
Appendix A. MDA: Model-Driven Architecture
This appendix summarizes Model Driven Architecture (MDA). Several authors dedicate whole books to MDA; seek out those books. The treatment here aims simply to demystify MDA enough so that you can talk sensibly about it. Better yet, investigate the vendor offerings. Abstract descriptions don’t deliver value: tools do.
Tip
Both Model Driven Architecture and MDA, like the Unified Modeling Language and UML, are trademarks of the Object Management Group.
What Is MDA?
MDA is the natural evolution of UML, Object Oriented Analysis and Design (OOAD), code generators, and third millennium computing power. At the highest level, MDA envisions the day that UML models become the standard way to design and build software. Business software developers will build their systems through MDA tools. Development in 3GL languages such as Java or .Net will remain a toilsome necessity for the system level. For business applications, current languages will be too inefficient to be viable, used only by the most backward-looking organizations. As an analogy, consider the place of assembler and C (or even C++) in main-line business applications today.
MDA uses models to get the highest leverage out of software development. MDA isn’t a development process. It isn’t a specification. It isn’t an implementation. It isn’t a conformance suite. It doesn’t have a reference implementation. The OMG, wisely, has avoided specifying how you go about leveraging software models. MDA has not matured, so each of the nearly 50 companies committed to MDA promote vastly differing visions. If you find this confusing, you aren’t alone.
MDA defines a framework for processing and relating models. MDA tools transform pure business models into complete, deployable, running applications with a minimum of technological decisions. Modifying the pure business model behind an application require only updates in the dependent technological area(s). Technology decisions unrelated to the change remain, so the application can be regenerated in a matter of a few minutes.
An application has many concerns; some related to the business itself, some related to a particular implementation tier, some related to a particular implementation technology. MDA further separates the technological concerns of an application from the business; it separates high-level technical decisions from their technological implementation; it separates one technology from another. Web forms or database tactics don’t complicate the business concepts of, say, Account and Customer. Transaction management decisions don’t affect persistence. Messaging doesn’t interfere with property management or security. Each technology can be replaced without recoding. In the extreme case, the business application can be redeployed on a completely different technology platform.
MDA keeps these separate concerns in different models, while at the same time keeping the system consistent and coherent as a whole. The concept of account, for example, permeates most or all of the models: business, web, database, persistence, business logic, business delegate, and code. Not only is any one model consistent within itself, but also the concepts from one model relate to the corresponding concepts in other models. Changes in the concept of account must affect all related models. This notion moves significantly ahead of current non-MDA modeling tools that either model everything in one model or require manual synchronization of separate models.
Although ultimately hoping to eliminate all programming languages, current MDA tools can’t provide enough finesse to deliver varied and high quality systems without a hybrid approach of UML and 3GL. MDA allows handcoded extensions and other tweaking throughout the abstraction layers. It remembers the origins of these changes so that subsequent generations of the system respect them.
MDA tools are sophisticated systems. No offering has established itself as a leader. Most of the MDA offerings cater to niche markets. Most predate MDA, so they drag along baggage of a less well-defined approach, or of a well-defined but narrow proprietary approach. None manages highly abstract models and generates crack code and generates a variety of implementations, at least not yet. Though a one-size-fits-all offering doesn’t exist, many offerings are very productive. The goal of MDA, while simple to voice, has yet to be fully implemented.
The Models of MDA
Models play a big role in MDA. As a framework for building systems, MDA abstracts systems into abstraction layers. Traditionally OOAD had analysis, detailed design and code roughly representing a system’s business perspective, the architectural/technological perspective, and the implementation perspective. MDA adds one abstraction on top, representing the business context of the system. Figure A-1 shows the different abstraction layers and their associated MDA models. Abstraction increases toward the left and concreteness increases toward the right. Concrete models outnumber abstract models. In general, the abstract begets the concrete; as each model becomes more concrete, it realizes the abstractions with respect to one technology or platform. The inverse, making abstract models from the concrete, also known as reverse engineering, rarely happens, except when the starting point is code. Even then because the system must support a business, starting from the business needs is generally more appropriate.
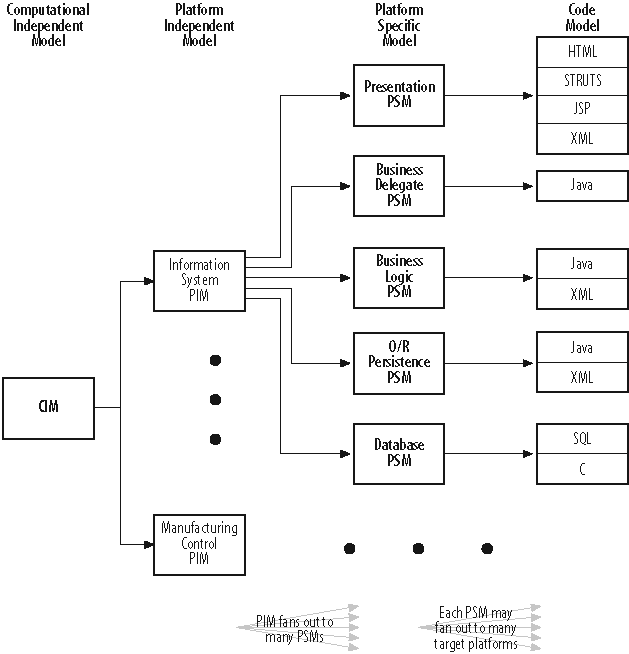
The abstraction models match well with the conceptual layers of a system:
- Computational-independent model (CIM)
The CIM represents the highest-level business model. The CIM uses a specialized business process language and not UML, although its language could well be derived from the meta-object facility (MOF).
The CIM transcends computer systems. Each process interacts with human workers and/or machine components. The CIM describes these interactions between these processes and the responsibilities of each worker, be it human or otherwise.
Anyone understanding business and business processes can understand a CIM. It avoids specialized knowledge of procedures internal to a worker computer system, such as accounting procedures or sales commissions.
- Platform-independent model (PIM)
A PIM represents the business model to be implemented by an information system. Commonly, UML or some UML derivative describes the PIM.
The PIM describes the processes and structure of the system, without reference to the delivery platforms. The PIM ignores operating systems, programming languages, hardware, and networking.
Anyone understanding the specialized domain of the computer system under study can understand the PIM. Although destined to be an information system, the PIM requires no information system background.
The PIM is the starting point for MDA discussions in this appendix.
- Platform-specific model (PSM)
The PSM projects the PIM onto a specific platform. Because one PIM begets multiple PSMs, the PSMs must collaborate to deliver a consistent and complete solution. Commonly, the implementer defines a different UML profile to define the PSM for each target platform.
The PSM realizes the PIM as it applies to one specific platform. The PSM deals explicitly with the operating system, programming language, technology platform (e.g., CORBA, .Net, J2EE, or PHP), remote distribution or local collocation. Although porting from one platform or language probably means discarding the PSM, sibling PSMs and the PIM remain unchanged.
Despite the need for an understanding of the underlying technology to understand the PSM, the understanding need not be profound. Modelers must know the difference between locally and remotely located components; they don’t need to know how to implement or debug them.
- Code model
The code model represents the deployable code, usually in a high-level language such as XML, Java, C#, C++, VB, HTML, JSP, or ASP. It may or may not be readable. It may or may not be extendable, although often it has extension points in the form of protected code blocks.
Ideally, the code model is compile-ready. It doesn’t require any further human intervention. Deployment should be automated. In a mature MDA environment, you can think of the code model as you would think of object files or class files—they’re just machine files, opaque to mere mortals.
In reality, MDA tools aren’t mature. Developers need to understand the technology so that they can debug the application or the deployment. Developers need to load the source into IDEs and debug and deploy as normal. Because little code is actually handwritten, the dilemma is more to deploy correctly than to debug infrastructure.
These models can continue on to the right. We can have a bytecode or link object model, and beyond that a machine code model. Software has matured so much that the vast majority of workers take those models for granted. They just work. If they don’t, we just replace them.
Figure A-1 shows a one-tier PSM. MDA doesn’t restrict PSMs to one tier. Each PSM addresses a different technological layer of a system. If a particular technology lends itself to multiple layers of abstraction, the PSM allows for that too. The specific technologies, and hence, PSMs, are defined by the MDA tool and the architecture it proposes. As a business application developer, you will have to work with that particular framework.
Design Decisions
As you’ve seen in Figure A-1, the number of models increases as you go from the abstract to the concrete. How abstract models become transformed into more concrete models will be discussed a little later. For now, suffice it to say that some function transforms them. Several concrete models can come from a single abstract model. At any one level of abstraction, the model presents the system, without the messiness of implementation details found in the more concrete, downstream models.
Effective model transformation demands precise implementation details. Decisions at one layer imply gross differences at the next, more concrete layer. Consider the following business rules:
There are only a few (50) states, and they don’t change.
Account transactions can be added, but never changed or deleted, and there can be hundreds of thousands of transactions for one account.
Account balances are updated very often, but account contact information is updated relatively rarely compared to the number of times it’s read. Changes must be audited.
If similar code were to be generated to manage these data entities, you would have a very poor system. To live up to its moniker, MDA must provide some clue in the business model to differentiate between these cases. The business layer doesn’t involve itself with design issues such as data access patterns, but it must provide hints. These hints are design decisions . Models provide implicit hints through the structure (a one-to-one association versus a many-to-one association), and they can be elaborated with explicit hints (such as differentiating the three earlier cases).
At the level of code generation, 3GLs have hints, although they work at a much lower level of abstraction. Programmers switch on code optimization or debugging information. As a result, the bytecode/object code becomes vastly different, with different performance characteristics.
Figure A-2 shows how MDA records design decisions as marks . A transformation function uses related marks, held in a subordinate marking model , along with the principle model, either PIM or PSM as the case may be, to create the next, more concrete model. Partitioning the marks into separate marking models keeps the principle model pure, and the marks related to different concerns separate from each other. Were the downstream technology to change, the related marks could be dropped without disturbing the principle model.
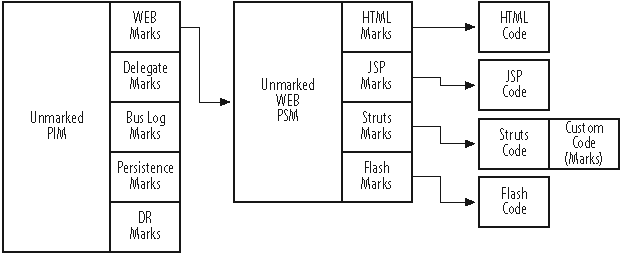
Model elaboration is the intentional enrichment of a generated model. Generated models likely have need tailoring or optimization (otherwise, why have them?). Modelers assign or update the marks to control the transformation function. Programmers will add custom code in protected areas. Marks record both the updates and whether the marks originate from humans.
The unpolluted model, be it PIM or PSM, remains the same no matter how many downstream technologies there are. The principle model remains unchanged, regardless of whether a dependent model appears or disappears.
With the technology concerns partitioned from the principle model and each other, the marking models can evolve independently of each other. The technology functions can create default marks for elements. Technical modelers, who are experts in different fields, elaborate their models separately.
Sewing the Models Together
At any one time, the many models are implicitly related. For example, a transformation function transforms the PIM and related marks from a marking model to create a PSM. An MDA system of models probably has several PSMs, each with its own marking model and at least one code model, and likely its own marking model or handcoded extensions.
Over time, the PIM will change, as will the marks on it and on the PSM. If the transformation function summarily overwrites existing marks explicitly updated by a modeler, the effect of the marks disappears; the modeler must reenter all again. Clearly, this is untenable. On the other hand, deletions from the PIM will remove the justification of derived elements in the PSM. The transformation function must have a way to detect and merge collisions, and to remove deadwood. Traceability of ownership and generation becomes a serious issue.
MDA stores the relationships between source models, marks, and target models in a mapping model . The example in Figure A-3 shows how each element in the target model has a mapping to the source model and the appropriate marks (and, optionally, to the marking models).
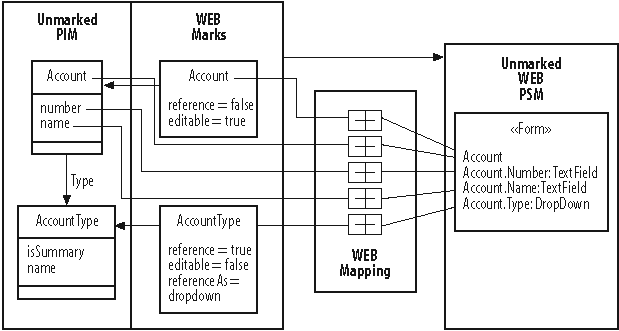
The mappings provide the traceability necessary for subtle evolution of the whole system. The transformation process follows the links when updating a target model from new versions of the source model or source mark model. The transformation function detects conflicts between the generated elements and the existing element added or modified by modelers. It identifies deadwood in the new target model that exists only because of now-deleted elements in the source model.
Transforming Models
The models up to now provide multiple abstractions of the system. They separate the platform concerns. They trace the origin of each element. These models are static. Transformation functions apply a transformation to a source model to produce a target model. Figure A-4 shows the general case of the transformation function creating or updating target models from the source model and marks. The transformation function, along with the marks and the mappings, are called the bridge between the two principle models.
The mapping model acts in two roles. Before the transformation, it relates the elements of the source models, together with previous versions of the target models. After the transformation, the mapping model traces the source of every target model element created or updated.
During model evolution, transformations at the PIM can cause turmoil in the PSM and code models. Because of the leverage MDA gives, slight refactoring can render the mapping model incapable of reconciling changes. If mappings are recorded by element ID, deleting an element and recreating it risks orphaning it from its marks
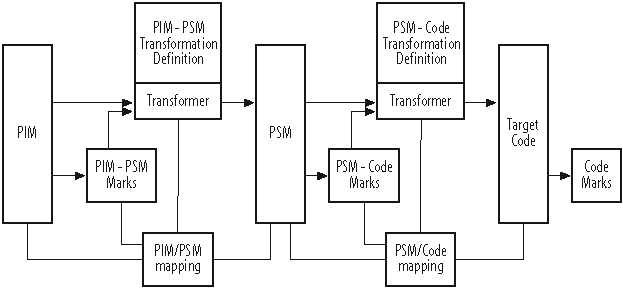
and derivative elements in the target models. If the PSM or code model has a great deal of elaboration, MDA doesn’t proscribe a solution to this.
Figure A-4 shows a transformer acting through a transformation definition. The transformer can be implemented equally well as a script or a procedural language. In any case, each transformation requires its own definition; the transformer from PIM to presentation PSM can’t be reused for the database PSM to SQL code model.
The concept of reverse engineering, or round-trip engineering, received a great deal of interest a few years ago. MDA doesn’t address it specifically. Each transformation function can have an inverse function to create the abstract from the concrete, but nothing requires an MDA solution to provide it.
Reverse engineering generally creates more problems than it solves. You reverse-engineer only elaborate concrete models. Concrete models may not respect the naming conventions, or they may have slight or gross variants of expected patterns. The resultant abstract model will have no insight into the structures found. Furthermore, it becomes unclear where ultimate truth lies. Remember, MDA doesn’t stand for program-driven modeling.
Languages to Formally Describe MDA
The transformations describe in the preceding section can’t work without strict inputs. Each model must respect a structure that constrains its expressiveness formally; automated transformations can’t understand just any model. Each model requires a specialized model, as shown in Figure A-5. UML profiles provide one vehicle to constrain each model; alternative MOF-based metamodels provide another.
Explicit UML profiles enforce constraints so that only models considered valid by the transformers can be processed. Considering the leverage of expression between the PIM and each PSM, and again between each PSM and its derivative

code models, slightly invalid source models would produce rubbish. UML profiles provide the discipline needed to keep such a complex system running.
MDA systems need not have such a formal definition as the one we described. Certainly architects who extend the transformations with custom scripting will not back it with a formal transformation language. The languages act much as DTDs or schemas do for an XML document: languages assure that the consumers will understand the model.