
Appendix II — Hardware Constraints for Transformer Models
Transformer models could not exist without optimized hardware. Memory and disk management design remain critical components. However, computing power remains a prerequisite. It would be nearly impossible to train the original Transformer described in Chapter 2, Getting Started with the Architecture of the Transformer Model, without GPUs. GPUs are at the center of the battle for efficient transformer models.
This appendix to Chapter 3, Fine-Tuning BERT Models, will take you through the importance of GPUs in three steps:
- The architecture and scale of transformers
- CPUs versus GPUs
- Implementing GPUs in PyTorch as an example of how any other optimized language optimizes
The Architecture and Scale of Transformers
A hint about hardware-driven design appears in the The architecture of multi-head attention section of Chapter 2, Getting Started with the Architecture of the Transformer Model:
“However, we would only get one point of view at a time by analyzing the sequence with one dmodel block. Furthermore, it would take quite some calculation time to find other perspectives.
A better way is to divide the dmodel = 512 dimensions of each word xn of x (all the words of a sequence) into 8 dk = 64 dimensions.
We then can run the 8 “heads” in parallel to speed up the training and obtain 8 different representation subspaces of how each word relates to another:
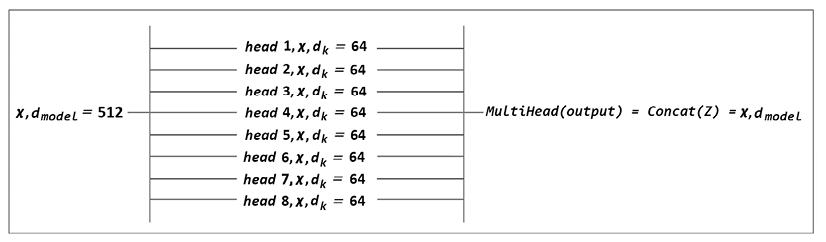
Figure II.1: Multi-head representations
You can see that there are now 8 heads running in parallel.
We can easily see the motivation for forcing the attention heads to learn 8 different perspectives. However, digging deeper into the motivations of the original 8 attention heads performing different calculations in parallel led us directly to hardware optimization.
Brown et al. (2020), in Language Models are Few-Shot Learners, https://arxiv.org/abs/2005.14165, describe how they designed GPT models. They confirm that transformer architectures are hardware-driven.
We partition the model across GPUs along with both the depth and width dimension to minimize data-transfer between nodes. The precise architectural parameters for each model are chosen based on computational efficiency and load-balancing in the layout of models across GPUs.
Transformers differ in their construction (encoders and decoders) and size. But they all have hardware constraints that require parallel processing. We need to take this a step further and see why GPUs are so special.
Why GPUs are so special
A clue to GPU-driven design emerges in the The architecture of multi-head attention section of Chapter 2, Getting Started with the Architecture of the Transformer Model.
Attention is defined as “Scaled Dot-Product Attention,” which is represented in the following equation into which we plug Q, K, and V:
![]()
We can now conclude the following:
- Attention heads are designed for parallel computing
- Attention heads are based on matmul, matrix multiplication
GPUs are designed for parallel computing
A CPU (central processing unit) is optimized for serial processing. But if we run the attention heads through serial processing, it would take far longer to train an efficient transformer model. Very small educational transformers can run on CPUs. However, they do not qualify as state-of-the-art models.
A GPU (graphics processing unit) is designed for parallel processing. Transformer models were designed for parallel processing (GPUs), not serial processing (CPUs).
GPUs are also designed for matrix multiplication
NVIDIA GPUs, for example, contain tensor cores that accelerate matrix operations. A significant proportion of artificial intelligence algorithms use matrix operations, including transformer models. NVIDIA GPUs contain a goldmine of hardware optimization for matrix operations. The following links provide more information:
- https://blogs.nvidia.com/blog/2009/12/16/whats-the-difference-between-a-cpu-and-a-gpu/
- https://www.nvidia.com/en-us/data-center/tesla-p100/
Google’s Tensor Processing Unit (TPU) is the equivalent of NVIDIA’s GPUs. TensorFlow will optimize the use of tensors when using TPUs.
- For more on TPUs, see https://cloud.google.com/tpu/docs/tpus.
- For more on tensors in TensorFlow, see https://www.tensorflow.org/guide/tensor.
BERTBASE (110M parameters) was initially trained with 16 TPU chips. BERTLARGE (340M parameters) was trained with 64 TPU chips. For more on training BERT, see https://arxiv.org/abs/1810.04805.
We have established that the architecture of the transformer perfectly fits the constraints of parallel hardware. We still need to address the issue of implementing source code that runs on GPUs.
Implementing GPUs in code
PyTorch, among other languages and frameworks, manages GPUs. PyTorch contains tensors just as TensorFlow does. A tensor may look like NumPy np.arrays(). However, NumPy is not fit for parallel processing. Tensors use the parallel processing features of GPUs.
Tensors open the doors to distributed data over GPUs in PyTorch, among other frameworks: https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
In the Chapter03 notebook, BERT_Fine_Tuning_Sentence_Classification_GPU.ipynb, we used CUDA (Compute Unified Device Architecture) to communicate with NVIDIA GPUs. CUDA is an NVIDIA platform for general computing on GPUs. Specific instructions can be added to our source code. For more, see https://developer.nvidia.com/cuda-zone.
In the Chapter03 notebook, we used CUDA instructions to transfer our model and data to NVIDIA GPUs. PyTorch has an instruction to specify the device we wish to use: torch.device.
For more, see https://pytorch.org/docs/stable/notes/cuda.html.
We will explain device to illustrate the implementation of GPUs in PyTorch and programs in general. Let’s focus on selecting a device, data parallelism, loading a model to a device, and adding batch data to the device. Each bullet point contains the way device is used and the cell number in BERT_Fine_Tuning_Sentence_Classification_GPU.ipynb:
- Select device (Cell 3)
The program checks to see if CUDA is available on an NVIDIA GPU. If not, the device will be CPU:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") !nvidia-smi - Data parallelism (Cell 16)
The model can be distributed for parallel computing over several GPUs if more than one GPU is available:
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2) model = nn.DataParallel(model) - Loading the model to the device (cell 16)
The model is sent to the device:
model.to(device) - Add batch to device (cell 20) for training and validation data
Batches of data are added to the GPUs available (
1ton):# Add batch to GPU batch = tuple(t.to(device) for t in batch)
In the following section, I describe tests I made to illustrate the use of GPUs for transformer models by running a notebook of the chapter with three runtime configurations.
Testing GPUs with Google Colab
In this section, I describe informal tests I ran to illustrate the potential of GPUs. We’ll use the same Chapter03 notebook: BERT_Fine_Tuning_Sentence_Classification_GPU.ipynb.
I ran the notebook on three scenarios:
- Google Colab Free with a CPU
- Google Colab Free with a GPU
- Google Colab Pro
Google Colab Free with a CPU
It is nearly impossible to fine-tune or train a transformer model with millions or billions of parameters on a CPU. CPUs are mostly sequential. Transformer models are designed for parallel processing.
In the Runtime menu and Change Runtime Type submenu, you can select a hardware accelerator: None (CPU), GPU, or TPU.
This test was run with None (CPU), as shown in Figure II.2:

Figure II.2: Selecting a hardware accelerator
When the notebook reaches the training loop, it slows down right from the start:

Figure II.3: Training loop
After 15 minutes, nothing has really happened.
CPUs are not designed for parallel processing. Transformer models are designed for parallel processing, so part from toy models, they require GPUs.
Google Colab Free with a GPU
Let’s go back to the notebook settings to select a GPU.
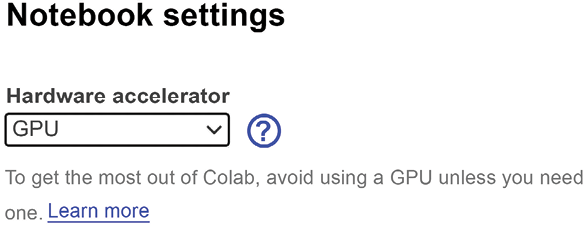
Figure II.4 Selecting a GPU
At the time of writing, I tested Google Colab, and an NVIDIA K80 was attributed to the VM with CUDA 11.2:
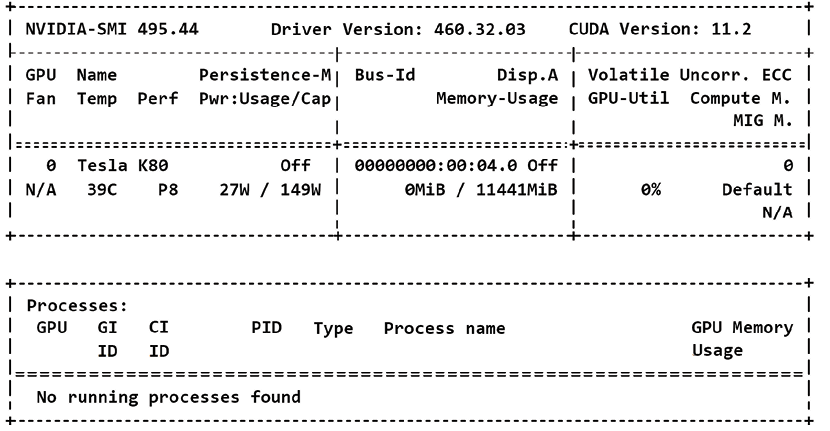
Figure II.5: NVIDIA K80 GPU activated
The training loop advanced normally and lasted about 20 minutes. However, Google Colab VMs, at the time of these tests (November 2021), do not provide more than one GPU. GPUs are expensive. In any case, Figure II.6, shows that the training loop was performed in a reasonable time:

Figure II.6: Training loop with a K80 GPU
I found it interesting to see whether Google Colab Pro provides faster GPUs.
Google Colab Pro with a GPU
The VM activated with Google Colab provided an NVIDIA P100 GPU, as shown in Figure II.7. That was interesting because the original Transformer was trained with 8 NVIDIA P100s as stated in Vaswani et al.(2017), Attention is All you Need. It took 12 hours to train the base models with 106×65 parameters and with 8 GPUs:
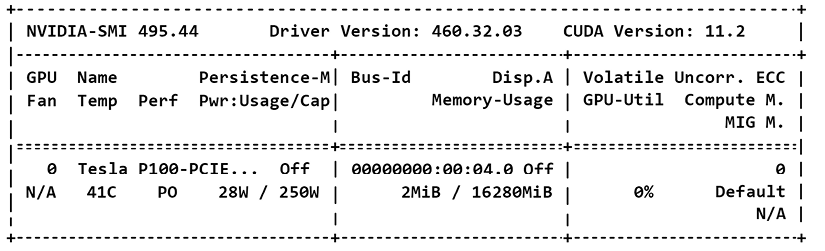
Figure II.7: The Google Colab Pro VM was provided with a P100 GPU
The training loop time was considerably reduced and lasted less than 10 minutes, as shown in Figure II.8:
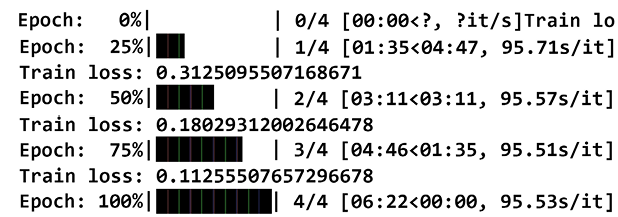
Figure II.8: Training loop with a P100 GPU
Join our book’s Discord space
Join the book’s Discord workspace:
https://www.packt.link/Transformers
