
11
Let Your Data Do the Talking: Story, Questions, and Answers
Reading comprehension requires many skills. When we read a text, we notice the keywords and the main events and create mental representations of the content. We can then answer questions using our knowledge of the content and our representations. We also examine each question to avoid traps and making mistakes.
No matter how powerful they have become, transformers cannot answer open questions easily. An open environment means that somebody can ask any question on any topic, and a transformer would answer correctly. That is difficult but possible to some extent with GPT-3, as we will see in this chapter. However, transformers often use general domain training datasets in a closed question-and-answer environment. For example, critical answers in medical care and law interpretation will often require additional NLP functionality.
However, transformers cannot answer any question correctly regardless of whether the training environment is closed with preprocessed question-answer sequences. A transformer model can sometimes make wrong predictions if a sequence contains more than one subject and compound propositions.
This chapter will focus on methods to build a question generator that finds unambiguous content in a text with the help of other NLP tasks. The question generator will show some of the ideas applied to implement question-answering.
We will begin by showing how difficult it is to ask random questions and expect the transformer to respond well every time.
We will help a DistilBERT model answer questions by introducing Named Entity Recognition (NER) functions that suggest reasonable questions. In addition, we will lay the ground for a question generator for transformers.
We will add an ELECTRA model that was pretrained as a discriminator to our question-answering toolbox.
We will continue by adding Semantic Role Labeling (SRL) functions to the blueprint of the text generator.
Then, the Next steps section will provide additional ideas to build a reliable question-answering solution, including implementing the Haystack framework.
Finally, we will go straight to the GPT-3 Davinci engine interface online to explore question-answering tasks in an open environment. Again, no development, no training, and no preparation are required!
By the end of the chapter, you will see how to build your own multi-task NLP helpers or use Cloud AI for question-answering.
This chapter covers the following topics:
- The limits of random question-answering
- Using NER to create meaningful questions based on entity identification
- Beginning to design the blueprint of a question generator for transformers
- Testing the questions found with NER
- Introducing an ELECTRA encoder pretrained as a discriminator
- Testing the ELECTRA model with standard questions
- Using SRL to create meaningful questions based on predicate identification
- Project management guidelines to implement question-answering transformers
- Analyzing how to create a question generated using SRL
- Using the output of NER and SRL to define the blueprint of a question generator for transformers
- Exploring Haystack’s question-answering framework with RoBERTa
- Using GPT-3’s interface requires no development or preparation
Let’s begin by going through the methodology we will apply to analyze the generation of questions for question-answering tasks.
Methodology
Question-answering is mainly presented as an NLP exercise involving a transformer and a dataset containing the ready-to-ask questions and answering those questions. The transformer is trained to answer the questions asked in this closed environment.
However, in more complex situations, reliable transformer model implementations require customized methods.
Transformers and methods
A perfect and efficient universal transformer model for question-answering or any other NLP task does not exist. The best model for a project is the one that produces the best outputs for a specific dataset and task.
The method outperforms models in many cases. For example, a suitable method with an average model often will produce more efficient results than a flawed method with an excellent model.
In this chapter, we will run DistilBERT, ELECTRA, and RoBERTa models. Some produce better performances than others.
However, performance does not guarantee a result in a critical domain.
For example, in a space rocket and spacecraft production project, asking an NLP bot a question means obtaining one exact answer.
Suppose the user needs to ask a question on a hundred-page report on the status of a regeneratively cooled nozzle and combustion chamber of a rocket. The question could be specific, such as Is the cooling status reliable or not? That is the bottom-line information the user wants from the NLP bot.
To cut a long story short, letting the NLP bot, transformer model or not, make a literal statistical answer with no quality and cognitive control is too risky and would not happen. A trustworthy NLP bot would be connected to a knowledge base containing data and rules to run a rule-based expert system in the background to check the NLP bot’s answer. The NLP transformer model bot would produce a smooth, reliable natural language answer, possibly with a human voice.
A universal transformer model and method that will fit all needs does not exist. Each project requires specific functions and a customized approach and will vary tremendously depending on the users’ expectations.
This chapter will focus on the general constraints of question-answering beyond a specific transformer model choice. This chapter is not a question-answering project guide but an introduction to how transformers can be used for question-answering.
We will focus on using question-answering in an open environment where the questions were not prepared beforehand. Transformer models require help from other NLP tasks and classical programs. We will explore some methods to give an idea of how to combine tasks to reach the goal of a project:
- Method 0 explores a trial and error approach of asking questions randomly.
- Method 1 introduces NER to help prepare the question-answering tasks.
- Method 2 tries to help the default transformer with an ELECTRA transformer model. It also introduces SRL to help the transformer prepare questions.
The introduction to these three methods shows that a single question-answering method will not work for high-profile corporate projects. Adding NER and SRL will improve the linguistic intelligence of a transformer agent solution.
For example, in one of my first AI NLP projects implementing question-answering for a defense project in a tactical situation for an aerospace corporation, I combined different NLP methods to ensure that the answer provided was 100% reliable.
You can design a multi-method solution for each project you implement.
Let’s start with the trial and error approach.
Method 0: Trial and error
Question-answering seems very easy. Is that true? Let’s find out.
Open QA.ipynb, the Google Colab notebook we will be using in this chapter. We will run the notebook cell by cell.
Run the first cell to install Hugging Face’s transformers, the framework we will be implementing in this chapter:
!pip install -q transformers
Note: Hugging Face transformers continually evolve, updating libraries and modules to adapt to the market. If the default version doesn’t work, you might have to pin one with !pip install transformers==[version that runs with the other functions in the notebook].
We will now import Hugging Face’s pipeline, which contains many ready-to-use transformer resources. They provide high-level abstraction functions for the Hugging Face library resources to perform a wide range of tasks. We can access those NLP tasks through a simple API. The program was created on Google Colab. It recommended to run it on Google Colab VM using a free Gmail account.
The pipeline is imported with one line of code:
from transformers import pipeline
Once that is done, we have one-line options to instantiate transformer models and tasks:
- Perform an NLP task with the default
modeland defaulttokenizer:pipeline("<task-name>") - Perform an NLP task using a custom
model:pipeline("<task-name>", model="<model_name>") - Perform NLP tasks using a custom
modeland a customtokenizer:pipeline('<taskname>', model='<model name>', tokenizer='<tokenizer_name>')
Let’s begin with the default model and tokenizer:
nlp_qa = pipeline('question-answering')
Now, all we have to do is provide a text that we will then use to submit questions to the transformer:
sequence = "The traffic began to slow down on Pioneer Boulevard in Los Angeles, making it difficult to get out of the city. However, WBGO was playing some cool jazz, and the weather was cool, making it rather pleasant to be making it out of the city on this Friday afternoon. Nat King Cole was singing as Jo, and Maria slowly made their way out of LA and drove toward Barstow. They planned to get to Las Vegas early enough in the evening to have a nice dinner and go see a show."
The sequence is deceptively simple, and all we need to do is plug one line of code into the API to ask a question and obtain an answer:
nlp_qa(context=sequence, question='Where is Pioneer Boulevard ?')
The output is a perfect answer:
{'answer': 'Los Angeles,', 'end': 66, 'score': 0.988201259751591, 'start': 55}
We have just implemented a question-answering transformer NLP task in a few lines of code! You could now download a ready-to-use dataset that contains texts, questions, and answers.
In fact, the chapter could end right here, and you would be all set for question-answering tasks. However, things are never simple in real-life implementations. Suppose we have to implement a question-answering transformer model for users to ask questions on many documents stored in the database. We have two significant constraints:
- We first need to run the transformer through a set of key documents and create questions that show that the system works
- We must show how we can guarantee that the transformer answers the questions correctly
Several questions immediately arise:
- Who is going to find the questions to ask to test the system?
- Even if an expert agrees to do the job, what will happen if many of the questions produce erroneous results?
- Will we keep training the model if the results are not satisfactory?
- What happens if some of the questions cannot be answered, no matter which model we use or train?
- What if this works on a limited sample but the process takes too long and cannot be scaled up because it costs too much?
If we just try questions that come to us with an expert’s help and see which ones work and which ones don’t, it could take forever. Trial and error is not the solution.
This chapter aims to provide some methods and tools that will reduce the cost of implementing a question-answering transformer model. Finding good questions for question-answering is quite a challenge when implementing new datasets for a customer.
We can think of a transformer as a LEGO® set of building blocks we can assemble as we see fit using encoder-only or decoder-only stacks. We can use a set of small, large, or extra-large (XL) transformer models.
We can also think of the NLP tasks we have explored in this book as a LEGO® set of solutions in a project we must implement. We can assemble two or more NLP tasks to reach our goals, just like any other software implementation. We can go from a trial and error search for questions to a methodical approach.
In this chapter:
- We will continue to run
QA.ipynbcell by cell to explore the methods described in each section. - We will also use the
AllenNLPNER interface to obtain a visual representation of the NER and SRL results. You can enter the sentence in the interface by going to https://demo.allennlp.org/reading-comprehension, then select Named Entity Recognition or Semantic Role Labeling, and enter the sequence. In this chapter, we will take theAllenNLPmodel used into account. We just want to obtain visual representations.
Let’s start by trying to find the right XL transformer model questions for question-answering with a NER-first method.
Method 1: NER first
This section will use NER to help us find ideas for good questions. Transformer models are continuously trained and updated. Also, the datasets used for training might change. Finally, these are not rule-based algorithms that produce the same result each time. The outputs might change from one run to another. NER can detect people, locations, organizations, and other entities in a sequence. We will first run a NER task that will give us some of the main parts of the paragraph we can focus on to ask questions.
Using NER to find questions
We will continue to run QA.ipynb cell by cell. The program now initializes the pipeline with the NER task to perform with the default model and tokenizer:
nlp_ner = pipeline("ner")
We will continue to use the deceptively simple sequence we ran in the Method 0: Trial and error section of this chapter:
sequence = "The traffic began to slow down on Pioneer Boulevard in Los Angeles, making it difficult to get out of the city. However, WBGO was playing some cool jazz, and the weather was cool, making it rather pleasant to be making it out of the city on this Friday afternoon. Nat King Cole was singing as Jo and Maria slowly made their way out of LA and drove toward Barstow. They planned to get to Las Vegas early enough in the evening to have a nice dinner and go see a show."
We run the nlp_ner cell in QA.ipynb:
print(nlp_ner(sequence))
The output generates the result of the NLP tasks. The scores were rounded up to two decimal places to fit the width of the page:
[{'word': 'Pioneer', 'score': 0.97, 'entity': 'I-LOC', 'index': 8},
{'word': 'Boulevard', 'score': 0.99, 'entity': 'I-LOC', 'index': 9},
{'word': 'Los', 'score': 0.99, 'entity': 'I-LOC', 'index': 11},
{'word': 'Angeles', 'score': 0.99, 'entity': 'I-LOC', 'index': 12},
{'word': 'W', 'score': 0.99, 'entity': 'I-ORG', 'index': 26},
{'word': '##B', 'score': 0.99, 'entity': 'I-ORG', 'index': 27},
{'word': '##G', 'score': 0.98, 'entity': 'I-ORG', 'index': 28},
{'word': '##O', 'score': 0.97, 'entity': 'I-ORG', 'index': 29},
{'word': 'Nat', 'score': 0.99, 'entity': 'I-PER', 'index': 59},
{'word': 'King', 'score': 0.99, 'entity': 'I-PER', 'index': 60},
{'word': 'Cole', 'score': 0.99, 'entity': 'I-PER', 'index': 61},
{'word': 'Jo', 'score': 0.99, 'entity': 'I-PER', 'index': 65},
{'word': 'Maria', 'score': 0.99, 'entity': 'I-PER', 'index': 67},
{'word': 'LA', 'score': 0.99, 'entity': 'I-LOC', 'index': 74},
{'word': 'Bar', 'score': 0.99, 'entity': 'I-LOC', 'index': 78},
{'word': '##sto', 'score': 0.85, 'entity': 'I-LOC', 'index': 79},
{'word': '##w', 'score': 0.99, 'entity': 'I-LOC', 'index': 80},
{'word': 'Las', 'score': 0.99 'entity': 'I-LOC', 'index': 87},
{'word': 'Vegas', 'score': 0.9989519715309143, 'entity': 'I-LOC', 'index': 88}]
The documentation of Hugging Face describes the labels used. In our case, the main ones are:
I-PER, the name of a personI-ORG, the name of an organizationI-LOC, the name of a location
The result is correct. Note that Barstow was split into three tokens.
Let’s run the same sequence on AllenNLP in the Named Entity Recognition section (https://demo.allennlp.org/named-entity-recognition) to obtain a visual representation of our sequence:

Figure 11.1: NER
We can see that NER has highlighted the key entities we will use to create questions for question-answering.
Let’s ask our transformer two types of questions:
- Questions related to locations
- Questions related to persons
Let’s begin with location questions.
Location entity questions
QA.ipynb produced nearly 20 entities. The location entities are particularly interesting:
[{'word': 'Pioneer', 'score': 0.97, 'entity': 'I-LOC', 'index': 8},
{'word': 'Boulevard', 'score': 0.99, 'entity': 'I-LOC', 'index': 9},
{'word': 'Los', 'score': 0.99, 'entity': 'I-LOC', 'index': 11},
{'word': 'Angeles', 'score': 0.99, 'entity': 'I-LOC', 'index': 12},
{'word': 'LA', 'score': 0.99, 'entity': 'I-LOC', 'index': 74},
{'word': 'Bar', 'score': 0.99, 'entity': 'I-LOC', 'index': 78},
{'word': '##sto', 'score': 0.85, 'entity': 'I-LOC', 'index': 79},
{'word': '##w', 'score': 0.99, 'entity': 'I-LOC', 'index': 80},
{'word': 'Las', 'score': 0.99 'entity': 'I-LOC', 'index': 87},
{'word': 'Vegas', 'score': 0.9989519715309143, 'entity': 'I-LOC', 'index': 88}]
Applying heuristics
We can apply heuristics, a method, to create questions with the output QA.ipynb generated:
- Merge the locations back into their original form with a parser
- Apply a template to the locations
It is beyond the scope of this book to write classical code for a project. We could write a function that would do the work for us, as shown in this pseudocode:
for i in range beginning of output to end of the output:
filter records containing I-LOC
merge the I-LOCs that fit together
save the merged I-LOCs for questions-answering
The NER output would become:
I-LOC,Pioneer BoulevardI-LOC,Los AngelesI-LOC,LAI-LOC,BarstowI-LOC,Las Vegas
We could then generate questions automatically with two templates. For example, we could apply a random function. We could write a function that would do the job for us, as shown in the following pseudocode:
from the first location to the last location:
choose randomly:
Template 1: Where is [I-LOC]?
Template 2: Where is [I-LOC] located?
We would obtain five questions automatically. For example:
Where is Pioneer Boulevard?
Where is Los Angeles located?
Where is LA?
Where is Barstow?
Where is Las Vegas located?
We know that some of these questions cannot be directly answered with the sequence we created. But we can also manage that automatically. Suppose the questions were created automatically with our method:
- Enter a sequence
- Run NER
- Create the questions automatically
Let’s suppose the questions were created automatically and let’s run them:
nlp_qa = pipeline('question-answering')
print("Question 1.",nlp_qa(context=sequence, question='Where is Pioneer Boulevard ?'))
print("Question 2.",nlp_qa(context=sequence, question='Where is Los Angeles located?'))
print("Question 3.",nlp_qa(context=sequence, question='Where is LA ?'))
print("Question 4.",nlp_qa(context=sequence, question='Where is Barstow ?'))
print("Question 5.",nlp_qa(context=sequence, question='Where is Las Vegas located ?'))
The output shows that only Question 1 was answered correctly:
Question 1. {'score': 0.9879662851935791, 'start': 55, 'end': 67, 'answer': 'Los Angeles,'}
Question 2. {'score': 0.9875189033668121, 'start': 34, 'end': 51, 'answer': 'Pioneer Boulevard'}
Question 3. {'score': 0.5090435442006118, 'start': 55, 'end': 67, 'answer': 'Los Angeles,'}
Question 4. {'score': 0.3695214621538554, 'start': 387, 'end': 396, 'answer': 'Las Vegas'}
Question 5. {'score': 0.21833994202792262, 'start': 355, 'end': 363, 'answer': 'Barstow.'}
The output displays the score, the start and end position of the answer, and the answer itself. The score of Question 2 is 0.98 in this run, although it wrongly states that Los Angeles in Pioneer Boulevard.
What do we do now?
It’s time to control transformers with project management to add quality and decision-making functions.
Project management
We will examine four examples, among many others, of how to manage the transformer and the hard-coded functions that manage it automatically. We will classify these four project management examples into four project levels: easy, intermediate, difficult, and very difficult. Project management is not in the scope of this book, so we will briefly go through these four categories:
- An easy project could be a website for an elementary school. A teacher might be delighted by what we have seen. The text could be displayed on an HTML page. The five answers to the questions we obtained automatically could be merged with some development into five assertions in a fixed format:
I-LOC is in I-LOC(for example,Barstow is in California). We then add(True, False)under each assertion. All the teacher would have to do would be to have an administrator interface that allows the teacher to click on the right answers to finalize a multiple-choice questionnaire! - An intermediate project could be to encapsulate the transformer’s automatic questions and answers in a program that uses an API to check the answers and correct them automatically. The user would see nothing. The process is seamless. The wrong answers the transformer made would be stored for further analysis.
- A difficult project would be implementing an intermediate project in a chatbot with follow-up questions. For example, the transformer correctly places
Pioneer BoulevardinLos Angeles. A chatbot user might ask a natural follow-up question such asnear where in LA?. This requires more development. - A very difficult project would be a research project that would train the transformer to recognize
I-LOCentities over millions of records in datasets and output results of real-time streaming of map software APIs.
The good news is that we can also find a way to use what we find.
The bad news is that implemented transformers or any AI in real-life projects require powerful machines and a tremendous amount of teamwork between project managers, Subject Matter Experts (SMEs), developers, and end users.
Let’s now try person entity questions.
Person entity questions
Let’s start with an easy question for the transformer:
nlp_qa = pipeline('question-answering')
nlp_qa(context=sequence, question='Who was singing ?')
The answer is correct. It states who in the sequence was singing:
{'answer': 'Nat King Cole,'
'end': 277,
'score': 0.9653632081862433,
'start': 264}
We will now ask the transformer a question that requires some thinking because it is not clearly stated:
nlp_qa(context=sequence, question='Who was going to Las Vegas ?')
It is impossible to answer that question without taking the sentence apart. The transformer makes a big mistake:
{'answer': 'Nat King Cole,'
'end': 277,
'score': 0.3568152742800521,
'start': 264}
The transformer is honest enough to display a score of only 0.35. This score might vary from one calculation to another or from one transformer model to another. We can see that the transformer faced a semantic labeling problem. Let’s try to do better with person entity questions applying an SRL-first method.
Method 2: SRL first
The transformer could not find who was driving to go to Las Vegas and thought it was from Nat King Cole instead of Jo and Maria.
What went wrong? Can we see what the transformers think and obtain an explanation? To find out, let’s go back to semantic role modeling. If necessary, take a few minutes to review Chapter 10, Semantic Role Labeling with BERT-Based Transformers.
Let’s run the same sequence on AllenNLP in the Semantic Role Labeling section, https://demo.allennlp.org/semantic-role-labeling, to obtain a visual representation of the verb drove in our sequence by running the SRL BERT model we used in the previous chapter:
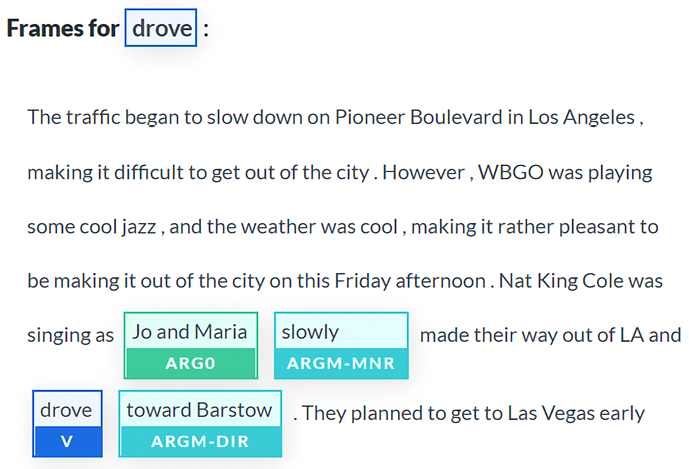
Figure 11.2: SRL run on the text
SRL BERT found 19 frames. In this section, we focus on drove.
Note: The results may vary from one run to another or when AllenNLP updates the model versions.
We can see the problem. The argument of the verb drove is Jo and Maria. It seems that the inference could be made.
Keep in mind that transformer models keep evolving. The output might vary; however, the concepts remain the same.
Is that true? Let’s ask the question in QA.ipynb:
nlp_qa(context=sequence, question='Who are they?')
The output is correct:
{'answer': 'Jo and Maria',
'end': 305,
'score': 0.8486017557290779,
'start': 293}
Could we find a way to ask the question to obtain the right answer? We will try by paraphrasing the question:
nlp_qa(context=sequence, question='Who drove to Las Vegas?')
We obtain a somewhat better result:
{'answer': 'Nat King Cole was singing as Jo and Maria',
'end': 305,
'score': 0.35940926070820467,
'start': 264}
The transformer now understands that Nat King Cole was singing and that Jo and Maria were doing something in the meantime.
We still need to go further and find a way to ask better questions.
Let’s try another model.
Question-answering with ELECTRA
Before switching models, we need to know which one we are using:
print(nlp_qa.model)
The output first shows that the model is a DistilBERT model trained on question-answering:
DistilBertForQuestionAnswering((distilbert): DistilBertModel(
The model has 6 layers and 768 features, as shown in layer 6 (the layers are numbered from 0 to n):
(5): TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
We will now try the ELECTRA transformer model. Clark et al. (2020) designed a transformer model that improved the Masked Language Modeling (MLM) pretraining method.
In Chapter 3, Fine-Tuning BERT Models, in the Masked language modeling subsection, we saw that the BERT model inserts random masked tokens with [MASK] during the training process.
Clark et al. (2020) introduced plausible alternatives with a generator network rather than simply using random tokens. BERT models are trained to predict the identities of the (masked) corrupted tokens. Clark et al. (2020) trained an ELECTRA model as a discriminator to predict whether the masked token was a generated token or not. Figure 11.3 shows how ELECTRA is trained:
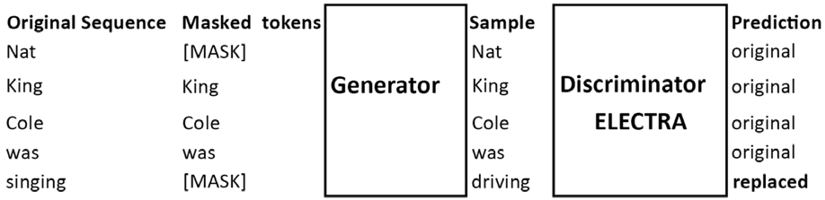
Figure 11.3: ELECTRA is trained as a discriminator
Figure 11.3 shows that the original sequence is masked before going through the generator. The generator inserts acceptable tokens and not random tokens. The ELECTRA transformer model is trained to predict whether a token comes from the original sequence or has been replaced.
The architecture of an ELECTRA transformer model and most of its hyperparameters are the same as BERT transformer models.
We now want to see if we can obtain a better result. The next cell to run in QA.ipynb is the question-answering cell with an ELECTRA-small-generator:
nlp_qa = pipeline('question-answering', model='google/electra-small-generator', tokenizer='google/electra-small-generator')
nlp_qa(context=sequence, question='Who drove to Las Vegas ?')
The output is not what we expect:
{'answer': 'to slow down on Pioneer Boulevard in Los Angeles, making it difficult to',
'end': 90,
'score': 2.5295573154019736e-05,
start': 18}
The output might change from one run or transformer model to another; however, the idea remains the same.
The output also sends training messages:
- This IS expected if you are initializing ElectraForQuestionAnswering from the checkpoint of a model trained on another task or with another architecture..
- This IS NOT expected if you are initializing ElectraForQuestionAnswering from the checkpoint of a model that you expect to be exactly identical..
You might not like these warning messages and might conclude that this is a bad model. But always explore every avenue that is offered to you. ELECTRA might require more training, of course. But experiment as much as possible to find new ideas! Then you can decide to train a model further or move on to another one.
We must now think of the next steps to take.
Project management constraints
We have not obtained the results we expected with the default DistilBERT and ELECTRA transformer models.
There are three main options among other solutions:
- Train DistilBERT and ELECTRA or other models with additional datasets. Training datasets is a costly process in real-life projects. The training could last months if new datasets need to be implemented and hyperparameters changed. The hardware cost needs to be taken into account as well. Furthermore, if the result is unsatisfactory, a project manager might shut the project down.
- You can also try ready-to-use transformers, although they might not fit your needs, such as the Hugging Face model: https://huggingface.co/transformers/usage.html#extractive-question-answering.
- Find a way to obtain better results by using additional NLP tasks to help the question-answering model.
In this chapter, we will focus on finding additional NLP tasks to help the default DistilBERT model.
Let’s use SRL to extract the predicates and their arguments.
Using SRL to find questions
AllenNLP uses the BERT-based model we implemented in the SRL.ipynb notebook in Chapter 10, Semantic Role Labeling with BERT-Based Transformers.
Let’s rerun the sequence on AllenNLP in the Semantic Role Labeling section, https://demo.allennlp.org/semantic-role-labeling, to obtain a visual representation of the predicates in the sequence.
We will enter the sequence we have been working on:
The traffic began to slow down on Pioneer Boulevard in Los Angeles, making it difficult to get out of the city. However, WBGO was playing some cool jazz, and the weather was cool, making it rather pleasant to be making it out of the city on this Friday afternoon. Nat King Cole was singing as Jo and Maria slowly made their way out of LA and drove toward Barstow. They planned to get to Las Vegas early enough in the evening to have a nice dinner and go see a show.
The BERT-based model found several predicates. Our goal is to find the properties of SRL outputs that could automatically generate questions based on the verbs in a sentence.
We will first list the predicate candidates produced by the BERT model:
verbs={"began," "slow," "making"(1), "playing," "making"(2), "making"(3), "singing,",…, "made," "drove," "planned," go," see"}
If we had to write a program, we could start by introducing a verb counter, as shown in the following pseudocode:
def maxcount:
for in range first verb to last verb:
for each verb
counter +=1
if counter>max_count, filter verb
If the counter exceeds the number of acceptable occurrences (max_count), the verb will be excluded in this experiment. Without further development, it will be too difficult to disambiguate multiple semantic roles of the verb’s arguments.
Let’s take made, which is the past tense of make, out of the list as well.
Our list is now limited to:
verbs={"began," "slow," "playing," "singing," "drove," "planned," go," see"}
If we continued to write a function to filter the verbs, we could look for verbs with lengthy arguments. The verb began has a very long argument:

Figure 11.4: SRL applied to the verb “began”
The argument of began is so long it doesn’t fit in the screenshot. The text version shows how difficult it would be to interpret the argument of began:
began: The traffic [V: began] [ARG1: to slow down on Pioneer Boulevard in Los Angeles , making it difficult to get out of the city] . However , WBGO was playing some cool jazz] , and the weather was cool , making it rather pleasant to be making it out of the city on this Friday afternoon . Nat King Cole was singing as Jo and Maria slowly made their way out of LA and drove toward Barstow . They planned to get to Las Vegas early enough in the evening to have a nice dinner and go see a show .
We could add a function to filter verbs that contain arguments that exceed a maximum length:
def maxlength:
for in range first verb to last verb:
for each verb
if length(argument of verb)>max_length, filter verb
If the length of one verb’s arguments exceeds a maximum length (max_length), the verb will be excluded in this experiment. For the moment, let’s just take began out of the list:
Our list is now limited to:
verbs={ "slow", "playing", "singing", "drove", "planned"," go"," see"}
We could add more exclusion rules depending on the project we are working on. We can also call the maxlength function again with a very restrictive max_length value to extract potentially interesting candidates for our automatic question generator. The verb candidates with the shortest arguments could be transformed into questions. The verb slow fits the three rules we set: it appears only once in the sequence, the arguments are not too long, and it contains some of the shortest arguments in the sequence. The AllenNLP visual representation confirms our choice:
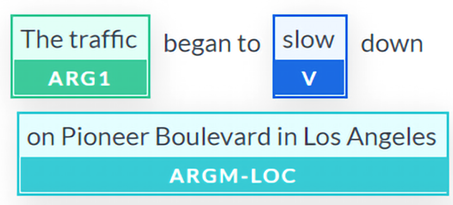
Figure 11.5: SRL applied to the verb “slow”
The text output can be easily parsed:
slow: [ARG1: The traffic] began to [V: slow] down [ARG1: on] [ARGM-ADV: Pioneer Boulevard] [ARGM-LOC: in Los Angeles] , [ARGM-ADV: making it difficult to get out of the city] .
This result and the following outputs may vary with the ever-evolving transformer models, but the idea remains the same. The verb slow is identified and this is the key aspect of this SRL output.
We could automatically generate the what template. We will not generate a who template because none of the arguments were labeled I-PER (person). We could write a function that manages these two possibilities, as shown in the following pseudocode:
def whowhat:
if NER(ARGi)==I-PER, then:
template=Who is [VERB]
if NER(ARGi)!=I-PER, then:
template=What is [VERB]
This function would require more work to deal with verb forms and modifiers. However, in this experiment, we will just apply the function and generate the following question:
What is slow?
Let’s run the default pipeline with the following cell:
nlp_qa = pipeline ('question-answering')
nlp_qa(context= sequence, question='What was slow?')
The result is satisfactory:
{'answer': 'The traffic',
'end': 11,
'score': 0.4652545872921081,
'start': 0}
The default model, in this case, DistilBERT, correctly answered the question.
Our automatic question generator can do the following:
- Run NER automatically
- Parse the results with classical code
- Generate entity-only questions
- Run SRL automatically
- Filter the results with rules
- Generate SRL-only questions using the NER results to determine which template to use
This solution is by no means complete. More work needs to be done and probably requires additional NLP tasks and code. However, it gives an idea of the hard work implementing AI, in any form, requires.
Let’s try our approach with the next filter verb: playing. The visual representation shows that the arguments are WBGO and some cool jazz:

Figure 11.6: SRL applied to the verb “playing”
The text version is easy to parse:
playing: The traffic began to slow down on Pioneer Boulevard in Los Angeles , making it difficult to get out of the city . [ARGM-DIS: However] , [ARG0: WBGO] was [V: playing] [ARG1: some cool jazz]
This result and the following outputs may vary with the ever-evolving transformer models, but the idea remains the same: identifying the verb and its arguments.
If we ran the whowhat function, it would show that there is no I-PER in the arguments. The template chosen will be the what template, and the following question could be generated automatically:
What is playing?
Let’s run the default pipeline with this question in the following cell:
nlp_qa = pipeline('question-answering')
nlp_qa(context=sequence, question='What was playing')
The output is also satisfactory:
{'answer': 'cool jazz,,'
'end': 153,
'score': 0.35047012837950753,
'start': 143}
singing is a good candidate, and the whowhat function would find the I-PER template and automatically generate the following question:
Who is singing?
We have already successfully tested this question in this chapter.
The next verb is drove, which we have already tagged as a problem. The transformer cannot solve this problem.
The verb go is a good candidate:

Figure 11.7: SRL applied to the verb “go”
It would take additional development to produce a template with the correct verb form. Let’s suppose the work was done and ask the model the following question:
nlp_qa = pipeline('question-answering')
nlp_qa(context=sequence, question='Who sees a show?')
The output is the wrong argument:
{'answer': 'Nat King Cole,'
'end': 277,
'score': 0.5587267250683112,
'start': 264}
We can see that the presence of Nat King Cole and Jo and Maria in the same sequence in a complex sequence creates disambiguation problems for transformer models and any NLP model. More project management and research would be required.
Next steps
There is no easy way to implement question-answering or shortcuts. We began to implement methods that could generate questions automatically. Automatic question generation is a critical aspect of NLP.
More transformer models need to be pretrained with multi-task datasets containing NER, SRL, and question-answering problems to solve. Project managers also need to learn how to combine several NLP tasks to help solve a specific task, such as question-answering.
Coreference resolution, https://demo.allennlp.org/coreference-resolution, could have helped our model identify the main subjects in the sequence we worked on. This result produced with AllenNLP shows an interesting analysis:

Figure 11.8: Coreference resolution of a sequence
We could continue to develop our program by adding the output of coreference resolution:
Set0={'Los Angeles', 'the city,' 'LA'}
Set1=[Jo and Maria, their, they}
We could add coreference resolution as a pretraining task or add it as a post-processing task in the question generator. In any case, question generators that simulate human behavior can considerably enhance the performance of question-answering tasks. We will include more customized additional NLP tasks in the pretraining process of question-answering models.
Of course, we can decide to use new strategies to pretrain the models we ran in this chapter, such as DistilBERT and ELECTRA, and then let users ask the questions they wish. I recommend both approaches:
- Work on question generators for question-answering tasks. These questions can be used for educational purposes, train transformers, or even provide ideas for real-time users.
- Work on pretraining transformer models by including specific NLP tasks, which will improve their question-answering performance. Use the question generator to train it further.
Exploring Haystack with a RoBERTa model
Haystack is a question-answering framework with interesting functionality. It is worth exploring to see if it might fit your needs for a given project.
In this section, we will run question-answering on the sentence we experimented with using other models and methods in this chapter.
Open Haystack_QA_Pipeline.ipynb.
If you have trouble running Haystack_QA_Pipeline.ipynb on Google Colab, try running the 01_Basic_QA_Pipeline.ipynb notebook instead.
The first cell installs the modules necessary to run Haystack:
# Install Haystack
!pip install farm-haystack==0.6.0
# Install specific versions of urllib and torch to avoid conflicts with preinstalled versions on Colab
!pip install urllib3==1.25.4
!pip install torch==1.6.0+cu101-f https://download.pytorch.org/whl/torch_stable.html
The notebook uses a RoBERTa model:
# Load a local model or any of the QA models on Hugging Face's model hub (https://huggingface.co/models)
from haystack.reader.farm import FARMReader
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2", use_gpu=True, no_ans_boost=0, return_no_answer=False)
You can go back to Chapter 4, Pretraining a RoBERTa Model from Scratch, for a general description of a RoBERTa model.
The remaining cells of the notebook will answer questions on the text we have been exploring in detail in this chapter:
text = "The traffic began to slow down on Pioneer Boulevard in…/… have a nice dinner and go see a show."
You can compare the answers obtained with the previous sections’ outputs and decide which transformer model you would like to implement.
Exploring Q&A with a GTP-3 engine
This section will try to avoid training, fine-tuning, loading a program on a server, or even using a dataset. Instead, a user can simply connect to their OpenAI account and use the interactive educational interface.
A GPT-3 engine online educational interface will provide sufficiently good answers by providing E (explanation) and T (text) as follows:
E = Answer questions from this text
T = The traffic began to slow down on Pioneer Boulevard in…/… have a nice dinner and go see a show.
Here are some questions asked and answers obtained in the form of question-answer:
Who is going to Las Vegas?:Jo and MariaWho was singing?:Nat King ColeWhat kind of music was playing?:jazzWhat was the plan for the evening?:to have a nice dinner and go see a show
That’s it! That’s all you need to do to run a wide range of educational NLP tasks online with an interactive interface even without an API with GPT-3 engines.
You can change S (showing GPT-3 what is expected) and E and create endless interactions. The next generation of NLP is born! An Industry 4.0 developer, consultant, or project manager will need to acquire a new set of skills: cognitive approaches, linguistics, psychology, and other cross-disciplinary dimensions. If necessary, you can take your time and go back to Chapter 7, The Rise of Suprahuman Transformers with GPT-3 Engines.
We have explored some critical aspects of the use of question-answering with transformers. Let’s sum up the work we have done.
Summary
In this chapter, we found that question-answering isn’t as easy as it seems. Implementing a transformer model only takes a few minutes. However, getting it to work can take a few hours or several months!
We first asked the default transformer in the Hugging Face pipeline to answer some simple questions. DistilBERT, the default transformer, answered the simple questions quite well. However, we chose easy questions. In real life, users ask all kinds of questions. The transformer can get confused and produce erroneous output.
We then decided to continue to ask random questions and get random answers, or we could begin to design the blueprint of a question generator, which is a more productive solution.
We started by using NER to find useful content. We designed a function that could automatically create questions based on NER output. The quality was promising but required more work.
We tried an ELECTRA model that did not produce the results we expected. We stopped for a few minutes to decide if we would spend costly resources to train transformer models or design a question generator.
We added SRL to the blueprint of the question generator and tested the questions it could produce. We also added NER to the analysis and generated several meaningful questions. The Haystack framework was also introduced to discover other ways of addressing question-answering with RoBERTa.
Finally, we ran an example using a GPT-3 engine directly in the OpenAI educational interactive interface without an API. Cloud AI platforms are increasing in power and accessibility.
Our experiments led to one conclusion: multi-task transformers will provide better performance on complex NLP tasks than a transformer trained on a specific task. Implementing transformers requires well-prepared multi-task training, heuristics in classical code, and a question generator. The question generator can be used to train the model further by using the questions as training input data or as a standalone solution.
In the next chapter, Detecting Customer Emotions to Make Predictions, we will explore how to implement sentiment analysis on social media feedback.
Questions
- A trained transformer model can answer any question. (True/False)
- Question-answering requires no further research. It is perfect as it is. (True/False)
- Named Entity Recognition (NER) can provide useful information when looking for meaningful questions. (True/False)
- Semantic Role Labeling (SRL) is useless when preparing questions. (True/False)
- A question generator is an excellent way to produce questions. (True/False)
- Implementing question answering requires careful project management. (True/False)
- ELECTRA models have the same architecture as GPT-2. (True/False)
- ELECTRA models have the same architecture as BERT but are trained as discriminators. (True/False)
- NER can recognize a location and label it as
I-LOC. (True/False) - NER can recognize a person and label that person as
I-PER. (True/False)
References
- The Allen Institute for AI: https://allennlp.org/
- The Allen Institute for reading comprehension resources: https://demo.allennlp.org/reading-comprehension
- Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning, 2020, ELECTRA: Pretraining Text Encoders as Discriminators Rather Than Generators: https://arxiv.org/abs/2003.10555
- Hugging Face pipelines: https://huggingface.co/transformers/main_classes/pipelines.html
- GitHub Haystack framework repository: https://github.com/deepset-ai/haystack/
Join our book’s Discord space
Join the book’s Discord workspace:
https://www.packt.link/Transformers
