
(2)When the input and output data contain measurement noise, the learning parameter cannot converge to the true value using the LSE objective function.
When the input and output data contain noise, the input and output data pairs can be expressed as:

where are the true values of the input and output data, respectively, are the input and output data contained in the noise, respectively, and the variance is
When learning the parameter of a DFMLS that includes input/output noise, the error cost function [30] is defined as
where is the estimate of the true value
Theorem 1.4 When the input and output data contain noise, the learning parameter converges strongly to the true value of the parameters using the error cost function of (1.14), which is
![]()
Proof: The proof is easy using the proof of Lemma 2 in [23].
1.3.1.2Parameter learning algorithm
According to the analysis in the previous section, we know that the parameters that need to be learned in the DFMLS are further modified according to the iterative equation of the parameter-learning algorithm described in (1.12) and the adaptive training step provided by (1.13). These give the corresponding parameter Learning Algorithm Description:
For the noise variance included in the input and output data of the error cost function and the estimated value of the true value we use the direction of steepest gradient descent correction parameters to obtain the learning algorithm:

Equations (1.15)–(1.20) constitute the parameter-learning algorithm of the whole DFMLS.
1.3.1.3Examples
To verify the validity of the parameter-learning algorithm for the DFMLS proposed in this section, and to illustrate the superiority of this algorithm, we simulate the nonlinear function proposed in [22]. Finally, the algorithm is compared with the algorithm in [22]:
![]()
where is random interference noise with mean and mean square error
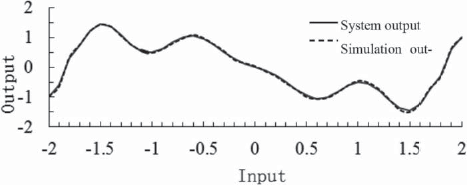
A total of 200 input and output points were uniformly selected as training samples. The noise variance of the input and output samples was set to and the subtraction clustering algorithm [24] was used to cluster the sample data. Thirty-two dynamic fuzzy logic (DFL) rules were extracted, and the corresponding initial parameters were determined. Using the adaptive parameter-learning algorithm proposed in [22] and the method proposed in this section, the algorithm trained 100 steps for the relevant parameters, where was set to 0.01. The results are shown in Figs. 1.9 and 1.10. Figure 1.9 shows the simulated output of the adaptive parameter-learning algorithm, which has a root mean square error of RMSE = Fig. 1.10 shows the parametric-learning algorithm described in this section, which has a root mean square error of RMSE = Obviously, our algorithm is superior.
1.3.2Maximum likelihood estimation algorithm in DFMLS
Incomplete observations and unpredictable data losses in the process of learning mean that many real systems have a lot of missing data. Thus, studies on incomplete data have very important theoretical and practical value in terms of how to use the observed data to estimate the missing data in a certain range. Earlier solutions include the Expectation-Maximization (EM) algorithm [25] proposed by Dempster, Laird, and Rubin in 1977; the Gibbs sampling proposed by S. Geman and D. Geman in 1984; and the Metropolis-Hastings method proposed by Metropolis in 1953 and improved by Hastings. The EM algorithm has been extended into a series of algorithms, such as the EM algorithm proposed by Meng and Rubbin in 1993 and the Monte Carlo EM algorithm. The EM algorithm is an iterative procedure based on the maximum likelihood estimation (MLE) and is a powerful tool. The advantage of the EM algorithm is obvious, as it simplifies a problem through division, but its shortcomings cannot be ignored: its convergence rate is slow, and local convergence and pseudo-convergence phenomena [26] may also occur. The GEM algorithm and Monte Carlo EM algorithm offer various improvements, but the slow convergence rate has not been adequately dealt with. The α-EM algorithm for calculating the entropy rate in information theory can overcome this defect. Therefore, this paper proposes a dynamic fuzzy α-EM algorithm (DFα-EM) for the statistical inference problem of incomplete DFD in a DFMLS.

1.3.2.1DF α-EM algorithm
Definition 1.9 Let be the α – logarithm, where α ∈ (−∞+∞) r ∈ (0, +∞).
Theorem 1.5 For α ∈ (–∞+∞), r ∈ (0, +∞), the α – logarithm has the following properties [27]:
(1)L(−1) (r) = lbr.
(3)L(α)(r) on r is monotonically increasing.
(4)When α < 1, L(α) (r) is a strictly concave function; when α = 1, L(α) (r) is a linear function; when α > 1, L(α) (r) is a strictly convex function.
(5)When α < β, L(α)(r) α ≤ L(β) (r), and if and only if r = 1 equal sign.
The nonlinear DFMLM (see Definition 1.5) can be expressed as

where are independent observational data points; is the response variable of the i th data point; is the k th known explanatory variable vector of the i th data point; is an appropriate function; are regression coefficients; is the mean of and belongs to the dynamic fuzzy open interval is the known deviation function defined on C × Ω satisfying when the equality holds.