The example script initializes by including the LIB_http and LIB_parse libraries you read about earlier. It also creates an array where the parsed data is stored, and it sets the product counter to zero, as shown in Listing 7-1.
# Initialization
include("LIB_http.php");
include("LIB_parse.php");
$product_array=array();
$product_count=0;
# Download the target (practice store) web page
$target = "http://www.schrenk.com/webbots/example_store";
$web_page = http_get($target, "");
Listing 7-1: Initializing the price-monitoring webbot
After initialization, the script proceeds to download the target web page with the get_http() function described in Chapter 3.
After downloading the web page, the script parses all the page's tables into an array, as shown in Listing 7-2.
# Parse all the tables on the web page into an array $table_array = parse_array($web_page['FILE'], "<table", "</table>");
Listing 7-2: Parsing the tables into an array
The script does this because the product pricing data is in a table. Once we neatly separate all the tables, we can look for the table with the product data. Notice that the script uses <table, not <table>, as the leading indicator for a table. It does this because <table will always be appropriate, no matter how many table formatting attributes are used.
Next, the script looks for the first landmark, or text that identifies the table where the product data exists. Since the landmark represents text that identifies the desired data, that text must be exclusive to our task. For example, by examining the page's source code we can see that we cannot use the word origin as a landmark because it appears in both the description of this week's auction and the list of products for sale. The example script uses the words Products for Sale, because that phrase only exists in the heading of the product table and is not likely to exist elsewhere if the web page is updated. The script looks at each table until it finds the one that contains the landmark text, Products for Sale, as shown in Listing 7-3.
# Look for the table that contains the product information
for($xx=0; $xx<count($table_array); $xx++)
{
$table_landmark = "Products For Sale";
if(stristr($table_array[$xx], $table_landmark)) // Process this table
{
echo "FOUND: Product table
";
Listing 7-3: Examining each table for the existence of the landmark text
Once the table containing the product pricing data is found, that table is parsed into an array of table rows, as shown in Listing 7-4.
# Parse table into an array of table rows $product_row_array = parse_array($table_array[$xx], "<tr", "</tr>");
Listing 7-4: Parsing the table into an array of table rows
Then, once an array of table rows from the product data table is available, the script looks for the product table heading row. The heading row is useful for two reasons: It tells the webbot where the data begins within the table, and it provides the column positions for the desired data. This is important because in the future, the order of the data columns could change (as part of a web page update, for example). If the webbot uses column names to identify data, the webbot will still parse data correctly if the order changes, as long as the column names remain the same.
Here again, the script relies on a landmark to find the table heading row. This time, the landmark is the word Condition, as shown in Listing 7-5. Once the landmark identifies the table heading, the positions of the desired table columns are recorded for later use.
for($table_row=0; $table_row<count($product_row_array); $table_row++)
{
# Detect the beginning of the desired data (heading row)
$heading_landmark = "Condition";
if((stristr($product_row_array[$table_row], $heading_landmark)))
{
echo "FOUND: Table heading row
";
# Get the position of the desired headings
$table_cell_array = parse_array($product_row_array[$table_row], "<td", "</td>");
for($heading_cell=0; $heading_cell<count($table_cell_array); $heading_cell++)
{
if(stristr(strip_tags(trim($table_cell_array[$heading_cell])), "ID#"))
$id_column=$heading_cell;
if(stristr(strip_tags(trim($table_cell_array[$heading_cell])),
"Product name"))
$name_column=$heading_cell;
if(stristr(strip_tags(trim($table_cell_array[$heading_cell])), "Price"))
$price_column=$heading_cell;
}
echo "FOUND: id_column=$id_column
";
echo "FOUND: price_column=$price_column
";
echo "FOUND: name_column=$name_column
";
# Save the heading row for later use
$heading_row = $table_row;
}
Listing 7-5: Detecting the table heading and recording the positions of desired columns
As the script loops through the table containing the desired data, it must also identify where the pricing data ends. A landmark is used again to identify the end of the desired data. The script looks for the landmark Calculate, from the form's submit button, to identify when it has reached the end of the data. Once found, it breaks the loop, as shown in Listing 7-6.
# Detect the end of the desired data table
$ending_landmark = "Calculate";
if((stristr($product_row_array[$table_row], $ending_landmark)))
{
echo "PARSING COMPLETE!
";
break;
}
Listing 7-6: Detecting the end of the table
If the script finds the headers but doesn't find the end of the table, it assumes that the rest of the table rows contain data. It parses these table rows, using the column position data gleaned earlier, as shown in Listing 7-7.
# Parse product and price data
if(isset($heading_row) && $heading_row<$table_row)
{
$table_cell_array = parse_array($product_row_array[$table_row], "<td", "</td>");
$product_array[$product_count]['ID'] =
strip_tags(trim($table_cell_array[$id_column]));
$product_array[$product_count]['NAME'] =
strip_tags(trim($table_cell_array[$name_column]));
$product_array[$product_count]['PRICE'] =
strip_tags(trim($table_cell_array[$price_column]));
$product_count++;
echo"PROCESSED: Item #$product_count
";
}
Listing 7-7: Assigning parsed data to an array
Once the prices are parsed into an array, the webbot script can do anything it wants with the data. In this case, it simply displays what it collected, as shown in Listing 7-8.
# Display the collected data
for($xx=0; $xx<count($product_array); $xx++)
{
echo "$xx. ";
echo "ID: ".$product_array[$xx]['ID'].", ";
echo "NAME: ".$product_array[$xx]['NAME'].", ";
echo "PRICE: ".$product_array[$xx]['PRICE']."
";
}
Listing 7-8: Displaying the parsed product pricing data
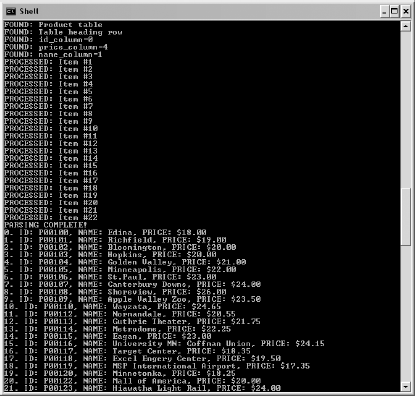
As shown in Figure 7-2, the webbot indicates when it finds landmarks and prices. This not only tells the operator how the webbot is running, but also provides important diagnostic information, making both debugging and maintenance easier.
Since prices are almost always in HTML tables, you will usually parse price information in a manner that is similar to that shown here. Occasionally, pricing information may be contained in other tags, (like <div> tags, for example), but this is less likely. When you encounter <div> tags, you can easily parse the data they contain into arrays using similar methods.