
14
Interpreting Black Box Transformer Models
Million- to billion-parameter transformer models seem like huge black boxes that nobody can interpret. As a result, many developers and users have sometimes been discouraged when dealing with these mind-blowing models. However, recent research has begun to solve the problem with innovative, cutting-edge tools.
It is beyond the scope of this book to describe all of the explainable AI methods and algorithms. So instead, this chapter will focus on ready-to-use visual interfaces that provide insights for transformer model developers and users.
The chapter begins by installing and running BertViz by Jesse Vig. Jesse did quite an excellent job of building a visual interface that shows the activity in the attention heads of a BERT transformer model. BertViz interacts with the BERT models and provides a well-designed interactive interface.
We will continue to focus on visualizing the activity of transformer models with the Language Interpretability Tool (LIT). LIT is a non-probing tool that can use PCA or UMAP to represent transformer model predictions. We will go through PCA and use UMAP as well.
Finally, we will visualize a transformer’s journey through the layers of a BERT model with dictionary learning. Local Interpretable Model-agnostic Explanations (LIME) provides practical functions to visualize how a transformer learns how to understand language. The method shows that transformers often begin by learning a word, then the word in the sentence context, and finally long-range dependencies.
By the end of the chapter, you will be able to interact with users to show visualizations of the activity of transformer models. BertViz, LIT, and visualizations through dictionary learning still have a long way to go. However, these nascent tools will help developers and users understand how transformer models work.
This chapter covers the following topics:
- Installing and running BertViz
- Running BertViz’s interactive interface
- The difference between probing and non-probing methods
- A Principal Component Analysis (PCA) reminder
- Running LIT to analyze transformer outputs
- Introducing LIME
- Running transformer visualization through dictionary learning
- Word-level polysemy disambiguation
- Visualizing low-level, mid-level, and high-level dependencies
- Visualizing key transformer factors
Our first step will begin by installing and using BertViz.
Transformer visualization with BertViz
Jesse Vig’s article, A Multiscale Visualization of Attention in the Transformer Model, 2019, recognizes the effectiveness of transformer models. However, Jesse Vig explains that deciphering the attention mechanism is challenging. The paper describes the process of BertViz, a visualization tool.
BertViz can visualize attention head activity and interpret a transformer model’s behavior.
BertViz was first designed to visualize BERT and GPT-3 models. In this section, we will visualize the activity of a BERT model.
Let’s now install and run BertViz.
Running BertViz
It only takes five steps to visualize transformer attention heads and interact with them.
Open the BertViz.ipynb notebook in the Chapter14 directory in the GitHub repository of this book.
The first step is to install BertViz and the requirements.
Step 1: Installing BertViz and importing the modules
The notebook installs BertViz, Hugging Face transformers, and the other basic requirements to implement the program:
!pip install bertViz
from bertViz import head_view, model_view
from transformers import BertTokenizer, BertModel
The head view and model view libraries are now imported. We will now load the BERT model and tokenizer.
Step 2: Load the models and retrieve attention
BertViz supports BERT, GPT-2, RoBERTa, and other models. You can consult BertViz on GitHub for more information: https://github.com/jessevig/BertViz.
In this section, we will run a bert-base-uncased model and a pretrained tokenizer:
# Load model and retrieve attention
model_version = 'bert-base-uncased'
do_lower_case = True
model = BertModel.from_pretrained(model_version, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_version, do_lower_case=do_lower_case)
We now enter our two sentences. You can try different sequences to analyze the behavior of the model. sentence_b_start will be necessary for Step: 5 Model view:
sentence_a = "A lot of people like animals so they adopt cats"
sentence_b = "A lot of people like animals so they adopt dogs"
inputs = tokenizer.encode_plus(sentence_a, sentence_b, return_tensors='pt', add_special_tokens=True)
token_type_ids = inputs['token_type_ids']
input_ids = inputs['input_ids']
attention = model(input_ids, token_type_ids=token_type_ids)[-1]
sentence_b_start = token_type_ids[0].tolist().index(1)
input_id_list = input_ids[0].tolist() # Batch index 0
tokens = tokenizer.convert_ids_to_tokens(input_id_list)
And that’s it! We are ready to interact with the visualization interface.
Step 3: Head view
We just have one final line to add to activate the visualization of the attention heads:
head_view(attention, tokens)
The words of the first layer (layer 0) are not the actual tokens, but the interface is educational. The 12 attention heads of each layer are displayed in different colors. The default view is set to layer 0, as shown in Figure 14.1:

Figure 14.1: The visualization of attention heads
We are now ready to explore attention heads.
Step 4: Processing and displaying attention heads
Each color above the two columns of tokens represents an attention head of the layer number. Choose a layer number and click on an attention head (color).
The words in the sentences are broken down into tokens in the attention. However, in this section, the word tokens loosely refers to words to help us understand how the transformer heads work.
I focused on the word animals in Figure 14.2:

Figure 14.2: Selecting a layer, an attention head, and a token
BertViz shows that the model made a connection between animals and several words. This is normal since we are only at layer 0.
Layer 1 begins to isolate words animals is related to, as shown in Figure 14.3:

Figure 14.3: Visualizing the activity of attention head 11 of layer 1
Attention head 11 makes a connection between animals, people, and adopt.
If we click on cats, some interesting connections are shown in Figure 14.4:

Figure 14.4: Visualizing the connections between cats and other tokens
The word cats is now associated with animals. This connection shows that the model is learning that cats are animals.
You can change the sentences and then click on the layers and attention heads to visualize how the transformer makes connections. You will find limits, of course. The good and bad connections will show you how transformers work and fail. Both cases are valuable for explaining how transformers behave and why they require more layers, parameters, and data.
Let’s see how BertViz displays the model view.
Step 5: Model view
It only takes one line to obtain the model view of a transformer with BertViz:
model_view(attention, tokens, sentence_b_start)
BertViz displays all of the layers and heads in one view, as shown in the view excerpt in Figure 14.5:

Figure 14.5: Model view mode of BertViz
If you click on one of the heads, you will obtain a head view with word-to-word and sentence-to-sentence options. You can then go through the attention heads to see how the transformer model makes better representations as it progresses through the layers. For example, Figure 14.6 shows the activity of an attention head in the first layers:

Figure 14.6: Activity of an attention head in the lower layers of the model
Sometimes, the representation makes connections between the separator, [SEP], and words, which does not make much sense. However, sometimes tokens are not activated in every attention head of every layer. Also, the level of training of a transformer model limits the quality of the interpretation.
In any case, BertViz remains an interesting educational tool and interpretability tool for transformer models.
Let’s now run the intuitive LIT tool.
LIT
LIT’s visual interface will help you find examples that the model processes incorrectly, dig into similar examples, see how the model behaves when you change a context, and more language issues related to transformer models.
LIT does not display the activities of the attention heads like BertViz does. However, it’s worth analyzing why things went wrong and trying to find solutions.
You can choose a Uniform Manifold Approximation and Projection (UMAP) visualization or a PCA projector representation. PCA will make more linear projections in specific directions and magnitude. UMAP will break its projections down into mini-clusters. Both approaches make sense depending on how far you want to go when analyzing the output of a model. You can run both and obtain different perspectives of the same model and examples.
This section will use PCA to run LIT. Let’s begin with a brief reminder of how PCA works.
PCA
PCA takes data and represents it at a higher level.
Imagine you are in your kitchen. Your kitchen is a 3D cartesian coordinate system. The objects in your kitchen are all at specific x, y, z coordinates too.
You want to cook a recipe and gather the ingredients on your kitchen table. Your kitchen table is a higher-level representation of the recipe in your kitchen.
The kitchen table is using a cartesian coordinate system too. But when you extract the main features of your kitchen to represent the recipe on your kitchen table, you are performing PCA. This is because you have displayed the principal components that fit together to make a specific recipe.
The same representation can be applied to NLP. For example, a dictionary is a list of words. But the words that mean something together constitute a representation of the principal components of a sequence.
The PCA representation of sequences in LIT will help visualize the outputs of a transformer.
The main steps to obtain an NLP PCA representation are:
- Variance: The numerical variance of a word in a dataset; the frequency and frequency of its meaning, for example.
- Covariance: The variance of more than one word is related to that of another word in the dataset.
- Eigenvalues and eigenvectors: To obtain a representation in the cartesian system, we need the vectors and magnitudes representation of the covariances. The eigenvectors will provide the direction of the vectors. The eigenvalues will provide their magnitudes.
- Deriving the data: The last step is to apply the feature vectors to the original dataset by multiplying the row feature vector by the row data:
- Data to display = row of feature vector * row of data
PCA projections provide a clear linear visualization of the data points to analyze.
Let’s now run LIT.
Running LIT
You can run LIT online or open it in a Google Colaboratory notebook. Click on the following link to access both options:
The tutorial page contains several types of NLP tasks to analyze:
In this section, we will run LIT online and explore a sentiment analysis classifier:
Click on Explore this demo yourself, and you will enter the intuitive LIT interface. The transformer model is a small transformer model:

Figure 14.7: Selecting a model
You can change the model by clicking on the model. You can test this type of model and similar ones directly on Hugging Face on its hosted API page:
https://huggingface.co/sshleifer/tiny-distilbert-base-uncased-finetuned-sst-2-english
The NLP models might change on LIT’s online version based on subsequent updates. The concepts remain the same, just the models change.
Let’s begin by selecting the PCA projector and the binary 0 or 1 classification label of the sentiment analysis of each example:

Figure 14.8: Selecting the projector and type of label
We then go to the data table and click on a sentence and its classification label:

Figure 14.9: Selecting a sentence
The algorithm is stochastic so the output can vary from one run to another.
The sentence will also appear in the datapoint editor:

Figure 14.10: Datapoint editor
The datapoint editor allows you to change the context of the sentence. For example, you might want to find out what went wrong with a counterfactual classification that should have been in one class but ended up in another one. You can change the context of the sentence until it appears in the correct class to understand how the model works and why it made a mistake.
The sentence will appear in the PCA projector with its classification:

Figure 14.11: PCA projector in a positive cluster
You can click the data points in the PCA projector, and the sentences will appear in the datapoint editor under the sentence you selected. That way, you can compare results.
LIT contains a wide range of interactive functions you can explore and use.
The results obtained in LIT are not always convincing. However, LIT provides valuable insights in many cases. Also, it is essential to get involved in these emerging tools and techniques.
Let’s now visualize transformer layers through dictionary learning.
Transformer visualization via dictionary learning
Transformer visualization via dictionary learning is based on transformer factors.
Transformer factors
A transformer factor is an embedding vector that contains contextualized words. A word with no context can have many meanings, creating a polysemy issue. For example, the word separate can be a verb or an adjective. Furthermore, separate can mean disconnect, discriminate, scatter, and has many other definitions.
Yun et al., 2021, thus created an embedding vector with contextualized words. A word embedding vector can be constructed with sparse linear representations of word factors. For example, depending on the context of the sentences in a dataset, separate can be represented as:
separate=0.3" keep apart"+"0.3" distinct"+ 0.1 "discriminate"+0.1 "sever" + 0.1 "disperse"+0.1 "scatter"
To ensure that a linear representation remains sparse, we don’t add 0 factors that would create huge matrices with 0 values. Thus, we do not include useless information such as:
separate= 0.0"putting together"+".0" "identical"
The whole point is to keep the representation sparse by forcing the coefficients of the factors to be greater than 0.
The hidden state for each word is retrieved for each layer. Since each layer progresses in its understanding of the representation of the word in the dataset of sentences, the latent dependencies build up. This sparse linear superposition of transformer factors becomes a dictionary matrix with a sparse vector of coefficients to be inferred that we can sum up as:
![]()
In which:
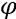 (phi) is the dictionary matrix
(phi) is the dictionary matrix 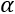 is the sparse vector of coefficients to be inferred
is the sparse vector of coefficients to be inferred
Yun et al., 2021, added, ![]() , Gaussian noise samples to force the algorithm to search for deeper representations.
, Gaussian noise samples to force the algorithm to search for deeper representations.
Also, to ensure that the representation remains sparse, the equation must be written s.t. (such that) ![]() .
.
The authors refer to X as the set of hidden states of the layers and x as a sparse linear superposition of transformer factors that belongs to X.
They beautifully sum up their sparse dictionary learning model as:
![]()
In the dictionary matrix, ![]() :,c refers to a column of the dictionary matrix and contains a transformer factor.
:,c refers to a column of the dictionary matrix and contains a transformer factor.
![]() :,c is divided into three levels:
:,c is divided into three levels:
- Low-level transformer factors to solve polysemy problems through word-level disambiguation
- Mid-level transformer factors take us further into sentence-level patterns that will bring vital context to the low level
- High-level transformer patterns that will help understand long-range dependencies
The method is innovative, exciting, and seems efficient. However, there is no visualization functionality at this point. Therefore, Yun et al., 2021, created the necessary information for LIME, a standard interpretable AI method to visualize their findings.
The interactive transformer visualization page is thus based on LIME for its outputs. The following section is a brief introduction to LIME.
Introducing LIME
LIME stands for Local Interpretable Model-Agnostic Explanations. The name of this explainable AI method speaks for itself. It is model-agnostic. Thus, we can draw immediate consequences about the method of transformer visualization via dictionary learning:
- This method does not dig into the matrices, weights, and matrix multiplications of transformer layers.
- The method does not explain how a transformer model works, as we did in Chapter 2, Getting Started with the Architecture of the Transformer Model.
- In this chapter, the method peeks into the mathematical outputs provided by the sparse linear superpositions of transformer factors.
LIME does not try to parse all of the information in a dataset. Instead, LIME finds out whether a model is locally reliable by examining the features around a prediction.
LIME does not apply to the model globally. It focuses on the local environment of a prediction.
This is particularly efficient when dealing with NLP because LIME explores the context of a word, providing invaluable information on the model’s output.
In visualization via dictionary learning, an instance x can be represented as:
![]()
The interpretable representation of this instance is a binary vector:
![]()
The goal is to determine the local presence or absence of a feature or several features. In NLP, the features are tokens that can be reconstructed into words.
For LIME, g represents a transformer model or any other machine learning model. G represents a set of transformer models containing g, among other models:
![]()
LIME’s algorithm can thus be applied to any transformer model.
At this point, we know that:
- LIME targets a word and searches the local context for other words
- LIME thus provides the local context of a word to explain why that word was predicted and not another one
Exploring explainable AI such as LIME is not in the scope of this book on transformers for NLP. However, for more on LIME, see the References section.
Let’s now see how LIME fits in the method of transformer visualization via dictionary learning.
Let’s now explore the visualization interface.
The visualization interface
Visit the following site to access the interactive transformer visualization page: https://transformervis.github.io/transformervis/.
The visualization interface provides intuitive instructions to start analyzing a transformer factor of a specific layer in one click, as shown in Figure 14.12:

Figure 14.12: Selecting a transformer factor
Once you have chosen a factor, you can click on the layer you wish to visualize for this factor:

Figure 14.13: Visualize function per layer
The first visualization shows the activation of the factor layer by layer:
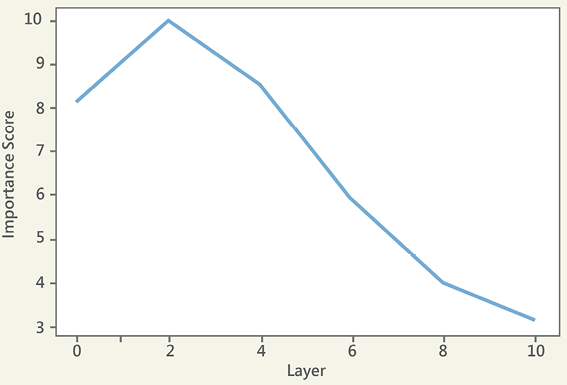
Figure 14.14: Importance of a factor for each layer
Factor 421 focuses on the lexical field of separate, as shown in the lower layers:

Figure 14.15: The representation of “separate” in the lower layers
As we visualize higher layers, longer-range representations emerge. Factor 421 began with the representation of separate. But at higher levels, the transformer began to form a deeper understanding of the factor and associated separate with distinct, as shown in Figure 14.16:

Figure 14.16: The higher-layer representations of a transformer factor
Try several transformer factors to visualize how transformers expand their perception and understanding of language, layer by layer.
You will find many good examples and also poor results. Focus on the good examples to understand how a transformer makes its way through language learning. Use the poor results to understand why it made a mistake. Also, the transformer model used for the visualization interface is not the most powerful or well-trained one.
In any case, get involved and stay in the loop of this ever-evolving field!
For example, you can explore Understanding_GPT_2_models_with_Ecco.ipynb, which is in the GitHub repository of this book for this chapter. It shows you how transformers generate candidates before choosing a token. It is self-explanatory.
In this section, we saw how transformers learn the meaning of words layer by layer. A transformer generates candidates before making a choice. As shown in the notebook, a transformer model is stochastic and as such chooses among several top probabilities. Consider the following sentence:
"The sun rises in the_____."
What word would you choose at the end of the sentence? We all hesitate. So do transformers!
In this case, the GPT-2 model chooses the word sky:

Figure 14.17: Completing a sequence
But there are other candidates the GPT-2 model may choose in another run, as shown in Figure 14.18:

We can see that sky appears in rank first. However, morning appears in rank second and could fit as well. If we run the model several times, we may obtain different outputs because the model is stochastic.
It seems that the domain of AI and transformers is complete.
However, let’s see why humans still have a lot of work to do before we go.
Exploring models we cannot access
The visual interfaces explored in this chapter are fascinating. However, there is still a lot of work to do!
For example, OpenAI’s GPT-3 model runs online or through an API. Thus, we cannot access the weights of some Software as a Service (SaaS) transformer models. This trend will increase and expand in the years to come. Corporations that spend millions of dollars on research and computer power will tend to provide pay-as-you-go services, not open-source applications.
Even if we had access to the source code or output weights of a GPT-3 model, using a visual interface to analyze the 9,216 attention heads (96 layers x 96 heads) would be quite challenging.
Finding what is wrong will still require some human involvement in many cases.
For example, the polysemy issue of the word coach in English to French translation often represents a problem. In English, a coach can be a person who trains people, or a bus. The word coach exists in French, but it only applies to a person who trains people.
If you go to OpenAI AI GPT-3 playground, https://openai.com/, and translate sentences containing the word coach, you might obtain mixed results.
Sentence 1 is translated correctly by the OpenAI engine:
English: The coach broke down, and everybody complained.
French: Le bus a eu un problème et tout le monde s'est plaint.
coach is translated as a bus, which is fine. More context would be required.
The outputs are stochastic, so the translation might be correct one time and false the time after.
However, Sentence 2 is mistranslated:
English: The coach was dissatisfied with the team and everybody complained.
French: Le bus était insatisfait du équipe et tout le monde s'est plaint.
This time, the GPT-3 engine missed the fact that coach meant a person, not a bus. The same stochastic runs will provide unstable outputs.
If we modify sentence 2 by adding context, we will obtain the proper translation:
English: The coach of the football team was dissatisfied and everybody complained.
French: Le coach de l'équipe de football était insatisfait et tout le monde s'est plaint.
The translation now contains the French word coach for the same definition of the English word coach in this sentence. More context was added.
OpenAI’s solutions, AI in general, and transformer models in particular, are continuously progressing. Furthermore, most Industry 4.0 AI-driven micro-decisions do not require the level of sophistical of NLP or translation tasks and are effective.
However, human intervention and development at the Cloud AI API level will still remain necessary for quite a long time!
Summary
Transformer models are trained to resolve word-level polysemy disambiguation and low-level, mid-level, and high-level dependencies. The process is achieved by connecting training million- to trillion-parameter models. The task of interpreting these giant models seems daunting. However, several tools are emerging.
We first installed BertViz. We learned how to interpret the computations of the attention heads with an interactive interface. We saw how words interacted with other words for each layer.
The chapter continued by defining the scope of probing and non-probing tasks. Probing tasks such as NER provide insights into how a transformer model represents language. However, non-probing methods analyze how the model makes predictions. For example, LIT plugged a PCA project and UMAP representations into the outputs of a BERT transformer model. We could then analyze clusters of outputs to see how they fit together.
Finally, we ran transformer visualization via dictionary learning. A user can choose a transformer factor to analyze and visualize the evolution of its representation from the lower layers to the higher layers of the transformer. The factor will progressively go from polysemy disambiguation to sentence context analysis and finally to long-term dependencies.
The tools of this chapter will evolve along with other techniques. However, the key takeaway of this chapter is that transformer model activity can be visualized and interpreted in a user-friendly manner. In the next chapter, we will discover new transformer models. We will also go through risk management methods to choose the best implementations for a transformer model project.
Questions
- BertViz only shows the output of the last layer of the BERT model. (True/False)
- BertViz shows the attention heads of each layer of a BERT model. (True/False)
- BertViz shows how the tokens relate to each other. (True/False)
- LIT shows the inner workings of the attention heads like BertViz. (True/False)
- Probing is a way for an algorithm to predict language representations. (True/False)
- NER is a probing task. (True/False)
- PCA and UMAP are non-probing tasks. (True/False)
- LIME is model agnostic. (True/False)
- Transformers deepen the relationships of the tokens layer by layer. (True/False)
- Visual transformer model interpretation adds a new dimension to interpretable AI. (True/False)
References
- BertViz: Jesse Vig,2019, A Multiscale Visualization of Attention in the Transformer Model,2019, https://aclanthology.org/P19-3007.pdf
- BertViz: https://github.com/jessevig/BertViz
- LIT, explanation of sentiment analysis representations: https://pair-code.github.io/lit/tutorials/sentiment/
- LIT: https://pair-code.github.io/lit/
- Transformer visualization via dictionary learning: Zeyu Yun, Yubei Chen, Bruno A Olshausen, Yann LeCun, 2021, Transformer visualization via dictionary learning: contextualized embedding as a linear superposition of transformer factors, https://arxiv.org/abs/2103.15949
- Transformer visualization via dictionary learning: https://transformervis.github.io/transformervis/
Join our book’s Discord space
Join the book’s Discord workspace:
https://www.packt.link/Transformers
