
The biggest complaint users have about webbots is their unreliability: Your webbots will suddenly and inexplicably fail if they are not fault tolerant, or able to adapt to the changing conditions of your target websites. This chapter is devoted to helping you write webbots that are tolerant to network outages and unexpected changes in the web pages you target.
Webbots that don't adapt to their changing environments are worse than nonfunctional ones because, when presented with the unexpected, they may perform in odd and unpredictable ways. For example, a non-fault-tolerant webbot may not notice that a form has changed and will continue to emulate the nonexistent form. When a webbot does something that is impossible to do with a browser (like submit an obsolete form), system administrators become aware of the webbot. Furthermore, it's usually easy for system administrators to identify the owner of a webbot by tracing an IP address or matching a user to a username and password. Depending on what your webbot does and which website it targets, the identification of a webbot can lead to possible banishment from the website and the loss of a competitive advantage for your business. It's better to avoid these issues by designing fault-tolerant webbots that anticipate changes in the websites they target.
Fault tolerance does not mean that everything will always work perfectly. Sometimes changes in a targeted website confuse even the most fault-tolerant webbot. In these cases, the proper thing for a webbot to do is to abort its task and report an error to its owner. Essentially, you want your webbot to fail in the same manner a person using a browser might fail. For example, if a webbot is buying an airline ticket, it should not proceed with a purchase if a seat is not available on a desired flight. This action sounds silly, but it is exactly what a poorly programmed webbot may do if it is expecting an available seat and has no provision to act otherwise.
For a webbot, fault tolerance involves adapting to changes to URLs, HTML content (which affect parsing), forms, cookie use, and network outages and congestion). We'll examine each of these aspects of fault tolerance in the following sections.
Possibly the most important type of webbot fault tolerance is URL tolerance, or a webbot's ability to make valid requests for web pages under changing conditions. URL tolerance ensures that your webbot does the following:
Download pages that are available on the target site
Follow header redirections to updated pages
Use referer values to indicate that you followed a link from a page that is still on the website
Before you determine that your webbot downloaded a valid web page, you should verify that you made a valid request. Your webbot can verify successful page requests by examining the HTTP code, a status code returned in the header of every web page. If the request was successful, the resulting HTTP code will be in the 200 series—meaning that the HTTP code will be a three-digit number beginning with a two. Any other value for the HTTP code may indicate an error. The most common HTTP code is 200, which says that the request was valid and that the requested page was sent to the web agent. The script in Listing 25-1 shows how to use the LIB_http library's http_get() function to validate the returned page by looking at the returned HTTP code. If the webbot doesn't detect the expected HTTP code, an error handler is used to manage the error and the webbot stops.
<?
include("LIB_http.php");
# Get the web page
$page = http_get($target="www.schrenk.com", $ref="");
# Vector to error handler if error code detected
if($page['STATUS']['http_code']!="200")
error_handler("BAD RESULT", $page['STATUS']['http_code']);
?>
Listing 25-1: Detecting a bad page request
Before using the method described in Listing 25-1, review a list of HTTP codes and decide which codes apply to your situation.[70]
If the page no longer exists, the fetch will return a 404 Not Found error. When this happens, it's imperative that the webbot stop and not download any more pages until you find the cause of the error. Not proceeding after detecting an error is a far better strategy than continuing as if nothing is wrong.
Web developers don't always remove obsolete web pages from their websites—sometimes they just link to an updated page without removing the old one. Therefore, webbots should start at the web page's home page and verify the existence of each page between the home page and the actual targeted web page. This process does two things. It helps your webbot maintain stealth, as it simulates the browsing habits of a person using a browser. Moreover, by validating that there are links to subsequent pages, you verify that the pages you are targeting are still in use. In contrast, if your webbot targets a page within a site without verifying that other pages still link to it, you risk targeting an obsolete web page.
The fact that your webbot made a valid page request does not indicate that the page you've downloaded is the one you intended to download or that it contains the information you expected to receive. For that reason, it is useful to find a validation point, or text that serves as an indication that the newly downloaded web page contains the expected information. Every situation is different, but there should always be some text on every page that validates that the page contains the content you're expecting. For example, suppose your webbot submits a form to authenticate itself to a website. If the next web page contains a message that welcomes the member to the website, you may wish to use the member's name as a validation point to verify that your webbot successfully authenticated, as shown in Listing 25-2.
$username = "GClasemann";
$page = http_get($target, $ref="");
if(!stristr($page['FILE'], "$username")
{
echo "authentication error";
error_handler("BAD AUTHENTICATION for ".$username, $target);
}
Listing 25-2: Using a username as a validation point to confirm the result of submitting a form
The script in Listing 25-2 verifies that a validation point, in this case a username, exists as anticipated on the fetched page. This strategy works because the only way that the user's name would appear on the web page is if he or she had been successfully authenticated by the website. If the webbot doesn't find the validation point, it assumes there is a problem and it reports the situation with an error handler.
Page redirections are instructions sent by the server that tell a browser that it should download a page other than the one originally requested. Web developers use page redirection techniques to tell browsers that the page they're looking for has changed and that they should download another page in its place. This allows people to access correct pages even when obsolete addresses are bookmarked by browsers or listed by search engines. As you'll discover, there are several methods for redirecting browsers. The more web redirection techniques your webbots understand, the more fault tolerant your webbot becomes.
Header redirection is the oldest method of page redirection. It occurs when the server places a Location: URL line in the HTTP header, where URL represents the web page the browser should download (in place of the one requested). When a web agent sees a header redirection, it's supposed to download the page defined by the new location. Your webbot could look for redirections in the headers of downloaded pages, but it's easier to configure PHP/CURL to follow header redirections automatically.[71] Listing 25-3 shows the PHP/CURL options you need to make automatic redirection happen.
curl_setopt($curl_session, CURLOPT_FOLLOWLOCATION, TRUE); // Follow redirects curl_setopt($curl_session, CURLOPT_MAXREDIRS, 4); // Only follow 4 redirects
Listing 25-3: Configuring PHP/CURL to follow up to four header redirections
The first option in Listing 25-3 tells PHP/CURL to follow all page redirections as they are defined by the target server. The second option limits the number of redirections your webbot will follow. Limiting the number of redirections defeats webbot traps where servers redirect agents to the page they just downloaded, causing an endless number of requests for the same page and an endless loop.
In addition to header redirections, you should also be prepared to identify and accommodate page redirections made between the <head> and </head> tags, as shown in Listing 25-4.
<html>
<head>
<meta http-equiv="refresh" content="0; URL=http://www.nostarch.com">
</head>
</html >
Listing 25-4: Page redirection between the <head> and </head> tags
In Listing 25-4, the web page tells the browser to download http://www.nostarch.com instead of the intended page. Detecting these kinds of redirections is accomplished with a script like the one in Listing 25-5. This script looks for redirections between the <head> and </head> tags in a test page on the book's website.
<?
# Include http, parse, and address resolution libraries
include("LIB_http.php");
include("LIB_parse.php");
include("LIB_resolve_addresses.php");
# Identify the target web page and the page base
$target = "http://www.schrenk.com/nostarch/webbots/head_redirection_test.php";
$page_base = "http://www.schrenk.com/nostarch/webbots/";
# Download the web page
$page = http_get($target, $ref="");
# Parse the <head></head>
$head_section = return_between($string=$page['FILE'], $start="<head>", $end="</head>",
$type=EXCL);
# Create an array of all the meta tags
$meta_tag_array = parse_array($head_section, $beg_tag="<meta", $close_tag=">");
# Examine each meta tag for a redirection command
for($xx=0; $xx<count($meta_tag_array); $xx++)
{
# Look for http-equiv attribute
$meta_attribute = get_attribute($meta_tag_array[$xx], $attribute="http-equiv");
if(strtolower($meta_attribute)=="refresh")
{
$new_page = return_between($meta_tag_array[$xx], $start="URL", $end=">",
$type=EXCL);
# Clean up URL
$new_page = trim(str_replace("", "", $new_page));
$new_page = str_replace("=", "", $new_page);
$new_page = str_replace(""", "", $new_page);
$new_page = str_replace("'", "", $new_page);
# Create fully resolved URL
$new_page = resolve_address($new_page, $page_base);
}
break;
}
# Echo results of script
echo "HTML Head redirection detected<br>";
echo "Redirect page = ".$new_page;
?>
Listing 25-5: Detecting redirection between the <head> and </head> tags
Listing 25-5 is also an example of the need for good coding practices as part of writing fault-tolerant webbots. For instance, in Listing 25-5 notice how these practices are followed:
The script looks for the redirection between the
<head>and</head>tags, and not just anywhere on the web pageThe script looks for the
http-equivattribute only within a meta tagThe redirected URL is converted into a fully resolved address
Like a browser, the script stops looking for redirections when it finds the first one
The last—and most troublesome—type of redirection is that done with JavaScript. These instances are troublesome because webbots typically lack JavaScript parsers, making it difficult for them to interpret JavaScript. The simplest redirection of this type is a single line of JavaScript, as shown in Listing 25-6.
<script>document.location = 'http://www.schrenk.com'; </script>
Listing 25-6: A simple JavaScript page redirection
Detecting JavaScript redirections is also tricky because JavaScript is a very flexible language, and page redirections can take many forms. For example, consider what it would take to detect a page redirection like the one in Listing 25-7.
<html>
<head>
<script>
function goSomeWhereNew(URL)
{
location.href = URL;
}
</script>
<body onLoad=" goSomeWhereNew('http://www.schrenk.com')">
</body>
</html>
Listing 27-7: A complicated JavaScript page redirection
Fortunately, JavaScript page redirection is not a particularly effective way for a web developer to send a visitor to a new page. Some people turn off JavaScript in their browser configuration, so it doesn't work for everyone; therefore, JavaScript redirection is rarely used. Since it is difficult to write fault-tolerant routines to handle JavaScript, you may have to tough it out and rely on the error-detection techniques addressed later in this chapter.
The last aspect of verifying that you're using correct URLs is ensuring that your referer values correctly simulate followed links. You should set the referer to the last target page you requested. This is important for several reasons. For example, some image servers use the referer value to verify that a request for an image is preceded by a request for the entire web page. This defeats bandwidth hijacking, the practice of sourcing images from other people's domains. In addition, websites may defeat deep linking, or linking to a website's inner pages, by examining the referer to verify that people followed a prescribed succession of links to get to a specific point within a website.
Parse tolerance is your webbot's ability to parse web pages when your webbot downloads the correct page, but its contents have changed. The following paragraphs describe how to write parsing routines that are tolerant to minor changes in web pages. This may also be a good time to review Chapter 4, which covers general parsing techniques.
To facilitate fault tolerance when parsing web pages, you should avoid all attempts at position parsing, or parsing information based on its position within a web page. For example, it's a bad idea to assume that the information you're looking for has these characteristics:
Starts x characters from the beginning of the page and is y characters in length
Is in the xth table in a web page
Is at the very top or bottom of a web page
Any small change in a website can effect position parsing. There are much better ways of finding the information you need to parse.
Relative parsing is a technique that involves looking for desired information relative to other things on a web page. For example, since many web pages hold information in tables, you can place all the tables into an array, identifying which table contains a landmark term that identifies the correct table. Once a webbot finds the correct table, the data can be parsed from the correct cell by finding the cell relative to a specific column name within that table. For an example of how this works, look at the parsing techniques performed in Chapter 7 in which a webbot parses prices from an online store.
Table column headings may also be used as landmarks to identify data in tables. For example, assume you have a table like Table 25-1, which presents statistics for three baseball players.
Table 25-1. Use Table Headers to Identify Data Within Columns
Player | Team | Hits | Home Runs | Average |
|---|---|---|---|---|
Zoe | Marsupials | 78 | 15 | .327 |
Cullen | Wombats | 56 | 16 | .331 |
Kade | Wombats | 58 | 17 | .324 |
In this example you could parse all the tables from the web page and isolate the table containing the landmark Player Statistics. In that table, your webbot could then use the column names as secondary landmarks to identify players and their statistics.
You achieve additional fault tolerance when you choose landmarks that are least likely to change. From my experience, the things in web pages that change with the lowest frequency are those that are related to server applications or back-end code. In most cases, names of form elements and values for hidden form fields seldom change. For example, in Listing 25-8 it's very easy to find the names and breeds of dogs because the form handler needs to see them in a well-defined manner. Webbot developers generally don't look for data values in forms because they aren't visible in rendered HTML. However, if you're lucky enough to find the data values you're looking for within a form definition, that's where you should get them, even if they appear in other visible places on the website.
<form method="POST" action="dog_form.php"> <input type="hidden" name="Jackson" value="Jack Russell Terrier"> <input type="hidden" name="Xing" value="Shepherd Mix"> <input type="hidden" name="Buster" value="Maltese"> <input type="hidden" name="Bare-bear" value="Pomeranian"> </form>
Listing 25-8: Finding data values in form variables
Similarly, you should avoid landmarks that are subject to frequent changes, like dynamically generated content, HTML comments (which Macromedia Dreamweaver and other page-generation software programs automatically insert into HTML pages), and information that is time or calendar derived.
Form tolerance defines your webbot's ability to verify that it is sending the correct form information to the correct form handler. When your webbot detects that a form has changed, it is usually best to terminate your webbot, rather than trying to adapt to the changes on the fly. Form emulation is complicated, and it's too easy to make embarrassing mistakes—like submitting nonexistent forms. You should also use the form diagnostic page on the book's website (described in Chapter 5) to analyze forms before writing form emulation scripts.
Before emulating a form, a webbot should verify that the form variables it plans to submit are still in use in the submitted form. This check should verify the data pair names submitted to the form handler and the form's method and action. Listing 25-9 parses this information on a test page on the book's website. You can use similar scripts to isolate individual form elements, which can be compared to the variables in form emulation scripts.
<?
# Import libraries
include("LIB_http.php");
include("LIB_parse.php");
include("LIB_resolve_addresses.php");
# Identify location of form and page base address
$page_base ="http://www.schrenk.com/nostarch/webbots/";
$target = "http://www.schrenk.com/nostarch/webbots/easy_form.php";
$web_page = http_get($target, "");
# Find the forms in the web page
$form_array = parse_array($web_page['FILE'], $open_tag="<form", $close_tag="</form>");
# Parse each form in $form_array
for($xx=0; $xx<count($form_array); $xx++)
{
$form_beginning_tag = return_between($form_array[$xx], "<form", ">", INCL);
$form_action = get_attribute($form_beginning_tag, "action");
// If no action, use this page as action
if(strlen(trim($form_action))==0)
$form_action = $target;
$fully_resolved_form_action = resolve_address($form_action, $page_base);
// Default to GET method if no method specified
if(strtolower(get_attribute($form_beginning_tag, "method")=="post"))
$form_method="POST";
else
$form_method="GET";
$form_element_array = parse_array($form_array[$xx], "<input", ">");
echo "Form Method=$form_method<br>";
echo "Form Action=$fully_resolved_form_action<br>";
# Parse each element in this form
for($yy=0; $yy<count($form_element_array); $yy++)
{
$element_name = get_attribute($form_element_array[$yy], "name");
$element_value = get_attribute($form_element_array[$yy], "value");
echo "Element Name=$element_name, value=$element_value<br>";
}
}
?>
Listing 25-9: Parsing form values
Listing 25-9 finds and parses the values of all forms in a web page. When run, it also finds the form's method and creates a fully resolved URL for the form action, as shown in Figure 25-1.
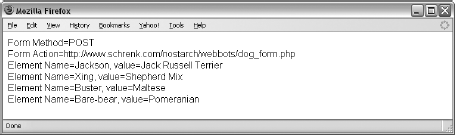
Cookie tolerance involves saving the cookies written by websites and making them available when fetching successive pages from the same website. Cookie management should happen automatically if you are using the LIB_http library and have the COOKIE_FILE pointing to a file your webbots can access.
One area of concern is that the LIB_http library (and PHP/CURL, for that matter) will not delete expired cookies or cookies without an expiration date, which are supposed to expire when the browser is closed. In these cases, it's important to manually delete cookies in order to simulate new browser sessions. If you don't delete expired cookies, it will eventually look like you're using a browser that has been open continuously for months or even years, which can look pretty suspicious.
Unless you plan accordingly, your webbots and spiders will hang, or become nonresponsive, when a targeted website suffers from a network outage or an unusually high volume of network traffic. Webbots become nonresponsive when they request and wait for a page that they never receive. While there's nothing you can do about getting data from nonresponsive target websites, there's also no reason your webbot needs to be hung up when it encounters one. You can avoid this problem by inserting the command shown in Listing 25-10 when configuring your PHP/CURL sessions.
curl_setopt($curl_session, CURLOPT_TIME, $timeout_value);
Listing 25-10: Setting time-out values in PHP/CURL
CURLOPT_TIME defines the number of seconds PHP/CURL waits for a targeted website to respond. This happens automatically if you use the LIB_http library featured in this book. By default, page requests made by LIB_http wait a maximum of 25 seconds for any target website to respond. If there's no response within the allotted time, the PHP/CURL session returns an empty result.
While on the subject of time-outs, it's important to recognize that PHP, by default, will time-out if a script executes longer than 30 seconds. In normal use, PHP's time-out ensures that if a script takes too long to execute, the webserver will return a server error to the browser. The browser, in turn, informs the user that a process has timed-out. The default time-out works great for serving web pages, but when you use PHP to build webbot or spider scripts, PHP must facilitate longer execution times. You can extend (or eliminate) the default PHP script-execution time with the commands shown in Listing 25-11.
You should exercise extreme caution when eliminating PHP's time-out, as shown in the second example in Listing 25-11. If you eliminate the time-out, your script may hang permanently if it encounters a problem.
set_time_limit(60); // Set PHP time-out to 60 seconds set_time_limit(0); // Completely remove PHP script time-out
Listing 25-11: Adjusting the default PHP script time-out
Always try to avoid time-outs by designing webbots that execute quickly, even if that means your webbot needs to run more than once to accomplish a task. For example, if a webbot needs to download and parse 50 web pages, it's usually best to write the bot in such a way that it can process pages one at a time and know where it left off; then you can schedule the webbot to execute every minute or so for an hour. Webbot scripts that execute quickly are easier to test, resemble normal network traffic more closely, and use fewer system resources.