
12
Detecting Customer Emotions to Make Predictions
Sentiment analysis relies on the principle of compositionality. How can we understand a whole sentence if we cannot understand parts of a sentence? Is this tough task possible for NLP transformer models? We will try several transformer models in this chapter to find out.
We will start with the Stanford Sentiment Treebank (SST). The SST provides datasets with complex sentences to analyze. It is easy to analyze sentences such as The movie was great. However, what happens if the task becomes very tough with complex sentences such as Although the movie was a bit too long, I really enjoyed it.? This sentence is segmented. It forces a transformer model to understand the structure of the sequence and its logical form.
We will then test several transformer models with complex sentences and simple sentences. We will find that no matter which model we try, it will not work if it isn’t trained enough. Transformer models are like us. They are students that need to work hard to learn and try to reach real-life human baselines.
Running DistilBERT, RoBERTa-large, BERT-base, MiniLM-L12-H84-uncased, and BERT-base multilingual models is fun! However, we will discover that some of these students require more training, just like we would.
Along the way, we will see how to use the output of the sentiment tasks to improve customer relationships and see a nice five-star interface you could implement on your website.
Finally, we will use GPT-3’s online interface for sentiment analysis with an OpenAI account. No AI development or API is required!
This chapter covers the following topics:
- The SST for sentiment analysis
- Defining compositionality for long sequences
- Sentiment analysis with AllenNLP (RoBERTa)
- Running complex sentences to explore the new frontier of transformers
- Using Hugging Face sentiment analysis models
- DistilBERT for sentiment analysis
- Experimenting with MiniLM-L12-H384-uncased
- Exploring RoBERTa-large-mnli
- Looking into a BERT-base multilingual model
- Sentiment analysis with GPT-3
Let’s begin by going through the SST.
Getting started: Sentiment analysis transformers
This section will first explore the SST that the transformers will use to train models on sentiment analysis.
We will then use AllenNLP to run a RoBERTa-large transformer.
The Stanford Sentiment Treebank (SST)
Socher et al. (2013) designed semantic word spaces over long phrases. They defined principles of compositionality applied to long sequences. The principle of compositionality means that an NLP model must examine the constituent expressions of a complex sentence and the rules that combine them to understand the meaning of a sequence.
Let’s take a sample from the SST to grasp the meaning of the principle of compositionality.
This section and chapter are self-contained, so you can choose to perform the actions described or read the chapter and view the screenshots provided.
Go to the interactive sentiment treebank: https://nlp.stanford.edu/sentiment/treebank.html?na=3&nb=33.
You can make the selections you wish. Graphs of sentiment trees will appear on the page. Click on an image to obtain a sentiment tree:
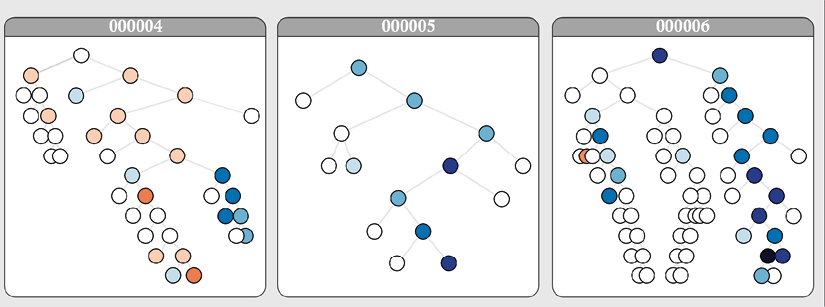
Figure 12.1: Graphs of sentiment trees
For this example, I clicked on graph number 6, which contains a sentence mentioning Jacques Derrida, a pioneer in deconstruction theories in linguistics. A long, complex sentence appears:
Whether or not you're enlightened by any of Derrida's lectures on the other and the self, Derrida is an undeniably fascinating and playful fellow.
Socher et al. (2013) worked on compositionality in vector spaces and logic forms.
For example, defining the rule of logic that governs the Jacques Derrida sample implies an understanding of the following:
- How the words
Whether,or, andnotand the comma that separates theWhetherphrase from the rest of the sentence can be interpreted - How to understand the second part of the sentence after the comma with yet another
and!
Once the vector space was defined, Socher et al. (2013) could produce complex graphs representing the principle of compositionality.
We can now view the graph section by section. The first section is the Whether segment of the sentence:
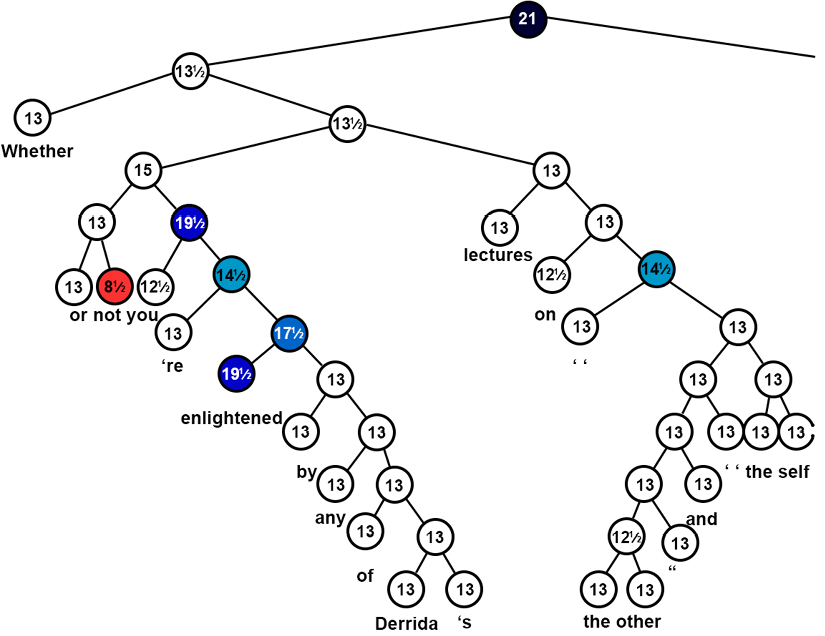
Figure 12.2: The “Whether” segment of a complex sentence
The sentence has been correctly split into two main parts. The second segment is also correct:
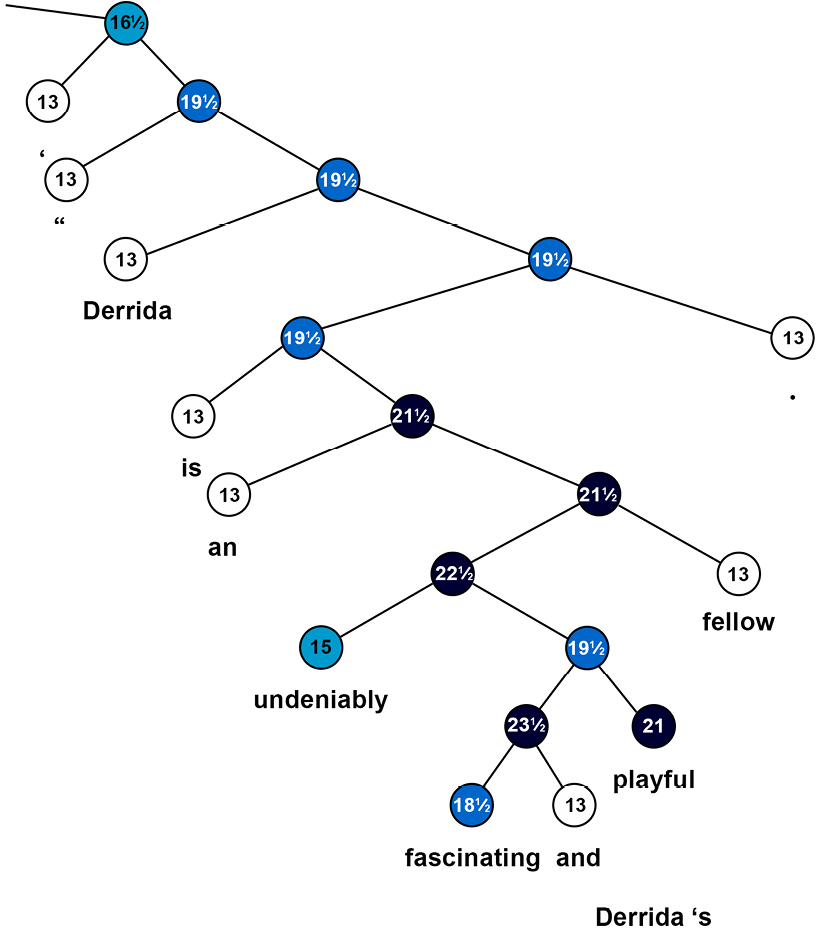
Figure 12.3: The main segment of a complex sentence
We can draw several conclusions from the method Socher et al. (2013) designed:
- Sentiment analysis cannot be reduced to counting positive and negative words in a sentence
- A transformer model or any NLP model must be able to learn the principle of compositionality to understand how the constituents of a complex sentence fit together with logical form rules
- A transformer model must be able to build a vector space to interpret the subtilities of a complex sentence
We will now put this theory into practice with a RoBERTa-large model.
Sentiment analysis with RoBERTa-large
In this section, we will use the AllenNLP resources to run a RoBERTa-large transformer. Liu et al. (2019) analyzed the existing BERT models and found that they were not trained as well as expected. Considering the speed at which the models were produced, this was not surprising. They worked on improving the pretraining of BERT models to produce a Robustly Optimized BERT Pretraining Approach (RoBERTa).
Let’s first run a RoBERTa-large model in SentimentAnalysis.ipynb.
Run the first cell to install allennlp-models:
!pip install allennlp==1.0.0 allennlp-models==1.0.0
Now let’s try to run our Jacques Derrida sample:
!echo '{"sentence": "Whether or not you're enlightened by any of Derrida's lectures on the other and the self, Derrida is an undeniably fascinating and playful fellow."}' |
allennlp predict https://storage.googleapis.com/allennlp-public-models/sst-roberta-large-2020.06.08.tar.gz -
The output first displays the architecture of the RoBERTa-large model, which has 24 layers and 16 attention heads:
"architectures": [
"RobertaForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"eos_token_id": 2,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 1024,
"initializer_range": 0.02,
"intermediate_size": 4096,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 514,
"model_type": "roberta",
"num_attention_heads": 16,
"num_hidden_layers": 24,
"pad_token_id": 1,
"type_vocab_size": 1,
"vocab_size": 50265
}
If necessary, you can take a few minutes to go through the description of a BERT architecture in the BERT model configuration section in Chapter 3, Fine-Tuning BERT Models, to take full advantage of this model.
Sentiment analysis produces values between 0 (negative) and 1 (positive).
The output then produces the result of the sentiment analysis task, displaying the output logits and the final positive result:
prediction: {"logits": [3.646597385406494, -2.9539334774017334], "probs": [0.9986421465873718, 0.001357800210826099]
Note: The algorithm is stochastic so the ouputs may vary from one run to another.
The output also contains the token IDs (which may vary from one run to another) and the final output label:
"token_ids": [0, 5994, 50, 45, 47, 769, 38853, 30, 143, 9, 6113, 10505, 281, 25798, 15, 5, 97, 8, 5, 1403, 2156, 211, 14385, 4347, 16, 41, 35559, 12509, 8, 23317, 2598, 479, 2], "label": "1",
The output also displays the tokens themselves:
"tokens": ["<s>", "u0120Whether", "u0120or", "u0120not", "u0120you", "u0120re", "u0120enlightened", "u0120by", "u0120any", "u0120of", "u0120Der", "rid", "as", "u0120lectures", "u0120on", "u0120the", "u0120other", "u0120and", "u0120the", "u0120self", "u0120,", "u0120D", "err", "ida", "u0120is", "u0120an", "u0120undeniably", "u0120fascinating", "u0120and", "u0120playful", "u0120fellow", "u0120.", "</s>"]}
Take some time to enter some samples to explore the well-designed and pretrained RoBERTa model.
Now let’s see how we can use sentiment analysis to predict customer behavior with other transformer models.
Predicting customer behavior with sentiment analysis
This section will run a sentiment analysis task on several Hugging Face transformer models to see which ones produce the best results and which ones we simply like the best.
We will begin this by using a Hugging Face DistilBERT model.
Sentiment analysis with DistilBERT
Let’s run a sentiment analysis task with DistilBERT and see how we can use the result to predict customer behavior.
Open SentimentAnalysis.ipynb and the transformer installation and import cells:
!pip install -q transformers
from transformers import pipeline
We will now create a function named classify, which will run the model with the sequences we send to it:
def classify(sequence,M):
#DistilBertForSequenceClassification(default model)
nlp_cls = pipeline('sentiment-analysis')
if M==1:
print(nlp_cls.model.config)
return nlp_cls(sequence)
Note that if you send M=1 to the function, it will display the configuration of the DistilBERT 6-layer, 12-head model we are using:
DistilBertConfig {
"activation": "gelu",
"architectures": [
"DistilBertForSequenceClassification"
],
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"finetuning_task": "sst-2",
"hidden_dim": 3072,
"id2label": {
"0": "NEGATIVE",
"1": "POSITIVE"
},
"initializer_range": 0.02,
"label2id": {
"NEGATIVE": 0,
"POSITIVE": 1
},
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"output_past": true,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"tie_weights_": true,
"vocab_size": 30522
}
The specific parameters of this DistilBERT model are the label definitions.
We now create a list of sequences (you can add more) that we can send to the classify function:
seq=3
if seq==1:
sequence="The battery on my Model9X phone doesn't last more than 6 hours and I'm unhappy about that."
if seq==2:
sequence="The battery on my Model9X phone doesn't last more than 6 hours and I'm unhappy about that. I was really mad! I bought a Moel10x and things seem to be better. I'm super satisfied now."
if seq==3:
sequence="The customer was very unhappy"
if seq==4:
sequence="The customer was very satisfied"
print(sequence)
M=0 #display model cofiguration=1, default=0
CS=classify(sequence,M)
print(CS)
In this case, seq=3 is activated to simulate a customer issue we need to take into account. The output is negative, which is the example we are looking for:
[{'label': 'NEGATIVE', 'score': 0.9997098445892334}]
We can draw several conclusions from this result to predict customer behavior by writing a function that would:
- Store the predictions in the customer management database.
- Count the number of times a customer complains about a service or product in a period (week, month, year). A customer that complains often might switch to a competitor to get a better product or service.
- Detect the products and services that keep occurring in negative feedback messages. The product or service might be faulty and require quality control and improvements.
You can take a few minutes to run other sequences or create some sequences to explore the DistilBERT model.
We will now explore other Hugging Face transformers.
Sentiment analysis with Hugging Face’s models’ list
This section will explore Hugging Face’s transformer models list and enter some samples to evaluate their results. The idea is to test several models, not only one, and see which model fits your need the best for a given project.
We will be running Hugging Face models: https://huggingface.co/models.
For each model we use, you can find the description of the model in the documentation provided by Hugging Face: https://huggingface.co/transformers/.
We will test several models. If you implement them, you might find that they require fine-tuning or even pretraining for the NLP tasks you wish to perform. In that case, for Hugging Face transformers, you can do the following:
- For fine-tuning, you can refer to Chapter 3, Fine-Tuning BERT Models
- For pretraining, you can refer to Chapter 4, Pretraining a RoBERTa Model from Scratch
Let’s first go through the list of Hugging Face models: https://huggingface.co/models.
Then, select Text Classification in the Tasks pane:

Figure 12.4: Selecting text classification models
A list of transformer models trained for text classification will appear:
Figure 12.5: Hugging Face pretrained text-classification models
The default sort mode is Sort: Most downloads.
We will now search for some exciting transformer models we can test online.
We will begin with DistilBERT.
DistilBERT for SST
The distilbert-base-uncased-finetuned-sst-2-english model was fine-tuned on the SST.
Let’s try an example that requires a good understanding of the principles of compositionality:
"Though the customer seemed unhappy, she was, in fact satisfied but thinking of something else at the time, which gave a false impression."
This sentence is tough for a transformer to analyze and requires logical rule training.
The output is a false negative:

Figure 12.6: The output of a complex sequence classification task
A false negative does not mean that the model is not working correctly. We could choose another model. However, it could mean that we must download and train it longer and better!
At the time of writing this book, BERT-like models have good rankings on both the GLUE and SuperGLUE leaderboards. The rankings will continuously change but not the fundamental concepts of transformers.
We will now try a difficult but less complicated example.
This example is a crucial lesson for real-life projects. When we try to estimate how many times a customer complained, we will get both false negatives and false positives. Therefore, regular human intervention will still be mandatory for several more years.
Let’s give a MiniLM model a try.
MiniLM-L12-H384-uncased
Microsoft/MiniLM-L12-H384-uncased optimizes the size of the last self-attention layer of the teacher, among other tweakings of a BERT model, to obtain better performances. It has 12 layers, 12 heads, and 33 million parameters, and is 2.7 times faster than BERT-base.
Let’s test it for its capacity to understand the principles of compositionality:
Though the customer seemed unhappy, she was, in fact satisfied but thinking of something else at the time, which gave a false impression.
The output is interesting because it produces a careful split (undecided) score:
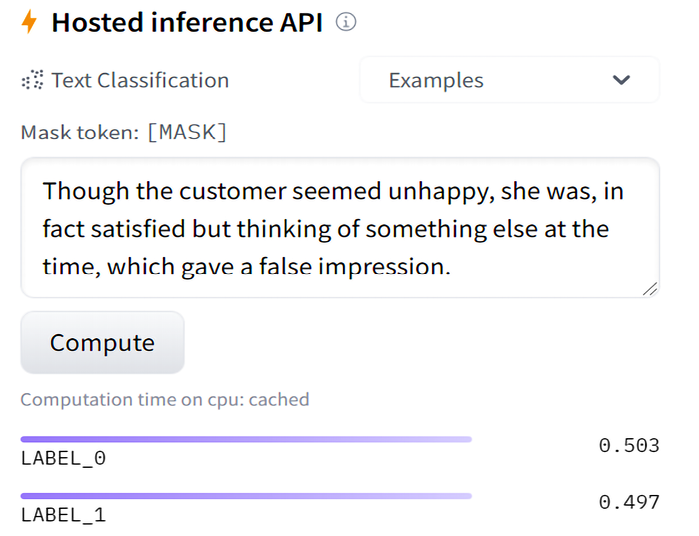
Figure 12.7: Complex sentence sentiment analysis
We can see that this output is not conclusive since it is around 0.5. It should be positive.
Let’s try a model involving entailment.
RoBERTa-large-mnli
A Multi-Genre Natural Language Inference (MultiNLI) task, https://cims.nyu.edu/~sbowman/multinli/, can help solve the interpretation of a complex sentence when we are trying to determine what a customer means. Inference tasks must determine whether a sequence entails the following one or not.
We need to format our input and split the sequence with sequence splitting tokens:
Though the customer seemed unhappy</s></s> she was, in fact satisfied but thinking of something else at the time, which gave a false impression
The result is interesting, although it remains neutral:
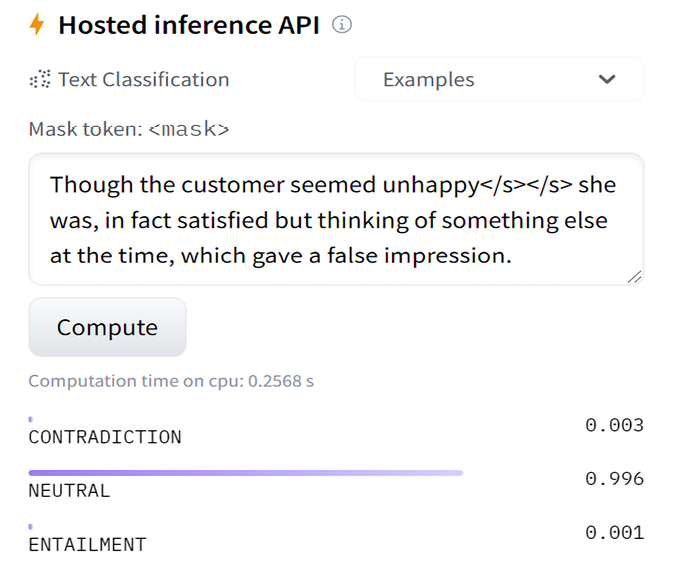
Figure 12.8: The neutral result obtained for a slightly positive sentence
However, there is no mistake in this result. The second sequence is not inferred from the first sequence. The result is carefully correct.
Let’s finish our experiments on a “positive sentiment” multilingual BERT-base model.
BERT-base multilingual model
Let’s run our final experiment on a super cool BERT-base model: nlptown/bert-base-multilingual-uncased-sentiment.
It is very well-designed.
Let’s run it with a friendly and positive sentence in English:
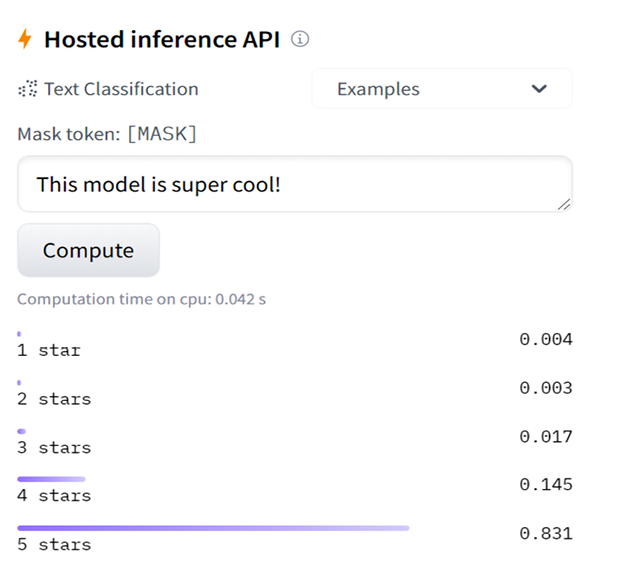
Figure 12.9: Sentiment analysis in English
Let’s try it in French with "Ce modèle est super bien!" ("this model is super good," meaning "cool"):
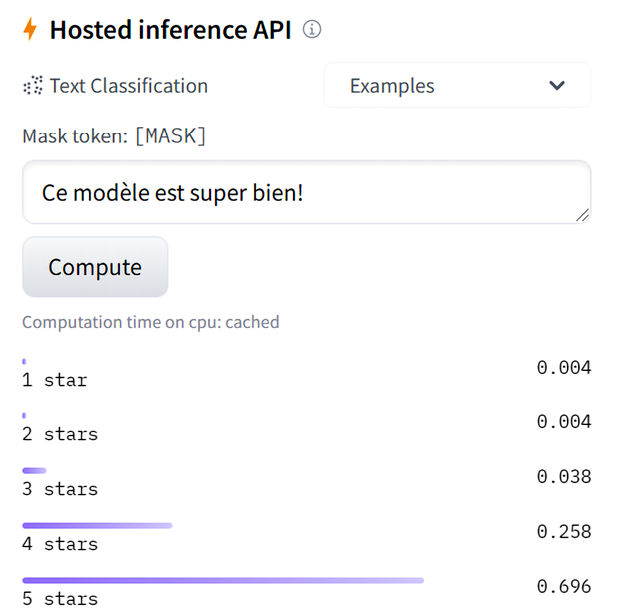
Figure 12.10: Sentiment analysis in French
The path of this model for Hugging Face is nlptown/bert-base-multilingual-uncased-sentiment. You can find it in the search form on the Hugging Face website. Its present link is https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment?text=Ce+mod%C3%A8le+est+super+bien%21.
You can implement it on your website with the following initialization code:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("nlptown/bert-base-multilingual-uncased-sentiment")
model = AutoModelForSequenceClassification.from_pretrained("nlptown/bert-base-multilingual-uncased-sentiment")
It will take some time and patience, but the result could be super cool!
You could implement this transformer on your website to average out the global satisfaction of your customers! You could also use it as continuous feedback to improve your customer service and anticipate customer reactions.
Before we leave, we will see how GPT-3 performs sentiment analysis.
Sentiment analysis with GPT-3
You will need an OpenAI account to run the examples in this section. The educational interface requires no API, no development, or training. You can simply enter some tweets, for example, and ask for sentiment analysis:
Tweet: I didn't find the movie exciting, but somehow I really enjoyed watching it!
Sentiment: Positive
Tweet: I never ate spicy food like this before but find it super good!
Sentiment: Positive
The outputs are satisfactory.
We will now submit a difficult sequence to the GPT-3 engine:
Tweet: It's difficult to find what we really enjoy in life because of all of the parameters we have to take into account.
Sentiment: Positive
The output is false! The sentiment is not positive at all. The sentence shows the difficulty of life. However, the word enjoy introduced bias for GPT-3.
If we take enjoy out of the sequence and replace it with the verb are, the output is negative:
Tweet: It's difficult to find what we really are in life because of all of the parameters we have to take into account.
Sentiment: Negative
The output is false also! It’s not because life is difficult to figure out that we can conclude that the sentence is negative. The correct output should have been neutral. Then we could ask GPT-3 to perform another task to explain why it is difficult in a pipeline, for example.
Running NLP tasks as a user with nothing to do shows where Industry 4.0 (I4.0) is going: less human intervention and more automatic functionality. However, we know that some situations require our new skills, such as designing preprocessing functions when the transformer doesn’t produce the expected result. Humans are still useful!
An example of tweet classification with ready-to-use code is described in the Running OpenAI GPT-3 Tasks section of Chapter 7, The Rise of Suprahuman Transformers with GPT-3 Engines. You can implement the examples of this section in that code if you wish.
Let’s now see how we can still prove ourselves valuable assets.
Some Pragmatic I4.0 thinking before we leave
The sentiment analysis with Hugging Face transformers contained a sentence that came out as “neutral.”
But is that true?
Labeling this sentence “neutral” bothered me. I was curious to see if OpenAI GPT-3 could do better. After all, GPT-3 is a foundation model that can theoretically do many things it wasn’t trained for.
I examined the sentence again:
Though the customer seemed unhappy, she was, in fact, satisfied but thinking of something else at the time, which gave a false impression.
When I read the sentence closely, I could see that the customer is she. When I looked deeper, I understood that she is in fact satisfied. I decided not to try models blindly until I reached one that works. Trying one model after the other is not productive.
I needed to get to the root of the problem using logic and experimentation. I didn’t want to rely on an algorithm that would find the reason automatically. Sometimes we need to use our neurons!
Could the problem be that it is difficult to identify she as the customer for a machine? As we did in Chapter 10, Semantic Role Labeling with BERT-Based Transformers, let’s ask SRL BERT.
Investigating with SRL
Chapter 10 ended with my recommendation to use SRL with other tools, which we are doing now.
I first ran She was satisfied using the Semantic Role Labeling interface on https://demo.allennlp.org/.
The result was correct:

Figure 12.11: SRL of a simple sentence
The analysis is clear in the frame of this predicate: was is the verb, She is ARG1, and satisfied is ARG2.
We should find the same analysis in a complex sentence, and we do:
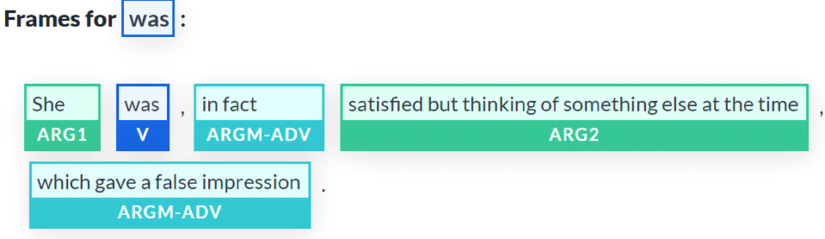
Figure 12.12: The verb “satisfied” is merged with other words, causing confusion
Satisfied is still ARG2, so the problem might not be there.
Now, the focus is on ARGM-ADV, which modifies was as well. The word false is quite misleading because ARGM-ADV is relative to ARG2, which contains thinking.
The thinking predicate gave a false impression, but thinking is not identified as a predicate in this complex sentence. Could it be that she was is an unidentified ellipsis, as we saw in the Questioning the scope of SRL section of Chapter 10?
We can quickly verify that by entering the full sentence without an ellipsis:
Though the customer seemed unhappy, she was, in fact, satisfied but she was thinking of something else at the time, which gave a false impression.
The problem with SRL was the ellipsis again, as we saw in Chapter 10. We now have five correct predicates with five accurate frames.
Frame 1 shows that unhappy is correctly related to seemed:

Figure 12.13: “Unhappy” is correctly related to “seemed”
Frame 2 shows that satisfied is now separated from the sentence and individually identified as an argument of was in a complex sentence:

Figure 12.14: “satisfied” is now a separate word in ARG2
Now, let’s go straight to the predicate containing thinking, which is the verb we wanted BERT SRL to analyze correctly. Now that we suppressed the ellipsis and repeated “she was” in the sentence, the output is correct:
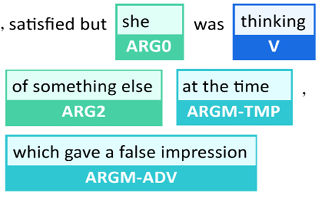
Figure 12.15: Accurate output without an ellipsis
Now, we can leave our SRL investigation with two clues:
- The word
falseis a confusing argument for an algorithm to relate to other words in a complex sentence - The ellipsis of the repetition of
she was
Before we go to GPT-3, let’s go back to Hugging Face with our clues.
Investigating with Hugging Face
Let’s go back to the DistilBERT base uncased fine-tuned SST-2 model we used in this chapter’s DistilBERT for SST section.
We will investigate our two clues:
- The ellipsis of
she wasWe will first submit a full sentence with no ellipsis:
Though the customer seemed unhappy, she was, in fact, satisfied but she was thinking of something else at the time, which gave a false impressionThe output remains negative:
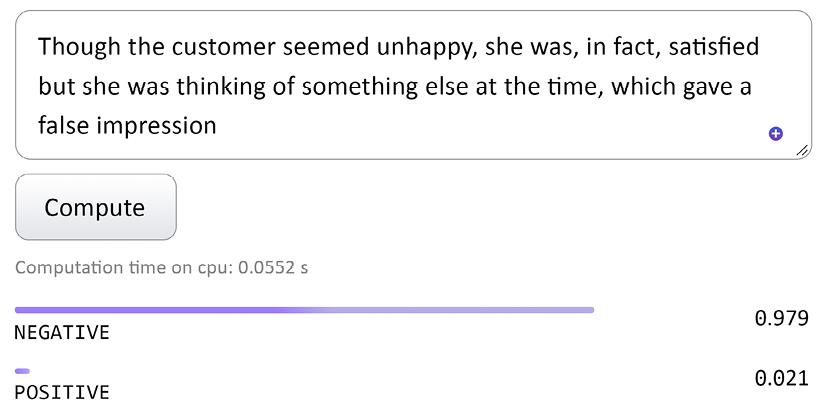
Figure 12.16: A false negative
- The presence of
falsein an otherwise positive sentence.We will now take
falseout of the sentence but leave the ellipsis:Though the customer seemed unhappy, she was, in fact, satisfied but thinking of something else at the time, which gave an impressionBingo! The output is positive:
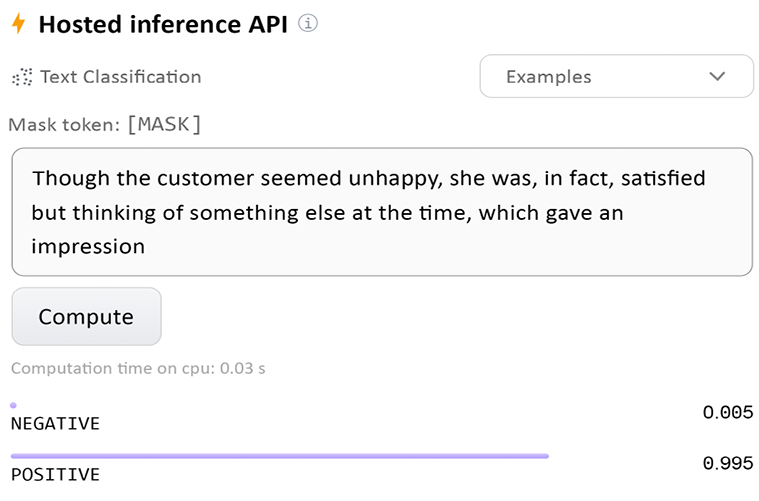
Figure 12.17: A true positive
We know that the word false creates confusion for SRL if there is an ellipsis of was thinking. We also know that false creates confusion for the sentiment analysis Hugging Face transformer model we used.
Can GPT-3 do better? Let’s see.
Investigating with the GPT-3 playground
Let’s use the OpenAI’s example of an Advanced tweet classifier and modify it to satisfy our investigation in three steps:
- Step 1: Showing GPT-3 what we expect:
Sentence:
"The customer was satisfied"Sentiment:
PositiveSentence:
"The customer was not satisfied"Sentiment:
NegativeSentence:
"The service was "
" Sentiment:
PositiveSentence:
"This is the link to the review"Sentiment:
Neutral - Step 2: Showing it a few examples of the output format we expect:
1. "I loved the new Batman movie!"2. "I hate it when my phone battery dies"3. "My day has been"4. "This is the link to the article"5. "This new music video blew my mind"Sentence sentiment ratings:
1: Positive2: Negative3: Positive4: Neutral5: Positive - Step 3: Entering our sentence among others (number 3):
1. "I can't stand this product"2. "The service was bad! "
"3. "Though the customer seemed unhappy she was in fact satisfied but thinking of something else at the time, which gave a false impression"4. "The support team was
"5. "Here is the link to the product."Sentence sentiment ratings:
1: Negative2: Positive3: Positive4: Positive5: Neutral
The output seems satisfactory since our sentence is positive (number 3). Is this result reliable? We could run the example here several times. But let’s go down to code level to find out.
GPT-3 code
We just click on View code in the playground, copy it, and paste it into our SentimentAnalysis.ipynb chapter notebook. We add a line to only print what we want to see:
response = openai.Completion.create(
engine="davinci",
prompt="This is a Sentence sentiment classifier
Sentence: "The customer was satisfied"
Sentiment: Positive
###
Sentence: "The customer was not satisfied"
Sentiment: Negative
###
Sentence: "The service was The output is not stable, as we can see in the following responses:
- Run 1: Our sentence (number 3) is neutral:
1: Negative2: Negative3: Neutral4: Positive5: Positive - Run 2: Our sentence (number 3) is positive:
1: Negative2: Negative3: Positive4: Positive5: Neutral - Run 3: Our sentence (number 3) is positive
- Run 4: Our sentence (number 3) is negative
This leads us to the conclusions of our investigation:
- SRL shows that if a sentence is simple and complete (no ellipsis, no missing words), we will get a reliable sentiment analysis output.
- SRL shows that if the sentence is moderately difficult, the output might, or might not, be reliable.
- SRL shows that if the sentence is complex (ellipsis, several propositions, many ambiguous phrases to solve, and so on), the result is not stable, and therefore not reliable.
The conclusions of the job positions of developers in the present and future are:
- Less AI development will be required with Cloud AI and ready-to-use modules.
- More design skills will be required.
- Classical development of pipelines to feed AI algorithms, control them, and analyze their outputs will require thinking and targeted development.
This chapter shows a huge future for developers as thinkers, designers, and pipeline development!
It’s now time to sum up our journey and explore new transformer horizons.
Summary
In this chapter, we went through some advanced theories. The principle of compositionality is not an intuitive concept. The principle of compositionality means that the transformer model must understand every part of the sentence to understand the whole sentence. This involves logical form rules that will provide links between the sentence segments.
The theoretical difficulty of sentiment analysis requires a large amount of transformer model training, powerful machines, and human resources. Although many transformer models are trained for many tasks, they often require more training for specific tasks.
We tested RoBERTa-large, DistilBERT, MiniLM-L12-H384-uncased, and the excellent BERT-base multilingual model. We found that some provided interesting answers but required more training to solve the SST sample we ran on several models.
Sentiment analysis requires a deep understanding of a sentence and extraordinarily complex sequences. So, it made sense to try RoBERTa-large-mnli to see what an interference task would produce. The lesson here is not to be conventional with something as unconventional as transformer models! Try everything. Try different models on various tasks. Transformers’ flexibility allows us to try many different tasks on the same model or the same task on many different models.
We gathered some ideas along the way to improve customer relations. If we detect that a customer is unsatisfied too often, that customer might just seek out our competition. If several customers complain about a product or service, we must anticipate future problems and improve our services. We can also display our quality of service with online real-time representations of a transformer’s feedback.
Finally, we ran sentiment analysis with GPT-3 directly online with nothing to do but use the interface! It’s surprisingly effective, but we see that humans are still required to solve the more difficult sequences. We saw how SRL could help identify the issues in complex sequences.
We can conclude that developers have a huge future as thinkers, designers, and pipeline development.
In the next chapter, Analyzing Fake News with Transformers, we’ll use sentiment analysis to analyze emotional reactions to fake news.
Questions
- It is not necessary to pretrain transformers for sentiment analysis. (True/False)
- A sentence is always positive or negative. It cannot be neutral. (True/False)
- The principle of compositionality signifies that a transformer must grasp every part of a sentence to understand it. (True/False)
- RoBERTa-large was designed to improve the pretraining process of transformer models. (True/False)
- A transformer can provide feedback that informs us whether a customer is satisfied or not. (True/False)
- If the sentiment analysis of a product or service is consistently negative, it helps us make the proper decisions to improve our offer. (True/False)
- If a model fails to provide a good result on a task, it requires more training before changing models. (True/False)
References
- Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher Manning, Andrew Ng, and Christopher Potts, Recursive Deep Models for Semantic Compositionality over a Sentiment Treebank: https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf
- Hugging Face pipelines, models, and documentation:
- Yinhan Liu, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov, 2019, RoBERTa: A Robustly Optimized BERT Pretraining Approach: https://arxiv.org/pdf/1907.11692.pdf
- The Allen Institute for AI: https://allennlp.org/
- The Allen Institute for reading comprehension resources: https://demo.allennlp.org/sentiment-analysis
- RoBERTa-large contribution, Zhaofeng Wu: https://zhaofengwu.github.io/
- The Stanford Sentiment Treebank: https://nlp.stanford.edu/sentiment/treebank.html
Join our book’s Discord space
Join the book’s Discord workspace:
https://www.packt.link/Transformers
