
Chapter 12. Fault Handling
Fault Exception Overview
In ARM processors, when a program goes wrong and if the processor detects the fault, a fault exception occurs. On the Cortex-M0 processor, there is only one exception type that handles faults: the hard fault handler.
The hard fault handler is almost the highest priority exception type, with a priority level of −1. Only the Nonmaskable interrupt (NMI) can preempt it. When it is executed, we know that the microcontroller is in trouble and corrective action is needed. The hard fault handler is also useful for debugging during the software development stage. When a breakpoint has been set in the hard fault handler, the program execution stops when a fault occurs. By examining the content of the stack, we can back trace the location of the fault and try to identify the reason for the failure.
This behavior is very different from that of most 8-bit and 16-bit microcontrollers. In these microcontrollers, often the only safety net is a watchdog timer. However, it takes time for a watchdog timer to be triggered, and often there is no way to tell how the program went wrong.
What Can Cause a Fault?
There are a number of possible reasons for a fault to occur. For the Cortex-M0 processor, we can group these potential causes into two areas, as described in Table 12.1.
| Fault Classification | Fault Condition |
|---|---|
| Memory related | • Bus error (can be program accesses or data accesses, also referred to as bus faults in Cortex-M3) Bus error generated by bus infrastructure because of an invalid address during bus transaction Bus error generated by bus slave • Attempt to execute the program from a memory region marked as nonexecutable (see the discussion of memory attributes in Chapter 7) |
| Program error (also referred to as usage faults in the Cortex-M3) | • Execution of undefined instruction • Trying to switch to ARM state (Cortex-M0 only supports Thumb instructions) • Attempt to generate an unaligned memory access (not allowed in ARMv6-M) • Attempt to execute an SVC when the SVC exception priority level is the same or lower than the current exception level • Invalid EXC_RETURN value during exception return • Attempt to execute a breakpoint instruction (BKPT) when debug is not enabled (no debugger attached) |
For memory-related faults, the error response from the bus system can also have a number of causes:
• The address being accessed is invalid.
• The bus slave cannot accept the transfer because the transfer type is invalid (depending on bus slave).
• The bus slave cannot access the transfer because it is not enabled or initialized (for example, a microcontroller might generate an error response if a peripheral is accessed but the clock for the peripheral bus is turned off).
When the direct cause of the hard fault exception is located, it might still take some effort to locate the source of the problem. For example, a bus error fault can be caused by an incorrect pointer manipulation, a stack memory corruption, a memory overflow, an incorrect memory map setup, or other reasons.
Analyze a Fault
Depending on the type of fault, often it is straightforward to locate the instruction that caused the hard fault exception. To do that we need to know the register contents when the hard fault exception is entered and the register contents that were pushed to the stack just before the hard fault handler started. These values include the return program address, which usually tells us the instruction address that caused the fault.
If a debugger is available, we can start by creating a hard fault exception handler, with a breakpoint instruction that halts the processor. Alternatively, we can use the debugger to set a breakpoint to the beginning of the hard fault handler so that the processor halts automatically when a hard fault is entered. After the processor is halted because of a hard fault, we can then try to locate the fault by the flow shown in Figure 12.1.
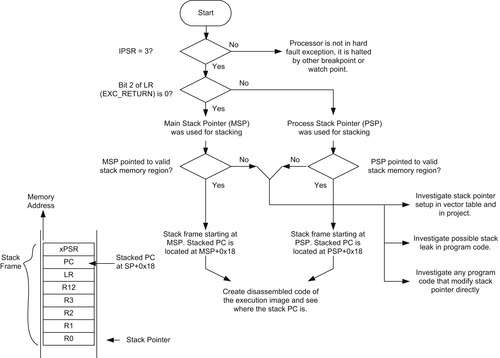
To aid the analysis, we should also generate a disassembly listing of the compiled image and locate the fault using the stacked PC value found on the stack frame. If the faulting address is a memory access instruction, you should also check the register value (or stacked register value) to see if the memory access operated on the right address. In addition to checking the address range, we should also verify that the memory address is aligned correctly.
Apart from the stacked PC (return address) value, the stack frame also contains other stacked register values that can be useful for debugging. For example, the stacked IPSR (within the xPSR) indicates if the processor was running an exception, and the stacked EPSR shows the processor state (if the T bit of EPSR is 0, the fault is caused by accidentally switching to ARM state).
The stacked LR might also provide information like the return address of the faulting function, or if the fault happened within an exception handler, or whether the value of the EXC_RETURN was accidentally corrupted.
Also, the current register values can provide various types of information that can help identify the cause of a fault. Apart from the current stack pointer values, the current Link Register (R14) value might also be useful. If the LR shows an invalid EXC_RETURN value, it could mean that the value of LR was modified incorrectly during a previous exception handler.
The CONTROL register can also be useful. In simple applications without an OS, the processor stack pointer (PSP) is not used and the CONTROL register should always be zero in such cases. If the CONTROL register value was set to 0x2 (PSP is used in Thread state), it could mean LR was modified incorrectly during a previous exception handler, or a stack corruption has taken place that resulted in an incorrect value for EXC_RETURN to be used.
Accidental Switching to ARM State
A number of common program errors that cause hard faults are related to the accidental switching to ARM state. Usually this can be detected by checking the values of the stacked xPSR. If the T (Thumb) bit is cleared, then the fault was caused by an accidental switching to ARM state.
Table 12.2 describes the common errors that cause this problem.
Error Handling in Real Applications
In real applications, the embedded systems will be running without a debugger attached and stopping the processor is not acceptable for many applications. In most cases, the hard fault exception handler can be used to carry out safety actions and then reset the processor. For example, the following steps can be carried out:
• Perform application specific safety actions (e.g., performance shut-down sequence in a motor controller)
Because a hard fault could be caused by an error in the stack pointer value, a hard fault handler programmed in C language might not be able to perform correctly, as C-generated code might require stack memory to operate. Therefore, for safety-critical systems, ideally the hard fault handler should be programmed in assembly language, or use an assembly language wrapper to make sure that the stack pointer is in valid memory range before entering a C routine.
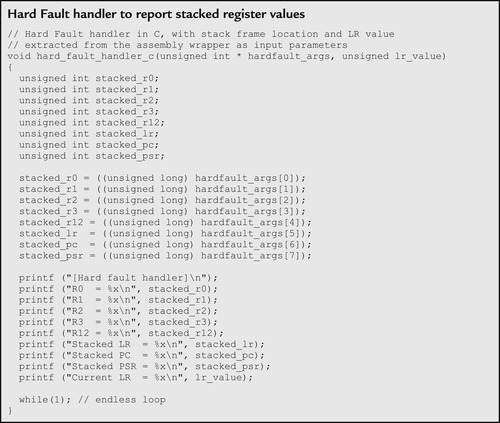
If a hard fault handler is written in C to report debug information like faulting a program address to a terminal display, we will also need an assembly wrapper (Figure 12.2). The wrapper code extracts the address of the exception stack frame and passes it on to the C hard fault handler for displaying. Otherwise, there is no easy way to locate the stack frame inside the C handler—although you can access the stack pointer value using inline assembly, embedded assembly, a named register variable, or an intrinsic function, the value of the stack pointer could have been changed by the C function itself.

The assembly code for such an assembly wrapper can be implemented using embedded assembly, for example:

The handler in C accepts the parameters from the assembly wrapper and extracts the stack frame contents and LR values:
 |
The C handler can only work if the stack is still in a valid memory region because it tries to extract debug information from the stack, and the program codes generated from C compilers often require stack memory. Alternatively, you can carry out the debug information reporting entirely in assembly code. Doing this in assembly language is relatively easy when you have an assembly routine for text output ready. Examples of assembly text outputting routines can be found in Chapter 16. Details about embedded assembly programming (used in the assembly wrapper) can also be found in that chapter.
Lockup
The Cortex-M0 processor can enter a lockup state if another fault occurs during the execution of a hard fault exception handler or when a fault occurs during the execution of an NMI handler. This is because when these two exception handlers are executing, the priority level does not allow the hard fault handler to preempt.
During the lockup state, the processor stops executing instructions and asserts a LOCKUP status signal. Depending on the implementation of the microcontroller, the LOCKUP status signal can be programmed to reset the system automatically, rather than waiting for a watchdog timer to time out and reset the system.
The lockup state prevents the failed program from corrupting more data in the memory or data in the peripherals. During software development, this behavior can help us debug the problem, as the memory contents might contain vital clues about how the software failed.
Causes of Lockup
A number of conditions can cause lockup in the Cortex-M0 processor (or ARMv6-M architecture):
• A fault occurred during the execution of the NMI handler
• A fault occurred during the execution of the hard fault handler (double fault)
• There was an SVC execution inside the NMI handler or the hard fault handler (insufficient priority)
• A bus error response during reset sequence (initial SP value)
• There was a bus fault during the unstacking of the xPSR during the exception return using the main stack pointer (MSP) for the unstacking
Besides fault conditions, the use of an SVC in an NMI or hard fault handler can also cause a lockup because the SVC priority level is always lower than these handlers and therefore blocked. Because this program error cannot be handled by the hard fault exception (the priority level is already −1 or −2), the system enters lockup state.
The lockup state can also be caused by a bus system error during the reset sequence. When the first two words of the memory are fetched and if a bus fault happens in one of these accesses, it means the processor cannot determine the initial stack pointer value (the hard fault handler might need the stack as well), or the reset vector is unknown. In these cases, the processor cannot continue normal operation and must enter a lockup state.
If a bus error response occurs at exception, entrance (stacking) does not cause a lockup, even it is entering hard fault or entering NMI exception (Figure 12.3). However, once the hard fault exception or NMI exception handlers are entered, a bus error response can cause lockup. As a result, in safety-critical systems, a hard fault handler written in C might not be the best arrangement because the C compiler might insert stack operations right at the beginning of the handler code:

HardFault_Handler
PUSH {R4, R5} ; This can cause lock up if the MSP is corrupted
...
For an exception exit (unstacking), it is possible to cause a lockup if a bus error response is received during the unstacking process of the xPSR using MSP. In such cases, the xPSR cannot be determined and therefore the correct priority level of the system is unknown. As a result, the system is locked up and cannot be recovered apart from resetting it or halting it for debug.
What Happens during a Lockup?
If the lockup is caused by a double fault, the priority level of the system stays at −1. If an NMI exception has occurred, it is possible for the NMI to preempt and execute. After the NMI is completed, the exception handler is terminated and the system returns to lockup state.
Preventing Lockup
Lockup and hard fault exceptions might look scary to some embedded developers, but embedded systems can go wrong for various reasons and the lockup and hard fault mechanisms can be used to keep the problem from getting worse. Various sources of errors or problems can cause an embedded system to crash in any microcontrollers, for example:
• Unstable power supply or electromagnetic interferences
• Flash memory corruption
• An error in external interface signals
• Component damage that results from operating conditions or the natural aging process
• An incorrect clock generation arrangement or poor clock signal quality
• Software errors
The hard fault and lockup behaviors allow error conditions to be detected and help debugging. Although we cannot fully prevent all the potential issues listed, we can take various measures in software to improve the reliability of an embedded system.
First, we should keep the NMI exception handler and hard fault exception handler as simple as possible. Some tasks associated with the NMI exception or hard fault exception can be separated into a different exception like PendSV and executed after the urgent parts of the exception handling have completed. By making the NMI and hard fault handler shorter and easier to understand, we can also reduce the risk of accidentally using SVC instructions in these handlers (this can be caused by calling a function which contains an SVC instruction).
Second, for safety-critical applications, you might want to use an assembly wrapper to check the SP value before entering the hard fault handler in C (Figure 12.4).
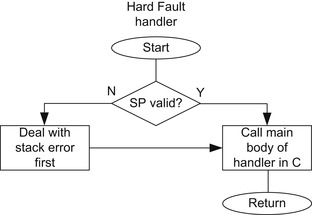
If necessary, we can program the entire hard fault handler in assembly. In such cases, we can avoid some stack memory accesses to prevent lockup if the stack pointer is corrupted and pointing to an invalid memory location.
Similarly, if the NMI handler is simple, we can program the NMI handler in assembly language and use just R0 to R3 and R12 if we want to avoid stack memory accesses because these registers are already stacked. But in most cases, a stack pointer error would be likely to trigger the hard fault exception fairly quickly, so there is no need to worry about programming the NMI in C language.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.