
First, let's examine the precision of the classifiers. Remember that the precision is how well the classifiers do at only returning positive reviews. This indicates the percentage of reviews that each classifier has identified as being positive is actually positive in the test set:
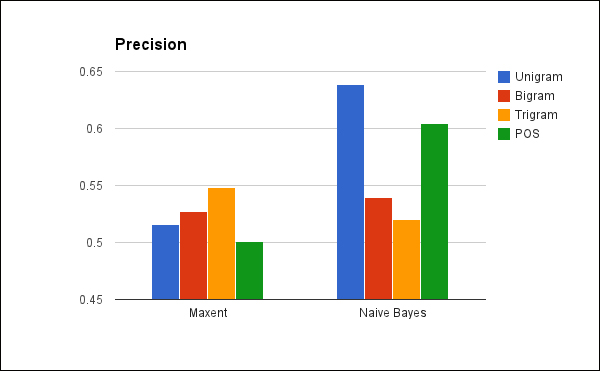
We need to remember a couple of things while looking at this graph. First, sentiment analysis is difficult, compared to other categorization tasks. Most importantly, human raters only agree about 80 percent of the time. So, the bar seen in the preceding figure that almost reaches 65 percent is actually decent, if not great. Still, we can see that the naive Bayesian classifier generally outperforms the maxent one for this dataset, especially when using unigram features. It performed less well for the bigram and trigram features, and slightly lesser for the POS-tagged unigrams.
We didn't try tagging the bigram and trigrams with POS information, but that might have been an interesting experiment. Based on what we can see here, these feature generators would not get better results than what we've already tested, but it would be good to know that more definitively.
It's interesting to see that maxent performed best with trigrams. Generally, compared to unigrams, trigrams pack more information into each feature, as they encode some implicit syntactical information into each feature. However, each feature also occurs fewer times, which makes performing some statistical processes on it more difficult. Remember that recall is the percentage of positives in the test set that were correctly identified by each classifier. Now let's look at the recall of these classifiers:
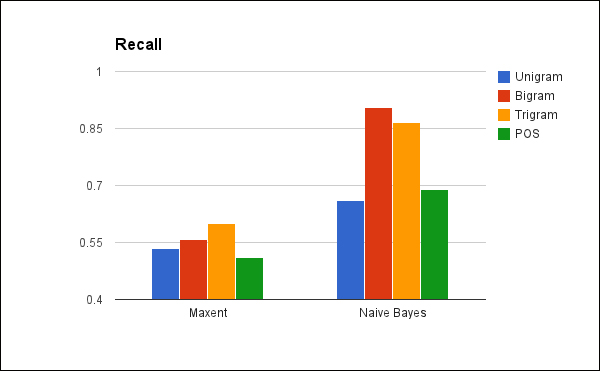
First, while the naive Bayesian classifier still outperforms the maxent classifier, this time the bigram and trigram get much better results than the unigram or POS-tagged features.
Also, the recall numbers on these two tests are better than any of the values for the precision. The best part is that the naive Bayes bigram test had a recall of just over 90 percent.
In fact, just looking at the results, there appeared to be an inverse relationship between the precision and the recall, as there typically is. Tests with high precision tended to have lower recall numbers and vice versa. This makes intuitive sense. A classifier can get a high recall number by marking more reviews as positive, but that negatively impacts its precision. Or, a classifier can have better precision by being more selective in what it marks as positive but also noting that will drag down its recall.
We can combine these two into a single metric using the harmonic mean of the precision and recall, also known as the F-measure. We'll compute this with the following function:
(defn f-score [error]
(let [{:keys [precision recall]} error]
(* 2 (/ (* precision recall) (+ precision recall)))))This gives us a way to combine the precision and recall in a rational, meaningful manner. Let's see what values it gives for the F-measure:
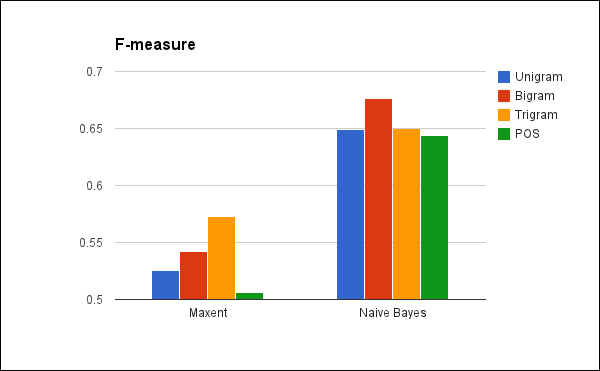
So, as we've already noticed, the naive Bayesian classifier performed better than the maxent classifier in general, and on balance, the bigram features worked best for this classifier.
While this gives us a good starting point, we'll also want to consider why we're looking for this information, how we'll use it, and what penalties are involved. If it's vitally important that we get all the positive reviews, then we will definitely want to use the naive Bayesian classifier with the bigram features. However, if the cost of missing some isn't so high but the cost of having to sort through too many false results is high, then we'll probably want to use unigram features, which would minimize the number of false results we have to manually sort through later.