
15
Stopping
In Chapter 14 we studied how to determine an optimal fixed sample size. In that discussion, the decision maker selects a sample size before seeing any of the data. Once the data are observed, the decision maker then makes a terminal decision, typically an inference. Here, we will consider the case in which the decision maker can make observations one at a time. At each time, the decision maker can either stop sampling (and choose a terminal decision), or continue sampling. The general technique for solving this sequential problem is dynamic programming, presented in general terms in Chapter 12.
In Section 15.1, we start with a little history of the origin of sequential sampling methods. Sequential designs were originally investigated because they can potentially reduce the expected sample size (Wald 1945). Our revisitation of Wald’s sequential stopping theory is almost entirely Bayesian and can be traced back to Arrow et al. (1949). In their paper, they address some limitations of Wald’s proof of the optimality of the sequential probability ratio test, derive a Bayesian solution, and also introduce a novel backward induction method that was the basis for dynamic programming. We illustrate the gains that can be achieved with sequential sampling using a simple example in Section 15.2. Next, we formalize the sequential framework for the optimal choice of the sample size in Sections 15.3.1, 15.3.2, and 15.3.3. In Section 15.4, we present an example of optimal stopping using the dynamic programming technique.
In Section 15.5, we discuss sequential sampling rules that do not require specifying the costs of experimentation, but rather continue experimenting until enough information about the parameters of interest is gained. An example is to sample until the posterior probability of a hypothesis of interest reaches a prespecified level. We examine the question of whether such a procedure could be used to design studies that always reach a foregone conclusion, and conclude that from a Bayesian standpoint, that is not the case. Finally, in Section 15.6 we discuss the role of stopping rules in the terminal decision, typically inferences, and connect our decision-theoretic approach to the Likelihood Principle.
Featured articles:
Wald, A. (1945). Sequential tests of statistical hypotheses, Annals of Mathematical Statistics 16: 117–186.
Arrow, K., Blackwell, D. and Girshick, M. (1949). Bayes and minimax solutions of sequential decision problems, Econometrica 17: 213–244.
Useful reference texts for this chapter are DeGroot (1970), Berger (1985), and Bernardo and Smith (2000).
15.1 Historical note
The earliest example of a sequential method in the statistical literature is, as far as we know, provided by Dodge and Romig (1929) who proposed a two-stage procedure in which the decision of whether or not to draw a second sample was based on the observations of the first sample. It was only years later that the idea of sequential analysis would be more broadly discussed. In 1943, US Navy Captain G. L. Schuyler approached the Statistical Research Group at Columbia University with the problem of determining the sample size needed for comparing two proportions. The sample size required was very large. In a letter addressed to Warren Weaver, W. Allen Wallis described Schuyler’s impressions:
When I presented this result to Schuyler, he was impressed by the largeness of the samples required for the degree of precision and certainty that seemed to him desirable in ordnance testing. Some of these samples ran to many thousands of rounds. He said that when such a test program is set up at Dahlgren it may prove wasteful. If a wise and seasoned ordnance expert like Schuyler were on the premises, he would see after the first few thousand or even few hundred [rounds] that the experiment need not be completed, either because the new method is obviously inferior or because it is obviously superior beyond what was hoped for. He said that you cannot give any leeway to Dahlgren personnel, whom he seemed to think often lack judgement and experience, but he thought it would be nice if there were some mechanical rule which could be specified in advance stating the conditions under which the experiment might be terminated earlier than planned. (Wallis 1980, p. 325)
W. Allen Wallis and Milton Friedman explored this idea and came up with the following conjecture:
Suppose that N is the planned number of trials and WN is a most powerful critical region based on N observations. If it happens that on the basis of the first n trials (n < N) it is already certain that the completed set of N must lead to a rejection of the null hypothesis, we can terminate the experiment at the n-trial and thus save some observations. For instance, if WN is defined by the inequality ![]() , and if for some n < N we find that
, and if for some n < N we find that ![]() , we can terminate the process at this stage. Realization of this naturally led Friedman and Wallis to the conjecture that modifications of current tests may exist which take advantage of sequential procedure and effect substantial improvements. More specifically, Friedman and Wallis conjectured that a sequential test may exist that controls the errors of the first and second kinds to exactly the same extent as the current most powerful test, and at the same time requires an expected number of observations substantially smaller than the number of observations required by the current most powerful test. (Wald 1945, pp. 120–121)
, we can terminate the process at this stage. Realization of this naturally led Friedman and Wallis to the conjecture that modifications of current tests may exist which take advantage of sequential procedure and effect substantial improvements. More specifically, Friedman and Wallis conjectured that a sequential test may exist that controls the errors of the first and second kinds to exactly the same extent as the current most powerful test, and at the same time requires an expected number of observations substantially smaller than the number of observations required by the current most powerful test. (Wald 1945, pp. 120–121)
They first approached Wolfowitz with this idea. Wolfowitz, however, did not show interest and was doubtful about the existence of a sequential procedure that would improve over the most powerful test. Next, Wallis and Friedman brought this problem to the attention of A. Wald who studied it and, in April of 1943, proposed the sequential probability ratio test. In the problem of testing a simple null versus a simple alternative Wald claimed that:
The sequential probability ratio test frequently results in a saving of about 50% in the number of observations as compared with the current most powerful test. (Wald 1945, p. 119)
Wald’s finding was of immediate interest, as he explained:
Because of the substantial savings in the expected number of observations effected by the sequential probability ratio test, and because of the simplicity of this test procedure in practical applications, the National Defense Research Committee considered these developments sufficiently useful for the war effort to make it desirable to keep the results out of the reach of the enemy, at least for a certain period of time. The author was, therefore, requested to submit his findings in a restricted report. (Wald 1945, p. 121)
It was only in 1945, after the reports of the Statistical Research Group were no longer classified, that Wald’s research was published. Wald followed his paper with a book published in 1947 (Wald 1947b).
In Chapter 7 we discussed Wald’s contribution to statistical decision theory. In our discussion, however, we only considered the situation in which the decision maker has a fixed number of observations. Extensions of the theory to sequential decision making are in Wald (1947a) and Wald (1950). Wald explores minimax and Bayes rules in the sequential setting. The paper by Arrow et al. (1949) is, however, the first example we know of utilizing backwards induction to derive the formal Bayesian optimal sequential procedure.
15.2 A motivating example
This example, based on DeGroot (1970), illustrates the insight of Wallis and Friedman, and shows how a sequential procedure improves over the fixed sample size design.
Suppose it is desired to test the null hypothesis H0 : θ = θ0 versus the alternative H1 : θ = θ1. Let ai denote the decision of accepting hypothesis Hi, i = 0, 1. Assume that the utility function is
The decision maker can take observations xi, i = 1, 2, .... Each observation costs c units and it has a probability α of providing an uninformative outcome, while in the remainder of the cases it provides an answer that reveals the value of θ without ambiguity. Formally xi has the following probability distribution:

Let π = π(θ = θ0) denote the prior probability of the hypothesis H0, and assume that π ≤ 1/2. If no observations are made, the Bayes decision is a1 and the associated expected utility is –π. Now, let us study the case in which observations are available. Let yx count the number of observations with value x, with x = 1, 2, 3. Given a sequence of observations xn = (x1, ..., xn), the posterior distribution is

There is no learning about θ if all the observed x are equal to 3, the uninformative case. However, in any other case, the value of θ is known with certainty. It is futile to continue experimenting after x = 1or x = 2 is observed. For sequences xn that reveal the value of θ with certainty, the expected posterior utility, not including sampling costs, is 0. When πxn = π, the expected posterior utility is –π. Thus, the expected utility of taking n observations, accounting for sampling costs, is
Suppose that the values of c and α are such that Uπ(1) > Uπ(0), that is it is worthwhile to take at least one observation, and let n* denote the positive integer that maximizes equation (15.4). An approximate value is obtained by assuming continuity in n. Differentiating with respect to n, and setting the result to 0, gives

The decision maker can reduce costs of experimentation by taking the n* observations sequentially with the possibility of stopping as soon as he or she observes a value different from 3. Using this procedure, the sample size N is a random variable. Its expected value is

This is independent of θ, so E[N|θ1] = E[N|θ0]. Thus, E[N] = (1 – αn*) / (1 – α).
This sequential sampling scheme imposes an upper bound of n* observations on the expected value of N. To illustrate the reduction on the number of observations when using the sequential sampling, let α = 1/4, c = 0.000 001, π = 1/4. We obtain n* = 10 and E[N] = 1.33; that is, on average, we have a great reduction in the sample size needed.
Figure 15.1 illustrates this further using a simulation. We chose values of θ from its prior distribution with π = 1/2. Given θ, we sequentially simulated observations using (15.2) with α = 1/4 until we obtained a value different from 3, or reached the maximum sample size n* and recorded the required sample size. We repeated this procedure 100 times. In the figure we show the resulting number of observations with the sequential procedure.

Figure 15.1 Sample size for 100 simulated sequential experiments in which π = 1/2 and α = 1/4.
15.3 Bayesian optimal stopping
15.3.1 Notation
As in Chapter 14, suppose that observations x1, x2, ... become available sequentially one at a time. After taking n observations, that is observing xn = (x1, ..., xn), the joint probability density function (or joint probability mass function depending on the application) is f (xn|θ). As usual, assuming that π is the prior distribution for θ, after n observations, the posterior density is π(θ|xn) and the marginal distribution of xn is
The terminal utility function associated with a decision a when the state of nature is θ is u(a(θ)). The experimental cost of taking n observations is denoted by C(n). The overall utility is, therefore,
u(θ, a, n) = u(a(θ)) – C(n).
The terminal decision rule after n observations (that is, after observing xn) is denoted by δn(xn). As in the nonsequential case, for every possible experimental outcome xn, δn(xn) tell us which action to choose if we stop sampling after xn. In the sequential case, though, a decision rule requires the full sequence δ = {δ1(x1), δ2(x2), ...} of terminal decision rules. Specifying δ tells us what to do if we stop sampling after 1, 2, ... observations have been made. But when should we stop sampling?
Let ζn(xn) be the decision rule describing whether or not we stop sampling after n observations, that is

If ζ0 ≡ 1 there is no experimentation. We can now define stopping rule, stopping time, and sequential decision rule.
Definition 15.1 The sequence ζ = {ζ0, ζ1(x1), ζ2(x2), ...} is called a stopping rule.
Definition 15.2 The number N of observations after which the decision maker decides to stop sampling and make the final decision is called stopping time.
The stopping time is a random variable whose distribution depends on ζ. Specifically,
N = min{n ≥ 0, |
such that |
ζn(xn) = 1}. |
We will also use the notation {N = n} for the set of observations (x1, x2, ...) such that the sampling stops at n, that is for which
ζ0 = 0, ζ1(x1) = 0, ..., ζn−1(xn −1) = 0, ζn(xn) = 1.
Definition 15.3 A sequential decision rule d consists of a stopping rule and a decision rule, that is d = (ζ, δ). If Pθ(N < ∞) = 1 for all values of θ, then we say that the sequential stopping rule ζ is proper.
From now on, in our discussion we will consider just the class of proper stopping rules.
15.3.2 Bayes sequential procedure
In this section we extend the definition of Bayes rule to the sequential framework. To do so, we first note that

The counterpart of the frequentist risk R in this context is the long-term average utility of the sequential procedure d for a given θ, that is

where
with δn(xn)(θ) denoting that for each xn the decision rule δn(xn) produces an action, which in turn is a function from states to outcomes.
The counterpart of the Bayes risk is the expected utility of the sequential decision procedure d, given by
Definition 15.4 The Bayes sequential procedure dπ is the procedure which maximizes the expected utility Uπ (d).
Theorem 15.1 If ![]() is a Bayes rule for the fixed sample size problem with observations x1, ..., xn and utility u(θ, a, n), then
is a Bayes rule for the fixed sample size problem with observations x1, ..., xn and utility u(θ, a, n), then ![]() is a Bayes sequential decision rule.
is a Bayes sequential decision rule.
Proof: Without loss of generality, we assume that Pθ(N = 0) = 0:

If we interchange the integrals on the right hand side of the above expression we obtain

Note that f (xn|θ)π(θ) = π(θ|xn)m(xn). Using this fact, let
denote the posterior expected utility at stage n. Thus,

The maximum of Uπ (d) is attained if, for each xn, δn(xn) is chosen to maximize the posterior expected utility Uπxn,N=n(δn(xn)) which is done in the fixed sample size problem, proving the theorem.
This theorem tells us that, regardless of the stopping rule used, once the experiment is stopped, the optimal decision is the formal Bayes rule conditional on the observations collected. This result echoes closely our discussion of normal and extensive forms in Section 12.3.1. We will return to the implications of this result in Section 15.6.
15.3.3 Bayes truncated procedure
Next we discuss how to determine the optimal stopping time. We will consider bounded sequential decision procedures d (DeGroot 1970) for which there is a positive number k such that P(N ≤ k) = 1. The technique for solving the optimal stopping rule is backwards induction as we previously discussed in Chapter 12.
Say we carried out n steps and observed xn. If we continue we face a new sequential decision problem with the same terminal decision as before, the possibility of observing xn+1, xn+2, ..., and utility function u(a(θ)) – C(j), where j is the number of additional observations. Now, though, our updated probability distribution on θ, that is πxn, will serve as the prior. Let Dn be the class of all proper sequential decision rules for this problem. The expected utility of a rule d in Dn is Uπxn (d), while the maximum achievable expected utility if we continue is
To decide whether or not to stop we compare the expected utility of the continuation problem to the expected utility of stopping immediately. At time n, the posterior expected utility of collecting an additional 0 observations is
Therefore, we would continue sampling if W(πxn, n) > W0(πxn, n).
A catch here is that computing W(πxn, n) may not be easy. For example, dynamic programming tells us we should begin at the end, but here there is no end. An easy fix is to truncate the problem. Unless you plan to be immortal, you can do this with little loss of generality. So consider now the situation in which the decision maker can take no more than k overall observations. Formally, we will consider a subset ![]() of Dn, consisting of rules that take a total of k observations. These rules are all such that ζk(xk) = 1. Procedures dk with this feature are called k-truncated procedures. We can define the k-truncated value of the experiment starting at stage n as
of Dn, consisting of rules that take a total of k observations. These rules are all such that ζk(xk) = 1. Procedures dk with this feature are called k-truncated procedures. We can define the k-truncated value of the experiment starting at stage n as
Given that we made it to n and saw xn, the best we could possible do if we continue for at most k – n additional steps is Wk−n(πxn, n). Because ![]() is a subset of Dn, the value of the k-truncated problem is non-decreasing in k.
is a subset of Dn, the value of the k-truncated problem is non-decreasing in k.
The Bayes k-truncated procedure dk is a procedure that lies in ![]() and for which
and for which
Also, you can think of W(πxn, n) as W∞(πxn, n).
The relevant expected utilities for the stopping problem can be calculated by induction. We know the value is W0(πxn, n) if we stop immediately. Then we can recursively evaluate the value of stopping at any intermediate stage between n and k by

Based on this recursion we can work out the following result.
Theorem 15.2 Assume that the Bayes rule ![]() exists for all n, and Wj(πxn, n) are finite for j ≤ k, n ≤ (k –j). The Bayes k-truncated procedure is given by dk = (ζ k, δ*) where ζ k is the stopping rule which stops sampling at the first n such that
exists for all n, and Wj(πxn, n) are finite for j ≤ k, n ≤ (k –j). The Bayes k-truncated procedure is given by dk = (ζ k, δ*) where ζ k is the stopping rule which stops sampling at the first n such that
This theorem tell us that at the initial stage we compare W0(π, 0), associated with an immediate Bayes decision, to the overall k-truncated Wk(π, 0). We continue sampling (observe x1) only if W0(π,0) < Wk(π, 0). Then, if this is the case, after x1 has been observed, we compare W0(πx1, 1) of an immediate decision to the (k – 1)-truncated problem Wk−1(πx1, 1) at stage 1. As before, we continue sampling only if W0(πx1,1) < Wk−1(πx1, 1). We proceed until W0(πxn, n) = Wk−n(πxn, n).
In particular, if the cost of each observation is constant and equal to c, we have C(n) = nc. Therefore,

It follows that
If we define, inductively,
then Wj(πxn, n) = Vj(πxn) – nc.
Corollary 2 If the cost of each observation is constant and equal to c, the Bayes k-truncated stopping rule, ζ k, is to stop sampling and make a decision for the first n ≤ k for which
V0(πxn) = Vk−n(πxn).
We move next to applications.
15.4 Examples
15.4.1 Hypotheses testing
This is an example of optimal stopping in a simple hypothesis testing setting. It is discussed in Berger (1985) and DeGroot (1970). Another example in the context of estimation is Problem 15.1. Assume that x1, x2, ... is a sequential sample from a Bernoulli distribution with unknown probability of success θ. We wish to test H0: θ= 1/3 versus H1 : θ = 2/3. Let ai denote accepting Hi. Assume u(θ, a, n) = u(a(θ)) – nc, with sampling cost c = 1 and with “0–20” terminal utility: that is, no loss for a correct decision, and a loss of 20 for an incorrect decision, as in Table 15.1. Finally, let π0 denote the prior probability that H0 is true, that is Pr(θ = 1/3) = π0. We want to find d2, the optimal procedure among all those taking at most two observations.
Table 15.1 Utility function for the sequential hypothesis testing problem.
|
True value of θ |
|
|
θ = 1/3 |
θ = 2/3 |
a0 |
0 |
–20 |
a1 |
–20 |
0 |
We begin with some useful results. Let ![]()
The marginal distribution of xn is

The posterior distribution of θ given x is
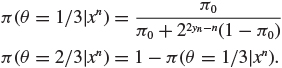
The predictive distribution of xn+1 given xn is

Before making any observation, the expected utility of immediately making a decision is
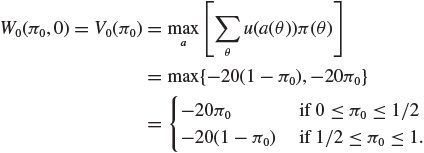
Therefore, the Bayes decision is a0 if 1/2 ≤ π0 ≤ 1 and a1 if 0 ≤ π0 ≤ 1/2. Figure 15.2 shows the V-shaped utility function V0 highlighting that we expect to be better off at the extremes than at the center of the range of π0 in addressing to choice of hypothesis.
Next, we calculate V0(πx1), the value of taking an observation and then stopping. Suppose that x1 has been observed. If x1 = 0, the posterior expected utility is


Figure 15.2 Expected utility functions V0 (solid), V1 (dashed), and V2 (dot–dashed) as functions of the prior probability π0. Adapted from DeGroot (1970).
If x1 = 1 the posterior expected utility is

Thus, the expected posterior utility is

Using the recursive relationship we derived in Section 15.3.3, we can derive the utility of the optimal procedure in which no more than one observation is taken. This is

If the prior is in the range 23/60 ≤ π0 ≤ 37/60, the observation of x1 will potentially move the posterior sufficiently to change the optimal decision, and to do so with sufficient confidence to offset the cost of observation.
The calculation of V2 follows the same steps and works out so that

which leads to
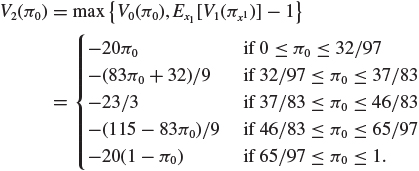
Because of the availability of the second observation, the range of priors for which it is optimal to start sampling is now broader, as shown in Figure 15.2.
To see how the solution works out in a specific case, suppose that π0 = 0.48. With this prior, a decision with no data is a close call, so we expect the data to be useful. In fact, V0(π0) = − 9.60 < V2(π0) = − 7.67, so we should observe x1. If x1 = 0, we have V0(πx1) = V1(πx1) = − 7.03. Therefore, it is optimal to stop and choose a0. If x1 = 1, V0(πx1) = V1(πx1) = − 6.32 and, again, it is optimal to stop, but we choose a1.
15.4.2 An example with equivalence between sequential and fixed sample size designs
This is another example from DeGroot (1970), and it shows that in some cases there is no gain from having the ability to accrue observations sequentially.
Suppose that x1, x2, ... is a sequential sample from a normal distribution with unknown mean θ and specified variance 1/ω. The parameter ω is called precision and is a more convenient way to handle this problem as we will see. Assume that θ is estimated under utility u(a(θ)) = −(θ – a)2 and that there is a fixed cost c per observation. Also, suppose that the prior distribution π of θ is a normal distribution with mean μ and precision h. Then the posterior distribution of θ given xn is normal with posterior precision h + nω. Therefore, there is no uncertainty about future utilities, as

and so V0(πxn) = −1/(h+nω)for n = 0, 1, 2, .... This result shows that the expected utility depends only on the number of observations taken and not on their observed values. This implies that the optimal sequential decision procedure is a procedure in which a fixed number of observations is taken, because since the beginning we can predict exactly what our state of information will be at any stage in the process. Try Problem 15.3 for a more general version of this result.
Exploring this example a bit more, we discover that in this simple case we can solve the infinite horizon version of the dynamic programming solution to the optimal stopping rule. From our familiar recursion equation

Now
whenever
Using this fact, and an inductive argument (Problem 15.4), one can show that Wj(π, n) = − 1/(h + nω) – nc for βn <ω ≤ βn+1 where βn is defined as β0 = 0, βn = c(h + (n – 1)ω)(h + nω) for n = 1, ..., j, and βj+1 = ∞. This implies that the optimal sequential decision is to take exactly n* observations, where n* is an integer such that ![]() . If the decision maker is not allowed to take more than k observations, then if n* > k, he or she should take k observations.
. If the decision maker is not allowed to take more than k observations, then if n* > k, he or she should take k observations.
15.5 Sequential sampling to reduce uncertainty
In this section we discuss sampling rules that do not involve statements of costs of experimentation, following Lindley (1956) and DeGroot (1962). The decision maker’s goal is to obtain enough information about the parameters of interest. Experimentation stops when enough information is reached. Specifically, let Vx(E) denote the observed information provided by observing x in experiment E as defined in Chapter 13. Sampling would continue until Vxn (E) ≥ 1/∊, with ∊ chosen before experimentation starts. In estimation under squared error loss, for example, this would mean sampling until Var[θ|xn] < ∊ for some ∊.
Example 15.1 Suppose that Θ = {θ0, θ1} and let π = π(θ0) and πxn = πxn (θ0). Consider the following sequential procedure: sampling continues until the Shannon information of πxn is at least ∊. In symbols, sampling continues until
For more details on Shannon information and entropy see Cover and Thomas (1991). One can show that Shannon’s information is convex in πxn. Thus, inequality (15.7) is equivalent to sampling as long as
with A′ and B′ satisfying the equality in (15.7). If πxn < A′, then we stop and accept H1;if πxn > B′ we stop and accept H0.
Rewriting the posterior in terms of the prior and likelihood,

This implies that inequality (15.8) is equivalent to
with
The procedure just derived is of the same form as Wald’s sequential probability ratio test (Wald 1947b), though in Wald the boundaries for stopping are determined using frequentist operating characteristics of the algorithm.
Example 15.2 Let x1, x2, ... be sequential observations from a Bernoulli distribution with unknown probability of success θ. We are interested in estimating θ under the quadratic loss function. Suppose that θ is a priori Beta(α0, β0), and let αn and βn denote the parameters of the beta posterior distribution. The optimal estimate of θ is the posterior mean, that is δ* = αn/(αn + βn). The associated Bayes risk is the posterior variance Var[θ|xn] = αnβn/[(αn + βn)2(αn + βn + 1)].
Figure 15.3 shows the contour plot of the Bayes risk as a function of αn and βn. Say the sampling rule is to take observations as long as Var[θ|xn] ≥ ∊ = 0.02. Starting with a uniform prior (α = β = 1), the prior variance is approximately equal to 0.08. The segments in Figure 15.3 show the trajectory of the Bayes risk after observing a particular sample. The first observation is a success and thus αn = 2, βn = 1, so our trajectory moves one step to the right. After n = 9 observations

Figure 15.3 Contour plot of the Bayes risk as a function of the beta posterior parameters αn (labeled a) and βn (labeled b).
with x = (1, 0, 0, 1, 1, 1, 0, 1, 1) the decision maker crosses the 0.02 curve, and stops experimentation.
For a more detailed discussion of this example, including the analysis of the problem using asymptotic approximations, see Lindley (1956) and Lindley (1957).
Example 15.3 Suppose that x1, x2, ... are sequentially drawn from a normal distribution with unknown mean θ and known variance σ 2. Suppose that a priori θ has N(0, 1) distribution. The posterior variance Var[θ|xn] = σ 2/(n + σ 2) is independent of xn. Let 0 < ∊ < 1. Sampling until Var[θ|xn] < is equivalent to taking a fixed sample size with n > σ 2(1 – ∊)/∊.
15.6 The stopping rule principle
15.6.1 Stopping rules and the Likelihood Principle
In this section we return to our discussion of foundation and elaborate on Theorem 15.1, which states that the Bayesian optimal decision is not affected by the stopping rule. The reason for this result is a general factorization of the likelihood: for any stopping rule ζ for sampling from a sequence of observations x1, x2, ... having fixed sample size parametric model f(xn|n, θ) = f(xn|θ), the likelihood function is
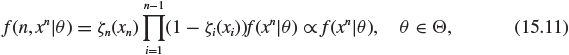
for all (n, xn) such that f(n, xn|θ) = 0.
Thus the likelihood function is the same irrespective of the stopping rule. The stopping time provides no additional information about θ to that already contained in the likelihood function f(xn|θ) or in the prior π(θ), a fact referred to as the stopping rule principle (Raiffa and Schlaifer 1961). If one uses any statistical procedure satisfying the Likelihood Principle the stopping rule should have no effect on the final reported evidence about θ (Berger and Wolpert 1988):
The stopping rule principle does not say that one can ignore the stopping rule and then use any desired measure of evidence. It does say that reasonable measures of evidence should be such that they do not depend on the stopping rule. Since frequentist measures do depend on the stopping rule, they do not meet this criterion of reasonableness. (Berger and Berry 1988, p. 45)
Some of the difficulties faced by frequentist analysis will be illustrated with the next example (Berger and Wolpert 1988, pp. 74.1–74.2.). A scientist comes to the statistician’s office with 100 observations that are assumed to be independent and identically distributed N(θ, 1). The scientist wants to test the hypothesis H0 : θ = 0 versus H1 : θ = 0. The sample mean is ![]() , so that the test statistic is
, so that the test statistic is ![]() . At the level 0.05, a classical statistician could conclude that there is significant evidence against the null hypothesis.
. At the level 0.05, a classical statistician could conclude that there is significant evidence against the null hypothesis.
With a more careful consultancy skill, suppose that the classical statistician asks the scientist the reason for stopping experimentation after 100 observations. If the scientist says that she decided to take only a batch of 100 observations, then the statistician could claim significance at the level 0.05. Is that right? From a classical perspective, another important question would be the scientist’s attitude towards a non-significant result. Suppose that the scientist says that she would take another batch of 100 observations thus, considering a rule of the form:
Take 100 observations.
If
 then stop and reject the null hypothesis.
then stop and reject the null hypothesis.If
 then take another 100 observations and reject the null hypothesis if
then take another 100 observations and reject the null hypothesis if  .
.
This procedure would have level α = 0.05, with k = 2.18. Since ![]() , the scientist could not reject the null hypothesis and would have to take additional 100 observations.
, the scientist could not reject the null hypothesis and would have to take additional 100 observations.
This example shows that when using the frequentist approach, the interpretation of the results of an experiment depends not only on the data obtained and the way they were obtained, but also on the experimenter’s intentions. Berger and Wolpert comment on the problems faced by frequentist sequential methods:
Optional stopping poses a significant problem for classical statistics, even when the experimenters are extremely scrupulous. Honest frequentists face the problem of getting extremely convincing data too soon (i.e., before their stopping rule says to stop), and then facing the dilemma of honestly finishing the experiment, even though a waste of time or dangerous to subjects, or of stopping the experiment with the prematurely convincing evidence and then not being able to give frequency measures of evidence. (Berger and Wolpert 1988, pp. 77–78)
15.6.2 Sampling to a foregone conclusion
One of the reasons for the reluctance of frequentist statisticians to accept the stopping rule principle is the concern that when the stopping rule is ignored, investigators using frequentist measures of evidence could be allowed to reach any conclusion they like by sampling until their favorite hypothesis receives enough evidence. To see how that happens, suppose that x1, x2, ... are sequentially drawn, normally distributed random variables with mean θ and unit variance. An investigator is interested in disproving the null hypothesis that θ = 0. She collects the data sequentially, by performing a fixed sample size test, and stopping when the departure from the null hypothesis is significant at some prespecified level α. In symbols, this means continue sampling until ![]() , where
, where ![]() denotes the sample mean and kα is chosen so that the level of the test is α. This stopping rule can be proved to be proper. Thus, almost surely she will reject the null hypothesis. This may take a long time, but it is guaranteed to happen. We refer to this as “sampling to a foregone conclusion.”
denotes the sample mean and kα is chosen so that the level of the test is α. This stopping rule can be proved to be proper. Thus, almost surely she will reject the null hypothesis. This may take a long time, but it is guaranteed to happen. We refer to this as “sampling to a foregone conclusion.”
Kadane et al. (1996) examine the question of whether the expected utility theory, which leads to not using the stopping rule in reaching a terminal decision, is also prone to sampling to a foregone conclusion. They frame the question as follows: can we find, within the expected utility paradigm, a stopping rule such that, given the experimental data, the posterior probability of the hypothesis of interest is necessarily greater than its prior probability?
One thing they discover is that sampling to foregone conclusions is indeed possible when using improper priors that are finitely, but not countably, additive (Billingsley 1995). This means trouble for all the decision rules that, like minimax, are Bayes only when one takes limits of priors:
Of course, there is a ... perspective which also avoids foregone conclusions. This is to prescribe the use of merely finitely additive probabilities altogether. The cost here would be an inability to use improper priors. These have been found to be useful for various purposes, including reconstructing some basic “classical” inferences, affording “minimax” solutions in statistical decisions when the parameter space is infinite, approximating “ignorance” when the improper distribution is a limit of natural conjugate priors, and modeling what appear to be natural states of belief. (Kadane et al. 1996, p. 1235)
By contrast, though, if all distributions involved are countably additive, then, as you may remember from Chapter 10, the posterior distribution is a martingale, so a priori we expect it to be stable. Consider any real-valued function h. Assuming that the expectations involved exist, it follows from the law of total probability that
Eθ[h(θ)] = Ex[Eθ[h(θ)|x]].
So there can be no experiment designed to drive up or drive down for sure the conditional expectation of h, given x. Let h = I{θ∈ Θ0} denote the indicator that θ belongs to Θ0, the subspace defined by some hypothesis H0, and let Eθ[h(θ)] = π(H0) = π0. Suppose that x1, x2, ... are sequentially observed. Consider a design with a minimum sample of size k ≥ 0 and define the stopping time N = inf{n ≥ k : π(H0|xn) ≥ q}, with N = ∞ if the set is empty. This means that sampling stops when the posterior probability is at least q. Assume that q > π0. Then

where F(xn|n) is the cumulative distribution of xn given N = n. From the inequality above, P(N < ∞) ≤ π0/q < 1. Then, with probability less than 1, a Bayesian stops the sequence of experiments and concludes that the posterior probability of hypothesis H0 is at least q. Based on this result, a foregone conclusion cannot be reached for sure.
Now that we have reached the conclusion that our Bayesian journey could not be rigged to reach a foregone conclusion, we may stop.
15.7 Exercises
Problem 15.1 (Berger 1985) This is an application of optimal stopping in an estimation problem. Assume that x1, x2, ... is a sequential sample from a Bernoulli distribution with parameter θ. We want to estimate θ when the utility is u(θ, a, n) = −(θ – a)2 – nc. Assume a priori that θ has a uniform distribution on (0,1). The cost of sampling is c = 0.01. Find the Bayes three-truncated procedure d3.
Solution
First, we will state without proof some basic results:
The posterior distribution of θ given xn is a (
 ,
,  ).
).Let
 . The marginal distribution of xn is given by
. The marginal distribution of xn is given by
The predictive distribution of xn+1 given xn is

Now, since the terminal utility is u(a(θ)) = −(θ – a)2, the optimal action a* is the posterior mean, and the posterior expected utility is minus the posterior variance. Therefore,
Using this result,

Observe that
Note that

and, similarly,

Thus,

Proceeding similarly, we find,

We can now describe the optimal three-truncated Bayes procedure. Since at stage 0, W0(π,0) = −0.083 < W3(π,0) = −0.0617, x1 should be observed. After observing x1, as W0(πx1,1) = − 0.0655 < W2(πx1,1) = − 0.0617, we should observe x2. After observing it, since we have W0(πx2,2) = W1(πx2, 2), it is optimal to stop. The Bayes action is

Problem 15.2 Sequential problems get very hard very quickly. This is one of the simplest you can try, but it will take some time. Try to address the same question as the worked example in Problem 15.1, except with Poisson observations and a Gamma(1, 1) prior. Set c = 1/12.
Problem 15.3 (From DeGroot 1970) Let π be the prior distribution of θ in a sequential decision problem. (a) Prove by using an inductive argument that, in a sequential decision problem with fixed cost per observation, if V0(πxn) is constant for all observed values xn, then every function Vj for j = 1, 2, ... as well as V0 has this property. (b) Conclude that the optimal sequential decision procedure is a procedure in which a fixed number of observations are taken.
Problem 15.4 (From DeGroot 1970) (a) In the context of Example 15.4.2, for n = 0, 1, ..., j, prove that
where βn is defined as β0 = 0, βn = c(h + (n – 1)ω)(h + nω) for n = 1, ..., j and βj+1 = ∞. (b) Conclude that if the decision maker is allowed to take no more than k observations, then the optimal procedure is to take n* ≤ k observations where n* is such that βn* < ω ≤ βn*+1.