
10
Semantic Role Labeling with BERT-Based Transformers
Transformers have made more progress in the past few years than NLP in the past generation. Standard NLU approaches first learn syntactical and lexical features to explain the structure of a sentence. The former NLP models would be trained to understand a language’s basic syntax before running Semantic Role Labeling (SRL).
Shi and Lin (2019) started their paper by asking if preliminary syntactic and lexical training can be skipped. Can a BERT-based model perform SRL without going through those classical training phases? The answer is yes!
Shi and Lin (2019) suggested that SRL can be considered sequence labeling and provide a standardized input format. Their BERT-based model produced surprisingly good results.
This chapter will use a pretrained BERT-based model provided by the Allen Institute for AI based on the Shi and Lin (2019) paper. Shi and Lin took SRL to the next level by dropping syntactic and lexical training. We will see how this was achieved.
We will begin by defining SRL and the standardization of the sequence labeling input formats. We will then get started with the resources provided by the Allen Institute for AI. Next, we will run SRL tasks in a Google Colab notebook and use online resources to understand the results.
Finally, we will challenge the BERT-based model by running SRL samples. The first samples will show how SRL works. Then, we will run some more difficult samples. We will progressively push the BERT-based model to the limits of SRL. Finding the limits of a model is the best way to ensure that real-life implementations of transformer models remain realistic and pragmatic.
This chapter covers the following topics:
- Defining semantic role labeling
- Defining the standardization of the input format for SRL
- The main aspects of the BERT-based model’s architecture
- How an encoder-only stack can manage a masked SRL input format
- BERT-based model SRL attention process
- Getting started with the resources provided by the Allen Institute for AI
- Building a notebook to run a pretrained BERT-based model
- Testing sentence labeling on basic examples
- Testing SRL on difficult examples and explaining the results
- Taking the BERT-based model to the limit of SRL and explaining how this was done
Our first step will be to explore the SRL approach defined by Shi and Lin (2019).
Getting started with SRL
SRL is as difficult for humans as for machines. However, once again, transformers have taken a step closer to our human baselines.
In this section, we will first define SRL and visualize an example. We will then run a pretrained BERT-based model.
Let’s begin by defining the problematic task of SRL.
Defining semantic role labeling
Shi and Lin (2019) advanced and proved the idea that we can find who did what, and where, without depending on lexical or syntactic features. This chapter is based on Peng Shi and Jimmy Lin’s research at the University of Waterloo, California. They showed how transformers learn language structures better with attention layers.
SRL labels the semantic role as the role a word or group of words plays in a sentence and the relationship established with the predicate.
A semantic role is the role a noun or noun phrase plays in relation to the main verb in a sentence. For example, in the sentence Marvin walked in the park, Marvin is the agent of the event occurring in the sentence. The agent is the doer of the event. The main verb, or governing verb, is walked.
The predicate describes something about the subject or agent. The predicate could be anything that provides information on the features or actions of a subject. In our approach, we will refer to the predicate as the main verb. For example, in the sentence Marvin walked in the park, the predicate is walked in its restricted form.
The words in the park modify the meaning of walked and are the modifier.
The noun or noun phrases that revolve around the predicate are arguments or argument terms. Marvin, for example, is an argument of the predicate walked.
We can see that SRL does not require a syntax tree or a lexical analysis.
Let’s visualize the SRL of our example.
Visualizing SRL
This chapter will be using the Allen Institute’s visual and code resources (see the References section for more information). The Allen Institute for AI has excellent interactive online tools, such as the one we’ve used to represent SRL visually throughout this chapter. You can access these tools at https://demo.allennlp.org/.
The Allen Institute for AI advocates AI for the common good. We will make good use of this approach. All of the figures in this chapter were created with the AllenNLP tools.
The Allen Institute provides transformer models that continuously evolve. Therefore, the examples in this chapter might produce different results when you run them. The best way to get the most out of this chapter is to:
- Read and understand the concepts explained beyond merely running a program
- Take the time to understand the examples provided
Then run your own experiments with sentences of your choice with the tool used in this chapter: https://demo.allennlp.org/semantic-role-labeling.
We will now visualize our SRL example. Figure 10.1 is an SRL representation of Marvin walked in the park:
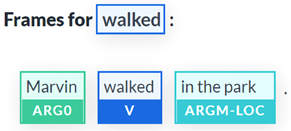
Figure 10.1: The SRL representation of a sentence
We can observe the following labels in Figure 10.1:
- Verb: The predicate of the sentence
- Argument: An argument of the sentence named ARG0
- Modifier: A modifier of the sentence. In this case, a location. It could have been an adverb, an adjective, or anything that modifies the predicate’s meaning
The text output is interesting as well, which contains shorter versions of the labels of the visual representation:
walked: [ARG0: Marvin] [V: walked] [ARGM-LOC: in the park]
We have defined SRL and gone through an example. It is time to look at the BERT-based model.
Running a pretrained BERT-based model
This section will begin by describing the architecture of the BERT-based model used in this chapter.
Then we will define the method used to experiment with SRL samples with a BERT model.
Let’s begin by looking at the architecture of the BERT-based model.
The architecture of the BERT-based model
AllenNLP’s BERT-based model is a 12-layer encoder-only BERT model. The AllenNLP team implemented the BERT model described in Shi and Lin (2019) with an additional linear classification layer.
For more on the description of a BERT model, take a few minutes, if necessary, to go back to Chapter 3, Fine-Tuning BERT Models.
The BERT-based model takes full advantage of bidirectional attention with a simple approach and architecture. The core potential of transformers resides in the attention layers. We have seen transformer models with both encoder and decoder stacks. We have seen other transformers with encoder layers only or decoder layers only. The main advantage of transformers remains in the near-human approach of attention layers.
The input format of the predicate identification format defined by Shi and Lin (2019) shows how far transformers have come to understand a language in a standardized fashion:
[CLS] Marvin walked in the park.[SEP] walked [SEP]
The training process has been standardized:
[CLS]indicates that this is a classification exercise[SEP]is the first separator, indicating the end of the sentence[SEP]is followed by the predicate identification designed by the authors[SEP]is the second separator, which indicates the end of the predicate identifier
This format alone is enough to train a BERT model to identify and label the semantic roles in a sentence.
Let’s set up the environment to run SRL samples.
Setting up the BERT SRL environment
We will be using a Google Colab notebook, the AllenNLP visual text representations of SRL available at https://demo.allennlp.org/ under the Semantic Role Labeling section.
We will apply the following method:
- We will open
SRL.ipynb, installAllenNLP, and run each sample - We will display the raw output of the SRL run
- We will visualize the output using AllenNLP’s online visualization tools
- We will display the output using AllenNLP’s online text visualization tools
If you have trouble running SRL.ipynb on Google Colab, try running the Semantic_Role_Labeling_with_ChatGPT.ipynb notebook instead.
This chapter is self-contained. You can read through it or run the samples as described.
The SRL model output may differ when AllenNLP changes the transformer model used. This is because AllenNLP models and transformers, in general, are continuously trained and updated. Also, the datasets used for training might change. Finally, these are not rule-based algorithms that produce the same result each time. The outputs might change from one run to another, as described and shown in the screenshots.
Let’s now run some SRL experiments.
SRL experiments with the BERT-based model
We will run our SRL experiments using the method described in the Setting up the BERT SRL environment section of this chapter. We will begin with basic samples with various sentence structures. We will then challenge the BERT-based model with some more difficult samples to explore the system’s capacity and limits.
Open SRL.ipynb and run the installation cell:
!pip install allennlp==2.1.0 allennlp-models==2.1.0
Then we import the tagging module and a trained BERT predictor:
from allennlp.predictors.predictor import Predictor
import allennlp_models.tagging
import json
predictor = Predictor.from_path("https://storage.googleapis.com/allennlp-public-models/structured-prediction-srl-bert.2020.12.15.tar.gz")
We also add two functions to display the JSON object SRL BERT returns. The first one displays the verb of the predicate and the description:
def head(prediction):
# Iterating through the json to display excerpt of the prediciton
for i in prediction['verbs']:
print('Verb:',i['verb'],i['description'])
The second one displays the full response, including the tags:
def full(prediction):
#print the full prediction
print(json.dumps(prediction, indent = 1, sort_keys=True))
At the time of this publication, the BERT model was specifically trained for semantic role labeling use. The name of the model is SRL BERT. SRL BERT was trained using the OntoNotes 5.0 dataset: https://catalog.ldc.upenn.edu/LDC2013T19.
This dataset contains sentences and annotations. The dataset was designed to identify predicates (a part of a sentence containing a verb) in a sentence and identify the words that provide more information on the verbs. Each verb comes with its “arguments” that tell us more about it. A “frame” contains the arguments of a verb.
SRL BERT is thus a specialized model trained to perform a specific task, and as such, it is not a foundation model like OpenAI GPT-3 as we saw in Chapter 7, The Rise of Suprahuman Transformers with GPT-3 Engines.
SRL BERT will focus on semantic role labeling with acceptable accuracy as long as the sentence contains a predicate.
We are now ready to warm up with some basic samples.
Basic samples
Basic samples seem intuitively simple but can be tricky to analyze. Compound sentences, adjectives, adverbs, and modals are difficult to identify, even for non-expert humans.
Let’s begin with an easy sample for the transformer.
Sample 1
The first sample is long but relatively easy for the transformer:
Did Bob really think he could prepare a meal for 50 people in only a few hours?
Run the Sample 1 cell in SRL.ipynb:
prediction=predictor.predict(
sentence="Did Bob really think he could prepare a meal for 50 people in only a few hours?"
)
head(prediction)
BERT SRL identified the four predicates; the verb for each one labeled the result as shown in this excerpt using the head(prediction) function:
Verb: Did [V: Did] Bob really think he could prepare a meal for 50 people in only a few hours ?
Verb: think Did [ARG0: Bob] [ARGM-ADV: really] [V: think] [ARG1: he could prepare a meal for 50 people in only a few hours] ?
Verb: could Did Bob really think he [V: could] [ARG1: prepare a meal for 50 people in only a few hours] ?
Verb: prepare Did Bob really think [ARG0: he] [ARGM-MOD: could] [V: prepare] [ARG1: a meal for 50 people] [ARGM-TMP: in only a few hours] ?
You can view the full response by running the full(prediction) cell.
If we use the description of the arguments of the dataset based on the structure of the PropBank (Proposition Bank), the verb think, for example, in this excerpt can be interpreted as:
Videntifies the verbthinkARG0identifies the agent; thus,Bobis the agent or “pro-agent”ARGM-ADVconsidersreallyas an adverb (ADV), withARGMmeaning that the adverb provides an adjunct (not necessary) thus not numbered
If we run the sample in the AllenNLP online interface, we obtain a visual representation of the SRL task of one frame per verb. The first verb is Did:

Figure 10.2: Identifying the verb “Did”
The second verb identified is think:
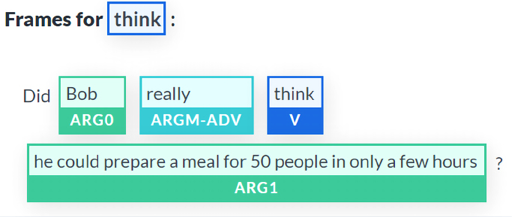
Figure 10.3: Identifying the verb “think”
If we take a close look at this representation, we can detect some interesting properties of the SRL BERT that:
- Detected the verb
think - Avoided the
preparetrap that could have been interpreted as the main verb. Instead,prepareremained part of the argument ofthink - Detected an adverb and labeled it
The third verb is could:

Figure 10.4: Identifying the verb “could” and the argument
The transformer then moved to the verb prepare, labeled it, and analyzed its context:
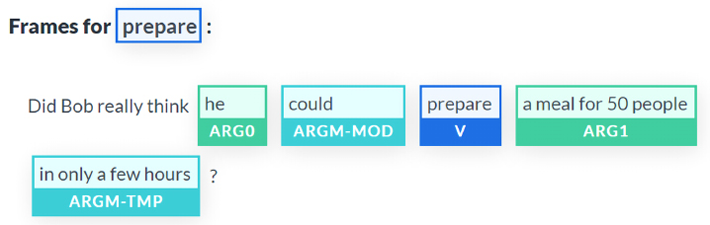
Figure 10.5: Identifying the verb “prepare”, the arguments, and the modifiers
Again, the simple BERT-based transformer model detected a lot of information on the grammatical structure of the sentence and found:
- The verb
prepareand isolated it - The noun
heand labeled it as an argument and did the same fora meal for 50 people, which is a “proto-patient,” which involves a modification by other participants - That
in only a few hoursis a temporal modifier (ARGM-TMP) - That
couldwas a modal modifier that indicates the modality of a verb, such as the likelihood of an event
We will now analyze another relatively long sentence.
Sample 2
The following sentence seems easy but contains several verbs:
Mrs. and Mr. Tomaso went to Europe for vacation and visited Paris and first went to visit the Eiffel Tower.
Will this confusing sentence make the transformer hesitate? Let’s see by running the Sample 2 cell of the SRL.ipynb notebook:
prediction=predictor.predict(
sentence="Mrs. and Mr. Tomaso went to Europe for vacation and visited Paris and first went to visit the Eiffel Tower."
)
head(prediction)
The excerpt of the output proves that the transformer correctly identified the verbs in the sentence:
Verb: went [ARG0: Mrs. and Mr. Tomaso] [V: went] [ARG4: to Europe] [ARGM-PRP: for vacation] and visited Paris and first went to visit the Eiffel Tower .
Verb: visited [ARG0: Mrs. and Mr. Tomaso] went to Europe for vacation and [V: visited] [ARG1: Paris] and first went to visit the Eiffel Tower .
Verb: went [ARG0: Mrs. and Mr. Tomaso] went to Europe for vacation and visited Paris and [ARGM-TMP: first] [V: went] [ARG1: to visit the Eiffel Tower] .
Verb: visit [ARG0: Mrs. and Mr. Tomaso] went to Europe for vacation and visited Paris and first went to [V: visit] [ARG1: the Eiffel Tower] .
Running the sample on AllenNLP online identified four predicates, thus generating four frames.
The first frame is for went:

Figure 10.6: Identifying the verb “went,” the arguments, and the modifier
We can interpret the arguments of the verb went. Mrs. and Mr. Tomaso are the agents. The transformer found that the main modifier of the verb was the purpose of the trip: to Europe. The result would not be surprising if we did not know that Shi and Lin (2019) had only built a simple BERT model to obtain this high-quality grammatical analysis.
We can also notice that went was correctly associated with Europe. The transformer correctly identified the verb visited as being related to Paris:

Figure 10.7: Identifying the verb “visited” and the arguments
The transformer could have associated the verb visited directly with the Eiffel Tower. But it didn’t. It stood its ground and made the right decision.
The next task we asked the transformer to do was identify the context of the second use of the verb went. Again, it did not fall into the trap of merging all of the arguments related to the verb went, used twice in the sentence. Again, it correctly split the sequence and produced an excellent result:

Figure 10.8: Identifying the verb “went,” the argument, and the modifiers
The verb went was used twice, but the transformer did not fall into the trap. It even found that first was a temporal modifier of the verb went.
Finally, the verb visit was used a second time, and SRL BERT correctly interpreted its use:

Figure 10.9: Identifying the verb “visit” and the arguments
Let’s run a sentence that is a bit more confusing.
Sample 3
Sample 3 will make things more difficult for our transformer model. The following sample contains variations of the verb drink four times:
John wanted to drink tea, Mary likes to drink coffee but Karim drank some cool water and Faiza would like to drink tomato juice.
Let’s run Sample 3 in the SRL.ipynb notebook:
prediction=predictor.predict(
sentence="John wanted to drink tea, Mary likes to drink coffee but Karim drank some cool water and Faiza would like to drink tomato juice."
)
head(prediction)
The transformer found its way around, as shown in the following excerpt of the output that contains the verbs:
Verb: wanted [ARG0: John] [V: wanted] [ARG1: to drink tea] , Mary likes to drink coffee but Karim drank some cool water and Faiza would like to drink tomato juice .
Verb: drink [ARG0: John] wanted to [V: drink] [ARG1: tea] , Mary likes to drink coffee but Karim drank some cool water and Faiza would like to drink tomato juice .
Verb: likes John wanted to drink tea , [ARG0: Mary] [V: likes] [ARG1: to drink coffee] but Karim drank some cool water and Faiza would like to drink tomato juice .
Verb: drink John wanted to drink tea , [ARG0: Mary] likes to [V: drink] [ARG1: coffee] but Karim drank some cool water and Faiza would like to drink tomato juice .
Verb: drank John wanted to drink tea , Mary likes to drink coffee but [ARG0: Karim] [V: drank] [ARG1: some cool water] and Faiza would like to drink tomato juice .
Verb: would John wanted to drink tea , Mary likes to drink coffee but Karim drank some cool water and [ARG0: Faiza] [V: would] like [ARG1: to drink tomato juice] .
Verb: like John wanted to drink tea , Mary likes to drink coffee but Karim drank some cool water and [ARG0: Faiza] [ARGM-MOD: would] [V: like] [ARG1: to drink tomato juice] .
Verb: drink John wanted to drink tea , Mary likes to drink coffee but Karim drank some cool water and [ARG0: Faiza] would like to [V: drink] [ARG1: tomato juice] .
We obtain several visual representations when we run the sentence on the AllenNLP online interface. We will examine two of them.
The first one is perfect. It identifies the verb wanted and makes the correct associations:

Figure 10.10: Identifying the verb “wanted” and the arguments
When it identified the verb drank, it correctly excluded Faiza and only produced some cool water as the argument.

Figure 10.11: Identifying the verb “drank” and the arguments
We’ve found that the BERT-based transformer produces relatively good results up to now on basic samples. So let’s try some more difficult ones.
Difficult samples
This section will run samples that contain problems that the BERT-based transformer will first solve. Finally, we will end with an intractable sample.
Let’s start with a complex sample that the BERT-based transformer can analyze.
Sample 4
Sample 4 takes us into more tricky SRL territory. The sample separates Alice from the verb liked, creating a long-term dependency that has to jump over whose husband went jogging every Sunday.
The sentence is:
Alice, whose husband went jogging every Sunday, liked to go to a dancing class in the meantime.
A human can isolate Alice and find the predicate:
Alice liked to go to a dancing class in the meantime.
Can the BERT model find the predicate like us?
Let’s find out by first running the code in SRL.ipynb:
prediction=predictor.predict(
sentence="Alice, whose husband went jogging every Sunday, liked to go to a dancing class in the meantime."
)
head(prediction)
The output identified the verbs for each predicate and labeled each frame:
Verb: went Alice , [ARG0: whose husband] [V: went] [ARG1: jogging] [ARGM-TMP: every Sunday] , liked to go to a dancing class in the meantime .
Verb: jogging Alice , [ARG0: whose husband] went [V: jogging] [ARGM-TMP: every Sunday] , liked to go to a dancing class in the meantime .
Verb: liked [ARG0: Alice , whose husband went jogging every Sunday] , [V: liked] [ARG1: to go to a dancing class in the meantime] .
Verb: go [ARG0: Alice , whose husband went jogging every Sunday] , liked to [V: go] [ARG4: to a dancing class] [ARGM-TMP: in the meantime] .
Verb: dancing Alice , whose husband went jogging every Sunday , liked to go to a [V: dancing] class in the meantime .
Let’s focus on the part we are interested in and see if the model found the predicate. It did! It found the verb liked as shown in this excerpt of the output, although the verb like is separated from Alice by another predicate:
Verb: liked [ARG0: Alice , whose husband went jogging every Sunday]
Let’s now look at the visual representation of the model’s analysis after running the sample on AllenNLP’s online UI. The transformer first finds Alice’s husband:

Figure 10.12: The predicate “went” has been identified
The transformer explains that:
- The predicate or verb is
went whose husbandis the argumentjoggingis another argument related towentevery Sundayis a temporal modifier represented in the raw output as[ARGM-TMP: every Sunday]
The transformer then found what Alice’s husband was doing:

Figure 10.13: SRL detection of the verb “jogging”
We can see that the verb jogging was identified and was related to whose husband with the temporal modifier every Sunday.
The transformer doesn’t stop there. It now detects what Alice liked:

Figure 10.14: Identifying the verb “liked”
The transformer also detects and analyzes the verb go correctly:

Figure 10.15: Detecting the verb “go,” its arguments, and modifier
We can see that the temporal modifier in the meantime was also identified. It is quite a performance considering the simple sequence + verb input SRL BERT was trained with.
Finally, the transformer identifies the last verb, dancing, as being related to class:

Figure 10.16: Relating the argument “class” to the verb “dancing”
The results produced by Sample 4 are quite convincing! Let’s try to find the limit of the transformer model.
Sample 5
Sample 5 does not repeat a verb several times. However, Sample 5 contains a word with multiple functions and meanings. It goes beyond polysemy since the word round can have different meanings and grammatical functions. The word round can be a noun, an adjective, an adverb, a transitive verb, or an intransitive verb.
As a transitive or intransitive verb, round can attain perfection or completion. In this sense, round can be used with off.
The following sentence uses round in the past tense:
The bright sun, the blue sky, the warm sand, the palm trees, everything round off.
The verb round in this predicate is used in a sense of “to bring to perfection.” Of course, the most accessible grammatical form would have been “rounded.” but let’s see what happens with our sentence.
Let’s run Sample 5 in SRL.ipynb:
prediction=predictor.predict(
sentence="The bright sun, the blue sky, the warm sand, the palm trees, everything round off."
)
head(prediction)
The output shows no verbs. The transformer did not identify the predicate. In fact, it found no verbs at all even when we run the full(prediction) function:
"verbs": []
However, the online version seems to interpret the sentence better because it found the verb:

Figure 10.17: Detecting the verb “round” and “everything” as the argument
Since we like our SRL transformer, we will be kind to it. We will show it what to do with a verb form that is more frequently used. Let’s change the sentence from the past tense to the present tense by adding an s to round:
The bright sun, the blue sky, the warm sand, the palm trees, everything rounds off.
Let’s give SRL.ipynb another try with the present tense:
prediction=predictor.predict(
sentence="The bright sun, the blue sky, the warm sand, the palm trees, everything rounds off."
)
head(prediction)
The raw output shows that the predicate was found, as shown in the following output:
Verb: rounds [ARG1: The bright sun , the blue sky , the warm sand , the palm trees , everything] [V: rounds] [ARGM-PRD: off] .
If we run the sentence on AllenNLP, we obtain the visual explanation:

Figure 10.18: Detecting the word “rounds” as a verb
Our BERT-based transformer did well because the word round can be found as rounds in its present tense form.
The BERT model initially failed to produce the result we expected. But with a little help from its friends, all ended well for this sample.
We can see that:
- Outputs may vary with the evolution of the versions of a model we have implemented
- An Industry 4.0 pragmatic mindset requires more cognitive efforts to show a transformer what to do
Let’s try another sentence that’s difficult to label.
Sample 6
Sample 6 takes a word we often think is just a noun. However, more words than we suspect can be both nouns and verbs. For example, to ice is a verb used in hockey to shoot a puck all the way across the rink and beyond the goal line of an opponent. A puck is the disk used in hockey.
A hockey coach can start the day by telling a team to train icing pucks. We then can obtain the imperative sentence when the coach yells:
Now, ice pucks guys!
Note that guys can mean persons regardless of their sex.
Let’s run the Sample 6 cell to see what happens:
prediction=predictor.predict(
sentence="Now, ice pucks guys!"
)
head(prediction)
The transformer fails to find the verb: "verbs": [].
Game over! We can see that transformers have made tremendous progress, but there is still a lot of room for developers to improve the models. Humans are still in the game to show transformers what to do.
The online interface confuses pucks with a verb:

Figure 10.19: The model incorrectly labels “pucks” as the verb
This problem may be solved with another model, but you will reach another limit. Even GPT-3 has limits you will have to cope with.
When you implement transformers for a customized application with specialized jargon or technical vocabulary, you will reach intractable limits at some point.
These limits will require your expertise to make a project a success. Therefore, you will have to create specialized dictionaries to succeed in a project. This is good news for developers! You will develop new cross-disciplinary and cognitive skills that your team will appreciate.
Try some examples or samples of your own to see what SRL can do with the approach’s limits. Then explore how to develop preprocessing functions to show the transformer what to do for your customized applications.
Before we leave, let’s question the motivation of SRL.
Questioning the scope of SRL
We are alone when faced with a real-life project. We have a job to do, and the only people to satisfy are those who asked for that project.
Pragmatism must come first. Technical ideology after.
In the 2020s, former AI ideology and new ideology coexist. By the end of the decade, there will be only one winner merging some of the former into the latter.
This section questions the productivity of SRL and also its motivation through two aspects:
- The limit of predicate analysis
- Questioning the use of the term “semantic”
The limit of predicate analysis
SRL relies on predicates. SRL BERT only works as long as you provide a verb. But millions of sentences do not contain verbs.
If you provide SRL BERT in the Semantic Role Labeling section in the AllenNLP demo interface (https://demo.allennlp.org/) with an assertion alone, it works.
But what happens if your assertion is an answer to a question:
- Person 1:
What would you like to drink, please? - Person 2:
A cup of coffee, please.
When we enter Person 2’s answer, SRL BERT finds nothing:

Figure 10.20: No frame obtained
The output is 0 total frames. SRL was unable to analyze this sentence because it contains an ellipsis. The predicate is implicit, not explicit.
The definition of an ellipsis is the act of leaving one or several words out of a sentence that is not necessary for it to be understood.
Hundreds of millions of sentences containing an ellipsis are spoken and written each day.
Yet SRL BERT yields 0 Total Frames for all of them.
The following answers (A) to questions (Q) beginning with what, where, and how yield 0 Total Frames:
Q: What would you like to have for breakfast?
A: Pancakes with hot chocolate.
(The model deduces: pancakes=proper noun, with=preposition, hot= adjective, and chocolate=common noun.)
Q: Where do you want to go?
A: London, please.
(The model deduces: London=proper noun and please=adverb.)
Q: How did you get to work today?
A: Subway.
(The model deduces: subway=proper noun.)
We could find millions more examples that SRL BERT fails to understand because the sentences do not contain predicates.
We could apply this to questions in the middle of dialogue as well and still obtain no frames (outputs) from SRL BERT:
Context: The middle of a conversation during which person 2 did not want coffee:
Q: So, tea?
A: No thanks.
Q: Ok, hot chocolate?
A: Nope.
Q: A glass of water?
A: Yup!
We just saw a conversation with no frames, no semantic labeling. Nothing.
We can finish with some movie, concert, or exhibition reviews on social media that produce 0 frames:
Best movie ever!Worst concert in my life!Excellent exhibition!
This section showed the limits of SRL. Let’s now redefine SRL and show how to implement it.
Redefining SRL
SRL BERT presupposes that sentences contain predicates, which is a false assumption in many cases. Analyzing a sentence cannot be based on a predicate analysis alone.
A predicate contains a verb. The predicate tells us more about the subject. The following predicate contains a verb and additional information:
The dog ate his food quickly.
ate...quickly tells us more about the way the dog ate. However, a verb alone can be a predicate, as in:
Dogs eat.
The problem here resides in the fact that “verbs” and “predicates” are part of syntax and grammar analysis, not semantics.
Understanding how words fit together from a grammatical, functional point of view is restrictive.
Take this sentence that means absolutely nothing:
Globydisshing maccaked up all the tie.
SRL BERT perfectly performs “semantic” analysis on a sentence that means nothing:
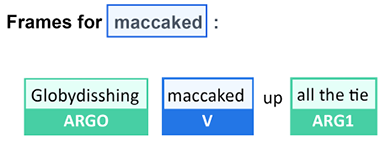
Figure 10.21: Analyzing a meaningless sentence
We can draw some conclusions from these examples:
- SRL predicate analysis only works when there is a verb in the sentence
- SRL predicate analysis cannot identify an ellipsis
- Predicates and verbs are part of the structure of a language, of grammatical analysis
- Predicate analysis identifies structures but not the meaning of a sentence
- Grammatical analysis goes far beyond predicate analysis as the necessary center of a sentence
Semantics focuses on the meaning of a phrase or sentence. Semantics focuses on context and the way words relate to each other.
Grammatical analysis includes syntax, inflection, and the functions of words in a phrase or sentence. The term semantic role labeling is misleading; it should be named “predicate role labeling.”
We perfectly understand sentences without predicates and beyond sequence structure.
Sentiment analysis can decode the meaning of a sentence and give us an output without predicate analysis. Sentiment analysis algorithms perfectly understand that “Best movie ever” is positive regardless of the presence of a predicate or not.
Using SRL alone to analyze language is restrictive. Using SRL in an AI pipeline or other AI tools can be very productive to add more intelligence to natural language understanding.
My recommendation is to use SRL with other AI tools, as we will see in Chapter 13, Analyzing Fake News with Transformers.
Let’s now conclude our exploration of the scope and limits of SRL.
Summary
In this chapter, we explored SRL. SRL tasks are difficult for both humans and machines. Transformer models have shown that human baselines can be reached for many NLP topics to a certain extent.
We found that a simple BERT-based transformer can perform predicate sense disambiguation. We ran a simple transformer that could identify the meaning of a verb (predicate) without lexical or syntactic labeling. Shi and Lin (2019) used a standard sentence + verb input format to train their BERT-based transformer.
We found that a transformer trained with a stripped-down sentence + predicate input could solve simple and complex problems. The limits were reached when we used relatively rare verb forms. However, these limits are not final. If difficult problems are added to the training dataset, the research team could improve the model.
We also discovered that AI for the good of humanity exists. The Allen Institute for AI has made many free AI resources available. In addition, the research team has added visual representations to the raw output of NLP models to help users understand AI. We saw that explaining AI is as essential as running programs. The visual and text representations provided a clear view of the potential of the BERT-based model.
Finally, we explored the scope and limits of SRL to optimize how we will use this method with other AI tools.
Transformers will continue to improve the standardization of NLP through their distributed architecture and input formats.
In the next chapter, Chapter 11, Let Your Data Do the Talking: Story, Questions, and Answers, we will challenge transformers on tasks usually only humans perform well. We will explore the potential of transformers when faced with Named Entity Recognition (NER) and question-answering tasks.
Questions
- Semantic Role Labeling (SRL) is a text generation task. (True/False)
- A predicate is a noun. (True/False)
- A verb is a predicate. (True/False)
- Arguments can describe who and what is doing something. (True/False)
- A modifier can be an adverb. (True/False)
- A modifier can be a location. (True/False)
- A BERT-based model contains encoder and decoder stacks. (True/False)
- A BERT-based SRL model has standard input formats. (True/False)
- Transformers can solve any SRL task. (True/False)
References
- Peng Shi and Jimmy Lin, 2019, Simple BERT Models for Relation Extraction and Semantic Role Labeling: https://arxiv.org/abs/1904.05255
- The Allen Institute for AI: https://allennlp.org/
- The Allen Institute for AI semantic role labeling resources: https://demo.allennlp.org/semantic-role-labeling
Join our book’s Discord space
Join the book’s Discord workspace:
https://www.packt.link/Transformers
