
4.2. Solutions: Data Flow Diagrams
Exercise 1: Nelson Buzzcott’s Employment Agency
a) What is the most probable data content of MATCHED APPLICATION?
The best way to answer this question is to ask your users. If they are not available, imagine that you are the process receiving the data flow. Now, what data do you need to do your job?
You have to interact with CLIENTS and APPLICANTS, so you can reasonably expect the incoming data flow to deliver an identifier and telephone number for each of these. If the interview is arranged by mail (unlikely), you’d want a postal address. You’d also like to know what job you are talking about, so the flow must contain an identifier and description of the job.
We haven’t yet discussed the topic of the data dictionary, but here is the definition in data dictionary format:
Matched Application = Client Identifier + Client Telephone + Job Identifier
+ Job Description + Applicant Identifier + Applicant Telephone
The reason that we asked you this question is that the data drive the processes. If you do not know the content of a flow, you cannot understand the process that receives that flow. We will talk much more about data in coming chapters because the role of data is so critical to the system.
b) What kind of information would you find in JOB REGISTER?
Typically, we’d find a number of jobs, each one having some kind of identifier, a description of the job, the salary being offered, an identifier, and telephone (and possibly address) of the client.
Our answer is partly from speculation, and partly from deductions made by looking at the model. Most of the data in MATCHED APPLICATION must come from the JOB REGISTER: If we know one, we will know the other. The next step is to take our preliminary definition to the users and ask them to confirm or amend it. Naturally, if the users have a job register in use at the moment, we would also want to look at that.
c) Which is processed first: process 1 FIND SUITABLE APPLICANTS, or process 2 REGISTER APPLICANT?
This was something of a trick question, as there is no “first.” The data flow diagram does not show any sequence for the processes. It does show the data produced by each process and the dependencies between processes, and from this you could work out a sequence if you wanted. But it really doesn’t matter. A process is active whenever it has some data to process. Both of the bubbles mentioned are triggered by data flows from the outside world, so it is impossible to predict when the flow will arrive. For all you know (or care), processes 1 and 2 could be active at the same time. Probably the best answer to this question is it doesn’t matter because the data flow diagram models asynchronous processes.
d) Why isn’t CLIENTS shown as a bubble?
CLIENTS isn’t a process that we’re studying. CLIENTS is a shorthand notation for the clients’ systems. These systems have processes, but we are not interested in them. When we defined the context, we decided that the internal workings of the clients’ systems were beyond the scope of our study.
e) What happens to the dataflow UNFILLED JOB? Why?
UNFILLED JOB carries the details of a new job for which there are no applicants on file. This file is recorded in the data store JOB REGISTER, where it awaits a match to a new applicant. Its data content is the same as one of the entries in JOB REGISTER.
f) How do we know that a job has been filled?
The current model doesn’t show any way of recording that a job has been filled, so the model is incomplete. You must now raise this question with your users and find out how they record filled jobs. Note here the success (not failure) of the model. By demonstrating an inconsistency, it has helped you to raise a necessary question. By raising it, you are nearing your goal of finding all the requirements for the system.
Exercise 2: The FastBuck Book Company
You were asked to list the errors you found in the model of the FastBuck Book Company (Figure 2.2.15).
Process 1 PROCESS ORDER doesn’t appear to do anything. This is a very poor name for a bubble, and its vagueness suggests that the analyst is rather unsure about just exactly what is happening. The solution to this problem is to write a coherent description of the bubble. If you cannot, then you should de-bubble it.
There is no rejection flow from this bubble, but recall we were told that it rejects orders without payment.
Process 2 GENERATE BOOK has no output. All functions must produce something. In this case, a BOOK would be the most likely output.
Both the data stores being accessed by this function are read-only. There is no source of input. This suggests an everlasting fountain of data, which needs no maintenance and has no data added to it. Read-only or write-only data stores must be investigated further (as should the dealings of the FastBuck Book Company, but that’s a job for someone else).
SEND PHONY INVOICE TO REPEAT CUSTOMER has no way of knowing that the incoming order is to a repeat customer. To know this, the system needs access to a data store of previous orders.
The data flow PHONY INVOICE should flow to the CUSTOMER terminator. We redrew this model (Figure 4.2.1) to show what we think Benedict should have produced.

In this model, note that we have added an ORDERS FILE so that the process CHECK ORDER can tell whether an incoming order is a repeat order from a customer. The process also stores all orders.
Both the data stores in the previous model were read-only. Process 5 puts material into the SUPPLY OF COVERS store. We are guessing that the book covers come from a printer. Since we are even less sure where the generic books come from and since the people who run this company are very tight-lipped on this one, we have left it as a question mark.
The last paragraph was a joke, but the point of it is that when you are unsure of something, the best approach is always to put down your best guess. Put a large question mark beside it to indicate that you are guessing, and to remind yourself to ask the users.
The question mark beside process 6 is there because we don’t know if the company wants us to study this part of the operation. It also looks suspicious because the way we have drawn it, the company appears only to advertise “books” it has in stock. We think this company is not above advertising books that it does not have.
Exercise 3: The Government Research Paper Clearing House
There is no right answer to this exercise, for there can be no right context diagram until you talk to the users and all the other people who have an interest in the system. We cannot transport you to the Clearing House, but we can give you some alternatives, and some observations.
The first alternative, shown in Figure 4.2.2, represents the most rational approach. It includes all the functionality mentioned in the problem statement.

First, some technical observations: All of the data flows in your diagram should be named, and the names recognizable to the system users. The name of each terminator should reflect its role. From a mechanical point of view, context diagrams are reasonably simple. However, before proceeding, take time to ensure that all the notation on your diagram is correct.
The ADVICE OF NEW R&D flow was not specifically mentioned, but the Clearing House must have some way of knowing what papers are available for requests. The other flows in the diagram are referenced in the problem statement.
You were given details of the processing done by the Clearing House, but for the moment you hide these details inside the context bubble. Later you can break them out; the task here is to define the scope of the problem.
You may well have come up with a different solution to that given in Figure 4.2.2. For example, you were told that the Accounting Office handles the invoicing. Although you may feel it wise to study the way that the office produces the invoices, doing so implies that the Clearing House also must look after the receipt of payments, as well as the dunning of customers who fail to pay on time. In this case, you’ll have to add data flows such as PAYMENT and DUNNING LETTER to the context diagram. Alternatively, the Accounting Office may have no desire for you to study this part of its activities, in which case you must show the ACCOUNTING OFFICE as a terminator. As all the accounting activity will take place inside this terminator, there can be no INVOICE flow from the context to the CITIZENS terminator, but there must be a flow to advise the ACCOUNTING OFFICE of the charges. Figure 4.2.3 shows this arrangement.
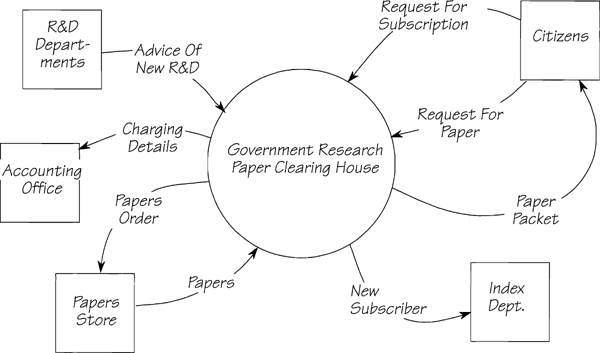
Figure 4.2.3: An alternative context diagram. The Accounting Office and Index Department are now outside the scope of the study, along with the Papers Store.
The Index Department may also be outside the scope of your study. The two women who run it are adamant that you are not to study their activities, and that their efficiency awards mean that the job is being done as well as possible, and that there is no reason to try to improve it. This decision does mean that the subscribers’ list is maintained in two places; the Clearing House has to keep an up-to-date list and advise the Index Department of new subscribers to update its list. Now you can remove the indexes from your diagram, because the Index Department sends the index packet directly to the citizen. Note that it is incorrect to show a data flow between terminators.
As we said, there is no one right answer, but either of these diagrams gives you a starting point to raise questions with the users. Take a moment to reconcile the data flows in our diagram with yours.
When you are satisfied with your grasp of the drawing conventions, and with your answer versus the alternatives presented here, it’s time for some more work.
![]() Easiest: Now that you know about data flow diagrams, go to Chapter 1.2 Start with the Context, where you will build a context diagram for the Piccadilly Project.
Easiest: Now that you know about data flow diagrams, go to Chapter 1.2 Start with the Context, where you will build a context diagram for the Piccadilly Project.
![]() More Difficult: If you made it here, perhaps you should be following the
More Difficult: If you made it here, perhaps you should be following the ![]() Easiest Trail. If you have not already built the Piccadilly context diagram in Chapter 1.2 Start with the Context, that is your destination. Otherwise, go to Chapter 2.3 A Variety of Viewpoints.
Easiest Trail. If you have not already built the Piccadilly context diagram in Chapter 1.2 Start with the Context, that is your destination. Otherwise, go to Chapter 2.3 A Variety of Viewpoints.
![]() Most Difficult: Any chapter number beginning with a “4” is not part of your trail. Try picking up your trail in Chapter 1.2 Start with the Context.
Most Difficult: Any chapter number beginning with a “4” is not part of your trail. Try picking up your trail in Chapter 1.2 Start with the Context.
![]() Promenade: The purpose of data flow diagrams is to model the processes, and the flows of data between the processes. The data in a system are just as important as the processes, so the next logical step for you is to learn about the data. Jump to Chapter 2.9 Data Dictionary. Don’t worry about the chapters you pass over to get there. Eventually, you will return to learn about the models in those chapters.
Promenade: The purpose of data flow diagrams is to model the processes, and the flows of data between the processes. The data in a system are just as important as the processes, so the next logical step for you is to learn about the data. Jump to Chapter 2.9 Data Dictionary. Don’t worry about the chapters you pass over to get there. Eventually, you will return to learn about the models in those chapters.