
Now that you know how to store data, you'll want to efficiently store the data in ways that reduce the amount of disk spaced required, while facilitating easy retrieval and manipulation of that data. The following section explores methods for reducing the size of the data your webbots collect in these ways:
Storing references to data
Compressing data
Removing unneeded formatting
Thumbnailing or creating smaller representations of larger graphic files
Since your webbot and the image files it discovers share the same network, it is possible to store a network reference to the image instead of making a physical copy of it. For example, instead of downloading and storing the image north_beach.jpg from www.schrenk.com, you might store a reference to its URL, http://www.schrenk.com/north_beach.jpg, in a database. Now, instead of retrieving the file from your data structure, you could retrieve the actual file from its original location. While you can apply this technique to images, this technique is not limited to image files but also applies to HTML, JavaScript, Style Sheets, or any other networked file.
There are three main advantages to recording references to images instead of storing copies of the images. The most obvious advantage is that the reference to an image will usually consume much less space than a copy of the image file. Another advantage is that if the original image on the website changes, you will still have access to the most current version of that image—provided that the network address of the image hasn't also changed. A less obvious advantage to storing the network address of an image is that you may shield yourself from potential copyright issues when you make a copy of someone else's intellectual property.
The disadvantage of storing a reference to an image instead of the actual images is that there is no guarantee that it still references an image that's available online. When the remote image changes, your reference will be obsolete. Given the short-lived nature of online media, images can change or disappear without warning.
From a webbot's perspective, compression can happen either when a webserver delivers pages or when your webbot compresses pages before it stores them for later use. Compression on inbound files will save bandwidth; the second method can save space on your hard drives. If you're ambitious, you can use both forms of compression.
Many webservers automatically compress files before they serve pages to browsers. Managing your incoming data is just as important as managing the data on your hard drive.
Servers configured to serve compressed web pages will look for signals from the web client indicating that it can accept compressed pages. Like browsers, your webbots can also tell servers that they can accept compressed data by including the lines shown in Listing 6-7 in your PHP and cURL routines.
$header[] = "Accept-Encoding: compress, gzip"; curl_setopt($curl_session, CURLOPT_HTTPHEADER, $header);
Listing 6-7: Requesting compressed files from a webserver
Servers equipped to send compressed web pages won't send compressed files if they decide that the web agent cannot decompress the pages. Servers default to uncompressed pages if there's any doubt of the agent's ability to decompress compressed files. Over the years, I have found that some servers look for specific agent names—in addition to header directions—before deciding to compress outgoing data. For this reason, you won't always gain the advantage of inbound compression if your webbot's agent name is something nonstandard like Test Webbot. For that reason, when inbound file compression is important, it's best if your webbot emulates a common browser.[22]
Since the webserver is the final arbiter of an agent's ability to handle compressed data—and since it always defaults on the side of safety (no compressions)—you're never guaranteed to receive a compressed file, even if one is requested. If you are requesting compression from a server, it is incumbent on your webbot to detect whether or not a web page was compressed. To detect compression, look at the returned header to see if the web page is compressed and, if so, what form of compression was used (as shown in Listing 6-8).
if (stristr($http_header, "zip")) // Assumes that header is in $http_header
$compressed = TRUE;
Listing 6-8: Analyzing the HTTP header to detect inbound file compression
If the data was compressed by the server, you can decompress the files with the function gzuncompress() in PHP, as shown in Listing 6-9.
$uncompressed_file = gzuncompress($compressed_file);
Listing 6-9: Decompressing a compressed file
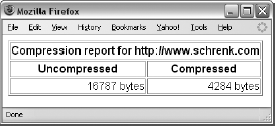
PHP provides a variety of built-in functions for compressing data. Listing 6-10 demonstrates these functions. This script downloads the default HTML file from http://www.schrenk.com, compresses the file, and shows the difference between the compressed and uncompressed files. The PHP sections of this script appear in bold.
# Demonstration of PHP file compression # Include cURL library include("LIB_http.php"); # Get web page $target = "http://www.schrenk.com"; $ref = ""; $method = "GET"; $data_array = ""; $web_page = http_get($target, $ref, $method, $data_array, EXCL_HEAD); # Get sizes of compressed and uncompressed versions of web page $uncompressed_size = strlen($web_page['FILE']); $compressed_size = strlen(gzcompress($web_page['FILE'], $compression_value = 9)); $noformat_size = strlen(strip_tags($web_page['FILE'])); # Report the sizes of compressed and uncompressed versions of web page ?> <table border="1"> <tr> <th colspan="3">Compression report for <? echo $target?></th> </tr> <tr> <th>Uncompressed</th> <th>Compressed</th> </tr> <tr> <td align="right"><?echo $uncompressed_size?> bytes</td> <td align="right"><?echo $compressed_size?> bytes</td> </tr> </table>
Listing 6-10: Compressing a downloaded file
Running the script from Listing 6-10 in a browser provides the results shown in Figure 6-6.
Before you start compressing everything your webbot finds, you should be aware of the disadvantages of file compression. In this example, compression resulted in files roughly 20 percent of the original size. While this is impressive, the biggest drawback to compression is that you can't do much with a compressed file. You can't perform searches, sorts, or comparisons on the contents of a compressed file. Nor can you modify the contents of a file while it's compressed. Furthermore, while text files (like HTML files) compress effectively, many media files like JPG, GIF, WMF, or MOV are already compressed and will not compress much further. If your webbot application needs to analyze or manipulate downloaded files, file compression may not be for you.
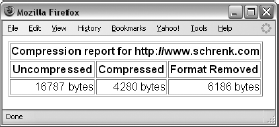
Removing unneeded HTML formatting instructions is much more useful for reducing the size of a downloaded file than compressing it, since it still facilitates access to the useful information in the file. Formatting instructions like <div class="font_a"> are of little use to a webbot because they only control format and not content, and because they can be removed without harming your data. Removing formatting reduces the size of downloaded HTML files while still leaving the option of manipulating the data later. Fortunately, PHP provides strip_tags_(), a built-in function that automatically strips HTML tags from a document. For example, if I add the lines shown in Listing 6-11 to the previous script, we can see the affect of stripping the HTML formatting.
$noformat = strip_tags($web_page['FILE']); // Remove HTML tags $noformat_size = strlen($noformat); // Get size of new string
Listing 6-11: Removing HTML formatting using the strip_tags() function
If you run the program in Listing 6-10 again and modify the output to also show the size of the unformatted file, you will see that the unformatted web page is nearly as compact as the compressed version. The results are shown in Figure 6-7.
{kind=link}
Unlike the compressed data, the unformatted data can still be sorted, modified, and searched. You can make the file even smaller by removing excessive spaces, line feeds, and other white space with a simple PHP function called trim(), without reducing your ability to manipulate the data later. As an added benefit, unformatted pages may be easier to manipulate, since parsing routines won't confuse HTML for the content you're acting on. Remember that removing the HTML tags removes all links, JavaScript, image references, and CSS information. If any of that is important, you should extract it before removing a page's formatting.