C H A P T E R 10
Client-Side Programming
At this point, you are going to take a slight detour from building the visual components of your sites into the magical realm of code writing. As you have seen throughout this book, some amazing things can be accomplished with SharePoint Server 2010 and SharePoint Designer 2010 without ever writing a line of code. However, in order to build the richest of user experiences, it is sometimes necessary to crack open the toolbox and pull out the power tools.
In this chapter, you will take a brief look at some of the tools that are available for writing high-performance client-side behaviors in SharePoint. This is not intended to be a comprehensive discussion of client-side programming in SharePoint. The purpose of this chapter is simply to make you aware of the tools that are available. Many excellent resources are available online, including on MSDN, and more are appearing all the time. The SharePoint client object models described here are catching on very rapidly, and a great deal of interest has been generated among developers who write blogs.
![]() Note This chapter assumes that the reader has a certain familiarity with writing code that runs in a web browser. This includes technologies such as JavaScript, HTML, DOM, AJAX, and WCF. If these terms are foreign to you, don't feel too bad. You are in good company (with most of the human race) and should feel free to skip this chapter.
Note This chapter assumes that the reader has a certain familiarity with writing code that runs in a web browser. This includes technologies such as JavaScript, HTML, DOM, AJAX, and WCF. If these terms are foreign to you, don't feel too bad. You are in good company (with most of the human race) and should feel free to skip this chapter.
You will learn about the following topics in this chapter:
- How SharePoint 2010 exposes server functionality by using client-side object models (CSOMs).
- Why Microsoft felt this was an important feature to provide
- Why writing code that runs in the client browser is sometimes preferable to code that runs on the server
- How to make the browser interact with the server more efficiently
- Why we all love writing code so much!
Understanding Client- vs. Server-Side Programming
In previous versions of SharePoint, we had two interfaces for accessing the objects and content stored within SharePoint: API calls or web services.
If our code was destined to run on the SharePoint server—for example, in a web part or event receiver—we could use the SharePoint API (a.k.a. the SharePoint server object model). This allowed us to create, read, update, and delete (CRUD) objects such as SPSite, SPWeb, SPList, and SPListItem. We could set permissions, configure features, and manipulate just about anything in the SharePoint environment as long as we had the necessary credentials. We could also write code against the API that would run as an add-on to the SharePoint Administration tool (STSADM) or in a .NET application. The only restriction was that it had to run on the SharePoint server. This interface still exists in SharePoint 2010, along with a new set of PowerShell commands that can be used for many of the same purposes.
If our SharePoint 2007 code needed to run on a computer other than the SharePoint server, we had to use SharePoint's web services interface. This interface was not as rich as the full server API, but it suited many scenarios well enough. The problem with the web services interface was that it worked well for the situations Microsoft designed it for, but not at all in most other cases. The web service method you needed either existed, or it didn't—and you were out of luck.
Many developers, me included, began routinely deploying custom web services within our SharePoint sites to allow client applications to perform actions not supported by the web services interface. Using AJAX-style code in the web browser, these services could be used to provide a richer user experience that did not require as many time-consuming page posts to the web server. JavaScript code running in the web browser would call the custom web service to carry out a server-side function, returning data objects to the browser. The script would then update the currently displayed page without posting the entire page to the server. Unfortunately, these services often performed poorly and affected scalability by transferring logic that could be done on the client side to the server.
Another approach to the problem was to redefine the client application as a server application. For example, integrating SQL Server Reporting Services (SSRS) with SharePoint 2007 required the SQL server to have SharePoint installed locally so that SQL could use the SharePoint API to communicate with SharePoint. This was true even if there was no plan to render pages or run any other SharePoint server processes on the SSRS server. Although this did not have a large impact when using the free Windows SharePoint Services (WSS) package, this could get very expensive once you started deploying Microsoft Office SharePoint Server (MOSS).
As Microsoft began developing the next version of SharePoint, they were flooded with requests for additional web services to be added to the interface. More and more web sites have the need for a flexible client-side programming interface to support rich browser interfaces and mobile web applications. At some point, Microsoft came up with a more elegant solution than continuing to add new SharePoint web services ad infinitum.
Working with the SharePoint Client Object Model
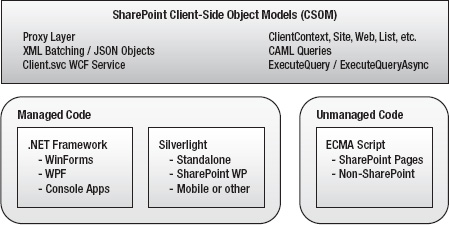
SharePoint 2010 contains a new set of features called the SharePoint Foundation 2010 client-side object model (CSOM) or just the client object model. Note that I am using the abbreviation CSOM instead of COM to avoid confusing it with the old component object model. The purpose of the CSOM is to provide a client-side subset of the SharePoint API that can be used from a variety of platforms. The object model is available for .NET Framework applications, Silverlight applications, and web sites using ECMAScript-compatible scripting languages such as JScript and JavaScript.
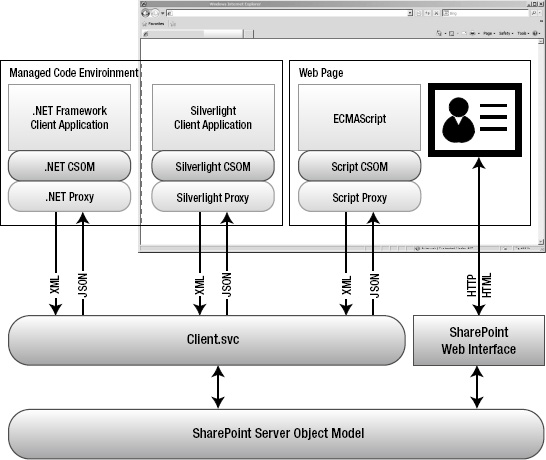
Figure 10-1. Client-side object model components
Each version of the client object model has a similar component structure. The specifics of each environment are presented in a later section. For now, you will look at the architecture that is common to them all (see Figure 10-1).
On the SharePoint server, there is a new component called Client.svc. As the name suggests, this is a Windows Communication Foundation (WCF) service. This service acts as a façade for the SharePoint Server object model running on the server. The client service receives client requests in XML form, executes the request against the server API, and returns objects to the caller in JavaScript Object Notation (JSON) format.
Each client object model implementation consists of two layers. The first layer is the client-side object model classes. These classes map directly in most cases to a corresponding SharePoint Server object model class. For example, the SPSite server object is represented by the Site object in each client object model.
The second layer of the implementation consists of a proxy layer, or runtime. The purpose of the proxy component is to streamline the passing of requests and responses to and from the server. A key difference between the server and client object models is the effect of the proxy layer. When a call is made to the client object model, that request is not immediately processed on the server. The proxy batches the requests until the client application explicitly tells it to contact the server. At that point, all of the outstanding requests are processed in order, and the results are returned to the client. This makes writing good client-side SharePoint code very different from writing server-side code. In the “Using Best Practices” section, you will learn some of the ways to leverage this batching behavior to dramatically improve performance and scalability.
.NET Framework Client Object Model
The .NET Framework client object model is used when writing client applications by using the .NET Framework version 3.5. This allows SharePoint calls to be made from console applications, Windows applications, and Windows services.
![]() Note The .NET client object model assemblies for SharePoint 2010 are version 3.5 assemblies, not version 4.0. Be sure to select the correct .NET Framework version when writing code against the object model.
Note The .NET client object model assemblies for SharePoint 2010 are version 3.5 assemblies, not version 4.0. Be sure to select the correct .NET Framework version when writing code against the object model.
There are two assemblies to be referenced when building SharePoint client applications in .NET, as shown in Table 10-1. Both assemblies can be found in the 14 hive's ISAPI directory. By default, the full path is C:Program FilesCommon FilesMicrosoft SharedWeb Server Extensions14ISAPI.

Silverlight Client Object Model
The Silverlight client object model is used when writing Silverlight applications. These applications may be hosted in a variety of environments, from mobile phones to SharePoint sites, using the Silverlight web part.
Again, two assemblies need to be referenced when building SharePoint client applications. Both assemblies can be found in the 14 hive's TEMPLATELAYOUTSClientBin directory. SharePoint's 14 hive is the location to which SharePoint installs the content files and executables that are deployed as part of a SharePoint site. The full default path to these files is C:Program FilesCommon FilesMicrosoft SharedWeb Server Extensions14TEMPLATELAYOUTSClientBin. There is also an Extensible AJAX Platform (XAP) file containing both dynamic-link libraries (DLLs). Table 10-2 lists the files.

ECMAScript Client Object Model
The ECMAScript client object model is used when writing JavaScript code within web pages. The method of delivering the script to the web page may vary. It could be included in a Content Editor web part or other standard control, as you will see in our example. It could also be emitted by a custom web control or embedded in a .js script file.
In this case, only one file is needed for the client object model. All of the object and proxy logic is included in a single JavaScript file called sp.js. This file is commonly loaded at runtime by using a script statement like the one shown in Listing 10-1.
Listing 10-1. JavaScript Reference for the sp.js File
<script type="text/javascript">
ExecuteOrDelayUntilScriptLoaded(MyFunction, "sp.js");
</script>
This causes the sp.js file to load before running the MyFunction routine, which can then use the client object model. This file is compacted and difficult to read. For debugging purposes, you may want to use the sp.debug.js file. It is easier to work with but is 40 percent larger than the production file. Table 10-3 lists the ECMAScript CSOM files.

The ECMAScript object model has some limitations because of the environment in which it executes. Objects created with the model can access only the local site collection. In the server API or the other client object models, you can create a Site (or SPSite) object that points to any SharePoint site collection anywhere on the network. Because script objects exist within a certain web page, any attempt to access another site collection would be considered a cross-site scripting attack and is therefore prevented.
The proxy layer in any of the client object models can batch multiple requests destined for the server. When the client application wants to send the batch, it calls either ExecuteQuery or ExecuteQueryAsync. The former call blocks the current thread until the results are returned. The latter registers callback routines that are called asynchronously after the request is completed. Because blocking the browser's user interface thread can cause the browser to freeze, only asynchronous requests are permitted. The ExecuteQuery method is not even included in the script object model.
The ECMAScript version of the client object model is the one that we can use from within SharePoint Designer 2010, so we will limit our discussion to it for the rest of this chapter.
SharePoint Object Model Comparison
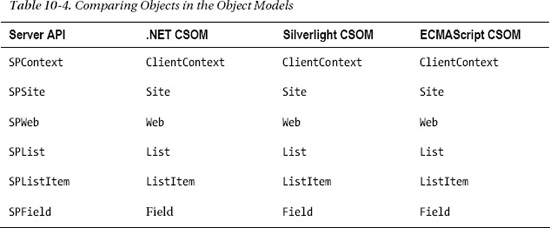
All of the client object models are a subset of the server object model. Some of the objects, properties, and methods available within the server API are not available on the client side. That being said, most of the objects commonly used by SharePoint developers are available in a very similar form. Table 10-4 lists some of the most common objects and their client equivalents.
Using Best Practices
This section covers some best practices around using client-side script with SharePoint solutions. You will examine the most common use cases for which client-side programming is useful or preferable. Then you will look at some of the architectural considerations that affect performance and scalability of a SharePoint farm when using server-side vs. client-side logic. For those familiar with AJAX-style programming, many of these points will seem obvious.
The two main reasons for moving logic to the client are to improve site performance and create a richer user experience. The key is to remember that moving logic to the client side improves the scalability of the SharePoint farm by removing that processing from the server. Eliminating unneeded full-page post-backs is good for both the user experience and reducing load on the server.
User Experience
The new client object model is a powerful new tool for building SharePoint solutions, but when should it be used, and when is it best to avoid client-side scripting? It is important to understand what types of things can be done effectively from the client side. SharePoint server provides web parts and pages that handle most routine tasks by presenting a form to the user and receiving the data posted back from the form. Client-side forms allow more-complex behaviors to be created that make the user interface respond more quickly and interactively.
For example, in SharePoint 2007, when the user clicked the +Add Document link in a document library, the entire page was replaced by an upload form. Starting in SharePoint 2010, the same link will open a modal dialog box form to upload the document, as shown in Figure 10-2. Forms like this one are loaded without posting the entire page back to the server. When the form is submitted, the page behind it is redisplayed and updated only as necessary. This creates a much smoother interface.
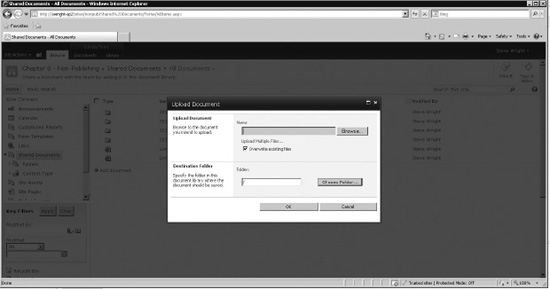
Figure 10-2. Modal dialog box form
The client object model contains a set of classes for displaying this type of modal dialog box easily from within client-side script. The dialog box can accept input, perform actions such as posting data back to the server, and return status and data elements to the calling client script.
Client-side scripts can also be used to update the elements on the current web page. A common scenario is to execute a Collaborative Application Markup Language (CAML) query against SharePoint server by using the client object model and then to render the results to controls already present on the web page. As you will see in the example later in this chapter, it is also simple to retrieve and update information about individual content objects that exist within the site. These objects can include web sites, lists, libraries, list items, and documents.
Using SharePoint Designer, it is also possible to create custom actions within the SharePoint site, as you can see in Figure 10-3. These are menu items that can launch a form, start a workflow, or navigate to a specific URL. By adding a JavaScript call to the custom action's URL, this feature can be used to run arbitrary client-side script when the menu item is selected.
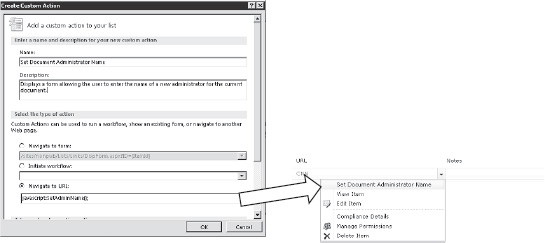
Figure 10-3. Client-side custom actions
Because the client object model is a subset of the server object model, many of the tasks traditionally performed within a site's web parts and forms can now be done on the client side.
Performance and Scalability
Performance and scalability are two sides of the same coin. What the user experiences as performance from your web site is dependent on how quickly actions taken in the browser are communicated to the server and then reflected back in the browser. As additional users place additional load on the server, it naturally responds more slowly. SharePoint server farms are intended to provide scalability by providing additional servers to handle the load. However, the design of your application will determine how effectively those server resources can be used.
Getting the best performance possible requires balancing the functionality of the application against the capabilities of the hardware supporting it. The SharePoint client object models are designed to allow some of the processing that might have occurred on the servers to be performed on the client side of the network connection. This frees up server capacity and improves scalability.
Consider all of the logic that goes into a SharePoint application. This might include querying, reading, formatting, and updating data. It might also include time-consuming calculations or repetitive tasks. Some of these have to be done, at least in part, on the server side because they involve accessing SharePoint's databases. When designing functionality for the SharePoint environment, consider which pieces of logic can be done on the client and which cannot. Of those that can be moved to the client side, consider the savings in terms of server resources that could be gained by doing so.
Your goal is to reduce the physical load on the servers in terms of CPU time, memory usage, disk I/O, and network traffic. Because SharePoint is an IIS-based application, you also need to consider the worker threads allocated within IIS as a limited resource to be managed and conserved. Performing calculations and formatting tasks on the client side can help reduce CPU and thread usage. Carefully managing the volume of data being sent to and received from the server can make a big difference when network capacity is at a premium. Of course, having pages load faster is a boost to the user experience even when the servers are lightly loaded.
The following are some concrete suggestions for improving performance and scalability when using the client object model.
Update Only a Small Portion of the Page
Using client-side script, you can retrieve information from the server and display it in the controls and display elements within the current web page instead of posting back and re-rendering the entire page. This eliminates the need to re-render those parts of the page that are not changing. For example, if you are adding an item to a list, there is no need to regenerate the page's navigation controls including all of the security checks and HTML creation that goes with them. Additionally, the network bandwidth consumed will be greatly reduced because there will be less redundant data to transmit.
Carefully Design Request Batches Submitted to the Proxy Layer
When using the client object model, the proxy layer records the requests made to the objects in the ClientContext object. It sends those requests to the server only when explicitly instructed to do so via the ExecuteQueryAsnyc() method. At that time, it packages the requests into an XML document, establishes a connection to the server, and transfers the data. The server then transmits the response data back to the proxy layer as JSON objects. The amount of time and network bandwidth used sending and receiving data is proportional to the amount of data being sent. The overhead associated with the call (connecting, error correcting, and so forth) is fairly consistent for all calls made, no matter how big or small.
To maximize the efficiency of the interaction between the client and server, try to reduce the number of calls by planning the request batches that will be sent to the proxy layer. Each batch should contain as many requests as possible. In some cases, the results of one operation are needed as inputs to the next one. Those operations will have to be in separate batches, but the client object model was designed to minimize this type of dependency. It is possible to open a webpage, find a list, and create list items, all before sending anything to the server.
In short, remember to keep your interactions chunky, not chatty. A few large data transfers are more efficient than many small ones.
Minimize Data Volume by Limiting the Items and Fields Returned
Wait a minute! Didn't we just say to make your request and response batches bigger? Yes—but only as big as they need to be.
When you retrieve an object by using the server-side SharePoint API, you generally expect the object to be populated with all of the properties for the object. In the client object models, you can specify which properties you are interested in so that none of the others need to be retrieved. If you are generating a list of documents in a library, you may be interested in its name and URL, but not its status, creation, and modification information. The size of the response sent from the server to the client can be greatly reduced by carefully selecting only those properties that you are actually going to use after the object is loaded. The concept is similar to writing SQL statements that avoid using SELECT * FROM to retrieve all of the fields in a table. If you cannot list all of the fields in the object, you probably do not need all of their values in the response.
It is also worth mentioning that you should limit the number of items being returned as well. Querying the properties of objects is one operation that is much better done on the server side. Imagine looking for a particular document in a library of a million items by pulling the entire list into the client web browser and then looping through it. The CAML query object is ideal for retrieving only those items and fields that are actually needed.
Use Modal Dialogs Instead of Launching Forms on a New Page
As described earlier in the subsection “User Experience” and shown in Figure 10-2, the client object model contains utility classes, such as SP.UI.ModalDialog, for creating modal dialog boxes within the current page. Although this may seem quite trivial at first, just consider how that same interface would probably have appeared in SharePoint 2007. A full-page post-back would be executed to load a form into the web browser. Then, the form data would be posted to the server. The form data would be processed, and then the user's browser would be redirected to a new page that would have to be completely generated from scratch. By presenting the form in a dialog box, we have turned two complete round-trips to the server into a couple of small requests for HTML and posting data. The rest of the current page remains in the browser, ready for use.
Client-Side Anti-Patterns
Just as it is important to know when to use the client object model, you also need to consider cases in which using it might not be desirable. The dangers introduced by using the client object model are similar to the risks that have always been associated with browser-based scripting.
The most obvious reason not to use client-side scripting is that it might not be available. All modern browsers support ECMAScript, but older browsers may not. Also, some organizations limit or disable scripts when they come from the Internet. Consider the network environment and required browser support when moving to client-side scripts. When creating a public-facing Internet site, your site needs to degrade gracefully when faced with old, or intentionally crippled, browsers.
When you write a client-side script and place it on a web page, you are essentially releasing your source code to the public. Anyone can view and copy the scripts associated with a web page. Never put proprietary logic into the scripts on a web page. Most client-side logic is fairly straightforward, so exposing it isn't really an issue. If your company's secret sauce is algorithms, such as a search technique or financial analysis process, keep it inside the firewall by keeping it on the server.
Remember too that there is nothing to keep hackers from writing their own client object model code or altering the code you include in your web page. Always make sure that the objects within your sites are properly secured against access and modification. Just because you don't provide an interface to access or modify something, doesn't mean that an intruder using a well-known interface, such as the client object model, couldn't do so.
Creating a Client-Side Script
Now you will walk through a few examples using the client object model. You will start with simply reading an object. Then you will write to that object and verify that the change has taken effect. Finally, you will perform a CAML query against a list and display the results.
![]() Note The source files for these exercises can be downloaded from the book's web site at
Note The source files for these exercises can be downloaded from the book's web site at www.apress.com.
Creating a Test Environment
The first step in your exploration of the client object model will be to create a test page in which you can run your scripts. For simplicity's sake, you will your scripts within a Content Editor web part. The script files will be stored in a library on the site. Here are the steps:
- Create a new site by using the Blank Site template.
- Open the site in SharePoint Designer 2010.
- From the Navigation pane, select Lists and Libraries.
- From the New group on the menu, click the Document Library drop-down and select Document Library.
- Name the new library Scripts and then click OK.
- In the Navigation pane, click All Files.
- Click the Scripts link in the file listing.
- From the All Files tab on the menu, click the File drop-down in the New group and select HTML.
- For the filename, type
ListWebTitle.htmland then press Enter. - Open the
ListWebTitle.htmlfile in the Page Editor. - Replace the default HTML with the code in Listing 10-2. The contents of the script are detailed in the next section.
Listing 10-2. List Web Title Script
<script type="text/javascript">
ExecuteOrDelayUntilScriptLoaded(GetProperties, "sp.js");
var web;
function GetProperties() {
var ctx = new SP.ClientContext.get_current();
web = ctx.get_web();
ctx.load(web);
ctx.executeQueryAsync(
Function.createDelegate(this, this.onLoadSuccess),
Function.createDelegate(this, this.onLoadFail));
}
function onLoadSuccess(sender, args) {
document.getElementById('output').innerText =
'Current Web Title: ' + web.get_title();
}
function onLoadFail(sender, args){
document.getElementById('output').innerText =
'Failed to get the web. Error:' + args.get_message();
}
</script>
<h1 id="output"></h1>- Save the file in SharePoint Designer.
- Open the site's defa he Web-Part drop-down and select Content Editor.
- Right-click the new web part and select ult.aspx file in the Page Editor.
- Select the web part zone labeled Left.
- From the Insert tab of the menu, click t
- Web Part Properties.
- In the Content Link text box, type scripts/ListWebTitle.html and then click OK, as shown in Figure 10-4.
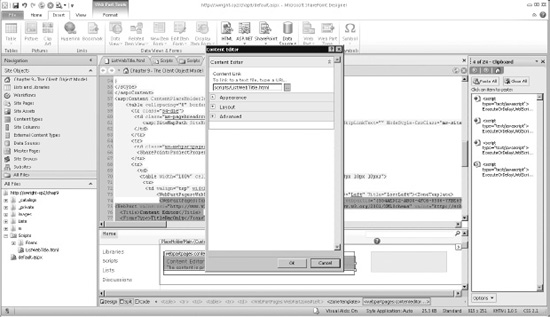
Figure 10-4. Linking a script to a Content Editor web part
- Save the
default.aspx page. - Press F12 to launch the page in a web browser.
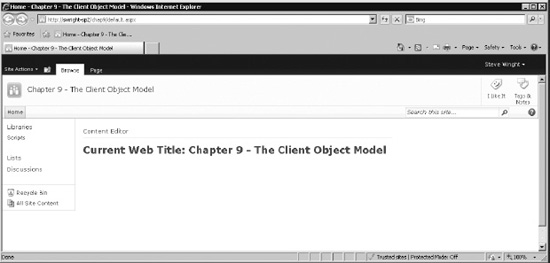
Figure 10-5. Home page with client script
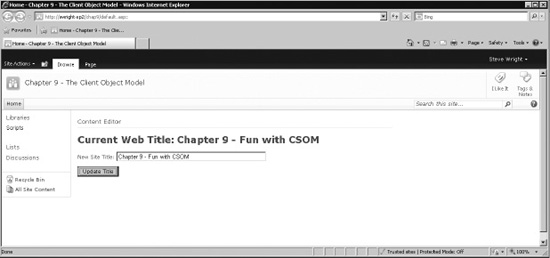
At this point, you have a web part on the home page of your site that reads its contents from a file in the Scripts library. The script currently linked to the web part reads the current site's title property and displays it on the page, as shown in Figure 10-5.
Reading and Writing Object Properties
Loading and manipulating SharePoint objects are probably the most common operations performed when using the SharePoint server object model. It is reasonable to assume that the same will be true for the client-side models. Let's take a closer look at the code in Listing 10-2.
At the highest level, you have a <script> tag followed by an <h1> header tag. The <h1> tag has an ID of output so that you can write into it by using JavaScript. Starting at the top, you can see that the script starts out by loading the sp.js file containing the ECMAScript client object model components:
ExecuteOrDelayUntilScriptLoaded(GetProperties, "sp.js");
var web;
You use ExecuteOrDelayUntilScriptLoaded to ensure that your CSOM code doesn't begin running before the library is loaded. Once loading is complete, you will run the GetProperties method. Next, you declare a global variable that will contain a reference to the site's web object. Remember that site collections are called SPSite or Site in the object models, and sites are SPWeb or Web.
The GetProperties method begins by retrieving a reference to the current client context object. Because this is ECMAScript, the current context is the only one available. You cannot connect to other site collections. Next, you get a reference to the local web object and tell the context to load the properties for it. Looking at the code, you might expect the web object to be ready to use, but you would be wrong. Remember, the proxy layer batches all requests until you explicitly tell it to send them. Up to this point, you have not sent any requests or data to the server whatsoever.
function GetProperties() {
var ctx = new SP.ClientContext.get_current();
web = ctx.get_web();
ctx.load(web);
ctx.executeQueryAsync(
Function.createDelegate(this, this.onLoadSuccess),
Function.createDelegate(this, this.onLoadFail));
}
The last statement in this routine calls the executeQueryAsync method. This causes a request to be sent to the server containing all outstanding requests. In this case, that consists of a request to load the current web site's property values into the object referenced by the web global variable. When the response is received, the proxy layer will populate the objects received and then call either onLoadSuccess, if the call succeeded, or onLoadFail, if it failed.
Both of the onLoad routines perform similar actions. They write a message into the <h1> tag for display on the web page. In the case of success, the object reference saved in the global web variable is used to retrieve the web site's title:
function onLoadSuccess(sender, args) {
document.getElementById('output').innerText =
'Current Web Title: ' + web.get_title();
}
function onLoadFail(sender, args){
document.getElementById('output').innerText =
'Failed to get the web. Error:' + args.get_message();
}
![]() Note If this is the only thing you are going to do with the
Note If this is the only thing you are going to do with the web object, this code is wasteful. The web object contains many properties that will also be returned by this code, which wastes bandwidth. This example would work just as well if you used the following statement to load the web object:
ctx.Load(web, ‘Title'), // Load only the “Title” property
Now that you have seen how to read an object, let's look at updating one. In this example, you will add code to the script that will read the web's title, allow you to update it, and then reread it to ensure that it worked:.
- Create a second HTML file in the Scripts library called
UpdateWebTitle.html. - Replace the file's contents with Listing 10-3.
- Edit the
default.aspxpage and replace theListWebTitle.htmlreference withUpdateWebTitle.html. - Save both files.
Listing 10-3. Update Web Title Script
<script type="text/javascript">
ExecuteOrDelayUntilScriptLoaded(GetProperties, "sp.js");
var web;
function GetProperties() {
var ctx = new SP.ClientContext.get_current();
web = ctx.get_web();
ctx.load(web, 'Title'),
ctx.executeQueryAsync(
Function.createDelegate(this, this.onLoadSuccess),
Function.createDelegate(this, this.onLoadFail));
}
function onLoadSuccess(sender, args) {
document.getElementById('output').innerText =
'Current Web Title: ' + web.get_title();
document.getElementById('txtTitle').value = web.get_title();
}
function onLoadFail(sender, args) {
document.getElementById('output').innerText =
'Failed to get the web. Error:' + args.get_message();
}
function UpdateTitle() {
var ctx = new SP.ClientContext.get_current();
web = ctx.get_web();
web.set_title(document.getElementById('txtTitle').value);
web.update();
ctx.executeQueryAsync(
Function.createDelegate(this, this.onUpdateSucceed),
Function.createDelegate(this, this.onUpdateFail));
}
function onUpdateSucceed(sender, args) {
alert('The title was updated, but you have to refresh the page to see it in the site header.'),
GetProperties();
}
function onUpdateFail(sender, args) {
alert('Unable to update the title. Error: ' + args.get_message());
}
</script>
<h1 id="output"></h1>
<p>
New Site Title:
<input type="text" id="txtTitle" value="" size="50" />
</p>
<p>
<input name="btnUpdate" type="button" value="Update Title"onclick="javascript:UpdateTitle();" />
</p> - Press F12 to launch the
default.aspxpage in your web browser.
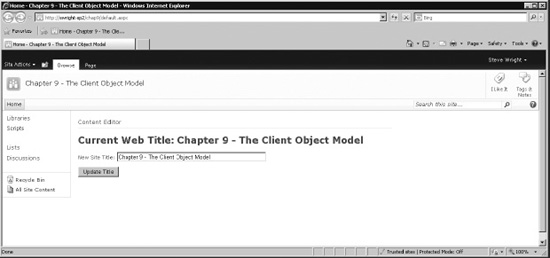
Figure 10-6. Home page with title
- Type a new title for the web site into the text box, as shown in Figure 10-6.
- Click the Update Title button. An alert dialog box displays, as shown in Figure 10-7.
Figure 10-7. Alert dialog box
- Click OK.
- Note that the site title at the top of the page no longer matches the one in the
<h1>tag. This is because the title at the top of the page is updated only when the full page is retrieved from the server.
- Click the Refresh button on your web browser.
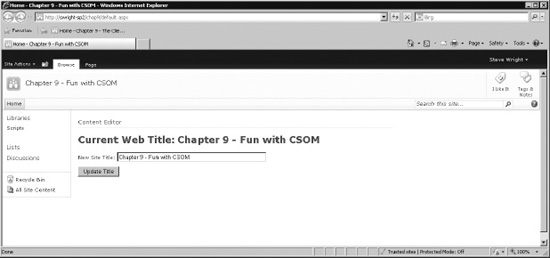
Figure 10-9. Home page with title (refreshed)
The new elements in this page are a text box, an input button, and some additional script. When the page loads, the title is loaded into the text box. The user can then update the title and click the Update Title button. This executes the UpdateTitle method:
function UpdateTitle() {
var ctx = new SP.ClientContext.get_current();
web = ctx.get_web();
web.set_title(document.getElementById('txtTitle').value);
web.update();
ctx.executeQueryAsync(
Function.createDelegate(this, this.onUpdateSucceed),
Function.createDelegate(this, this.onUpdateFail));
}
At first glance, this method looks similar to the GetProperties method you looked at before. The difference is that you are setting the title instead of loading it. Take a close look at the code. You get the context and web objects and then you set the title without loading the web object from the server first. This is an important difference between loading and updating objects. Because of the way the CSOM handles the identity of objects, it is not always necessary to load an object before updating it. In this case, the web object represents the current web site, so there is no need to load it. The object to be updated has already been identified. The call to web.Update() instructs the proxy layer to send the changes to the web object to the server. Again, the request batch is sent only when you call executeQueryAsync.
If you needed to, you could create, update, and delete several objects before sending anything to the server. This makes the passing of requests and responses very efficient because the overhead of the call is shared among multiple requests.
Querying Lists and Libraries with CAML
In our final example, you will see how to query the SharePoint content database efficiently. This includes limiting the number of items you retrieve and the number of properties for those items. Here are the steps:
- Create another HTML file in the Scripts library called
QueryFiles.html. - Replace the file's contents with Listing 10-4.
- Edit the
default.aspxpage and replace theUpdateWebTitle.htmlreference withQueryFiles.html. - Save both files.
Listing 10-4. Query Files Script
<script type="text/javascript">
ExecuteOrDelayUntilScriptLoaded(LoadPages, "sp.js");
var ctx;
var web;
var list;
var itemCollection;
function LoadPages()
{
ctx = new SP.ClientContext.get_current();
web = ctx.get_web();
ctx.load(web);
list = web.get_lists().getByTitle("Scripts");
ctx.load(list);
var qry = new SP.CamlQuery();
qry .set_viewXml(
"<View>"
+ "<ViewFields><FieldRef Name='ID' /><FieldRef Name='FileLeafRef' /><FieldRef Name='Modified' /></ViewFields>"
+ "<RowLimit>50</RowLimit>"
+ "</View>");
itemCollection = list.getItems(qry);
ctx.load(itemCollection);
ctx.executeQueryAsync(
Function.createDelegate(this, this.onQuerySuccess),
Function.createDelegate(this, this.onQueryFailed));
}
function onQuerySuccess(sender, args)
{
var s = '';
var itemEnumerator = itemCollection .getEnumerator();
while (itemEnumerator .moveNext())
{
var item = itemEnumerator .get_current();
s = s + item.get_item('FileLeafRef')
+ ' modified on ' + item.get_item('Modified') + "<br />";
}
document.getElementById('output').innerHTML = s;
}
function onQueryFailed(sender, args)
{
alert('Query failed.'),
}
</script>
<div id="output"></div>
<p>
<input name="cmdRefresh" type="button" value="Refresh" onclick="javascript:LoadPages();"/>
</p> - Press F12 to launch the
default.aspxpage in your web browser (see Figure 10-10).
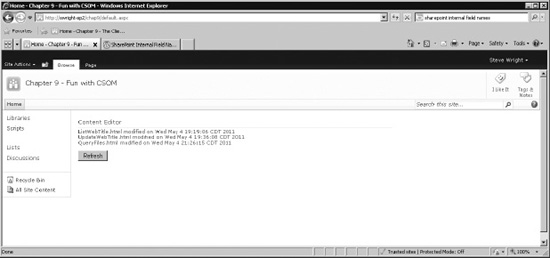
Figure 10-10. Home page with query results
When this script runs, the LoadPages method creates a CamlQuery object that defines the data that you want to retrieve. This is represented by a CAML view definition. In this case, you specify that you want only the ID, FileLeafRef, and Modified fields for up to 50 items. You then use the query to retrieve items from the Scripts document library.
var qry = new SP.CamlQuery();
qry .set_viewXml(
"<View>"
+ "<ViewFields><FieldRef Name='ID' /><FieldRef Name='FileLeafRef' /><FieldRef Name='Modified' /></ViewFields>"
+ "<RowLimit>50</RowLimit>"
+ "</View>");
itemCollection = list.getItems(qry);
ctx.load(itemCollection);
![]() Warning You may have noticed that one of the fields listed in this query is called
Warning You may have noticed that one of the fields listed in this query is called FileLeafRef. Unfortunately, SharePoint fields have two different names: display names and internal names. The display name for a field is the one you see on your web site. The internal field name is used…well…internally. CAML uses internal field names in its queries. FileLeafRef is the internal name for the Name column in a document library. There is no rhyme or reason to the internal names in many cases. For example, the Modified field is called Editor. The Web provides several lists of mappings from display to internal names. Here is one that I use:
http://sharepointmalarkey.wordpress.com/2008/08/21/sharepoint-internal-field-names
When the query completes, the data returned is placed into a collection of objects that can be enumerated and used to access the data returned, as shown here:
var itemEnumerator = itemCollection.getEnumerator();
while (itemEnumerator.moveNext())
{
var item = itemEnumerator.get_current();
s = s + item.get_item('FileLeafRef')
+ ' modified on ' + item.get_item('Modified') + "<br />";
}
CAML queries in SharePoint can do more than just return a certain number of items. They can include a <query> tag that allows the criteria for filtering items to be extensive. A CAML query can also be used to sort the returned items. This gives CAML a level of flexibility similar to that seen in SQL.
Summary
In this chapter, you have
- Explored the various client-side object models exposed by the SharePoint
Client.svcservice - Discussed the best practices for writing ECMAScript client-side code that leverages the client object model
- Considered why running code on the client may be preferable to running it on the server in some cases
- Examined the client object model code for loading, updating, and querying SharePoint objects