
The TIFF format is a versatile image format that can be customized for very diverse needs. The file is composed of a Header, at least one Image File Directory, and any amount of Image Data. Explaining it in a simple way, the header tells where the first directory is on the file. The directory contains information about the image, tells how to read the data related to it, and tells where the next directory is. Each combination of a directory and image data is an image, so a single TIFF file may have multiple images inside it.
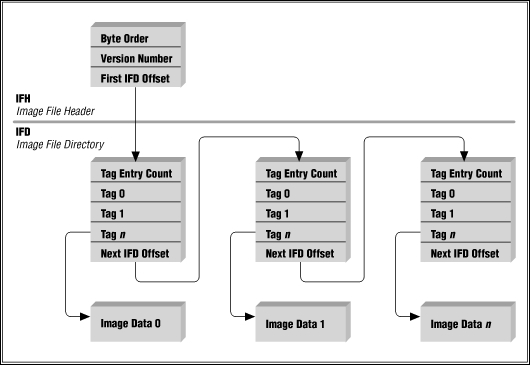
Each image data (a whole image) contains blocks of data (that is, parts of the image) that can be read separately, each one representing a specific region of the image. This allows the user to read the image by chunks, just like we did.
The blocks of data are indivisible; in order to return data from an image, the program that is reading it needs to read at least one whole block. If the desired region is smaller than a block, the whole block will be read anyway, decoded, and cropped; the data will then be returned to the user.
The blocks of data can be in strips or in tiles. Strips contain data for an entire image row and may be one row or more in length. Tiles have width and length (which must be a multiple of 16) and are interesting because they allow us to retrieve specific regions with no need to read entire rows.
In our previous examples, we programmed a function that was able to read images one row at a time; now we will improve that function in order to read blocks of any size. This will allow us to make fancier stuff with the images in the upcoming topics.
This time, we will take a different approach to how we iterate the image.
- Inside your
Chapter10/experimentsfolder, create a new file namedblock_generator.py. - Edit this file and insert the following code:
# coding=utf-8 import os from pprint import pprint from osgeo import gdal, gdal_array def create_blocks_list(crop_region, block_shape): """Creates a list of block reading coordinates. :param crop_region: Offsets and shape of the region of interest. (xoff, yoff, xsize, ysize) :param block_shape: Width and height of each block. """ img_columns = crop_region[2] img_rows = crop_region[3] blk_width = block_shape[0] blk_height = block_shape[1] # Get the number of blocks. x_blocks = int((img_columns + blk_width - 1) / blk_width) y_blocks = int((img_rows + blk_height - 1) / blk_height) print("Creating blocks list with {} blocks ({} x {}).".format( x_blocks * y_blocks, x_blocks, y_blocks)) blocks = [] for block_column in range(0, x_blocks): # Recalculate the shape of the rightmost block. if block_column == x_blocks - 1: valid_x = img_columns - block_column * blk_width else: valid_x = blk_width xoff = block_column * blk_width + crop_region[0] # loop through Y lines for block_row in range(0, y_blocks): # Recalculate the shape of the final block. if block_row == y_blocks - 1: valid_y = img_rows - block_row * blk_height else: valid_y = blk_height yoff = block_row * blk_height + crop_region[1] blocks.append((xoff, yoff, valid_x, valid_y)) return blocks - Before some explanation, let's see this function working. Add the
if __name__ == '__main__':block at the end of the file with this code:if __name__ == '__main__': blocks_list = create_blocks_list((0, 0, 1024, 1024), (32, 32)) pprint(blocks_list) - Run the code. Since we are running a different file from before, remember to press Alt + Shift + F10 to select the file to run. Check the output:
Creating blocks list with 1024 blocks (32 x 32). [(0, 0, 32, 32), (0, 32, 32, 32), (0, 64, 32, 32), (0, 96, 32, 32), (0, 128, 32, 32), (0, 160, 32, 32), (0, 192, 32, 32), ... (992, 928, 32, 32), (992, 960, 32, 32), (992, 992, 32, 32)] Process finished with exit code 0
The sole purpose of this function is to create a list of block coordinates and dimensions; each item on the list contains the offset and the size of a block. We need the size because the blocks on the edges may be smaller than the desired size.
The intention of this design choice, instead of iterating through an image directly, was to hide this low-level functionality. This function is extensive and unintuitive; we don't want it mixed with higher-level code, making our programs much cleaner. As a bonus, we may gain a little speed when iterating multiple images because the list only needs to be produced once.
- Now, let's adapt the function to copy the image. To use the iteration by blocks, add this code to the file:
def copy_image(src_image, dst_image, block_shape): try: os.remove(dst_image) except OSError: pass src_dataset = gdal.Open(src_image) cols = src_dataset.RasterXSize rows = src_dataset.RasterYSize driver = gdal.GetDriverByName('GTiff') new_dataset = driver.Create(dst_image, cols, rows, eType=gdal.GDT_UInt16) gdal_array.CopyDatasetInfo(src_dataset, new_dataset) band = new_dataset.GetRasterBand(1) blocks_list = create_blocks_list((0, 0, cols, rows), block_shape) n_blocks = len(blocks_list) for index, block in enumerate(blocks_list, 1): if index % 10 == 0: print("Copying block {} of {}.".format(index, n_blocks)) block_data = src_dataset.ReadAsArray(*block) band.WriteArray(block_data, block[0], block[1]) - Edit the
if __name__ == '__main__':block to test the code (we are also going to measure its execution time):if __name__ == '__main__': base_path = "../../data/landsat/" img_name = "LC80140282015270LGN00_B8.TIF" img_path = os.path.join(base_path, img_name) img_copy = "../output/B8_copy.tif" t1 = datetime.now() copy_image(img_path, img_copy, (1024, 1024)) print("Execution time: {}".format(datetime.now() - t1)) - Now, run it and check the output:
Creating blocks list with 256 blocks (16 x 16). Copying block 10 of 256. Copying block 20 of 256. ... Copying block 240 of 256. Copying block 250 of 256. Execution time: 0:00:26.656000 Process finished with exit code 0
We used blocks of 1024 by 1024 pixels to copy the image. The first thing to notice is that the process is extremely slow. This happened because we are reading blocks smaller than the size of the blocks in the image, resulting in a lot of reading and writing overhead.
So, let's adapt our function in order to detect the block size and optimize the reading.
- Edit the
copy_imagefunction:def copy_image(src_image, dst_image, block_width=None, block_height=None): try: os.remove(dst_image) except OSError: pass src_dataset = gdal.Open(src_image) cols = src_dataset.RasterXSize rows = src_dataset.RasterYSize src_band = src_dataset.GetRasterBand(1) src_block_size = src_band.GetBlockSize() print("Image shape {}x{}px. Block shape {}x{}px.").format( cols, rows, *src_block_size) block_shape = (block_width or src_block_size[0], block_height or src_block_size[1]) driver = gdal.GetDriverByName('GTiff') new_dataset = driver.Create(dst_image, cols, rows, eType=gdal.GDT_UInt16) gdal_array.CopyDatasetInfo(src_dataset, new_dataset) band = new_dataset.GetRasterBand(1) blocks_list = create_blocks_list((0, 0, cols, rows), block_shape) n_blocks = len(blocks_list) for index, block in enumerate(blocks_list, 1): if index % 10 == 0: print("Copying block {} of {}.".format(index, n_blocks)) block_data = src_dataset.ReadAsArray(*block) band.WriteArray(block_data, block[0], block[1])
We separated the block shape arguments into width and height, and made them optional. Then we got the size (shape) of the block that is defined in the image. If the block width or height are not passed as arguments, the image values are used instead.
We have a hint that this image is divided in stripes. Remember that when we copied the image one row at a time, it was fast. So, we are going to test reading multiple rows at a time.
- Edit the
if __name__ == '__main__':block:if __name__ == '__main__': base_path = "../../data/landsat/" img_name = "LC80140282015270LGN00_B8.TIF" img_path = os.path.join(base_path, img_name) img_copy = "../output/B8_copy.tif" t1 = datetime.now() copy_image(img_path, img_copy, block_height=100) print("Execution time: {}".format(datetime.now() - t1)) - Run the code and see the difference:
Image shape 15401x15661px. Block shape 15401x1px. Creating blocks list with 157 blocks (1 x 157). Copying block 10 of 157. Copying block 20 of 157. Copying block 30 of 157. ... Copying block 130 of 157. Copying block 140 of 157. Copying block 150 of 157. Execution time: 0:00:02.083000 Process finished with exit code 0
It's confirmed that, for Landsat 8 images, each block is one row of the image. And by reading whole lines, we achieved the same level of speed as before.
You can play with the block height parameter; instead of reading 100 lines, try reading 1 or 1,000 lines and see if it has any influence on the execution time.