
In many respects, this anonymizer is like the previously described network proxies. However, this anonymizer is web-based, in contrast to most (corporate) proxies, which provide the only path from a local network to the Internet. Since all traffic between the private network and the Internet passes through these network proxies, it is simpler for them to modify traffic. Our web-based proxy, in contrast, runs on a web script and must contain the traffic within a browser. What this means is that every link passing through a web-based proxy must be modified to keep the web surfer on the anonymizer's web page, which is shown in Figure 10-5.
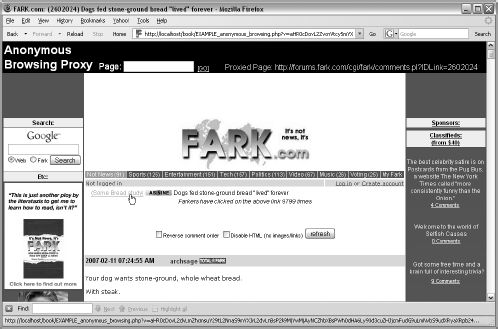
The user interface of the anonymous browsing proxy provides a place for web surfers to enter the URL of the website they wish to surf anonymously. After clicking Go, the page appears in the browser window, and the webserver, where the content originates, records the identity of the anonymizer. Because of the proxy, the webserver has no knowledge of the identity of the web surfer.
In order for the proxy to work, all web surfing activity must happen within the anonymizer script. If someone clicks a link, he or she must return to the anonymizer and not end up at the website referenced by the link. Therefore, before sending the web page to the browser, the anonymizer changes each link address to reference itself, while passing a Base64-encoded address of the link in a variable, as shown in the status bar at the bottom of Figure 10-5.
Note
This is a simple anonymizer, designed for study; it is not suitable for use in production environments. It will not work correctly on web pages that rely on forms, cookies, JavaScript, frames, or advanced web development techniques.
The following scripts describe the anonymizer's design. The complete script for the anonymizer project is available on this book's website.[33] For clarity, only script highlights are described in detail here.
After initializing libraries and variables, which is done in Listing 10-1, the anonymizer downloads and prepares the target web page for later processing. Note that the anonymizer makes use of the parsing and HTTP libraries described in Part I.
# Download the target web page $page_array = http_get($target_webpage), $ref="", GET, $data_array="", EXCL_HEAD); # Clean up the HTML formatting with Tidy $web_page = tidy_html($page_array['FILE']); # Get the base page address so we can create fully resolved addresses later $page_base = get_base_page_address($page_array['STATUS']['url']); # Remove JavaScript and HTML comments from web page $web_page = remove($web_page, "<script", "</script>"); $web_page = remove($web_page, "<!--", "-->");
Listing 10-1: Downloading and prepping the target web page
After prepping the target web page, the <base> tag is either inserted or modified so all relative page addresses will properly resolve from the anonymizer's URL. This is shown in Listing 10-2.
$new_base_value = "<base href="".$page_base."">";
if(!stristr($web_page, "<base"))
{
# If there is a <head>, insert <base> at beginning of <head></head>
if(stristr($web_page, "<head"))
{
$web_page = eregi_replace("<head>", "<head>
".$new_base_value, $web_page);
}
# Else insert a <head><base></head> at beginning of web page
else
{
$web_page = "</head>
".$new_base_value."
</head>" . $web_page;
}
}
Listing 10-2: Adjusting the target page's <base> tag
The next step is to create an array of all the links on the page, which is done with the script in Listing 10-3.
$a_tag_array = parse_array($web_page, "<a", ">");
Listing 10-3: Creating an array of all the links (anchor tags)
After parsing links into an array, the code loops through each link. This loop, shown in Listing 10-4, performs the following steps:
Parse the hyper-reference attribute for each link.
Convert the hyper-reference into a fully resolved URL.
Convert the hyper-reference into the following format:
anonymizer_address?v= hyper referencebase64_encoded
Substitute the original hyper-reference with the URL (representing the
anonymizer_addressand the original link passed as a variable) created in the previous step.
for($xx=0; $xx<count($a_tag_array); $xx++)
{
// Get the original href value
$original_href = get_attribute($a_tag_array[$xx], "href");
// Convert href to a fully resolved address
$fully_resolved_href = get_fully_resolved_address($original_href, $page_base);
// Substitute the original href with "this_page?v=fully resolved address"
$substitution_tag = str_replace($original_href,
trim($this_page."?v=".base64_encode($fully_resolved_href)),
$a_tag_array[$xx]);
// Substitute the original tag with the new one
$web_page = str_replace($a_tag_array[$xx], $substitution_tag, $web_page);
}
Listing 10-4: Substituting links with coded links that re-reference the anonymizer
Once all the links are processed, the anonymizer sends the newly processed web page to the requesting web surfer's browser, as shown in Listing 10-5.
# Display the processed target web page echo $web_page;
Listing 10-5: Displaying the proxied web page
That's all there is to it. The important thing is to design the anonymizer so all links displayed in the anonymizer's window re-reference the anonymizer with a $_GET variable that identifies the actual page to download. This is really not that hard to do, but as mentioned earlier, this anonymizer does not handle forms, cookies, JavaScript, frames, or more advanced web design techniques. That being said, it's a good place to start, and you should use this script to further explore the concept of anonymizing. With a few modifications, you could write web proxies that modify web content in a variety of ways.