
Brent Zundel and Sajida Zouarhi
Cryptography is the fuel that powers all of self-sovereign identity (SSI). The goal of this chapter is to help you be conversant in the basic building blocks of cryptography: hash functions, encryption, digital signatures, verifiable data structures, and proofs, as well as common patterns for how they are combined to create the cryptographic magic SSI delivers. Cryptography as a topic is too broad and complex to summarize in a few pages. We intend this chapter to be a reference and a refresher for those readers who understand the basic cryptographic techniques explained here and an index of what may be studied in more depth for those who have had less exposure to cryptography. Your guides will be two technical cryptographers with direct experience in the SSI space: Brent Zundel, senior cryptography engineer at Evernym, and Sajida Zouarhi, engineer and researcher with ConsenSys. Brent also serves as co-chair of the W3C Decentralized Identifier Working Group that is producing the DID standard (the subject of chapter 8).
To paraphrase the famous philosophical observation, “It is turtles all the way down,” many SSI architects have said, “It is cryptography all the way down.” Modern cryptography uses techniques from mathematics and computer science to secure and authenticate digital communications around the world. Encryption, digital signatures, and hashing are just some of the uses of cryptography that help make SSI possible—and also what make blockchains and distributed ledgers possible. The SSI building blocks introduced in chapter 2 and covered in more detail in the coming chapters, including verifiable credentials (VCs), decentralized identifiers (DIDs), digital wallets and agents, and decentralized key management, rely on these cryptographic techniques.
This chapter is intended to give you a basic understanding of the cryptographic techniques used in SSI infrastructure. While understanding these techniques is not essential to exploring SSI, it will make you more confident in some of the SSI “magic.” The cryptography underlying SSI infrastructure is constructed from five basic building blocks:
6.1 Hash functions
A cryptographic hash is like a unique digital fingerprint of a digital message or document. It is a fixed-length character sequence produced by running the input through a hashing function. Every input document produces a different output hash. If the same hashing function is applied to the same input data, the resulting hash will always be the same. A change of even a single bit of the input data will cause the resulting hash to be different. Table 6.1 shows some examples of hashes using the SHA-256 hash function. (You can try this online using this website or other online resources: https://www.xorbin.com/tools/sha256-hash-calculator.)
Table 6.1 Examples of hashes that use the SHA-256 hash function
|
689f6a627384c7dcb2dcc1487e540223e77bdf9dcd0d8be8a326eda65b0ce9a4 |
|
|
d44aa82c3fbeb2325226755df6566851c959259d42d1259bebdcd4d59c44e201 |
|
|
3b151979d1e61f1e390fe7533b057d13ba7b871b4ee9a2441e31b8da1b49b999 |
The purpose of a hash is not to encode or hide a message, but to verify a message’s integrity. If a document has not been tampered with, its hash will stay the same. For example, hashes are used by software companies when they publish software programs with a corresponding hash. When users download the software, they can verify the integrity of the files by comparing the hash of the software downloaded with the hash provided by the company. If the hashes are the same, the users know that the files have not been tampered with or corrupted—the file received by the user is an exact copy of the file published by the company.
6.1.1 Types of hash functions
Hash functions are an example of a unidirectional function (also called a one-way function). A unidirectional function is a mathematical function that provides a quick and efficient method to perform a calculation, with no known method to reverse the calculation in a reasonable amount of time.
There are many different hash functions, such as MD5 and SHA-256. Hash functions differentiate themselves by some basic characteristics:
-
Efficiency —How fast you can generate a hash, and what the computational cost is.
-
Resistance to preimage —The input of a hash function is called the preimage. Resistance to preimage means that for a given hash, it is very difficult to discover the input. The output of a preimage-resistant hash function appears random and cannot be predicted unless calculated. For example, if given the hash value 689f6a627384c7dcb2dcc1487e540223e77bdf9dcd0d8be8a326eda65b0ce9a4, it would be computationally infeasible to determine that the input was the word “identity.”
-
Resistance to second preimage or collision —Resistance to second preimage means for a given hash, there will be only one preimage. In other words, two different inputs will not produce the same hash. If two inputs produce the same hash, this is known as a collision. A hash function that has resistance to second preimage is also called collision-resistant. For example, a collision-resistant hash function that produces 689f6a627384c7dcb2dcc1487e540223e77bdf9dcd0d8be8a326 eda65b0ce9a as the hash of “identity” will not produce the same output for any other input.
NOTE There are many types of unidirectional functions. A well-known example is the product of two prime integers. Multiplying two large prime numbers is quick and efficient, but reversing that calculation and using the product to find the two input prime numbers is very difficult. This problem is called integer factorization.
Some hash functions, such as MD5 and SHA-1, are no longer considered cryptographically secure. Cryptanalysts have found good attack vectors for these.
SHA-256 (SHA stands for Secure Hash Algorithm) belongs to the family of SHA-2 functions designed by the National Security Agency (NSA) and recognized by the National Institute of Standards and Technology (NIST) in the USA.
6.1.2 Using hash functions in SSI
Hash functions are used as a building block for verifiable data structures and as part of digital signature algorithms, both of which enable necessary components for self-sovereign identity. Blockchains and distributed ledgers, verifiable credentials, and DIDs all rely on cryptographically secure hash functions.
6.2 Encryption
Encryption is a way to hide the content of messages or documents so they can only be read by someone who knows a secret. Early examples of encryption consisted primarily of substitution ciphers and other methods of shuffling text. The secret messages usually relied on some secret method for their security. If an adversary knew the secret method, they could read the secret message. The secret message is also called the ciphertext.
Modern encryption methods no longer rely on keeping the encryption method secret. Instead, the encryption methods are public and well-studied, and the security of the encryption methods is based on the difficulty in solving some underlying problem. This difficulty is known as computational hardness. The secrecy of the ciphertext relies on secret keys. If the encryption methods are computationally hard, and the key is kept secret, the ciphertext will be unreadable for anyone who doesn’t know the secret key.
Cryptography is divided into two families: symmetric-key and asymmetric-key. In symmetric-key cryptography, the secret key used to encrypt messages is the same as the one that is used to decrypt ciphertexts. Symmetric-key cryptography may also be called secret-key encryption.
In asymmetric-key cryptography, there are two keys, one for encrypting messages and the other for decrypting secret messages. Asymmetric-key cryptography has also been called public-key encryption because the key used for encrypting messages is called the public key. The key used for decrypting ciphertexts is called the secret key or private key.
NOTE The intimate relationship of public and private keys to DIDs is explored in great detail in chapter 8.
6.2.1 Symmetric-key cryptography
In symmetric-key cryptography, where the same key is used to encrypt and decrypt, one of the challenges is safely sharing the secret key with the recipient to enable them to decrypt the ciphertext. It follows that some of the most convenient uses of symmetric-key cryptography are when there is no need to share the secret key. For example, if you want to encrypt your hard drive, you can encrypt and decrypt it with the same key.
One other advantage of symmetric-key cryptography is that it is more efficient than public-key cryptography; it provides the same levels of security but uses much smaller keys and much faster computations. One of the best-known algorithms for symmetric-key cryptography is Advanced Encryption Standard (AES). AES uses secret keys of up to 256 bits.1 This is 256 zeros and ones in a random sequence, as in this example:
011101010010101110101111010010101101001000010110101010010011101011111010001 010010010101110100100110100001101100100100101110011011111100111011101110010 101110000101001101100110111110110011001110011101000011100000011010100011111 0001111010101000010010010011111
The size of secret keys is a critical element in determining the security of a cipher. The greater the number of possible keys, the more difficult it is for a computer to discover the valid key through a brute-force attack (an attack based on trying one possible secret key at a time).
6.2.2 Asymmetric-key cryptography
Asymmetric-key cryptography, also known as public-key cryptography, uses a pair of keys, one public, and one secret, as shown in figure 6.1. The keys are related mathematically and are always used in pairs. If one key is used to alter a message, only the other key can change the message back.

Figure 6.1 In this example, Bob uses Alice’s public key to encrypt a message that only Alice will be able to decrypt with her private key.
A secret key must be kept private, but the public key can be shared with the world. Anyone can use a public key to encrypt a message that only someone with the secret key will be able to decrypt. The secret key may also be called the private key.
In many public-key cryptosystems, you use the private key to calculate the public key, but the private key cannot be derived from the public key. The function to derive a public key is another type of unidirectional function.
The private key may be nothing more than a large random number. This secret number is so big that it is nearly impossible to discover with a brute-force attack. Some public-key cryptographic systems include algorithms such as Rivest-Shamir-Adleman (RSA).
To encrypt a message using public-key cryptography, it is necessary to know the recipient’s public key. The public key is used to transform the message into a ciphertext. The ciphertext can only be decrypted back into the message using the associated private key.
DIDs make use of asymmetric-key cryptography. Following the same principle, a DID holder stores private keys for DIDs in their digital wallet, while the public keys for DIDs may be publicly discoverable. Figure 6.2 is an example of the public and private keys that correspond to a DID that uses the Sovrin DID method. (See chapter 8 for more about DIDs.)

Figure 6.2 An example of a DID on the Sovrin DID network. A DID functions as the identifier of a public key on a blockchain or other decentralized network. In most cases, it can also be used to locate an agent for interacting with the entity identified by the DID.
note As of early 2021, the Sovrin DID method is evolving to become one of the Indy DID methods, so the DID prefix will become did:indy:sov.
6.3 Digital signatures
Written or “wet ink” signatures are used every day to verify the authenticity of documents, indicate the signer’s consent, or both. Digital signatures use cryptographic functions to accomplish the same goals. Signing a message means transforming it in some verifiable way using a private key. The transformed message is called a signature. The message is then sent along with the signature to a recipient. The recipient can check the validity of a signature to verify that only the one who knew the private key could have created the signature from the message.
Digital signatures rely on public-key cryptography as described previously. A digital signature is created using the private key of a key pair, and the signature can be verified using the associated public key. The larger the random number used to generate the private key, the harder it is to discover with a brute-force attack. Some public-key cryptographic systems include specific algorithms for digital signatures, such as Elliptic Curve Digital Signature Algorithm (ECDSA).
Digital signatures are used everywhere in SSI infrastructure—across all four layers of the SSI stack described in chapter 5. For example:
-
In Layer 1, they are used for every transaction with a blockchain.
-
In Layer 2, they are used to form DID-to-DID connections and sign every DIDComm message.
-
In Layer 3, they are used to sign every verifiable credential (some VCs contain digital signatures over each individual claim in the credential).
-
In Layer 4, they are used to sign governance framework documents to ensure that they are authentic and to sign VCs issued for assigned roles within a governance framework.
6.4 Verifiable data structures
Cryptography can also be used to create data structures that have specific useful properties for data verification.
6.4.1 Cryptographic accumulators
An accumulator is a single number that represents the result of some computation on a large set of numbers. Someone who knows one of the accumulated values can prove their number is a member of the set or, alternatively, prove their number is not contained in the set. Some accumulators are based on a set of prime numbers, while others are based on a set of elliptic curve points. The benefit of using a cryptographic accumulator is the minimal size of the accumulated value, but there are drawbacks in the size of the data that must be used to generate proofs against the accumulated value.
6.4.2 Merkle trees
One of the most interesting cryptographic data structures was invented by Ralph Merkle in the early days of public-key cryptography. Called a Merkle tree, it provides a very compact and computation-efficient way to verify the integrity of even very large data sets. (Merkle first described the Merkle tree in his 1979 paper “A Certified Digital Signature” and subsequently patented it.) Merkle trees are now a core component of many blockchain and decentralized computing technologies—starting with the Bitcoin protocol based on the blockchain architecture originally described by Satoshi Nakamoto in 2008.
The basic idea of a Merkle tree (also known as a hash tree) is that it can provide proof that a specific item of data—such as a blockchain transaction—exists somewhere within a very large amount of information (for example, the history of all bitcoin transactions) using a mathematical process that results in a single hash called the Merkle root.
To show how a Merkle tree is built, let’s start with a formal definition:
A Merkle tree is a tamper-resistant data structure that allows a large amount of data to be compressed into a single hash and can be queried for the presence of specific elements in the data with a proof constructed in logarithmic space. [1]
This means even though a Merkle tree may contain 1 million pieces of data, proving that any single piece of data is in the tree takes only around 20 calculations.
To build a Merkle tree, a computer will gather the hashes of all the inputs and then group them in pairs—an operation called a concatenation. For example, if you start with 20 inputs, after the first round of concatenation, you will have 10 hashes. Once you repeat the operation, you will have five hashes, then three, then two, and then one.2 This final hash is called the Merkle root. This overall structure is shown in figure 6.3.

Figure 6.3 In a Merkle tree, different transactions are hashed until a unique hash is created for all the transactions included in the tree.
The goal of a structure like this is not to store or transfer the exhaustive set of input data but to save a proof of their existence in a format small enough that it can be easily stored and exchanged between computers.
A computer (such as a node on a blockchain like Bitcoin, which has a local copy of the Merkle tree of all the transactions in a block) can quickly verify that a specific piece of information (for example, a bitcoin transaction) exists within the Merkle tree. To do so, the computer only needs the following proof information:
-
The leaf hash, which is the hash of the piece of information (such as a transaction hash).
-
The hashes along the root path. The root path is the path from leaf to the root—it consists of the sibling hashes needed to compute the hashes on the path all the way from the leaf to the Merkle root.
Instead of having to verify the whole set of transactions, a computer can quickly and efficiently verify just that a certain hash exists in the Merkle tree. This can help ensure data integrity and can also be used in consensus algorithms to reveal if a computer is trying to lie about transactions to its peers.
Merkle trees are used mainly for the following:
-
Storage optimization —For a large volume of information, there’s no need to store the complete data set.
-
Verification speed —Only a few data points are needed for verification, rather than the whole data set.
The key concept that makes the Merkle tree tamper-proof is the hash function’s resistance to a preimage attack: an attack that tries to find the message that has a specific hash value. To put it simply, we can easily verify that a value belongs in a Merkle tree by computing the resulting hash for each level in the path all the way down to the Merkle root. However, we cannot find the inputs that were used to generate a specific hash. Hashing is a unidirectional function, which means it is computationally infeasible to retrieve the original inputs from a hash.
6.4.3 Patricia tries
We have seen the value of Merkle trees for protocols (e.g., the Bitcoin protocol). Building on this concept, we now focus on another interesting cryptographic data structure called a Patricia trie. (The word trie comes from reTRIEval.) Instead of hashes, these tries are constituted of regular alphanumeric strings. But first, what is a trie, and why do we need tries in SSI?
A radix trie (or compact prefix trie) is a data structure that looks like a hierarchical tree structure with a root value and subtrees of children with a parent node, represented as a set of linked nodes. The subtlety of radix tries is that the nodes don’t store any information; they are only there to indicate a location in the trie where there is a split in the string of characters. Because it knows the key, an algorithm knows how to reassemble the previous prefixes (edge labels), leading to that position in the trie. Figure 6.4 shows an example using a set of dictionary words.
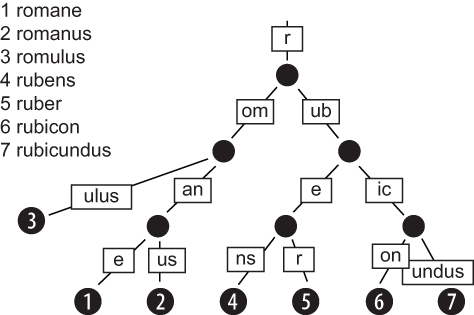
Figure 6.4 In a radix trie, nodes don’t store any information; they are indicators of a location in a trie. The algorithm goes through the trie and walks a path called the key to find the word. If we take the node in position 6 as the key and run through the trie as the algorithm would (from top to bottom), we reconstitute the word “rubicon.”
The acronym PATRICIA stands for “Practical Algorithm To Retrieve Information Coded In Alphanumeric.” (Donald R. Morrison first described what he called Patricia trees in 1968.) A Patricia trie is a variant of the trie we just saw; however, instead of explicitly storing every bit of every key, the nodes store only the position of the first bit, which differentiates two subtrees. This makes a Patricia trie more compact than a standard binary trie and thus faster at finding common prefixes and lighter in terms of storage.
6.4.4 Merkle-Patricia trie: A hybrid approach
Merkle trees and Patricia tries can be used in combination to create data structures in different ways depending on the aspect a protocol needs to optimize, such as speed, memory efficiency, or code simplicity. A particularly interesting combination example is the modified Merkle Patricia trie (MPT) [2] found in the Ethereum protocol (https://ethereum.github.io/yellowpaper/paper.pdf#appendix.D). MPT also forms the basis of the architecture for the Hyperledger Indy distributed ledger discussed in chapter 5—a codebase designed for use in SSI infrastructure.
All MPT nodes have a hash value called a key. Key-values are paths on the MPT, just as we saw with the radix trie in figure 6.4.
MPT offers a cryptographically authenticated data structure that can be used to store key-value bindings in a fully deterministic way. This means when you are provided with the same starting information, you will get the same trie with a O(log(n)) efficiency.
6.5 Proofs
A proof is a way of using cryptography to demonstrate that a computational fact is true. For example, Patricia tries let you prove that a large set of data is correct without storing the entire set. They are very useful for blockchains because instead of storing past transactions for 24 hours, for example, you only need to store new “proof information” on-chain. The rest of the data can be securely stored off-chain. No one can tamper with the data without it being evident to the rest of the network.
Note On-chain transactions are reflected on a public ledger and are visible to all participants on the blockchain network. Off-chain transactions are transfer agreements between two or more parties.
Hybrid systems that combine on-chain and off-chain capabilities are used to overcome some blockchain limitations (e.g., scalability, privacy). This is particularly useful for applications such as SSI, where there is frequently the need to protect private information by keeping it off-chain. Hybrid systems enable software architects to have the best of both worlds.
A digital signature, as discussed previously, is also a form of proof. Anyone with knowledge of the public key but no knowledge of the private key can prove that a specific signature was indeed generated by someone having prior knowledge of the corresponding private key. The prover, who signs, can prove to the verifier possession of knowledge of information (the private key) without revealing any information about the key: only the message and the signature.
6.5.1 Zero-knowledge proofs
Now imagine if it were possible to also keep the signature and parts of the signed message secret. The only thing revealed would be the parts of the message that were disclosed and that the prover knew the signature. This is the goal of zero-knowledge proof (ZKP) cryptography.
A ZKP needs to have the following three properties [3]:
-
Completeness —“If the statement is really true and both users follow the rules properly, then the verifier would be convinced without any artificial help.”
-
Soundness —“In case of the statement being false, the verifier would not be convinced in any scenario.” (The method is probabilistically checked to ensure that the probability of falsehood is equal to zero.)
-
Zero-knowledge —“The verifier in every case would not know any more information.”
Properties 1 and 2 are needed for all interactive proof systems, such as digital signature proofs. Property 3 is what makes the proof “zero-knowledge.”
As explained in chapter 5 and in much more detail in chapter 8, zero-knowledge digital signatures are used with some verifiable credential systems. Other ZKPs that have emerged are the zk-S*ARK family of arithmetic-circuit based proof systems:
-
zk-SNARK (optimized for privacy and consensus) —This is a zero-knowledge succinct non-interactive argument of knowledge. It is used in blockchain protocols such as Zcash to hide the information relative to the sender and recipient of a transaction and the amount of the transaction itself, while at the same time allowing this transaction to be verified by the network and confirmed to the blockchain.
-
zk-STARK (optimized for scalability and transparency) —This form of ZKP, introduced by Eli Ben-Sasson, provides proofs that can be verified much faster by scaling exponentially relative to the data set they are representing.
6.5.2 ZKP applications for SSI
ZKPs can be very useful to prove information regarding an individual’s credentials without having to fully disclose other sensitive personal identity information. Every scenario where we need to prove that a person has the right to access a service without disclosing more personal data than necessary is a potential application for a ZKP. In the following sections, we will look at a number of specific examples in SSI.
Concerns about privacy are driving significant changes in the way data is gathered, stored, and used. News coverage of continual data breaches has led to growing public unease about the lack of security around personal information, while political controversy has triggered alarm about the collection and sale of personal information without full and clear individual consent.
If personal data is less generally available, identity theft and fraud can be reduced. The best way to do this is if people—”data subjects” in terms of data-protection regulations like the EU General Data Protection Regulation (GDPR)—have an easy, practical way to exercise personal control over what information they need to reveal to access online resources.
With conventional public/private key cryptography, a digital signature is every bit as correlatable as a public key. Zero-knowledge cryptographic methods do not reveal the actual signature. Instead, they only reveal a cryptographic proof of a valid signature. Only the holder of the signature has the information needed to present the credential to a verifier. This means ZKP signatures do not increase correlation risk for the signer and automatically protect the signer from impersonation.
Selective disclosure means you don’t have to reveal all of the attributes (claims) contained in a credential. For example, if you only need to prove your name, you should not need to disclose your address or telephone number. Similarly, verifiers shouldn’t have to collect more data than is necessary to complete a transaction. Selective disclosure is not just a privacy boon for individuals; it also reduces a verifier’s liability for handling or holding personal data they do not need.
Note The term selective disclosure is used in both the privacy community and the financial community. In the privacy community, it has the positive meaning discussed in this section. See https://www.privacypatterns.org/patterns/Support-Selective-Disclosure. In the financial community, it has a negative meaning: a publicly traded company disclosing material information to a single person or a limited group of people or investors, as opposed to disclosing the information to all investors at the same time.
Zero-knowledge cryptography allows a credential holder to choose which attributes to reveal and which attributes to withhold on a case-by-case basis—without the need to involve the issuer of the credential in any way. Furthermore, for every attribute in a credential, ZKP gives you two selective disclosure options:
-
Prove that the attribute exists in the credential, but do not reveal its value.
-
Reveal the value of an attribute without revealing any other attributes.
A predicate proof is a proof that answers a true-or-false question about the value of an attribute. For example, if a car rental company requires proof that you are old enough to rent a car, it doesn’t need to know your exact birthdate. It just needs a verifiable answer to the question, “Are you over the age of 18?”
Using zero-knowledge methods, predicate proofs are generated by the credential holder at the time of presentation to a verifier and without the issuer’s involvement. For example, a credential with the attributes name, birthdate, and address can be used in a presentation to reveal your name and prove you are over the age of 18 while withholding everything else. The same credential could then be used in a different presentation to reveal just your address and proof that you are over the age of 25 while never revealing your birthdate.
Another benefit of ZKP-based verifiable credentials is that proofs can be produced across any set of credentials in a holder’s wallet. The verifier does not need to ask for a specific attribute in the context of a specific credential from a specific issuer. However, the verifier can still do that if they need to—in other words, specify that an attribute must be from a specific credential and/or issuer. The ability to simply ask for proof of a set of attributes across all ZKP-based credentials in a holder’s wallet makes life much easier for verifiers and also significantly promotes selective disclosure.
There are many reasons a credential may need to be revoked by the issuer: the data has changed, the holder no longer qualifies, the credential has been misused, or the credential was mis-issued. Regardless of the reason, if a credential is revocable, verifiers need to be able to determine the credential’s current revocation status.
As explained earlier in this chapter, zero-knowledge methods such as cryptographic accumulators enable the verifier to confirm that a credential is not revoked without revealing the list of revoked credentials (which could have serious privacy implications). The holder can produce a proof of non-revocation, and the verifier can check this proof against the revocation registry on a public ledger. If the credential is not revoked, the proof will validate. If the credential is revoked, the proof will fail. But the verifier is never able to determine any other information from the cryptographic accumulator. This reduces the ability of network monitors to correlate a holder’s credential presentations.
Correlation is the ability to link data from multiple interactions to a single user. Correlation can be performed by a verifier, by issuers and verifiers working together, or by a third party observing interactions on the network. Unauthorized correlation is when a party collects data about a user without the user’s consent or knowledge. This includes a party who deanonymizes private transactions. For example, say a person uses a credential to prove their legal identity so they are authorized to vote in an election. The person then submits a secret ballot that is supposed to be anonymized. If it is possible to deanonymize the voting data and correlate the person’s credential with the secret ballot, the vote could be linked to a specific voter. This is a clear violation of the democratic process as it could enable retaliation and other negative consequences.
One way to reduce correlation is through data minimization: sharing only the information required to complete a transaction, as discussed earlier in the “Selective disclosure” and “Predicate proofs” sections.
A second way to reduce correlation is to avoid using the same globally unique identifiers across multiple transactions. Globally unique identifiers such as government ID numbers, mobile phone numbers, and reusable public keys make it easy for an observer to link multiple interactions to a single user. ZKPs avoid this linkability by producing unique proofs for every transaction.
Correlation can never be eliminated completely—and intentional correlation is sometimes a business requirement (such as when searching criminal records). The goal of zero-knowledge methods is to reduce the probability of unintentional correlation and put control over the level of correlation into the credential holder’s hands.
6.5.3 A final note about proofs and veracity
As previously discussed, a verifiable credential is “verifiable” because it contains one or more cryptographic proofs that can be verified as being true. Some VC proofs are composed of many different smaller proofs. For example, if I wanted to prove the value of my first name based on a claim on a digital birth certificate signed by the government, I would also need to prove the following:
Even with these proofs, the verifier still needs to determine whether they trust that the government didn’t make a mistake. In other words, even after I’ve proven the integrity of the credential (i.e., that it hasn’t changed, is about me, and was issued by the government to me), the verifier still has no guarantees about the veracity of the data in the credential (i.e., whether it is true—some also use the term validity), beyond the level of their trust in the issuer (this is another place where governance frameworks come into play; see chapter 11).
This applies throughout all uses of cryptography. For example, if the information sent to a blockchain network is not verified prior to its storage, then false information is being stored in an immutable blockchain (“garbage in, garbage out”). The presumption that information is correct simply because it is encrypted is dangerous, particularly if it is fed to other cryptographic components, such as smart contracts, without raising an error in the system.
The point is that the cryptographic properties used in blockchain technology can’t help the system know what is true and what is false, only what is stored and when. Cryptography is fundamental to SSI because it enables data to be verified for integrity or traceability, but not veracity or validity. Regardless of how cutting-edge or complicated a cryptographic proof may be, it can still only prove a computational fact about data. It cannot prove facts about the real world—only humans can do that (at least, until we start to have very advanced artificial intelligence).
However, cryptographic proofs can help humans make some decisions about veracity and validity. For example, certain kinds of proofs can enable non-repudiation—the property that when someone performs a cryptographically verifiable operation, they can’t afterward claim that they did not make that operation, some other entity did. Non-repudiation also prevents someone from adding or deleting information about someone else without their permission. So non-repudiable proofs help increase the accountability of humans for their digital interactions.
In this chapter, we have shown that blockchain technology was the dawn of SSI because it proved that cryptography could be deployed at scale in highly decentralized systems with extremely strong security properties. SSI takes the next step in harnessing that cryptography to prove digital facts about the identities and attributes of the participants in an SSI ecosystem. Every layer of the SSI architecture described in chapter 5 uses the cryptographic structures—hash functions, encryption, digital signatures, verifiable data structures, and proofs—described in this chapter.
In the next chapter, we will dive into the core data structure enabled by all this cryptography—the “carrier of trust” across the trust triangle—verifiable credentials.
References
1. Hackage. 2018. “Merkle-Tree: An Implementation of a Merkle Tree and Merkle Tree Proofs of Inclusion.” http://hackage.haskell.org/package/merkle-tree.
2. Kim, Kiyun. 2018. “Modified Merkle Patricia Trie—How Ethereum Saves a State.” CodeChain. https://medium.com/codechain/modified-merkle-patricia-trie-how-ethereum-saves-a-state-e6d7 555078dd.
3. Goldwasser, S., S. Micali, and C. Rackoff. 2018. “The Knowledge Complexity of Interactive Proof Systems.” SIAM Journal of Computing 18 (1), 186-208. https://dl.acm.org/citation.cfm?id=63434.
1. This means 2^256 possible combinations of zeros and ones. The number of possible 256-bit keys is 115,792,089,237,316,195,423,570,985,008,687,907,853,269,984,665,640,564,039,457,584,007,913,129,639,936.
2. Since 5 is an odd number, the fifth element is duplicated (we now have six elements) and grouped with itself; hence the resulting three hashes in the next round. The same process repeats with the third element in this round. It is duplicated (we now have four elements) and grouped with itself to result in two hashes in the next round.