
Chapter 4. Working with duplicate code
This chapter covers
- The hidden cost of duplicate code
- Identifying duplications
- Realizing the impact of code duplications
- Finding duplications across multiple projects
- Cleaning up your duplications
When you start a new project, you have a clean code base with no duplications, unless you copied another project to start with. Every single line of code is written from scratch, and you have absolute confidence that neither you nor your teammates will introduce any duplications.
As the project progresses, you and your teammates communicate regularly and write good, clean code. You probably think you’ve done everything you need to, to avoid duplications. But over time they still creep in, because you can’t totally avoid code duplications no matter how hard you try.
Because duplications always creep in, you need an efficient way to track and eventually remove them. You’ve already seen how SonarQube helps you measure test coverage and identify issues. Following a similar path, we’ll show you how easy SonarQube makes it to spot repeated code blocks in a project and across multiple projects. We’ll start from the comments and duplications widget on the dashboard, and progress to the Duplications drilldown and the Duplications tab in the file detail view.
Unfortunately, code duplications exist in every project. Even if this is the least controversial deadly sin, everybody agrees that duplication is bad. The more complex a software system, the more code blocks are likely to be repeated. This chapter will show you how duplications affect your code, what metrics are available for tracking them, and how to get started eliminating those duplications by applying basic refactoring patterns.
4.1. The hidden cost of duplicate code
Friday morning. Your team is on track to roll out a major relaunch of your online coin store on Monday. Suddenly, a guy from the QA team runs in. “The new version doesn’t include the 10% discount we’re offering for the next three weeks. We can’t release it!”
After some frantic debugging, you pin down the problem and commit the changes. Once the QA team verifies the fix, you head off to lunch, incredibly relieved that you didn’t have to spend the whole weekend working on the issue.
Monday noon. Customer Service says they’ve gotten several emails from customers complaining that they didn’t get the discount you’re advertising. And because you claimed to fix the problem on Friday (and then took a long lunch), your boss is apoplectic. You dive back into the code and quickly come to an alarming conclusion: there are two different methods for calculating the discount. You fixed only half the problem on Friday.
If only you’d known what SonarQube had to say about your duplications. If only you’d had access to what’s shown in figure 4.1.
Figure 4.1. SonarQube detects duplications in files and projects and also across projects.
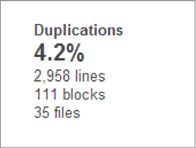
SonarQube reports duplication by line, block, and file. If you’ve lived through this type of situation, you already know that duplicate code is one of the highest risk factors for bug propagation. But why does code get repeated again and again?
Survey the developers you work with, and ask them if copying and pasting code is acceptable. Not only will most of them say code duplications are evil, but they’ll probably also say they’ve never copy/pasted code themselves. Now analyze your code base with SonarQube. You’ll probably see that nearly every developer has duplicated code. Can you explain this paradox? Can they?
Table 4.1 lists some of the most common reasons for duplicated code, with the most likely ones first. Which ones apply to your organization?
Table 4.1. Common causes of code duplication
|
Description |
|
|---|---|
| Laziness | Reusing code that you know works is always tempting, even if it’s written by someone else. Besides, copying and pasting several lines of code is faster and shows productivity with less effort. |
| Risk of regressions | Source code isn’t covered by unit tests and integration tests, so to prevent any regression, this code is duplicated (and that may not be the worst option if there’s no safety net). |
| Absence of refactoring | It’s common to start developing functionality by copying an existing piece of software. You then improve it until it does what you want. Finally, you refactor to remove the duplication—but this step is often forgotten |
| Strict deadlines; never enough time | Some developers see copying existing, tested code as more efficient than refactoring, especially when deadlines loom. We’ve been there hundreds of times, and even after many years of coding, we’re still tempted to copy and paste. |
| Poor team communication | Lack of communication can lead to duplications. It’s more likely to happen on large development teams, where communication is more difficult. We saw one project where three folks wrote the same utility method, rather than asking if it already existed. Things get even worse in large organizations with multiple development teams. |
| Misunderstandings | Green developers have a tendency to slap in existing code that seems to do what they want, rather than working to understand the real problem or underlying business logic. Aside from leading to dirty code, this practice means they don’t develop real knowledge of the problem’s domain. |
| Merging projects | Merging projects isn’t a common task, but when it happens, it’s likely that the newly created/merged project will contain duplicated code. One reason is that coders tend to need similar utilities in every project, so of course they copy/paste already-proven code from previous projects. If the merged projects had similar requirements, then it’s even more likely that similar code may have migrated from one to the other, producing duplications in the merged project. |
Now that you’ve seen that code duplications exist in software systems and that there are many reasons for them, let’s move on and discuss what SonarQube has to tell you about finding segments of repeated (copied and pasted) code.
4.2. Identifying duplications
We’ve said several times that SonarQube uses existing, best-of-breed technologies and aggregates the results for your convenience, but it doesn’t do that across the board. When it makes sense, the creators of SonarQube roll up their sleeves and start from scratch to build code-quality engines that are superior to what’s already available. That’s the case with duplications. SonarQube’s detection engine finds duplications at three different levels:
- Duplications in the same file
- Duplications in different files in a project
- Duplications across multiple projects (off by default)
Duplication detection is one of the core functionalities of the SonarQube platform, so it’s available at all three levels natively, and with a uniform presentation, for every language you can analyze under SonarQube.
4.2.1. Finding your first duplication
To get your feet wet with duplication, look at figure 4.2, which shows the default project dashboard’s comments and duplications widget. SonarQube provides one widget for both, with duplications on the right in the widget.
Figure 4.2. Duplications widget information
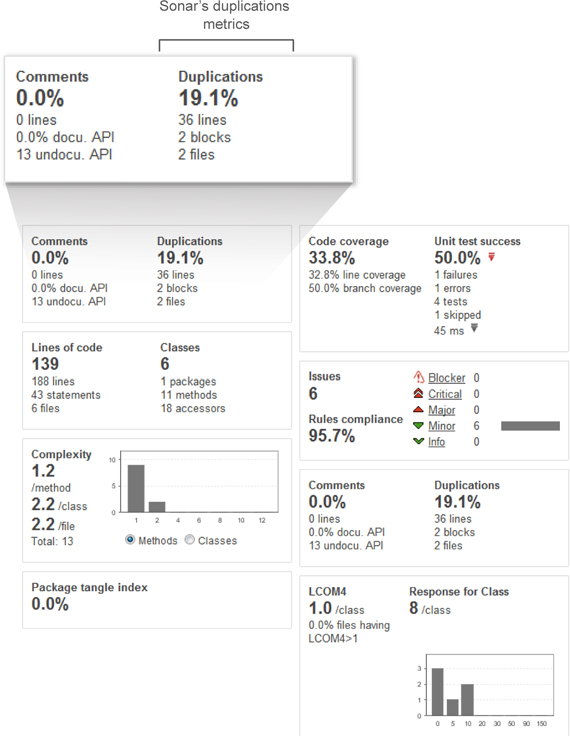
Figure 4.2 says there are 36 duplicate lines in two files. Before we proceed to the Duplications drilldown, let’s take a quick look at those files, which come from the online coin store we looked at earlier. The problem in the example was duplications in different files in a project. The business requirement was to implement a default discount policy for all purchases made in the next three weeks. Unfortunately, it was only half done when the site relaunched on Monday, because of the necessary changes we made to only one of two files.
The files involved are related to the requirement that the site charge a sales tax that varies based on the customer’s country. To achieve this, there are two different classes: Order and InternationalOrder. Listing 4.1 shows the relevant part of the Order class that is responsible for handling orders from U.S. residents.
Listing 4.1. Order class

Listing 4.2. InternationalOrder class

You can easily spot the duplications. At a glance, you can see that the getTotal() method ![]() is exactly the same for both classes. Moreover, the method that returns the discount percent
is exactly the same for both classes. Moreover, the method that returns the discount percent ![]() is also identical for both classes. This code may look simplistic, but we’ve seen real code much like it. Whether the examples
are simplistic or sophisticated, the general idea remains the same: duplicate code means duplicate work down the road.
is also identical for both classes. This code may look simplistic, but we’ve seen real code much like it. Whether the examples
are simplistic or sophisticated, the general idea remains the same: duplicate code means duplicate work down the road.
4.2.2. Finding duplications on a larger scale
In the previous code listings, you can find the duplications fairly easily. It’s not hard to identify code repetitions in a few classes and a couple dozen lines. But what about in a hundred lines? A thousand? Or more? You’d need days to manually scan your source code just to find duplications in the same file, let alone across multiple files or projects.
Note
We strongly believe that any duplication density over 0% is a problem, one you need to address as soon as possible, no matter how small the number.
Clearly, manual detection is impractical at best. Instead, the best practice is to run a SonarQube analysis on a regular basis. This can be after each commit or at predefined intervals, depending on your continuous inspection strategy. Chapter 9 goes into detail on continuous inspection, but for now let’s assume that you run an analysis every time the code base is modified.
4.2.3. SonarQube’s duplication metrics
We’ve said that duplications are bad, but also that you can’t totally avoid them. You’re probably wondering what the duplication numbers we’ve shown mean and when you should start worrying about them. We’ll answer those questions beginning with a brief definition of each duplication-related metric in the comments and duplications widget (see table 4.2).
Table 4.2. SonarQube duplications-related metrics
|
Metric description |
|
|---|---|
| Duplicated Lines | Absolute number of physical lines (not just lines of code) of source code involved in at least one duplication. Physical lines means all carriage returns in a file. |
| Duplicated Blocks | Absolute number of duplicated source code blocks. |
| Duplicated Files | Absolute number of source files that contain duplicated lines. |
| Density of Duplicated Lines | Percentage shown at the top of the Duplications section, calculated by dividing Duplicated Lines by the total physical lines in the project multiplied by 100. |
The first three metrics in table 4.2 are pretty clear. The only complicated one is Density of Duplicated Lines. Imagine that you have a project with a total of 1,000 physical lines of code, and the SonarQube analysis finds 1 one block of 5 lines repeated 10 times, for 50 duplicated lines. That means Density of Duplicated Lines is 50 / 1000 * 100 = 5%.
Note that all metrics are calculated not only across each project, but also on a submodule, package, and file basis. This makes it even easier to find the sections of your software with the most duplications.
4.2.4. Drilling in: from the duplications widget to the Duplications tab
To start chasing your duplications, click any metric in the comments and duplications widget, and you’ll land at the common Drilldown metrics view (see figure 4.3). At upper left is the package panel: a list of the project’s packages with duplications. At upper right is the file panel showing the files with duplications.
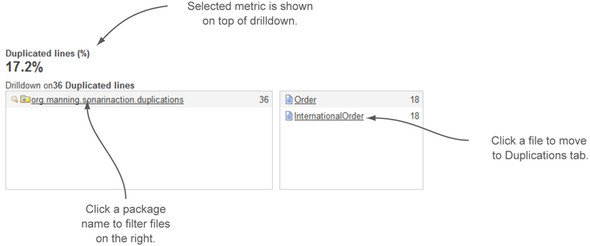
Figure 4.3. Drilldown view example: density of duplicated lines
We’ve mentioned that SonarQube detects duplications on three levels: in a file, throughout a project, and across multiple projects of the same language. We’ll talk here about the first two levels, and come back to how you can spot code copied from one project to another.
In the package and file panels, the number to the right of each item is the value of the metric you clicked in the comments and duplications widget in the dashboard for that package or file—with one exception. If you click Duplicated Lines %, then the number to the right of each item in the package and file panels is the number of lines, rather than their density in the project. Either way, descriptive messages in the drilldown view header make it clear which metrics are being displayed.
From the drilldown header in figure 4.3, you see the following:
- 17.2% of the code is flagged as duplicated.
- 36 lines participate in duplications.
- Two files (Order and InternationalOrder classes), both found under the org.manning.sonarinaction.duplications package, have 18 duplicate lines each.
This information is useful and important, but it’s just the tip of the iceberg. Click a filename, and the file detail view for that file is added to the screen, with the Duplications tab activated. This is where you can see exactly which lines of the file are duplicated and exactly what it is that they duplicate. Figure 4.4 shows the file detail view for the Order class in the example project.
Figure 4.4. The Duplications tab view of a file/class
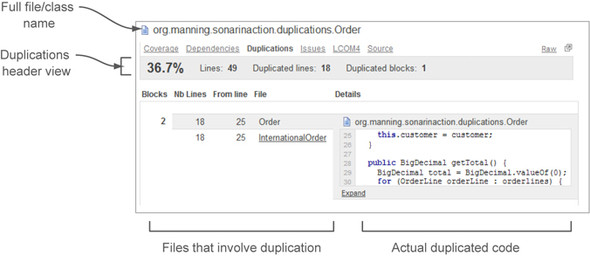
There’s a lot going on in figure 4.4, so we’ll break it into three parts, starting with the top section (the file header), which shows a metric summary for the current file/class (see figure 4.5). Note that whereas the header section of the Duplications drilldown varies based on which metric you chose on the dashboard, the Duplications tab is always the same.
Figure 4.5. The Duplications tab’s file header
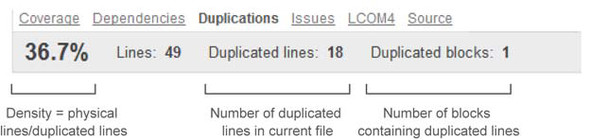
The percentage displayed at left in the header is the density of duplications in the current file. Next is Lines, which is the number of physical lines in the file. Again, don’t confuse physical lines and lines of code, which are computed differently.
Note
The lines of code (LOC) calculation varies slightly from language to language, but for Java it’s as follows: LOC = physical lines – blank lines – comment lines – header file comments.
The Duplicated Lines number is the absolute number of repeated lines; and the Duplicated Blocks number, at right in the header, is the number of code blocks those duplicated lines are spread across. To sum up, the Duplications tab header includes a file-level view of three out of the four duplication metrics calculated by SonarQube, and it’s easy to see why the fourth, Duplicated Files, isn’t included here.
Below the header, SonarQube shows you the duplicated blocks in your file. They’re presented in a two-column grid, with one row for each duplicated block. At left is high-level information about the block, including the exact position of the duplicated code in the current file/class, as shown in figure 4.6.
Figure 4.6. Locate the exact position of duplicated code in two classes.
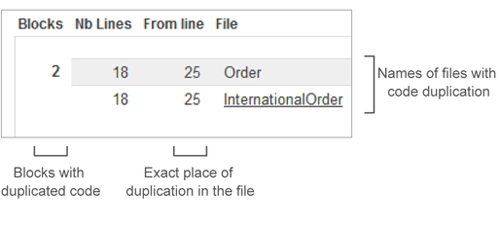
The left side of each row is broken into a subgrid, with one row for each instance of the duplicated block (one row for each time it was duplicated). It starts at the far left in figure 4.6 with a simple count of the number of times the code block under examination has been duplicated. You’ll see a subrow in this column for each one of those blocks.
Each subrow ends with the name of a file containing a copy of this block. For first-level duplications (copies in the same class), the filenames are identical. In the example, which is a second-level duplication (from one class to another), the Nb Lines value shows that 18 lines of code are the same in the classes Order and InternationalOrder. Note that the number of lines listed from file to file isn’t always the same. SonarQube’s duplication-detection mechanism is sophisticated enough to pick up a duplicated block even when there are whitespace differences from one copy to the next.
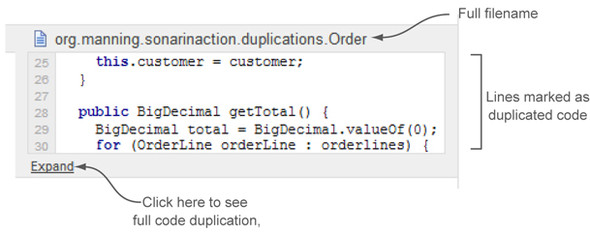
Next to NB Lines in each subrow is the From Line metric: the exact line number in each file where the duplicated block starts. Click the name of a file, and the column on the right shows a few lines of the duplicated block. By default, the code view is collapsed to hide very large blocks of code. But you can expand it to see the full duplication by clicking Expand, as shown in figure 4.7. Once a duplicated block has been expanded to its full length, the Expand link is swapped for a Collapse link, which does what you would think.
Figure 4.7. Viewing all lines containing detected code repetition
Now that you know how to find duplications, you’re probably asking yourself one of two questions: either “Why do I care?” or “How do I fix them?” They’re both good questions, and we’ll answer them next, starting with why duplications are important and how they affect your project’s overall quality.
4.3. Realizing the impact of code duplication
At this point you may be wondering, “What’s wrong with having duplicate code? I have unit tests that cover all the lines and branches, and I know the code is bug-free, so why fix something that doesn’t appear to be broken?” Our experience, though, has shown that most of the time, when there are lots of duplicated lines, there are few unit tests (see “Risk of regression” in table 4.1).
At first glance, that seems fair enough; but as our coin store example demonstrated, even bug-free, fully unit-tested duplicate code can cause problems. One more argument is that, as we’ll discuss later in this section, the cost of maintaining software is commonly said to be directly proportional to the number of lines in the software. Next we’ll delve more deeply into why duplication is a bad idea.
4.3.1. The DRY principle: minimizing and eliminating duplications
Don’t Repeat Yourself (DRY) is a software engineering principle that should be applied to every aspect of a software project. It focuses on minimizing or eliminating duplications among the resources of a system, especially in code.
One of the basic concepts of DRY is that it’s more efficient and productive to keep a single copy of each resource than to keep several copies. This may sound familiar to those acquainted with database normalization, but it applies beyond just your data. That’s because having multiple copies of anything, whether data or algorithms, not only means more work when there are changes, but also could mean that you end up with some outdated copies, which is the most dangerous side effect of duplication.
Think back for a minute to the coin store example, with its Order and InternationalOrder classes, each with identical getTotal() and getDiscount() methods. Forgetting to update the InternationalOrder class with the promotional discount had a huge impact on the system, the customers, and the business in general. How many of the customers who didn’t get that discount will come back to place another order? Duplicated code is responsible for a lot of bugs, and it can have farreaching impacts, especially in systems that are continuously evolving to reflect market needs.
4.3.2. Duplications vs. size and complexity
Having outdated copies of duplicated code is the most obvious problem caused by duplications, but there are others. Your project’s size and complexity are pointlessly increased by each code repetition. You may think that’s acceptable for small projects, but consider a project with 100,000 lines of code and only 20% duplications. That 20% means you have an extra 20,000 obsolete lines of code to maintain.
Note
By the terms obsolete code and useless code, we don’t mean the code isn’t working or used by the application; but you should refactor this part of your system in order to eliminate as many duplicated lines as is feasible. In section 4.5, we’ll give you some tips on how to clean up this obsolete code.
Furthermore, code duplication is responsible for large blocks of code with only minor differences, sometimes only a couple of lines or, even worse, only a few characters apart.
The comprehension of this code is a time-consuming task that makes further modifications or enhancements extremely difficult. That means the maintainability of your software decreases dramatically. And last but not least, repeated code, especially between methods with different method signatures, can hide the real purpose of each method, making it harder to decide which one to use.
4.4. Finding duplications across multiple projects
Now that you know how to track and identify duplications in the same project, it’s time to explore a noteworthy feature of SonarQube: duplication detection across multiple projects. This functionality is unique; you can’t find it in any other relevant tool.
Because the duplication-detection engine is core functionality of SonarQube, it’s available for all the languages you can analyze with SonarQube. Cross-project duplication detection isn’t on by default, so this section will show you how to activate it and how to recognize cross-project duplications in the file detail view’s Duplications tab.
4.4.1. Turning on cross-project duplication detection
By default SonarQube is installed with cross-project duplication detection disabled, perhaps because its use incurs a performance penalty during analysis. But it’s a powerful tool, and we urge you to turn it on.
This may increase the time needed for completing an analysis, especially when you have a lot of projects of the same language in SonarQube, but the ROI of cross-project duplication detection is worth the hit to analysis speed.
You can toggle its use at a global level or on a project-by-project basis. To set it globally, a logged-in administrator can choose Configuration under the Settings menu at upper right in the interface. A submenu is added next to the left rail; choose Duplications there, as shown in figure 4.8.
Figure 4.8. Enabling cross-project duplication detection

In the Duplications settings, choose True for Cross Project Duplication Detection, and save your changes. From now on, all SonarQube analyses will perform cross-project duplication detections. Additionally, you can turn this feature on or off for a particular project by modifying the same attribute under the project settings configuration.
Note
Remember that if cross-project duplication detection is turned off for a project, SonarQube won’t look for cross-project duplications when the code is analyzed. But the project’s source code will still be available for cross-project duplication detection to other projects with this option enabled.
4.4.2. Cross-project duplications in source code tab
After activating cross-project duplication detection, you’ll need to run a new analysis to begin seeing duplications. In this case, to show how duplications across multiple projects are displayed in the file detail view, we reanalyzed the sample project with a different project key.
Once you turn on cross-project detection and start running new analyses, the first thing you notice is that your duplication metrics jump dramatically. This is expected and perfectly normal. But if you expected the duplication density to go to 100%, you might wonder why it’s sitting below that. It’s because the duplication-detection engine only tallies up duplicated lines of code. When counting duplicate lines, it ignores import statements as well as any blank lines or comments that may be embedded in a duplicated block. As we mentioned earlier, the density of duplicated code is based on physical file lines (including those lines the duplications engine ignored), so you should expect to see a number below 100%.
Now let’s examine the Duplications tab in the file detail view. If you’re looking at a file with cross-project duplications, you’ll probably see something like figure 4.9, which is similar to what we showed you earlier.
Figure 4.9. Cross-project duplication in source code tab
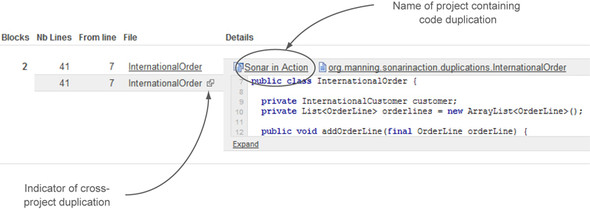
In the figure, notice that InternationalOrder is shown twice. As you can see, there is a special icon next to one of the class names, which indicates that the class belongs to another project. Click the icon or the class name to see part of the duplicated block. When you do, the class’s project name (linked to its dashboard) is displayed to the left of the full class name (linked to its file detail view), making it even easier to identify the exact position of code repetitions, even between projects. Expanding and collapsing code blocks works the same way across projects as within a project.
Because our example of cross-project duplications analyzed the same project under two different project keys, figure 4.9 shows the same class name displayed twice: once for each project it appears in. Unfortunately, this wholesale duplication of classes isn’t as outlandish an example as it should be. We’ve seen utility classes copied in their entirety from one project to another (class name intact!), not just in private enterprises, but also among well-known open source projects (but not SonarQube).
Note
As you’ll learn, you can analyze multiple branches of the same project by using the sonar.branch property. You may think that in this case, if cross-project duplication detection is turned on, all code would be marked as duplicated. To avoid this situation, SonarQube turns off this feature whenever you analyze a project with the sonar.branch property.
Now that you’ve seen SonarQube’s suite of duplication-related functionality, it’s time to look at how to clean up the mess. If you’re not a programmer, you may want to skip to section 4.6, “Related plugins.”
4.5. Cleaning up your duplications
The purpose of this book isn’t just to teach you how to use SonarQube, but also to give you adequate examples to improve your code quality and help you evolve as a software engineer. Getting a list of code repetitions is a great start, but just looking at them won’t fix the problem, unless you have some of Uri Geller’s talents.
This section includes practical examples of applying software-engineering best practices to code-duplication issues. First we’ll look at the extract pattern, then we’ll explain the delegate pattern, and finally we’ll present a case in which you need to create a new library to eliminate duplications across multiple projects.
4.5.1. Introduction to refactoring patterns
Teaching you refactoring patterns in general is out of the scope of this book. For that, you should consult Refactoring to Patterns by Joshua Kerievsky (Addison-Wesley, 2004) or Refactoring: Improving the Design of Existing Code by Martin Fowler et al. (Addison-Wesley, 1999). Those two books are about refactoring code using best practices that are typically referred to as patterns. The following examples use patterns that move code within the same file or to another file in the same project. Before you see them in action, here’s a brief explanation of each pattern:
- Extract method— Used for duplicate code in the same class. All you have to do is create a new method, place the repeated block of code in this method, and replace the duplicated blocks with invocations of the new method.
- Pull up field— Usually used in conjunction with the extract method. The basic idea is to move a field used in two or more subclasses up to a superclass.
- Extract superclass— Applied in the case of code repetitions in different classes. When classes have the same or even similar features, consider moving those features to a superclass.
- Extract class— A combination of the extract method and extract superclass, applied mainly to unrelated classes. Move code that’s repeated in unrelated classes to a new utility class, and then invoke its methods from the source classes.
4.5.2. Applying patterns to remove code duplication
Going back to the Order and InternationalOrder classes, let’s look at how to eliminate the duplications between them. Thanks to SonarQube, you know exactly where the problem code is, so we can easily start refactoring our classes in order to get rid of it.
From a design perspective, the classes have a lot in common. Each is responsible for holding information about an order placed by a customer (domestic or international). The code that returns the total amount is exactly the same from class to class, but the classes differ in how they compute the discount and sales tax. Because the sales tax is based on a customer’s country, you don’t need to make any changes in the getTax() method. But you do need to do something about the other two methods. Because you have similar classes with duplicate functionality, the extract superclass method is the best pattern to use.
Refactoring is a practice that developers should learn and be able to apply in their everyday activities. But it requires experience in software engineering, discipline, and broad knowledge of many related topics. Among its main purposes are optimizing code, removing duplications, and increasing maintainability.
There is one thing to consider every time you want to refactor your code: ensure that the affected classes are covered by the correct unit tests and that after you complete the refactoring, the same unit tests aren’t failing. Only then can you be confident that you haven’t created any bugs or other side effects.
Now that you know which pattern to use, you’re ready to begin refactoring. Start by creating a new class, AbstractOrder, and move the getTotal() and getDiscount() methods into it, as well as any shared members and their getters and setters. Because getTotal() calls getTax(), you also need to specify an abstract getTax() method to be implemented by your concrete subclasses. (That getTax() call is why we made this an abstract class to start with; another option would have been to leave the parent class concrete and implement an overridable, default version of getTax().) The following listing details the AbstractOrder class after refactoring.
Listing 4.3. AbstractOrder class
public class AbstractOrder {
private List<OrderLine> orderlines = new ArrayList<OrderLine>();
//Add/remove order line code omitted
public BigDecimal getTotal() {
BigDecimal total = BigDecimal.valueOf(0);
for (OrderLine orderLine : orderlines) {
total = total.add(orderLine.getOrderLineTotal());
}
BigDecimal discount = total.multiply(getDiscount());
total = total.subtract(discount);
BigDecimal tax = total.multiply(getTax());
total = total.add(tax);
return total;
}
public final BigDecimal getDiscount(){
return BigDecimal.valueOf(0.10);
}
# Abstract method to be implemented by concrete classes
protected abstract BigDecimal getTax();
}
With the superclass in place, you can refactor the Order and InternationalOrder classes as shown in listings 4.4 and 4.5.
Listing 4.4. Refactored Order class

Both refactored classes now extend from the AbstractOrder class and implement the abstract method getTax(). The code contained in that method is the only difference in those classes. The rest of their behavior, which is the same, is inherited by the AbstractOrder class.
Listing 4.5. Refactored InternationalOrder class

With these modifications in place, a new SonarQube analysis will show that you’ve not only removed any duplications between classes, but also decreased the complexity of your code. It looks much cleaner than before and is much more maintainable. Next, we’ll finish our examples by considering when you might need to create a new commons library.
4.5.3. Time for a new commons library?
In the previous section, we looked at evolving code to eliminate duplications in a single project. Assume that once you finish that project, you start a new one. After a few weeks, you find yourself in a similar situation, where you again need to use an Order class.
Remembering your work on the previous project, you copy the classes you need into your new project, feeling a little smug that you didn’t have to rewrite them. What you’ve forgotten is that SonarQube’s detection mechanism can identify code duplications across multiple projects. Because both projects now have exactly the same Order class implementation, SonarQube registers a new duplication for each file.
How you should handle this kind of duplication? It’s time to start thinking about creating a new library for the functionality that’s common to both projects. The process of creating such a library is similar to the process you used to create the AbstractOrder class.
Apache is the father of commons libraries. The purpose of such libraries is to develop and maintain reusable Java components that can be used by other applications or systems. Currently, several commons libraries cover various fields of interest, such as string manipulation, file I/O, logging, and many more. For more information, see Apache’s website at http://commons.apache.org/.
After creating the new library project, follow these steps to refactor your code:
1. Move the AbstractOrder class and its concrete implementations to the new library.
2. Add the library as a dependency in your existing projects.
3. Modify your code to access the classes of the new library.
4. Run a SonarQube analysis, and pat yourself on the back when it shows zero duplications.
4.6. Related plugins
SonarQube has become a standard for code-duplication detection, and it’s by far the most stable and mature tool in this category. But it can be extended by the development of new plugins (if you want to create one, check out chapter 16 of this book), with brilliant ideas for more functionalities and features. This section covers a plugin that’s related to duplicated code and that extends SonarQube’s default metrics and capabilities: the Useless Code Tracker plugin.
If you tried to give another definition for duplicate code, you’d probably end up with something like “lines that are useless and could be deleted from the code base.” The Useless Code Tracker plugin reports on exactly this kind of metric by adding to a SonarQube analysis the meaningful numbers explained in table 4.3.
Table 4.3. Metrics of the Useless Code Tracker plugin
|
Metric name |
Metric description |
|---|---|
| Lines in Duplications | Although it may seem identical to Duplicated Lines as described in table 4.2, this metric is a little more sophisticated. It reports actual lines that may be removed from your code, not just duplicated lines. For example, if your code has 100 duplicated lines in four blocks (that is, 25 lines repeated four times), then the duplicated lines to reduce should be 75. |
| Lines in Unused Private Methods | To activate this metric, you have to add one of two rules to your rule set: PMD:UnusedPrivateMethod or SQUID:UnusedPrivateMethod. See chapter 13 for more detailed descriptions of rule profiles. |
| Lines in Unused Protected Methods | To activate this metric, you have to add one of two rules to your rule set: PMD:UnusedProtectedMethod or SQUID:UnusedProtectedMethod. See chapter 13 for more detailed descriptions of rule profiles. |
You can add the plugin’s widget to any dashboard, and because it isn’t categorized, you’ll find it if you select None as the widget’s filter. Figure 4.10 shows how the metrics described in table 4.3 are displayed to the end user and what they represent.
Figure 4.10. Useless Code Tracker plugin
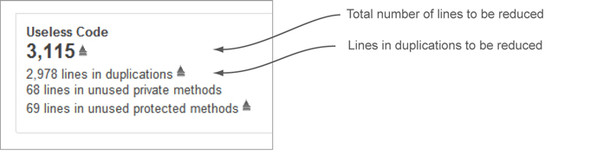
The power of this plugin is that it doesn’t execute any duplication detection (including cross project) itself, but rather relies on SonarQube’s embedded mechanism and the results of duplication analysis. This means it can be used with any language with duplication detection. To see it in action, add the Useless Code Tracker plugin to your dashboard and run a new analysis. We’re sure you’ll find it useful.
4.7. Summary
At this point, you understand how to use SonarQube to detect duplicate code. Even better, you understand where duplications come from, why they’re a basic software quality issue, and how they contribute to new bugs.
Face it! You can’t avoid the creation of duplicate code. But SonarQube will help you find code duplications in the same file, in the same project, or even across multiple projects, so you can clean up your duplications.
There are four metrics related to code duplication. The most important is the density of duplications, which represents the number of duplicated lines relative to the total physical lines of the project. SonarQube shows you all the duplications metrics on a project, package, or class basis. Further, you can use the Duplications tab in the file detail view to see the location of a duplication in a class.
Just looking at your duplications isn’t enough. Knowing that you have code duplications is the first step; eliminating them is the final goal. You can begin to accomplish that with the patterns you learned here, such as extract method and extract class.