
This webbot project solves a problem shared by all web developers—detecting broken links on web pages. Verifying links on a web page isn't a difficult thing to do, and the associated script is short.
Figure 9-1 shows the simplicity of this webbot.
For clarity, I'll break down the creation of the link-verification webbot into manageable sections, which I'll explain along the way. The code and libraries used in this chapter are available for download at this book's website.
Before validating links on a web page, your webbot needs to load the required libraries and initialize a few key variables. In addition to LIB_http and LIB_parse, this webbot introduces two new libraries: LIB_resolve_addresses and LIB_http_codes. I'll explain these additions as I use them.
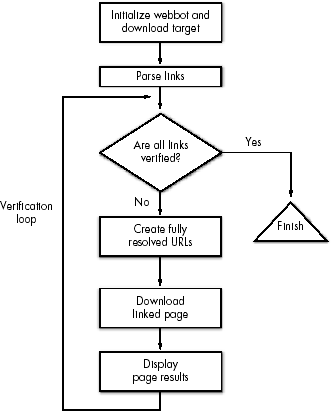
The webbot downloads the target web page with the http_get() function, which was described in Chapter 3.
# Include libraries
include("LIB_http.php");
include("LIB_parse.php");
include("LIB_resolve_addresses.php");
include("LIB_http_codes.php");
# Identify the target web page and the page base
$target = "http://www.schrenk.com/nostarch/webbots/page_with_broken_links.php";
$page_base = "http://www.schrenk.com/nostarch/webbots/";
# Download the web page
$downloaded_page = http_get($target, $ref="");
Listing 9-1: Initializing the bot and downloading the target web page
In addition to defining the $target, which points to a diagnostic page on the book's website, Listing 9-1 also defines a variable called $page_base. A page base defines the domain and server directory of the target page, which tells the webbot where to find web pages referenced with relative links.
Relative links are references to other files—relative to where the reference is made. For example, consider the relative links in Table 9-1.
Table 9-1. Examples of Relative Links
Link | References a File Located In . . . |
|---|---|
| Same directory as web page |
| The page's parent directory (up one level) |
| The page's parent's parent directory (up 2 levels) |
| The server's root directory |
Your webbot would fail if it tried to download any of these links as is, since your webbot's reference point is the computer it runs on, and not the computer where the links where found. The page base, however, gives your webbot the same reference as the target page. You might think of it this way: The page base is to a webbot as the <base> tag is to a browser. The page base sets the reference for everything referred to on the target web page.
You can easily parse all the links and place them into an array with the script in Listing 9-2.
# Parse the links $link_array = parse_array($downloaded_page['FILE'], $beg_tag="<a", $close_tag=">");
Listing 9-2: Parsing the links from the downloaded page
The code in Listing 9-2 uses parse_array() to put everything between every occurrence of <a and > into an array.[28] The function parse_array() is not case sensitive, so it doesn't matter if the target web page uses <a>, <A> or a combination of both tags to define links.
You gain a great deal of convenience when the parsed links are available in an array. The array allows your script to verify the links iteratively through one set of verification instructions, as shown in Listing 9-3. The PHP sections of this script appear in bold.
Listing 9-3 also includes some HTML formatting to create a nice-looking report, which you'll see later. Notice that the contents of the verification loop have been removed for clarity. I'll explain what happens in this loop next.
<b>Status of links on <?echo $target?></b><br>
<table border="1" cellpadding="1" cellspacing="0">
<tr bgcolor="#e0e0e0">
<th>URL</th>
<th>HTTP CODE</th>
<th>MESSAGE</th>
<th>DOWNLOAD TIME (seconds)</th>
</tr>
<?
for($xx=0; $xx<count($link_array); $xx++)
{
// Verification and display go here
}
Listing 9-3: The verification loop
Since the contents of the $link_array elements are actually complete anchor tags, we need to parse the value of the href attribute out of the tags before we can download and test the pages they reference.
The value of the href attribute is extracted from the anchor tag with the function get_attribute(), as shown in Listing 9-4.
// Parse the HTTP attribute from link $link = get_attribute($tag=$link_array[$xx], $attribute="href");
Listing 9-4: Parsing the referenced address from the anchor tag
Once you have the href address, you need to combine the previously defined $page_base with the relative address to create a fully resolved URL, which your webbot can use to download pages. A fully resolved URL is any URL that describes not only the file to download, but also the server and directory where that file is located and the protocol required to access it. Table 9-2 shows the fully resolved addresses for the links in Table 9-1, assuming the links are on a page in the directory, http://www.schrenk.com/nostarch/webbots.
Table 9-2. Examples of Fully Resolved URLs (for links on http://www.schrenk.com/nostarch/book)
Link | Fully Resolved URL |
|---|---|
| |
| |
| |
|
Fully resolved URLs are made with the resolve_address() function (see Listing 9-5), which is in the LIB_resolve_addresses library. This library is a set of routines that converts all possible methods of referencing web pages in HTML into fully resolved URLs.
// Create a fully resolved URL $fully_resolved_link_address = resolve_address($link, $page_base);
Listing 9-5: Creating fully resolved addresses with resolve_address()
The webbot verifies the status of each page referenced by the links on the target page by downloading each page and examining its status. It downloads the pages with http_get(), just as you downloaded the target web page earlier (see Listing 9-6).
// Download the page referenced by the link and evaluate $downloaded_link = http_get($fully_resolved_link_address, $target);
Listing 9-6: Downloading a page referenced by a link
Notice that the second parameter in http_get() is set to the address of the target web page. This sets the page's referer variable to the target page. When executed, the effect is the same as telling the server that someone requested the page by clicking a link from the target web page.
Once the linked page is downloaded, the webbot relies on the STATUS element of the downloaded array to analyze the HTTP code, which is provided by PHP/CURL. (For your future projects, keep in mind that PHP/CURL also provides total download time and other diagnostics that we're not using in this project.)
HTTP status codes are standardized, three-digit numbers that indicate the status of a page fetch.[29] This webbot uses these codes to determine if a link is broken or valid. These codes are divided into ranges that define the type of errors or status, as shown in Table 9-3.
Table 9-3. HTTP Code Ranges and Related Categories
HTTP Code Range | Category | Meaning |
|---|---|---|
100-199 | Informational | Not generally used |
200-299 | Successful | Your page request was successful |
300-399 | Redirection | The page you're looking for has moved or has been removed |
400-499 | Client error | Your web client made a incorrect or illogical page request |
500-599 | Server error | A server error occurred, generally associated with a bad form submission |
The $status_code_array was created when the LIB_http_codes library was imported. When you use the HTTP code as an index into $status_code_array, it returns a human-readable status message, as shown in Listing 9-7. (PHP script is in bold.)
<tr>
<td align="left"><?echo $downloaded_link['STATUS']['url']?></td>
<td align="right"><?echo $downloaded_link['STATUS']['http_code']?></td>
<td align="left"><?echo $status_code_array[$downloaded_link['STATUS']
['http_code']]?></td>
<td align="right"><?echo $downloaded_link['STATUS']['total_time']?></td>
</tr>
Listing 9-7: Displaying the status of linked web pages
As an added feature, the webbot displays the amount of time (in seconds) required to download pages referenced by the links on the target web page. This period is automatically measured and recorded by PHP/CURL when the page is downloaded. The period required to download the page is available in the array element: $downloaded_link['STATUS']['total_time'].
[29] The official reference for HTTP codes is available on the World Wide Web Consortium's website (http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html).