
The parsing library used in this book, LIB_parse, provides easy-to-read parsing functions that should meet most parsing tasks your webbots will encounter. Primarily, LIB_parse contains wrapper functions that provide simple interfaces to otherwise complicated routines. To use the examples in this book, you should download the latest version of this library from the book's website.
One of the things you may notice about LIB_parse is the lack of regular expressions. Although regular expressions are the mainstay for parsing text, you won't find many of them here. Regular expressions can be difficult to read and understand, especially for beginners. The built-in PHP string manipulation functions are easier to understand and usually more efficient than regular expressions.
The following is a description of the functions in LIB_parse and the parsing problems they solve. These functions are also described completely within the comments of LIB_parse.
The simplest parsing function returns a string that contains everything before or after a delimiter term. This simple function can also be used to return the text between two terms. The function provided for that task is split_string(), shown in Listing 4-1.
/* string split_string (stringunparsed, stringdelimiter,BEFORE/AFTER,INCL/EXCL)Whereunparsedis the string to parsedelimiterdefines boundary between substring you want and substring you don't wantBEFOREindicates that you want what is before the delimiterAFTERindicates that you want what is after the delimiterINCLindicates that you want to include the delimiter in the parsed textEXCLindicates that you don't want to include the delimiter in the parsed text */
Listing 4-1: Using split_string()
Simply pass split_string() the string you want to split, the delimiter where you want the split to occur, whether you want the portion of the string that is before or after the delimiter, and whether or not you want the delimiter to be included in the returned string. Examples using split_string() are shown in Listing 4-2.
include("LIB_parse.php");
$string = "The quick brown fox";
# Parse what's before the delimiter, including the delimiter
$parsed_text = split_string($string, "quick", BEFORE, INCL);
// $parsed_text = "The quick"
# Parse what's after the delimiter, but don't include the delimiter
$parsed_text = split_string($string, "quick", AFTER, EXCL);
// $parsed_text = "brown fox"
Listing 4-2: Examples of split_string() usage
Sometimes it is useful to parse text between two delimiters. For example, to parse a web page's title, you'd want to parse the text between the <title> and </title> tags. Your webbots can use the return_between() function in LIB_parse to do this.
The return_between() function uses a start delimiter and an end delimiter to define a particular part of a string your webbot needs to parse, as shown in Listing 4-3.
/* string return_between (stringunparsed, stringstart, stringend,INCL/EXCL) Whereunparsedis the string to parsestartidentifies the starting delimiterendidentifies the ending delimiterINCLindicates that you want to include the delimiters in the parsed textEXCLindicates that you don't want to include delimiters in the parsed text */
Listing 4-3: Using return_between()
The script in Listing 4-4 uses return_between() to parse the HTML title of a web page.
# Include libraries
include("LIB_parse.php");
include("LIB_http.php");
# Download a web page
$web_page = http_get($target="http://www.nostarch.com", $referer="");
# Parse the title of the web page, inclusive of the title tags
$title_incl = return_between($web_page['FILE'], "<title>", "</title>", INCL);
# Parse the title of the web page, exclusive of the title tags
$title_excl = return_between($web_page['FILE'], "<title>", "</title>", EXCL);
# Display the parsed text
echo "title_incl = ".$title_incl;
echo "
";
echo "title_excl = ".$title_excl;
Listing 4-4: Using return_between() to find the title of a web page
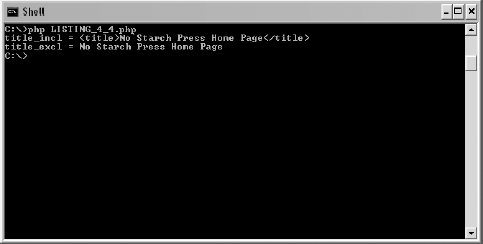
When Listing 4-4 is run in a shell, the results should look like Figure 4-1.
Sometimes the things your webbot needs to parse, like links, appear more than once in a web page. In these cases, a single parsed result isn't as useful as an array of results. Such a parsed array could contain all the links, meta tags, or references to images in a web page. The parse_array() function does essentially the same thing as the return_between() function, but it returns an array of all items that match the parse description or all occurrences of data between two delimiting strings. This function, for example, makes it extremely easy to extract all the links and images from a web page.
The parse_array() function , shown in Listing 4-5, is most useful when your webbots need to parse the content of reoccurring tags. For example, returning an array of everything between every occurrence of <img and > returns information about all the images in a web page. Alternately, returning an array of everything between <script and </script> will parse all inline JavaScript. Notice that in each of these cases, the opening tag is not completely defined. This is because <img and <script are sufficient to describe the tag, and additional parameters (that we don't need to define in the parse) may be present in the downloaded page.
This simple parse is also useful for parsing tables, meta tags, formatted text, video, or any other parts of web pages defined between reoccurring HTML tags.
/* array return_array (stringunparsed, stringbeg, stringend) Whereunparsedis the string to parsebegis a reoccurring beginning delimiterendis a reoccurring ending delimiterarraycontains every occurrence of what's found between beginning and end. */
Listing 4-5: Using parse_array()
The script in Listing 4-6 uses the parse_array() function to parse and display all the meta tags on the FBI website. Meta tags are primarily used to define a web page's content to a search engine.
The following code, which uses parse_array() to gather the meta tags from a web page, could be incorporated with the project in Chapter 11 to determine how adjustments in your meta tags affect your ranking in search engines. To parse all the meta tags, the function must be told to return all instances that occur between <meta and >. Again, notice that the script only uses enough of each delimiter to uniquely identify where a meta tag starts and ends. Remember that the definitions you apply for start and stop variables must apply for each data set you want to parse.
include("LIB_parse.php"); # Include parse library
include("LIB_http.php"); # Include cURL library
$web_page = http_get($target="http://www.fbi.gov", $referer="");
$meta_tag_array = parse_array($web_page['FILE'], "<meta", ">");
for($xx=0; $xx<count($meta_tag_array); $xx++)
echo $meta_tag_array[$xx]."
";
Listing 4-6: Using parse_array() to parse all the meta tags from http://www.fbi.gov
When the script in Listing 4-6 runs, the result should look like Figure 4-2.

Once your webbot has parsed tags from a web page, it is often important to parse attribute values from those tags. For example, if you're writing a spider that harvests links from web pages, you will need to parse all the link tags, but you will also need to parse the specific href attribute of the link tag. For these reasons, LIB_parse includes the get_attribute() function.
The get_attribute() function provides an interface that allows webbot developers to parse specific attribute values from HTML tags. Its usage is shown in Listing 4-7.
/* string get_attribute( stringtag, stringattribute) Wheretagis the HTML tag that contains the attribute you want to parseattributeis the name of the specific attribute in the HTML tag */
Listing 4-7: Using get_attribute()
This parse is particularly useful when you need to get a specific attribute from a previously parsed array of tags. For example, Listing 4-8 shows how to parse all the images from http://www.schrenk.com, using get_attribute() to get the src attribute from an array of <img> tags.
include("LIB_parse.php"); # include parse library
include("LIB_http.php"); # include curl library
// Download the web page
$web_page = http_get($target="http://www.schrenk.com", $referer="");
// Parse the image tags
$meta_tag_array = parse_array($web_page['FILE'], "<img", ">");
// Echo the image source attribute from each image tag
for($xx=0; $xx<count($meta_tag_array); $xx++)
{
$name = get_attribute($meta_tag_array[$xx], $attribute="src");
echo $name ."
";
}
Listing 4-8: Parsing the src attributes from image tags
Figure 4-3 shows the output of Listing 4-8.

Up to this point, parsing meant extracting desired text from a larger string. Sometimes, however, parsing means manipulating text. For example, since webbots usually lack JavaScript interpreters, it's often best to delete JavaScript from downloaded files. In other cases, your webbots may need to remove all images or email addresses from a web page. For these reasons, LIB_parse includes the remove() function. The remove() function is an easy-to-use interface for removing unwanted text from a web page. Its usage is shown in Listing 4-9.
/* string remove( stringweb page, stringopen_tag, stringclose_tag) Whereweb_pageis the contents of the web page you want to affectopen_tagdefines the beginning of the text that you want to removeclose_tagdefines the end of the text you want to remove */
Listing 4-9: Using remove()
By adjusting the input parameters, the remove() function can remove a variety of text from web pages, as shown in Listing 4-10.
$uncommented_page = remove($web_page, "<!--", "-->"); $links_removed = remove($web_page, "<a", "</a>"); $images_removed = remove($web_page, "<img", " >"); $javascript_removed = remove($web_page, "<script", "</script>");
Listing 4-10: Using remove()