
9
Matching Tokenizers and Datasets
When studying transformer models, we tend to focus on the models’ architecture and the datasets provided to train them. We have explored the original Transformer, fine-tuned a BERT-like model, trained a RoBERTa model, explored a GPT-3 model, trained a GPT-2 model, implemented a T5 model, and more. We have also gone through the main benchmark tasks and datasets.
We trained a RoBERTa tokenizer and used tokenizers to encode data. However, we did not explore the limits of tokenizers to evaluate how they fit the models we build. AI is data-driven. Raffel et al. (2019), like all the authors cited in this book, spent time preparing datasets for transformer models.
In this chapter, we will go through some of the limits of tokenizers that hinder the quality of downstream transformer tasks. Do not take pretrained tokenizers at face value. You might have a specific dictionary of words you use (advanced medical language, for example) with words not processed by a generic pretrained tokenizer.
We will start by introducing some tokenizer-agnostic best practices to measure the quality of a tokenizer. We will describe basic guidelines for datasets and tokenizers from a tokenization perspective.
Then, we will see the limits of tokenizers with a Word2Vec tokenizer to describe the problems we face with any tokenizing method. The limits will be illustrated with a Python program.
We will continue our investigation by running a GPT-2 model on a dataset containing specific vocabulary with unconditional and conditional samples.
We will go further and see the limits of byte-level BPE methods. We will build a Python program that displays the results produced by a GPT-2 tokenizer and go through the problems that occur during the data encoding process. This will show that the superiority of GPT-3 is not always necessary for common NLP analysis.
However, at the end of the chapter, we will probe a GPT-3 engine with a Part-of-Speech (POS) task to see how much the model understands and if a ready-to-use tokenized dictionary fits our needs.
This chapter covers the following topics:
- Basic guidelines to control the output of tokenizers
- Raw data strategies and preprocessing data strategies
- Word2Vec tokenization problems and limits
- Creating a Python program to evaluate Word2Vec tokenizers
- Building a Python program to evaluate the output of byte-level BPE algorithms
- Customizing NLP tasks with specific vocabulary
- Running unconditional and conditional samples with GPT-2
- Evaluating GPT-2 tokenizers
Our first step will be to explore the text-to-text methodology defined by Raffel et al. (2019).
Matching datasets and tokenizers
Downloading benchmark datasets to train transformers has many advantages. The data has been prepared, and every research lab uses the same references. Also, the performance of a transformer model can be compared to another model with the same data.
However, more needs to be done to improve the performance of transformers. Furthermore, implementing a transformer model in production requires careful planning and defining best practices.
In this section, we will define some best practices to avoid critical stumbling blocks.
Then we will go through a few examples in Python using cosine similarity to measure the limits of tokenization and encoding datasets.
Let’s start with best practices.
Best practices
Raffel et al. (2019) defined a standard text-to-text T5 transformer model. They also went further. They began destroying the myth of using raw data without preprocessing it first.
Preprocessing data reduces training time. Common Crawl, for example, contains unlabeled text obtained through web extraction. Non-text and markup have been removed from the dataset.
However, the Google T5 team found that much of the text obtained through Common Crawl did not reach the level of natural language or English. So they decided that datasets need to be cleaned before using them.
We will take the recommendations Raffel et al. (2019) made and apply corporate quality control best practices to the preprocessing and quality control phases. Among many other rules to apply, the examples described show the tremendous work required to obtain acceptable real-life project datasets.
Figure 9.1 lists some of the key quality control processes to apply to datasets:
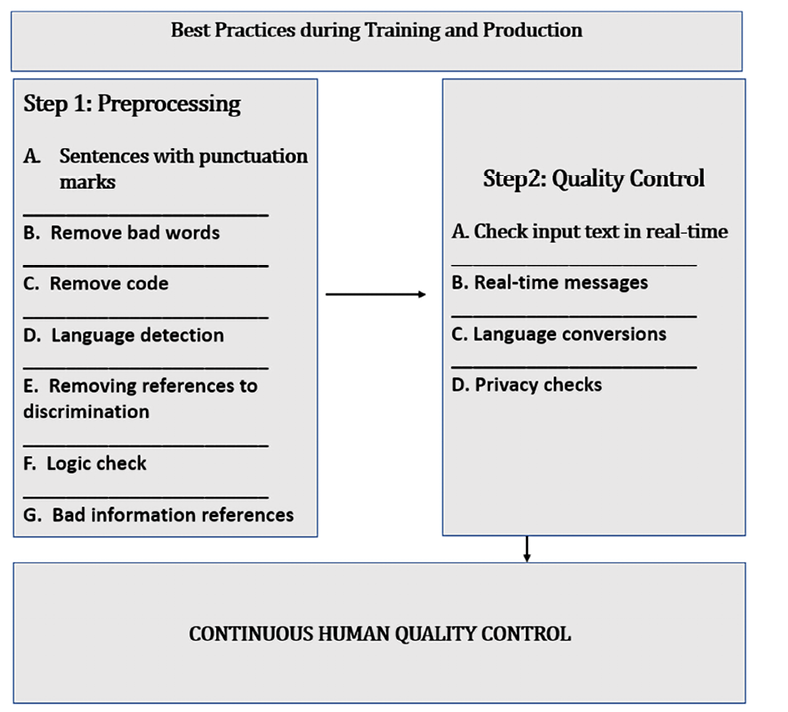
Figure 9.1: Best practices for transformer datasets
As shown in Figure 9.1, quality control is divided into the preprocessing phase (Step 1) when training a transformer and quality control when the transformer is in production (Step 2).
Let’s go through some of the main aspects of the preprocessing phase.
Step 1: Preprocessing
Raffel et al. (2019) recommended preprocessing datasets before training models on them, and I added some extra ideas.
Transformers have become language learners, and we have become their teachers. But to teach a machine-student a language, we must explain what proper English is, for example.
We need to apply some standard heuristics to datasets before using them:
- Sentences with punctuation marks
The recommendation is to select sentences that end with punctuation marks such as a period or a question mark.
- Remove bad words
Bad words should be removed. Lists can be found at the following site, for example: https://github.com/LDNOOBW/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words.
- Remove code
This is tricky because sometimes code is the content we are looking for. However, it is generally best to remove code from content for NLP tasks.
- Language detection
Sometimes, websites contain pages with the default “lorem ipsum” text. It is necessary to make sure all of a dataset’s content is in the language we wish. An excellent way to start is with
langdetect, which can detect 50+ languages: https://pypi.org/project/langdetect/. - Removing references to discrimination
This is a must. My recommendation is to build a knowledge base with everything you can scrape on the web or from specific datasets you can get your hands on. Suppress any form of discrimination. You certainly want your machine to be ethical!
- Logic check
It could be a good idea to run a trained transformer model on a dataset that performs Natural Language Inferences (NLI) to filter sentences that make no sense.
- Bad information references
Eliminate text that refers to links that do not work, unethical websites, or persons. This is a tough job, but certainly worthwhile.
This list contains some of the primary best practices. However, more is required, such as filtering privacy law violations and other actions for specific projects.
Once a transformer is trained to learn proper English, we need to help it detect problems in the input texts in the production phase.
Step 2: Quality control
A trained model will behave like a person who learned a language. It will understand what it can and learn from input data. Input data should go through the same process as Step 1: Preprocessing and add new information to the training dataset. The training dataset, in turn, can become the knowledge base in a corporate project. Users will be able to run NLP tasks on the dataset and obtain reliable answers to questions, useful summaries of specific documents, and more.
We should apply the best practices described in Step 1: Preprocessing to real-time input data. For example, a transformer can be running on input from a user or an NLP task, such as summarizing a list of documents.
Transformers are the most powerful NLP models ever. This means that our ethical responsibility is heightened as well.
Let’s go through some of the best practices:
- Check input text in real time
Do not accept bad information. Instead, parse the input in real time and filter the unacceptable data (see Step 1).
- Real-time messages
Store the rejected data along with the reason it was filtered so that users can consult the logs. Display real-time messages if a transformer is asked to answer an unfitting question.
- Language conversions
You can convert rare vocabulary into standard vocabulary when it is possible. See Case 4 of the Word2Vec tokenization section in this chapter. This is not always possible. When it is, it could represent a step forward.
- Privacy checks
Whether you are streaming data into a transformer model or analyzing user input, private data must be excluded from the dataset and tasks unless authorized by the user or country the transformer is running in. It’s a tricky topic. Consult a legal adviser when necessary.
We just went through some of the best practices. Let’s now see why human quality control is mandatory.
Continuous human quality control
Transformers will progressively take over most of the complex NLP tasks. However, human intervention remains mandatory. We think social media giants have automized everything. Then we discover there are content managers that decide what is good or bad for their platform.
The right approach is to train a transformer, implement it, control the output, and feed the significant results back into the training set. Thus, the training set will continuously improve, and the transformer will continue to learn.
Figure 9.2 shows how continuous quality control will help the transformer’s training dataset grow and increase its performance in production:

Figure 9.2: Continuous human quality control
We have gone through several best practices described by Raffel et al. (2019), and I have added some guidance based on of my experience in corporate AI project management.
Let’s go through a Python program with some examples of some of the limits encountered with tokenizers.
Word2Vec tokenization
As long as things go well, nobody thinks about pretrained tokenizers. It’s like in real life. We can drive a car for years without thinking about the engine. Then, one day, our car breaks down, and we try to find the reasons to explain the situation.
The same happens with pretrained tokenizers. Sometimes the results are not what we expect. For example, some word pairs just don’t fit together, as we can see in Figure 9.3:
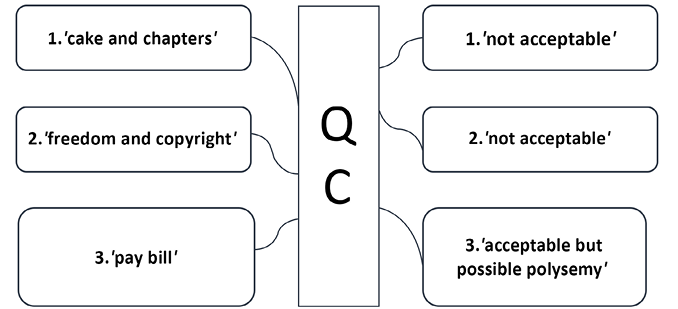
Figure 9.3: Word pairs that tokenizers miscalculated
The examples shown in Figure 9.3 are drawn from the American Declaration of Independence, the Bill of Rights, and the English Magna Carta:
cakeandchaptersdo not fit together, although a tokenizer computed them as having a high value of cosine similarity.freedomrefers to the freedom of speech, for example.copyrightrefers to the note written by the editor of the free ebook.payandbillfit together in everyday English.polysemyis when a word can have several meanings. For example,Billmeans an amount to pay but also refers to theBill of Rights. The result is acceptable, but it may be pure luck.
Before continuing, let’s take a moment to clarify some points. QC refers to quality control. In any strategic corporate project, QC is mandatory. The quality of the output will determine the survival of a critical project. If the project is not strategic, errors will sometimes be acceptable. In a strategic project, even a few errors imply a risk management audit’s intervention to see if the project should be continued or abandoned.
From the perspectives of quality control and risk management, tokenizing datasets that are irrelevant (too many useless words or critical words missing) will confuse the embedding algorithms and produce “poor results.” That is why in this chapter, I use the word “tokenizing” loosely, including some embedding because of the impact of one upon the other.
In a strategic AI project, “poor results” can be a single error with a dramatic consequence (especially in the medical sphere, airplane or rocket assembly, or other critical domains).
Open Tokenizer.ipynb, based on positional_encoding.ipynb, which we created in Chapter 2, Getting Started with the Architecture of the Transformer Model.
Results might vary from one run to another due to the stochastic nature of Word2Vec algorithms.
The prerequisites are installed and imported first:
#@title Pre-Requisistes
!pip install gensim==3.8.3
import nltk
nltk.download('punkt')
import math
import numpy as np
from nltk.tokenize import sent_tokenize, word_tokenize
import gensim
from gensim.models import Word2Vec
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings(action = 'ignore')
text.txt, our dataset, contains the American Declaration of Independence, the Bill of Rights, the Magna Carta, the works of Immanuel Kant, and other texts.
We will now tokenize text.txt and train a word2vec model:
#@title Word2Vec Tokenization
#'text.txt' file
sample = open("text.txt", "r")
s = sample.read()
# processing escape characters
f = s.replace("
", " ")
data = []
# sentence parsing
for i in sent_tokenize(f):
temp = []
# tokenize the sentence into words
for j in word_tokenize(i):
temp.append(j.lower())
data.append(temp)
# Creating Skip Gram model
model2 = gensim.models.Word2Vec(data, min_count = 1, size = 512,window = 5, sg = 1)
print(model2)
window = 5 is an interesting parameter. It limits the distance between the current word and the predicted word in an input sentence. sg = 1 means a skip-gram training algorithm is used.
The output shows that the size of the vocabulary is 10816, the dimensionality of the embeddings is 512, and the learning rate was set to alpha=0.025:
Word2Vec(vocab=10816, size=512, alpha=0.025)
We have a word representation model with embedding and can create a cosine similarity function named similarity(word1,word2). We will send word1 and word2 to the function, which will return a cosine similarity value between them. The higher the value, the higher the similarity.
The function will first detect unknown words, [unk], and display a message:
#@title Cosine Similarity
def similarity(word1,word2):
cosine=False #default value
try:
a=model2[word1]
cosine=True
except KeyError: #The KeyError exception is raised
print(word1, ":[unk] key not found in dictionary")#False implied
try:
b=model2[word2]#a=True implied
except KeyError: #The KeyError exception is raised
cosine=False #both a and b must be true
print(word2, ":[unk] key not found in dictionary")
Cosine similarity will only be calculated if cosine==True, which means that both word1 and word2 are known:
if(cosine==True):
b=model2[word2]
# compute cosine similarity
dot = np.dot(a, b)
norma = np.linalg.norm(a)
normb = np.linalg.norm(b)
cos = dot / (norma * normb)
aa = a.reshape(1,512)
ba = b.reshape(1,512)
#print("Word1",aa)
#print("Word2",ba)
cos_lib = cosine_similarity(aa, ba)
#print(cos_lib,"word similarity")
if(cosine==False):cos_lib=0;
return cos_lib
The function will return cos_lib, the computed value of cosine similarity.
We will now go through six cases. We will name text.txt the “dataset.”
Let’s begin with Case 0.
Case 0: Words in the dataset and the dictionary
The words freedom and liberty are in the dataset, and their cosine similarity can be computed:
#@title Case 0: Words in text and dictionary
word1="freedom";word2="liberty"
print("Similarity",similarity(word1,word2),word1,word2)
The similarity is limited to 0.79 because a lot of content was inserted from various texts to explore the limits of the function:
Similarity [[0.79085565]] freedom liberty
The similarity algorithm is not an iterative deterministic calculation. This section’s results might change with the dataset’s content, the dataset’s size after another run, or the module’s versions. If you run the cell 10 times, you may or may not obtain different values, such as in the following 10 runs.
In the following case, I obtained the same result 10 times with a Google Colab VM and a CPU:
Run 1: Similarity [[0.62018466]] freedom liberty
Run 2: Similarity [[0.62018466]] freedom liberty
...
Run 10: Similarity [[0.62018466]] freedom liberty
However, I did a “factory reset runtime” of the runtime menu in Google Colab. With a new VM and a CPU, I obtained:
Run 1: Similarity [[0.51549244]] freedom liberty
Run 2: Similarity [[0.51549244]] freedom liberty
...
Run 10: Similarity [[0.51549244]] freedom liberty
I performed another “factory reset runtime” of the runtime menu in Google Colab. I also activated the GPU. With a new VM and GPU, I obtained:
Run 1: Similarity [[0.58365834]] freedom liberty
Run 2: Similarity [[0.58365834]] freedom liberty
...
Run 10: Similarity [[0.58365834]] freedom liberty
The conclusion here is that stochastic algorithms are based on probabilities. It is good practice to run a prediction n times if necessary.
Let’s now see what happens when a word is missing.
Case 1: Words not in the dataset or the dictionary
A missing word means trouble in many ways. In this case, we send corporations and rights to the similarity function:
#@title Word(s) Case 1: Word not in text or dictionary
word1="corporations";word2="rights"
print("Similarity",similarity(word1,word2),word1,word2)
The dictionary does not contain the word corporations:
corporations :[unk] key not found in dictionary
Similarity 0 corporations rights
Dead end! The word is an unknown [unk] token.
The missing word will provoke a chain of events and problems that distort the transformer model’s output if the word is important. We will refer to the missing word as unk.
Several possibilities need to be checked, and questions answered:
unkwas in the dataset but was not selected to be in the tokenized dictionary.unkwas not in the dataset, which is the case for the wordcorporations. This explains why it’s not in the dictionary in this case.unkwill now appear in production if a user sends an input to the transformer that contains the token and it is not tokenized.unkwas not an important word for the dataset but is for the usage of the transformer.
The list of problems will continue to grow if the transformer produces terrible results in some cases. We can consider 0.8 as excellent performance for a transformer model for a specific downstream task during the training phase. But in real life, who wants to work with a system that’s wrong 20% of the time:
- A doctor?
- A lawyer?
- A nuclear plant maintenance team?
0.8 is satisfactory in a fuzzy environment like social media, in which many of the messages lack proper language structure anyway.
Now comes the worst part. Suppose an NLP team discovers this problem and tries to solve it with byte-level BPE, as we have been doing throughout this book. If necessary, take a few minutes and go back to Chapter 4, Pretraining a RoBERTa Model from Scratch, Step 3: Training a tokenizer.
The nightmare begins if a team only uses byte-level BPE to fix the problem:
unkwill be broken down into word pieces. For example, we could end up withcorporationsbecomingcorp+o+ra+tion+s. One or several of these tokens have a high probability of being found in the dataset.unkwill become a set of sub-words represented by tokens that exist in the dataset but do not convey the original token’s meaning.- The transformer will train well, and nobody will notice that
unkwas broken into pieces and trained meaninglessly. - The transformer might even produce excellent results and move its performance up from
0.8to0.9. - Everybody will be applauding until a professional user applies an erroneous result in a critical situation. For example, in English,
corpcan meancorporationorcorporal. This could create confusion and bad associations betweencorpand other words.
We can see that the standard of social media might be enough to use transformers for trivial topics. But in real-life corporate projects, it will take hard work to produce a pretrained tokenizer that matches the datasets. In real life, datasets grow every day with user inputs. User inputs become part of the datasets of models that should be trained and updated regularly.
For example, one way to ensure quality control can be through the following steps:
- Train a tokenizer with a byte-level BPE algorithm.
- Control the results with a program such as the one we will create in the Controlling tokenized data section of this chapter.
- Also, train a tokenizer with a Word2Vec algorithm, which will only be used for quality control, then parse the dataset, find the
unktokens, and store them in the database. Run queries to check if critical words are missing.
It might seem unnecessary to check the process in such detail, and you might be tempted to rely on a transformer’s ability to make inferences with unseen words.
However, I recommend running several different quality control methods in a strategic project with critical decision making. For example, in a legal summary of a law, one word can make the difference between losing and winning a case in court. In an aerospace project (airplanes, rockets), there is a 0 error tolerance standard.
The more quality control processes you run, the more reliable your transformer solution will be.
We can see that it takes a lot of legwork to obtain a reliable dataset! Every paper written on transformers refers in one way or another to the work it took to produce acceptable datasets.
Noisy relationships also cause problems.
Case 2: Noisy relationships
In this case, the dataset contained the words etext and declaration:
#@title Case 2: Noisy Relationship
word1="etext";word2="declaration"
print("Similarity",similarity(word1,word2),word1,word2)
Furthermore, they both ended up in the tokenized dictionary:
Similarity [[0.880751]] etext declaration
Even better, their cosine similarity seems to be sure about its prediction and exceeds 0.5. The stochastic nature of the algorithm might produce different results on various runs.
At a trivial or social media level, everything looks good.
However, at a professional level, the result is disastrous!
etext refers to Project Gutenberg’s preface to each ebook on their site, as explained in the Matching datasets and tokenizers section of this chapter. What is the goal of the transformer for a specific task:
- To understand an editor’s preface?
- Or to understand the content of the book?
It depends on the usage of the transformer and might take a few days to sort out. For example, suppose an editor wants to understand prefaces automatically and uses a transformer to generate preface text. Should we take the content out?
declaration is a meaningful word related to the actual content of the Declaration of Independence.
etext is part of a preface that Project Gutenberg adds to all of its ebooks.
This might produce erroneous natural language inferences such as etext is a declaration when the transformer is asked to generate text.
Let’s look into a missing word issue.
Case 3: Words in the text but not in the dictionary
In some cases, a word may be in a text but not in the dictionary. This will distort the results.
Let’s take the words pie and logic:
#@title Case 3: word in text, not in dictionary
word1="pie";word2="logic"
print("Similarity",similarity(word1,word2),word1,word2)
The word pie is not in the dictionary:
pie :[unk] key not found in dictionary
Similarity 0 pie logic
We can assume that the word pie would be in a tokenized dictionary. But what if it isn’t or another word isn’t? The word pie is not in the text file.
Therefore, we should have functions in the pipeline to detect words that are not in the dictionary to implement corrections or alternatives. Also, we should have functions in the pipeline to detect words in the datasets that may be important.
Let’s see the problem we face with rare words.
Case 4: Rare words
Rare words produce devasting effects on the output of transformers for specific tasks that go beyond simple applications.
Managing rare words extends to many domains of natural language. For example:
- Rare words can occur in datasets but go unnoticed, or models are poorly trained to deal with them.
- Rare words can be medical, legal, engineering terms, or any other professional jargon.
- Rare words can be slang.
- There are hundreds of variations of the English language. For example, different English words are used in certain parts of the United States, the United Kingdom, Singapore, India, Australia, and many other countries.
- Rare words can come from texts written centuries ago that are forgotten or that only specialists use.
For example, in this case, we are using the word justiciar:
#@title Case 4: Rare words
word1="justiciar";word2="judgement"
print("Similarity",similarity(word1,word2),word1,word2)
The similarity with judgement is reasonable but should be higher:
Similarity [[0.6606605]] justiciar judgement
You might think that the word justiciar is far-fetched. The tokenizer extracted it from the Magna Carta, dating back to the early 13th century. Unfortunately, the program will get confused, and we will obtain unexpected results after each run.
Note: The predictions may vary from one run to another. However, they show how careful we must be in the tokenizing and embedding phases of our transformer model projects.
However, several articles of the Magna Carta are still valid in 21st century England! For example, clauses 1, 13, 39, and 40 are still valid!
The most famous part of the Magna Carta is the following excerpt, which is in the dataset:
(39) No free man shall be seized or imprisoned, or stripped of his
rights or possessions, or outlawed or exiled, or deprived of his
standing in any other way, nor will we proceed with force against him,
or send others to do so, except by the lawful judgement of his equals
or by the law of the land.
(40) To no one will we sell, to no one deny or delay right or justice.
If we implement a transformer model in a law firm to summarize documents or other tasks, we must be careful!
Let’s now see some methods we could use to solve a rare word problem.
Case 5: Replacing rare words
Replacing rare words represents a project in itself. This work is reserved for specific tasks and projects. Suppose a corporate budget can cover the cost of having a knowledge base in aeronautics, for example. In that case, it is worth spending the necessary time querying the tokenized directory to find words it missed.
Problems can be grouped by topic, solved, and the knowledge base will be updated regularly.
In Case 4, we stumbled on the word justiciar. If we go back to its origin, we can see that it comes from the French Normand language and is the root of the French Latin-like word judicaire.
We could replace the word justiciar with judge, which conveys the same meta-concept:
#@title Case 5: Replacing rare words
word1="judge";word2="judgement"
print("Similarity",similarity(word1,word2),word1,word2)
It produces an interesting result, but we still need to be careful because of the non-deterministic aspect of the algorithm:
Similarity [[0.7962761]] judge judgement
We could also keep the word justiciar, but try the word’s modern meaning and compare it to judge. You could try implementing Case 5: Replacing rare words:
word1="justiciar";word2="judge"
print("Similarity",similarity(word1,word2),word1,word2)
In any case, some rare words need to be replaced by more mainstream words.
The result would be satisfactory:
Similarity [[0.9659128]] justiciar judge
We could create queries with replacement words that we run until we find correlations that are over 0.9, for example. Moreover, if we are managing a critical legal project, we could have the essential documents that contained rare words of any kind translated into standard English. Thus, the transformer’s performance with NLP tasks would increase, and the knowledge base of the corporation would progressively increase.
Let’s now see how to use cosine similarity for entailment verification.
Case 6: Entailment
In this case, we are interested in words in the dictionary and test them in a fixed order.
For example, let’s see if “pay" + “debt" makes sense in our similarity function:
#@title Case 6: Entailment
word1="pay";word2="debt"
print("Similarity",similarity(word1,word2),word1,word2)
The result is satisfactory:
Similarity [[0.89891946]] pay debt
We could check the dataset with several word pairs and check if they mean something. These word pairs could be extracted from emails in a legal department, for example. If the cosine similarity is above 0.9, then the email could be stripped of useless information and the content added to the knowledge base dataset of the company.
Let’s now see how well-pretrained tokenizers match with NLP tasks.
Standard NLP tasks with specific vocabulary
This section focuses on Case 4: Rare words and Case 5: Replacing rare words from the Word2Vec tokenization section of this chapter.
We will use Training_OpenAI_GPT_2_CH09.ipynb, a renamed version of the notebook we used to train a dataset in Chapter 7, The Rise of Suprahuman Transformers with GPT-3 Engines.
Two changes were made to the notebook:
dset, the dataset, was renamedmdsetand contains medical content- A Python function was added to control the text that was tokenized using byte-level BPE
We will not describe Training_OpenAI_GPT_2_CH09.ipynb, which we covered in Chapter 7, The Rise of Suprahuman Transformers with GPT-3 Engines, and Appendices III and IV. Make sure you upload the necessary files before beginning, as explained in Chapter 7.
There is no limit to the time you wish to train the model for. Interrupt it in order to save the model.
The files are on GitHub in the gpt-2-train_files directory of Chapter09. Although we are using the same notebook as in Chapter 7, note that the dataset, dset, is now named mdset in the directory and code.
First, let’s generate an unconditional sample with a GPT-2 model trained to understand medical content.
Generating unconditional samples with GPT-2
We will get our hands dirty in this section to understand the inner workings of transformers. We could, of course, skip the whole chapter and simply use an OpenAI API. However, a 4.0 AI specialist must become an AI guru to show, not vaguely tell, Transformer models what to do through preprocessing pipelines. In order to show a transformer model what to do, it is necessary to understand how a transformer model works.
In Case 4: Rare words, and Case 5: Replacing rare words, we saw that rare words could be words used in a specific field, old English, variations of the English language around the world, slang, and more.
In 2020, the news was filled with medical terms to do with the COVID-19 outbreak. In this section, we will see how a GPT-2 transformer copes with medical text.
The dataset to encode and train contains a paper by Martina Conte and Nadia Loy (2020), named Multi-cue kinetic model with non-local sensing for cell migration on a fibers network with chemotaxis.
The title in itself is not easy to understand and contains rare words.
Load the files located in the gpt-2-train_files directory, including mdset.txt. Then run the code, as explained in Chapter 7, The Rise of Suprahuman Transformers with GPT-3 Engines. You can run this code cell by cell using Chapter 7 to guide you. Take special care to follow the instructions to make sure tf 1.x is activated. Make sure to run Step 4, then restart the runtime and then run the Step 4 tf 1.x cell again before continuing. Otherwise you will get an error in the notebook. We are getting our hands dirty to use the low-level original GPT-2 code in this section and not an API.
After training the model on the medical dataset, you will reach the unconditional sample cell, Step 11: Generating Unconditional Samples:
#@title Step 11: Generating Unconditional Samples
import os # import after runtime is restarted
os.chdir("/content/gpt-2/src")
!python generate_unconditional_samples.py --model_name '117M'
The time it takes to run this command and the other code in this notebook depends on the power of your machine. This notebook and all other GPT-2 code is explained for educational purposes only in this book. It is recommended to use OpenAI’s API for GPT-3 in production. The response times are faster for transformer projects.
Run the cell and stop it when you wish. It will produce a random output:
community-based machinery facilitates biofilm growth. Community members place biochemistry as the main discovery tool to how the cell interacts with the environment and thus with themselves, while identifying and understanding all components for effective Mimicry.
2. Ol Perception
Cytic double-truncation in phase changing (IP) polymerases (sometimes called "tcrecs") represents a characteristic pattern of double-crossing enzymes that alter the fundamental configuration that allows initiation and maintenance of process while chopping the plainNA with vibrational operator. Soon after radical modification that occurred during translational parasubstitution (TMT) achieved a more or less uncontrolled activation of SYX. TRSI mutations introduced autophosphorylation of TCMase sps being the most important one that was incorporated into cellular double-triad (DTT) signaling across all
cells, by which we allow R h and ofcourse an IC 2A- >
.../...
If we have a close look at the output, we notice the following points:
- The structure of the generated sentences is relatively acceptable
- The grammar of the output is not bad
- To a non-professional, the output might seem human-like
However, the content makes no sense. The transformer was unable to produce real content related to the medical paper we trained. Obtaining better results will take hard work. Of course, we can always increase the size of the dataset. But will it contain what we are looking for? Could we find wrong correlations with more data? For example, imagine a medical project involving COVID-19 with a dataset containing the following sentences:
COVID-19 is not a dangerous virus, but it is like ordinary flu.COVID-19 is a very dangerous virus.COVID-19 is not a virus but something created by a lab.COVID-19 was certainly not created by a lab!Vaccines are dangerous!Vaccines are lifesavers!Governments did not manage the pandemic correctly.Governments did what was necessary.
And more contradictory sentences such as these. These discrepancies confirm that both datasets and tokenizers must be customized for specialized healthcare projects, aeronautics, transportation, and other critical domains.
Imagine you have a dataset with billions of words, but the content is so conflictual and noisy that you could never obtain a reliable result no matter what you try!
This could mean that the dataset would have to be smaller and limited to content from scientific papers. But even then, scientists often disagree with each other.
The conclusion is that it will take a lot of hard work and a solid team to produce reliable results.
Let’s now try to condition the GPT-2 model.
Generating trained conditional samples
In this section, we move to the Step 12: Interactive Context and Completion Examples cell of the notebook and run it:
#@title Step 12: Interactive Context and Completion Examples
import os # import after runtime is restarted
os.chdir("/content/gpt-2/src")
!python interactive_conditional_samples.py --temperature 0.8 --top_k 40 --model_name '117M' --length 50
An Industry 4.0 AI specialist will focus less on code and more on how to show a transformer model what to do. Every model requires a level of showing what to do and not just using unconditional data to tell it to vaguely do something.
We condition the GPT-2 model by entering a part of the medical paper:
During such processes, cells sense the environment and respond to external factors that induce a certain direction of motion towards specific targets (taxis): this results in a persistent migration in a certain preferential direction. The guidance cues leading to directed migration may be biochemical or biophysical. Biochemical cues can be, for example, soluble factors or growth factors that give rise to chemotaxis, which involves a mono-directional stimulus. Other cues generating mono-directional stimuli include, for instance, bound ligands to the substratum that induce haptotaxis, durotaxis, that involves migration towards regions with an increasing stiffness of the ECM, electrotaxis, also known as galvanotaxis, that prescribes a directed motion guided by an electric field or current, or phototaxis, referring to the movement oriented by a stimulus of light [34]. Important biophysical cues are some of the properties of the extracellular matrix (ECM), first among all the alignment of collagen fibers and its stiffness. In particular, the fiber alignment is shown to stimulate contact guidance [22, 21]. TL;DR:
We added TL;DR: at the end of the input text to tell the GPT-2 model to summarize the text we conditioned it with. The output makes sense, both grammatically and semantically:
the ECM of a single tissue is the ECM that is the most effective.
To address this concern, we developed a novel imaging and immunostaining scheme that, when activated, induces the conversion of a protein to its exogenous target
Since the outputs are non-deterministic, we could get this response also:
Do not allow the movement to be directed by a laser (i.e. a laser that only takes one pulse at a time), but rather a laser that is directed at a target and directed at a given direction. In a nutshell, be mindful.
The results are better but require more research.
The conclusion we can draw from this example and chapter is that pretraining transformer models on vast amounts of random web crawl data, for example, will teach the transformer English. However, like us, a transformer also needs to be trained in specific domains to become a specialist in that field.
Let’s take our investigation further and control the tokenized data.
Controlling tokenized data
This section will read the first words the GPT-2 model encoded with its pretrained tokenizer.
When running the cells, stop a cell before running a subsequent one.
We will go to the Additional Tools: Controlling Tokenized Data cell of the Training_OpenAI_GPT_2_CH09.ipynb notebook we are using in this chapter. This cell was added to the notebook for this chapter.
The cell first unzips out.npz, which contains the encoded medical paper that is in the dataset, mdset:
#@title Additional Tools : Controlling Tokenized Data
#Unzip out.npz
import zipfile
with zipfile.ZipFile('/content/gpt-2/src/out.npz', 'r') as zip_ref:
zip_ref.extractall('/content/gpt-2/src/')
out.npz is unzipped and we can read arr_0.npy, the NumPy array that contains the encoded dataset we are looking for:
#Load arr_0.npy which contains encoded dset
import numpy as np
f=np.load('/content/gpt-2/src/arr_0.npy')
print(f)
print(f.shape)
for i in range(0,10):
print(f[i])
The output is the first few elements of the array:
[1212 5644 326 ... 13 198 2682]
We will now open encoder.json and convert it into a Python dictionary:
#We first import encoder.json
import json
i=0
with open("/content/gpt-2/models/117M/encoder.json", "r") as read_file:
print("Converting the JSON encoded data into a Python dictionary")
developer = json.load(read_file) #converts the encoded data into a Python dictionary
for key, value in developer.items(): #we parse the decoded json data
i+=1
if(i>10):
break;
print(key, ":", value)
Finally, we display the key and value of the first 500 tokens of our encoded dataset:
#We will now search for the key and value for each encoded token
for i in range(0,500):
for key, value in developer.items():
if f[i]==value:
print(key, ":", value)
The first words of mdset.txt are as follows:
This suggests that
I added those words to make sure the GPT-2 pretrained tokenizer would easily recognize them, which is the case:
This : 1212
Ġsuggests : 5644
Ġthat : 326
We can easily recognize the initial tokens preceded by the initial whitespace characters (Ġ). However, let’s take the following word in the medical paper:
amoeboid
amoeboid is a rare word. We can see that the GPT-2 tokenizer broke it down into sub-words:
Ġam : 716
o : 78
eb : 1765
oid : 1868
Let’s skip the whitespace and look at what happened. amoeboid has become am + o+ eb + oid. We must agree that there are no unknown tokens: [unk]. That is due to the byte-level BPE strategy used.
However, the transformer’s attention layers might associate:
amwith other sequences such asI amowith any sequence that was taken apart and contained anoas welloidwith another sequence containingoid, possiblytabloidwith some algorithms
This is not good news at all. Let’s take this further with the following words:
amoeboid and mesenchymal
The output clearly displays and. As for the rest, the tokens are confusing:
Ġam : 716
o : 78
eb : 1765
oid : 1868
Ġand : 290
Ġmes : 18842
ench : 24421
ym : 4948
al : 282
You might wonder why this is a problem. The reason can be summed up in one word: polysemy. If we use a word2vec tokenizer, the dictionary might not contain rare words such as amoeboid, and we would come up with an unknown token.
If we use byte-level BPE, we obtain overall better results because we exclude fewer variations of the same word, such as go and go + ing.
However, the am token in amoeboid brings polysemy into the problem at a low level. am can be a sort of prefix, the word am as in I + am, or a sub-word such as in am + bush. Attention layers could associate the am of one token with another am, creating relationships that do not exist. This defines the core problem of polysemy in NLU.
We can say that progress is being made, but we need to work harder to improve NLP.
We have gone through a lot of the everyday problems we face in real-life projects using some examples. Take some time and try some examples you think are useful.
Before we leave, we will use a probing task to verify the level of NLU that a transformer model provides.
Exploring the scope of GPT-3
Even the most powerful transformers such as OpenAI GPT-3 have their limits. Let’s see how GPT-3 reacts to the word amoeboid, which is closer to a medical term than a mainstream word. We will need technical jargon in many projects. Matching datasets requires quality control of how a transformer organizes its dictionary and embeddings.
We humans can detect errors and correct somebody. For example, in this chapter, we explored the word amoeboid in the Controlling tokenized data section of this chapter.
Let’s first ask GPT-3 what amoeboid means:

Figure 9.4: Asking GPT-3 what “amoeboid” means
amoeboid (resembling an amoeba) is an adjective, yet GPT-3 states that it is a noun in the output:
A: Amoeboid is a noun which means "resembling an amoeba"
We then ask GPT-3 a more precise question and still obtain an incorrect answer:
Q: Is amoeboid a noun or an adjective?
A: Amoeboid is a noun.
Finally, we insist and ask for a clear definition and obtain a correct answer:
Q: What does amoeboid mean in medical terms?
A: Amoeboid means "resembling an amoeba".
The definition is accurate, although the grammatical analysis isn’t.
What’s more important in a real-life project? To understand the definition of a word or to identify its role in a sentence as an adjective or a noun?
The definition of a word is sufficient for a medical project. In this case, GPT-3 might be sufficient. If the definition is sufficient, SRL wasn’t a prerequisite for understanding a sentence.
Maybe grammatical aspects are important for an educational grammar school project, but not for corporate supply chain, finance, and e-commerce applications.
OpenAI GPT-3 can be fine-tuned in both cases, as we saw in Chapter 7, The Rise of Suprahuman Transformers with GPT-3 Engines.
This section concludes that we have to ensure we have all the data we need in a trained transformer model. If not, the tokenization process will be incomplete. Maybe we should have taken a medical dictionary and created a large corpus of medical articles that contained that specific vocabulary. Then if the model still is not accurate enough, we might have to tokenize our dataset and train a model from scratch.
A 2022 developer will have less development work, but will still have to think and design a lot!
Let’s now conclude this chapter and move on to another NLU task.
Summary
In this chapter, we measured the impact of the tokenization and subsequent data encoding process on transformer models. A transformer model can only attend to tokens from the embedding and positional encoding sub-layers of a stack. It does not matter if the model is an encoder-decoder, encoder-only, or decoder-only model. It does not matter if the dataset seems good enough to train.
If the tokenization process fails, even partly, the transformer model we are running will miss critical tokens.
We first saw that for standard language tasks, raw datasets might be enough to train a transformer.
However, we discovered that even if a pretrained tokenizer has gone through a billion words, it only creates a dictionary with a small portion of the vocabulary it comes across. Like us, a tokenizer captures the essence of the language it is learning and only remembers the most important words if these words are also frequently used. This approach works well for a standard task and creates problems with specific tasks and vocabulary.
We then looked for some ideas, among many, to work around the limits of standard tokenizers. We applied a language checking method to adapt the text we wish to process, such as how a tokenizer thinks and encodes data.
We applied the method to unconditional and conditional tasks with GPT-2.
Finally, we analyzed the limits of data tokenizing and matching datasets with GPT-3. The lesson you can take away from this chapter is that AI specialists are here to stay for quite some time!
In the next chapter, Semantic Role Labeling with BERT-Based Transformers, we will dig deep into NLU and use a BERT model to ask a transformer to explain the meaning of a sentence.
Questions
- A tokenized dictionary contains every word that exists in a language. (True/False)
- Pretrained tokenizers can encode any dataset. (True/False)
- It is good practice to check a database before using it. (True/False)
- It is good practice to eliminate obscene data from datasets. (True/False)
- It is good practice to delete data containing discriminating assertions. (True/False)
- Raw datasets might sometimes produce relationships between noisy content and useful content. (True/False)
- A standard pretrained tokenizer contains the English vocabulary of the past 700 years. (True/False)
- Old English can create problems when encoding data with a tokenizer trained in modern English. (True/False)
- Medical and other types of jargon can create problems when encoding data with a tokenizer trained in modern English. (True/False)
- Controlling the output of the encoded data produced by a pretrained tokenizer is good practice. (True/False)
References
- Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu, 2019, Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer: https://arxiv.org/pdf/1910.10683.pdf
- OpenAI GPT-2 GitHub repository: https://github.com/openai/gpt-2
- N. Shepperd GitHub repository: https://github.com/nshepperd/gpt-2
- Hugging Face framework and resources: https://huggingface.co/
- U.S. Legal, Montana Corporate Laws: https://corporations.uslegal.com/state-corporation-law/montana-corporation-law/#:~:text=Montana%20Corporation%20Law,carrying%20out%20its%20business%20activities
- Martina Conte, Nadia Loy, 2020, Multi-cue kinetic model with non-local sensing for cell migration on a fibers network with chemotaxis: https://arxiv.org/abs/2006.09707
- The Declaration of Independence of the United States of America, by Thomas Jefferson: https://www.gutenberg.org/ebooks/1
- The United States Bill of Rights, by the United States, and related texts: https://www.gutenberg.org/ebooks/2
- The Magna Carta: https://www.gutenberg.org/ebooks/10000
- The Critique of Pure Reason, The Critique of Practical Reason, and Fundamental Principles of the Metaphysic of Moral: https://www.gutenberg.org
Join our book’s Discord space
Join the book’s Discord workspace:
https://www.packt.link/Transformers
