
XQuery and XSLT are both languages designed to query and manipulate XML documents. There is an enormous amount of overlap among the features and capabilities of these two languages. In fact, the line between querying and transformation is somewhat blurred. For example, suppose someone wants a list of all the product names from the catalog, but wants to call them product_name in the results. On the one hand, this could be considered a query: "Retrieve all the name elements from the catalog, but give them the alias product_name." On the other hand, it could be considered a transformation: "Transform all the name elements to product_name elements, and ignore everything else in the document."
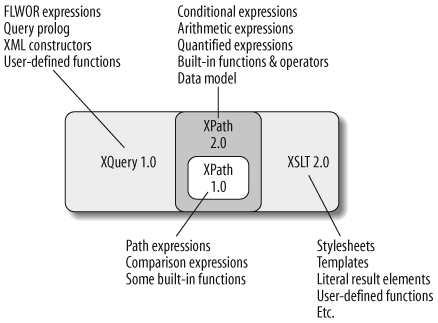
The good news is that if you've learned one of these two languages, you're well on your way toward learning the other. XQuery 1.0 and XSLT 2.0 were developed together, with compatibility between them in mind. Among the components they share are:
- The data model
Both languages use the data model described in Chapter 2. They have the same concepts of sequences, atomic values, nodes, and items. Namespaces are handled identically. In addition, they share the same type system and relationship to XML Schema.
- XPath 2.0
XQuery 1.0 is essentially a superset of XPath 2.0. XSLT 2.0 makes use of XPath 2.0 expressions in many areas, from the expressions used to match templates to the instructions that copy nodes from input documents.
- Built-in functions and operators
All of the built-in functions described in Appendix A can be used in both XQuery and XSLT 2.0, with the same results. All of the operators, such as comparison and arithmetic operators, yield identical values in both languages.
In addition to the components they directly share, XQuery 1.0 and XSLT 2.0 also have some features that are highly analogous in the two languages; they just use a different syntax. XSLT instructions relating to flow control (e.g., xsl:if and xsl:for-each) have direct equivalents in XQuery (conditional and FLWOR expressions). Literal result elements in XSLT are analogous to direct XML constructors in XQuery, while the use of xsl:element and xsl:attribute in XSLT is like using computed constructors in XQuery. Some of these commonly used features are listed in Table 25-1.
Table 25-1. Comparison of XSLT and XQuery features
|
XSLT feature |
Present in 1.0? |
XQuery equivalent |
Chapter |
|---|---|---|---|
|
|
yes |
|
6 |
|
XPath |
no |
|
6 |
|
|
yes |
|
6, 12 |
|
|
yes |
|
7 |
|
|
yes |
Conditional expressions (if-then-else) |
3 |
|
Literal result elements |
yes |
Direct constructors |
5 |
|
|
yes |
Computed constructors |
5 |
|
|
yes |
Computed constructors | |
|
|
no |
User-defined functions |
8 |
|
Named templates |
yes |
User-defined functions |
8 |
|
|
yes |
An enclosed expression in curly braces inside an element constructor |
4 |
|
|
yes |
The path or other expression that would appear in the |
4 |
|
|
no |
The path or other expression that would appear in the |
4 |
|
|
yes |
Module import |
12 |
|
|
yes |
No direct equivalent; can be simulated with user-defined functions |
25 |
The most obvious difference between XQuery and XSLT is the syntax. A simple XQuery query might take the form:
<ul type="square">{
for $product in doc("catalog.xml")/catalog/product[@dept = 'ACC']
order by $product/name
return <li>{data($product/name)}</li>
}</ul>The XSLT equivalent of this query is:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<ul type="square">
<xsl:for-each select="catalog/product[@dept = 'ACC']">
<xsl:sort select="name"/>
<li><xsl:value-of select="name"/></li>
</xsl:for-each>
</ul>
</xsl:template>
</xsl:stylesheet>XQuery is somewhat less verbose, and many people find it less cumbersome than using the XML syntax of XSLT. Users who know SQL find XQuery familiar and intuitive. Its terseness also makes it more convenient to embed in program code than XSLT.
On the other hand, XSLT stylesheets use XML syntax, which means that they can be easily parsed and/or created by standard XML tools. This is convenient for the dynamic generation of stylesheets.
The most significant difference between XQuery and XSLT lies in their ability to react to unpredictable content. To understand this difference, we must digress briefly into the two different paradigms for developing XSLT stylesheets, which are sometimes called pull and push. Pull stylesheets, also known as program-driven stylesheets, tend to be used for highly structured, predictable documents. They use xsl:for-each and xsl:value-of elements to specifically request the information that is desired. An example of a pull stylesheet is shown in Example 25-1.
Example 25-1. A pull stylesheet
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="catalog">
<ul>
<xsl:for-each select="product">
<li>Product #: <xsl:value-of select="number"/></li>
<li>Product name: <xsl:value-of select="name"/></li>
</xsl:for-each>
</ul>
</xsl:template>
</xsl:stylesheet>The stylesheet is counting on the fact that the product elements appear as children of catalog and that each product element has a single name and a single number child. The template states exactly what to do with the descendants of the catalog element, and where they can be found.
By contrast, push stylesheets use multiple templates that specify what to do for each element type, and then pass processing off to other templates using xsl:apply-templates. Which templates are used depends on the type of children of the current node. This is sometimes called a content-driven approach, because the stylesheet is simply reacting to child elements found in the input content by matching them to templates. Example 25-2 shows a push stylesheet that is equivalent to Example 25-1.
Example 25-2. A push stylesheet
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="catalog">
<ul>
<xsl:apply-templates/>
</ul>
</xsl:template>
<xsl:template match="product">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="number">
<li>Product #: <xsl:value-of select="."/></li>
</xsl:template>
<xsl:template match="name">
<li>Product name: <xsl:value-of select="."/></li>
</xsl:template>
<xsl:template match="node( )"/>
</xsl:stylesheet>This may not seem like a particularly useful approach for a predictable document like the product catalog. However, consider a narrative document structure, such as an HTML paragraph. The p (paragraph) element has mixed content and may contain various inline elements such as b (bold) and i (italic) to style the text in the paragraph, as in:
<p>It was a <b>dark</b> and <i>stormy</i> night.</p>
This input is less predictable because there is no predefined number or order of the b or i children in any given paragraph. A push stylesheet on this paragraph is shown in Example 25-3.
Example 25-3. A push stylesheet on narrative content
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="p">
<para>
<xsl:apply-templates/>
</para>
</xsl:template>
<xsl:template match="b">
<Strong><xsl:apply-templates/></Strong>
</xsl:template>
<xsl:template match="i">
<Italics><xsl:apply-templates/></Italics>
</xsl:template>
</xsl:stylesheet>It would be difficult to write a good pull stylesheet on the narrative paragraph. Example 25-4 shows an attempt.
Example 25-4. An attempt at a pull stylesheet on narrative content
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="p">
<para>
<xsl:for-each select="node( )">
<xsl:choose>
<xsl:when test="self::text( )">
<xsl:value-of select="."/>
</xsl:when>
<xsl:when test="self::b">
<Strong><xsl:value-of select="."/></Strong>
</xsl:when>
<xsl:when test="self::i">
<Italics><xsl:value-of select="."/></Italics>
</xsl:when>
</xsl:choose>
</xsl:for-each>
</para>
</xsl:template>
</xsl:stylesheet>However, this stylesheet is not very robust, because it does not handle the case where a b element is embedded within an i element. It is cumbersome to maintain because the code would have to be repeated if b and i can also appear in some other parent element besides p. If a change is made, or a new type of inline element is added, it has to be changed in multiple places.
The distinction between push and pull XSLT stylesheets is relevant to the comparison with XQuery. XQuery can easily handle the scenarios supported by pull stylesheets. The equivalent of Example 25-1 in XQuery is:
for $catalog in doc("catalog.xml")/catalog
return <ul>{for $prod in $catalog/product
return (<li>Product #: {data($prod/number)}</li>,
<li>Product name: {data($prod/name)}</li> )
}</ul>XQuery has a much harder time emulating the push stylesheet model, due to its lack of templates. In order to write a query that modifies the HTML paragraph, you could use a brittle pull model analogous to the one shown in Example 25-4. Alternatively, you could emulate templates using user-defined functions, as shown in Example 25-5. This is somewhat better in that it supports b elements within i elements and vice versa, and it specifies in one place what to do with each element type. However, it is still more cumbersome than its XSLT equivalent and does not support features of XSLT like modes, priorities, or imports that override templates.
Example 25-5. Emulating templates with user-defined functions
declare function local:apply-templates($nodes as node()*) as node( )* {
for $node in $nodes
return typeswitch ($node)
case element(p) return local:p-template($node)
case element(b) return local:b-template($node)
case element(i) return local:i-template($node)
case element() return local:apply-templates($node/(@*|node( )))
default return $node
};
declare function local:p-template($node as node()) as node( )* {
<para>{local:apply-templates($node/(@*|node( )))}</para>
};
declare function local:b-template($node as node()) as node( )* {
<Strong>{local:apply-templates($node/(@*|node( )))}</Strong>
};
declare function local:i-template($node as node()) as node( )* {
<Italics>{local:apply-templates($node/(@*|node( )))}</Italics>
};
local:apply-templates(doc("p.xml")/p)It is very important to note that this does not mean that XQuery is not good for querying narrative content. On the contrary, XQuery is an easy and fast method of searching within large bodies of narrative content. However, it is not ideal for taking that retrieved narrative content and significantly transforming or restructuring it. If this is your objective, you may want to consider pipelining two processes together: an XQuery query to retrieve the appropriate content from the database, and an XSLT stylesheet to transform it for presentation or other uses.
Implementations of XSLT and XQuery tend to be optimized for particular use cases. XSLT implementations are generally built for transforming one whole document. They load the entire input document into memory and take one or more complete passes through the document. This is appropriate behavior when an entire document is being transformed, since the entire document needs to be accessed anyway. Additional input documents can be accessed using the doc or document functions, in which case they too are loaded into memory.
XQuery implementations, on the other hand, are generally optimized for selecting fragments of data—possibly across many documents—for example, from a database. When content is loaded into the database, it is broken into chunks that are usually smaller than the entire documents. Those chunks are indexed so that they can be retrieved quickly. XQuery queries can access these chunks without being forced to load the entire documents that contain them. This makes selecting a subset of information from a large body of XML documents much faster using the average XQuery implementation.
XSLT 2.0 has several convenient features that are absent from XQuery. They include:
-
xsl:analyze-string This instruction breaks a string into parts that match and do not match a regular expression and allows manipulation of them.
-
xsl:result-document This instruction allows the creation of multiple output files directly in a stylesheet.
-
xsl:for-each-group This instruction allows grouping by position in addition to grouping by value.
-
xsl:import This instruction allows you to override templates and functions in an imported stylesheet.
The xsl:import instruction of XSLT gives you some of the capabilities of inheritance and polymorphism from object languages, which is particularly useful when writing large application suites designed to handle a variety of related and overlapping tasks. This is quite hard to organize in XQuery, which has neither the polymorphism of object-oriented languages nor the function pointers of a language like C. The modules of XQuery also have significant limitations when writing large applications, such as the rule banning cyclic imports.