
Graph theory concepts and definitions used in image processing and analysis
Université de Caen Basse-Normandie
GREYC UMR CNRS 6072
6 Bvd. Maréchal Juin
F-14050 CAEN, FRANCE
Email: [email protected]
Department of Image Analytics and Informatics
Siemens Corporate Research
755 College Rd.
Princeton, NJ 08540, USA
Email: [email protected]
CONTENTS
1.4 Paths, Trees, and Connectivity
1.4.4 Trees and Minimum Spanning Trees
1.4.5 Maximum Flows and Minimum Cuts
1.5 Graph Models in Image Processing and Analysis
1.5.3 Proximity Graphs for Unorganized Embedded Data
Graphs are structures that have a long history in mathematics and have been applied in almost every scientific and engineering field (see [1] for mathematical history, and [2, 3, 4] for popular accounts). Many excellent primers on the mathematics of graph theory may be found in the literature [5, 6, 7, 8, 9, 10], and we encourage the reader to learn the basic mathematics of graph theory from these sources. We have two goals for this chapter: First, we make this work self-contained by reviewing the basic concepts and notations for graph theory that are used throughout this book. Second, we connect these concepts to image processing and analysis from a conceptual level and discuss implementation details.
Intuitively, a graph represents a set of elements and a set of pairwise relationships between those elements. The elements are called nodes or vertices, and the relationships are called edges. Formally, a graph G
Every graph may be viewed as weighted. Given a graph G = (V, ℰ)
Each edge is considered to be oriented and some edges additionally directed. An orientation of an edge means that each edge eij ∈ ℰ
The edge orientation of an undirected graph provides a reference to determine the sign of a flow through that edge. This concept was developed early in the circuit theory literature to describe the direction of current flow through a resistive branch (an edge). For example, a current flow through eij from node υi to υj is considered positive, while a current flow from υj to υi is considered negative. In this sense, flow through a directed edge is usually constrained to be strictly positive.
Drawing a graph is typically done by depicting each node with a circle and each edge with a line connecting circles representing the two nodes. The edge orientation or direction is usually represented by an arrow. Edge eij is drawn with an arrow pointing from node υi to node υj.
We consider two functions s, t : ℰ → V
Given these preliminaries, we may now list a series of basic definitions:
1. Adjacent: Two nodes υi and υj are called adjacent if ∃eij ∈ ℰ
2. Incident: An edge eij is incident to nodes υi and υj (and each node is incident to the edge).
3. Isolated: A node υi is called isolated if wij = wji = 0, ∀υj ∈ V
4. Degree: The outer degree of node υi, deg− (υi), is equal to deg−(υi) = ∑eij ∈ ℰwij
5. Complement: A graph ˉG = (V, ˉℰ)
6. Regular: An undirected graph is called regular if di = k, ∀υi ∈ V for some constant k.
7. Complete (fully connected): An undirected graph is called complete or fully connected if each node is connected to every other node by an edge, that is when ℰ = V × V. A complete graph of n vertices is denoted Kn. Figure 1.1 gives an example of K5.
8. Partial graph: A graph G′ = (V, ℰ′) is called a partial graph [11] of G = (V, ℰ) if ℰ′ ⊆ ℰ.
9. Subgraph: A graph G′ = (V′, ℰ′) is called a subgraph of G = (V, ℰ) if V′ ⊆ V, and ℰ′ = {eij ∈ ℰ | υi ∈ V′ and υj ∈ V′}.
10. clique: A clique is defined as a fully connected subset of the vertex set (see Figure 1.2).
11. Bipartite: A graph is called bipartite if V can be partitioned into two subsets V1 ⊂ V and V2 ⊂ V, where V1 ∩ V2 = 0 and V1 ∪ V2 = V, such that ℰ ⊆ V1 × V2. If |V| = m and |V| = n, and ℰ = V1 × V2, then G is called a complete bipartite graph and is denoted by Km,n. Figure 1.2 gives an example of K3, 5.
12. Graph isomorphism: Let G1 = (V1, ℰ1) and G2 = (V2, ℰ2) be two undirected graphs. A bijection f : V1 → V2 from G1 to G2 is called a graph isomorphism if (υi, υj)∈ ℰ1 implies that (f(υi), f(υj)) ∈ ℰ2. Figure 1.3 shows an example of an isomorphism between two graphs.
13. Higher-order graphs (hypergraph): A graph G = (V, ℰ, ℱ) is considered to be a higher-order graph or hypergraph if each element of ℱ, fi ∈ ℱ is defined as a set of nodes for which each |fi| > 2. Each element of a higher-order set is called a hyperedge, and each hyperedge may also be weighted. A k-uniform hypergraph is one for which all hyperedges have size k. Therefore, a 3-uniform hypergraph would be a collection of node triplets.
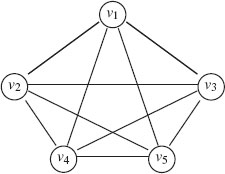
FIGURE 1.1
An example of complete graph K5.
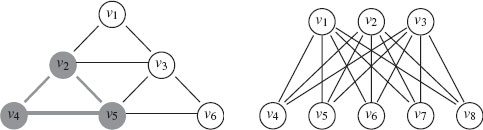
FIGURE 1.2
Left: A clique in a graph (grey). Right: The complete bipartite graph K3, 5 with V1 = {υ1, υ2, υ3} and V2 = {υ4, υ5, υ6, υ7, υ8}.
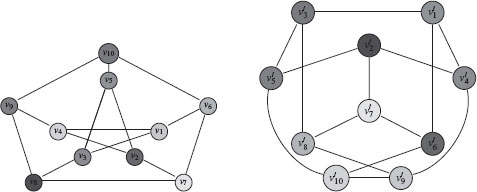
FIGURE 1.3
Example of two isomorphic graphs under the mapping υ10 → υ′3, υ9 → υ′5, υ8 → υ′2, υ7 → υ′7, υ6 → υ′8, υ5 → υ′1, υ4 → υ′10, υ3 → υ′4, υ2 → υ′6, υ1 → υ′9.
Several computer representations of graphs can be considered. The data structures used to represent graphs can have a significant influence on the size of problems that can be performed on a computer and the speed with which they can be solved. It is therefore important to know the different representations of graphs. To illustrate them, we will use the graph depicted in Figure 1.4.
A graph may be represented by one of several different common matrices. A matrix representation may provide efficient storage (since most graphs used in image processing are sparse), but each matrix representation may also be viewed as an operator that acts on functions associated with the nodes or edges of a graph.
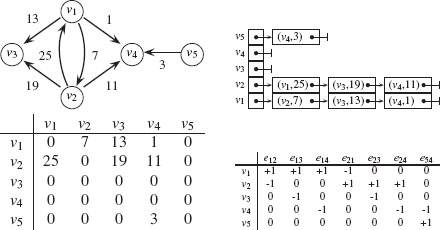
FIGURE 1.4
From top-left to bottom-right: a weighted directed graph, its adjacency list, its adjacency matrix, and its (transposed) incidence matrix representations.
The first matrix representation of a graph is given by the incidence matrix. The incidence matrix for G = (V, ℰ) is an |ℰ| × |V| matrix A where
(1.1) |
The incidence matrix has the unique property of the matrices in this section that it preserves the orientation information of each edge but not the edge weight. The adjoint (transpose) of the incidence matrix also represents the boundary operator for a graph in the sense that multiplying this matrix with a signed indicator vector of edges in a path will return the endpoints of the path. Furthermore, the incidence matrix defines the exterior derivative for functions associated with the nodes of the graph. As such, this matrix plays a central role in discrete calculus (see [12] for more details).
The constitutive matrix of graph G = (V, ℰ) is an |ℰ| × |ℰ| matrix C where
(1.2) |
The adjacency matrix representation of graph G = (V, ℰ) is a |V| × |V| matrix W where
(1.3) |
For undirected graphs the matrix W is symmetric.
The Laplacian matrix of an undirected graph G =(V, ℰ) is a |V| × |V| matrix GL where
(1.4) |
and G is a diagonal matrix with Gii = w(υi). In the context of the Laplacian matrix, w(υi) = 1 or w(υi) = 1di are most often adopted (see [12] for a longer discussion on this point).
If G = I, then for an undirected graph these matrices are related to each other by the formula
(1.5) |
where D is a diagonal matrix of node degrees with Dii = di.
The advantage of adjacency lists over matrix representations is less memory usage. Indeed, a full incidence matrix requires O(|V| × |ℰ|) memory, and a full adjacency matrix requires O(|V|2) memory. However, sparse graphs can take advantage of sparse matrix representations for a much more efficient storage.
An adjacency list representation of a graph is an array L of |V| linked lists (one for each vertex of V). For each vertex υi, there is a pointer Li to a linked list containing all vertices υj adjacent to υi. For weighted graphs, the linked list contains both the target vertex and the edge weight. With this representation, iterating through the set of edges is O(|V| + |ℰ|) whereas it is O(|V|2) for adjacency matrices. However, checking if an edge ek ∈ ℰ is an O(|V|) operation with adjacency lists whereas it is an O(1) operation with adjacency matrices.
1.4 Paths, Trees, and Connectivity
Graphs model relationships between nodes. These relationships make it possible to define whether two nodes are connected by a series of pairwise relationships. This concept of connectivity, and the related ideas of paths and trees, appear in some form throughout this work. Therefore, we now review the concepts related to connectivity and the basic algorithms used to probe connectivity relationships.
Given a directed graph G = (V, ℰ) and two vertices υi, υj∈ V, a walk (also called a chain) from υi to υj is a sequence π(υ1, υn) = (υ1, e1, υ2, …, υn−1, en−1, υn), where n ≥ 1, υi ∈ V, and ej∈ ℰ:
υ1 = υi, υj = υn, and {s(ei), t(ei)}= {υi, υi+1}, 1 ≤ i ≤ n. |
(1.6) |
The length of the walk is denoted as |π| = n. A walk may contain a vertex or edge more than once. If υi = υj, the walk is called a closed walk; otherwise it is an open walk. A walk is called a trail if every edge is traversed only once. A closed trail is called a circuit. A circuit is called a cycle if all nodes are distinct. An open walk is a path if every vertex is distinct. A subpath is any sequential subset of a path. Figure 1.5 is used to illustrate the concepts of walk, trail, and path. In Figure 1.5, bolded grey arrows provide a walk π(υ1, υ1) = (υ1, e8, υ5, e7, υ1, e1, υ2, e6, υ6, e4, υ5, e7, υ1) that is a closed walk, but is neither a trail (e7 is traversed twice) nor a cycle. Dashed grey arrows provide a walk π(υ6, υ4) = (υ6, e5, υ2, e2, υ3, e3, υ4) that is an open walk, a trail, and a path. Black arrows are arrows not involved in the walks π(υ1, υ1) and π(υ6, υ4).
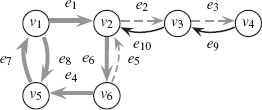
FIGURE 1.5
Illustration of a walk π(υ1, υ1) (bolded grey), trail, and path π(υ6, υ4) (dashed grey).
Two nodes are called connected if ∃π(υi, υj) or ∃π(υj, υi). A graph G = (V, ℰ) is called a connected graph iff ∀υi, υj ∈ V, ∃π(υi, υj), or ∃π(υj, υi). Therefore, the relation
(1.7) |
is an equivalence relation. The induced equivalence classes by this relation form a partition of V into V1, V2, …, Vp subsets. Subgraphs G1, G2, …, Gp induced by V1, V2, …, Vp are called the connected components of the graph G. Each connected component is a connected graph. The connected components of a graph G are the set of largest subgraphs of G that are each connected.
Two nodes are strongly connected if ∃π(υi, υj) and ∃π(υj, υi). If two nodes are connected but not strongly connected, then the nodes are called weakly connected. Note that, in an undirected graph, all connected nodes are strongly connected. The graph is strongly connected iff ∀υi, υj∈ V, ∃π(υi, υj), and ∃π(υj, υi). Therefore, the relation

FIGURE 3.9
Illustrating the label-cost prior. (a) Crop of a stereo image (“cones” image from Middlebury database). (b) Result without a label-cost prior. In the left image each color represents a different surface, where gray-scale colors mark planes and nongrayscale colors, B-splines. The right image shows the resulting depth map. (c) Corresponding result with label-cost prior. The main improvement over (b) is that large parts of the green background (visible through the fence) are assigned to the same planar surface.

FIGURE 3.10
Illustrating the advantage of using an marginal probability field (MPF) over an MRF. (a) Set of training images for binary texture denoising. Superimposed is a pairwise term (translationally invariant with shift (15; 0); 3 exemplars in red). Consider the labeling k = (1, 1) of this pairwise term ϕ. Each training image has a certain number h(1, 1) of (1, 1) labels, i.e. h(1, 1) = Σi[ϕi = (1, 1)]. The negative logarithm of the statistics {h(1, 1)} over all training images is illustrated in blue (b). It shows that all training images have roughly the same number of pairwise terms with label (1, 1). The MPF uses the convex function fk (blue) as cost function. It is apparent that the linear cost function of an MRF is a bad fit. (c) A test image and (d) a noisy input image. The result with an MRF (e) is inferior to the MPF model (f). Here the MPF uses a global potential on unary and pairwise terms.

FIGURE 3.11
Results for image denoising using a pairwise MRF (c) and an MPF model (d). The MPF forces the derivatives of the solution to follow a mean distribution, which was derived from a large dataset. (f) Shows derivative histograms (discretized into the 11 bins). Here black is the target mean statistic, blue is for the original image (a), yellow for noisy input (b), green for the MRF result (c), and red for the MPF result (d). Note, the MPF result is visually superior and does also match the target distribution better. The runtime for the MRF (c) is 1096s and for MPF (d) 2446s.
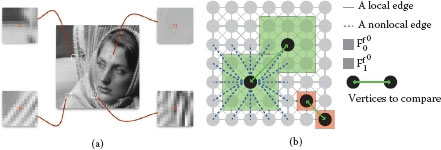
FIGURE 7.2
(a) Four examples of image patches. Central pixels (in red) are associated with vectors of gray-scale values within a patch of size 13 × 13 (Ff06). (b) Graph topology and feature vector illustration: a 8-adjacency grid graphs is constructed. The vertex surrounded by a red box shows the use of the simplest feature vector, i.e., the initial function. The vertex surrounded by a green box shows the use of a feature vector that exploits patches.

FIGURE 7.9
Isotropic colorization of a grayscale image with w = g2 and λ = 0.01 in local and nonlocal configurations.
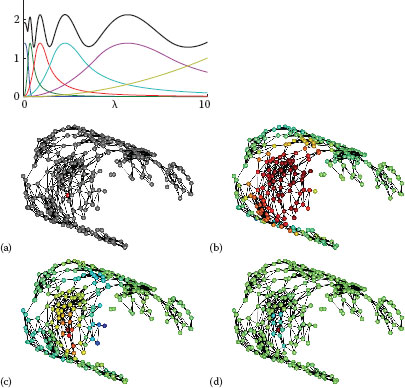
FIGURE 8.1
Left: Scaling function h(λ) (blue curve), wavelet generating kernels g(tjλ), and sum of squares G (black curve), for J = 5 scales, λmax = 10, K1p = 20. Details in Section 8.2.3. Right: Example graph showing specified center vertex (a), scaling function (b) and wavelets at two scales (c,d). Figures adapted from [1].
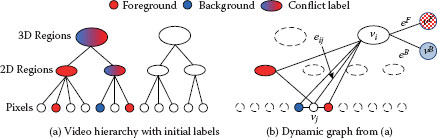
FIGURE 9.8
Video hierarchy and dynamic graph construction in the 3D video cutout system [38]. (a). Video hierarchy created by two-step mean shift segmentation. User-specified labels are then propagated upward from the bottom level. (b). A graph is dynamically constructed based on the current configuration of the labels. Only highest level nodes that have no conflict are selected. Each node in the hierarchy also connects to two virtual nodes υF and υB.
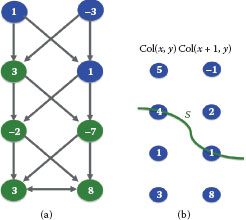
FIGURE 10.5
Illustrating the recovery of a feasible surface from a closed set. (a) shows a closed set in the constructed graph in Figure 10.4(d), which consists of all green nodes. The surface specified by the closed set in (a) is shown in (b).
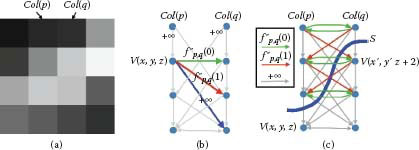
FIGURE 10.9
Graph construction for the convex smoothness penalty function. (a) Example of two adjacent columns. The smoothness parameter Δx = 2. (b) Weighted arcs introduced for each node V(x, y, z). Gray arcs of weight +∞ reflect the hard smoothness constraints. (c) Weighted arcs are built between nodes corresponding to the two adjacent columns. The feasible surface S cuts the arcs with a total weight of fp,q(2)=f″p,q(0)+[f″p,q(0)+f″p,q(1)], which determines smoothness shape compliance term of α(S) for the two adjacent columns.
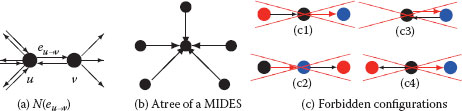
FIGURE 11.11
Directed neighborhood N(eu→υ) of edge eu→υ(a). A tree of a MIDES defining unambiguously its surviving vertex (b). Two edges within a same neighborhood cannot be both selected. Hence, red edges in (c) cannot be selected once black edges have been added to the MIDES.
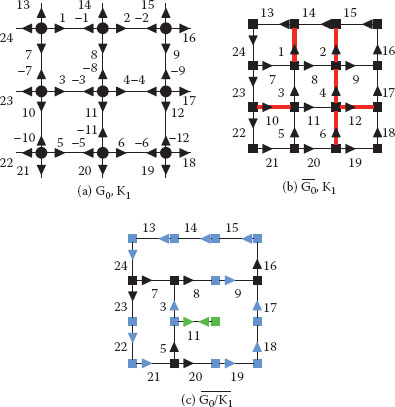
FIGURE 11.21
A combinatorial map (a) and its dual (b) encoding a 3 × 3 grid with the contraction kernel K1 = α*(1, 2, 4, 12, 6, 10) (▬) superimposed to both figures. Only positive darts are represented in (b) and (c) in order to not overload them. The resulting reduced dual combinatorial map (c) should be further simplified by a removal kernel of empty self-loops (RKESL) K2 = α*(11) to remove dual vertices of degree 1 (■). Dual vertices of degree 2 (■) are removed by the RKEDE K3 = φ*(24, 13, 14, 15, 9, 22, 17, 21, 19, 18,) ∪ {3, −5}. Note that the dual vertex φ*(3) = (3, −5, 11) becomes a degree 2 vertex only after the removal of α*(11).
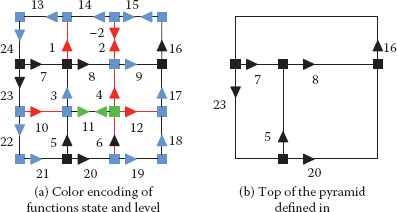
FIGURE 11.22
Implicit encoding (a) and top level combinatorial map (b) of the pyramid defined in Figure 11.21. Red, green and blue darts have level equal to 1, 2, and 3 respectively. States associated to these levels are, respectively, equal to CK, RKESL, RKEDE.
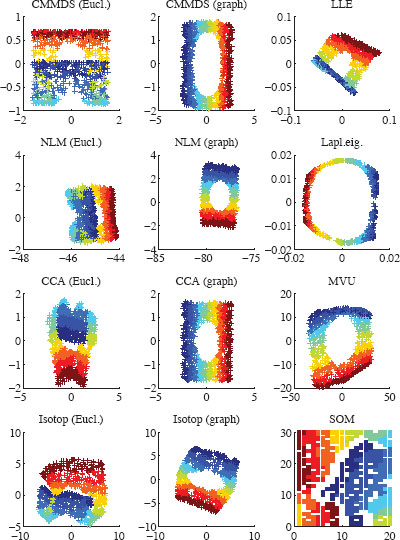
FIGURE 12.03
Two-dimensional embeddings of the Swiss roll with various NLDR methods. Distance-based methods use either Euclidean norm (‘Eucl.’) or shortest paths in a neighborhood graph (‘Graph’).
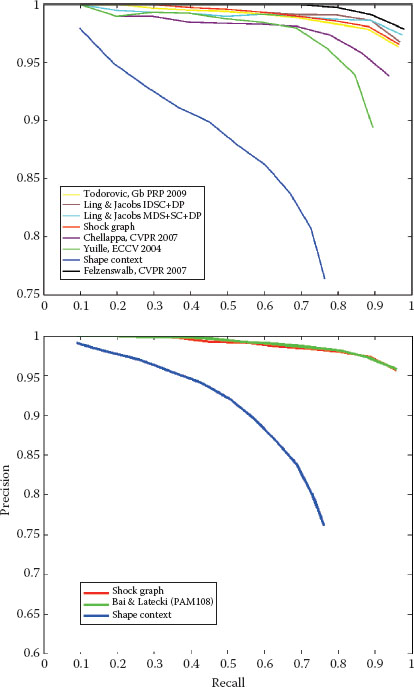
FIGURE 14.6
The recognition performance of the shock-graph matching based on the approach described above for the Kimia-99 and Kimia-216 shape databases [11].
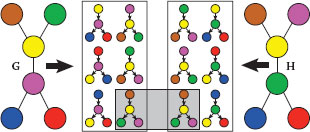
FIGURE 17.3
Graph kernels between two graphs (each color represents a different label). We display all binary 1-tree walks with a specific tree structure, extracted from two simple graphs. The graph kernels are computing and summing the local kernels between all those extracted tree-walks. In the case of the Dirac kernel (hard matching), only one pair of tree-walks is matched (for both labels and structures).
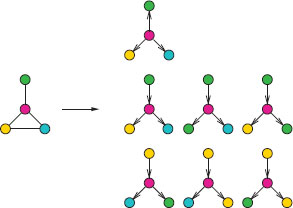
FIGURE 17.5
Examples of tree-walks from a graph. Each color represents a different label.
(1.8) |
is an equivalence relation. The subgraphs induced by the obtained partition of G are the strongly connected components of G. Figure 1.6 illustrates the concepts of strongly and weakly connected components.
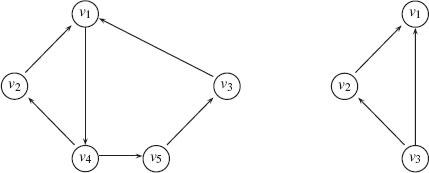
FIGURE 1.6
Left: A strongly connected component. Right: A weakly connected component.
The problems of routing in graphs (in particular the search for a shortest path) are among the oldest and most common problems in graph theory. Let G= (V, ℰ) be a weighted graph where a weight function w : ℰ → ℝ associates a real value (i.e., a weight also called a length in this context) to each edge.1 In this section we consider only graphs for which all edge weights are nonnegative. Let l(π(υi, υj)) denote the total weight (or length) of a walk:
(1.9) |
We will also use the convention that the length of the walk equals ∞ if υi and υj are not connected and l(π(υi, υi)) = 0. The minimum length between two vertices is
(1.10) |
A walk satisfying the minimum in (1.10) is a path called a shortest path. The shortest path between two nodes may not be unique. Different algorithms can be used to compute l* if one wants to find a shortest path from one vertex to all the others or between all pairs of vertices. We will restrict ourselves to the first kind of problem.
To compute the shortest path from one vertex to all the others, the most common algorithm is from Dijkstra [13]. Dijkstra’s algorithm solves the problem for every pair υi, υj, where υi is a fixed starting point and υj∈ V. Dijkstra’s algorithm exploits the property that the path between any two nodes contained in a shortest path is also a shortest path. Specifically, let π(υi, υj) be a shortest path from υi to υj in a weighted connected graph G = (V, ℰ) with positive weights (w : ℰ → ℝ+) and let υk be a vertex in π(υi, υj). Then, the subpath π(υi, υk) ⊂ π(υi, υj) is a shortest path from υi to υk. Dijkstra’s algorithm for computing shortest paths with υi as a source is provided in Figure 1.7 with an example on a given graph. In computer vision, shortest paths have been used for example, for interactive image segmentation [14, 15].
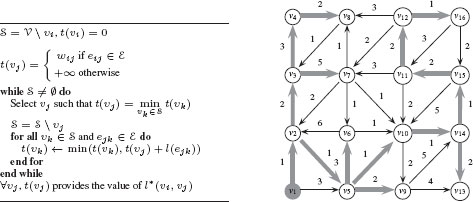
FIGURE 1.7
Left: Dijkstra’s algorithm for computing shortest path from a source vertex υi to all vertices in a graph. Right: Illustration of Dijkstra’s algorithm. The source is vertex υ1. The shortest path from υ1 to other vertices is shown with bolded grey arrows.
1.4.4 Trees and Minimum Spanning Trees
A tree is an undirected connected graph without cycles (acyclic). An unconnected tree without cycles is called a forest (each connected component of a forest is a tree). More precisely, if G is a graph with |V| = n vertices and if G is a tree, the following properties are equivalent:
• G is connected without cycles,
• G is connected and has n − 1 edges,
• G has no cycles and has n − 1 edges,
• G has no cycles and is maximal for this property (i.e., adding any edge creates a cycle),
• G is connected and is minimal for this property (i.e., removing any edge makes the graph disconnected),
• There exists a unique path between any two vertices of G.
A partial graph G′ = (V, ℰ′) of a connected graph G = (V, ℰ) is called a spanning tree of G if G′ is a tree. There is at least one spanning tree for any connected graph.
We may define the weight (or cost) of any tree T = (V, ℰT) by
(1.11) |
A spanning tree of the graph that minimizes the cost (compared to all spanning trees of the graph) is called a minimal spanning tree. The minimal spanning tree of a graph may not be unique. The problem of finding a minimal spanning tree of a graph appears in many applications (e.g., in phone network design). There are several algorithms for finding minimum spanning trees, and we present the one proposed by Prim. The principle of Prim’s algorithm is to progressively build a tree. The algorithm starts from the edge of minimum weight and adds iteratively to the tree the edge of minimum weight among all the possible edges that maintain a partial graph that is acyclic. More precisely, for a graph G = (V, ℰ), one progressively constructs from a vertex υ1 a subset V′ with {υ1} ⊆ V′ ⊆ V and a subset ℰ′ ⊆ ℰ such that the partial graph G′ = (V, ℰ′) is a minimum spanning tree of G. To do this, at each step, one selects the edge eij of minimum weight in the set {ekl | ekl ∈ ℰ, υk ∈ V′, l ∈ V V′}. Subset V′ and ℰ′ are then augmented with vertex υj and edge eij : V′ ← V′ ∪ {υj} and ℰ′ ← ℰ′ ∪ {eij}. The algorithm terminates when V′ = V. Prim’s algorithm for computing minimum spanning trees is provided in Figure 1.8 along with an example on a given graph. In computer vision, minimum spanning trees have been used, for example, for image segmentation [16] and image hierarchical representation [17].
1.4.5 Maximum Flows and Minimum Cuts
A transport network is a weighted directed graph G = (V, ℰ) such that
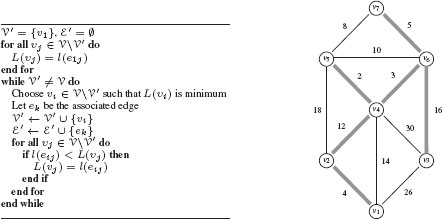
FIGURE 1.8
Left: Prim’s algorithm for computing minimum spanning trees in a graph starting from node υ1. Note that, any node may be selected as υ1, and the algorithm will generate a minimal spanning tree. However, when a graph contains multiple minimal spanning trees the selection of υ1 may determine which minimal spanning tree is determined by the algorithm. Right: Illustration of Prim’s algorithm. The minimum spanning tree is shown by the grey bolded edges.
• There exists exactly one vertex υ1 with no predecessor called the source (and denoted by υs), that is, deg+ (υ1) = 0,
• There exists exactly one vertex υn with no successor called the sink (and denoted by υt), that is, deg− (υn) = 0,
• There exists at least one path from υs to υt,
• The weight w(eij) of the directed edge eij is called the capacity and it is a nonnegative real number, that is, we have a mapping w : ℰ → ℝ+.
We denote by A+(υi) the set of inward directed edges from vertex υi:
(1.12) |
Similarly, we denote by A−(υi) the set of outward directed edges from vertex υi:
(1.13) |
A function φ : ℰ → ℝ+ is called a flow iff
• Each vertex υi ∉ {υs, υt} satisfies the conservation condition (also called Kirchhoff’s Current Law):
(1.14) |
which may also be written in matrix form as
(1.15) |
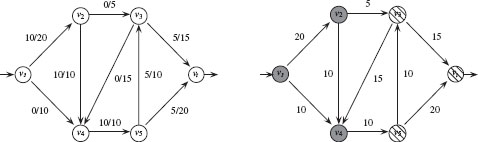
FIGURE 1.9
Left: an (s, t)-flow with value 10. Each edge is labeled with its flow/capacity. Right: An (s, t)-cut with capacity 30, V1 = {υs, υ2, υ4} (grey) and V2 = {υ3, υ5, υt} (striped).
where pi = 0 for any υi ∉ {υs, υt}. Intuitively, this law states that the flow entering each node must also leave that node (i.e., conservation of flow).
• For each edge eij, the capacity constraint φ(eij) ≤ w(eij) is satisfied.
The value of a flow is |φ| = ∑eij ∈ A − (υs)φ(eij) = ∑eij ∈ A + (υt)φ(eij) = ps. A flow φ* is a maximum flow if its value is the largest possible, that is, |φ*| ≥ |φ| for every other flow φ. Figure 1.9 shows an (s, t) flow with value 10.
An (s, t)-cut is a partition P =< V1, V2 > of the vertices into subsets V1 and V2, such that, V1 ∩ V2 = 0, V1 ∪ V2 = V, υs ∈ V1 and υt ∈ V2. The capacity of a cut P is the sum of the capacities of the edges that start in V1 and end in V2:
(1.16) |
with w(eij) = 0 if eij ∉ ℰ. Figure 1.9 shows an (s, t)-cut with capacity 30. The minimum cut problem is to compute an (s, t)-cut for which the capacity is as low as possible. Intuitively, the minimum cut is the least expensive way to disrupt all flow from υs to υt. In fact, one can prove that, for any weighted directed graph, there is always a flow φ and a cut (V1, V2) such that the value of the maximum flow is equal to the capacity of the minimum cut [18].
We call an edge eij saturated by a flow if φ(eij) = wij. A path from υs to υt is saturated if any one of its edges is saturated. The residual capacity of an edge cr : V × V → ℝ+ is
cr(eij) = {wij− φ(eij) if eij ∈ ℰ,φ(eij) if eji ∈ ℰ,0 otherwise. |
(1.17) |
The residual capacity represents the flow quantity that can still go through the edge. We may define the residual graph as a partial graph Gr = (V, ℰr) of the initial graph where all the edges of zero residual capacity have been removed, that is, ℰr = {eij∈ ℰ | cr(eij) > 0}.
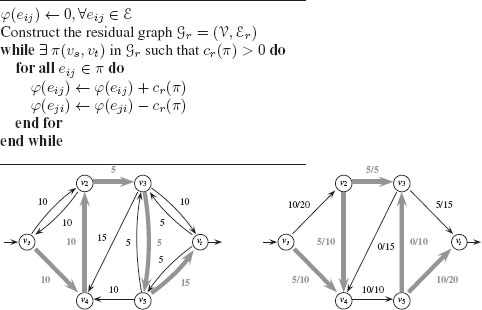
FIGURE 1.10
Top: Ford–Fulkerson algorithm for maximum flow. Bottom: An augmenting path π in Gr with cr(π) = 5, and the associated augmented flow φ′.
Given a path π in Gr from υs to υt, the residual capacity of an augmenting path is the minimum of all the residual capacities of its edges:
(1.18) |
Such a path is called an augmenting path if cr(π) > 0. From this augmenting path we can define a new augmented flow function φ′:
φ′(eij) = {φ(eij) + cr(π) if eij ∈ π,φ(eij) − cr(π) if eji ∈ π,φ(eij) otherwise. |
(1.19) |
A flow is called a maximum flow if and only if the corresponding residual graph is disconnected (i.e., there is no augmenting path). There are several algorithms for finding maximum flows, but we present the classic algorithm proposed by Ford and Fulkerson [18]. The principle of the Ford–Fulkerson algorithm is to add flow along one path as long as there exists an augmenting path in the graph. Figure 1.10 provides the algorithm along with one step of generating an augmenting path. In computer vision, the use of maximum-flow/min-cut solutions to solve problems is typically referred to as graph cuts, following the publication by Boykov et al. [19]. Furthermore, the Ford–Fulkerson algorithm was found to be inefficient for many computer vision problems, with the algorithm by Boykov and Kolmogorov generally preferred [20].
1.5 Graph Models in Image Processing and Analysis
In the previous sections we have presented some of the basic definitions and notations used for graph theory in this book. These definitions and notations may be found in other sources in the literature but were presented to make this work self-contained. However, there are many ways in which graph theory is applied in image processing and computer vision that are specialized to these domains. We now build on the previous definitions to provide some of the basics for how graph theory has been specialized for image processing and computer vision in order to provide a foundation for the subsequent chapters.
Digital image processing operates on sampled data from an underlying continuous light field. Each sample is called a pixel in 2D or a voxel in 3D. The sampling is based on the notion of lattice, which can be viewed as a regular tiling of a space by a primitive cell. A d-dimensional lattice Ld is a subset of the d-dimensional Euclidean space ℝd with
(1.20) |
where u1, …, ud ∈ ℝd form a basis of ℝd and U is the matrix of column vectors. A lattice in a d-dimensional space is therefore a set of all possible vectors represented as integer weighted combinations of d linearly independent basis vectors. The lattice points are given by Uk with kT = (k1, …, kd) ∈ ℤd.
The unit cell of Ld with respect to the basis u1, …, ud is
(1.21) |
where [0, u1]d is the unit cube in ℝd. The volume of C is given by |det U|. The density of the lattice is given by 1/|detU|, that is, the lattice sites per unit surface. The set {C + x | x ∈ ℝd} of all lattice cells covers ℝd. The Voronoi cell of a lattice is called the unit cell (a cell of a lattice whose translations cover the whole space). The Voronoi cell encloses all points that are closer to the origin than to other lattice points. The Voronoi cell boundaries are equidistant hyperplanes between surrounding lattice points. Two well-known 2D lattices are the rectangular U1 = [1001] and hexagonal U2 = [√320121] lattices. Figure 1.11 presents these two lattices. By far the most common lattice in image processing and computer vision is the rectangular sampling lattice derived from U1. In 3D image processing, the lattice sampling is typically given by
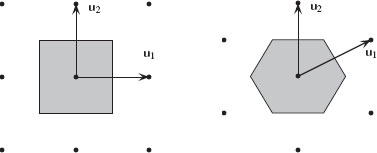
FIGURE 1.11
The rectangular (left) and hexagonal (right) lattices and their associated Voronoi cells.
(1.22) |
for some constant k in which the typical situation is that k ≥ 1.
The most common way of using a graph to model image data is to identify every node with a pixel (or voxel) and to impose an edge structure to define local neighborhoods for each node. Since a lattice defines a regular arrangement of pixels it is possible to define a regular graph by using edges to connect pairs of nodes that fall within a fixed Euclidean distance of each other.
For example, in a rectangular lattice, two pixels p = (p1, p2)T and q = (q1, q2)T of ℤ2, are called 4-adjacent (or 4-connected) if they differ by at most one coordinate:
(1.23) |
and 8-adjacent (or 8-connected) if they differ at most of 2 coordinates:
(1.24) |
In the hexagonal lattice, only one adjacency relationship exists: 6-adjacency. Figure 1.11 presents adjacency relationships on the 2D rectangular and hexagonal lattices. Similarly, in ℤ3, we can say in a rectangular lattice that voxels are 6-adjacent, 18-adjacent, or 26-adjacent whether they differ at most of 1, 2, or 3 coordinates. Figure 1.12 presents adjacency relationships between 3D cells (voxels).
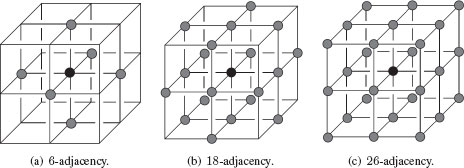
FIGURE 1.12
Different adjacency structures in a 3D lattice.
If one considers edges that connect pairs of nodes that are not directly (i.e., locally) spatially adjacent (e.g., 4- or 8-connected in ℤ2) [21], the corresponding edges are called nonlocal edges [22]. The level of nonlocality of an edge depends on how far the two points are in the underlying domain. These nonlocal edges are usually obtained from proximity graphs (see Section 1.5.3) on the pixel coordinates (e.g., ϵ-ball graphs) or on pixel features (e.g., k-nearest-neighbor graphs on patches).
Image data is almost always sampled in a regular, rectangular lattice that is modeled with the graphs in the previous section. However, images are often simplified prior to processing by merging together regions of adjacent pixels using an untargeted image segmentation algorithm. The purpose of this simplification is typically to reduce processing time for further operations, but it can also be used to compress the image representation or to improve the effectiveness of subsequent operations. When this image simplification has been performed, a graph may be associated with the simplified image by identifying each merged region with one node and defining an edge relationship for two adjacency regions. Unfortunately, this graph is no longer guaranteed to be regular due to the image-dependent and space-varying merging of the underlying pixels. In this section we review common simplification methods that produce these irregular graphs.
One very well-known irregular image tessellation is the region quadtree tessellation [25]. A region quadtree is a hierarchical image representation that is derived from recursively subdividing the 2D space into four quadrants of equal size until every square contains one homogeneous region (based on appearance properties of every region of the underlying rectangular grid) or contains a maximum of one pixel. A region quadtree tesselation can be easily represented by a tree where each node of the tree corresponds to a square. The set of all nodes at a given depth provides a given level of decomposition of the 2D space. Figure 1.13 presents a simple example on an image (Figure 1.13(a)) with the associated tree (Figure 1.13(b)), as well as an example on a real image (Figure 1.13(c)). Quadtrees easily generalize to higher dimensions. For instance, in three dimensions, the 3D space is recursively subdivided into eight octants, and thus the tree is called an octree, where each node has eight children.
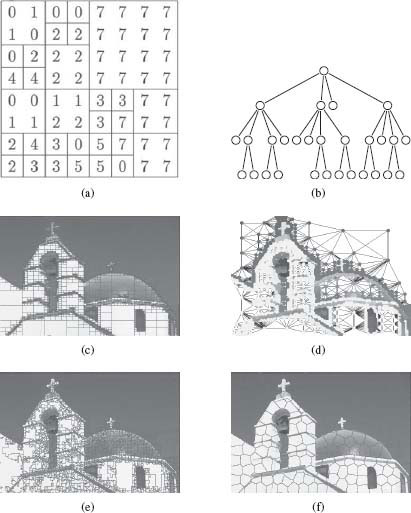
FIGURE 1.13
(a) An image with the quadtree tessellation, (b) the associated partition tree, (c) a real image with the quadtree tessellation, (d) the region adjacency graph associated to the quadtree partition, (e) and (f) two different irregular tessellations of an image using image-dependent superpixel segmentation methods: Watershed [23] and SLIC superpixels [24].
Finally, any partition of the classical rectangular grid can be viewed as producing an irregular tessellation of an image. Therefore any segmentation of an image can be associated with a region adjacency graph. Figure 1.13(d) presents the region adjacency graph associated to the partition depicted in 1.13(c). Specifically, given a graph G = {V, ℰ} where each node is identified with a pixel, a partition into R connected regions V1 ∪ V2 ∪ … ∪ VR = V, V1 ∩ V2 ∩ … ∩ VR = 0 may be identified with a new graph ˜G = {˜V, ˜ℰ} where each partition of V is identified with a node of ˜V, that is, Vi∈ ˜V. A common method for defining ˜ℰ is to let the edge weight between each new node equal the sum of the edge weights connecting each original node in the sets, that is, for edge eij ∈ ˜ℰ
(1.25) |
Each contiguous Vi is called a superpixel. Superpixels are an increasingly popular trend in computer vision and image processing. This popularity is partly due to the success of graph-based algorithms, which can be used to operate efficiently on these irregular structures (as opposed to traditional image-processing algorithms which required that each element is organized on a grid). Indeed, graph-based models (e.g., Markov Random Fields or Conditional Random Fields) can provide dramatic speed increases when moving from pixel-based graphs to superpixel-based graphs due to the drastic reduction in the number of nodes. For many vision tasks, compact and highly uniform superpixels that respect image boundaries are desirable. Typical algorithms for generating superpixels are Normalized Cuts [21], Watersheds [23], Turbo Pixels [26], and simple linear iterative clustering superpixels [24], etc. Figure 1.13(e) and (f) presents some irregular tessellations based on superpixel algorithms.
1.5.3 Proximity Graphs for Unorganized Embedded Data
Sometimes the relevant features of an image are neither individual pixels nor a partition of the image. For example, the relevant features of an image might be the blood cells in a biomedical image, and it is these blood cells that we wish to identify with the nodes of our graph. We may assume that each node (feature) in a dD image is associated with a coordinate in d dimensions. However, although each node has a geometric representation, it is much less clear than before how to construct a meaningful edge set for a graph based on the proximity of features.
There are many ways to construct a proximity graph representation from a set of data points that are embedded in ℝd. Let us consider a set of data points {x1, …, xn}∈ ℝd. To each data point we associate a vertex of a proximity graph G to define a set of vertices V = {υ1, υ2, …, υn}. Determining the edge set ℰ of the proximity graph G requires defining the neighbors of each vertex υi according to its embedding xi. A proximity graph is therefore a graph in which two vertices are connected by an edge iff the data points associated to the vertices satisfy particular geometric requirements. Such particular geometric requirements are usually based on a metric measuring the distance between two data points. A usual choice of metric is the Euclidean metric. We will denote as D(υi, υj) = ‖xi − xj‖2 the Euclidean distance between vertices, and as B(υi; r) = {xj ∈ ℝn | D (υi,υj) ≤ r} the closed ball of radius r centered on xi. Classical proximity graphs are:
• The ϵ-ball graph: υi ~ υj if xj ∈ B(υi ; ϵ).
• The k-nearest-neighbor graph (k-NNG): υi ~ υj if the distance between xi and xi is among the k-th smallest distances from xi to other data points. The k-NNG is a directed graph since one can have xi among the k-nearest neighbors of xj but not vice versa.
• The Euclidean Minimum Spanning Tree (EMST): This is a connected tree subgraph that contains all the vertices and has a minimum sum of edge weights (see Section 1.4.4). The weight of the edge between two vertices is the Euclidean distance between the corresponding data points.
• The symmetric k-nearest-neighbor graph (Sk-NNG): υi ~ υj if xi is among the k-nearest neighbors of y or vice versa.
• The mutual k-nearest-neighbor graph (Mk-NNG): υi ~ υj if xi is among the k-nearest neighbors of y and vice versa. All vertices in a mutual k-NN graph have a degree upper-bounded by k, which is not usually the case with standard k-NN graphs.
• The Relative Neighborhood Graph (RNG): υi ~ υj iff there is no vertex in
(1.26) |
• The Gabriel Graph (GG): υi ~ υj iff there is no vertex in
(1.27) |
• The β-Skeleton Graph (β-SG): υi ~ υj iff there is no vertex in
B((1− β2) υi + β2 υj; β2 D(υi, υj)) ∩B ((1 − β2) υj + β2 υi; β2 D(υi, υj)). |
(1.28) |
The Gabriel Graph is obtained with β = 1, and the Relative Neighborhood Graph with β = 2.
• The Delaunay Triangulation (DT): υi ~ υj iff there is a closed ball B(⋅ ; r) with υi and υj on its boundary and no other vertex υk contained in it. The Delaunay Triangulation is the dual of the Voronoi irregular tessellation where each Voronoi cell is defined by the set {x ∈ ℝn | D(x, υk) ≤ D(x, υj) for all υj ≠ υk}. In such a graph, ∀ υi, deg (υi) = 3.
• The Complete Graph (CG): υi ~ υj ∀(υi, υj), that is, it is a fully connected graph that contains an edge for each pair of vertices and ℰ = V × V.
A surprising relationship between the edge sets of these graphs is that [27]
(1.29) |
Figure 1.14 presents examples of some of these proximity graphs. All these graphs are extensively used in different image analysis tasks. These methods have been used in Scientific Computing to obtain triangular irregular grids (triangular meshes) adapted for the finite element method [28] for applications in physical modeling used in industries such as automotive, aeronautical, etc. Proximity graphs have also been used in Computational and Discrete Geometry [29] for the analysis of point sets in ℝ2 (e.g., for 2D shapes) or ℝ3 (e.g., for 3D meshes). They are also the basis of many classification and model reduction methods [30] that operate on feature vectors in ℝd, for example, Spectral Clustering [31], Manifold Learning [32], object matching, etc. Figure 1.15 presents some proximity graph examples on real-world data.
Graphs are tools that make it possible to model pairwise relationships between data elements and have found wide application in science and engineering. Computer vision and image processing have a long history of using graph models, but these models have been increasingly dominant representations in the recent literature. Graphs may be used to model spatial relationships between nearby or distant pixels, between image regions, between features, or as models of objects and parts. The subsequent chapters of this book are written by leading researchers who will provide the reader with a detailed understanding of how graph theory is being successfully applied to solve a wide range of problems in computer vision and image processing.
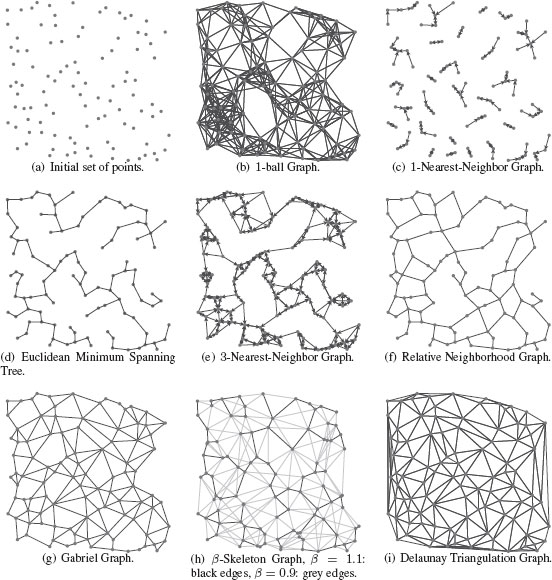
FIGURE 1.14
Examples of proximity graphs from a set of 100 points in ℤ2.
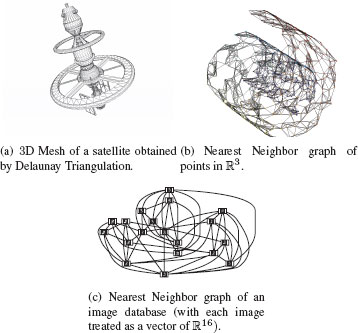
FIGURE 1.15
Some proximity graph examples on real-world data.
[1] N. Biggs, E. Lloyd, and R. Wilson, Graph Theory, 1736–1936. Oxford University Press, New-York, 1986.
[2] A.-L. Barabasi, Linked: How Everything Is Connected to Everything Else and What It Means. Plume, New-York, 2003.
[3] D. J. Watts, Six Degrees: The Science of a Connected Age. W. W. Norton, 2004.
[4] N. A. Christakis and J. H. Fowler, Connected: The Surprising Power of Our Social Networks and How They Shape Our Lives. Little, Brown and Company, 2009.
[5] F. Harary, Graph Theory. Addison-Wesley, 1994.
[6] A. Gibbons, Algorithmic Graph Theory. Cambridge University Press, 1989.
[7] N. Biggs, Algebraic Graph Theory, 2nd ed. Cambridge University Press, 1994.
[8] R. Diestel, Graph Theory, 4th ed., ser. Graduate Texts in Mathematics. Springer-Verlag, 2010, vol. 173.
[9] J. L. Gross and J. Yellen, Handbook of Graph Theory, ser. Discrete Mathematics and Its Applications. CRC Press, 2003, vol. 25.
[10] J. Bondy and U. Murty, Graph Theory, 3rd ed., ser. Graduate Texts in Mathematics. Springer-Verlag, 2008, vol. 244.
[11] J. Gallier, Discrete Mathematics, 1st ed., ser. Universitext. Springer-Verlag, 2011.
[12] L. Grady and J. R. Polimeni, Discrete Calculus: Applied Analysis on Graphs for Computational Science. Springer, 2010.
[13] E. W. Dijkstra, “A note on two problems in connexion with graphs,” Numerische Mathematik, vol. 1, no. 1, pp. 269–271, 1959.
[14] E. N. Mortensen and W. A. Barrett, “Intelligent scissors for image composition,” in SIGGRAPH, 1995, pp. 191–198.
[15] P. Felzenszwalb and R. Zabih, “Dynamic programming and graph algorithms in computer vision,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 33, no. 4, pp. 721–740, 2011.
[16] P. F. Felzenszwalb and D. P. Huttenlocher, “Efficient graph-based image segmentation,” Int. J. Computer Vision, vol. 59, no. 2, pp. 167–181, 2004.
[17] L. Najman, “On the equivalence between hierarchical segmentations and ultrametric watersheds,” J. of Math. Imaging Vision, vol. 40, no. 3, pp. 231–247, 2011.
[18] L. Ford Jr and D. Fulkerson, “A suggested computation for maximal multi-commodity network flows,” Manage. Sci., pp. 97–101, 1958.
[19] Y. Boykov, O. Veksler, and R. Zabih, “Fast approximate energy minimization via graph cuts,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 23, no. 11, pp. 1222–1239, 2001.
[20] Y. Boykov and V. Kolmogorov, “An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 26, no. 9, pp. 1124–1137, 2004.
[21] J. Shi and J. Malik, “Normalized cuts and image segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 22, no. 8, pp. 888–905, 2000.
[22] A. Elmoataz, O. Lezoray, and S. Bougleux, “Nonlocal discrete regularization on weighted graphs: A framework for image and manifold processing,” IEEE Trans. Image Process., vol. 17, no. 7, pp. 1047–1060, 2008.
[23] L. Vincent and P. Soille, “Watersheds in digital spaces: An efficient algorithm based on immersion simulations,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 13, no. 6, pp. 583–598, 1991.
[24] A. Radhakrishna, “Finding Objects of Interest in Images using Saliency and Superpixels,” Ph.D. dissertation, 2011.
[25] H. Samet, “The quadtree and related hierarchical data structures,” ACM Comput. Surv., vol. 16, no. 2, pp. 187–260, 1984.
[26] A. Levinshtein, A. Stere, K. N. Kutulakos, D. J. Fleet, S. J. Dickinson, and K. Siddiqi, “Turbopixels: Fast superpixels using geometric flows,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 12, pp. 2290–2297, 2009.
[27] G. T. Toussaint, “The relative neighbourhood graph of a finite planar set,” Pattern Recogn., vol. 12, no. 4, pp. 261–268, 1980.
[28] O. Zienkiewicz, R. Taylor, and J. Zhu, The Finite Element Method: Its Basis and Fundamentals, 6th ed. Elsevier, 2005.
[29] J. E. Goodman and J. O’Rourke, Handbook of Discrete and Computational Geometry, 2nd ed. CRC Press LLC, 2004.
[30] M. A. Carreira-Perpinan and R. S. Zemel, “Proximity graphs for clustering and manifold learning,” in NIPS, 2004.
[31] U. von Luxburg, “A tutorial on spectral clustering,” Stat. Comp., vol. 17, no. 4, pp. 395–416, 2007.
[32] J. A. Lee and M. Verleysen, Nonlinear Dimensionality Reduction. Springer, 2007.
1Edge weights may be used to represent either affinities or distances between nodes. An affinity weight of zero is viewed as equivalent to a disconnection (removal of the edge from ℰ), and a distance weight of ∞ is viewed as equivalent to a disconnection. An affinity weight a may be converted to a distance weight b via b = 1a. A much longer discussion on this relationship may be found in [12]. In this work, affinity weights and distance weights use the same notation, with the distinction being made by context. All weights in this section are considered to be distance weights.