
XQuery has a data model that is used to define formally all the values used within queries, including those from the input document(s), those in the results, and any intermediate values. The XQuery data model is officially known as the XQuery 1.0 and XPath 2.0 Data Model, or XDM. It is not simply the same as the Infoset (the W3C model for XML documents) because it has to support values that are not complete XML documents, such as sequences of elements (without a single outermost element) and atomic values.
Understanding the XQuery data model is analogous to understanding tables, columns, and rows when learning SQL. It describes the structure of both the inputs and outputs of the query. It is not necessary to become an expert on the intricacies of the data model to write XML queries, but it is essential to understand the basic components:
- Node
An XML construct such as an element or attribute
- Atomic value
A simple data value with no markup associated with it
- Item
A generic term that refers to either a node or an atomic value
- Sequence
An ordered list of zero, one, or more items
The relationship among these components is depicted in Figure 2-2.
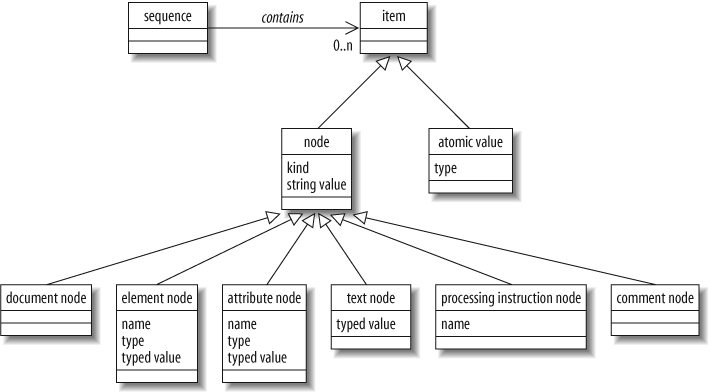
Nodes are used to represent XML constructs such as elements and attributes. Nodes are returned by many expressions, including path expressions and constructors. For example, the path expression doc("catalog.xml")/catalog/product returns four product element nodes.
XQuery uses six kinds of nodes:[*]
- Element nodes
Represent an XML element
- Attribute nodes
Represent an XML attribute
- Document nodes
Represent an entire XML document (not its outermost element)
- Text nodes
Represent some character data content of an element
- Processing instruction nodes
Represent an XML processing instruction
- Comment nodes
Represent an XML comment
Most of this book focuses on element and attribute nodes, the ones most often used within queries. Generally, the book refers to them simply as "elements" and "attributes" rather than "element nodes" and "attribute nodes," unless a special emphasis on the data model is required. The other node kinds are discussed in Chapter 21.
An XML document (or document fragment) is made up of a hierarchy of nodes. For example, suppose you have the document shown in Example 2-2.
Example 2-2. Small XML example
<catalog xmlns="http://datypic.com/cat">
<product dept="MEN" xmlns="http://datypic.com/prod">
<number>784</number>
<name language="en">Cotton Dress Shirt</name>
<colorChoices>white gray</colorChoices>
<desc>Our <i>favorite</i> shirt!</desc>
</product>
</catalog>When translated to the XQuery data model, it looks like the diagram in Figure 2-3.[*]
A family analogy is used to describe the relationships between nodes in the hierarchy. Each node can have a number of different kinds of relatives:
- Children
An element may have zero, one, or several other elements as its children. It can also have text, comment, and processing instruction children. Attributes are not considered children of an element. A document node can have an element child (the outermost element), as well as comment and processing instruction children.
- Parent
The parent of an element is either another element or a document node. The parent of an attribute is the element that carries it.[*]
- Ancestors
Ancestors are a node's parent, parent's parent, etc.
- Descendants
Descendants are a node's children, children's children, etc.
- Siblings
A node's siblings are the other children of its parent. Attributes are not considered to be siblings.

A lot of confusion surrounds the term root in XML processing, because it's used to mean several different things. XML 1.0 uses the term root element, synonymous with document element, to mean the top-level, outermost element in a document. Every well-formed XML document must have a single element at the top level. In Example 2-2, the root element or document element is the catalog element.
XPath 1.0, by contrast, does not use the term root element and instead would call the catalog element the document element. XPath 1.0 has a separate concept of a root node, which is equivalent to a document node in XQuery (and XPath 2.0). A root node represents the entire document and would be the parent of the catalog element in our example.
This terminology made sense in XPath 1.0, where the input to a query was always expected to be a complete, well-formed XML document. However, the XQuery 1.0/XPath 2.0 data model allows for inputs that are not complete documents. For example, the input might be a document fragment, a sequence of multiple elements, or even a sequence of processing instruction nodes. Therefore, the root is not one special kind of node; it could be one of several different kinds of nodes.
In order to avoid confusion, this book does not use either of the terms root element or document element. Instead, when referring to the top-level element, it uses the term outermost element. The term root is reserved for whatever node might be at the top of a hierarchy, which may be a document node (in the case of a complete XML document), or an element or other kind of node (in the case of a document fragment).
Every node has a unique identity. You may have two XML elements in the input document that contain the exact same data, but that does not mean they have the same identity. Note that identity is unique to each node and is assigned by the query processor. Identity values cannot be retrieved, but identities can be compared with the is operator.
In addition to their identity, element and attribute nodes have names.
These names can be accessed using the built-in functions node-name, name, and local-name.
There are two kinds of values for a node: string and typed. All nodes have a string value. The string value of an element node is its character data content and that of all its descendant elements concatenated together. The string value of an attribute node is simply the attribute value.
The string value of a node can be accessed using the string function. For example:
string(doc("catalog.xml")/catalog/product[4]/number)returns the string 784, while:
string(<desc>Our <i>favorite</i> shirt!</desc>)
returns the string Our favorite shirt!, without the i start and end tags.
Element and attribute nodes also both have a typed value that takes into account their type, if any. An element or attribute might have a particular type if it has been validated with a schema. The typed value of a node can be accessed using the data function. For example:
data(doc("catalog.xml")/catalog/product[4]/number)returns the integer 784, if the number element is declared in a schema to be an integer. If it is not declared in the schema, its typed value is still 784, but the value is considered to be untyped (meaning it does not have a specified type).
An atomic value is a simple data value such as 784 or ACC, with no markup, and no association with any particular element or attribute. An atomic value can have a specific type, such as xs:integer or xs:string, or it can be untyped.[*]
Atomic values can be extracted from element or attribute nodes using the string and data functions described in the previous section. They can also be created from literals in queries. For example, in the expression @dept = 'ACC', the string ACC is an atomic value.
The line between a node and an atomic value that it contains is often blurred. That is because all functions and operators that expect to have atomic values
as their operands also accept nodes. For example, you can call the substring function as follows:
doc("catalog.xml")//product[4]/substring(name, 1, 15)The function expects a string atomic value as the first argument, but you can pass it an element node (name). In this case, the atomic value is automatically extracted from the node in a process known as atomization.
Atomic values don't have identity. It's not meaningful (or possible) to ask whether a and a are the same string or different strings; you can only ask whether they are equal.
Sequences are ordered collections of items. A sequence can contain zero, one, or many items. Each item in a sequence can be either an atomic value or a node.
The most common way that sequences
are created is that they are returned from expressions or functions that return sequences. For example, the expression doc("catalog.xml")/catalog/product returns a sequence of four items, which happen to be product element nodes.
A sequence can also be created explicitly using a sequence constructor. The syntax of a sequence constructor is a series of values, delimited by commas, surrounded by parentheses. For example, the expression (1, 2, 3) creates a sequence consisting of those three atomic values.
You can also use expressions in sequence constructors. For example, the expression:
(doc("catalog.xml")/catalog/product, 1, 2, 3)results in a seven-item sequence containing the four product element nodes, plus the three atomic values 1, 2, and 3, in that order.
Important
Unlike node-sets in XPath 1.0, sequences in XQuery (and XPath 2.0) are ordered, and the order is not necessarily the same as the document order. Another difference from XPath 1.0 is that sequences can contain duplicate nodes.
Sequences do not have names, although they may be bound to a named variable. For example, the let clause:
let $prodList := doc("catalog.xml")/catalog/productbinds the sequence of four product elements to the variable $prodList.
A sequence with only one item is known as a singleton sequence. There is no difference between a singleton sequence and the item it contains. Therefore, any of the functions or operators that can operate on sequences can also operate on items, which are treated as singleton sequences.
A sequence with zero items is known as the empty sequence. In XQuery, the empty sequence is different from a zero-length string (i.e., "") or a zero value. Many of the built-in functions and operations accept the empty sequence as an argument, and have defined behavior for handling it. Some expressions will return the empty sequence, such as doc("catalog.xml")//foo, if there are no foo elements in the document.
Sequences cannot be nested within other sequences; there is only one level of items. If a sequence is inserted into another sequence, the items of the inserted sequence become full-fledged items of the new sequence. For example:
(10,(20, 30), 40)
is equivalent to:
(10, 20, 30, 40)
Quite a few functions and operators in XQuery operate on sequences. Some of the most used functions on sequences are the aggregation functions (min, max, avg, sum). In addition, union, except, and intersect expressions allow sequences to be combined. There are also a number of functions that operate generically on any sequence, such as index-of and insert-before.
Like atomic values, sequences have no identity. You can't ask whether (1,2,3) and (1,2,3) are the same sequence; you can only compare their contents.
[*] The data model also allows for namespace nodes, but the XQuery language does not provide any way to access them or perform any operations on them. Therefore, they are not discussed directly in this book. Chapter 10 provides complete coverage of namespaces in XQuery.
[*] The figure is actually slightly oversimplified because, in the absence of a DTD or schema, there will also be text nodes for the line breaks and spaces in between elements.
[*] Even though attributes are not considered children of elements, elements are considered parents of attributes!
[*] Technically, if an atomic value is untyped, it is assigned a generic type called xs:untypedAtomic.