
This chapter explains how to sort and group data from input documents. It covers sorting in FLWORs, grouping results together, and calculating summary values using the aggregation functions.
Path expressions, which are most often used to select elements and attributes from input documents, always return items in document order. FLWORs by default return results based on the order of the sequence specified in the for clause, which is also often document order if a path expression was used.
The only way to sort data in an order other than document order is by using the order by clause of the FLWOR. Therefore, in some cases it is necessary to use a FLWOR where it would not otherwise be necessary. For example, if you simply want to select all of your items from an order, you can use the path expression doc("order.xml")//item. However, if you want to sort those items based on their num attribute, you have to use a FLWOR.
Example 7-1 shows an order by clause in a FLWOR.
The results will be sorted by item number. The syntax of an order by clause is shown in Figure 7-1.
The order by clause is made up of one or more ordering specifications, separated by commas, each of which consists of an expression and an optional modifier. The expression can only return one value for each item being sorted. In Example 7-1, there is only one num attribute of $item. If instead, you had specified order by $item/@*, which selects all attributes of item, a type error would have been raised because more than one value is returned by that expression.
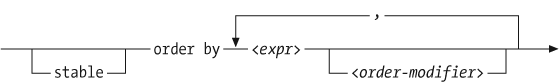
Unlike SQL, XQuery allows you to order by a value that is not returned by the expression. For example, you can order by $item/@dept and only return $item/@num in the results.
In order to sort on more than one expression, you can include multiple ordering specifications, as shown in Example 7-2.
Example 7-2. Using multiple ordering specifications
for $item in doc("order.xml")//item
order by $item/@dept, $item/@num
return $itemThis sorts the results first by department, then by item number. An unlimited number of ordering specifications can be included.
When sorting values, the processor considers their type. All the values returned by a single ordering specification expression must have comparable types. For example, they could be all xs:integer or all xs:string. They could also be a mix of xs:integer and xs:decimal, since values of these two types can be compared.
However, if integer values are mixed with string values, a type error is raised. It is acceptable, of course, for different ordering specifications to sort on values of different types; in Example 7-2, item numbers could be integers while departments are strings.
Untyped values are treated like strings. If your values are untyped but you want them to be treated as numeric for sorting purposes, you can use the number function, as in:
order by number($item/@num)
This allows the untyped value 10 to come after the untyped value 9. If they were treated as strings, the value 10 would come before 9.
Several order modifiers can optionally be specified for each ordering specification.
ascendinganddescendingspecify the sort direction. The default isascending.empty greatestandempty leastspecify how to sort the empty sequence.collation, followed by a collation URI in quotes, specifies a collation used to determine the sort order of strings. Collations are described in detail in Chapter 17.
The syntax of an order modifier is shown in Figure 7-2.

Order modifiers apply to only one order specification. For example, if you specify:
order by $item/@dept, $item/@num descending
the descending modifier applies only to $item/@num, not to $item/@dept. If you want both to be sorted in descending order, you have to specify:
order by $item/@dept descending, $item/@num descending
The order modifiers empty greatest and empty least indicate whether the empty sequence and NaN should be considered a low value or a high value. If empty greatest is specified, the empty sequence is greater than NaN, and NaN is greater than all other values. If empty least is specified, the opposite is true; the empty sequence is less than NaN, and NaN is less than all other values. Note that this applies to the empty sequence and NaN only, not to zero-length strings.
You can also specify the default behavior for all order by clauses in the query prolog, using an empty order declaration, whose syntax is shown in Figure 7-3.

Example 7-3 shows a query that uses an empty order declaration and sorts the results by the color attributes. Because the greatest option is chosen, the items with no color attribute appear last in the results.
Example 7-3. Using an empty order declaration
Query declare default order empty greatest; for $item in doc("order.xml")//item order by $item/@color return $item Results <item dept="WMN" num="557" quantity="1" color="black"/> <item dept="MEN" num="784" quantity="1" color="gray"/> <item dept="WMN" num="557" quantity="1" color="navy"/> <item dept="MEN" num="784" quantity="1" color="white"/> <item dept="ACC" num="563" quantity="1"/> <item dept="ACC" num="443" quantity="2"/>
The setting in the empty order declaration applies unless it is overridden by an order modifier in an individual ordering specification. The empty order declaration in the prolog applies only when an order by clause is present; otherwise, the results are not sorted. If no empty order declaration is present, the default order for empty sequences is implementation-defined.
When you sort on $item/@num, several values may be returned that have the same sort value. If stable ordering
is not in use, the implementation is free to return those values that have equal sort values in any order. If you want those with equal sort values to be sorted in the order of the input sequence, or if you simply want to ensure that every implementation returns the values in the same order for the query, you can use the stable keyword before the keywords order by. For example, if you specify:
stable order by $item/@num
the items with the same num value are always returned in the order returned by the for expression, within the sorted results.
So far, the order specifications have been simple path expressions. You can sort based on almost any expression, as long as it only returns a single item. For example, you could sort on the result of a function call, such as:
order by substring($item/@dept, 2, 2)
which sorts on a substring of the department, or you could sort on a conditional expression, as in:
order by (if ($item/@color) then $item/@color else "unknown")
which sorts on the color if it exists or the string unknown if it does not. In addition, you could use a path expression that refers to a completely different XML document, as in:
order by doc("catalog.xml")//product[number = $item/@num]/namewhich orders the results based on a name it looks up in the catalog.xml document.
A common requirement is to parameterize the sort key—that is, to decide at runtime what sort key to use. In some cases you can use:
order by $item/@*[name( )=$param]
In other cases you may need to use an extension function, as described in "Dynamic Paths" in Chapter 4.
Every XML document (or document fragment) has an order, known as document order, which defines the sequence of nodes. Document order is significant because certain expressions return nodes in document order. Additionally, document order is used when determining whether one node precedes another. Note that, unlike in XPath 1.0, items in sequences are not always arranged in document order; it depends on how the sequence was constructed.
The document order of a set of nodes is:
The document node itself
Each element node in order of the appearance of its first tag, followed by:
Its attribute nodes, in an implementation-dependent order
Its children (text nodes, child elements, comments, and processing instructions) in the order they appear
Sorting a sequence of nodes in document order will remove any duplicate nodes.
If a sequence containing nodes from more than one document is sorted in document order, it is arbitrary (implementation-dependent) which document comes first, but all of the nodes from one document come before all of the nodes from the other document. For nodes that are not part of a document, such as those that are constructed in your query, the order is implementation-dependent, but stable.
There is no such thing as a document order on atomic values.
Certain kinds of expressions, including path expressions and operators that combine sequences (|, union, intersect, and except), return nodes in document order automatically. For example, the path expression:
doc("catalog.xml")//product/(number | name)retrieves the number and name children of product, in document order. If you want all the number children to appear before all the name children, you need to use a sequence constructor, as in:
(doc("catalog.xml")//product/number, doc("catalog.xml")//product/name)which uses parentheses and a comma. This sequence constructor maintains the order of the items, putting all the results of the first expression first in the sequence, and all the results of the second expression next.
If you have a sequence of nodes that are not in document order, but you want them to be, you can simply use the expression:
$mySequence/.
where $mySequence is a sequence of nodes. The / operator means that it is a path expression, which always returns nodes in document order.
If you have used an order by clause to sort the results of a FLWOR, you should use caution when using the resulting sequence in another expression, since the results may be resorted to document order. The example shown in Example 7-4 first sorts the products in order by product number, then returns their names in li elements.
Example 7-4. Inadvertent resorting in document order
let $sortedProds := for $prod in doc("catalog.xml")//product
order by $prod/number
return $prod
for $prodName in $sortedProds/name
return <li>{string($prodName)}</li>However, this query returns the products in document order, not product number order. This is because the expression $sortedProds/name resorts the nodes back to document order. In this case, the expression can easily be rewritten as shown in Example 7-5. In more complex queries, the error might be more subtle.
Two nodes can be compared based on their relative position in document order using the << and >> operators. For example, $n1 << $n2 returns true if $n1 precedes $n2 in document order. According to the definition of document order, a parent precedes its children.
Each of the operands of the << and >> operators must be a single node, or the empty sequence. If one of the operators is the empty sequence, the result of the comparison is the empty sequence.
Example 7-6 shows a FLWOR that makes use of an order comparison in its where clause. For each product, it checks whether there are any other products later in the document that are in the same department. If so, it returns the product element. Specifically, it binds the $prods variable to a sequence of all four product elements. In the where clause, it uses predicates to choose from the $prods sequence those that are in the same department as the current $prod, and then gets the last of those. If the current $prod precedes that last product in the department, the expression evaluates to true, and the product is selected.
In the case of catalog.xml, only the second product element is returned because it appears before another product in the same department (ACC).
The reverse function reverses the order of items in a sequence. For example:
reverse(doc("catalog.xml")//product)returns the product elements in reverse document order. The function is not just for reversing document order; it can reverse any sequence. For example:
reverse((6, 2, 3))
returns the sequence (3, 2, 6).
As described in the previous section, several kinds of expressions return results in document order. In cases where the order of the results does not matter, the processor may be much more efficient if it does not have to keep track of order. This is especially true for FLWORs that perform joins. For example, processing multiple variable bindings in a for clause might be significantly faster if the processor can decide which variable binding controls the join without regard to the order of the results.
To make a query more efficient, there are three ways for a query author to indicate that order is not significant: the unordered function, the unordered expression, and the ordering mode declaration.
A query author can tell the processor that order does not matter for an individual expression by enclosing it in a call to the unordered function, as shown in Example 7-7. The unordered function takes as an argument any sequence of items, and returns those same items in an undetermined order. Rather than being a function that performs some operation on its argument, it is more a signal to the processor to evaluate the expression without regard to order.
An unordered expression is similar to a call to the unordered function, except that it affects not just the main expression passed as an argument, but also every embedded expression. The syntax of an unordered expression is similar, but it uses curly braces instead of the parentheses, as shown in Example 7-8.
Example 7-8. An unordered expression
unordered {
for $item in doc("order.xml")//item,
$product in doc("catalog.xml")//product
where $item/@num = $product/number
return <item number="{$item/@num}"
name="{$product/name}"
quantity="{$item/@quantity}"/>
}Similarly, an ordered expression will allow you to specify that order matters in a certain section of your query. This is generally unnecessary except to override an ordering mode declaration as described in the next section.
You can specify whether order is significant for an entire query in the query prolog, using an ordering mode declaration, whose syntax is shown in Figure 7-4.

For example, the prolog declaration:
declare ordering unordered;
allows the processor to disregard order for the scope of the entire query, unless it is overridden by an ordered expression or an order by clause. If no ordering mode declaration is present, the default is ordered.