
7
The Rise of Suprahuman Transformers with GPT-3 Engines
In 2020, Brown et al. (2020) described the training of an OpenAI GPT-3 model containing 175 billion parameters that learned using huge datasets such as the 400 billion byte-pair-encoded tokens extracted from Common Crawl data. OpenAI ran the training on a Microsoft Azure supercomputer with 285,00 CPUs and 10,000 GPUs.
The machine intelligence of OpenAI’s GPT-3 engines and their supercomputer led Brown et al. (2020) to zero-shot experiments. The idea was to use a trained model for downstream tasks without further training the parameters. The goal would be for a trained model to go directly into multi-task production with an API that could even perform tasks it wasn’t trained for.
The era of suprahuman cloud AI engines was born. OpenAI’s API requires no high-level software skills or AI knowledge. You might wonder why I used the term “suprahuman.” You will discover that a GPT-3 engine can perform many tasks as well as a human in many cases. For the moment, it is essential to understand how GPT models are built and run to appreciate the magic.
This chapter will first examine the architecture and the evolution of the size of the transformer model. We will investigate the zero-shot challenge of using trained transformer models with little to no fine-tuning of the model’s parameters for downstream tasks. We will explore the innovative architecture of GPT transformer models. OpenAI provides specially trained versions of their models named engines.
We will use a 345M parameter GPT-2 transformer in TensorFlow from OpenAI’s repository. We must get our hands dirty to understand GPT models. We will interact with the model to produce text completion with general conditioning sentences.
We will continue by using a 117M parameter customized GPT-2 model. We will tokenize the high-level conceptual Kant dataset we used to train the RoBERTa model in Chapter 4, Pretraining a RoBERTa Model from Scratch.
The chapter will then explore using a GPT-3 engine that does not require a data scientist, an artificial specialist, or even an experienced developer to get started. However, that does not mean that a data scientist or an AI specialist will not be required down the line.
We will see that GPT-3 engines do sometimes require fine-tuning. We will run a Google Colab notebook to fine-tune a GPT-3 Ada engine.
The chapter will end with the new mindset and skillset of an Industry 4.0 AI specialist.
By the end of the chapter, you will know how a GPT model is built and how to use a seamless GPT-3 API. You will understand the gratifying tasks an Industry 4.0 AI specialist can accomplish in the 2020s!
This chapter covers the following topics:
- Getting started with a GPT-3 model
- The architecture of OpenAI GPT models
- Defining zero-shot transformer models
- The path from few-shots to one-shot
- Building a near-human GPT-2 text completion model
- Implementing a 345M parameter model and running it
- Interacting with GPT-2 with a standard model
- Training a language modeling GPT-2 117M parameter model
- Importing a customized and specific dataset
- Encoding a customized dataset
- Conditioning the model
- Conditioning a GPT-2 model for specific text completion tasks
- Fine-tuning a GPT-3 model
- The role of an Industry 4.0 AI specialist
Let’s begin our journey by exploring GPT-3 transformer models.
Suprahuman NLP with GPT-3 transformer models
GPT-3 is built on the GPT-2 architecture. However, a fully trained GPT-3 transformer is a foundation model. A foundation model can do many tasks it wasn’t trained for. GPT-3 completion applies all NLP tasks and even programming tasks.
GPT-3 is one of the few fully trained transformer models that qualify as a foundation models. GPT-3 will no doubt lead to more powerful OpenAI models. Google will produce foundation models beyond the Google BERT version they trained on their supercomputers. Foundation models represent a new way of thinking about AI.
It will not take long for companies to realize they do not need a data scientist or an AI specialist to start an NLP project with an API like the one that OpenAI provides.
Why bother with any other tool? An OpenAI API is available with access to one of the most efficient transformer models trained on one of the most powerful supercomputers in the world.
Why develop tools, download libraries, or use any other tool if an API exists that only deep pockets and the best research teams in the world can design, such as Google or OpenAI?
The answer to these questions is quite simple. It’s easy to start a GPT-3 engine, just as it is to start a Formula 1 or Indy 500 race car. No problem. But then, trying to drive such a car is nearly impossible without months of training! GPT-3 engines are powerful AI race cars. You can get them to run in a few clicks. However, mastering their incredible horsepower requires the knowledge you have acquired from the beginning of this book up to now and what you will discover in the following chapters!
We first need to understand the architecture of GPT models to see where developers, AI specialists, and data scientists fit in the era of suprahuman NLP models.
The architecture of OpenAI GPT transformer models
Transformers went from training, to fine-tuning, and finally to zero-shot models in less than three years between the end of 2017 and the first part of 2020. A zero-shot GPT-3 transformer model requires no fine-tuning. The trained model parameters are not updated for downstream multi-tasks, which opens a new era for NLP/NLU tasks.
In this section, we will first learn about the motivation of the OpenAI team that designed GPT models. We will begin by going through the fine-tuning of zero-shot models. Then we will see how to condition a transformer model to generate mind-blowing text completion. Finally, we will explore the architecture of GPT models.
We will first go through the creation process of the OpenAI team.
The rise of billion-parameter transformer models
The speed at which transformers went from small models trained for NLP tasks to models that require little to no fine-tuning is staggering.
Vaswani et al. (2017) introduced the Transformer, which surpassed CNNs and RNNs on BLEU tasks. Radford et al. (2018) introduced the Generative Pre-Training (GPT) model, which could perform downstream tasks with fine-tuning. Devlin et al. (2019) perfected fine-tuning with the BERT model. Radford et al. (2019) went further with GPT-2 models.
Brown et al. (2020) defined a GPT-3 zero-shot approach to transformers that does not require fine-tuning!
At the same time, Wang et al. (2019) created GLUE to benchmark NLP models. But transformer models evolved so quickly that they surpassed human baselines!
Wang et al. (2019, 2020) rapidly created SuperGLUE, set the human baselines much higher, and made the NLU/NLP tasks more challenging. Transformers are rapidly progressing, and some have already surpassed Human Baselines on the SuperGLUE leaderboards at the time of writing.
How did this happen so quickly?
We will look at one aspect, the models’ sizes, to understand how this evolution happened.
The increasing size of transformer models
From 2017 to 2020 alone, the number of parameters increased from 65M parameters in the original Transformer model to 175B parameters in the GPT-3 model, as shown in Table 7.1:
|
Transformer Model |
Paper |
Parameters |
|
Transformer Base |
Vaswani et al. (2017) |
65M |
|
Transformer Big |
Vaswani et al. (2017) |
213M |
|
BERT-Base |
Devlin et al. (2019) |
110M |
|
BERT-Large |
Devlin et al. (2019) |
340M |
|
GPT-2 |
Radford et al. (2019) |
117M |
|
GPT-2 |
Radford et al. (2019) |
345M |
|
GPT-2 |
Radford et al. (2019) |
1.5B |
|
GPT-3 |
Brown et al. (2020) |
175B |
Table 7.1: The evolution of the number of transformer parameters
Table 7.1 only contains the main models designed during that short time. The dates of the publications come after the date the models were actually designed. Also, the authors updated the papers. For example, once the original Transformer set the market in motion, transformers emerged from Google Brain and Research, OpenAI, and Facebook AI, which all produced new models in parallel.
Furthermore, some GPT-2 models are larger than the smaller GPT-3 models. For example, the GPT-3 Small model contains 125M parameters, which is smaller than the 345M parameter GPT-2 model.
The size of the architecture evolved at the same time:
- The number of layers of a model went from 6 layers in the original Transformer to 96 layers in the GPT-3 model
- The number of heads of a layer went from 8 in the original Transformer model to 96 in the GPT-3 model
- The context size went from 512 tokens in the original Transformer model to 12,288 in the GPT-3 model
The architecture’s size explains why GPT-3 175B, with its 96 layers, produces more impressive results than GPT-2 1,542M, with only 40 layers. The parameters of both models are comparable, but the number of layers has doubled.
Let’s focus on the context size to understand another aspect of the rapid evolution of transformers.
Context size and maximum path length
The cornerstone of transformer models resides in the attention sub-layers. In turn, the key property of attention sub-layers is the method used to process context size.
The context size is one of the main ways humans and machines can learn languages. The larger the context size, the more we can understand a sequence presented to us.
However, the drawback of context size is the distance it takes to understand what a word refers to. The path taken to analyze long-term dependencies requires changing from recurrent to attention layers.
The following sentence requires a long path to find what the pronoun “it” refers to:
“Our house was too small to fit a big couch, a large table, and other furniture we would have liked in such a tiny space. We thought about staying for some time, but finally, we decided to sell it.”
The meaning of “it” can only be explained if we take a long path back to the word “house” at the beginning of the sentence. That’s quite a path for a machine!
The order of function that defines the maximum path length can be summed up as shown in Table 7.2 in Big O notation:
|
Layer Type |
Maximum Path Length |
Context Size |
|
Self-Attention |
0(1) |
1 |
|
Recurrent |
0(n) |
100 |
Table 7.2: Maximum path length
Vaswani et al. (2017) optimized the design of context analysis in the original Transformer model. Attention brings the operations down to a one-to-one token operation. The fact that all of the layers are identical makes it much easier to scale up the size of transformer models. A GPT-3 model with a size 100 context window has the same maximum length path as a size 10 context window.
For example, a recurrent layer in an RNN has to store the total length of the context step by step. The maximum path length is the context size. The maximum length size for an RNN that would process the context size of a GPT-3 model would be 0(n) times longer. Furthermore, an RNN cannot split the context into 96 heads running on a parallelized machine architecture, distributing the operations over 96 GPUs, for example.
The flexible and optimized architecture of transformers has led to an impact on several other factors:
- Vaswani et al. (2017) trained a state-of-the-art transformer model with 36M sentences. Brown et al. (2020) trained a GPT-3 model with 400 billion byte-pair-encoded tokens extracted from Common Crawl data.
- Training large transformer models requires machine power that is only available to a small number of teams in the world. It took a total of 2.14*1023 FLOPS for Brown et al. (2020) to train GPT-3 175B.
- Designing the architecture of transformers requires highly qualified teams that can only be funded by a small number of organizations in the world.
The size and architecture will continue to evolve and probably increase to trillion-parameter models in the near future. Supercomputers will continue to provide the necessary resources to train transformers.
We will now see how zero-shot models were achieved.
From fine-tuning to zero-shot models
From the start, OpenAI’s research teams, led by Radford et al. (2018), wanted to take transformers from trained models to GPT models. The goal was to train transformers on unlabeled data. Letting attention layers learn a language from unsupervised data was a smart move. Instead of teaching transformers to do specific NLP tasks, OpenAI decided to train transformers to learn a language.
OpenAI wanted to create a task-agnostic model. So they began to train transformer models on raw data instead of relying on labeled data by specialists. Labeling data is time-consuming and considerably slows down the transformer’s training process.
The first step was to start with unsupervised training in a transformer model. Then, they would only fine-tune the model’s supervised learning.
OpenAI opted for a decoder-only transformer described in the Stacking decoder layers section. The metrics of the results were convincing and quickly reached the level of the best NLP models of fellow NLP research labs.
The promising results of the first version of GPT transformer models soon led Radford et al. (2019) to come up with zero-shot transfer models. The core of their philosophy was to continue training GPT models to learn from raw text. They then took their research a step further, focusing on language modeling through examples of unsupervised distributions:
Examples=(x1, x2, x3, ,xn)
The examples are composed of sequences of symbols:
Sequences=(s1, s2, s3, ,sn)
This led to a metamodel that can be expressed as a probability distribution for any type of input:
p (output/input)
The goal was to generalize this concept to any type of downstream task once the trained GPT model understands a language through intensive training.
The GPT models rapidly evolved from 117M parameters to 345M parameters, to other sizes, and then to 1,542M parameters. 1,000,000,000+ parameter transformers were born. The amount of fine-tuning was sharply reduced. The results reached state-of-the-art metrics again.
This encouraged OpenAI to go further, much further. Brown et al. (2020) went on the assumption that conditional probability transformer models could be trained in-depth and were able to produce excellent results with little to no fine-tuning for downstream tasks:
p (output/multi-tasks)
OpenAI was reaching its goal of training a model and then running downstream tasks directly without further fine-tuning. This phenomenal progress can be described in four phases:
- Fine-Tuning (FT) is meant to be performed in the sense we have been exploring in previous chapters. A transformer model is trained and then fine-tuned on downstream tasks. Radford et al. (2018) designed many fine-tuning tasks. The OpenAI team then reduced the number of tasks progressively to
0in the following steps. - Few-Shot (FS) represents a huge step forward. The GPT is trained. When the model needs to make inferences, it is presented with demonstrations of the task to perform as conditioning. Conditioning replaces weight updating, which the GPT team excluded from the process. We will be applying conditioning to our model through the context we provide to obtain text completion in the notebooks we will go through in this chapter.
- One-Shot (1S) takes the process further. The trained GPT model is presented with only one demonstration of the downstream task to perform. No weight updating is permitted either.
- Zero-Shot (ZS) is the ultimate goal. The trained GPT model is presented with no demonstration of the downstream task to perform.
Each of these approaches has various levels of efficiency. The OpenAI GPT team has worked hard to produce these state-of-the-art transformer models.
We can now explain the motivations that led to the architecture of the GPT models:
- Teaching transformer models how to learn a language through extensive training.
- Focusing on language modeling through context conditioning.
- The transformer takes the context and generates text completion in a novel way. Instead of consuming resources on learning downstream tasks, it works on understanding the input and making inferences no matter what the task is.
- Finding efficient ways to train models by masking portions of the input sequences forces the transformer to think with machine intelligence. Thus, machine intelligence, though not human, is efficient.
We understand the motivations that led to the architecture of GPT models. Let’s now have a look at the decoder-layer-only GPT model.
Stacking decoder layers
We now understand that the OpenAI team focused on language modeling. Therefore, it makes sense to keep the masked attention sublayer. Hence, the choice to retain the decoder stacks and exclude the encoder stacks. Brown et al. (2020) dramatically increased the size of the decoder-only transformer models to get excellent results.
GPT models have the same structure as the decoder stacks of the original Transformer designed by Vaswani et al. (2017). We described the decoder stacks in Chapter 2, Getting Started with the Architecture of the Transformer Model. If necessary, take a few minutes to go back through the architecture of the original Transformer.
The GPT model has a decoder-only architecture, as shown in Figure 7.1:
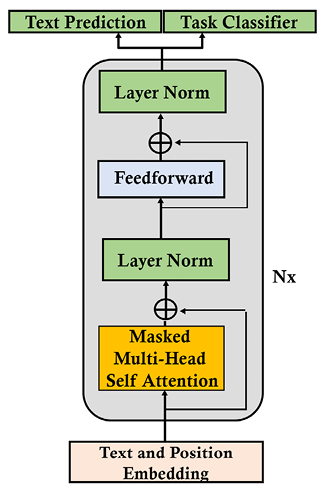
Figure 7.1: GPT decoder-only architecture
We can recognize the text and position embedding sub-layer, the masked multi-head self-attention layer, the normalization sub-layers, the feedforward sub-layer, and the outputs. In addition, there is a version of GPT-2 with both text prediction and task classification.
The OpenAI team customized and tweaked the decoder model by model. Radford et al. (2019) presented no fewer than four GPT models, and Brown et al. (2020) described no fewer than eight models.
The GPT-3 175B model has reached a unique size that requires computer resources that few teams in the world can access:
nparams = 175.0B, nlayers = 96, dmodel = 12288, nheads = 96
Let’s look into the growing number of GPT-3 engines.
GPT-3 engines
A GPT-3 model can be trained to accomplish specific tasks of different sizes. The list of engines available at this time is documented by OpenAI: https://beta.openai.com/docs/engines
The base series of engines have different functions – for example:
- The Davinci engine can analyze complex intent
- The Curie engine is fast and has good summarization
- The Babbage engine is good at semantic search
- The Ada engine is good at parsing text
OpenAI is producing more engines to put on the market:
- The Instruct series provides instructions based on a description. An example is available in the More GPT-3 examples section of this chapter.
- The Codex series can translate language to code.
- The Content filter series filters unsafe or sensitive text. We will explore this series in Chapter 16, The Emergence of Transformer-Driven Copilots.
We have explored the process that led us from fine-tuning to zero-shot GPT-3 models. We have seen that GPT-3 can produce a wide range of engines.
It is now time to see how the source code of GPT models is built. Although the GPT-3 transformer model source code is not publicly available at this time, GPT-2 models are sufficiently powerful to understand the inner workings of GPT models.
We are ready to interact with a GPT-2 model and train it.
We will first use a trained GPT-2 345M model for text completion with 24 decoder layers with self-attention sublayers of 16 heads.
We will then train a GPT-2 117M model for customized text completion with 12 decoder layers with self-attention layers of 12 heads.
Let’s start by interacting with a pretrained 345M parameter GPT-2 model.
Generic text completion with GPT-2
We will explore an example with a GPT-2 generic model from top to bottom. The goal of the example we will run is to determine the level of abstract reasoning a GPT model can attain.
This section describes the interaction with a GPT-2 model for text completion. We will focus on Step 9 of the OpenAI_GPT_2.ipynb notebook described in detail in Appendix III, Generic Text Completion with GPT-2.
You can first read this section to see how the generic pretrained GPT-2 model will react to a specific example. Then read Appendix III, Generic Text Completion with GPT-2, to go into the details of how a generic GPT-2 model is implemented in a Google Colab notebook.
You can also read Appendix III directly, which contains the interaction of Step 9 described below.
First, let’s understand the specific example of the pretrained GPT-2 being applied.
Step 9: Interacting with GPT-2
In this section, we will interact with the GPT-2 345M model.
To interact with the model, run the interact_model cell:
#@title Step 9: Interacting with GPT-2
interact_model('345M',None,1,1,300,1,0,'/content/gpt-2/models')
You will be prompted to enter some context:

Figure 7.2: Context input for text completion
You can try any type of context you wish since this is a standard GPT-2 model.
We can try a sentence written by Immanuel Kant:
Human reason, in one sphere of its cognition, is called upon to
consider questions, which it cannot decline, as they are presented by
its own nature, but which it cannot answer, as they transcend every
faculty of the mind.
Press Enter to generate text. The output will be relatively random since the GPT-2 model was not trained on our dataset, and we are running a stochastic model anyway.
Let’s have a look at the first few lines the GPT model generated at the time I ran it:
"We may grant to this conception the peculiarity that it is the only causal logic.
In the second law of logic as in the third, experience is measured at its end: apprehension is afterwards closed in consciousness.
The solution of scholastic perplexities, whether moral or religious, is not only impossible, but your own existence is blasphemous."
To stop the cell, double-click on the run button of the cell.
You can also press Ctrl + M to stop generating text, but it may transform the code into text, and you will have to copy it back into a program cell.
The output is rich. We can observe several facts:
- The context we entered conditioned the output generated by the model.
- The context was a demonstration of the model. It learned what to say from the context without modifying its parameters.
- Text completion is conditioned by context. This opens the door to transformer models that do not require fine-tuning.
- From a semantic perspective, the output could be more interesting.
- From a grammatical perspective, the output is convincing.
Can we do better? The following section presents the interaction of custom text completion.
Training a custom GPT-2 language model
We will continue our top-to-bottom approach in this section by exploring an example with a GPT-2 custom model that we will train on a specific dataset. The goal remains to determine the level of abstract reasoning a GPT model can attain.
This section describes the interaction with a GPT-2 model for text completion trained on a specific dataset. We will focus on Step 12 of the Training_OpenAI_GPT_2.ipynb notebook described in detail in Appendix IV, Custom Text Completion with GPT-2.
You can read this section first to see how an example with a custom GPT-2 model will improve responses. Then read Appendix IV, Custom Text Completion with GPT-2, to understand how to train a GPT-2 to obtain specific responses.
You can also decide to read Appendix IV directly, which also contains the interaction of Step 12 described below.
First, let’s understand how the interaction with GPT-2 improved by training it.
Step 12: Interactive context and completion examples
We will now run a conditional sample. The context we enter will condition the model to think as we want it to, to complete the text by generating tailor-made paragraphs.
Run the cell and explore the magic:
#@title Step 12: Interactive Context and Completion Examples
import os # import after runtime is restarted
os.chdir("/content/gpt-2/src")
!python interactive_conditional_samples.py --temperature 0.8 --top_k 40 --model_name '117M'
If necessary, take a few minutes to go back to Step 9, Interacting with GPT-2 of Appendix III, Generic Text Completion with GPT-2, to see the differences in the responses. The program prompts us to enter the context:

Figure 7.3: Context input for text completion
Let’s enter the same paragraph written by Immanuel Kant as we did in Step 9 of the Generic text completion with GPT-2 section of this chapter:
Human reason, in one sphere of its cognition, is called upon to
consider questions, which it cannot decline, as they are presented by
its own nature, but which it cannot answer, as they transcend every
faculty of the mind.
Press Enter to generate text as we did previously. Though structured and logical, the outputs might change from one run to another, making transformers attractive. This time, the result is not random and is impressive.
Let’s look at the first few lines the GPT-2 model produced:
"Now, what is the nature of the reason, except that it is of a kind and power of mind that is so called on to think, and to understand?
The reason is the thing which apprehends, and seeks to understand, the objects of its minds, which apprehend and apprehend the things of itself. No one can speak of this reason without the understanding and the understanding of the human reason. But that knowledge and understanding which is the most natural of all the faculties, which, because it is understood by the human reason, is the most natural of all the faculties, is not without reason, but only without understanding. The human reason, who sees and knows the things which the natural sense, which, though in the natural sense, does not understand, is the source of every other knowledge which we understand. The reason is the thing which does not understand, but understands the things which we comprehend, and therefore, is not to be understood. I mean that the reason is the thing which does not understand, but knows only the things which we do understand…."
To stop the cell, double-click on the run button of the cell or press Ctrl + M.
Wow! I doubt anybody could see the difference between the text completion produced by our trained GPT-2 model and a human. It might also generate different outputs at each run.
In fact, I think our model could outperform many humans in this abstract exercise in philosophy, reason, and logic!
We can draw some conclusions from our experiment:
- A well-trained transformer model can produce text completion at a human level
- A GPT-2 model can almost reach human level in text generation on complex and abstract reasoning
- Text context is an efficient way of conditioning a model by demonstrating what is expected
- Text completion is text generation based on text conditioning if context sentences are provided
You can enter conditioning text context examples to experiment with text completion. You can also train the model on your own data. Just replace the content of the dset.txt file with your own data and see what happens!
Remember that our trained GPT-2 model will react like a human. If you enter a short, incomplete, uninteresting, or tricky context, you will obtain puzzled or bad results. This is because GPT-2 expects the best out of us, as in real life!
Let’s go to the GPT-3 playground to see how a trained GPT-3 reacts to the example tested with GPT-2.
Running OpenAI GPT-3 tasks
In this section, we will run GPT-3 in two different ways:
- We will first run the GPT-3 tasks online with no code
- We will then implement GPT-3 in Google Colab notebook
We will be using GPT-3 engines in this book. When you sign up for the GPT-3 API, OpenAI gives you a free budget to get started. This free budget should cover most of the cost, if not all of the cost, of running the examples in this book once or twice.
Let’s begin by running NLP tasks online.
Running NLP tasks online
We will now go through some Industry 4.0 examples without an API, directly asking GPT-3 to do something for us.
Let us define a standard structure of a prompt and response as:
- N = name of the NLP task (INPUT).
- E = explanation for the GPT-3 engine. E precedes T (INPUT).
- T = the text or content we wish GPT-3 to look into (INPUT).
- S = showing GPT-3 what is expected. S follows T and is added when necessary (INPUT).
- R = GPT-3’s response (OUTPUT).
The structure of the prompt described above is a guideline. However, GPT-3 is very flexible, and many variations are possible.
We are now ready to run some educational examples online with no API:
- Questions and answers (Q&A) on existing knowledge:
E =
QT =
Who was the president of the United States in 1965?S = None
R =
APrompts and responses:
Q: Who was the president of the United States in 1965?A: Lyndon B. Johnson was president of the United States in 1965.Q: Who was the first human on the moon?A: Neil Armstrong was the first human on the moon. - Movie to Emoji:
E = Some examples of movie titles
T = None
S = Implicit through examples
R = Some examples of emojis
Prompts and responses:

A new prompt and response:

- Summarizing for a second grader (Summarize for a 2nd grader):
E =
My second grader asked me what this passage means:T =
"""The initial conclusions…."""S =
I rephrased it for him, in plain language a second grader can understand: """R = The summary
Prompt and response:
My second grader asked me what this passage means:""" The initial conclusions can be divided into two categories: facts and fiction. The facts are that OpenAI has one of the most powerful NLP services in the world. The main facts are: OpenAI engines are powerful zero-shot that require no hunting for all kinds of transformer models, no pre-training, and no fine-tuning. The supercomputers used to train the models are unique. If the prompt is well-designed, we obtain surprisingly accurate responses. Implementing the NLP tasks in this section required a copy and paste action that any software beginner can perform. Fiction begins with dystopian and hype assertions AI will replace data scientists and AI specialists. Is that true? Before answering that question, first ask yourself the following questions about the example we just ran: How do we know the sentence was incorrect in the first place? How do we know the answer is correct without us humans reading and confirming this? How did the engine know it was a grammar correction task? If the response is incorrect, how can we understand what happened to help improve the prompt or revert to manual mode in a well-designed human interface? The truth is that humans will need to intervene to answers these questions manually, with rule-bases, quality control automated pipelines, and many other tools. The facts are convincing. It is true that running an NLP task requires little development. The fiction is not convincing. Humans are still required. OpenAI engines are not there to replace humans but to help them perform more high-level gratifying tasks. You can now fly a jet without having to build it! """I rephrased it for him, in plain language a second grader can understand: """The first conclusion is that OpenAI has one of the most powerful NLP services in the world. The most important facts are: OpenAI engines are very powerful zero-shot that require no hunting for all kinds of transformer models, no pre-training, and no fine-tuning. The supercomputers used to train the models are unique. If the prompt is well-designed, we get surprisingly accurate responses.
The results are impressive and a huge step forward in the history of NLP.
The number of NLP tasks we can implement with the zero-shot GPT-3 engines provided by OpenAI is endless since we control how we show what we expect of the transformer models.
However, a true Industry 4.0 AI guru must get their hands dirty before implementing ready-to-use APIs. We will now explore the architecture of OpenAI GPT models and then build GPT-2 models to see how these engines work.
The more we know about GPT models, the better an Industry 4.0 NLP expert can implement them in real-life projects.
Let’s continue our top-to-bottom approach and drill down into the architecture of OpenAI GPT transformer models.
Getting started with GPT-3 engines
OpenAI has some of the most powerful transformer engines in the world. One GPT-3 model can perform hundreds of tasks. GPT-3 can do many tasks it wasn’t trained for.
This section will use the API in Getting_Started_GPT_3.ipynb.
To use a GPT-3, you must first go to OpenAI’s website, https://openai.com/, and sign up.
OpenAI has a playground for everybody to try, just like Google Translate or any user-friendly online service. So, let’s try some tasks.
Running our first NLP task with GPT-3
Let’s start using GPT-3 in a few steps.
Go to Google Colab and open Getting_Started_GPT_3.ipynb, which is the chapter directory of the book on GitHub.
You do not need to change the settings of the notebook. We are using an API, so we will not need much local computing power for the tasks in this section.
The steps of this section are the same ones as in the notebook.
Running an NLP is done in three simple steps:
Step 1: Installing OpenAI
Install openai using the following command:
try:
import openai
except:
!pip install openai
import openai
If openai is not installed, you must restart the runtime. A message will indicate when to do this, as shown in the following output:

Restart the runtime and then run this cell again to make sure openai is imported.
Step 2: Entering the API key
An API key is given that can be used with Python, C#, Java, and many other options. We will be using Python in this section:
openai.api_key=[YOUR API KEY]
You can now update the next cell with your API key:
import os
import openai
os.environ['OPENAI_API_KEY'] ='[YOUR_KEY or KEY variable]'
print(os.getenv('OPENAI_API_KEY'))
openai.api_key = os.getenv("OPENAI_API_KEY")
Let’s now run an NLP task.
Step 3: Running an NLP task with the default parameters
We copy and paste an OpenAI example for a grammar correction task:
response = openai.Completion.create(
engine="davinci",
prompt="Original: She no went to the market.
Standard American English:",
temperature=0,
max_tokens=60,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0,
stop=["
"]
)
The task is to correct this grammar mistake: She no went to the market.
We can process the response as we wish by parsing it. OpenAI’s response is a dictionary object. The OpenAI object contains detailed information on the task. We can ask the object to be displayed:
#displaying the response object
print(response)
We can explore the object:
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": " She didn't go to the market."
}
],
"created": 1639424815,
"id": "cmpl-4ElZfXLl9jGRNQoojWRRGof8AKr4y",
"model": "davinci:2020-05-03",
"object": "text_completion"}
The “created” number and “id”, and “model” name can vary with each run.
We can then ask the object dictionary to display "text" and to print the processed output:
#displaying the response object
r = (response["choices"][0])
print(r["text"])
The output of “text" in the dictionary is the grammatically correct sentence:
She didn't go to the market.
NLP tasks and examples
Now we will cover an industrial approach to GPT-3 engine usage. For example, OpenAI provides an interactive educational interface that does not require an API. So a school teacher, a consultant, a linguist, a philosopher, or anybody that wishes to use a GPT-3 engine for educational purposes can do so with no experience at all in AI.
We will first begin by using an API in a notebook.
Grammar correction
If we go back to Getting_Started_GPT_3.ipynb, which we began to explore in the Getting started with GPT-3 engines section of this chapter, we can experiment with grammar correction with different prompts.
Open the notebook and go to Step 4: Example 1: Grammar correction:
#Step 6: Running an NLP task with custom parameters
response = openai.Completion.create(
#defult engine: davinci
engine="davinci",
#default prompt for task:"Original"
prompt="Original: She no went to the market.
Standard American English:",
temperature=0,
max_tokens=60,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0,
stop=["
"]
)
The request body is not limited to the prompt. The body contains several key parameters:
engine="davinci". The choice of the OpenAI GPT-3 engine to use and possibly other models in the future.temperature=0. A higher value such as0.9will force the model to take more risks. Do not modify the temperature andtop_pat the same time.max_tokens=60. The maximum number of tokens of the response.top_p=1.0. Another way to control sampling liketemperature. In this case, thetop_ppercentage of tokens of the probability mass will be considered.0.2would make the system only take 20% of the top probability mass.frequency_penalty=0.0. A value between0and1limits the frequency of tokens in a given response.presence_penalty=0.0. A value between0and1forces the system to use new tokens and produce new ideas.stop=[" "]. A signal to the model to stop producing new tokens.
Some of these parameters are described at the source code level in the Steps 7b-8: Importing and defining the model section of Appendix III, Generic Text Completion with GPT-2.
You can play around with these parameters in the GPT-3 model if you gain access or in the GPT-2 model in Appendix III, Generic Text Completion with GPT-2. The concepts are the same in both cases.
This section will focus on the prompt:
prompt="Original: She no went to the market.
Standard American English:"
The prompt can be divided into three parts:
Original: This signals to the model that what follows is the original text, which the model will do something withShe no went to the market.: This part of the prompt shows the model that this is the original textStandard American English: This shows the model what task is expected
Let’s see how far we can get by changing the task:
- Standard American English produces:
prompt="Original: She no went to the market. Standard American English:"The text in response is:
"text": " She didn't go to the market."That is fine, but what if we do not want a contraction in the sentence?
- English with no contractions produces:
prompt="Original: She no went to the market. English with no contractions:"The text in response is:
"text": " She did not go to the market."Wow! This is impressive. Let’s try another language.
- French with no contractions produces:
"text": " Elle n'est pas allu00e9e au marchu00e9."This is impressive.
u00e9simply needs to be post-processed intoé.
Many more options are possible. Your Industry 4.0 cross-disciplinary imagination is the limit!
More GPT-3 examples
OpenAI contains many examples. OpenAI provides an online playground to explore tasks. OpenAI also provides source code for each example: https://beta.openai.com/examples
Just click on an example such as the grammar example we explored in the Grammar correction section:

Figure 7.4: The Grammar correction section of OpenAI
OpenAI will describe the prompt and the sample response for each task.
Figure 7.5: The sample response corrects the prompt
You can choose to go to the playground and run it online as we did in this chapter’s Running NLP tasks online section. To do so, click on the Open in Playground button:

Figure 7.6: The Open in Playground button
You can choose to copy and paste the code to run the API as we are doing in the Google Colab notebook of this chapter:
Figure 7.7: Running code using the Davinci engine
Getting_Started_GPT_3.ipynb contains ten examples that you can run to practice implementing the OpenAI GPT-3.
For each example:
- You can first read the link to the explanation provided by OpenAI. A link to the documentation is provided above each cell.
- You can then run the cell to observe GPT-3’s behavior.
Run these ten examples in the notebook:
- Example 1: Grammar correction
- Example 2: English-to-French translation
- Example 3: Instruct series that provides instructions
- Example 4: Movie to emoji
- Example 5: Programming language to another language. For example, Python to JavaScript.
- Example 6: Advanced tweet classifier
- Example 7: Q&A
- Example 8 Summarize a text
- Example 9: Parse unstructured data
- Example 10: Calculate time complexity
You can run many other tasks on the Examples page: https://beta.openai.com/examples
Let’s now compare the output of GPT-2 and GPT-3.
Comparing the output of GPT-2 and GPT-3
Our curiosity must be satisfied before we move on. What can the powerful GPT-3 model produce with the example we submitted to a pretrained GPT-2 model and then our custom-trained GPT-2 model?
Our example used for the GPT-2 model:
Human reason, in one sphere of its cognition, is called upon to consider questions, which it cannot decline, as they are presented by its own nature, but which it cannot answer, as they transcend every faculty of the mind.
GPT-3's response:
What is meant by this is that there are some things in our experience that are beyond reason. It is not that reason is a bad guide or is insufficient, but that there are some things that are beyond its reach. An example of this would be the existence of God.
The result is mind-blowing! It explains what the text means, including some deep philosophical reflections!
We have proven our point in this chapter. Transformer models can attain to abstract reasoning, which can help make micro-decisions in our fast-moving world.
OpenAI GPT-3 is a fully trained model. However, GPT-3 can be fine-tuned. Let’s see how.
Fine-tuning GPT-3
This section shows how to fine-tune GPT-3 to learn logic. Transformers need to learn logic, inferences, and entailment to understand language at a human level.
Fine-tuning is the key to making GPT-3 your own application, to customizing it to make it fit the needs of your project. It’s a ticket to AI freedom to rid your application of bias, teach it things you want it to know, and leave your footprint on AI.
In this section, GPT-3 will be trained on the works of Immanuel Kant using kantgpt.csv. We used a similar file to train the BERT-type model in Chapter 4, Pretraining a RoBERTa Model from Scratch.
Once you master fine-tuning GPT-3, you can use other types of data to teach it specific domains, knowledge graphs, and texts.
OpenAI provides an efficient, well-documented service to fine-tune GPT-3 engines. It has trained GPT-3 models to become different types of engines, as seen in the The rise of billion-parameter transformer models section of this chapter.
The Davinci engine is powerful but can be more expensive to use. The Ada engine is less expensive and produces sufficient results to explore GPT-3 in our experiment.
Fine-tuning GPT-3 involves two phases:
- Preparing the data
- Fine-tuning a GPT-3 model
Preparing the data
Open Fine_Tuning_GPT_3.ipynb in Google Colab in the GitHub chapter directory.
OpenAI has documented the data preparation process in detail:
https://beta.openai.com/docs/guides/fine-tuning/prepare-training-data
Step 1: Installing OpenAI
Step 1 is to install and import openai:
try:
import openai
except:
!pip install openai
import openai
Restart the runtime once the installation is complete and run the cell again to make sure import openai has been executed
import openai
You can also install wandb to visualize the logs:
try:
import wandb
except:
!pip install wandb
import wandb
We will now enter the API key
Step 2: Entering the API key
openai.api_key="[YOUR_KEY]"
Step 3: Activating OpenAI’s data preparation module
First, load your file. In this section, load kantgpt.csv. Now, kantgpt.csv. is a raw unstructured file. OpenAI has an inbuilt data cleaner that will ask questions at each step.
OpenAI detects that the file is a CSV file and will convert it to a JSONL file. JSONL contains lines in plain structured text.
OpenAI tracks all the changes we approve:
Based on the analysis we will perform the following actions:
- [Necessary] Your format 'CSV' will be converted to 'JSONL'
- [Necessary] Remove 27750 rows with empty completions
- [Recommended] Remove 903 duplicate rows [Y/n]: y
- [Recommended] Add a suffix separator ' ->' to all prompts [Y/n]: y
- [Recommended] Remove prefix 'completion:' from all completions [Y/n]: y
- [Recommended] Add a suffix ending '
' to all completions [Y/n]: y
- [Recommended] Add a whitespace character to the beginning of the completion [Y/n]: y
OpenAI saves the converted file to kantgpt_prepared.jsonl.
We are ready to fine-tune GPT-3.
Fine-tuning GPT-3
You can split the notebook into two separate notebooks: one for data preparation and one for fine-tuning.
Step 4: Creating an OS environment
Step 4 in the fine-tuning process creates an os environment for the API key:
import openai
import os
os.environ['OPENAI_API_KEY'] =[YOUR_KEY]
print(os.getenv('OPENAI_API_KEY'))
Step 5: Fine-tuning OpenAI’s Ada engine
Step 5 triggers fine-tuning the OpenAI Ada engine with the JSONL file that was saved after data preparation:
!openai api fine_tunes.create -t "kantgpt_prepared.jsonl" -m "ada"
OpenAI has many requests.
If your steam is interrupted, OpenAI will indicate the instruction to continue fine-tuning. Execute fine_tunes.follow instruction:
!openai api fine_tunes.follow -i [YOUR_FINE_TUNE]
Step 6: Interacting with the fine-tuned model
Step 6 is interacting with the fine-tuned model. The prompt is a sequence that is close to what Immanuel Kant might say:
!openai api completions.create -m ada:[YOUR_MODEL INFO] "Several concepts are a priori such as"
The instruction to run a completion task with [YOUR_MODEL INFO] is often displayed by OpenAI at the end of your fine-tune task. You can copy and paste it in a cell(add "!" to run the command line) or insert your [YOUR_MODEL INFO] in the following cell.
The completion is quite convincing:
Several concepts are a priori such as the term freedom and the concept of _free will_.substance
We have fine-tuned GPT-3, which shows the importance of understanding transformers and designing AI pipelines with APIs. Let’s see how this changes the role of AI specialists.
The role of an Industry 4.0 AI specialist
In a nutshell, the role of an Industry 4.0 developer is to become a cross-disciplinary AI guru. Developers, data scientists, and AI specialists will progressively learn more about linguistics, business goals, subject matter expertise, and more. An Industry 4.0 AI specialist will guide teams with practical cross-disciplinary knowledge and experience.
Human experts are mandatory in three domains when implementing transformers:
- Morals and ethics
An Industry 4.0 AI guru ensures moral and ethical practices are enforced when implementing humanlike transformers. European regulations, for example, are strict and require that automated decisions be explained to the users when necessary. The US has anti-discrimination laws to protect citizens from automated bias.
- Prompts and responses
Users and UI developers will need Industry 4.0 AI gurus to explain how to create the right prompts for NLP tasks, show a transformer model how to do a task, and verify the response.
- Quality control and understanding the model
What happens when the model does not behave as expected even after tweaking its hyperparameters? We will go deeper into such issues in Chapter 14, Interpreting Black Box Transformer Models.
Initial conclusions
The initial conclusions can be divided into two categories: facts and fiction.
One fact is that OpenAI has one of the most powerful NLP services in the world. Other facts include:
- OpenAI engines are powerful zero-shot engines that require no hunting for all kinds of transformer models, no pre-training, and no fine-tuning
- The supercomputers used to train the models are unique
- If a prompt is well designed, we can get surprisingly accurate responses
- Implementing the NLP tasks in this chapter only required a copy and paste action that any software beginner can perform
Many people believe AI will replace data scientists and AI specialists. Is that true? Before answering that question, first, ask yourself the following questions about the examples we ran in this chapter:
- How do we know if a sentence is incorrect?
- How do we know an answer is correct without us humans reading and confirming this?
- How did the engine know it was a grammar correction task?
- If a response is incorrect, how can we understand what happened to help improve the prompt or revert to manual mode in a well-designed human interface?
The truth is that humans will need to intervene to answers these questions manually, with rule bases, quality controlled automated pipelines, and many other tools.
The facts are convincing. Running an NLP task with a transformer requires little development in many cases.
Humans are still required. OpenAI engines are not there to replace humans but to help them perform more high-level gratifying tasks. You can now fly a jet without having to build it!
We need to answer the exciting questions we brought up in this section. So let’s now explore your new fascinating Industry 4.0 role on a wonderful path into the future of AI!
Let’s sum up the chapter and move on to the next exploration!
Summary
In this chapter, we discovered the new era of transformer models training billions of parameters on supercomputers. OpenAI’s GPT models are taking NLU beyond the reach of most NLP development teams.
We saw how a GPT-3 zero-shot model performs many NLP tasks through an API and even directly online without an API. The online version of Google Translate has already paved the way for mainstream online usage of AI.
We explored the design of GPT models, which are all built on the original transformer’s decoder stack. The masked attention sub-layer continues the philosophy of left-to-right training. However, the sheer power of the calculations and the subsequent self-attention sub-layer makes it highly efficient.
We then implemented a 345M parameter GPT-2 model with TensorFlow. The goal was to interact with a trained model to see how far we could get with it. We saw that the context provided conditioned the outputs. However, it did not reach the results expected when entering a specific input from the Kant dataset.
We trained a 117M parameter GPT-2 model on a customized dataset. The interactions with this relatively small trained model produced fascinating results.
We ran NLP tasks online with OpenAI’s API and fine-tuned a GPT-3 model. This chapter showed that the fully pretrained transformers and their engines can automatically accomplish many tasks with little help from engineers.
Does this mean that users will not need AI NLP developers, data scientists, and AI specialists anymore in the future? Instead, will users simply upload the task definition and input text to cloud transformer models and download the results?
No, it doesn’t mean that at all. Industry 4.0 data scientists and AI specialists will evolve into pilots of powerful AI systems. They will be increasingly necessary to ensure the inputs are ethical and secure. These modern-age AI pilots will also understand how transformers are built and adjust the hyperparameters of an AI ecosystem.
In the next chapter, Applying Transformers to Legal and Financial Documents for AI Text Summarization, we will take transformer models to their limits as multi-task models and explore new frontiers.
Questions
- A zero-shot method trains the parameters once. (True/False)
- Gradient updates are performed when running zero-shot models. (True/False)
- GPT models only have a decoder stack. (True/False)
- It is impossible to train a 117M GPT model on a local machine. (True/False)
- It is impossible to train the GPT-2 model with a specific dataset. (True/False)
- A GPT-2 model cannot be conditioned to generate text. (True/False)
- A GPT-2 model can analyze the context of an input and produce completion content. (True/False)
- We cannot interact with a 345M-parameter GPT model on a machine with less than 8 GPUs. (True/False)
- Supercomputers with 285,000 CPUs do not exist. (True/False)
- Supercomputers with thousands of GPUs are game-changers in AI. (True/False)
References
- OpenAI and GPT-3 engines: https://beta.openai.com/docs/engines/engines
BertVizGitHub Repository by Jesse Vig: https://github.com/jessevig/bertviz- OpenAI’s supercomputer: https://blogs.microsoft.com/ai/openai-azure-supercomputer/
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, 2017, Attention is All You Need: https://arxiv.org/abs/1706.03762
- Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, 2018, Improving Language Understanding by Generative Pre-Training: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, 2019, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding: https://arxiv.org/abs/1810.04805
- Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, 2019, Language Models are Unsupervised Multitask Learners: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
- Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplany, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei, 2020, Language Models are Few-Shot Learners: https://arxiv.org/abs/2005.14165
- Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, Samuel R. Bowman, 2019, SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems: https://w4ngatang.github.io/static/papers/superglue.pdf
- Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, Samuel R. Bowman, 2019, GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding: https://arxiv.org/pdf/1804.07461.pdf
- OpenAI GPT-2 GitHub Repository: https://github.com/openai/gpt-2
- N. Shepperd’s GitHub Repository: https://github.com/nshepperd/gpt-2
- Common Crawl data: https://commoncrawl.org/big-picture/
Join our book’s Discord space
Join the book’s Discord workspace:
https://www.packt.link/Transformers
