
To get a copy of the SOTU addresses, we'll visit the website for the American Presidency Project at the University of California, Santa Barbara (http://www.presidency.ucsb.edu/). This site has the text for the SOTU addresses as well as an archive of many messages, letters, public papers, and other documents for various presidents. It's a great resource for looking at political rhetoric.
In this case, we'll write some code to visit the index page for the SOTU addresses. From there, we'll visit each of the pages that contain an address; remove the menus, headers, and footers; and strip out the HTML. We'll save this in a file in the data directory.
We won't see all of the code for this. To see the rest, look at the download.clj file in the src/tm_sotu/ directory in the downloaded code.
To handle downloading and parsing the files, we'll use the Enlive library (https://github.com/cgrand/enlive/wiki). This library provides a DSL to navigate and pull data from HTML pages. The syntax and concepts are similar to CSS selectors, so if you're familiar with those, using Enlive will seem very natural.
We'll tackle this problem piece by piece. First, we need to set up the namespace and imports for this module with the following code:
(ns tm-sotu.download
(:require [net.cgrand.enlive-html :as enlive]
[clojure.java.io :as io])
(:import [java.net URL]
[java.io File]))Now, we can define a function that downloads the index page for the SOTU addresses as shown in the following code (http://www.presidency.ucsb.edu/sou.php). It will take this URL as a parameter, download the resource, pull out the list of links, and remove any text that isn't a year:
(defn get-index-links [index-url]
(->
index-url
enlive/html-resource
(enlive/select [:.doclist :a])
filter-year-content?))Let's walk through these lines step by step:
- First,
index-urlis just the URL of the index page that needs to be downloaded. This line just kicks off the processing pipeline. - The
enlive/html-resourcefunction downloads and parses the web page. Most processing that uses Enlive will start with this function. - Now,
(enlive/select [:.doclist :a])only pulls out certain anchor tags. The vector that specifies the tags to return is similar to a CSS selector. In this case, it would be equivalent to the.doclist :aselector. I found which classes and tags to look for by examining the source code for the HTML file and experimenting with it for a few minutes. - Finally, I called
filter-year-content?on the sequence of tags. This looks at the text within the anchor tag and throws out any text that is not a four-digit year.
The get-index-links function returns a sequence of anchor tags that need to be downloaded. Between the tag's href attribute and its content, we have the URL for the address and the year it was delivered, and we'll use both of them.
The next step of the process is the process-speech-page function. It takes an output directory and a tag, and it downloads the page the tag points to, gets the text of the address, strips out the HTML tags from it, and saves the plain text to a file, as shown in the following code:
(defn process-speech-page [outputdir a-tag]
(->> a-tag
:attrs
:href
URL.
enlive/html-resource
get-text-tags
extract-text
(save-text-seq
(unique-filename
(str outputdir / (first (:content a-tag)))))))This strings together a number of functions. We'll walk through these a little more quickly, and then dive into one of the functions this calls in more detail.
First, the sequence of keywords :attrs and :href gets the URL from the anchor tag. We pass this to enlive/html-resource to download and parse the web page. Finally, we identify the text (get-text-tags), strip out the HTML (extract-text), and save it (save-text-seq). Most of these operations are fairly straightforward, but let's dig into extract-text.
This procedure is actually the sole method from a protocol of types that we can pull text from, stripping out HTML tags in the process. The following code gives the definition of this protocol. It's also defined over all the data structures that Enlive uses to return data: Strings for text blocks, hash maps for tags, lazy sequences for lists of content, and nil to handle all the possible input values, as shown in the following code:
(defprotocol Textful
(extract-text [x]
"This pulls the text from an element.
Returns a seq of String."))
(extend-protocol Textful
java.lang.String
(extract-text [x] (list x))
clojure.lang.PersistentStructMap
(extract-text [x]
(concat
(extract-text (:content x))
(when (contains? #{:span :p} (:tag x))
["
"])))
clojure.lang.LazySeq
(extract-text [x] (mapcat extract-text x))
nil
(extract-text [x] nil))The preceding code allows us to find the parent elements for each address, pass those elements to this protocol, and get the HTML tags stripped out. Of all of these methods, the most interesting implementation is hash map's, which is highlighted in the preceding code.
First, it recursively calls the extract-text method to process the tag's content. Then, if the tag is p or span, the method adds a couple of new lines to format the tag as a paragraph. Having a span tag trigger a new paragraph is a bit odd, but the introduction to the address is in a span tag. Like any screen-scraping task, this is very specialized to the SOTU. Getting data from other sites will require a different set of rules and functions to get the data back out.
I've tied this process together in a function that first downloads the index page and then processes the address links one by one as shown in the following code:
(defn download-corpus [datadir index-url]
(doseq [link (get-index-links (URL. index-url))]
(println (first (:content link)))
(process-speech-page datadir link)))After this function executes, there will be a data/ directory that contains one text file for each SOTU address. Now we just need to see how to run LDA topic modeling on them.
To actually perform topic modeling, we'll use the MALLET Java library (http://mallet.cs.umass.edu/). MALLET (MAchine Learning for LanguagE Toolkit) contains a number of algorithms for various statistical and machine learning algorithms for natural-language processing, including document classification, sequence tagging, and numerical optimization. However, it's commonly also used for topic modeling, and its support for that is very robust and flexible. We'll interact with it using Clojure's Java interop functions.
Each document is stored in a MALLET cc.mallet.types.Instance class. So to begin with, we'll need to create a processing pipeline that reads the files from disk and processes them and loads them into MALLET.
The next group of code will go into the src/tm_sotu/topic_model.clj file. The following code is the namespace declaration with the list of dependencies for this module. Be patient; the following list isn't short:
(ns tm-sotu.topic-model
(:require [clojure.java.io :as io]
[clojure.data.csv :as csv]
[clojure.string :as str])
(:import [cc.mallet.util.*]
[cc.mallet.types InstanceList]
[cc.mallet.pipe
Input2CharSequence TokenSequenceLowercase
CharSequence2TokenSequence SerialPipes
TokenSequenceRemoveStopwords
TokenSequence2FeatureSequence]
[cc.mallet.pipe.iterator FileListIterator]
[cc.mallet.topics ParallelTopicModel]
[java.io FileFilter]
[java.util Formatter Locale]))Now we can write a function that creates the processing pipeline and the list of instances based on it, as shown in the following code:
(defn make-pipe-list []
(InstanceList.
(SerialPipes.
[(Input2CharSequence. "UTF-8")
(CharSequence2TokenSequence.
#"p{L}[p{L}p{P}]+p{L}")
(TokenSequenceLowercase.)
(TokenSequenceRemoveStopwords. false false)
(TokenSequence2FeatureSequence.)])))This function creates a pipeline of classes that process the input. Each stage in the process makes a small, select modification to its input, and then it passes the data down the pipeline.
The first step takes the input file's name and reads it as a sequence of characters. It tokenizes the character sequence using the regular expression given, which matches the sequence of letters with embedded punctuation.
Next, it normalizes the case of the tokens and removes stop words. Stop words are very common words. Most of these function grammatically in the sentence, but do not really add to the semantics (that is, to the content) of the sentence. Examples of stop words in English are the, of, and, and are.
Finally, it converts the token sequence to a sequence of features. A feature is a word, a token, or some metadata from a document that you want to include in the training. For example, the presence or absence of the word president might be a feature in this corpus. Features are often assembled into vectors; one vector for each document. The position of each feature in the vectors must be consistent. For example, the feature president must always be found at the seventh position in all documents' feature vectors.
Feature sequences are sequences of numbers along with mappings from words to indices, so the rest of the algorithm will deal with numbers instead of words.
For instance, the first SOTU address by George Washington (1790) begins with, "I embrace with great satisfaction the opportunity which now presents itself." The following are some of the steps that the processing pipeline would take for this input:
CharSequence2TokenSequence: After tokenization, it would be a sequence of individual strings such as I, embrace, with, great, and satisfaction.TokenSequenceLowercase: Normalizing the case would convert the first word to i.TokenSequenceRemoveStopwords: Removing stop words would leave just content words: embrace, great, satisfaction, opportunity, now, presents, and itself.TokenSequence2FeatureSequence: This changes input into a sequence of numbers. Internally, it also maintains a mapping between the indexes and the words, so 0 would be associated with embrace. The next time it finds a word that it has encountered before, it will reuse the feature index, so from here on, now will always be replaced by 4.
We can also visually represent this process as shown in the following chart:
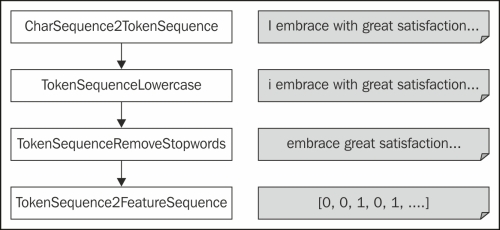
We still haven't specified which files to process or connected them to the processing pipeline. We do that using the instance list's addThruPipe method. To make this step easier, we'll define a function that takes a list of files and plugs them into the pipeline as shown in the following code:
(defn add-directory-files
"Adds the files from a directory to the instance list."
[instance-list data-dir]
(.addThruPipe
instance-list
(FileListIterator.
(.listFiles (io/file data-dir))
(reify FileFilter
(accept [this pathname] true))
#"/([^/]*).txt$"
true)))The FileListIterator function wraps the array of files. It can also filter the array, which is more than we need. The regular expression, #"/([^/]*).txt$", is used to separate the filename from the directory. This will be used to identify the instance for the rest of the processing.
That's it. Now we're ready to write a function to train the model. This process has a number of options, including how many threads to use, how many iterations to perform, how many topics to find, and a couple of hyper parameters to the algorithm itself: the α sum and β. The α parameter is the sum over the topics and β is the parameter for one dimension of the Dirichlet prior distributions that are behind topic modeling. In the following code, I've hardcoded them to 1.0 and 0.01, and I've provided defaults for the number of topics (100), threads (4), and iterations (50):
(defn train-model
([instances] (train-model 100 4 50 instances))
([num-topics num-threads num-iterations instances]
(doto (ParallelTopicModel. num-topics 1.0 0.01)
(.addInstances instances)
(.setNumThreads num-threads)
(.setNumIterations num-iterations)
(.estimate))))Finding the right number of topics is a bit of an art. The value is an interaction between the size of your collection, the type of documents it contains, and how finely grained you wish the topics to be. The number could range from the tens to the hundreds.
One way to get a grasp on this is to see how many instances have a given topic with the top weighting. In other words, if there are a lot of topics with only one or two documents strongly associated with them, then maybe those topics are too specific, and we can run the training again with fewer documents. If none do, or only a few do, then maybe we need to use fewer topics.
However, ultimately, the number of topics depends on how fine-grained and precise you want the topic categories to be, and that will depend upon exactly what questions you're attempting to answer. If you need to find topics that are only important for a year or two, then you'll want more topics; however, if you're looking for broader, more general trends and movements, then fewer topics will be more helpful.
For example, the following graph shows the weightings for each topic in each SOTU address when ten topics are used:
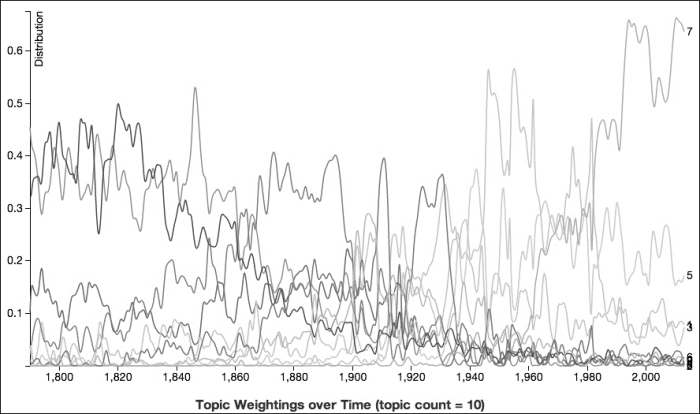
We can see that the lines describe large arcs. Some lines begin strong and then taper off. Others have a hump in the middle and fall away to both sides. Others aren't mentioned much at the beginning but finish strong at the end of the graph.
One line that peaks around 1890 is a good example of one of these trends. Its top ten keywords are year, government, states, congress, united, secretary, report, department, people, and fiscal. Initially, it's difficult to say what this topic would be about. In fact, it is less about the addresses' subject matter per se, and more about the way that the Presidents went into the details of the topics, reporting amounts for taxation, mining, and agriculture. They tended to use a lot of phrases, such as "fiscal year". The following paragraph on sugar production from Grover Cleveland's 1894 address is typical:
The total bounty paid upon the production of sugar in the United States for the fiscal year was $12,100,208.89, being an increase of $2,725,078.01 over the payments made during the preceding year. The amount of bounty paid from July 1, 1894, to August 28, 1894, the time when further payments ceased by operation of law, was $966,185.84. The total expenses incurred in the payment of the bounty upon sugar during the fiscal year was $130,140.85.
Exciting stuff.
This also illustrates how topics aren't always about the documents' subject matter, but also about rhetoric, ways of talking, and clusters of vocabulary that tend to be used together for a variety of reasons.
The topics represented in the following graph clearly describe large trends in the concerns that SOTU addresses dealt with. However, if we increase the number of topics to 200, the graph is very different, and not just because it has more lines on it:
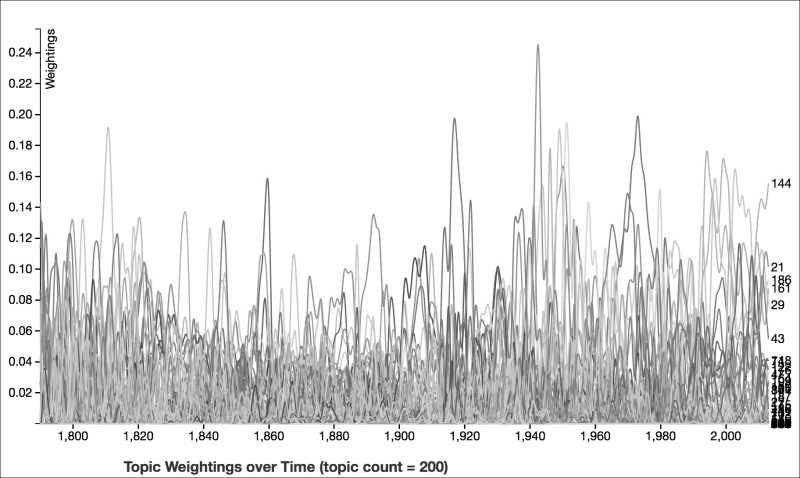
Once you start looking at the topics in more detail, in general, the topics are only relevant for a smaller period of time, like for a twenty- or forty-year period, and most of the time, the documents' weightings for a given topic aren't as high. There are exceptions to this of course; however, most of the topics are more narrowly relevant and narrowly defined. For example, the third topic is largely focused on events related to the Civil War, especially those that occurred around 1862. The top ten keywords for that topic are emancipation, insurgents, kentucky, laborers, adopted, north, hired, maryland, disloyal, and buy. The following graph represents the topic of the Civil War:
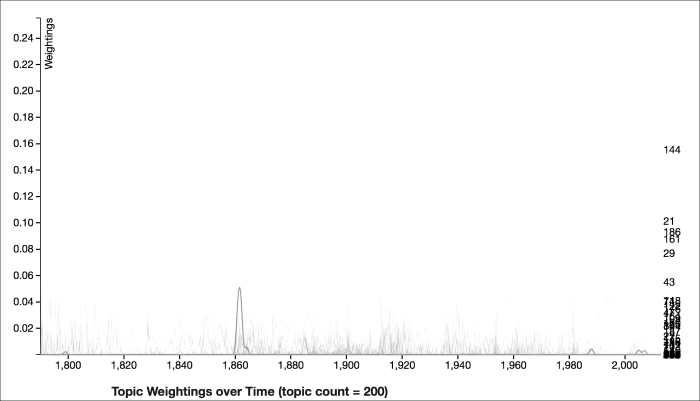
The previous three graphs illustrate the role that the number of topics plays in our topic modeling. However, for the rest of this chapter, we're going to look at a run with 75 models. This graph provides a more balanced set of topics than either of the last two examples. In general, the subjects are neither too broad nor too narrow.
Before we look at D3 or ClojureScript, we should take some time to examine how the visualizations are put together since they're such an integral part of our work. The graphs will be on a static web page, meaning that there will be no need to for any server-side component to help create them. All changes on the graph will be created through JavaScript.
The first component of this will be a standard web page that has a couple of pieces (the entire site is in the code download in the www/ directory). It needs a div tag for the JavaScript to hang the visualization on the static web page, as shown in the following code:
<div class="container"></div>
Then, it needs a few JavaScript libraries. We'll load jQuery (https://jquery.org/) from Google's content distribution network (CDN). We'll load D3 (http://d3js.org/) from its website, as they suggest and then we'll load our own script. Then, we'll call an entrance function in it as shown in the following code:
<script src="//ajax.googleapis.com/ajax/libs/jquery/1.10.1/jquery.min.js"></script>
<script src="http://d3js.org/d3.v3.min.js"
charset="utf-8"></script>
<script src="js/main.js"></script>
<script type="application/javascript">
tm_sotu.topic_plot.plot_topics();
</script>The js/main.js file will be the output of the compiled ClojureScript. We've already set up the configuration for this in the project.clj file, but let's look at that again in the following code:
:cljsbuild {:builds [{:source-paths ["src-cljs"],
:compiler {:pretty-printer true,
:output-to "www/js/main.js",
:optimizations :whitespace}}]})The preceding code specifies that ClojureScript will compile anything in the src-cljs/ directory into the www/js/main.js file. We'll need to create the source directory and the directories for the namespace structure.
In ClojureScript, the files look almost exactly like regular Clojure scripts. There are slight wrinkles in importing and using macros from other libraries, but we won't need to do that today. There is also a js namespace always available. This is used to reference a name directly from JavaScript without requiring it to be declared.
Speaking of which, the following is the namespace declaration we'll use for the graph. You can find the tm-sotu.utils file along with the code that I haven't listed here in the source code for the chapter:
(ns tm-sotu.topic-plot
(:require [tm-sotu.utils :as utils]
[clojure.browser.dom :as dom]
[clojure.string :as str]))Another difference with regular JavaScript is that some functions must be exported using metadata on the function's name. This allows them to be called from regular JavaScript. The entrance function plot-topics is an example of this and is described in the following code:
(defn ^:export plot-topics []
(let [{:keys [x y]} (utils/get-scales)
{:keys [x-axis y-axis]} (utils/axes x y)
color (.. js/d3 -scale category20)
line (utils/get-line #(x (get-year %))
#(y (get-distribution %)))
svg (utils/get-svg)]
(.csv js/d3 "topic-dists.csv"
(partial load-topic-weights
svg line color x x-axis y y-axis))))Most of this function is concerned with calling some functions from the tm-sotu.utils namespace that set up boilerplate for the graphic. It's all standard D3, if you're familiar with that. The more interesting part—actually dealing with the data—we'll look at in more detail.
Before we move on, though, I'd like to pay a little more attention to the highlighted line in the previous code. This is an example of calling JavaScript directly and it illustrates a couple of things to be aware of, as follows:
- As we saw in Chapter 1, Network Analysis – The Six Degrees of Kevin Bacon, we can access JavaScript's global scope with the
js/prefix, that is,js/d3. - Also, we distinguish JavaScript parameters by prefixing the name with a hyphen:
(.-scale js/d3). - Finally, we also see a call to a JavaScript function that takes no parameters. We've also used Clojure's standard
..macro to make the series of calls easier to type and clearer to read:(.. js/d3 -scale category20).
The last line in the preceding code is a call to another D3 function—d3.csv or (.csv js/d3 …)—as it is expressed in ClojureScript. This function makes an AJAX call back to the server for the data file "topic-dists.csv". The result, along with several other pieces of data from this function, is passed to load-topic-weights. You may have caught that I said "back to the server." This system doesn't need any code running on the server, but it does require a web server running in order to handle the AJAX calls that load the data. If you have Python installed on your system, it comes packaged with a zero-configuration web server that is simple to use. From the command line, just change into the directory that contains the website and execute the following command:
$ cd www $ python -m SimpleHTTPServer Serving HTTP on 0.0.0.0 port 8000 …
At this point, we've set the stage for the chart and loaded the data. Now we need to figure out what to do with it. The load-topic-dists function takes the pieces of the chart that we've created and the data, and populates the chart, as follows:
(defn load-topic-weights [svg line color x x-axis y y-axis data] (let [data (into-array (map parse-datum data))] (.domain color (into-array (set (map get-topic data)))) (let [topics (into-array (map #(make-topic data %) (.domain color))) wghts (map get-weighting data)] (.domain x (.extent js/d3 data get-instance)) (.domain y (array (apply min wghts) (apply max wghts))) (utils/setup-x-axis svg x-axis) (utils/setup-y-axis svg y-axis "Weightings") (let [topic-svg (make-topic-svg svg topics)] (add-topic-lines line color topic-svg) (add-topic-labels topic-svg x y) (utils/caption (str "Topic Weightings over Time (topic count = " (count topics) )) 650)))))
The lines in the preceding function fall into three broad categories:
- Transforming and filtering the data
- Setting the domains for the x axis, the y axis, and the color scheme
- Adding the transformed data to the chart
The transformation and filtering of data is handled in a number of different places. Let's see what they all are. I've highlighted them in the previous code; let's break them apart in more detail as follows:
- The
(into-array (map parse-datum data))form converts the data into its JavaScript-native types. The call tod3.csvreturns an array of JavaScript objects, and all of the values are strings. This parses the instance string (for example, "1790-0" or "1984-1") into a decimal (1790.0 or 1984.5). This allows the years with more than one SOTU address to be sorted and displayed more naturally. - The
(map #(make-topic data %) (.domain color))form creates a record with a topic number and the instances for that color. - Finally, the
(map get-weighting data)form pulls all the weightings from the data. This is used to set the domain for the y axis.
This data is used to set the domains for both axes and for the color scale. All of these tasks happen in the three calls to the domain method.
Finally, in the following code, we insert the data into the chart and create the SVG elements from it. This takes place in three other functions. The first, make-topic-svg, selects the elements with the topic class and inserts data into them. It then creates a g element for each datum:
(defn make-topic-svg [svg topics]
(.. svg
(selectAll ".topic")
(data topics)
(enter)
(append "g")
(attr "class" "topic")))The next function appends path elements for each line and populates it with attributes for the points on the line and for the color, as shown in the following code:
(defn add-topic-lines [line color topic-svg]
(.. topic-svg
(append "path")
(attr "class" "line")
(attr "id" #(str "line" (.-topic %)))
(attr "d" #(line (.-values %)))
(style "stroke" #(color (.-topic %)))))Finally, the last function in the following code adds a label for the line to the right-hand side of the graph. The label just displays the topic number for that line. Most of these topics get layered on top of each other and are illegible, but a few of the lines that are labelled at a higher level are distinguishable, and it's useful to be able to see them:
(defn add-topic-labels [topic-svg x y]
(.. topic-svg
(append "text")
(datum make-text)
(attr "transform" #(str "translate(" (x (.-year (.-value %)))
, (y (.-weighting (.-value %))) )))
(attr "x" 3)
(attr "dy" ".35em")
(text get-name)))Put together, these functions create the graphs we've seen so far. With a few added bells and whistles (refer to the source code), they'll also create the graphs that we'll see in the rest of this chapter.
Now, let's use these graphs to explore the topics that the LDA identified.
The following is a complete set of topic weightings that we'll dig into in this chapter. This is from a run of 75 topics. This should provide a relatively focused set of topics, but not so narrow that it will not apply to more than one year:
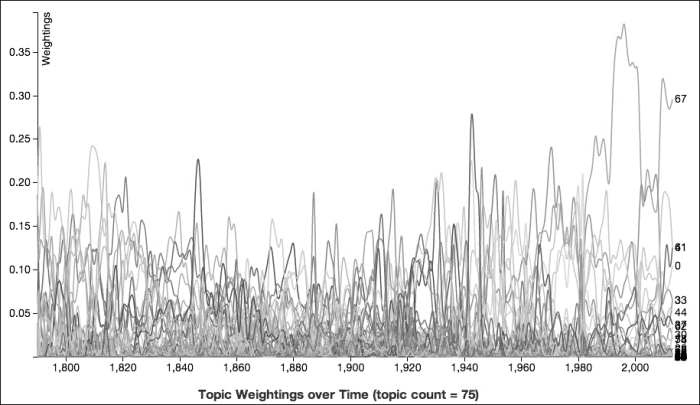
The MALLET library makes it easy to get a lot of information about each topic. This includes the words that are associated with each topic, ranked by how important each word is to that topic. The following table lists some of the topics from this run along with the top five words for each:
|
Topic number |
Top words |
|---|---|
|
0 |
states government subject united citizens good |
|
1 |
world free nations united democracy life |
|
2 |
people work tonight Americans year jobs |
|
3 |
years national support education rights water |
|
4 |
congress government made country report united |
|
5 |
present national tax great cent country |
|
6 |
government congress made American foreign conditions |
|
7 |
America great nation freedom free hope |
|
8 |
congress president years today future ago |
|
9 |
congress employment executive people measures relief |
The word lists help us get an understanding of the topics and what they contain. For instance, the seventh topic seems clearly about American freedom rhetoric. However, there are still a lot of questions left unanswered. The eighth and ninth topics both have congress as their most important word, and some of the words listed for many topics don't have a clear relationship among each other. We'll need to dig deeper.
A better graph would help. It could make each topic's dynamics and changes through time more clear, and it would make evident the trace of each topic's relation to history, wars, expansions, and economics.
Unfortunately, as presented here, the graph is pretty confusing and difficult to read. To make it easier to pull out the weightings for a single topic, I added a feature to the graph so I could select one topic and make the others fade into the background. We'll use the graph to look at a few topics. However, we'll still need to go further and look at some of the addresses for which these topics play an important part.
The first topic that we'll look at in more depth is number 43. The following are the top ten words for this topic and their corresponding weightings:
|
Word |
Weighting |
|---|---|
|
Great |
243 |
|
War |
165 |
|
Commerce |
143 |
|
Powers |
123 |
|
National |
115 |
|
Made |
113 |
|
British |
103 |
|
Militia |
80 |
|
Part |
74 |
|
Effect |
73 |
The following graph for topic 43 shows that this topic was primarily a concern between 1800 and 1825:
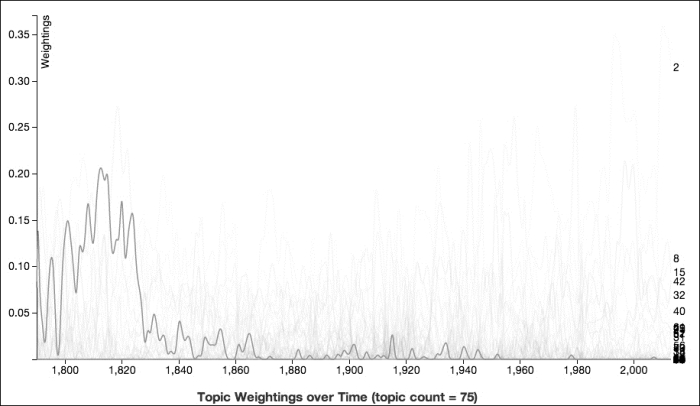
The dominant theme of this topic is foreign policy and setting up the military, with a particular emphasis on the War of 1812 and Great Britain. To get an idea of the arc of this topic, we'll take a look at several SOTU addresses: one from before that War, one from the time of the War, and one from after the War.
The first address we'll look at in more depth is James Madison's 1810 address. The topic model gave the probability for this topic in the document as 11 percent. One of its concerns is trade relations with other countries and how other countries' warships are disrupting them. The following is a quote where Madison rather verbosely talks about the ongoing talks with Britain and France over blockades that were impeding the new republic's trade (I've highlighted the words in the quote that are most applicable to the topic):
From the British Government, no communication on the subject of the act has been received. To a communication from our minister at London of a revocation by the French Government of its Berlin and Milan decrees it was answered that the British system would be relinquished as soon as the repeal of the French decrees should have actually taken effect and the commerce of neutral nations have been restored to the condition in which it stood previously to the promulgation of those decrees.
This pledge, although it does not necessarily import, does not exclude the intention of relinquishing, along with the others in council, the practice of those novel blockades which have a like effect of interrupting our neutral commerce, and this further justice to the United States is the rather to be looked for, in as much as the blockades in question, being not more contrary to the established law of nations than inconsistent with the rules of blockade formally recognized by Great Britain herself, could have no alleged basis other than the plea of retaliation alleged as the basis of the orders in council.
Later, as part of a larger discussion about enabling the state militias, Madison talks about the requirements for establishing schools of military science, even during peacetime, in the following part of the address:
Even among nations whose large standing armies and frequent wars afford every other opportunity of instruction these establishments are found to be indispensable for the due attainment of the branches of military science which require a regular course of study and experiment. In a government happily without the other opportunities seminaries where the elementary principles of the art of war can be taught without actual war, and without the expense of extensive and standing armies, have the precious advantage of uniting an essential preparation against external danger with a scrupulous regard to internal safety. In no other way, probably, can a provision of equal efficacy for the public defense be made at so little expense or more consistently with the public liberty.
Next, we'll look at Madison's 1813 address. The probability of topic 43 in this address was almost 21 percent. The War of 1812 had been going on for a year at that point, and his concerns reflect that. In the following address, Madison is concerned with the role of prisoners of war and Native Americans in the war (they sided with the British); however, there's only one mention of commerce, which had almost ceased because of interference by the war.
The following is a sample paragraph where Madison complains about the British trying some political prisoners in court:
The British commander in that Province, nevertheless, with the sanction, as appears, of his Government, thought proper to select from American prisoners of war and send to Great Britain for trial as criminals a # of individuals who had emigrated from the British dominions long prior to the state of war between the two nations, who had incorporated themselves into our political society in the modes recognized by the law and the practice of Great Britain, and who were made prisoners of war under the banners of their adopted country, fighting for its rights and its safety.
Finally, for topic 43, we'll take a look at James Monroe's 1820 SOTU address. The probability of topic 43 in this address was 20 percent. In this case, Monroe's looking at the United States' trade relations with the European powers. He goes through each of the major trading partners and talks about the latest happenings with them and discusses the country's military preparedness on a number of fronts.
The following is the paragraph where he talks about the trading relationship with Great Britain; he doesn't appear entirely satisfied:
The commercial relations between the United States and the British colonies in the West Indies and on this continent have undergone no change, the British Government still preferring to leave that commerce under the restriction heretofore imposed on it on each side. It is satisfactory to recollect that the restraints resorted to by the United States were defensive only, intended to prevent a monopoly under British regulations in favor of Great Britain, as it likewise is to know that the experiment is advancing in a spirit of amity between the parties.
In this topic, there's a clear trend of conversations around a series of events. In this case, topic modeling has pointed out an interesting dynamic in the US government's early years.
We'll look at a very different type of topic next. This one focuses on one event: the Japanese bombing of Pearl Harbor, which brought the United States actively and openly into World War II.
The following are the top ten words that contributed to this topic along with their weightings; as it is more narrowly focused, the subject of this topic is clear:
|
Word |
Weighting |
|---|---|
|
Production |
66 |
|
Victory |
48 |
|
Japanese |
44 |
|
Enemy |
41 |
|
United |
39 |
|
Fighting |
37 |
|
Attack |
37 |
|
Japan |
31 |
|
Pacific |
28 |
|
Day |
27 |
The narrow focus of the topic is evident in the graph as well. The spike at 1942 and 1943 in the following graph—the two years after the bombing of Pearl Harbor—lends weight to the evidence that this topic is about this particular event:
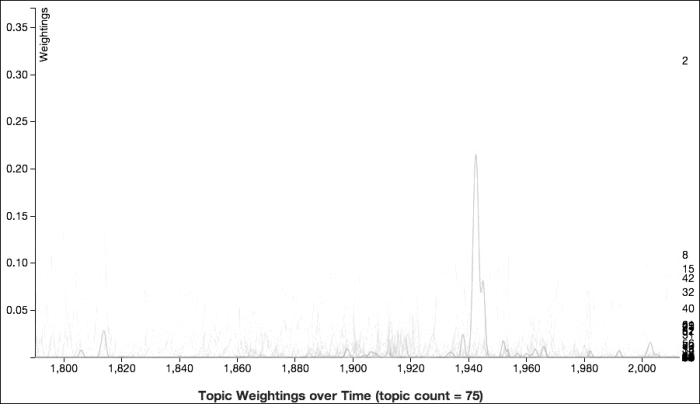
For the first SOTU address that we'll examine, we'll look at the one immediately after the Pearl Harbor bombing, presented by Franklin D. Roosevelt on January 6, 1942. This topic's probability of application is 22.7 percent. This was less than one month after the attack, so its memory was still pretty raw in the minds of American citizens, and this emotion is evident in the speech.
The text of the speech itself is predictable, especially given the words listed earlier. To paraphrase: After the attack; they're our enemy; bent on world conquest; along with the Nazis; we must have victory to maintain the cause of freedom and democracy. Beyond this, he's also making the point that we need to enter the European theater to fight alongside the British and other ally partners, and furthermore, to do that effectively, the U.S. must increase production of military weapons, vehicles, boats, airplanes, and supplies across the board.
The following is a short paragraph in which Roosevelt outlines the steps that are already underway to work with the allied powers:
Plans have been laid here and in the other capitals for coordinated and cooperative action by all the United Nations—military action and economic action. Already we have established, as you know, unified command of land, sea, and air forces in the southwestern Pacific theater of war. There will be a continuation of conferences and consultations among military staffs, so that the plans and operations of each will fit into the general strategy designed to crush the enemy. We shall not fight isolated wars—each Nation going its own way. These 26 Nations are united—not in spirit and determination alone, but in the broad conduct of the war in all its phases.
Although this particular SOTU address clearly dominates this topic, there are other addresses that have some small probability of applying. It might be interesting to see what else was categorized in this topic, even the words with a low probability percentage. One such address is James Madison's 1814 address, which has a probability of 3.7 percent for this topic.
In the following part of the address, Madison spends a lot of time talking about "the enemy," who in this case, is Great Britain. This short paragraph is typical:
In another recent attack by a powerful force on our troops at Plattsburg, of which regulars made a part only, the enemy, after a perseverance for many hours, was finally compelled to seek safety in a hasty retreat, with our gallant bands pressing upon them.
This address has a number of other short descriptions of battles like this one.
Finally, a more recent SOTU address also had a relatively high probability for this topic (2 percent): George W. Bush's 2003 address. In this address, most of the mentions of words that apply to this topic are spread out and there are few quotable clusters. He spends some time referring to the United Nations, which helps this document rate more highly for this topic. He also talks quite a bit about war as he is trying to build a case for invading Iraq, which he did less than two months later.
This document is clearly weaker than the other two on this topic. However, it does contain some shared vocabulary and some discourse, so its relationship to the topic, albeit weak, is clear. It's also interesting that in both of these cases, the President is trying to make a case for war.
Finally, we'll look at a more domestically oriented topic. The words in the following table suggest that this topic will be about childcare, schools, and healthcare:
|
Word |
Weighting |
|---|---|
|
Children |
270 |
|
Health |
203 |
|
Care |
182 |
|
Support |
164 |
|
Schools |
159 |
|
School |
139 |
|
Community |
131 |
|
Century |
130 |
|
Parents |
124 |
|
Make |
121 |
Looking at the following graph on this topic, it's clearly a late twentieth-century subject, and it really doesn't take off until after 1980. Somewhat predictably, this topic sees its zenith in the Clinton administration. We'll look at one of Clinton's speeches on this topic later in this section:
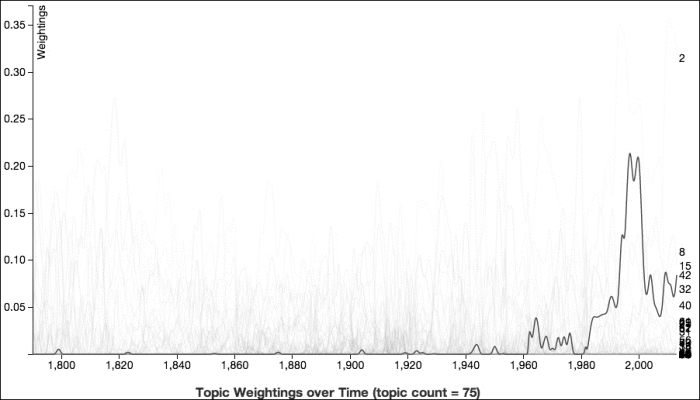
Let's first look at one of the SOTU addresses from the first, smaller cluster of addresses that prove this topic. For that, we'll pick Lyndon B. Johnson's 1964 SOTU address, which shows a probability of 4.4 percent for this topic.
In this speech, Johnson lays out a proposal that includes what would become the Civil Rights Act of 1964, which outlawed major forms of racial, ethnic, religious, and gender discrimination as well as the medicare and medicaid programs, which would be created in 1965. He's obviously laying the groundwork for the "Great Society" program he would announce in May of that year at Ohio University in Athens, Ohio.
His main topic in this is combating poverty—after all, this is the speech that gave us the phrase "war on poverty"—but he saw education and healthcare as being a big part of that:
Our chief weapons in a more pinpointed attack will be better schools, and better health, and better homes, and better training, and better job opportunities to help more Americans, especially young Americans, escape from squalor and misery and unemployment rolls where other citizens help to carry them.
He also saw education and healthcare as being integral to the goals of the program and the American dream itself:
This budget, and this year's legislative program, are designed to help each and every American citizen fulfill his basic hopes—his hopes for a fair chance to make good; his hopes for fair play from the law; his hopes for a full-time job on full-time pay; his hopes for a decent home for his family in a decent community; his hopes for a good school for his children with good teachers; and his hopes for security when faced with sickness or unemployment or old age.
So although this particular speech has only a low probability for this topic, it clearly raises issues that will be more directly addressed later.
One of the SOTU addresses with the highest probability for this topic is Bill Clinton's 2000 address, which had a probability of 22.1 percent. This is his last SOTU address before leaving office, and although he still had one year left in his term, realistically, not much was going to happen in it.
Additionally, because it was his last chance, Clinton spends a lot of time looking back at what he's accomplished. Children, education, and healthcare were major focuses of his administration, whatever actually was passed through Congress, and this was reflected in his retrospective:
We ended welfare as we knew it, requiring work while protecting health care and nutrition for children and investing more in child care, transportation, and housing to help their parents go to work. We've helped parents to succeed at home and at work with family leave, which 20 million Americans have now used to care for a newborn child or a sick loved one. We've engaged 150,000 young Americans in citizen service through AmeriCorps, while helping them earn money for college.
Clinton also spent time laying out what he saw as the major tasks ahead of the nation, and education and healthcare played a big part of them as well:
To 21st century America, let us pledge these things: Every child will begin school ready to learn and graduate ready to succeed. Every family will be able to succeed at home and at work, and no child will be raised in poverty. We will meet the challenge of the aging of America. We will assure quality, affordable health care, at last, for all Americans. We will make America the safest big country on Earth. We will pay off our national debt for the first time since 1835. We will bring prosperity to every American community. We will reverse the course of climate change and leave a safer, cleaner planet. America will lead the world toward shared peace and prosperity and the far frontiers of science and technology. And we will become at last what our Founders pledged us to be so long ago: One Nation, under God, indivisible, with liberty and justice for all.
In fact, even beyond these broad strokes, Clinton spends a lot of time talking specifically about education, what needs to be done to improve schools, and what works to make better schools. All of this contributes to this address's high probability for topic 42.
He also spent more time talking about healthcare, what he's done on that front, and what is still left to accomplish:
We also need a 21st century revolution to reward work and strengthen families by giving every parent the tools to succeed at work and at the most important work of all, raising children. That means making sure every family has health care and the support to care for aging parents, the tools to bring their children up right, and that no child grows up in poverty.
So looking at these addresses, we may wish that there was a separate topic for education and healthcare. However, it is interesting to note the ways in which the two topics are related. Not only are they often discussed together and simultaneously in two parts of a President's agenda for a year, but also have related rhetoric. Children are directly related to education, but they are also often invoked while talking about healthcare, and many laws about health insurance and healthcare try to ensure that children are still insured, even if their parents are not.