
2.12. Mini Specifications
Before You Reached Here ...
![]() Easiest: You have built an event-response model for Piccadilly in Chapter 1.10 Refining an Event-Response. Before the event-response model is complete, however, you must write a description of the processes in your model. These process descriptions are known as mini specifications; they’re also called process specifications, P-specs, or transformation specifications.
Easiest: You have built an event-response model for Piccadilly in Chapter 1.10 Refining an Event-Response. Before the event-response model is complete, however, you must write a description of the processes in your model. These process descriptions are known as mini specifications; they’re also called process specifications, P-specs, or transformation specifications.
![]() More Difficult and
More Difficult and ![]() Most Difficult: Your trails bypass this chapter. To rejoin your trail, go to Chapter 1.11 Writing Mini Specifications.
Most Difficult: Your trails bypass this chapter. To rejoin your trail, go to Chapter 1.11 Writing Mini Specifications.
![]() Promenade: So far, you’ve seen the data dictionary used to specify the data flows and entities found in the event-response models. (You just came from Chapter 2.11 Event-Response Models.) This chapter completes the event-response modeling topic, as it discusses how mini specifications describe the system’s processes.
Promenade: So far, you’ve seen the data dictionary used to specify the data flows and entities found in the event-response models. (You just came from Chapter 2.11 Event-Response Models.) This chapter completes the event-response modeling topic, as it discusses how mini specifications describe the system’s processes.
Working Models
Let us reiterate: The goal of systems analysis is to build a working model of the system. The working model is based on the Rule of Data Conservation, which states that each process in the model must receive data that are both necessary and sufficient to produce its output. The data dictionary defines both the inputs and outputs of each process, and it can be used to prove that each process is capable of producing its outputs from its inputs.
However, something’s missing. You need a specification that says what the process does with its inputs to produce its outputs. That is the role of the mini specification. Mini specifications, as the name implies, are small. They specify a small part of the system, the functional primitive, which can usually be described in a page or less. The mini specification describes a single, discrete functional component of the system.
Specifying the Functional Primitives
Your event partitioning breaks the system into functional pieces. Each event-response process model declares the essential processes and data concerned with that event. Now you need to specify the detailed processing rules.
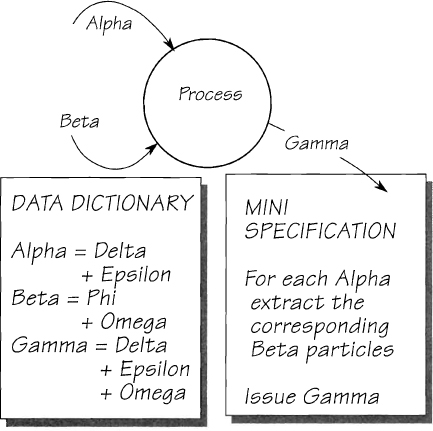
Figure 2.12.1: The complete and rigorous model. The data dictionary defines the data, and the mini specification describes the processing of that data.
You can model the system’s essential processing at several levels. At the highest level, you group all of the system’s responses to an event into one bubble. This one bubble is referred to as an essential activity. If the essential activity is small enough, you can specify it by writing a mini specification. Otherwise, you’ll need to decompose the essential activity into some number of functional primitives using leveling (see Chapter 2.7 Leveled Data Flow Diagrams). Each of these primitives is then specified in the form of a mini specification. When you have written all the mini specifications, you have something that is quite remarkable: a specification of a system that is complete. Everything is specified, but only once.
Isn’t It Late to Be Specifying?
We intentionally left this chapter about mini specifications until you had a chance to develop your process models. This is to make our point that you delay specifying the processes for as long as possible. By building the data flow diagrams, data models, and data dictionary first, you are refining your knowledge of the system. In the process of eliminating the implementation-dependent processes and data, you have reduced the requirements to their essential minimum, and there are fewer mini specifications to write.
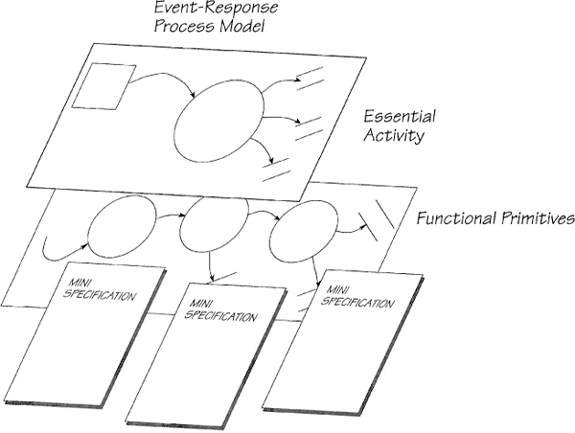
Figure 2.12.2: An event-response process model may have several levels. A complex essential activity will be broken down to its functional primitives, each of which is described by a mini specification.
However, postponing writing the mini specifications doesn’t mean that you must wait until you’ve finished all the event-response modeling before you write your first specification. Sometimes, when you discover a piece of essential policy while doing current physical modeling, it makes sense to write the specification right then. Above all, don’t write mini specifications for processes that are dependent on the implementation. Those processes are adequately specified with a current physical data flow diagram.
Sometimes, especially if you are asked to produce a high-level overview, it is useful to write a specification for a high-level process that is not a functional primitive. We refer to such a high-level specification as a maxi specification. Our advice is to avoid writing maxi specifications because they are a duplication of policy that will eventually be in several mini specifications. The high-level requirements are better specified by a combination of data flow diagrams, data model, and data dictionary. Normally, because you are using the models to talk about the system and raise questions, users accept them very easily. Put the strategy of writing a maxi specification into your analyst’s toolkit only for extreme situations when you are having trouble communicating with someone who insists on a text specification.
Specification Techniques
Each of the system’s processes is different, with one making many decisions, another doing extensive calculations, a third following many rules, and so on. Because of the differences, processes need different kinds of specification. When you write mini specifications, choose a technique that is appropriate for the process being described.
With an example, we’ll demonstrate some of the most useful methods for specifying processes. As we do, evaluate them for their suitability for other types of processes. Look at the following fragment of a model and the accompanying user’s statement. Neither gives you enough information to complete the specification. However, our attempt to write a mini specification for this process should reveal the missing parts.
Here is the user’s statement: “This process is part of a system for paying contract workers at a construction site. The workers submit their time cards at the end of the week. Another part of the system edits the cards, so this process receives only accurate data. When the workers fill in their time cards, the hours are complete hours and not fractions.
“Different work categories have different hourly rates of pay. Overtime worked under categories 4, 5, or 6 is not paid at overtime rates.”
As we write a mini specification for the process PRODUCE CONTRACTORS’ PAY SLIPS, we’ll illustrate several specification techniques. First, we’ll use a variant of our natural written language called structured language.
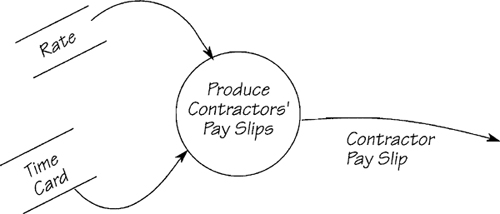
Figure 2.12.3: This process is part of a system to pay contract workers. The data dictionary gives some of the definitions for this model.
Contractor Pay Slip = Contractor Id
+ {Work Category + Normal Hours Worked + Loaded Rate
+ $ Amount + Overtime Hours Worked + Overtime Rate
+ Overtime $ Amount}
+ Total Hours Worked + Total $ Amount
Penalty Loading = * Data element. Awarded for dangerous or dirty work.*
Rate = {Work Category + Hourly Rate
+ (Penalty Loading)}
Time Card = Contractor Id
+ {Work Category + Normal Hours Worked
+ Overtime Hours Worked}
Structured Language
Structured language uses a subset of our natural language. The subset is restricted to a few verbs that manipulate the data items already established in the data dictionary.
The term “structured” is used because this language follows the same rules for combining statements as does structured programming. The structured programming rules were developed to make programs more concise, more readable, and provably correct. In 1966, the Italians Böhm and Jacopini in their landmark paper argued that programs written using only certain structures could be mathematically proved to be logically correct (see the Bibliography). Similarly, if you stick to the rules of structured language, it will be much easier to find the logical errors in your specifications.
Keep in mind that while structured language resembles some programming languages, the mini specification is not the specification of a computer program. You are still doing analysis and trying to state the essential requirements for a process. Therefore, avoid using any procedural terms that could influence the eventual implementation.
Let’s consider structured language. Böhm and Jacopini reasoned that programs have a sequence. Sequence means the statements are read from top to bottom with each statement following the previous one. Be careful here that you not inject arbitrary procedures into the specification, and that any sequence in the specification is necessary for policy reasons, not because the current implementation uses it.
In our example, all the available time cards must be processed. This means that the actions to process each of them must be repeated until all have been done. Hence, the first Böhm and Jacopini construct: repetition. Its general form looks like this:
That means you would write
For each TIME CARD
As you need to look at all the hours for each work category on one card, add
For each WORK CATEGORY
This second line is indented to show that it is subordinate to the first and also to make the specification more readable.
You were told that different work categories have different rates of pay. The data dictionary reveals that these rates are stored in the data store RATE. To look up the appropriate rate, use the general form
Find occurrence of the data corresponding to identifier
As you are using the category of work to locate the required entry in the RATE data store, you would write
Find the entry in RATE corresponding to WORK CATEGORY
Alternatively, a more relaxed version is
Find the entry in RATE with the same WORK CATEGORY
You may vary the verbs if you wish. Just be consistent so that your readers can understand your specification.
So far, our mini specification looks like this:
For each TIME CARD
For each WORK CATEGORY
Find the entry in RATE with the same WORK CATEGORY
Now you have to make some computations. These are usually written as an algebraic equation, thus:
LOADED RATE = HOURLY RATE multiplied by any present PENALTY LOADING
NORMAL $ AMOUNT = NORMAL HOURS WORKED times LOADED RATE
Some analysts prefer to use symbols such as “*” instead of “times” or “multiplied by,” and “/” rather than “divided by.” Thus,
NORMAL $ AMOUNT = NORMAL HOURS WORKED * LOADED RATE
The results of some of your calculations will be defined in the data dictionary as derivable or calculable data elements. If the algorithm for deriving a data element has been defined in the dictionary, your mini specification can reference the derivable element without having to repeat the algorithm.
Now you have to write a decision into your specification. This brings in the second Böhm and Jacopini construct: selection. The general form is
If this is true
Do this
Otherwise
Do this
To calculate the overtime, write
If the WORK CATEGORY is not 4, 5, 6
OVERTIME $ AMOUNT = OVERTIME HOURS WORKED * (HOURLY RATE * 1.5)
If the condition is not true, there is nothing to be done. (Never write meaningless lines like “Else do nothing.”)
Note that the user’s statement did not give any rules for calculating overtime. We assumed that overtime pays fifty percent more than normal, and we would need to go back to the user to confirm this rate. However, it is only when you try to write a mini specification that you discover this kind of shortfall in the requirements and can then get the missing information.
Writing this statement also triggers the question, “What happens if contractors submit overtime hours in category 4, 5, or 6? Are they paid at normal rates for all the hours they work? Or can I disregard any overtime in these categories?” Let’s suppose the user says that normal rates apply to all hours in any of these three categories. You could amend the above to read
If the WORK CATEGORY is not 4,5,6
NORMAL $ AMOUNT = NORMAL HOURS WORKED * LOADED RATE
OVERTIME $ AMOUNT = OVERTIME HOURS WORKED * (HOURLY RATE * 1.5)
Otherwise
NORMAL $ AMOUNT = (NORMAL HOURS WORKED
+ OVERTIME HOURS WORKED) * LOADED RATE
This assumes that category 4, 5, or 6 overtime is paid at the loaded rate. (Check with the user.) Now to use the product of your calculations
Accumulate TOTAL HOURS WORKED
Accumulate TOTAL $ AMOUNT
Again, the verb “accumulate” is rather informal, but the meaning is clear. With this, we finish specifying WORK CATEGORY. Some analysts like to write “End For” at this stage to indicate the end of the actions to be repeated. (We don’t because there is no need with indented subordinate clauses.)
The next statement applies to TIME CARD, and so its indentation must indicate that it is to be done after every WORK CATEGORY has been processed, but before a TIME CARD has been completed. The complete mini specification looks like this:
For each TIME CARD
For each WORK CATEGORY
Find the entry in RATE with the same WORK CATEGORY
LOADED RATE = HOURLY RATE multiplied by any present PENALTY LOADING
If the WORK CATEGORY is not 4, 5, 6
NORMAL $ AMOUNT = NORMAL HOURS WORKED * LOADED RATE
OVERTIME $ AMOUNT = OVERTIME HOURS WORKED * (HOURLY RATE * 1.5)
Otherwise
NORMAL $ AMOUNT = (NORMAL HOURS WORKED
+ OVERTIME HOURS WORKED) * LOADED RATE
Accumulate TOTAL HOURS WORKED
Accumulate TOTAL $ AMOUNT
Issue CONTRACTOR FAY SLIP
The verb “issue” means that all the necessary data for one CONTRACTOR PAY SLIP are gathered and sent along the data flow channel.
Some analysts prefer to number each line to further highlight subordinate lines. A numbered specification looks like this:
For each TIME CARD
1 For each WORK CATEGORY
1.1 Find the entry in RATE with the same WORK CATEGORY
1.2 LOADED RATE = HOURLY RATE multiplied by any present PENALTY
LOADING
1.3 If the WORK CATEGORY is not 4, 5, 6
NORMAL $ AMOUNT = NORMAL HOURS WORKED * LOADED RATE
OVERTIME $ AMOUNT = OVERTIME HOURS WORKED * (HOURLY RATE * 1.5)
Otherwise
NORMAL $ AMOUNT = (NORMAL HOURS WORKED
+ OVERTIME HOURS WORKED) * LOADED RATE
1.4 Accumulate TOTAL HOURS WORKED
1.5 Accumulate TOTAL $ AMOUNT
2 Issue CONTRACTOR FAY SLIP
While numbering adds some formality to the structure of the specification and makes the subordination clear, we’ve found that the majority of users prefer to read a “more English” or less mathematical version of the specification without numbers. Some users have stated their preferences in such strong terms that we had to relax the language to a point like this:
For each work category on each time card, the following has to be done
First, find the entry in rate with the same work category as the time
card
Second, calculate the loaded rate by multiplying the hourly rate by the
penalty loading if one is present
if the work category is not 4, 5, 6 (these categories do not attract
overtime)
Then the normal $ amount is equal to the hours worked multiplied
by the loaded rate
and the overtime rate is the hourly rate multiplied by 1.5
and the overtime $ amount is overtime hours worked multiplied by
overtime rate
Otherwise (this is for categories 4, 5, 6)
Add the normal hours worked and the overtime hours worked and
multiply that by the loaded rate
Accumulate the hours worked and the overtime hours worked into
total hours worked
Accumulate the $ amount and the overtime $ amount into total $
amount
When all that has been done for all the work categories on one time card, transfer the appropriate data items to the contractor pay slip and issue the contractor pay slip
This relaxed approach introduces a lot of redundancy, but its folksy manner may be helpful in some circumstances.
Recall that the mini specification is not intended to be procedural and should not influence any future implementation. Structured language infringes on this rule somewhat in that the statements must be written in some sort of order. For example, consider these two lines of the specification:
Accumulate total hours worked
Accumulate total $ amount
There is no reason why the hours have to be accumulated before the dollar amount; we just chose to write them that way. This case is quite innocent. Most reasonable implementors will realize that the order in which the two statements appear comes about by chance, and they won’t feel bound to implement them in that order. Of course, you could write
Do the following in any order
Accumulate TOTAL HOURS WORKED
Accumulate TOTAL $ AMOUNT
But this seems to be overkill when no harm is being done by the order of these statements. In some cases, implying a procedure could lead you into procedural thinking and thus divert you from analysis. There are less procedural ways of writing mini specifications, the most popular being the decision table.
Decision Tables
A decision table is used when the process makes decisions based on the answers to a variety of questions. Let’s take the same piece of policy you specified above, and build a decision table for it. When you have the two specifications to compare, consider which method better describes the policy of the process.
To begin, first look at the questions to be asked. The data dictionary shows
Rate = {Work Category + Hourly Rate
+ (Penalty Loading)}
So there is a question about whether or not PENALTY LOADING is present. The user’s statement told us, “Different work categories have different hourly rates of pay. Overtime worked under categories 4, 5, or 6 is not paid at overtime rates.”
This raises two more questions: Is the system processing hours in category 4, 5, or 6? Are overtime hours being worked? To start the decision table, write the questions
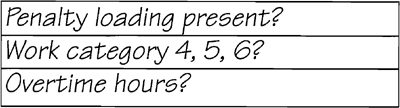
The table works by providing answers to combinations of these questions or, as they are referred to in decision tables, conditions. This means the table must contain an answer for every possible combination of conditions. Use this pattern to fill in the table: To discover how many combinations of conditions are possible, take the product of the number of possible values. In this case, each condition has 2 possible values. So the calculation is 2 * 2 * 2, which gives you 8 columns in your table. Now fill in the table to reflect each of the 8 combinations of conditions.

Note how this pattern is built. The top row begins by listing all possible answers to the question. In this case, there are only two: yes and no. Repeat this combination until you run out of columns in that row. The next row doubles the pattern: two yes’s and two no’s. This doubling continues until you reach the last row, which will always be half one answer, and half the other. (If there were three answers, the last row would be one third of each.) Note that sometimes the correct response to a question is don’t care. For instance, suppose the user had told you that even when contractors worked overtime for categories 4, 5, or 6, they submitted all their time as normal hours. Now the system can disregard the answer to the overtime question for those categories. Indifferent answers are shown as a dash. The table looks like this:

When the table is completed, it contains all combinations of possible answers to the questions. Now you must deal with the actions to be taken in response to the answers. Look at the data dictionary entry for the output:
Contractor Pay Slip = Contractor Id
+ {Work Category + Normal Hours Worked + Loaded Rate
+ $ Amount + Overtime Hours Worked + Overtime Rate
+ Overtime $ Amount}
+ Total Hours Worked + Total $ Amount
This entry says that you have to calculate the loaded rate of pay for each work category. The loaded rate varies depending on whether a penalty loading is present or not. You also have to determine if overtime is being worked, and to calculate the overtime pay. The total hours and total pay have to be accumulated.
Adding these answers to the table, you get
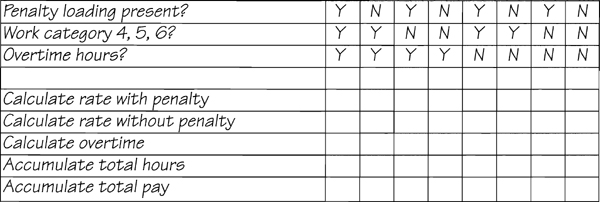
Now all that remains is to mark which combinations of answers provoke which actions. You can do this by going back over the user’s statement and consulting the data dictionary. Naturally, you would need to ask questions when the policy is not apparent. The final table looks like this:
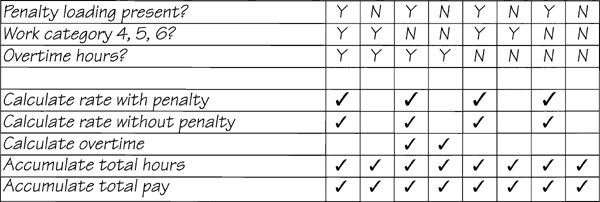
The algorithms for the calculations can be packaged with the decision table to complete this mini specification. Another alternative is to define the algorithms as calculable data elements in the data dictionary. For example,
Overtime = * Data element. Calculable. *
Overtime Hours Worked multiplied by Overtime Rate
This technique is particularly effective if the calculation is used in more than one mini specification.
To repeat, the decision table has the advantage over structured language of being nonprocedural. There is no reason why one question would be asked before another when it is obvious that all of them are going to be asked anyway. Nor is there any reason to think that one action would be taken before another. The table thus solves one problem, but raises another. Some users don’t like decision tables. They can be seen as unfriendly, “technical” specifications. To retain the decision logic and yet make the specification more friendly, try a decision tree.
Decision Trees
A decision tree does the same job as tables, and some people find them easier to read. We leave it to you to decide. The decision tree for paying the contractors is shown in Figure 2.12.4.
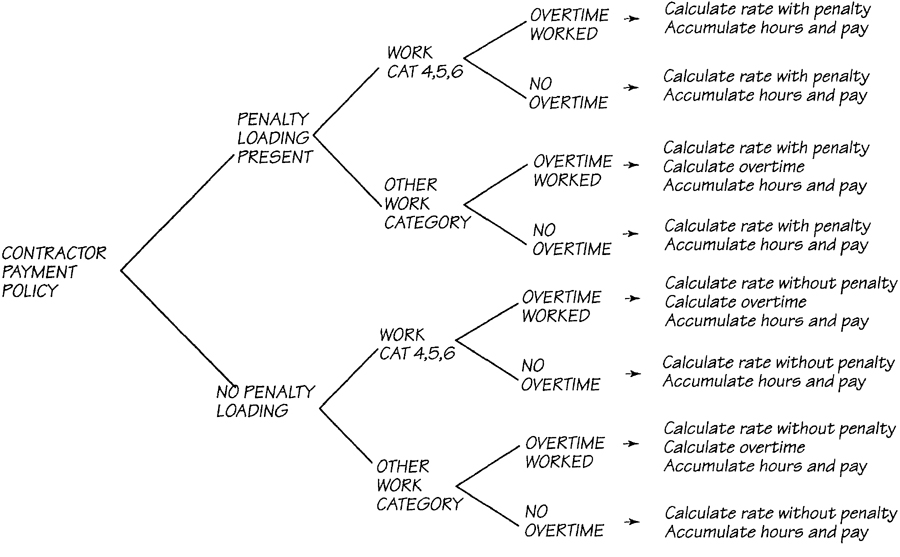
Specifying Judgmental Bubbles
A judgmental bubble is one with a process that does not appear to be definable. Although bubbles that make judgments are rare, you have to know what to do about them when you find one. Such bubbles are annotated with shading down the sides.
The process shown in Figure 2.12.5 is entirely subjective: “This vun I like,” “This vun no fun at all,” and so on. For truly subjective processes, the mini specification should state as many as possible of the criteria for making the decisions, and leave it at that. Later, when you start thinking about the implementation, the shading will highlight the processes that cannot be automated because they cannot be specified.
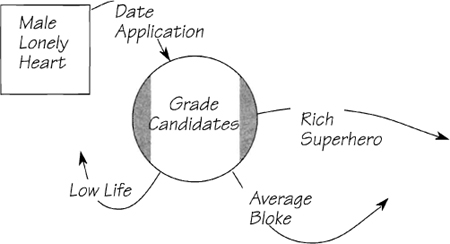
Figure 2.12.5: An example of a judgmental process from Miss Tweedy’s Dating Service. Zsa Zsa makes a decision on what kind of male is applying for a date.
Be forewarned: Many of the seemingly judgmental processes are not subjective at all. There are well-defined rules; they just can’t be seen, as when you hear, “I don’t know how I do it. I’ve been doing it for so many years.” You must investigate further to find the underlying policy for the process. Ask for all the information used by the process, ask for any existing written documentation about the process, and try to define all the algorithms, rules, guidelines, rules of thumb, telephone calls, and notes on the back of envelopes that you can find. The object of the exercise is to determine if the process is really a judgmental one, or if the process is a regular process just enveloped by the users’ mystique and can be specified by one of the regular specification methods.
Specifying Data Storage and Retrieval
Any system has many processes that manipulate essential stored data, so it is appropriate to discuss how to write mini specifications for them. We’ll use the data model in Figure 2.12.6 for our examples. Remember: An entity in a data model represents all the occurrences of that entity, and we show the entity as a data store in the process model.

In Figure 2.12.7, a process searches its data store, BOOK, to match the incoming enquiry data flow. The structured language form for this is
Retrieve the occurrence of BOOK corresponding to BOOK TITLE in BOOK ENQUIRY
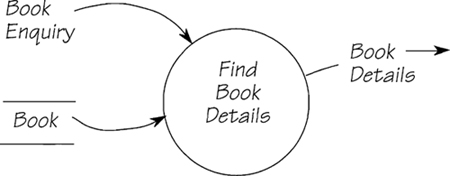
Keep in mind that you are not writing a computer program, and the data model is not a database. You are simply stating the requirement for this process to be able to access the stored data and to retrieve a particular book.
To specify the process shown in Figure 2.12.8, write the following:
Find the AUTHOR with the corresponding AUTHOR NAME
Retrieve all associated occurrences of BOOK
Issue BOOK LIST
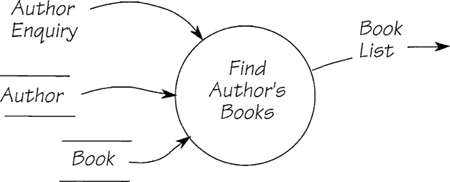
Figure 2.12.8: This process uses two entities: AUTHOR and BOOK. The AUTHOR ENQUIRY supplies the name of an AUTHOR, and the process lists every BOOK written by that AUTHOR.
The word “associated” refers to those entities sharing a relationship with the first one. Association can refer to entities several relationships away from the original. Take, for example, the process shown in Figure 2.12.9. The mini specification reads
Find PUBLISHER with the corresponding PUBLISHER NAME
Retrieve all associated occurrences of AUTHOR
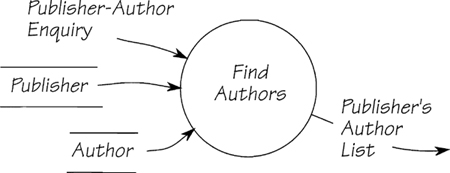
Figure 2.12.9: In this event-response, the task is to find all the authors that have written books for a designated publisher.
In Figure 2.12.9, the entities PUBLISHER and AUTHOR are separated by two relationships and an entity. If you look at the data model in Figure 2.12.6, you can see that it is necessary to access the entity BOOK to navigate the data model. However, there is no data in this entity and its relationships that are used by the essential process, so by convention we omit them from the process model to avoid unnecessary clutter.
Note that the cardinality in the data model must allow the necessary navigation. In this case, for any one publisher, the model allows the process to locate all the instances of book, and from each of those, all the authors. Sometimes, the entities are connected by more than one relationship. In these more unusual cases, you’ll need to specify the relationships in the access path that interests you.
Now to store some data. Figure 2.12.10 shows a process that stores a book and its author. For the purposes of this example, assume that the publisher entity already exists in the system’s stored data. (Another event will have previously stored it.)
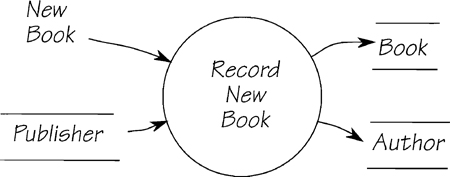
The incoming data flow NEW BOOK contains the book details and the author’s name. The mini specification looks like this:
Find the corresponding PUBLISHER
Establish an occurrence of BOOK and create a PUBLISHING relationship with
PUBLISHER
If the corresponding AUTHOR does not exist
Establish an occurrence
Create a WRITING relationship between AUTHOR and BOOK
Note that relationships are not shown in the process models unless they contain data that are stored or used by the process. Otherwise, the relationship is well enough specified by the data model. This minimalist approach is possible because the specification of every event-response is composed of an event-response process model and an event-response data model.
Summary
When you decompose high-level bubbles to their functionally primitive level, you unearth the real processes of the system. A mini specification is written to describe each of these real processes. Its role is to describe what a process does to transform the incoming data flows and stores into outgoing data. The mini specification can take many forms depending on the policy being specified; some policies are best described in a natural language, some cry out for a decision table or a decision tree, and others can be described simply by showing the stored data affected by the process.
Mini specifications are normally written when the essential event-response models are built. If you specify the processes in a physical model, the chances are that you’ll waste valuable time and effort specifying implementation-dependent processes.
Enough talk. Let’s do some work.
Exercise 1: Hopper’s Choppers
Larry Hopper runs a small helicopter service in the American Samoan Islands. The service ferries tourists, citizens of the islands, and employees of Hopper’s Choppers from island to island. Larry has a scale of fares, each fare offering different levels of priority. He has also established some rules for booking passengers onto the helicopters. Larry has asked his daughter, Grace, to analyze his business system with the goal of improving service. One of her event-response models appears in Figure 2.12.11. The data store HELICOPTER BOOKINGS is modeled in Figure 2.12.12.
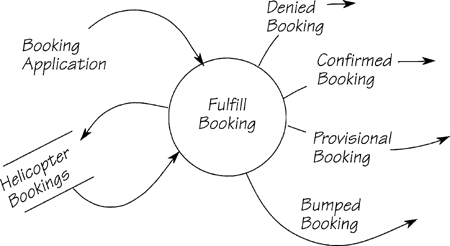
Figure 2.12.11: The event-response models for Passenger wants to make a booking from the Hopper’s Choppers system.
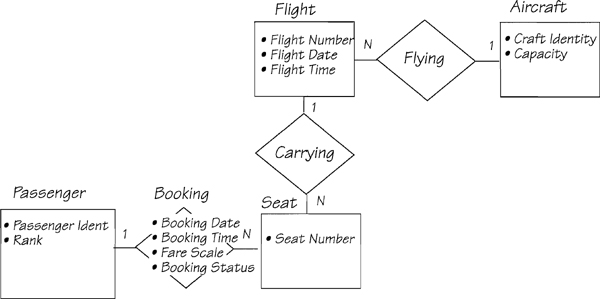
Booking Application = Passenger Ident + Flight Date + Flight Time
+ Number Of Seats Required + Fare Scale + Rank
Booking Statue = [ "Provisional" | "Confirmed" ]
Bumped Booking = Passenger Ident + Flight Date + Flight Time
Confirmed Booking = Passenger Ident + Flight Date + Flight Time
+ Booking Statue
Denied Booking = Flight Date + Flight Time
Fare Scale = [ "Full Fare" | "Economy" ]
Provisional Booking = Passenger Ident + Flight Date + Flight Time
+ Booking Status
Rank = [ "Civilian" | "Emergency Employee" | "Employee" ]
Here are Larry’s rules: “Anyone who pays the full fare gets a confirmed booking if a seat is available. We bump provisional bookings if someone wants to pay full fare. People use provisional bookings because the fare is cheaper, and most of the time they don’t get bumped.
“Employees fly free, so they don’t get any priority except when there is some emergency and we have to get an employee to the problem fast. Then we will bump anybody to get the employee on a flight. We would only ever have one emergency employee per flight.
“The rules for bumping are simple: Cheap fares go first, the latest bookings go before the oldest.”
Write a mini specification for the process FULFILL BOOKING.
Exercise 2: Terry’s Ski Tuning Service
Ski tuning is the craft of repairing skis: filing the base, sharpening the edges, and removing all the nicks caused by skiing over rocks or other people’s skis. Terry’s Ski Tuning does an excellent job of making skis perform like new, but the part of the business that pays Terry is in real need of your help.
Write a mini specification for the process CALCULATE SKI TUNING BILL shown in Figure 2.12.13. You’ll need to know that Terry and Joel are the master technicians, and that any service they perform is loaded by 15 percent. Services performed during the day attract a $20 surcharge. (The normal service is overnight, and Terry has to get someone to come in specially for any daytime work.) Tuesday and Wednesday nights are slow, so Terry offers a 20 percent discount for any work done on those nights.
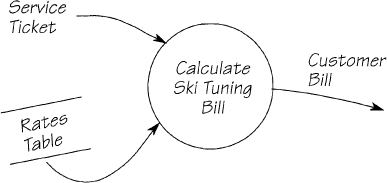
An incomplete but sufficient data dictionary is
Service Ticket = Technician + Day Of Week + Time Of Day
+ {Service Performed}
Rates Table = {Service Name + Service Rate}
Customer Bill = Service Ticket + Total Charge
Time Of Day = * Data element *
["Day" | "Night"]
Trail Guide
![]() Easiest: Now it’s time to return to the Piccadilly Project to specify some of the processes that you have identified. Your destination is Chapter 1.11 Writing Mini Specifications.
Easiest: Now it’s time to return to the Piccadilly Project to specify some of the processes that you have identified. Your destination is Chapter 1.11 Writing Mini Specifications.
![]() More Difficult and
More Difficult and ![]() Most Difficult: This chapter was not part of your trail, but there is no penalty for reading it. Your Project work resumes in Chapter 1.11 Writing Mini Specifications.
Most Difficult: This chapter was not part of your trail, but there is no penalty for reading it. Your Project work resumes in Chapter 1.11 Writing Mini Specifications.
![]() Promenade: You now know how to specify the requirements for a system. But there are other requirements that you’ll meet in Chapter 2.13 Modeling New Requirements.
Promenade: You now know how to specify the requirements for a system. But there are other requirements that you’ll meet in Chapter 2.13 Modeling New Requirements.