
16
The Emergence of Transformer-Driven Copilots
When Industry 4.0 (I4.0) reaches maturity, it will all be about machine-to-machine connections, communication, and decision-making. AI will be primarily embedded in ready-to-use pay-as-you-go cloud AI solutions. Big tech will absorb the most talented AI specialists to create APIs, interfaces, and integration tools.
AI specialists will go from development to design to becoming architects, integrators, and cloud AI pipeline administrators. Thus, AI is becoming a job for engineer consultants more than for engineer developers.
Chapter 1, What Are Transformers?, introduced foundation models, and transformers that can do NLP tasks they were not trained for. Chapter 15, From NLP to Task-Agnostic Transformer Models, expanded foundation model transformers to task-agnostic models that can perform vision tasks, NLP tasks, and much more.
This chapter will extend task-agnostic OpenAI GPT-3 models to a wide range of copilot tasks. A new generation of AI specialists and data scientists will learn how to work with AI copilots to help them generate source code automatically and make decisions.
This chapter begins by exploring prompt engineering in more detail. The example task consists of converting meeting notes into a summary. Transformers boost our productivity. However, we will see how natural language remains a challenge for AI.
We will learn how to use OpenAI’s Instruct models as a copilot. GitHub Copilot suggests source code as we write our programs and can also convert natural language into code.
We will then discover new AI methods with domain-specific GPT-3 engines. This chapter will show how to generate embeddings with 12,288 dimensions and plug them into machine learning algorithms. We will also see how to ask a transformer to produce instructions automatically.
We will see how to filter biased input and output before looking into transformer-driven recommenders. AI of the 2020s must be built with ethical methods.
Recommender systems have permeated every social media platform to suggest videos, posts, messages, books, and many other products we might want to consume. We will build an educational multi-purpose transformer-based recommender system using ML in the process.
Transformer models analyze sequences. They began with NLP but have successfully expanded to computer vision. We will explore a transformer-based computer vision program developed in JAX.
Finally, we will see AI copilots contribute to the transition of virtual systems into metaverses, which will expand in this decade. You are the pilot when you develop your applications. However, when you have code to develop, the activated completions are limited to methods, not lines of code. An IDE might suggest a list of methods. Copilots can produce completions of whole paragraphs of code!
This chapter covers the following topics:
- Prompt engineering
- GitHub Copilot for code completion
- Embedding datasets
- Embedded-driven machine learning
- Instruct series
- Content filter models
- Exploring transformer-based recommenders
- Extending NLP sequence learning to behavior predictions
- Implementing transformer models in JAX
- Applying transformer models to computer vision
Let’s begin with prompt engineering, which is a critical ability to acquire.
Prompt engineering
Speaking a specific language is not hereditary. There is not a language center in our brain containing the language of our parents. Our brain engineers our neurons early in our lives to speak, read, write, and understand a language. Each human has a different language circuitry depending on their cultural background and how they were communicated with in their early years.
As we grow up, we discover that much of what we hear is chaos: unfinished sentences, grammar mistakes, misused words, bad pronunciation, and many other distortions.
We use language to convey a message. We quickly find that we need to adapt our language to the person or audience we address. We might have to try additional “inputs” or “prompts” to obtain the result (“output”) we expect. Foundation-level transformer models such as GPT-3 can perform hundreds of tasks in an indefinite number of ways. We must learn the language of transformer prompts and responses as we would any other language. Effective communication with a person or near-human-level transformer must contain a minimum amount of information to maximize results. We represent the minimum input information to obtain a result as minI and the maximum output of any system as maxR.
We can represent this chain of communication as:
minI(input) ![]() maxR(output)
maxR(output)
We will replace “input” with “prompt” for transformers to show that our input influences how the model will react. The output is the “response.” The dialogue with transformers, d(T), can be expressed as:
d(T)=minI(prompt) ![]() maxR(response)
maxR(response)
When minI(prompt)![]()
1, the probability of maxR(response) ![]()
1.
When minI(prompt) ![]()
0, the probability of maxR(response) ![]()
0.
The quality d(T) depends on how well we can define minI(prompt).
If your prompt tends to reach 1, then it will produce probabilities that tend to 1.
If your prompt tends to reach 0, then it will produce output probabilities that tend to 0.
Your prompt is part of the content that impacts the probabilities! Why? Because the transformer will include the prompt and the response in its estimations.
It takes many years to learn a language as a child or an adult. It also takes quite some time to learn the language of transformers and how to design minI(prompt) effectively. We need to understand them, their architecture, and the way the algorithms calculate predictions. Then we need to spend quite some time understanding how to design the input, the prompt, for the transformers to behave as we expect.
This section focuses on oral language. The prompt for OpenAI GPT-3 for an NLP task will often be taken from meeting notes or conversations, which tend to be unstructured. Transforming meeting notes or conversations into a summary can be quite challenging. This section will focus on summarizing notes of the same conversation in seven situations that go from casual English to casual or formal English with limited context.
We will begin with casual English with a meaningful context.
Casual English with a meaningful context
Casual English is spoken with shorter sentences and a limited vocabulary.
Let’s ask OpenAI GPT-3 to perform a “notes to summary” task. Go to www.openai.com. Log in or sign up. Then go to the Examples page and select Notes to summarize.
We will give GPT-3 all the information required to summarize a casual conversation between Jane and Tom. Jane and Tom are two developers starting work. Tom offers Jane coffee. Jane declines the offer.
In this case, minI(prompt)=1 since the input information is fine, as shown in Figure 16.1:

Figure 16.1: Summarizing well-documented notes
When we click on Generate, we get a surprisingly good answer, as shown in Figure 16.2:
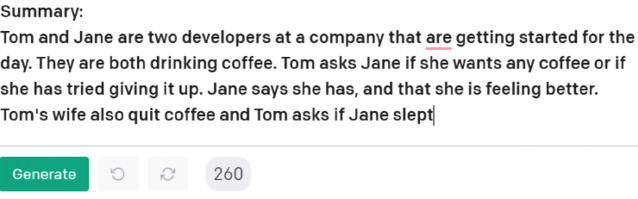
Figure 16.2: An acceptable summary is provided by GPT-3
Can we conclude that AI can find structures in our chaotic daily conversations, meetings, and aimless chatter? The answer isn’t easy. We will now complicate the input by adding a metonymy.
Casual English with a metonymy
Tom mentioned the word coffee, setting GPT-3 on track. But what if Tom used the word java instead of coffee. Coffee refers to the beverage, but java is an ingredient that comes from the island of Java. A metonymy is when we use an attribute of an object, such as java for coffee. Java is also a programming language with a logo that is a cup of coffee.
We are facing three possible definitions of java: an ingredient of coffee meaning coffee (metonymy), the island of Java, and the name of a programming language. GPT-3 now has a polysemy (several meanings of the same word) issue to solve.
Humans master polysemy. We learn the different meanings of words. We know that a word doesn’t mean much without context. In this case, Jane and Tom are developers, complicating the situation. Are they talking about coffee or the language?
The answer is easy for a human since Tom then talks about his wife, who stopped drinking it. GPT-3 can be confused by this polysemy when the word java replaces coffee, and it produces an incorrect answer:

Figure 16.3: Incorrect GPT-3 response when prompt is confusing
We thus confirm that when minI(prompt)![]()
0, the probability of maxR(response)![]()
0.
Human conversations can become even more difficult to analyze if we add an ellipsis.
Casual English with an ellipsis
The situation can get worse. Let’s suppose Tom is drinking a cup of coffee, and Jane looks at him and the cup of coffee as she casually greets him.
Instead of asking Jane if she wants coffee or java, Tom says:
"Want some?"
Tom left out the word coffee, which is an ellipsis. Jane can still understand what Tom means by looking at him holding a cup of coffee.
OpenAI GPT-3 detects the word drinking and still manages to associate this verb with the question Want some? We don’t want some of a programming language. The following summary produced by GPT-3 is still correct:

Figure 16.4: Correct response produced by GPT-3
Now, let’s see what happens when there is a vague context that a human can understand but remains a challenge for AI.
Casual English with vague context
If we take this further, Tom doesn’t need to mention his wife for Jane to understand what he is talking about since he is holding a cup of coffee.
Let’s remove Tom's reference to his wife and the verb drinking. Let’s leave want some in instead of coffee or java:

Figure 16.5: Vague input context
The output reflects the apparent chaos of the conversation:

Figure 16.6: Poor GPT-3 response
The prompt was too vague, leading to an inadequate response that we can sum up as:
d(T)![]() 0 because when minI(prompt)
0 because when minI(prompt)![]()
0, the probability of maxR(response)![]()
0
When humans communicate, they bring their culture, past relationships, visual situations, and other invisible factors into a conversation. These invisible factors for third parties can be:
- Reading a text without seeing what the people were doing (actions, facial expressions, body language, etc.)
- Listening to people refer to things they know about, but we don’t (movies, sports, problems in a factory, etc.)
- Cultural events from a culture that’s different from ours
The list is endless!
We can see that these invisible factors make AI blind.
Let’s now introduce sensors into the situation.
Casual English with sensors
We now introduce video sensors into the room for a thought experiment. Imagine we can use image captioning with a video feed and supply a context early in the dialogue such as:
Humans sometimes generate dialogue that only people that know each other well understand. Consider the following dialogue between Jane and Tom. The video feed produces image captioning showing that Tom is drinking a cup of coffee and Jane is typing on her keyboard. Jane and Tom are two developers, mumbling their way through the day while getting down to work in an open space.
Then we provide the following chaotic chat as a prompt:
Tom: "hi" Jane: "yeah sure" Tom: "Want some?" Jane: "Nope" Tom: "Cool. You're trying then." Jane: "Yup" Tom: "Sleep better?" Jane: "Yeah. Sure. "
The output of GPT-3 is acceptable though important semantic words are missing at the start:
Summarize: A developer can be seen typing on her keyboard. Another developer enters the room and offers her a cup of coffee. She declines, but he insists. They chat about her sleep and the coffee.
The results may change from one run to another. GPT-3 looks at the top probabilities and selects one of the best. GPT-3 made it through this experiment because image captioning provided the context.
However, what if Tom is not holding a cup of coffee, depriving GPT-3 of visual context?
Casual English with sensors but no visible context
The most difficult situation for AI is if Tom refers to an event every day but not today. Suppose that Tom comes in with a cup of coffee every morning. He comes in now and asks Jane if she wants some before getting some coffee. Our thought experiment is to imagine all the possible cases. In that case, the video feed in our thought experiment will reveal nothing, and we are back in chaos again. Also, the video feed can’t see if they are developers, accountants, or consultants. So, let’s take that part of context out, which leaves us with the following context. Let’s go further. The dialogue contains Tom: and Jane: So we don’t need to mention that context. We are left with:
Tom: "hi" Jane: "yeah sure" Tom: "Want some?" Jane: "Nope" Tom: "Cool. You're trying then." Jane: "Yup" Tom: "Sleep better?" Jane: "Yeah. Sure."
The output is quite astonishing. The casual language used by Jane and Tom leads GPT-3 to absurd conclusions. Remember, GPT-3 is a stochastic algorithm. The slightest change in the inputs can lead to quite different outputs. GPT-3 is trying to guess what they are talking about. GPT-3 detects that the conversation is about consuming something. Their casual language leads to nonsensical predictions about illegal substances that I am not reproducing in this section for ethical reasons.
GPT-3 determines the level of language used and associates it with related situations.
What will happen if we reproduce this same experiment using formal English?
Formal English conversation with no context
Let’s now keep all of the context out but provide formal English. Formal English contains longer sentences, good grammar, and manners. We can express the same conversation that contains no context using formal English:
Tom: "Good morning, Jane" Jane: "Good morning, Tom" Tom: "Want some as well?" Jane: "No, thank you. I'm fine." Tom: "Excellent. You are on the right track!" Jane: "Yes, I am" Tom: "Do you sleep better these days?" Jane: "Yes, I do. Thank you. "
GPT-3 naturally understands what Tom refers to with “drinking” with this level of English and good manners. The output is quite satisfactory:
Summarize: Tom says "good morning" to Jane. Tom offers her some of what he's drinking. Jane says "no, thank you. I'm fine." Tom says "excellent" and that she is on the right track. Jane says, "yes, I am." Tom asks if she sleeps better these days.
We could imagine an endless number of variations on this same conversation by introducing other people into the dialogue and other objects and generating an endless number of situations.
Let’s sum these experiments up.
Prompt engineering training
Our thoughts are often chaotic. Humans use many methods to reconstruct unstructured sentences. Humans often need to ask additional questions to understand what somebody is talking about. You need to accept this when interacting with a trained transformer such as OpenAI GPT-3.
Keep in mind that a dialogue d(T) with a transformer and the response, maxR(response), depends on the quality of your inputs, minI(prompt), as defined at the beginning of this section:
d(T)=minI(prompt) ![]() maxR(response)
maxR(response)
When minI(prompt)![]()
1, the probability of maxR(response)![]()
1.
When minI(prompt)![]()
0, the probability of maxR(response)![]()
0.
Practice prompt engineering and measure your progress in time. Prompt engineering is a new skill that will take you to the next level of AI.
The prompt engineering abilities lead to being able to master copilots.
Copilots
Welcome to the world of AI-driven development copilots powered by OpenAI and available in Visual Studio.
GitHub Copilot
Let’s begin with GitHub Copilot:
https://github.com/github/copilot-docs
In this section, we will use GitHub Copilot with PyCharm (JetBrains):
https://docs.github.com/en/copilot/getting-started-with-github-copilot
Follow the instructions in the documentation to install JetBrains and activate OpenAI GitHub Copilot in PyCharm.
Working with GitHub Copilot is a four-step process (see Figure 16.7):
- OpenAI Code generation is trained on public code and text on the internet.
- The trained model is plugged into the GitHub Copilot service.
- The GitHub service manages back-and-forth flows between code we write in an editor (in this case PyCharm) and the code generator. The GitHub Service Manager makes suggestions and then sends the interactions back for improvement.
- The code editor is our development workspace.

Figure 16.7: GitHub Copilot’s four-step process
Follow the instructions provided by GitHub Copilot, and log in to GitHub when you are in PyCharm. For any troubleshooting, read https://copilot.github.com/#faqs.
Once you are all set in the PyCharm editor, simply type:
import matplotlib.pyplot as plt
def draw_scatterplot
As soon as the code is typed, you can open the OpenAI GitHub suggestion pane and see the suggestions:
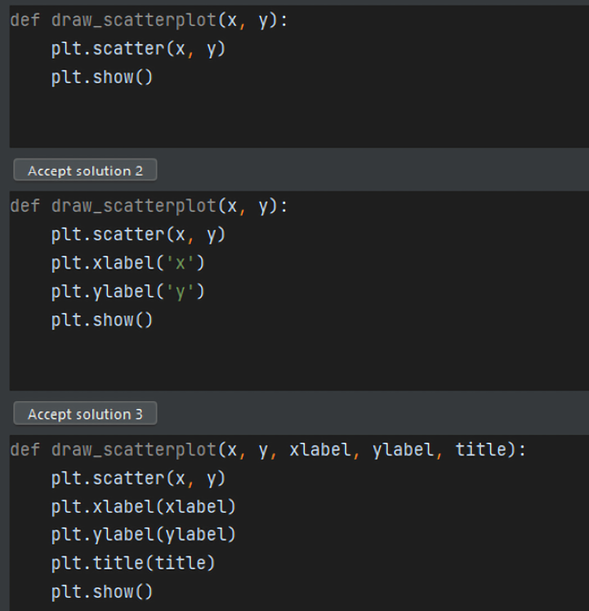
Figure 16.8: Suggestions for the code you typed
Once you choose the copilot suggestion you prefer, it will appear in the editor. You can confirm suggestions with the Tab key. You can wait for another suggestion, such as drawing a scatterplot:
import matplotlib.pyplot as plt
def draw_scatterplot(x, y):
plt.scatter(x, y)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
draw_scatterplot([1, 2, 3, 4, 5], [1, 4, 9, 16, 25])
The plot will be displayed:
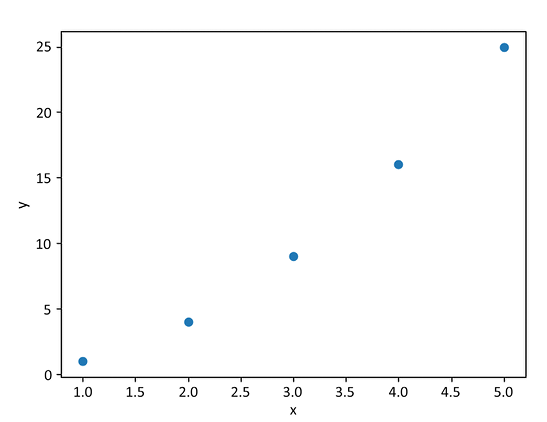
Figure 16.9: A GitHub Copilot scatterplot
You can run the result on your machine with GitHub_Copilot.py, which is in the Chapter16 folder in this book’s GitHub repository.
The technology is seamless, invisible, and will progressively expand into all areas of development. The system is packed with GPT-3 functionality along with other pipelines. The technology is available for Python, JavaScript, and more.
It will take training with prompt engineering to get used to working with GitHub Copilot driven by OpenAI.
Let’s go directly to OpenAI, which can be a good place to train using copilots.
In March 2023, Microsoft GitHub Copilot still offered Codex usage and support. Starting March 23rd, OpenAI discontinued Codex support and recommended GPT 3.5-turbo and GPT-4 instead. We will GPT-3.5-turbo and GPT-4 in Chapter 17, The Consolidation of Suprahuman Transformers with OpenAI’s ChatGPT and GPT-4.
OpenAI’s domain specific engines can provide valuable outputs to increase the performance of your projects.
Domain-specific GPT-3 engines
This section explores GPT-3 engines that can perform domain-specific tasks. We will run three models in the three subsections of this section:
- Embedding2ML to use GPT-3 to provide embeddings for ML algorithms
- Instruct series to ask GPT-3 to provide instructions for any task
- Content filter to filter bias or any form of unacceptable input and output
Open Domain_Specific_GPT_3_Functionality.ipynb.
We will begin with embedding2ML (embeddings as an input to ML).
Embedding2ML
OpenAI has trained several embedding models with different dimensions with different capabilities:
- Ada (1,024 dimensions)
- Babbage (2,048 dimensions)
- Curie (4,096 dimensions)
- Davinci (12,288 dimensions)
For more explanations on each engine, you will find more information on OpenAI’s website:
https://beta.openai.com/docs/guides/embeddings.
The Davinci model offers embedding with 12,288 dimensions. In this section, we will use the power of Davinci to generate the embeddings of a supply chain dataset. However, we will not send the embeddings to the embedding sublayer of the transformer!
We will send the embeddings to a clustering machine learning program from the scikit-learn library in six steps:
- Step 1: Installing and importing OpenAI, and entering the API key
- Step 2: Loading the dataset
- Step 3: Combining the columns
- Step 4: Running the GPT-3 embedding
- Step 5: Clustering (k-means) with the embeddings
- Step 6: Visualizing the clusters (t-SNE)
The process is summed up in Figure 16.10:

Figure 16.10: Six-step process for sending embeddings to a clustering algorithm
Open the Google Colab file, Domain_Specific_GPT_3_Functionality.ipynb and go to the Embedding2ML with GPT-3 engine section of the notebook.
The steps described in this section match the notebook cells. Let’s go through a summary of each step of the process.
Step 1: Installing and importing OpenAI
Let’s start with the following substeps:
- Run the cell
- Restart the runtime
- Run the cell again to make sure since you restarted the runtime:
try: import openai except: !pip install openai import openai - Enter the API key:
openai.api_key="[YOUR_KEY]"
Step 2: Loading the dataset
Load your file before running the cell. I uploaded tracking.csv (available in the GitHub repository of this book), which contains SCM data:
import pandas as pd
df = pd.read_csv('tracking.csv', index_col=0)
The data contains seven fields:
IdTimeProductUserScoreSummaryText
Let’s print the first few lines using the following command:
print(df)
Time Product User Score Summary Text
Id
1 01/01/2016 06:30 WH001 C001 4 on time AGV1
2 01/01/2016 06:30 WH001 C001 8 late R1 NaN
3 01/01/2016 06:30 WH001 C001 2 early R15 NaN
4 01/01/2016 06:30 WH001 C001 10 not delivered R20 NaN
5 01/01/2016 06:30 WH001 C001 1 on time R3 NaN
... ... ... ... ... ... ... ...
1049 01/01/2016 06:30 WH003 C002 9 on time AGV5 NaN
1050 01/01/2016 06:30 WH003 C002 2 late AGV10 NaN
1051 01/01/2016 06:30 WH003 C002 1 early AGV5 NaN
1052 01/01/2016 06:30 WH003 C002 6 not delivered AGV2 NaN
1053 01/01/2016 06:30 WH003 C002 3 on time AGV2 NaN
[1053 rows x 7 columns]
We can combine columns to build the clusters we wish.
Step 3: Combining the columns
We can combine the Product column with Summary to obtain a view of products and their delivery status. Remember that this is only an experimental exercise. In a real-life project, carefully analyze and decide on the columns you wish to combine.
The following example code can be replaced with any choice you make for your experimentation:
df['combined'] = df.Summary.str.strip()+ "-" + df.Product.str.strip()
print(df)
We can now see a new column named combined:
Time Product User ... Text combined
Id ...
1 01/01/2016 06:30 WH001 C001 ... AGV1 on time-WH001
2 01/01/2016 06:30 WH001 C001 ... R1 NaN late-WH001
3 01/01/2016 06:30 WH001 C001 ... R15 NaN early-WH001
4 01/01/2016 06:30 WH001 C001 ... R20 NaN not delivered-WH001
5 01/01/2016 06:30 WH001 C001 ... R3 NaN on time-WH001
... ... ... ... ... ... ... ...
1049 01/01/2016 06:30 WH003 C002 ... AGV5 NaN on time-WH003
1050 01/01/2016 06:30 WH003 C002 ... AGV10 NaN late-WH003
1051 01/01/2016 06:30 WH003 C002 ... AGV5 NaN early-WH003
1052 01/01/2016 06:30 WH003 C002 ... AGV2 NaN not delivered-WH003
1053 01/01/2016 06:30 WH003 C002 ... AGV2 NaN on time-WH003
[1053 rows x 8 columns]
We will now run the embedding model on the combined column.
Step 4: Running the GPT-3 embedding
We will now run the davinci-similarity model to obtain 12,288 dimensions for the combined column:
import time
import datetime
# start time
start = time.time()
def get_embedding(text, engine="davinci-similarity"):
text = text.replace("
", " ")
return openai.Engine(id=engine).embeddings(input = [text])['data'][0]['embedding']
df['davinci_similarity'] = df.combined.apply(lambda x: get_embedding(x, engine='davinci-similarity'))
# end time
end = time.time()
etime=end-start
conversion = datetime.timedelta(seconds=etime)
print(conversion)
print(df)
The result is impressive. We have 12,288 dimensions for the combined column:
0:04:44.188250
Time ... davinci_similarity
Id ...
1 01/01/2016 06:30 ... [-0.0047378824, 0.011997132, -0.017249448, -0....
2 01/01/2016 06:30 ... [-0.009643857, 0.0031537763, -0.012862709, -0....
3 01/01/2016 06:30 ... [-0.0077407444, 0.0035147679, -0.014401976, -0...
4 01/01/2016 06:30 ... [-0.007547746, 0.013380095, -0.018411927, -0.0...
5 01/01/2016 06:30 ... [-0.0047378824, 0.011997132, -0.017249448, -0....
... ... ... ...
1049 01/01/2016 06:30 ... [-0.0027823148, 0.013289047, -0.014368941, -0....
1050 01/01/2016 06:30 ... [-0.0071367626, 0.0046446105, -0.010336877, 0....
1051 01/01/2016 06:30 ... [-0.0050991694, 0.006131069, -0.0138306245, -0...
1052 01/01/2016 06:30 ... [-0.0066779135, 0.014575769, -0.017257102, -0....
1053 01/01/2016 06:30 ... [-0.0027823148, 0.013289047, -0.014368941, -0....
[1053 rows x 9 columns]
We now need to convert the result into a numpy matrix:
#creating a matrix
import numpy as np
matrix = np.vstack(df.davinci_similarity.values)
matrix.shape
The matrix has a shape of 1,053 records x 12,288 dimensions, which is quite impressive:
(1053, 12288)
The matrix is now ready to be sent to a scikit-learn machine-learning clustering algorithm.
Step 5: Clustering (k-means clustering) with the embeddings
We usually send classical datasets to a k-means clustering algorithm. We will send a 12,288-dimension dataset to the ML algorithm, not to the next sublayer of the transformer.
We first import k-means from scikit-learn:
from sklearn.cluster import KMeans
We now run a classical k-means clustering algorithm with our 12,288-dimension dataset:
n_clusters = 4
kmeans = KMeans(n_clusters = n_clusters,init='k-means++',random_state=42)
kmeans.fit(matrix)
labels = kmeans.labels_
df['Cluster'] = labels
df.groupby('Cluster').Score.mean().sort_values()
The output is four clusters as requested:
Cluster
2 5.297794
0 5.323529
1 5.361345
3 5.741697
We can print the labels for the content of the dataset:
print(labels)
The output is:
[2 3 0 ... 0 1 2]
Let’s now visualize the clusters using t-SNE.
Step 6: Visualizing the clusters (t-SNE)
t-SNE keeps local similarities. PCA maximizes large pairwise distances. In this case, smaller pairwise distances.
The notebook will use matplotlib to display t-SNE:
from sklearn.manifold import TSNE
import matplotlib
import matplotlib.pyplot as plt
Before visualizing we need to run the t-SNE algorithm:
#t-SNE
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims2 = tsne.fit_transform(matrix)
We can now display the results in matplotlib:
x = [x for x,y in vis_dims2]
y = [y for x,y in vis_dims2]
for category, color in enumerate(['purple', 'green', 'red', 'blue']):
xs = np.array(x)[df.Cluster==category]
ys = np.array(y)[df.Cluster==category]
plt.scatter(xs, ys, color=color, alpha=0.3)
avg_x = xs.mean()
avg_y = ys.mean()
plt.scatter(avg_x, avg_y, marker='x', color=color, s=100)
plt.title("Clusters of embeddings-t-SNE")
The plot shows the clusters with many data points piled up around them. There are also many data points circled around the clusters attached to the closest centroid:
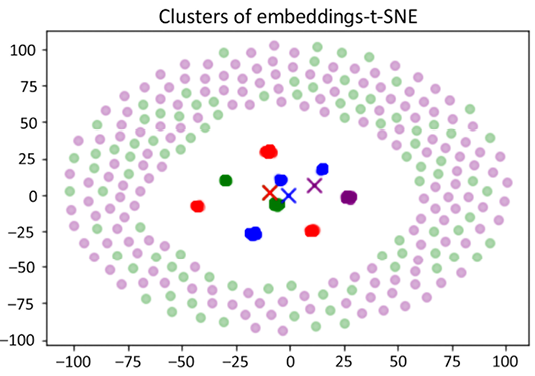
Figure 16.11: Clusters of embeddings-t-SNE
We ran a large GPT-3 model to embed 12,288 dimensions. Then we plugged the result into a clustering algorithm. The potential of combining transformers and machine learning is endless!
You can go to the Peeking into the embeddings section of the notebook if you wish to peek into the data frames.
Let’s now have a look at the instruct series.
Instruct series
Personal assistants, avatars in metaverses, websites, and many other domains will increasingly need to provide clear instructions when a user asks for help. Go to the instruct series section of Domain_Specific_GPT_3_Functionality.ipynb.
In this section, we will ask a transformer to explain how to set up parent control in Microsoft Edge with the following prompt: Explain how to set up parent control in Edge.
We first run the completion cell:
import os
import openai
os.environ['OPENAI_API_KEY'] ='[YOUR_API_KEY]'
print(os.getenv('OPENAI_API_KEY'))
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Completion.create(
engine="davinci-instruct-beta",
prompt="Explain how to set up parent control in Edge.
ACTIONS:",
temperature=0,
max_tokens=120,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
r = (response["choices"][0])
print(r["text"])
The response is a list of instructions as requested:
1. Start Internet Explorer.
2. Click on the tools menu.
3. Click on the Internet options.
4. Click on the advanced tab.
5. Click to clear or select the enable personalized favorite menu check box.
The number of instructions you can ask for is unlimited! Use your creativity and imagination to find more examples!
Sometimes the input or the output is not acceptable. Let’s see how to implement a content filter.
Content filter
Bias, unacceptable language, and any form of unethical input should be excluded from your AI applications.
One of OpenAI’s trained models is a content filter. We will run an example in this section. Go to the content filter section of Domain_Specific_GPT_3_Functionality.ipynb.
My recommendation is to filter the input and the output, as shown in Figure 16.12:
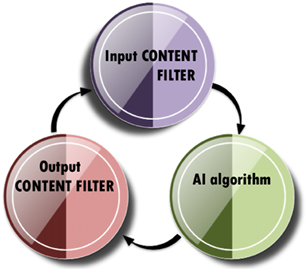
Figure 16.12: Implementing a content filter
My recommendation is to implement a three-step process:
- Apply a content filter to ALL input data
- Let the AI algorithm run as trained
- Apply a content filter to ALL output data
In this section, the input and output data will be named content.
Take an obnoxious input as the following one:
content = "Small and fat children should not play basketball at school."
This input is unacceptable! School is not the NBA. Basketball should remain a nice exercise for everyone.
Let’s now run the content filter in the cell - content-filter-alpha:
response = openai.Completion.create(
engine="content-filter-alpha",
prompt = "<|endoftext|>"+content+"
--
Label:",
temperature=0,
max_tokens=1,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
logprobs=10
)
The content filter stores the result in response, a dictionary object. We retrieve the value of choice to obtain the level of acceptability:
r = (response["choices"][0])
print("Content filter level:", r["text"])
The content filter sends one of three values back:
0– Safe1– Sensitive2– Unsafe
In this case, the result is 2, of course:
Content filter level: 2
The content filter might not be sufficient. I recommend adding other algorithms to control and filter input/output content: rule bases, dictionaries, and other methods.
Now that we have explored domain-specific models, let’s build a transformer-based recommender system.
Transformer-based recommender systems
Transformer models learn sequences. Learning language sequences is a great place to start considering the billions of messages posted on social media and cloud platforms each day. Consumer behaviors, images, and sounds can also be represented in sequences.
In this section, we will first create a general-purpose sequence graph and then build a general-purpose transformer-based recommender in Google Colaboratory. We will then see how to deploy them in metahumans.
Let’s first define general-purpose sequences.
General-purpose sequences
Many activities can be represented by entities and links between them. They are thus organized in sequences. For example, a video on YouTube can be an entity A, and the link can be the behavior of a person going from video A to video E.
Another example is a bad fever being an entity F, and the link being the inference a doctor may make leading to a micro-decision B. The purchase of product D on Amazon by a consumer can generate a link to a suggestion C or another product. The examples are infinite!
We can define the entities in this section with six letters:
E={A,B,C,D,E,F}
When we speak a language, we follow grammar rules and cannot escape them.
For example, suppose A=” I”, E=” eat”, and D=” candy”. There is only one proper sequence to express the fact that I consume candy: “I eat candy.”
If somebody says “eat candy I,” it will sound slightly off.
In this sequence, the links representing those rules are:
A->E (I eat)
E->D(eat candy)
We can automatically infer rules in any domain by observing behaviors, learning datasets with ML, or manually listening to experts.
In this section, we will suppose that we have observed a YouTube user for several months who spends several hours watching videos. We have noticed that the user systematically goes from one type of video to another. For example, from the video of singer B to the video of singer D. The behavior rules X of this person P seem to be:
X(P)={AE,BD,BF,C,CD,DB,DC,DE,EA,ED,FB}
We can represent this system of entities as vertices in a graph and the links as edges. For example, if we apply X(P) to the vertices, we obtain the following undirected graph:
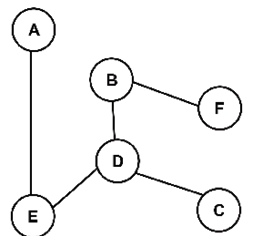
Figure 16.13: Graph of YouTube user’s video combinations
Suppose the vertices are videos of a viewer’s favorite singers and that C is the singer the viewer prefers. We can give a value of 1 to the statistical transitions (links or edges) the viewer made in the past weeks. We can also give a value of 100 to the viewer’s favorite singer’s videos.
For this viewer, the path is represented by the (edges, vertices) values V(R(P)):
V(X(P))={AE=1,BD=1,BF=1,C=100,CD=1,DB=1,DE=1,EA=1,ED=1,FB=1}
The goal of a recommender is thus to suggest sequences that lead to videos of singer C or suggest C directly in some cases.
We can represent the undirected graph in reward matrix R:
A,B,C,D,E,F
R = ql.matrix([ [0,0,0,0,1,0], A
[0,0,0,1,0,1], B
[0,0,100,1,0,0], C
[0,1,1,0,1,0], D
[1,0,0,1,0,0], E
[0,1,0,0,0,0]]) F
Let’s use this reward matrix to simulate the activity of a viewer X over several months.
Dataset pipeline simulation with RL using an MDP
In this section, we will simulate the behavior X of a person P watching videos of songs on YouTube, which we define as X(P). We will determine the values of the behavior of P as V(X(P)). We will then organize the values in a reward matrix R for a Markov Decision Process (MDP) that we will now implement in a Bellman equation.
Open KantaiBERT_Recommender.ipynb, which is in this chapter’s folder in the book’s GitHub repository. The notebook is a modification of KantaiBERT.ipynb described in Chapter 4, Pretraining a RoBERTa Model from Scratch.
In Chapter 4, we trained a transformer using kant.txt, which contained some of the works of Immanuel Kant. In this section, we will generate thousands of sequences of a person’s behavior through reinforcement learning (RL). RL is not in the scope of this book, but this section contains some reminders.
The first step is to train a transformer model to learn and simulate a person’s behavior.
Training customer behaviors with an MDP
KantaiBERT.ipynb in Chapter 4 began by loading kant.txt to train a RoBERTa with a DistilBERT architecture. kant.txt contained works by Immanuel Kant. In this section, we will generate sequences using the reward matrix R defined in the General-purpose sequences section of this chapter:
R = ql.matrix([ [0,0,0,0,1,0],
[0,0,0,1,0,1],
[0,0,100,1,0,0],
[0,1,1,0,1,0],
[1,0,0,1,0,0],
[0,1,0,0,0,0]])
The first cell of the program is thus:
Step 1A Training: Dataset Pipeline Simulation with RL using an MDP:
This cell implements an MDP using the Bellman equation:
# The Bellman MDP based Q function
Q[current_state, action] = R[current_state, action] + gamma * MaxValue
In this equation:
Ris the original reward matrix.Qis the updated matrix, which is the same size asR. However, it is updated through reinforcement learning to compute the relative value of the link (edge) between each entity (vertex).gammais a learning rate set to0.8to avoid overfitting the training process.MaxValueis the maximum value of the next vertex. For example, if the viewerPof YouTube videos is viewing singerA, the program might increase the value ofEso that this suggestion can appear as a recommendation.
Little by little, the program will try to find the best values to help a viewer find the best videos to watch. Once the reinforcement program has learned the best links (edges), it can recommend the best viewing sequences.
The original reward matrix has been trained to become an operational matrix. If we add the original entities, the trained values clearly appear:
A B C D E F
[[ 0. 0. 0. 0. 258.44 0. ] A
[ 0. 0. 0. 321.8 0. 207.752] B
[ 0. 0. 500. 321.8 0. 0. ] C
[ 0. 258.44 401. 0. 258.44 0. ] D
[207.752 0. 0. 321.8 0. 0. ] E
[ 0. 258.44 0. 0. 0. 0. ]] F
The original sequences of values V of the behaviors X of person P were:
V(X(P))={AE=1,BD=1,BF=1,C=100, CD=1,DB=1,DE=1,EA=1,ED=1,FB=1}
They have been trained to become:
V(X(P))={AE=259.44, BD=321.8 ,BF=207.752, C=500, CD=321.8 ,DB=258.44, DE=258.44, EA=207.752, ED=321.8, FB=258.44}
This is quite a change!
Now, it becomes possible to recommend a sequence of exciting videos of P’s preferred singers. Suppose P views a video of singer E. Line E of the trained matrix will recommend a video of the highest value of that line, which is D=321.8. Thus, a video of singer D will appear in the YouTube feed of person P.
The goal of this section is not to stop at this phase. Instead, this section uses an MDP to create meaningful sequences to create a dataset for the transformer to use for training.
YouTube does not need to generate sequences to create a dataset. YouTube stores all the behaviors of all viewers in big data. Then Google’s powerful algorithms take over to recommend the best videos in the video feed of a viewer.
Other platforms use cosine similarity as implemented in Chapter 9, Matching Tokenizers and Datasets, to make predictions.
The MDP could have been trained for YouTube viewers, Amazon buyers, Google search results, a doctor’s diagnosis path, a supply chain, and any type of sequence. Transformers are taking sequence learning, training, and predictions to another level.
Let’s implement a simulation to create behavior sequences for a transformer model.
Simulating consumer behavior with an MDP
Once the RL part of the program is trained in cell 1, cell 2, Step 1B Applying: Dataset Pipeline Simulation with MDP will simulate a YouTube viewer’s behavior over several months. It will also include similar viewer profiles adding up to a simulation of 10,000 sequences of video watching.
Cell 2 begins by creating the kant.txt file that will be used to train the KantaiBERT transformer model:
""" Simulating a decision-making process"""
f = open("kant.txt", "w")
Then the entities (vertices) are introduced:
conceptcode=["A","B","C","D","E","F"]
Now the number of sequences is set to 10,000:
maxv=10000
The function chooses a random start vertex named origin:
origin=ql.random.randint(0,6)
The program uses the trained matrix to select the best sequence for any domain from that point of origin. In this case, we suppose they are the favorite singers of a person such as the following examples:
FBDC EDC EDC DC BDC AEDC AEDC BDC BDC AEDC BDC AEDC EDC BDC AEDC DC AEDC DC…/…
Once 10,000 sequences have been calculated, kant.txt contains a dataset for the transformer.
With kant.txt, the remaining cells of the program are the same as in KantaiBERT.ipynb described in Chapter 4, Pretraining a RoBERTa Model from Scratch.
The transformer is now ready to make recommendations.
Making recommendations
In Chapter 4, KantaiBERT.ipynb contained the following masked sequence:
fill_mask("Human thinking involves human<mask>.")
This sequence is specific and related to Immanuel Kant’s works. This notebook has a general-purpose dataset that can be used in any domain.
In this notebook, the input is:
fill_mask("BDC<mask>.")
The output contains duplicates. It will take a cleaning function to filter them to obtain two non-duplicate sequences:
[{'score': 0.00036507684853859246,
'sequence': 'BDC FBDC.',
'token': 265,
'token_str': ' FBDC'},
{'score': 0.00023987806343939155,
'sequence': 'BDC DC.',
'token': 271,
'token_str': ' DC'}]
The sequences make sense. Sometimes a viewer will watch the same videos, sometimes not. The behavior can be chaotic. That’s where machine learning comes in and how AI can be used in metahumans.
Metahuman recommenders
Once the sequences have been generated, they will be converted back into natural language for user interfaces. Metahuman, in this section, refers to a recommender that takes large amounts of features that:
- Exceed human capacity to reason with that many parameters
- Lead to more accurate predictions than a human can make
These pragmatic metahumans are not digital humans yet in this context but powerful computing tools. We will go through metahumans in the digital sense in the Humans and AI copilots in metaverses section.
For example, the BDC sequences could be a song by singer B, followed by singer D, and then P’s favorite singer C.
Once the sequence is converted into natural language, several options are possible:
- The sequence can be sent to a bot or a digital human.
When an emerging technology appears, jump on the train and take the ride! You will get to know this technology and evolve with it. You can google other metahuman platforms. In any case, you can remain on the cutting edge by learning how to circumvent limits and find ways to use new technology.
- You can use the metahuman as an educational video while waiting for an API.
- A metahuman can be inserted into an interface as a voice message. For example, when using Google Maps in a car, you listen to the voice. It sounds like a human. We even slip and sometimes think it’s a person, but it isn’t. It’s a machine.
- It can also be an invisibly embedded suggestion in Amazon. It remains something that makes recommendations that lead us to make micro-decisions. It influences us as a salesperson would do. It’s an invisible metahuman.
In this case, the general-purpose sequences were created by an MDP and trained by a RoBERTa transformer. This shows that transformers can be applied to any type of sequence.
Let’s see how transformers are applied to computer vision.
Computer vision
This book is about NLP, not computer vision. However, in the previous section, we implemented general-purpose sequences that can be applied to many domains. Computer vision is one of them.
The title of the article by Dosovitskiy et al. (2021) says it all: An image is worth 16x16 words: Transformers for Image Recognition at Scale. The authors processed an image as sequences. The results proved their point.
Google has made vision transformers available in a Colaboratory notebook. Open Vision_Transformer_MLP_Mixer.ipynb in the Chapter16 directory of this book’s GitHub repository.
If you have trouble running this notebook, try running the Compact_Convolutional_Transformers.ipynb notebook instead
Open Vision_Transformer_MLP_Mixer.ipynb contains a transformer computer vision model in JAX(). JAX combines Autograd and XLA. JAX can differentiate Python and NumPy functions. JAX speeds up Python and NumPy by using compilation techniques and parallelization.
The notebook is self-explanatory. You can explore it to see how it works. However, bear in mind that when Industry 4.0 reaches maturity and Industry 5.0 kicks in, the best implementations will be obtained by integrating your data on Cloud AI platforms. Local development will diminish, and companies will turn to Cloud AI without bearing local development, maintenance, and support.
The notebook’s table of contents contains a transformer process we have gone through several times in this book. However, this time, it’s simply applied to sequences of digital image information:

Figure 16.14: Our vision transformer notebook
The notebook follows standard deep learning methods. It shows some images with labels:
# Show some images with their labels.
images, labels = batch['image'][0][:9], batch['label'][0][:9]
titles = map(make_label_getter(dataset), labels.argmax(axis=1))
show_img_grid(images, titles)

Figure 16.15: Images with labels
The images in this chapter are from Learning Multiple Layers of Features from Tiny Images, Alex Krizhevsky, 2009: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf. They are part of the CIFAR-10 and CIFAR-100 datasets (toronto.edu): https://www.cs.toronto.edu/~kriz/cifar.html.
The notebook contains the standard transformer process and then displays the training images:
# Same as above, but with train images.
# Note how images are cropped/scaled differently.
# Check out input_pipeline.get_data() in the editor at your right to see how the
# images are preprocessed differently.
batch = next(iter(ds_train.as_numpy_iterator()))
images, labels = batch['image'][0][:9], batch['label'][0][:9]
titles = map(make_label_getter(dataset), labels.argmax(axis=1))
show_img_grid(images, titles)

Figure 16.16: Trained data
Transformer programs can classify random pictures. It seems like a miracle to take a transformer model originally designed for NLP and use it for general-purpose sequences for recommenders and then for computer vision. However, we are just beginning to explore the generalization of sequences training.
The simplicity of the model is surprising! The vision transformer relies on the architecture of transformers. It does not contain the complexity of convolutional neural networks. Yet, it produces comparable results.
Now, robots and bots can be equipped with transformer models to understand language and interpret images to understand the world around them.
Vision transformers can be implemented in metahumans and metaverses.
Humans and AI copilots in metaverses
Humans and metahuman AI are merging into metaverses. Exploring metaverses is beyond the scope of this book. The toolbox provided by this book shows the path to metaverses populated by humans and metahuman AI.
Avatars, computer vision, and video game experience will make our communication with others immersive. We will go from looking at smartphones to being in locations with others.
From looking at to being in
The evolution from looking at to being in is a natural one. We invented computers, added screens, then invented smartphones, and now use apps for video meetings.
Now we can enter virtual reality for all types of meetings and activities.
We will use Facebook’s metaverse, for example, on our smartphone to feel present in the same location as the people (personal and professional) we meet. Feeling present will no doubt be a major evolution in smartphone communication.
Feeling present somewhere is quite different from looking at a small screen on a mobile.
The metaverse will make the impossible possible: a spacewalk, surfing on huge waves, walking in a forest, visiting dinosaurs, and wherever our imagination takes us.
Yes, there are limits, dangers, threats, and everything that goes with human technology. However, we can use AI to control AI, as we saw with content filtering.
The transformer tools in this book added to the emerging metaverse technology will take us literally to another world.
Make good use of the knowledge and skills you acquired in this book to create your ethical future in a metaverse or the physical world!
Summary
This chapter described the rise of AI copilots with human-decision-making-level capability. Industry 4.0 has opened the door to machine interconnectivity. Machine-to-machine micro-decision-making will speed up transactions. AI copilots will boost our productivity in a wide range of domains.
We saw how to use OpenAI Instruct models to generate source code while we code and even with natural language instructions.
We built a transformer-based recommender system using a dataset generated by the MDP program to train a RoBERTa transformer model. The dataset structure was a multi-purpose sequence model. A metahuman can thus acquire multi-domain recommender functionality.
The chapter then showed how a vision transformer could classify images processed as sequences of information.
Finally, we saw that the metaverse would make recommendations visible through a metahuman interface or invisible in deeply embedded functions in social media, for example.
Transformers have emerged with innovating copilots and models in an incredibly complex new era. Let’s continue this challenging and exciting journey in Chapter 17, The Consolidation of Suprahuman Transformers with OpenAI’s ChatGPT and GPT-4.
Questions
- AI copilots that can generate code automatically do not exist. (True/False)
- AI copilots will never replace humans. (True/False)
- GPT-3 engines can only do one task. (True/False)
- Transformers can be trained to be recommenders. (True/False)
- Transformers can only process language. (True/False)
- A transformer sequence can only contain words. (True/False)
- Vision transformers cannot equal CNNs. (True/False)
- AI robots with computer vision do not exist. (True/False)
- It is impossible to produce Python source code automatically. (True/False)
- We might one day become the copilots of robots. (True/False)
References
- OpenAI platform for GPT-3: https://openai.com
- OpenAI models and engines: https://beta.openai.com/docs/engines
- Vision Transformers: Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby, 2020, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929
- JAX for vision transformers: https://github.com/google/jax
- OpenAI, Visual Studio Copilot: https://copilot.github.com/
- Facebook metaverse: https://www.facebook.com/Meta/videos/577658430179350
- Markov Decision Process (MDP), examples and graph: Denis Rothman, 2020, Artificial Intelligence by Example, 2nd Edition: https://www.amazon.com/Artificial-Intelligence-Example-advanced-learning/dp/1839211539/ref=sr_1_3?crid=238SF8FPU7BB0&keywords=denis+rothman&qid=1644008912&sprefix=denis+rothman%2Caps%2C143&sr=8-3
Join our book’s Discord space
Join the book’s Discord workspace:
https://www.packt.link/Transformers
