
Advanced Technology Labs
Adobe Systems
801 N 34th St, Seattle, WA 98103, USA
CONTENTS
9.2 Graph Construction for Image Matting
9.2.1 Defining Edge Weight wij
9.3 Solving Image Matting Graphs
9.5.2 Graph-Based Trimap Generation
9.5.3 Matting with Temporal Coherence
Matting refers to the problem of accurately separating a foreground object from the background by determining both full and partial pixel coverage, in both still images and video sequences. Mathematically, the color vector cp of a pixel p in the input image is modeled as a convex combination of a foreground color fp and a background color bp:
(9.1) |
where αp ∈ [0, 1] is the alpha value of the pixel. The collection of alpha values of all pixels in the image is called the alpha matte. This equation, first introduced by Porter and Duff in 1984 [1], is called the Compositing Equation. In the matting problem, usually only the observed color cp is known, and the goal is to accurately recover the alpha value αp and the underlying foreground color fp1, so that the foreground object can be fully separated from the background. Once estimated, the alpha matte can be used as an operational mask in numerous image and video editing applications, such as applying special digital filters to the foreground object, or replacing the original background image with a new one to create a novel composite. Figure 9.1 shows an example of using matting techniques to extract the foreground object and compose it onto a new background image.

FIGURE 9.1
An image matting example: (a) original image, (b) user specified trimap, where white means foreground, black means background, and gray means unknown, (c) extracted alpha matte, white means higher alpha value, (d) a close-up view of the highlighted region on the alpha matte, (e) a new background image, (f) a new composite.
Matting can be viewed as an extension to the classic binary segmentation problem, where each pixel is assigned fully to either the foreground or the background, i.e., αp ∈ {0, 1}. In natural images, although the majority of pixels are usually either definite foreground or definite background, accurately estimating fractional alpha values for pixels on the foreground edge is essential for extracting fuzzy object boundaries such as hair or fur, as shown in the example in Figure 9.1.
Matting is inherently an under-constrained problem. Assuming the input image has three color channels, seven unknown variables (three for fp, three for bp, and one for αp) need to be estimated from three color channel values of cp. Without any additional constraint, the problem is ill-posed and many possible solutions exist. For instance, a simple solution satisfying the Compositing Equation is to set fp = bp = cp, and choose αp arbitrarily. This is obviously not the correct solution for separating the foreground. In order to estimate an alpha matte that represents the correct foreground coverage, most matting approaches rely on both user guidance and prior knowledge on natural image statistics to constrain the solution space. A typical user constraint provided to a matting system is a trimap, where each pixel in the image is assigned to three possible values: definite foreground ℱ (αp = 1), definite background ℬ (αp = 0), and unknown U (αp to be determined). Figure 9.1b shows an example of a user-specified trimap. Given the input trimap, the task of matting is thus reduced to estimating alpha values for unknown pixels, under the constraint of the known pixels in ℱ and ℬ.

FIGURE 9.2
Image matting with different trimaps: (a) input image, (b) a tight trimap, (c) a coarse trimap, (d) matte generated using the tight trimap, (e) a close-up view of the highlighted region in (d), (f) matte generated using the coarse trimap, (g) a close-up view of the highlighted region in (f). Both mattes are generated using the Robust matting algorithm [2].
The accuracy of the input trimap has a direct impact on the quality of the final alpha matte. In general, an accurately specified trimap, where the unknown region covers only truly semitransparent pixels, often leads to a more accurate alpha matte than a loosely defined trimap, due to the reduced number of unknown variables. An example is shown in Figure 9.2, where the same matting algorithm is applied to the same input image with two different trimaps. The trimap in Figure 9.2b is more accurate than the one shown in Figure 9.2c. Therefore, it leads to a more accurate alpha matte, as shown in Figure 9.2d to Figure 9.2g.
Given that manually specifying an accurate trimap is still a tedious process, fast image segmentation approaches have been adopted in matting systems for efficient trimap generation. The Grabcut system [3] can generate a fairly accurate binary segmentation of the foreground object starting from a user-specified bounding box, using iterated graph cuts optimization. Under a similar optimization framework, the Lazy Snapping system [4] generates a binary segmentation from a few foreground and background scribbles. Once the binary segmentation is obtained, one can simply erode and dilate the foreground contour to create an unknown region for matting. Rhemann et al. [5] proposed a more accurate trimap segmentation tool, which explicitly segments the image into three regions ℱ, ℬ, and U, using a parametric max-flow algorithm. With the help of these techniques, accurate trimaps can be efficiently generated with a small amount of user interaction.
In this chapter, for image matting, we assume the trimap is already given, and focus on how to estimate fractional alpha values in the U region. For video matting, we will describe how to generate temporally consistent trimaps for video frames, as it is the main bottleneck for applying matting techniques in video.
Earlier matting approaches try to estimate alpha values for individual pixels independently without any spatial regularization. A common strategy is that for an unknown pixel p, sampling a set of known foreground and background colors nearby as priors for fp and bp. Assuming the image colors vary smoothly, these samples can be treated as reasonably accurate estimates of fp and bp. Once fp and bp are estimated, solving αp from the composting equation becomes trivial.
Various statistical models have been used to estimate fp and bp from color samples. Ruzon and Tomasi developed a parametric sampling algorithm [6], where foreground and background color samples are modeled as mixture of Gaussians, and the observed color cp is modeled as coming from an intermediate distribution between the foreground and background Gaussian distributions. Mishima [7] developed a blue screen matting system which uses color samples in a nonparametric way. Detailed explanations of these methods can be found in Wang and Cohen’s survey [8].
A notable method among early approaches is the Bayesian matting [9] approach, which formulates the estimation of fp, bp, and αp in a Bayesian framework, and solves the matte using the maximum a posteriori (MAP) technique. It is the first to cast the matting problem into a well-formulated statistical inference framework. Mathematically, for an unknown pixel p, its matting solution is formulated as:
arg maxfp,bp,αp P(fp,bp,αp | cp) = arg maxfp,bp,αp L(cp | fp, bp, αp) + L(fp) + L(bp) + L(αp), |
(9.2) |
where L(·) is the log likelihood L(·) = logP(·). The first term on the right side is measured as:
(9.3) |
where the color variance σp is measured locally. This is simply the fitting error according to the compositing equation. To estimate L(fp), foreground colors in the nearby region are first partitioned into groups, and in each group an oriented Gaussian is estimated by computing the mean ˉf and covariance ΣF. L(fp) is then defined as:
(9.4) |
L(bp) is calculated in the same way using background samples. L(αp) is treated as a constant. The solution of the inference problem is obtained by iteratively estimating (fp, bp) and αp.
Despite their success in simple cases, matting approaches that only depend on color sampling often fail on more complicated images where foreground and background color distributions are overlapping, and the input trimap is loosely defined. This is due to two fundamental limitations of this framework. First, estimating alpha values independently for individual pixels without any spatial regularization is prone to image noise. Second, when the trimap is loosely defined, the sampled foreground and background colors are no longer good priors for estimating fp and bp, leading to estimation bias. Modern matting approaches try to avoid these limitations by enforcing local spatial regularization on the estimated alpha matte, which allows them to perform more robustly on difficult examples. We will focus on these methods from now on.
9.2 Graph Construction for Image Matting
Modern image matting approaches usually start by modeling the input image as an undirected and weighted graph G = (V, ℰ), where each υi ∈ V corresponds to an unknown pixel, i.e., a pixel in the U region of the input trimap2. An edge ei ∈ ℰ is usually defined between a node and its four spatial neighbors, although in some work the edges are defined among pixels in larger spatial neighborhoods such as 3 × 3 or 5 × 5 [10]. Additionally, some approaches define a node weight wi for each node υi, which encodes some prior knowledge of the alpha value of υi, given its observed color ci and nearby foreground and background colors. The structure of such a graph is shown in Figure 9.3. Using this graph representation, matting is transferred into a graph labeling problem, where the objective is to solve for the optimal αis that can minimize the total energy of the graph.
Although many image matting approaches share the same common graph structure, the key difference among them is the formulation of the edge weight wij, and optionally the node weight wi. Table 9.1 summaries some representative image matting techniques that will be discussed in this section, and their choices of the edge and the node weights. Specifically, different edge weights will be discussed in detail in Section 9.2.1, and various node weights will be illustrated in Section 9.2.2. Finally, how to solve the graph labeling problem using the define edge and node weights will be described in Section 9.3.
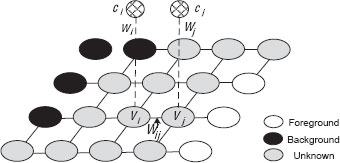
FIGURE 9.3
A typical graph setup for image matting.
Method |
Reference |
Edge weight |
Node weight |
Optimization method |
Random walk matting |
[11] |
wlppij (Eqn.9.7) |
No |
Linear system |
Easy matting |
[12] |
weasyij (Eqn.9.8) |
weasyi (Eqn.9.21) |
Linear system |
Iterative BP matting |
[13] |
wbpij (Eqn.9.9) |
wbpi (Eqn.9.22) |
Belief propagation |
Closed-form matting |
[10] |
wcfij (Eqn.9.13) |
No |
Linear system |
Robust matting |
[2] |
wcfij (Eqn.9.13) |
wrmi (Eqn.9.27) |
Linear system |
Learning-based matting |
[14] |
wlnij (Eqn.9.20) |
No |
Linear system |
Global sampling matting |
[15] |
wcfij (Eqn.9.13) |
wgsi (Eqn.9.32) |
Linear system |
TABLE 9.1
Summary of image matting techniques and their graph structures.
9.2.1 Defining Edge Weight wij
One straightforward idea of mapping pixel colors to the edge weight eij is to use the following classic Euclidean norm:
(9.5) |
where ci is the RGB color of υi, σij is a parameter which can be either manually selected by the user, or automatically computed based on local image statistics [16]. This function penalizes large alpha changes in flat image regions where the color difference between two neighboring pixels is small. This metric has been widely used in graph-based binary image segmentation systems [17]. Grady et al. [11] adopted this formulation for image matting, but instead of measuring the Euclidean norm in the RGB color space, they proposed to use the Locality Preserving Projections (LPP) technique [18] to define a conjugate norm, which is more reliable for describing perceptual object boundaries than the RGB color space. Mathematically, the projections defined by the LPP algorithm are given by solving the following generalized eigen-vector problem:
(9.6) |
where Z is a 3 × N (the number of pixels in the image) matrix with each ci color vector as a column, D is the diagonal matrix defined as Dii = di ˙= ∑wij, and L is the sparse Laplacian matrix where Lii = di, and Lij = −wij for j ≠ i. Denote its solution by Q where each eigenvector is a row, the final edge weight is computed as:
(9.7) |
The edge weights defined above are static given an input image, and they are not related to the values of the random variables αi and αj. In some other approaches, the edge weight is explicitly defined as a function of αi and αj to enforce the alpha matte to be locally smooth. The Easy matting system [12] defines the edge weight in a quadratic form as:
(9.8) |
where λ is a user defined constant. Minimizing the sum of edge weights over the graph will force the alpha values of adjacent pixels to be similar if local image gradient is small. Under the same motivation, Wang and Cohen [13] constructed a Markov Random Field (MRF) where the joint distribution over αi and αj is given by the Boltzmann distribution of a similar quadratic energy function as:
(9.9) |
All the edge weights defined above implicitly assume that the input image is locally smooth. In the closed-form matting algorithm [10], the local smoothness is explicitly modeled using a color line model. That is, in a small local window ϒ (3 × 3 or 5 × 5), the foreground and background colors (fis and bis) are linear mixtures of two latent colors:
fi = βfi fl1 + (1 − βfi) fl2andbi = βbi bl1 + (1 − βbi) bl2, ∀i ∈ ϒ, |
(9.10) |
where fl1, fl2, bl1, and bl2 are latent colors. Combining this constraint with the Compositing Equation, it is easy to show that alpha values in ϒ can be expressed as:
(9.11) |
where k refers to color channels, and ak and b are functions of βfi, βbi, fl1, fl2, bl1 and bl2, thus they are constants in the window. Based on this constraint, Levin et al. [10] defined a quadratic matting cost function as:
J(α, a, b) = ∑j ∈ I(∑i ∈ ϒj(αi − ∑kakjcki − bj)2 + ϵ ∑kak2j), |
(9.12) |
where the second term is a regularization term mainly for the purpose ot numerical stability. It also has a desirable side effect of biasing the solution toward smoother alpha mattes, since aj = 0 means that α is constant over the jth window. Given this cost function, the edge weight can be derived as:
wcfij = 1|ϒk| ∑k | (i, j) ∈ ϒk(1 + (ci − μk)T (∑k + ε|ϒk| I3)−1 (cj − μk)), |
(9.13) |
where Σk is a 3 × 3 covariance matrix, μk is a 3 × 1 mean vector of the colors in the window ϒk, and I3 is the 3 × 3 identity matrix. Consequently, a graph Laplacian matrix can be computed as:
Lcfij = {−wcfij:if i ≠ j, (i,j) ∈ ϒk,∑l, l ≠ iwcfil:if i = j,0:otherwise. |
(9.14) |
which is called the matting Laplacian. It is easy to show that the Laplacian matrix Lcf is symmetric and positive semidefinite.
There are several unique characteristics of the edge weight wcfij. First, each pixel has a nonzero weight with all other pixels in a local (5 × 5 if ϒ is 3 × 3) neighborhood, thus the Laplacian matrix is a much denser one than that of a typical four-neighbor image graph. In each row of the Laplacian matrix Lcf, there are 25 nonzero elements, compared with 5 in a four-neighbor graph Laplacian. Second, the edge weight wcfij can be negative, which is different from the strictly nonnegative edge weights defined in Equation 9.5 to 9.9. It is thus worth emphasizing that some of the commonly used nonnegative graph analysis methods do not apply to Lcf. For instance, in a nonnegative graph, the degree of a vertex υi is di = Σ wij for all edges eij incident on υi, and is often used for normalizing all nonzero values in the ith row of the graph Laplacian [17]. For the matting Laplacian Lcf, computing the degree of a vertex and using it for normalization is no longer suitable, as positive and negative values cancel out each other. Another side effect of using negative edge weights is that the computed alpha values are no longer guaranteed to be within [0, 1], as discussed in [19]. Using this method it is quite often to get alpha values that are out of bounds, thus in practice one has to clip the alpha values at 0 and 1 to generate visually correct alpha mattes.
Since the matting Laplacian Lcf is strictly derived from the color line model, it otten leads to accurate alpha mattes when the underlying color model is satisfied. In practice, if the input image is composed of smooth regions without strong textures, the color line model often holds true. Given its generality and accuracy, it has been widely used in recent matting approaches where it is combined with other techniques to achieve high-quality results. It has also been applied in many other applications such as image dehazing [20] and light source separation [21] as a general edge-aware interpolation tool.
The limitations of the matting Laplacian Lcf have also been extensively studied. Singaraju et al. [22] demonstrated that the color line model provides an overfit and leads to ambiguity when the intensity variations of the foreground and background layers are much simpler than the color line. Specifically, they studied two compact color models, point-point color model and line-point color model. The former applies when both the foreground and background intensities are locally constant (the point constraint), and the latter applies when one layer satisfies the point constraint while the other satisfies the color line constraint. These two color models lead to modified edge weights which work better than the original matting Laplacian in these special cases.
To deal with more complicated cases where a linear color model is incapable of accurately describing the color variations, Zheng et al. [14] proposed a semisupervised learning approach, where the well-known kernel trick [23] is used to deal with nonlinear local color distributions. This approach assumes that the alpha value of an unknown pixel υi is a linear combination of the alpha values of its neighboring pixels, e.g., a 7 × 7 window centered at the pixel:
(9.15) |
where α is the alpha value vector of all pixels in the image, and ξi is a coefficient vector where the majority values are 0 except for pixels which are in the neighborhood of υi. By introducing a new matrix G through stacking ξis: G = [ξ1, …, ξn], the above equation can be rewritten as:
(9.16) |
This leads to a solution of α by minimizing the following quadratic cost function:
(9.17) |
which can be reformulated as:
(9.18) |
The Laplacian matrix of this approach is then defined as:
(9.19) |
and the corresponding edge weight is
(9.20) |
The matrix G is obtained by training a non-linear alpha-color model from known pixels in the trimap, either locally or globally, as detailed in the original paper [14].
For each υi, the node weight wi measures how compatible an estimated αi is with its observed color ci, and nearby foreground and background colors. Not all matting approaches define and use this term, but it has been shown [2] that the node weight, if defined properly, can lead to more accurate alpha estimation.
A common approach for defining wi is to first sample a set of nearby known foreground and background colors, denoted as cfk and cbl, 0 < k, l < N, as shown in Figure 9.4. Assuming the foreground and background colors vary smoothly, these color samples assemble reasonable probabilistic distributions of fi and bi. Combined with ci, these samples can be used to test the feasibility of an estimated αi using the compositing equation. Using this idea, Guan et al. [12] defined the node weight in the Easy Matting system as:
weasyi = 1N2 N∑k = 1N∑l = 1‖ci − αi cfk − (1 − αi) cbl‖2 / σ2i, |
(9.21) |
where σi is the distance variance among ci and αi cfk + (1 − αi) cbl. This node weight favors an αi that can best explain the observed color ci as a linear combination of the sampled colors cfk and cbl. Similarly, Wang and Cohen [13] defined a node weight using exponential functions as:
wbpi = 1N2 N∑k = 1N∑l = 1μfk μbl ⋅ exp (−‖ci − αicfk − (1 − αi) cbl‖2 / σ2i), |
(9.22) |
where μfk and μbl are additional weights for color samples based on their spatial distances to υi.
The node weights defined in Equation 9.21 and 9.22 treat every color sample equally. In practice, however, when the size of the sample set is large and the foreground and background color distributions are complex, the samples set may present a large color variance. It is often the case that only a small number of samples are good for estimating αi. To decide which samples are good for defining wi, Wang and Cohen [2] proposed a color sample selection method. In this approach, “good” sample pairs are defined as those that can explain ci as a convex combination of themselves. Mathematically, as illustrated in Figure 9.4, for a pair of foreground and background colors (cfk, cbl), a distance ratio is defined as:
(9.23) |
where ˆαi is the alpha value estimated from this sample pair as:
(9.24) |
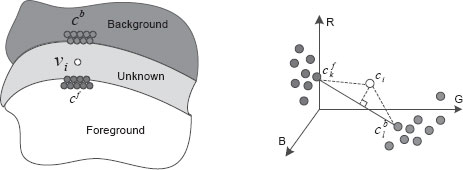
FIGURE 9.4
Left: to define the node weight for an unknown pixel υi, a set of spatially nearby foreground and background colors cf and cb are collected. Right: a sample pair cfk and cbl is considered to be a good estimation of the true foreground and background colors of υi if cfk, cbl, and ci together satisfy the linear constraint in the RGB color space.
Rd (cfk, cbl) essentially measures the linearity of cfk, cbl, and Ii in the color space. It is easy to show that Rd (cfk, cbl) is small if the three colors approximately lie on a color line, and vise versa. Based on the distance ratio, a confidence value for the sample pair is defined as:
(9.25) |
where σc is a constant set at 0.1. γ(cfk) is the weight for the color cfk:
(9.26) |
which favors foreground samples that are close to the target pixel. γ(cbl) is defined in a similar way.
Given a set of foreground and background samples, this approach exhaustively examines every possible foreground background sample combination, and finally chooses a few sample pairs (typically 3) with the highest confidence values. Denote the average confidence value of these pairs as ˉfi, and the average alpha value estimated from these pairs using Equation 9.24 as ˉαi, the final node weight is computed as
(9.27) |
where H(x) is the Heaviside step function which outputs 1 when x > 0 and 0 otherwise. This node weight encourages the final alpha value αi to be close to ˉαi when the sampling confidence ˉfi is high, and αi to be either 0 or 1 when the confidence is low. When the confidence is low, it suggests that ci cannot be well approximated as a linear interpolation of known foreground and background colors, and it is thus more likely to be a new foreground or background color.

FIGURE 9.5
An example of the color sampling method used in the Robust Matting system [2]. (a) Input image with overlayed trimap, (b) initial alpha matte computed by Equation 9.24 using best sample pairs, (c) the confidence map computed by Equation 9.25, white means higher confidence values, (d) final alpha matte after minimizing the energy in Equation 9.40.
Figure 9.5 shows an example of using this sampling method for alpha matting. Given the input image and the specified trimap as shown in Figure 9.5a, the alpha matte ˉαi computed using Equation 9.24, and the confidence map ˉfi computed using Equation 9.25 are visualized in Figure 9.5b and 9.5c. The final alpha matte of the Robust Matting algorithm after minimizing the energy function in Equation 9.40 is shown in Figure 9.5d.
Based on the color sampling method described above, Rhemann et al. [24] proposed an improved sampling procedure for defining the node weight. In Wang and Cohen’s work, foreground and background samples are selected solely based on their spatial distances to υi, without considering the underlying image structures. To improve this, Rhemann et al. proposed to select foreground samples based on their geodesic distances [25] to υi in the image space. This distance measure encourages the foreground samples to not only be close to υi spatially, but also belong to the same connected image component as υi. In this approach, a confidence function that is slightly different from Equation 9.25 is defined as:
f2 (cfk, cbl) = exp (−Rd(cfk, cbl) ⋅ γ′ (cfk) ⋅ γ′(cbl)σ2c), |
(9.28) |
where the sample weights are defined as
{γ′ (cfk)= exp (−maxk (‖cfk − ci‖2)‖cfk − ci‖2),γ′ (cbl)= exp (−maxk (‖cbl − ci‖2)‖cbl − ci‖2). |
(9.29) |
Both sampling procedures described above exhaustively examine every possible combination of foreground and background samples, thus their computational cost is high. For instance, if N (N = 20 in [2]) samples are collected for both the foreground and the background, N2 pair evaluations have to be performed for every unknown pixel. To reduce the computational cost while maintaining the sampling accuracy, Gastal and Oliveira proposed a Shared Sampling method [26], which is motivated by the fact that pixels in a small neighborhood usually share the same attributes. This algorithm first selects at most kg (a small number) foreground and background samples for each pixel, resulting in at most k2g test pairs, from which the best pair is selected. The algorithm also makes sure that sample sets of neighboring pixels are disjoint. Then, in a small neighborhood of kr pixels, each pixel analyzes the best choices of its kr spatial neighbors, and chooses the best sample pair as its final decision. Thus, while in practice k2g + kr pair evaluations are performed for each pixel, due to the affinity among neighboring pixels, this is roughly equivalent to performing k2g × kr pair evaluations. In their system, kg and kr are set to be 4 and 200, respectively, thus 4 × 4 + 200 = 216 pair evaluations can achieve the effect of evaluating 16 × 200 = 3200 pairs. Using this efficient sampling method plus some local smoothing postprocessing steps, Gastal and Oliveira developed a real-time matting system which achieves high accuracy on the publicly available online matting benchmark [27].
The sampling procedures described so far are all local sampling methods, i.e., for an unknown pixel, only a limited number of nearby foreground and background colors are collected for alpha estimation. He et al. [15] pointed out that due to the limited size of the sample set and sometimes complex foreground structures, local sampling may not always cover the true foreground and background colors of unknown pixels. They further proposed a global sampling approach, where for evaluating the alpha value of an unknown pixel, all known foreground and background colors in the image are used as samples. Specifically, from all possible sample pairs, the best one is chosen which minimizes the cost function:
Egs (cfk, cbl) = κ‖ci − ˆαicfk − (1 − ˆαi) cbl‖ + η(xfk) + η(xbl), |
(9.30) |
where ˆαi is the alpha value estimated from cfk and cbl using Equation 9.24, κ is a balancing weight and η(xfk) is the spatial energy computed from the spatial location of cfk and ci as:
(9.31) |
η(xbl) is the spatial energy computed for cbl in the same way. To handle the computational complexity introduced by the large number of samples, their system poses the sampling task as a correspondence problem in a special “FB search space”, and uses a generalized fast patch matching algorithm [28] to efficiently find the best sample pair in that space, denoted as ˆcfk and ˆcbl. After sample search, the node weight is finally defined as:
(9.32) |
Note that the global sampling method intrinsically assumes that the foreground and background color distributions are spatially invariant, so that the color samples that are spatially far away from the target pixel may still be valid estimations of the true foreground and background colors of the pixel. If the foreground or background colors are spatially varying, using remote color samples may introduce additional color ambiguity which will lead to less accurate alpha estimation.
9.3 Solving Image Matting Graphs
Once the edge and node weights are properly defined for the matting graph, solving the alpha matte becomes a graph labeling problem. Depending on exactly how the edge and node weights are formulated, various optimization techniques can be applied to obtain the solution. Here we review a few representative techniques that have been widely used in existing matting systems.
Wang and Cohen proposed an iterative optimization approach [13] to compute the alpha matte from sparsely specified user scribbles. In this method, the matting graph is formulated as a Markov Random Field (MRF), and the total energy to be minimized is defined as:
(9.33) |
where wbpi is the node weight defined in Equation 9.22, and wbpij is the edge weight in Equation 9.9. This approach also quantizes the continuous alpha value in [0, 1] into multiple discrete levels so that discrete optimization is applicable. With the MRF defined in this way, finding alpha labels corresponds to the MAP estimation problem, which can be practically solved using the loopy Belief Propagation (BP) algorithm [29].
To generate accurate alpha mattes from sparsely defined user trimaps, in this approach the energy minimization method described above is applied iteratively in an active region. The active region is created and updated iteratively by expanding the user scribbles toward the rest of the image until all unknown pixels have been covered. This ensures that pixels nearby the user scribbles are computed first, and they will in turn affect other pixels that are far away from the scribbles. In each iteration of the algorithm, the data weight wbpi and edge weight wbpij are updated based on the alpha matte computed in the previous iteration, and a new energy Ebp(α) is minimized using the BP algorithm.
One of the major limitations of the MRF formulation is its high computational complexity. Furthermore, iteratively applying the BP optimization may lead the algorithm to converge to a local minimum. To avoid these limitations, some approaches carefully define their energy functions in such a way that they can be efficiently solved by closed-form optimization techniques.
Grady et al. [11] defined a matting graph where the edge weight wlppij is formulated as Equation 9.7, and solved the graph labeling problem using Random Walks. In this algorithm, αi is modeled as the probability that a random walker starting from vi will reach a pixel in the foreground before striking a pixel in the background, when biased to avoid crossing the foreground boundary. Denote the degree of υi as:
(9.34) |
for all edges eij incident on υi. The probability that a random walker at υi transitions to υj is computed as pij = wlppij /di. Theoretical studies [30] show that the solution to the random walker problem is exactly the solution to the inhomogeneous Dirichlet problem from potential theory, given Dirichlet boundary conditions that αj = 1 if υj is in the foreground region of the trimap, and αj =0 if υj is in the background region. Specifically, these probabilities are an exact, steady-state, global minimum to the Dirichlet energy functional:
(9.35) |
subject to the boundary conditions. Lrm is the graph Laplacian given by:
Lrmij = {drmi: if i = j,−wlppij: if i and j are neighbors,0: otherwise. |
(9.36) |
The energy functional in Equation 9.35 can be efficiently minimized by solving a sparse, symmetric, positive-definite linear system, and has been further implemented on GPU for real-time interaction [11].
Similar to Wang and Cohen’s approach [13], the Easy Matting system [12] also employs an iterative optimization framework. In the kth iteration, the total energy to be minimized is defined as
(9.37) |
where weasyi is the node weight defined in Equation 9.21, and weasyi is the edge weight defined in Equation 9.8. Note that since both terms are carefully defined in quadratic forms, this energy function can be efficiently minimized by solving a large linear system. Also, unlike Ebp(α) defined in Equation 9.33 which uses a constant weight λ for balancing the two energy terms, the weight λk in Equation 9.37 is dynamically adjusted as
(9.38) |
where k is the number of iterations, and β is a predefined constant which is set to be 3.4 in the system. In this setting, λk becomes smaller when the iteration number k increases. This allows the foreground and background regions to grow faster from sparsely specified user scribbles in early iterations, by using large λk values early on. In later iterations when the foreground and background regions encounter, a smaller λk will allow the node weight weasyi to play a bigger role on determining alpha values for pixels on the foreground edge.
Based on the edge weight defined in Equation 9.13, Levin et al. proposed a matting energy as:
(9.39) |
where Lcf is the matting Laplacian defined in Equation 9.14. This is again a problem of minimizing a quadratic error score, which can be solved as a linear system. Built upon this, the Robust Matting algorithm [2] defines its energy function as:
(9.40) |
where wrmi is the node weight defined in Equation 9.27. The shared matting approach [26] and the global sampling approach [15] minimize a similar energy function, except that the node weight wi is determined using the shared sampling approach or the global sampling approach described in Section 9.2.2.

FIGURE 9.6
The height test images with different properties in the online image matting benchmark [27].
To quantitatively compare various image matting approaches, Rhemann et al. [27] proposed the first online benchmark3 for image matting. This benchmark provides a high resolution ground truth data set, which contains 8 test and 27 training images, along with predefined trimaps. These images were shot in a controlled environment, and the ground truth mattes were extracted using the triangulation method [31], by shooting the same foreground object against multiple single-colored backgrounds. The test images have different properties such as hard and soft boundaries, translucency, or different boundary topologies, as shown in Figure 9.6.
3 3The web URL for the benchmark is www.alphamatting.com.
The online system also provides all scripts and data necessary to allow people to submit new results on the test images, and compare them with results of other approaches in the system. Four different error metrics have been implemented when comparing results to the ground truth: absolute differences (SAD), mean squared error (MSE), and two other perceptually motivated measures named as connectivity and gradient errors. Since introduced, this benchmark has been used by many recent image matting systems for objective and quantitative evaluation.
Video matting refers to the problem of estimating alpha mattes of dynamic foreground objects from a video sequence. Compared with image matting, it is a considerably harder problem due to two new challenges: interaction efficiency and temporal coherence.
In image matting systems, the user is usually required to manually specify an accurate trimap in order to achieve accurate mattes. However, this quickly becomes tedious for video, as a short video sequence may contain hundreds or thousands of frames, and manually specifying a trimap for each frame requires simply too much work. To minimize the required user interaction, video matting approaches typically ask the user to provide trimaps only on sparsely distributed keyframes, and then use automatic methods to propagate trimaps to other frames. Automatic trimap generation thus becomes the key component of a video matting system.
In the video matting task, in addition to be accurate on each frame, the alpha mattes computed in consecutive frames are required to be temporally coherent. In fact, temporal coherence is often more important than single frame accuracy, as the human visualization system (HVS) is very sensitive to temporal inconsistency presented in a video sequence [32]. Simply applying image matting techniques frame-by-frame without considering temporal coherence often results in temporally jittering alpha mattes. Maintaining temporal coherence of the resulting mattes thus becomes another fundamental requirement for video matting.
9.5.2 Graph-Based Trimap Generation
Video matting approaches usually apply binary foreground object segmentation for trimap generation. Once a binary segmentation is obtained on each frame, the unknown region of the trimap can be easily generated by dilating and eroding the foreground region. An example is shown in Figure 9.9, where for the input image Figure 9.9b, a binary segmentation in Figure 9.9b is first created, which leads to the trimap shown in Figure 9.9c.
In the video object cut-and-paste system [33], each video frame is at first automatically segmented into atomic regions using the watershed image segmentation algorithm [34], mainly for improving the computational efficiency. These atomic regions are treated as basic elements for graph construction. The user is then required to provide accurate foreground object segmentation on a few keyframes as initial guidance, by using existing interactive image segmentation tools. Between each pair of successive keyframes, a 3D graph G = (V, ℰ) is then built on atomic regions, as shown in Figure 9.7.
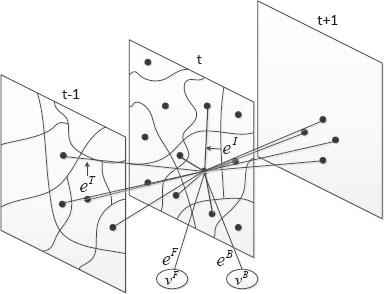
FIGURE 9.7
Graph construction for trimap generation in the video object cut-and-paste system [33].
In graph G, the node set V includes all atomic regions on all frames between the two keyframes. There are also two virtual nodes υF and υB, which correspond to definite foreground ℱ and definite background ℬ as hard constraints. There are three types of edges in the graph: intraframe edges eI, interframe edges eT, and edges between atomic regions and virtual nodes eF and eB. An intraframe edge eIij connects two adjacent atomic regions υti and υtj on frame t, while an interframe edge eTij connects υti and υt+1j, if the two regions have both similar colors and overlapping spatial locations. Every atomic region connects to the virtual nodes υF and υB.
For edges eFi and eBi, the weights wFi and wBi encode the user-provided hard constraints, as well as the color similarity between υi and user-marked regions. Mathematically, they are defined as:
(9.41) |
and
(9.42) |
If υi is marked as either ℱ (αi = 1) or ℬ (αi = 0) on the keyframes, then the edge weight is 0 to the corresponding node and ∞ to the other. Otherwise, wFi and wBi are determined by its color distances to the known foreground and background colors, denoted as dF (υi) and dB (υi). To compute the color distance, Gaussian Mixture Models (GMMs) [35] are used to describe the foreground and background color distributions, collected from the ground-truth segmentations on keyframes. Denote the kth component of the foreground GMM as (wfk, μfk, ∑fk), representing the weight, the mean color, and the color covariance matrix, respectively, for a given color c, dF(c) is computed as:
(9.43) |
where
(9.44) |
and
(9.45) |
For the node υi (note that υi is an atomic region containing many pixels), its distance to the foreground GMMs dF(υi) is defined as the average distance of dF (cj ∈ υi), where cj is the color of a pixel inside the atomic region. The background distance dF(υi) is defined in the same way using the background GMMs.
For the intraframe and interframe edges eI and eT, the edge weights are defined as
(9.46) |
where αi and αj are labels for υi and υj, which are constrained to be either 0 or 1 for the purpose of binary segmentation. β is a parameter that weights the color contrast, which can be set as a constant or computed adaptively using the robust method proposed by Blake et al. [36]. ˉci and ˉcj are the average colors of pixels inside υi and υj.
The total energy to be minimized for the graph labeling problem is
E(α) = ∑υi ∈ V(αiwFi) + (1 − αi) wBi + λ1 ∑eij ∈ eIwij + λ2 ∑eij ∈ eTwij, |
(9.47) |
where αi can only be 0 or 1 in this binary labeling problem, and λ1 and λ2 are used to adjust the weights of the energy terms. For instance, a higher λ2 will enforce the solution to be more temporally coherent. This energy function can be minimized using the graph cuts algorithm [16].
After the graph labeling problem is solved, a local tracking and refinement step is further employed to improve the segmentation accuracy. Finally, a trimap is created for each frame by dilating and eroding the segmented foreground region, and a coherent matting approach [37], which is a variant of the Bayesian matting algorithm [9], is used to generate the final alpha mattes. Wang et al. [38] introduced another 3D graph labeling approach for trimap generation in video. Their system first applies the 2D mean shift image segmentation algorithm [39] on each frame to generate oversegmented regions, similar to the atomic regions in the video object cut-and-paste system. The system then treats the 2D mean shift regions as super-pixels by representing each region using the mean position and color of all pixels inside it, and applies the mean shift algorithm again to group 2D regions into 3D spatiotemporal regions. This two-step clustering method results in a strict hierarchical structure of the input video, shown in Figure 9.8a, where each pixel belongs to a 2D region, and each 2D region belongs to a 3D spatiotemporal region.
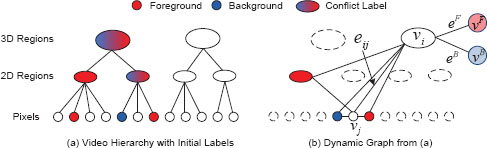
FIGURE 9.8
Video hierarchy and dynamic graph construction in the 3D video cutout system [38]. (a). Video hierarchy created by two-step mean shift segmentation. User-specified labels are then propagated upward from the bottom level. (b). A graph is dynamically constructed based on the current configuration of the labels. Only highest level nodes that have no conflict are selected. Each node in the hierarchy also connects to two virtual nodes υF and υB.
A unique characteristic of Wang et al.’s system is the dynamic graph construction. In this approach, an optimization graph is dynamically constructed in real time given the user input and the precomputed video hierarchy. Suppose the user has marked some pixels as foreground and some as background, as shown in Figure 9.8a. The labels are then automatically propagated upward in the hierarchy to all higher level nodes. Conflict with be introduced in this propagation process since upper level nodes may contain both foreground and background pixels. To construct the optimization graph, the system only picks out highest level nodes which have no conflict, and connects neighboring nodes using edges, as shown in Figure 9.8b. An edge is established between any two nodes which are adjacent to each other in the 3D video cube. The graph labeling problem is then solved by an optimization process, which assigns a label to every node in the graph. The computed labels are then propagated downward to every singe pixel to create the final segmentation. If the segmentation contains errors, the user can then mark more pixels as hard constraints, which will result in a new graph for optimization. This dynamic graph construction allows the system to always use the smallest number of nodes for optimization, and at the same time to satisfy all the user-provided constraints. The segmentation efficiency is thus greatly improved. For instance, the system can reportedly segment a 200-frame 720 × 480 video sequence in less than 10 seconds [8].
Similar to the graph constructed in Figure 9.7, each node in the dynamic graph (Figure 9.8b) also connects to two virtual nodes υF and υB. If υi is marked as foreground by the user, then wFi = 0 and wBi = ∞. Similarly, wFi = ∞ and wBi = 0 is specified as background. Otherwise they are computed as
(9.48) |
where DFi and DBi are color distances measured between υi and known foreground and background colors. The system first trains GMMs on known foreground and background colors, and then computes the color distances by fitting the average pixel color in υi (υi contains multiple pixels if it is a higher level node), denoted as ˉci, to the GMMs as
(9.49) |
where (wfk, μfk, ∑fk) represent the weight, the mean color, and the color covariance matrix of the kth component of the foreground GMM. DBi is computed in a similar way using the background GMM.
For the edge weight wij, the system uses the classic exponential term as defined in Equation 9.5. Additionally, if the input video is known to have a static background, a local background color model, as well as a local background link model, are defined and incorporated into the global node and edge weights, which can greatly help the system better recognize background nodes. The detailed definitions of the local node and edge weights can be found in the original paper [38].
The dynamically constructed graph is finally solved by the graph cuts algorithm, which assigns every node in the graph a foreground or background label. The labels are then propagated to the bottom level pixels to create a complete segmentation. The whole process iterates as the user provides more scribbles to correct segmentation errors, until satisfactory results are achieved.
9.5.3 Matting with Temporal Coherence
Once trimaps are created for all video frames, image matting techniques can be applied frame-by-frame to generate the final alpha mattes. However, as discussed earlier, this naive approach does not guarantee temporal coherence and can easily introduce temporal jitter to the mattes. Extra temporal coherence constraints thus have to be employed for video matting.
As described in Section 9.1.2, for an unknown pixel, Bayesian matting algorithm samples nearby foreground and background colors, and applies them in a Bayesian framework for estimating its alpha value. Chuang et al. [40] extended this approach for video matting, by constraining the color samples to be temporally coherent. Specifically, once the foreground object is masked out on each frame, the remaining background fragments are registered and assembled to form a composite mosaic [41], which can then be reprojected into each original frame to form a dynamic clean plate. The dynamic clean plate essentially gives every unknown pixel an accurate background estimation, resulting in improved accuracy of the foreground matte. Since the reconstructed clean plates are temporally coherent, the temporal coherence of the final alpha mattes is also greatly improved.
Xue et al. proposed a more explicit temporal coherence term in their matting approach in the Video SnapCut system [42]. The key idea of this algorithm is to warp the alpha matte computed on frame t − 1 to frame t using estimated motion between the two frames, and treat it as a prior for computing the matte on frame t. For the matting graph defined in this approach, the edge weight is defined using the closed-form solution in Equation 9.13. The node weight for pixel υi on frame t contains two components: a color prior αCi computed from locally sampled nearby foreground and background colors, and a temporal prior αt − 1s(i) which is the alpha value at pixel s(i) on frame t − 1. The pixel s(i) is the corresponding pixel of υi on frame t − 1, according to the computed optical flow between the two frames. The alpha matte is solved by minimizing the following energy function:
E(αt) = ∑i [λTi (αi − αt − 1s(i))2 + λCi (αi − αCi)2] + αtT Lcf αt, |
(9.50) |
where λTi and λCi are locally adaptive weights. Specifically, λCi measures the confidence of the sampled foreground and background colors on frame t and the alpha value estimated from them, which is computed as in Equation 9.25. λTi measures the confidence of the temporal prior αt − 1s(i), based on how similar the foreground shapes are in local windows around υi on frame t, and s(i) on frame t − 1. The detailed formulations can be found in the original paper [42]. Lcf is the matting Laplacian defined in Equation 9.14.
Figure 9.9 shows an example of how the explicit temporal coherence term (the first term in Equation 9.50) can help improve the temporal coherence of the alpha mattes. Given the input frames t and t + 1 shown in Figure 9.9b and 9.9e, binary segmentation results (Figure 9.9c and 9.9f) for these two frames are first created, and two trimaps are then generated from the binary segmentation, as shown in Figure 9.9d and 9.9g. Suppose αt, the alpha matte on frame t is already computed. If αt+1 is computed without the temporal coherence term, the resulting matte is erroneous and not consistent with αt, as shown in Figure 9.9i. On the contrary, with the temporal coherence term, αt+1 has less errors and is more consistent with αt, as shown in Figure 9.9j. This example shows that with the explicit temporal coherence term, the alpha estimation is more robust against dynamic backgrounds that have complex colors and textures.
Image and video matting is an active research topic which not only is theoretically interesting, but also has huge potentials in numerous real-world applications, ranging from image editing to film production. The state-of-the-art in matting research has been significantly advanced in recent years, by formulating matting as a graph labeling problem and solving it using graph optimization methods. In this chapter, we show that many image matting approaches share a rather common graph structure, and the merit of each method lies in its unique way to define the edge and node weights in the graph. We further show how to extend graph analysis to video for generating accurate trimaps and alpha mattes in a temporally coherent way.
Despite the significant progress that has been made, image and video matting still remains to be an unsolved problem in difficult cases. From the analysis presented in this chapter, it is clear that most matting approaches are built upon some smoothness image priors, either implicitly or explicitly. In difficult cases where the foreground and background regions contain high contrast textures, most existing matting approaches may not work well, since their underlying color smoothness assumptions are violated. Furthermore, compared with image matting, video matting poses additional challenges. A good video matting system has to provide accurate mattes on each frame. More importantly, the alpha mattes on adjacent frames have to be temporally coherent. Existing video matting solutions still cannot deal with dynamic objects with large semitransparent regions, such as long hair blowing in the wind against a moving background. We expect novel graphical models and new graph analysis methods to be be developed in the future to address these limitations.

FIGURE 9.9
An example of coherent matting in video. (a) The input sequence, the red box shows the highlighted region in the rest of the figure; (b) the highlighted region on frame t; (c) binary segmentation on frame t; (d) trimap generated on frame t; (e) the highlighted region on frame t + 1; (f) binary segmentation on frame t + 1; (g) trimap generated on frame t + 1; (h) computed αt, (i) computed αt+1 without the temporal coherence term in Equation 9.50, (j) computed αt+1 with the temporal coherence term.
[1] T. Porter and T. Duff, “Compositing digital images,” in Proc. ACM SIGGRAPH, vol. 18, July 1984, pp. 253–259.
[2] J. Wang and M. Cohen, “Optimized color sampling for robust matting,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2007, pp. 1–8.
[3] C. Rother, V. Kolmogorov, and A. Blake, “”grabcut”: Interactive foreground extraction using iterated graph cuts,” ACM Trans. Graphics, vol. 23, no. 3, pp. 309–314, 2004.
[4] Y. Li, J. Sun, C.-K. Tang, and H.-Y. Shum, “Lazy snapping,” ACM Trans. Graphics, vol. 23, no. 3, pp. 303–308, 2004.
[5] C. Rhemann, C. Rother, A. Rav-Acha, and T. Sharp, “High resolution matting via interactive trimap segmentation,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2008, pp. 1–8.
[6] M. Ruzon and C. Tomasi, “Alpha estimation in natural images,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2000, pp. 18–25.
[7] Y. Mishima, “Soft edge chroma-key generation based upon hexoctahedral color space,” in U.S. Patent 5,355,174, 1993.
[8] J. Wang and M. Cohen, “Image and video matting: A survey,” Foundations and Trends in Computer Graphics and Vision, vol. 3, no. 2, pp. 97–175, 2007.
[9] Y.-Y. Chuang, B. Curless, D. H. Salesin, and R. Szeliski, “A Bayesian approach to digital matting,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2001, pp. 264–271.
[10] A. Levin, D. Lischinski, and Y. Weiss, “A closed-form solution to natural image matting,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 30, no. 2, pp. 228–242, 2008.
[11] L. Grady, T. Schiwietz, S. Aharon, and R. Westermann, “Random walks for interactive alpha-matting,” in Proc. Visualization, Imaging, and Image Processing, 2005, pp. 423–429.
[12] Y. Guan, W. Chen, X. Liang, Z. Ding, and Q. Peng, “Easy matting: A stroke based approach for continuous image matting,” in Computer Graphics Forum, vol. 25, no. 3, 2006, pp. 567–576.
[13] J. Wang and M. Cohen, “An iterative optimization approach for unified image segmentation and matting,” in Proc. International Conference on Computer Vision, 2005, pp. 936–943.
[14] Y. Zheng and C. Kambhamettu, “Learning based digital matting,” in Proc. International Conference on Computer Vision, 2009.
[15] K. He, C. Rhemann, C. Rother, X. Tang, and J. Sun, “A global sampling method for alpha matting,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, June 2011, pp. 1–8.
[16] Y. Boykov, O. Veksler, and R. Zabih, “Fast approximate energy minimization via graph cuts,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 23, no. 11, pp. 1222–1239, 2001.
[17] J. Shi and J. Malik, “Normalized cuts and image segmentation,” IEEE Trans. Pattern Analysis and Machine Intelligence, pp. 888–905, 2000.
[18] X. He and P. Niyogi, “Locality preserving projections,” in Proc. Advances in Neural Information Processing Systems, 2003.
[19] D. Singaraju and R. Vidal, “Interactive image matting for multiple layers,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2008, pp. 1–7.
[20] K. He, J. Sun, and X. Tang, “Single image haze removal using dark channel prior,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2009, pp. 1956–1963.
[21] E. Hsu, T. Mertens, S. Paris, S. Avidan, and F. Durand, “Light mixture estimation for spatially varying white balance,” ACM Trans. Graphics, vol. 27, pp. 1–7, 2008.
[22] D. Singaraju, C. Rother, and C. Rhemann, “New appearance models for natural image matting,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2009, pp. 659–666.
[23] B. Scholkopf and A. J. Smola, Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. Cambridge, MA, USA: MIT Press, 2001.
[24] C. Rhemann, C. Rother, and M. Gelautz, “Improving color modeling for alpha matting,” in Proc. British Machine Vision Conference, 2008, pp. 1155–1164.
[25] X. Bai and G. Sapiro, “Geodesic matting: A framework for fast interactive image and video segmentation and matting,” International Journal on Computer Vision, vol. 82, no. 2, pp. 113–132, 2008.
[26] E. S. L. Gastal and M. M. Oliveira, “Shared sampling for real-time alpha matting,” Computer Graphics Forum, vol. 29, no. 2, pp. 575–584, May 2010.
[27] C. Rhemann, C. Rother, J. Wang, M. Gelautz, P. Kohli, and P. Rott, “A perceptually motivated online benchmark for image matting,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2009, pp. 1826–1833.
[28] C. Barnes, E. Shechtman, A. Finkelstein, and D. B. Goldman, “Patchmatch: A randomized correspondence algorithm for structural image editing,” ACM Trans. Graphics, vol. 28, no. 3, pp. 1–11, July 2009.
[29] Y. Weiss and W. Freeman, “On the optimality of solutions of the max-product belief propagation algorithm in arebitrary graphs,” IEEE Trans. Information Theory, vol. 47, no. 2, pp. 303–308, 2001.
[30] S. Kakutani, “Markov processes and the Dirichlet problem,” in Proc. Japanese Academy, vol. 21, 1945, pp. 227–233.
[31] A. R. Smith and J. F. Blinn, “Blue screen matting,” in Proc. ACM SIGGRAPH, 1996, pp. 259–268.
[32] P. Villegas and X. Marichal, “Perceptually-weighted evaluation criteria for segmentation masks in video sequences,” IEEE Trans. Image Processing, vol. 13, no. 8, pp. 1092–1103, 2004.
[33] J. S. Y. Li and H. Shum, “Video object cut and paste,” ACM Trans. Graphics, vol. 24, pp. 595–600, 2005.
[34] L. Vincent and P. Soille, “Watersheds in digital spaces: an efficient algorithm based on immersion simulations,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 13, no. 6, pp. 583–598, 1991.
[35] D. Titterington, A. Smith, and U. Makov, Statistical Analysis of Finite Mixture Distributions. John Wiley & Sons, 1985.
[36] A. Blake, C. Rother, M. Brown, P. Perez, and P. Torr, “Interactive image segmentation using an adaptive GMMRF model,” in Proc. European Conference on Computer Vision, 2004, pp. 428–441.
[37] H. Shum, J. Sun, S. Yamazaki, Y. Li, and C. Tang, “Pop-up light field: An interactive image-based modeling and rendering system,” ACM Trans. Graphics, vol. 23, no. 2, pp. 143–162, 2004.
[38] J. Wang, P. Bhat, R. A. Colburn, M. Agrawala, and M. F. Cohen, “Interactive video cutout,” ACM Trans. Graphics, vol. 24, pp. 585–594, 2005.
[39] D. Comaniciu and P. Meer, “Mean shift: A robust approach toward feature space analysis,” IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 24, no. 5, pp. 603–619, 2002.
[40] Y.-Y. Chuang, A. Agarwala, B. Curless, D. Salesin, and R. Szeliski, “Video matting of complex scenes,” ACM Trans. Graphics, vol. 21, pp. 243–248, 2002.
[41] R. Szeliski and H. Shum, “Creating full view panoramic mosaics and environment maps,” in Proc. ACM SIGGRAPH, 1997, pp. 251–258.
[42] X. Bai, J. Wang, D. Simons, and G. Sapiro, “Video snapcut: Robust video object cutout using localized classifiers,” ACM Trans. Graphics, vol. 28, no. 3, pp. 1–11, July 2009.
1In many applications, recovering αp alone is sufficient. We will mainly focus on how to recover the alpha matte in this chapter.
2For notation simplicity, we will use υi to denote both an unknown pixel and its corresponding node in the graph.