
2.15. Object-Oriented Viewpoint
Before You Reached Here ...
Regardless of your trail, ![]()
![]()
![]() or
or ![]() , you have read about the implementation of the new system in Chapter 1.17 Piccadilly’s New Environment, and you have arrived here because you decided to follow the optional fork in the trail. First let’s review why you should read this chapter. Object-oriented programming languages represent a fundamental change from third- and fourth-generation languages, and their proponents speak of revolutionary ways to build and maintain systems. As the popularity of object orientation is growing and we believe will continue to grow, it is important for you, a systems developer, to understand how it affects your job.
, you have read about the implementation of the new system in Chapter 1.17 Piccadilly’s New Environment, and you have arrived here because you decided to follow the optional fork in the trail. First let’s review why you should read this chapter. Object-oriented programming languages represent a fundamental change from third- and fourth-generation languages, and their proponents speak of revolutionary ways to build and maintain systems. As the popularity of object orientation is growing and we believe will continue to grow, it is important for you, a systems developer, to understand how it affects your job.
What Is Object Orientation?
Traditionally, systems have kept their data and their processes separate. This separation began with the first programming languages in the 1940s. The metaphor that language designers had in mind was the clerk or mathematician, whom the computer was intended to replace. They viewed a computer program as the equivalent of a set of instructions that could be given to a person. People kept their data in filing cabinets or books, retrieving the information when needed. So, too, the early programming language designers had the computer keep their data in files separate from the processes inside the computer.
The object paradigm changes this tradition by encapsulating items of data along with the processes that operate on that data. This encapsulation is called an object. To illustrate, let’s think of an object from the Piccadilly Project. Suppose you have an object called SALES EXECUTIVE, which is an abstraction of everything you know about a sales executive: the data that describes the sales executive (the attributes), together with the processes that manipulate the sales executive’s data, are packaged together in this object (see Figure 2.15.1).

Figure 2.15.1: The SALES EXECUTIVE object is an encapsulation of everything that we know about the object.
Encapsulating the data and processes means that the object is able to function as a self-contained unit, very much like the real-world sales executive. The details of how it performs its services are hidden from any other object, although what services it offers to other objects are known. Again, this approximates the behavior of the sales executives as you would see them in their natural state. For every sales executive employed by Piccadilly, an object-oriented system would have an instance of the SALES EXECUTIVE object. Each one is an encapsulation of its own data (sometimes called “state”), and its own process (also called “behavior”).
Other objects can send messages to the SALES EXECUTIVE object requesting it to perform one of its services. Suppose that an ADVERTISING AGENCY object wants a sales executive’s name. Such data are private, being hidden from every object except the SALES EXECUTIVE object. How does the ADVERTISING AGENCY object get what it needs? It sends a message to the SALES EXECUTIVE object, requesting the SALES EXECUTIVE object to carry out its REFERENCE EXECUTIVE NAME process and to return the EXECUTIVE NAME to the ADVERTISING AGENCY object (Figure 2.15.2).

Figure 2.15.2: The ADVERTISING AGENCY object sends a message, REFERENCE EXECUTIVE NAME, to the SALES EXECUTIVE object, which responds by carrying out its private process REFERENCE EXECUTIVE NAME.
In order to perform one of its processes, it might have to send messages to other objects, which might in turn send messages to other objects, and so on, until all of the messages have been resolved. Suppose that another object sends a SUMMARIZE CAMPAIGN message to an ADVERTISING AGENCY object, which has a process called SUMMARIZE CAMPAIGN. It responds to the message by activating that process. Now further suppose that the SUMMARIZE CAMPAIGN process needs to know the average predicted television ratings for the period of the campaign. To get these ratings, the ADVERTISING AGENCY object sends another message, CALCULATE AVERAGE RATINGS, to a PREDICTED RATING object. Figure 2.15.3 illustrates the messages flowing between objects.

If you continued with this example, you would discover that the PREDICTED RATING object and the SALES EXECUTIVE object in turn send messages to other objects. Even with this small example, you can get an inkling of the possible complexity of message flows. Now you can see that it is simplest to think of an object-oriented system as a network, made up of encapsulations of process and data, sending messages to each other.
Classes
Objects mimic their real-world counterparts by being uniquely identifiable. For instance, each SALES EXECUTIVE working for Piccadilly has a unique value for SALES EXECUTIVE NAME. However, even though each SALES EXECUTIVE object has a different value for SALES EXECUTIVE NAME, every instance of SALES EXECUTIVE object has a SALES EXECUTIVE NAME. So we can say that sales executives share the characteristic of having a sales executive name, and this leads to the concept that individual objects with the same characteristics can be categorized into classes.
The SALES EXECUTIVE class is a generalization of the data and processes that are common to all sales executives. For example, the SALES EXECUTIVE class knows that every SALES EXECUTIVE object must have a piece of data called SALES EXECUTIVE NAME. For every sales executive employed by Piccadilly, the object-oriented system holds an instance of the SALES EXECUTIVE object. Every new SALES EXECUTIVE object that is added to the system is cloned from the SALES EXECUTIVE class. The class acts as a template to ensure that the new object contains all the data and processes appropriate to an instance of that class.
Let’s extend the concept of classes a little further. Another class, MANAGER, has some characteristics in common with the SALES EXECUTIVE class. For instance, both classes need a name, address, employee number, and so on, together with the processes necessary to manipulate those data. Because there are data and processes common to both classes, we can create a more abstract class for the common characteristics. The manager and the executive are both employees of the company, so we can have a more abstract class called EMPLOYEE. We can factor out the common data and processes and assign them to this new super class. We can arrange the manager class and the employee class into a class hierarchy. This example is shown in Figure 2.15.4.
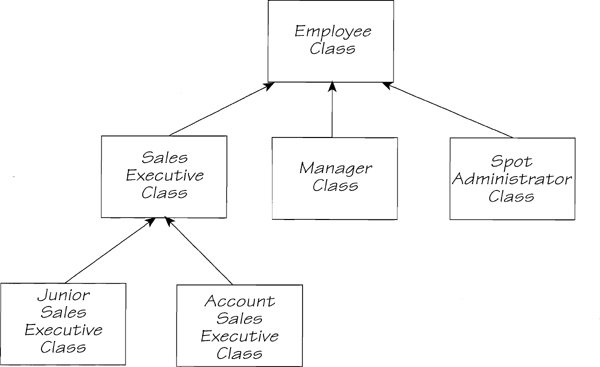
Figure 2.15.4: A class hierarchy. The classes toward the top are more abstract, while the lower ones are more specific.
The EMPLOYEE class holds the characteristics common to all employees. The MANAGER and the SALES EXECUTIVE classes have characteristics that are unique to their specialized roles in the company.
The advantage of arranging the classes into a hierarchy is that any class can inherit the data and process of the classes that are above them in the hierarchy. For example, Figure 2.15.4 shows two subclasses of SALES EXECUTIVE. The junior sales executive has a specialized role, and requires its own unique data and process. However, it also has to have all the properties of a SALES EXECUTIVE, so it inherits them from above. For example, suppose that a JUNIOR SALES EXECUTIVE object receives a message REFERENCE EMPLOYEE NUMBER. The JUNIOR SALES EXECUTIVE doesn’t have such a process. So JUNIOR SALES EXECUTIVE simply asks upstairs. Since the SALES EXECUTIVE class doesn’t have this process either, it in turn asks above it. The EMPLOYEE class has the required process, and so JUNIOR SALES EXECUTIVE can make use of it.
The benefit of inheritance is that once you have assigned a process or data to the correct class, either can be reused by any class below it in the inheritance. Thus, you avoid repeated implementation of the same data and process. Do it once, and reuse it.
Now suppose your system needs another type of EMPLOYEE, a spot administrator. You can extend the class hierarchy to include the new class. It has its own unique characteristics, such as an authority rating for preempting commercial spots. The class inherits everything else it needs from the EMPLOYEE class above it. Therefore, new classes, provided they are correctly located in the hierarchy, can be added with the minimum of new characteristics.
It is this notion of extension that gives the object approach a significant advantage. The existing classes are stored in a class hierarchy, which acts somewhat like a library for future programmers to make use of whatever they find. Object-oriented designers start their work by browsing the class hierarchy, looking for classes that can be used as they are, or ones that can be extended to satisfy the needs of a new application.
As the hierarchy is based on the data used by the system, it tends to be more stable and provide more reusability than libraries of reusable code modules that are based on functionality alone. Should Piccadilly decide to build a system for the Personnel Department, for instance, the developers can reuse the EMPLOYEE, SALES EXECUTIVE, MANAGER, and SPOT ADMINISTRATOR classes that you discovered when analyzing the Piccadilly Airtime Sales system.
The classes we have discussed here are application classes: They all are related to the essential subject matter of the business. An object-oriented design environment also provides you with many environmental classes: classes relating to the physical side of the business, like window, button, pointer, menu, table, line, page, counter, and so on. The job of an object-oriented designer is to assemble a system making optimum use of the application and environmental classes that already exist. When a class does not exist and cannot be bought, the designer writes a new class and adds it to the hierarchy. This new class becomes available for future systems development.
Relating Analysis to Object-Oriented Systems
As we’ve said, the object-oriented design strategy is quite different from traditional methods. But what about the analysis of object-oriented systems? To answer this question, we can look to the history of systems analysis.
To repeat, systems analysts have traditionally separated the modeling of process and the modeling of data. These two activities were seen, if not exactly as natural enemies, at best as distant relatives who didn’t speak to each other but only met at funerals. Early structured analysts considered (wrongly) that process analysis could be independent of data analysis, and the data analysts believed (again wrongly) that process was something so inconsequential it could be left for the programmers to invent as they chose.
The chasm between the two disciplines was narrowed by McMenamin and Palmer’s essential analysis approach, and by the growing awareness of the adherents of Chen’s and Flavin’s entity-relationship approach that process was important, too. (All three of these references can be found in the Bibliography.) Since our course “Modern Structured Analysis” was first offered in 1984, we have emphasized the importance of both data and process by teaching both types of model. Indeed, the exercises in this book give you first-hand experience of modeling each event response using both process and data models, so that you can see the strong link between the system’s process and data and thereby gain a complete and rigorous understanding of the system.
Consider the context diagram that you built at the beginning of the Piccadilly Project. The incoming boundary data flows deliver all of the data to be used or stored by the system. These flows are the source of the objects; they provide the raw data that you formed into entities in the data model (Figure 2.15.5).

Figure 2.15.5: The system’s context. The incoming data flows deliver all the data to the system. You can determine the entities and relationships from the boundary data flows.
What is the difference between the entities in the data model and the classes in an object-oriented system? Very little, once you have collected the processes necessary to complete the encapsulation. Identifying the entities is the first step in discovering the classes for an object-oriented implementation.
Next, let’s see how the analysis of processes differs in an object-oriented system. In the Piccadilly Project, you used a combination of current physical modeling and event-response modeling to collect the system’s processes (see Figure 2.15.6).

Once the event-responses have been modeled, they can be assembled around the entities that they access to make the classes. In other words, the entity becomes the anchor for various event-responses. For instance, using the event model in Figure 2.15.6 as an example, EXECUTIVE NAME is an attribute of the SALES EXECUTIVE entity. It becomes one of the data items belonging to the SALES EXECUTIVE class. Along with that, all the process fragments that use the EXECUTIVE NAME (CREATE A NEW SALES EXECUTIVE, CHANGE THE NAME IF SHE MARRIES, DISPLAY THE NAME, and so on) would become part of the SALES EXECUTIVE class. Meanwhile, other data and process fragments, such as AGENCY NAME and AGENCY CREATE, have nothing to do with our SALES EXECUTIVE, so they would be attributed to another class, probably called ADVERTISING AGENCY. In order to trigger the event-response in an object-oriented environment, you would design the message flow between the ADVERTISING AGENCY and SALES EXECUTIVE objects that are concerned with the event.
Analysis in an Object-Oriented Environment
You can start your analysis by identifying classes. This is similar to the strategy you used when you built a high-level or first-cut system data model very early in the Piccadilly Project. The question to ask is whether the classes that you discover are relevant to the problem that you are analyzing. This leads to the need for setting your context so that you can verify that a given class or entity type is relevant within the context of your project. This does not mean just verifying that the name of the class is relevant. You need to prove the relevancy of each fragment of data and process. The way to keep control of your analysis is to use a strategy that you are already familiar with: event partitioning.
As you have seen in the Piccadilly Project, your system is made up of a number of small systems, each of which is represented by an event. Event partitioning helps you identify the classes that you already have, identify the classes that you need to build, and design the message flows necessary to support the requirements within your context. Figure 2.15.7 summarizes the strategy to use if you are doing analysis in an object-oriented environment.
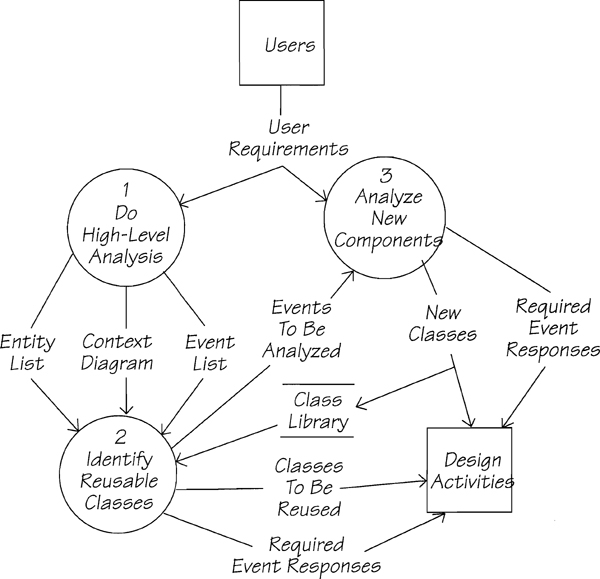
When you do the high-level analysis (process 1), you use the strategy you have been practicing in this book to set the context, make a list of potential entity types, and build an event list. Then you map the results of your high-level analysis to identify existing classes that can be reused to satisfy the requirements of the system within your context (process 2). The events or partial events that are not provided by the existing class library are analyzed in detail (process 3), new classes are added to the class library, and the required event-responses are the input for designing the message flow for each event. By using event partitioning, you have the freedom to iteratively analyze, design, and implement parts of the system while retaining control of your work.
Use of the approach that we recommend here will protect you from a number of dangers. First, if you risk doing analysis without defining your context using boundary data flows, you’ll certainly have a problem building a relevant and complete system. In our experience, the lack of a well-defined context is the most common reason for project failure.
The second problem area is the essential view. Your analysis technique must allow you to clearly differentiate between the essential requirements (represented by application classes) and the implementation constraints (environmental classes). Without this separation of views, you will perpetuate all of the long-term problems associated with systems that are difficult to understand and maintain.
The third and perhaps the worst problem is the fragmentation of information. Remember that a class is the encapsulation of data and the attendant processes. Now recall the example of the SALES EXECUTIVE class. This class is referred to by events that are the concern of both the Sales Department and the Personnel Department, each department being interested in sales executives for different reasons. They both process data about the executive, but they are probably unaware of the other’s processes. In other words, the processing for a single piece of data is distributed. There is no natural encapsulation of data and process, so it’s difficult for an analyst to find complete and relevant classes without having some way of controlling the analysis. Our approach to analysis provides you with the control and flexibility that you need.
Object-Oriented Systems Development
To map your essential requirements into an object-oriented environment, you group each entity and some of the relationships in the data model into a class. The fragments of processing from the event-response process models are allotted to a class according to the data that the process uses. The derivation of classes and objects can be organized by applying templates that are tailored to your own environment (see Figure 2.15.8). Templates are a way to make use of the repetitive nature of many design situations. Each template typically is a set of rules that help you to recognize characteristics of entities and to translate them into a design for the class. (Our partner John Palmer and we have developed a collection of analysis to object-oriented design templates as the subject of our workshop “Object-Oriented Design: The Essential Strategy.”
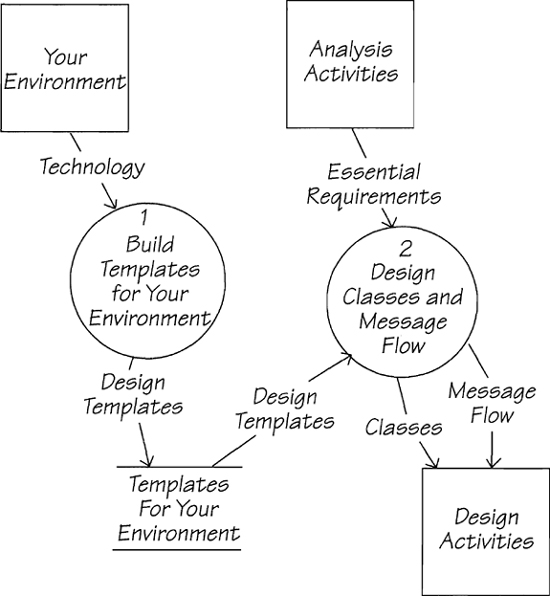
Figure 2.15.8: Templates specific to the system environment are used to derive classes and message flow from the essential requirements specification.
While we are on the subject of design, let’s step back to look at how design for an object-oriented environment relates to design for other environments. A design path is the name for the kind of design that must be done before the system is built. A developer’s design paths are determined by the types of technology within the system environment. For example, if the environment contains a number of people with different skills and an object-oriented programming language, the designer must take both the organizational design path and the object-oriented design path. In other words, the design technique varies according to whatever is being designed. However, no matter which or how many design paths are taken, the designs must be coordinated and connected before the new system can work.
In this chapter, we have discussed how essential requirements relate to object-oriented systems. As shown in Figure 2.15.9, the essential requirements, developed according to the strategy you have been using in this book, provide a complete and precise requirements specification to design using any combination of technologies.
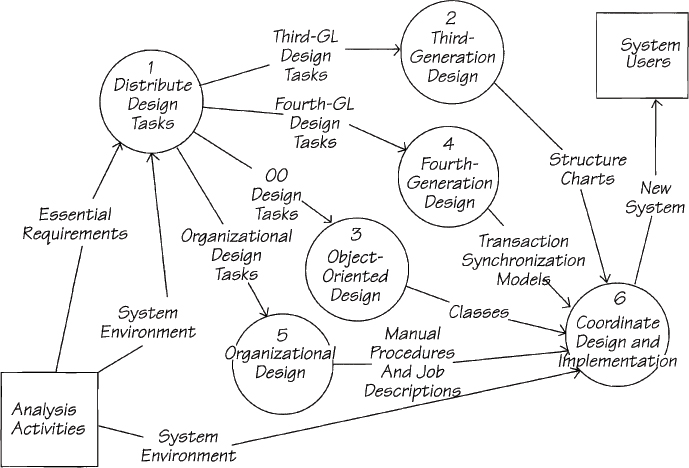
Figure 2.15.9: Note that the analysis is the same regardless of the implementation, whereas the design path differs according to the types of technology within the system environment.
Summary
The overwhelming advantage of object orientation is reuse, hence increasing the speed of building and changing systems. The object, a logical encapsulation of data and process, provides a well-specified component that could be reused in other systems interested in the same subject matter. This chapter is mainly concerned with discussing the object-oriented paradigm and illustrating how our approach to analysis maps with that paradigm.
We’ve not attempted to treat the object view in great detail. There are several good books on the subject, and we can’t do justice to this important subject in a single chapter. As the analysis thinking for object-oriented systems is the same as for any other kind of implementation, we chose to concentrate in this book on analysis and refer you to the Bibliography for more object-oriented reading (see Booch, Jacobson, Rumbaugh et al., and Shlaer and Mellor).