two of you—just as originally envisioned by Philip Zimmermann with PGP. The first advantage of this channel is that you can authenticate each other automatically—in both directions—just by exchanging messages signed by each of your private keys. Spoofing or phishing a relying party with whom you already have a connection becomes next to impossible.
The second significant advantage is that peer DIDs and private channels give you one simple, standard, verifiable way to share signed personal data—personal data for which you have granted specific permissions data to the relying party. On your side, the benefit is convenience and control—at a glance, you can see what you shared with whom and why. On the relying party side, the benefit is fresh, first-person data with cryptographically verifiable, GDPR-auditable consent—plus an easy, secure way to support all the other GDPR-mandated personal data rights (access, rectification, erasure, objection).
The third major benefit is that, with signed data, we can finally protect both individuals and relying on parties from the damage caused by the massive data breaches we read about almost daily (Target, Equifax, Sony, Yahoo, Capital One). What motivates criminals to break into those data silos is the value of that personal data—primarily because the criminals can use it to break into accounts all over the internet.
As those accounts convert to using pairwise peer DIDs and signed personal data, the value of that personal data to anyone but the relying party who has explicit signed permission disappears. If you cannot cryptographically prove you have permission to use the data, then not only does the data become worthless—it becomes toxic. Mere possession of unsigned personal data could become illegal. Like toxic waste, it will be something companies, organizations, and even governments will want to get rid of as quickly as possible.
So now you see why many in the SSI community consider the arrival of DIDs, verifiable credentials, and the Trust over IP stack to be a sea change in privacy on the internet. While we are still in the early stages of implementing this new approach, it can finally give individuals badly needed new tools for controlling the use of their personal data. And this control, when bundled with the rest of the tools in the Trust over IP stack for building and maintaining digital trust, might be a path to putting the privacy genie back in the bottle—a feat that many have believed was impossible.
8.5 The semantic level: What DIDs mean
Having explained how and why DIDs work, we now turn to the lowest level of understanding DIDs: exploring what they mean for the future of SSI and the internet.
8.5.1 The meaning of an address
Addresses do not exist on their own. They only exist in the context of a network that uses them. Whenever we have a new type of address, it is because we have a new type of network that needs this new address to do something that could not be done before. Table 8.7 shows this progression over the past few hundred years.
Table 8.7 An historical perspective on the evolution of addresses for different types of networks
So the real meaning of a DID comes down to what can be done with it on a DID network.
8.5.2 DID networks and digital trust ecosystems
Just as everything on the internet has an IP address—and everything on the web has a URL—everything on a DID network has a DID. But that begs the question: Why does everything on a DID network need a DID? What new communications network functionality do DIDs enable that could not be done before?
The short answer is that DIDs were invented to support both the cryptographic trust and the human trust required for any digital trust ecosystem based on the Trust over IP stack introduced in chapter 5 and shown again in figure 8.26.

Figure 8.26 DIDs are foundational to all four levels of the Trust over IP stack.
DIDs are essential to each layer of the stack as follows:
-
Layer 1: Public DID utilities—DIDs published on public blockchains like Bitcoin and Ethereum; distributed ledgers like Sovrin, ION, Element, and Veres One; or distributed file systems like IPFS can serve as publicly verifiable trust roots for participants at all higher layers. They literally form the foundation of a trust layer for the internet.
-
Layer 2: DIDComm—By definition, DIDComm is a P2P protocol between agents identified by DIDs. By default, these are pairwise pseudonymous peer DIDs issued and exchanged following the Peer DID specification, so they exist only at Layer 2. However, DIDComm can also use public DIDs from Layer 1.
-
Layer 3: Credential exchange—As covered in chapter 7, DIDs are integral to the process of issuing and verifying digitally signed verifiable credentials as well as to the discovery of service endpoint URLs for credential exchange protocols.
-
Layer 4: Digital trust ecosystems—As we will cover in chapter 11, DIDs are the anchor points for discovery and verification of the governance authorities (as legal entities) and governance frameworks (as legal documents) for digital trust ecosystems of all sizes and shapes (as well as for the participants they specify). DIDs also enable verifiable credentials to persistently reference the governance frameworks under which they are issued—and for governance frameworks to reference each other for interoperability.
In short, DIDs are the first widely available, fully standardized identifiers designed explicitly for building and maintaining digital trust networks that are protected by cryptography “all the way down.”
8.5.3 Why isn’t a DID human-meaningful?
Many people have asked, if DIDs are the latest and greatest identifier for the cutting edge of communications on the internet, why aren’t they more human-friendly? The answer lies in a conundrum called Zooko’s triangle, named after Zooko Wilcox-O’Hearn, who coined the term in 2001. (Zooko worked in the 1990s with famous cryptographer David Chaum developing DigiCash and also founded Zcash, a cryptocurrency aimed at using cryptography to provide enhanced privacy for its users.) It is the trilemma illustrated in figure 8.27, which states that an identifier system can achieve at most two of the following three properties:
-
Human-meaningful—Identifiers are semantic names from ordinary human language (and therefore low-entropy by definition).
-
Secure—Identifiers are guaranteed to be unique: each identifier is bound to only one specific entity and cannot easily be spoofed or impersonated.
-
Decentralized—Identifiers can be generated and correctly resolved to the identified entities without using a central authority or service.

Figure 8.27 Zooko’s triangle is a trilemma that proposes an identifier system can have at most two of these three properties
Although some believe Zooko’s triangle can be solved, most internet architects agree it is far easier to achieve two of these three properties than all three. As this chapter makes clear, with DIDs, the two properties chosen were secure and decentralized (the latter being built right into the acronym “DID”). What was given up—due to the cryptographic algorithms used to generate DIDs—was any attempt at being human-meaningful.
But while the SSI community realized that while DIDs alone could not solve the human-meaningful naming problem, they could in fact anchor a promising new solution. The trick was not to do it at the public DID utility layer (Layer 1 of the ToIP stack)—or at the peer DID layer (Layer 2)—but at the verifiable credentials layer (Layer 3). In other words, a specific class of verifiable credentials could assert one or more verifiable names for a DID subject. By creating searchable credential registries for the names in these credentials, we could collectively build a naming layer that is semantically richer, fairer, more trusted, and more distributed than the current DNS naming layer. This is shown in figure 8.28.

Figure 8.28 Verifiable credentials for the human-meaningful names of DID subjects can be layered over machine-friendly DIDs the same way human-meaningful DNS names were layered over machine-friendly IP addresses.
This verifiable naming layer would no longer need to be arbitrarily divided into top-level domain (TLD) name registries but could capture the full richness of human name(s) in any language for any kind of DID subject: person, organization, product, concept, and so on. Furthermore, the authenticity of names—for people, companies, products—could be attested to in a decentralized way by issuers of all kinds, so spoofing or phishing would become an order of magnitude harder than it is in today’s internet Wild West.
8.5.4 What does a DID identify?
We saved this question for last because, from a semantic standpoint, it is the deepest. The easy answer is exactly what it says in the W3C DID Core specification (https://www.w3.org/TR/did-core/): “A DID identifies the DID subject.” And that is completely true, no matter what that subject is: a person, organization, department, physical object, digital object, concept, software program—anything that has identity.
Where confusion may arise is with the DID document that a DID resolves to. Does the DID identify the DID document as a resource?
After much debate, the answer from the W3C DID Working Group was “No.” As an appendix to the DID Core Specification states:
To be very precise, the DID identifies the DID subject and resolves to the DID document (by following the protocol specified by the DID method). The DID document is not a separate resource from the DID subject and does not have a URI separate from the DID. Rather the DID document is an artifact of DID resolution controlled by the DID controller to describe the DID subject.
The same appendix includes figure 8.29 as a visual illustration of this conclusion.

Figure 8.29 A DID always identifies a DID subject (whatever it may be) and resolves to a DID document. The DID document is not a separate resource and does not have a URI separate from the DID.
Note that in figure 8.29, the DID controller and DID subject are shown as separate entities, which may be the case when digital guardianship or controllership is required, as discussed earlier in this chapter. The common case where the DID controller and DID subject are the same entity is shown in figure 8.30.

Figure 8.30 The same diagram as figure 8.29, except the DID controller and DID subject are the same entity
This final point about the semantics of what a DID actually identifies matters because it highlights another key feature of DID identification: DIDs can be used to identify any resource of any kind—whether that resource is on or off the web—and yet always produce the same kind of description of that resource: a DID document. This provides a universal means of cryptographically verifiable resource identification that does not need to rely on any centralized authorities.
Although this is one of the longest chapters in this book, if you’ve read it this far, you now have a much deeper understanding of why we call DIDs “the atomic building block of decentralized digital trust infrastructure.” They are far more than just a new type of globally unique identifier. By relying on cryptography for both generation and verification, DIDs change the internet’s fundamental power dynamics. Instead of scale laws pulling everything into the gravity well of the internet giants at the center, DIDs push power to the very edges—to the individual digital agents and wallets where DIDs are born and DID-to-DID connections are made. This Copernican inversion creates the new spacetime of decentralization: a universe where entities of all kinds can be self-sovereign and interact as peers using all four layers of the Trust over IP stack.
This is why in the next chapter, we move up to Layer 2 of the stack to understand the digital wallets and digital agents required to generate DIDs, form DID-to-DID connections, exchange verifiable credentials, and handle decentralized key management.