
A simple example of a processing model for XQuery is shown in Figure 2-1. This section describes the various components of this model.
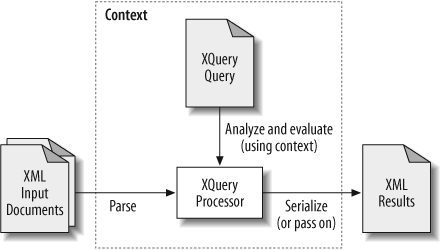
Throughout this book, the term input document is used to refer to the XML data that is being queried. The data that is being queried can, in fact, take a number of different forms, for example:
Text files that are XML documents
Fragments of XML documents that are retrieved from the Web using a URI
A collection of XML documents that are associated with a particular URI
Data stored in native XML databases
Data stored in relational databases that have an XML frontend
In-memory XML documents
Some queries
use a hardcoded link to the location of the input document(s), using the doc or collection function in the query. Other queries operate on a set of input data that is set by the processor at the time the query is evaluated.
Whether it is physically stored as an XML document or not, an input document must conform to other constraints on XML documents. For example, an element may not have two attributes with the same name, and element and attribute names may not contain special characters other than dashes, underscores, and periods.
An XQuery query could be contained in a text file, embedded in program code or in a query library, generated dynamically by program code, or input by the user on a command line or in a dialog box. Queries can also be composed from multiple files, known as modules.
A query is made up of two parts: a prolog and a body. The query prolog is an optional section that appears at the beginning of a query. Despite its name, the prolog is often much larger than the body. The prolog can contain various declarations, separated by semicolons, that affect settings used in evaluating the query. This includes namespace declarations, imports of schemas, variable declarations, function declarations, and others. These declarations are discussed in relevant sections throughout the book and summarized in Chapter 12.
The query body is a single expression, but that expression can consist of a sequence of one or more expressions that are separated by commas. Example 2-1 shows a query with a prolog (the first three lines), and a body (the last two lines) that contains two element constructor expressions separated by a comma.
Example 2-1. A query with prolog and body
declare boundary-space preserve;
declare namespace prod = "http://datypic.com/prod";
declare variable $catalog := doc("catalog.xml")//catalog;
<firstResult>{count($catalog/product)}</firstResult>,
<prod:secondResult>{$catalog/product/number}</prod:secondResult>The result of this query will be a firstResult element followed by a prod:secondResult element. If the comma after firstResult were not there, it would be a syntax error because there would be two separate expressions in the query body.
A query is not evaluated in a vacuum. The query context consists of a collection of information that affects the evaluation of the query. Some of these values can be set by the processor outside the scope of the query, while others are set in the query prolog. The context includes such values as:
The query processor is the software that parses, analyzes, and evaluates the query. The analysis and evaluation phases are roughly equivalent to compiling and executing program code. The analysis phase finds syntax errors and other static errors that do not depend on the input data. The evaluation phase actually evaluates the results of the query based on input documents, possibly raising dynamic errors for situations like missing input documents or division by zero. Either phase may raise type errors, which result when a value is encountered that has a different type than expected. All errors in XQuery all have eight-character names, such as XPST0001, and they are described in detail in Appendix C.
There are a number of implementations of XQuery. Some are open source, while others are available commercially from major vendors. Many are listed at the official XQuery web site at http://www.w3.org/XML/Query. This book does not delve into all the details of individual XQuery implementations but points out features that are implementation-defined or implementation-dependent, meaning that they may vary by implementation.
The query processor returns a sequence of values as the results. Depending on the implementation, these results can then be written to a physical XML file, sent to a user interface, or passed to another application for further processing.
Writing the results to a physical XML document is known as serialization. There may be some variations in the way different implementations serialize the results of the query. These variations have to do with whitespace, the encoding used, and the ordering of the attributes. The implementation you use may allow you to have some control over these choices.