
3.2. Review: What About the Business Data?
Looking for Potential Entities
We gave you a rule of thumb that says when you have a description of the business, look for nouns to indicate potential entities. Let’s apply it to part of “The Story of Piccadilly Television” from Chapter 1.2 Start with the Context.
“The advertising agencies buy commercial spots that make up campaigns to advertise the products they represent. Each agency sends its campaign requirements to the Piccadilly sales executive who deals with that agency. The executive then models the campaign by selecting commercial breaks for the spots to occupy that will be profitable to Piccadilly, and that will deliver the required ratings to the advertiser. When the executive is satisfied with his selections, the suggested campaign is communicated to the agency. The agency responds by selecting spots from the executive’s suggestions and informing him of the choices. The executive finalizes the deal by sending the agency written confirmation of the agreed spots that make up the campaign.”
The nouns in the description are advertising agency, commercial spot, advertising campaign, product, campaign requirement, sales executive, commercial break, rating, advertiser, selection, suggestion, choice, and confirmation. Note that in this listing, we have expressed the nouns as singular and used more descriptive names for advertising agency and advertising campaign. So let’s use these nouns as names for potential entities.
Are These Entities Relevant?
Testing for relevancy means asking if the system has a genuine business need to remember the facts that describe that entity. Ask, for instance, if there is a legal reason for storing those facts. Are they used by people or computers to do their jobs? Are they retrieved for reports? To illustrate a test for relevancy, you could ask if Piccadilly needs to remember anything about the potential entity ADVERTISING AGENCY. You already know that Piccadilly sells commercial airtime to the agencies, so there is a need to remember who the customers are. At the very least, Piccadilly is interested in the name and address of the advertising agency in order to mail the invoices. Given this need to remember, add the entity ADVERTISING AGENCY to your data model. You can test this entity by looking at the boundary data flows for data elements that must be remembered about agencies. If there are any, these data elements become attributes of ADVERTISING AGENCY, and confirm that this is a relevant entity.
The rule of thumb gave us a potential entity called CAMPAIGN REQUIREMENT. These are sent by the agency to the executive who uses them to plan and negotiate the campaign. Once the campaign is settled and the agency has agreed to the spots, there is no requirement for the executive to remember the agency’s original requirements. (You would have to get this decision from the users.) Any facts that must be remembered are attributes of ADVERTISING CAMPAIGN (there is a need to remember campaigns), so CAMPAIGN REQUIREMENT fails the relevancy test and can be omitted from the model. Similarly, ADVERTISER, SELECTION, SUGGESTION, CHOICE, and CONFIRMATION are potential entities that the system has no reason to remember. They fail the relevancy test and they, too, are omitted from the data model.
The entities we determined to be relevant from this test are shown in Figure 3.2.1. The next step is to find any relationships between these entities.
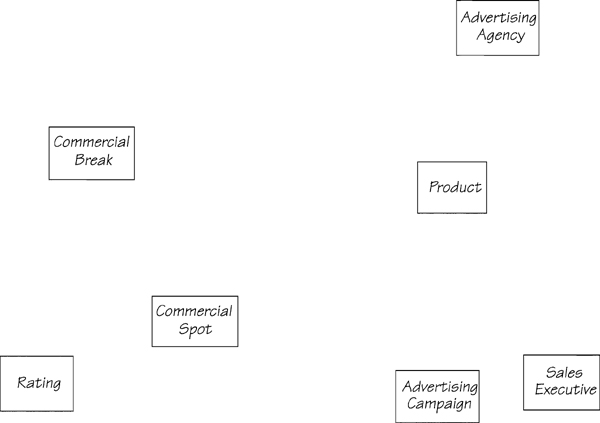
Figure 3.2.1: These seven entities are a starting point for the data model. Detailed analysis will specify the precise use of each entity and will add to and refine the data model.
Finding Relationships
Our rule of thumb also says that verbs in business descriptions indicate relationships. If we look again at the same paragraph:
“The advertising agencies buy commercial spots that make up campaigns to advertise the products they represent. Each agency sends its campaign requirements to the Piccadilly sales executive who deals with that agency. The executive then models the campaign by selecting commercial breaks for the spots to occupy that will be profitable to Piccadilly, and that will deliver the required ratings to the advertiser. When the executive is satisfied with his selections, the suggested campaign is communicated to the agency. The agency responds by selecting spots from the executive’s suggestions and informing him of the choices. The executive finalizes the deal by sending the agency written confirmation of the agreed spots that make up the campaign.”
The verbs and gerunds (words ending in “ing” that are the noun form of a verb) in the above are buy, make up, advertise, represent, sends, deals, models, selecting, occupy, deliver, satisfied, communicated, responds, selecting (again), informing, finalizes, sending, make up (again). Let’s treat each of these as potential relationships, and test them for relevancy. For each relationship, test its relevancy by asking, “What is the reason for this relationship? Does the system need to remember this relationship?”
Examine the first potential relationship: “The advertising agencies buy commercial spots ...” First, let’s discuss the reason for the relationship. You can see in the context diagram (Figure 3.1.1) a number of data flows between advertising agencies and the system. CAMPAIGN REQUIREMENTS, SELECTED SPOTS, and SUGGESTED CAMPAIGN exist because the agency is deciding to buy some spots. Selling spots to the agencies is a necessary part of Piccadilly’s business, so you can say that the reason for relating an agency to its commercial spots is that the agency is buying them.
The context diagram also yields the answer to the second question about the need to remember the relationship. After transmitting spots, Piccadilly sends an AGENCY INVOICE to the agency. The invoice lists the spots the agency is buying. Because Piccadilly must be able to identify which agency is buying which transmitted spot, this establishes the need to remember a relationship between agency and spot. The result of the relevancy test is that now you can say an agency and a commercial spot participate in a BUYING relationship.
These verbs—sends, deals, models, selecting, satisfied, communicated, responds, selecting (again), informing, finalizes, sending—did not pass the relevancy tests. “Each agency sends its campaign requirements to the ...” You’ve already omitted campaign requirements from your model, so there can be no relationship with it. “The executive then models the campaign by selecting commercial breaks ...” Does Piccadilly have a reason to remember which executive models a campaign, and which modeling effort selects which commercial breaks? It is highly unlikely. However, there is a strong reason for remembering which spots make up the final composition of a campaign, but modeling the campaign is a temporary state, and not worth remembering. Similarly, Piccadilly has no need to remember which breaks are part of the executive’s model: They aren’t invoiced, and sales executives cannot reserve spots for their clients. Similarly, communicated, satisfied, selecting, responds, informing, finalizes, and sending are all transitional in nature, and there appears no good reason to remember them. If you have included any of these in your model, don’t be too worried at this stage; remember that these are still potential relationships. Later analysis will confirm or deny the need for them and discover any that are missing, as you’ll see later in the Project.
After examining all of the potential relationships, we have added the relevant ones to the model (see Figure 3.2.2).
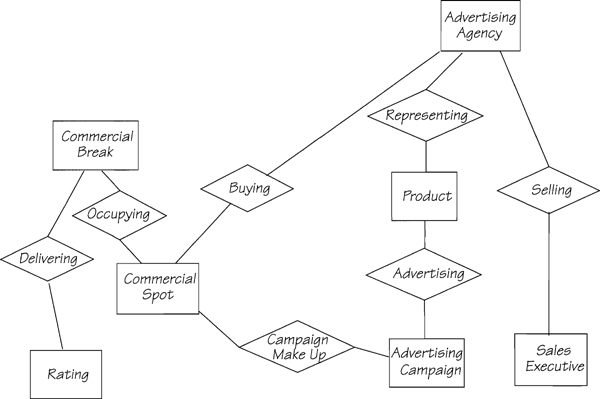
Figure 3.2.2: The data model with relationships added. We derived the relationships initially by identifying the verbs and gerunds in the Piccadilly description, and then testing each one for relevancy.
Adding Cardinality
Adding cardinality to each relationship in your data model is a way of learning more about the data. For each relationship in the data model, ask this question of the entities at either end of the relationship: “For one instance of this entity, how many of the other entity can participate in this relationship?”
For example, you know that the “advertising agencies buy commercial spots that make up campaigns to advertise the products they represent.” This tells you that for one agency, there are potentially many spots. From your knowledge of Piccadilly, you know that one campaign is made up of many spots, and you suspect that one agency has many products. If you question the entity at the other end of the relationship, you may find that one spot can be bought by only one agency. (If another agency wants it, the second agency must pay a higher price and preempt the first agency.) Also, a spot may belong to only one campaign, and a product is represented by only one agency at a time. Piccadilly keeps a credit history on previous purchases by agencies that owe money because Piccadilly needs a way to follow up on bad debts.
Only one sales executive is assigned to an agency, and although an executive may have more than one agency, you are not given any evidence of it. If you ask the executives, they each will confirm that they do indeed deal with more than one agency. You can reasonably assume that a product will have more than one campaign, and that one break will carry several spots. Breaks are two or three minutes long, and Piccadilly has to ensure that the executives fill the breaks with spots.
The model in Figure 3.2.3 shows the cardinality that results from testing the existing relationships.

Figure 3.2.3: To determine the cardinality of relationships, ask how many of each entity participate in a relationship. Knowing the cardinality gives you a better understanding of the data.
Building a data model always raises interesting questions, and you can learn a lot about the system from answering them. For example, we said that a product probably has more than one campaign, but can an advertising campaign be for more than one product? The answer is no. Piccadilly considers it too difficult to get paid for multi-product campaigns. While an advertiser may use copy that promotes several products, Piccadilly writes its contracts as if there is only one product.
Can a product be represented by more than one agency? The answer is that only one agency can represent a product. However, sometimes a product changes its agency. In that case, Piccadilly keeps track of the agency that previously represented the product because of the need to collect all its debts.
Can an agency be in a selling relationship with more than one sales executive? The users’ answer to this one is no. Piccadilly management is only interested in which sales executive has the current responsibility for selling to an agency. The answers to these questions show up as cardinal operators in the data model.
So far, the data model has defined only a subset of your knowledge about Piccadilly. Let’s look at some of the other parts of the policy statement from Chapter 1.2 Start with the Context.
“Piccadilly produces some of its own programmes, and buys others from a variety of programme suppliers both in England and overseas. These programme suppliers inform Piccadilly of their offerings, which include first-run films, sporting events, documentaries, talk shows, and old movies. Some of the programmes, such as the talk shows and documentaries, may be a series with a number of episodes.”
Now you have some more entities: PROGRAMME SUPPLIER, PROGRAMME, and EPISODE. Not all programmes have episodes. For example, a movie is a stand-alone programme. However, television broadcasters like to show movies under an umbrella programme name like “Prime Time Movie,” “Movie of the Week,” and so on. Therefore, it’s easier to think of all programmes as having a number of episodes. The entities and relationships for this piece of the policy are shown in Figure 3.2.4.
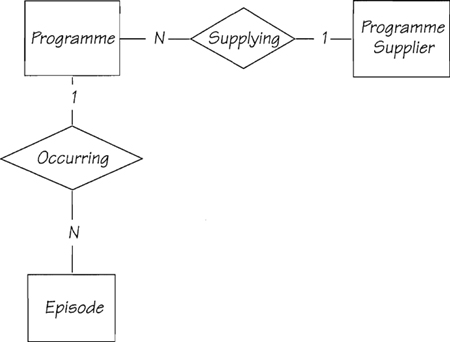
Figure 3.2.4: These entities and relationships show what Piccadilly remembers about the programming part of the system.
Let’s go on: “Piccadilly’s programme schedulers have the complicated job of deciding the date that each programme should be transmitted, and where in the programme the commercial breaks should be placed. To make these decisions, the schedulers use the weekly ratings that are supplied by the audience measurement bureaus and that tell them how many people are watching which programmes. The schedulers must also follow the Broadcasting Board’s rules for placement of programmes and for the number and placement of commercial breaks within those programmes. Four times a year, the schedulers set a new programme transmission schedule for the coming quarter.”
There is nothing in this description to tell you why this system needs to remember anything about the programme schedulers. Perhaps another system such as payroll may need to, but unless this system is to report on schedulers’ performance or suchlike, then you can eliminate the scheduler as an entity. The result of the schedulers’ efforts is the quarterly schedule. While there is a need to remember it, the published schedule is made up of the programmes and commercial breaks that the schedulers have decided. As there is only one schedule for this system, and as we already have entities and relationships that provide all the necessary information (PROGRAMME, EPISODE, COMMERCIAL BREAK), there is no need to have an entity called “schedule.”
The term “programme” is being used loosely here. If we are thinking there are many episodes of each programme, it’s the episode that is broadcast, not the programme. This means that COMMERCIAL BREAK relates to EPISODE, as the break’s proximity to the programme content of the episode is what attracts advertisers. The EPISODE will be one of many broadcasts on a given date.
The schedulers use RATING to anticipate the audience that each episode will attract. If an existing programme is continued in the new quarter’s schedule in the same time slot, its ratings will be similar, with allowances made for seasonal factors (ratings are higher in the fourth quarter of the year), and for competing channels’ programmes. For new programmes, the schedulers look at the actual ratings of similar programmes to work out the predicted ratings. The sales executives use the predicted ratings when they are selling commercial spots. So there are two types of ratings: predicted and actual. The upshot of this is that RATING relates to EPISODE, and that RATING has two subtypes: PREDICTED RATING and ACTUAL RATING. From this part of the business, we deduce the entities and relationships shown in Figure 3.2.5.
The entity DATE isn’t shown in Figure 3.2.5, and you may not have it in your model. After all, the date of transmission could be an attribute of EPISODE. However, the users will tell you that there is a “day of transmission” or, as Piccadilly calls it, “breakchart day.” Usually, the station starts its broadcasting day with the morning talk shows, and finishes some time in the early hours of the following morning with the “Late, Late Show.” (We are just as perplexed as you why something in the early hours is called “late.”) While this constitutes a day’s transmission, it actually covers two dates. Look again at the ratecard in Chapter 1.2 (Figure 1.2.1) and answer this: If an advertiser buys a spot in the late Friday segment, and the spot is not transmitted until after midnight, what rate does he pay? The answer is the weekday 23.40-to-close rate. So the breakchart day is different from the actual date. We thus change the name of this entity to make it more appropriate to the system.
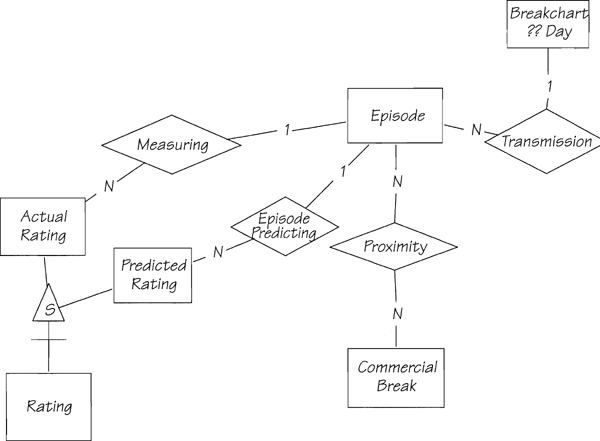
Figure 3.2.5: A partial data model for the scheduling part of the system. Note that some of the entities in this model have already appeared in other partial models.
How do you show the rules provided by the Broadcasting Board in a data model? One approach is not to show them: They could be considered as part of the scheduling process policy, and not as stored data at all. However, in this case, the PROGRAMMING RULES are shown in the context diagram as a data flow entering the system. So there must be a process like the one in Figure 3.2.6.

Figure 3.2.6: The programming rules from the Broadcasting Board are stored for use by the schedulers.
You can safely assume that the rules will change from time to time and that there may be special rules that apply to special seasons. So it makes good business sense to have the rules remembered. This gives an entity that we call BROADCASTING RULE because it is concerned not just with programmes but also with commercial breaks. But to what does it relate? The statement “The schedulers must also follow the Broadcasting Board’s rules for placement of programmes and for the number and placement of commercial breaks ...” indicates that the rules relate to the scheduling of breaks within and around programmes. In other words, an entity relates to a relationship. This seems a little mind-boggling, but we can neatly solve the problem by having a three-way relationship between the participating entities (see Figure 3.2.7). Similarly, the rules apply to scheduling episodes of programmes, and so they can participate in the SCHEDULING relationship. The way to make sense of this relationship is to view it in three different ways:
• For each instance of one EPISODE and one COMMERCIAL BREAK, there are many instances of BROADCASTING RULE.
• For each instance of one COMMERCIAL BREAK and one BROADCASTING RULE, there are many instances of EPISODE.
• For each instance of one EPISODE and one BROADCASTING RULE, there are many instances of COMMERCIAL BREAK.
As you can see, n-ary relationships are more complex to understand than binary relationships. Often, they indicate that an analyst doesn’t really understand a piece of policy, so he has related a clump of entities to each other. If this is the case, you’ll find it particularly difficult to give the relationship a meaningful name. The best advice we can give you is always look for binary relationships first. If you cannot define your meaning using binary relationships, that is an indication you have a real n-ary relationship.
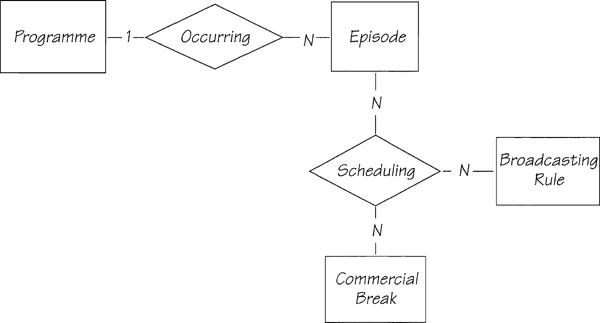
Figure 3.2.7: The programming rules participate in the relationship between the breaks in and around an episode, and the occurrence of episodes of a programme.
Bear in mind as you read through our explanation that your model does not have to agree entirely with ours. After all, you may have interpreted the statement differently and anticipated different answers from the users. The point of this discussion is to show you the data model that results from one interpretation of the business policy.
Let’s go back to the context diagram in Figure 3.1.1 to see the details of what data enter the system and need to be remembered. Take the data flow COMMERCIAL COPY RECORDING, which comes from PRODUCTION COMPANIES. The system needs to remember the copy and where it came from. This gives two entities: COMMERCIAL COPY and PRODUCTION COMPANY, with a FILMING relationship between them. The COMMERCIAL COPY entity must also relate to ADVERTISING CAMPAIGN. Now consider this from “The Story of Piccadilly Television”: “Some advertisers use several different commercials in a campaign, and the agency must send instructions on which copy is to be transmitted in each spot.” The boundary data flow COPY TRANSMISSION INSTRUCTIONS delivers the data, which must be remembered. Digging a little deeper, we will discover that the reason for the copy instructions is to make sure that Piccadilly transmits each copy in a defined sequence. So Piccadilly saves the dates in the COPY TRANSMISSION INSTRUCTIONS as attributes of the COMMERCIAL COPY entity. The spot manipulators use the copy transmission dates when doing the ALLOCATING of COMMERCIAL COPY to COMMERCIAL SPOT.
There are two relationships, OCCUPYING and TRANSMITTING, between COMMERCIAL BREAK and COMMERCIAL SPOT. The reason is that OCCUPYING represents a temporary placing of the spot within the break. Remember that for some spot rates, there is no obligation to keep it in the break, nor indeed to transmit the spot. The TRANSMITTING relationship is established when the spot is broadcast. So this relationship represents an actual happening and is used for invoicing.
When you assemble all the fragments of the data model, you have a complete (to date) description of the business; the assembled model is in Figure 3.2.8. Compare it to your own, and make sure before going on that you can reconcile all of your (and our) decisions on how to portray the business policy.
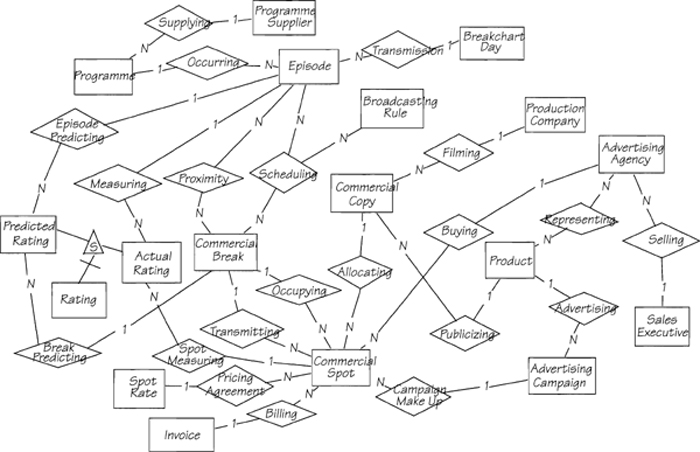
Figure 3.2.8: This first-cut data model serves as a guide for your detailed analysis. As you progress with the Piccadilly Project, you will define the data in each entity and relationship, as well as the processes that store and retrieve those data.
Defining Your Entities
We asked you to write down the attributes for the entity ADVERTISING CAMPAIGN. Some of the attributes are established by the executive when he uses (the data flow) CAMPAIGN REQUIREMENTS to plan the campaign. First consider what data make up the flow. When the agency gives Piccadilly the campaign requirements, the agency also must tell Piccadilly its name. So the name of the agency will be part of the flow, along with the name of the product to be advertised. The executive needs to know at least the budget for the campaign, the target audience, the ratings the agency wants to achieve, the length of the campaign, and, for scheduling purposes, the duration of each spot used in the campaign.
In the data dictionary, you can write the above description as
Campaign Requirements = * Data flow. An agency’s description of requirements for an advertising campaign. *
Agency Name + Product Name + Campaign Budget
+ Target Audience + Target Rating Percentage
+ Campaign Duration
+ {Required Spot Duration}
The braces around REQUIRED SPOT DURATION indicate there are many of them, whereas there is only one occurrence of each of the other data elements. (This notation is explained fully in Chapter 2.9 Data Dictionary. If you aren’t comfortable with it, look ahead, but for now just accept it as a convenient shorthand.)
Which of the items in this data flow need to be part of the ADVERTISING CAMPAIGN entity? For the moment, we think this is a fair definition:
Advertising Campaign = Campaign Budget + Target Audience
+ Target Rating Percentage + Campaign Duration
+ {Required Spot Duration}
Note that each of the attributes describes an advertising campaign and only an advertising campaign. Other items from the data flow, such as AGENCY NAME and PRODUCT NAME, are not included as attributes of the entity ADVERTISING CAMPAIGN as they describe other entities. AGENCY NAME is an attribute of the entity ADVERTISING AGENCY, and PRODUCT NAME is, of course, an attribute of the entity PRODUCT. If you look at the data model, you’ll see that ADVERTISING CAMPAIGN has a relationship called REPRESENTING with PRODUCT. The relationship links the product to its campaign, so that the system knows which campaigns belong to which products.
As the analysis progresses and you learn more about the system, add what you know to your models. You should write definitions for the entities and relationships as soon as you have something to say about them. At this stage, an examination of the boundary data flows reveals many data elements that you should attribute to your entities and relationships. It is also helpful to write a short statement explaining the purpose of each entity and relationship; this explanation is enclosed by asterisks.
Advertising Agency = * Entity. Buyer of commercial spots for advertising campaigns. *
Agency Name + Agency Address + Agency Phone Number
Representing = * Relationship. Keeps track of which agency is responsible for a product. Keeps track of historical relationships between agencies and products for collecting bad debts. Cardinality: for each Advertising Agency, there are many Products; for each Product, there are many Advertising Agency(s). Participation: Advertising Agency mandatory, Product mandatory. *
Representation Start Date + Representation End Date
Notice that the relationship definition specifies the purpose of the relationship, as well as the cardinality and participation rules for each entity involved in the relationship. The representing relationship also has two data elements attributed to it because both representation start date and representation end date truly describe the relationship. However, there will be many cases in which a relationship does not have any attributes.
The reason for writing these definitions is that they almost always raise questions. By asking these questions and getting answers, you’ll learn still more about the system. Adding that knowledge to your models raises more questions, and ... Believe us, it does end eventually.
Look at the other entities in the data model and consider the attributes they each contain. Later, after reading the data dictionary chapters (2.9 Data Dictionary and 1.5 Building the Data Dictionary), you will define them completely.
Another Way to Build the Data Model
Having just put you through the exercise of building a data model from a statement of the users’ business, we now confess that this is not the only way to build such a model. Our reason for doing it this way is to give you some practice with data modeling and to raise questions about Piccadilly. Shortly, you will partition the system by events and build event-response data models. (If you are unfamiliar with these terms and models, your trail will introduce them before you need them for the case study.)
Why do you need several methods? Because we have found in our own projects the enormous benefit of building a first-cut data model of the users’ business. This model is an invaluable vehicle for starting to understand the business policy. However, the first-cut model is too large to support very detailed thinking. Later, you will use event-response data models to partition the data model into head-sized pieces so that you can confirm all the details and assumptions. The result will be a data model that is descriptive and reliable because you have used the policy in the event-response models to verify it.
 Ski Patrol
Ski Patrol
Your data model should be substantially the same as ours. Naturally, there are sure to be some differences in interpretation of the meaning of data and in your choice of names. This is expected when building a first-cut model. Your reason for building the model is to discover potential misunderstandings and arrive at a consensus. If, after reviewing the answer, you feel you’ve accomplished the objective of the exercise, proceed directly to the Trail Guide for further directions.
If you had some problems—if perhaps the whole exercise of building a data model had no meaning for you—then Chapter 2.4 Data Viewpoint will give you the reason for needing a data model. Similarly, if you feel it to be overkill to build both a data model and a data flow model of the same system, we remind you that the purpose is to analyze and specify the complete system. Your specification is more rigorous and easier to build if you have both data and process models. This will be reinforced when you get to the essential modeling chapters.
Some commonly encountered problems in data modeling concern the questions of which attributes make up an entity, when to make a relationship, and how to name relationships. Chapter 2.5 Data Models will answer these questions, and the exercises there will give you some more practice. Also, remember that your data model is only a first cut, based on your current fragmentary knowledge of Piccadilly. As you do more of the Project, your increased knowledge will add to and improve your data model.
![]() Easiest: Go to Chapter 2.6 More on Data Flow Diagrams. You will leave data models for the moment to expand your knowledge of data flow models. You will rejoin the Piccadilly Project shortly.
Easiest: Go to Chapter 2.6 More on Data Flow Diagrams. You will leave data models for the moment to expand your knowledge of data flow models. You will rejoin the Piccadilly Project shortly.
![]() More Difficult: Now is the time to consider an appropriate viewpoint for this stage of the Piccadilly Project. Go to Chapter 2.8 Current Physical Viewpoint.
More Difficult: Now is the time to consider an appropriate viewpoint for this stage of the Piccadilly Project. Go to Chapter 2.8 Current Physical Viewpoint.
![]() Most Difficult: Continue on with the Piccadilly Project, when you will now get some more background into the company. Go to Chapter 1.4 The Piccadilly Organization.
Most Difficult: Continue on with the Piccadilly Project, when you will now get some more background into the company. Go to Chapter 1.4 The Piccadilly Organization.
![]() Promenade: This wasn’t intended to be part of your journey. However, if you have already been through the data modeling chapters (2.4 Data Viewpoint and 2.5 Data Models), look at the data model in Chapter 3.2 (Figure 3.2.8), then pick up your trail in Chapter 2.10 Essential Viewpoint.
Promenade: This wasn’t intended to be part of your journey. However, if you have already been through the data modeling chapters (2.4 Data Viewpoint and 2.5 Data Models), look at the data model in Chapter 3.2 (Figure 3.2.8), then pick up your trail in Chapter 2.10 Essential Viewpoint.