
CHAPTER 7
![]()
Indexing Outside the Bubble
When it comes to indexing, there are many best practices we could adhere to. These practices help define how and when we should build our indexes. They provide a starting point for us, and help guide us through creating the best set of indexes on the tables in our databases. Some popular best practices include the following:
- Use clustered indexes on primary keys, by default.
- Index on search columns.
- Use a database-level fill factor.
- Use an index-level fill factor.
- Index on foreign key columns.
This list provides a glimpse of what we should be looking for when indexing a table. The one thing missing from this list is context. It is easy to take a query, look at the tables, and identify the index that is best suited for that query. Unfortunately, in most of our SQL Server environments, there will be more than one query run on the server. In fact, on most databases, there will be hundreds or thousands of queries written against each table. With all of that activity, there are numerous variations of indexes that can be added to the table to get the best performance for each query. This could lead to a situation where the number of indexes on the tables is unsustainable. An insert or update would require so much effort from the SQL Server that the resulting blocking and locking would make the table unusable.
For these reasons, you should not use a query alone as the sole motivation for building an index. Working in isolation like this is sometimes referred to as working in a bubble. The problem with this is that because any one index will affect the other queries that are executed against a table, you must consider them all. You must work outside the bubble of a single query and consider all queries.
Along the same lines, an index that provides the best improvement for a query will not always be justified. If the query is not executed frequently or doesn't have a business need sufficient to justify it, then it isn't always necessary to have the perfect index. In these cases, to borrow from how the query optimizer builds execution plans, the query needs a set of indexes that are “good enough” to get the job done.
In this chapter, we're going to look at how you can break out of the bubble and start indexing for all of the queries that are running against a table, and the database in which it resides. We'll look at at two general areas of justifications for indexes. The first will be the workload that a database is encountering. Through this, we'll examine the tools available to investigate and analyze how to uncover and design the best indexes for the table. In the second part of the chapter, we'll examine how that workload isn't necessarily the only consideration when designing indexes.
The Environment Bubble
The first bubble to break out of when indexing is the environment bubble. You must consider not only the query at hand, but the other queries on the table. Of the two bubbles, this will be the easier, or rather more straightforward, to break out of. In order to so, you should use the following two steps:
- Identify missing indexes.
- Evaluate a workload.
By following these steps, you will break out of the trap of indexing within a bubble and change your indexing practices to consider all of the tables and indexes in the database, rather than the narrow scope of a single query.
Identifying Missing Indexes
The first place to start when indexing is with the missing index recommendations that are available within the SQL Server instance. The main reason to start here is that the SQL Server query optimizer has already determined that these indexing opportunities exist. While there might be other methods for improving query performance outside of adding the missing index, the addition of the index is one of the lowest risk activities you can do to improve performance.
A missing index recommendation can be created whenever a plan is generated for a query. If the statistics on the column are selective enough that an index could improve performance of the query, then the index schema is added to the list of missing index recommendations. However, be aware that there are a few situations where this won't happen. First, if there are already 500 recommendations, then no further recommendations will be made. Second, missing index recommendations won't include clustered, spatial, or columnstore indexes.
Each missing index recommendation includes a number of attributes that define the recommendation. Depending on the source of the recommendation, which we will discuss later in this chapter, the location of the attribute's values will differ. Table 7-1 lists all the attributes that will always be included for each source.

There are some activities that can cause missing index recommendations to be dropped from the list of missing indexes. The first occurs whenever indexes are added to the affected table. Since the new index could potentially cover the columns in the missing index, the suggestions for that table are removed from the queue. In a similar note, when indexes are rebuilt or defragmented, the missing index suggestions will also be removed.
As we review some missing index scenarios, there are a few recommendation limitations that are important to keep in mind. First, the missing index is in regards to the plan that was created. Even if the index is created, there still could be a different missing index suggestion that provides a greater improvement that hadn't been considered by the current plan. Second, the costing information for the inequality columns is less accurate than that of the equality columns because the inequality columns are based on ranges.
With all of the considerations, you might think that using the missing index recommendations doesn't hold much value. Fortunately, that is quite far from the truth. The recommendations that are provided allow you to immediately begin identifying indexing opportunities with minimal work. When done on a regular basis, the information is fresh, relevant, and provides a window into indexes that can easily improve performance on your SQL Server database.
There are two ways within SQL Server to access the missing index recommendations: the dynamic management objects and the plan cache. In the rest of this section, we'll look at how to use these sources to obtain the indexing suggestions.
Dynamic Management Objects
The first method for accessing missing index recommendations is through dynamic management objects (DMOs). Through the DMOs, the missing index information can be collected and viewed. The DMOs are as follows:
sys.dm_db_missing_index_details: This returns a list of missing index recommendations; each row represents one suggested index.sys.dm_db_missing_index_group_stats: This returns statistical information about groups of missing indexes.sys.dm_db_missing_index_groups: This returns information about what missing indexes are contained in a specific missing index group.sys.dm_db_missing_index_columns: For eachindex_handleprovided, the results returns the table columns that are missing an index.
The easiest manner to use the DMOs to return missing index information is by using the first three DMOs in this list (sys.dm_db_missing_index_details, sys.dm_db_missing_index_group_stats, and sys.dm_db_missing_index_groups). These three can be joined together to procedure a query that returns one row for every recommendation that has been identified. The query in Listing 7-1 uses these DMOs to return missing index recommendations.
While the DMOs provide quite a bit of useful information, keep in mind that when you review missing index recommendations, you should look beyond the statistics provided for the recommendation. You can also use those statistics to identify which recommendations would have the most impact on database performance.
The performance impact can be determined through two calculations included in the query. The first calculation, total_impact, provides an aggregate value of average impact to the queries, multiplied by the seeks and scans. This allows you to determine which indexes would have the highest percent impact if implemented. This helps you make judgments on whether an index that improves performance by 90 percent on one query is as valuable as an index that improves performance on 50 queries by 50 percent (where the total impact values would be 90 and 2,500, respectively).
The second calculation, index_score, includes avg_total_user_cost in the equation. Because the cost of a query relates to the amount of work that a query will perform, the impact of improving a query with a cost of 1,000 versus a cost of one will likely result in a greater visible performance improvement. Table 7-2 shows a full list of the columns and the information they provide.
![]() Note Occasionally, people will recommend adding indexes that have values in either the
Note Occasionally, people will recommend adding indexes that have values in either the total_impact or index_score calculations that exceed one value or another. None of these recommendations should ever be taken at face value. The longer a set of recommendations is in the missing index recommendation list, the greater the chance the score will be high. A recommendation shouldn't be accepted just because it is high and has accumulated long enough; it should be accepted after consideration between the other recommendations and the indexes that exist on the table.
Listing 7-1. Query for Missing Index DMOs
SELECT
DB_NAME(database_id) AS database_name
,OBJECT_SCHEMA_NAME(object_id, database_id) AS schema_name
,OBJECT_NAME(object_id, database_id) AS table_name
,mid.equality_columns
,mid.inequality_columns
,mid.included_columns
,migs.avg_total_user_cost
,migs.avg_user_impact
,(migs.user_seeks + migs.user_scans)
* migs.avg_user_impact AS total_impact
,migs.avg_total_user_cost
* (migs.avg_user_impact / 100.0)
* (migs.user_seeks + migs.user_scans) AS index_score
,migs.user_seeks
,migs.user_scans
FROM sys.dm_db_missing_index_details mid
INNER JOIN sys.dm_db_missing_index_groupsmig
ON mid.index_handle = mig.index_handle
INNER JOIN sys.dm_db_missing_index_group_statsmigs
ON mig.index_group_handle = migs.group_handle
ORDER BY migs.avg_total_user_cost * (migs.avg_user_impact / 100.0)
* (migs.user_seeks + migs.user_scans) DESC


The final DMO, sys.dm_db_missing_index_columns, returns a row for every column in the missing index recommendation. Because this DMO is an inline table-valued function, the index handle for the missing index recommendation is required in any queries, such as the example in Listing 7-2. While not especially useful for retrieving the recommendations in a single row, it can be useful when needing the columns for the recommendations returned in separate columns, such as those in Figure 7-1.
Listing 7-2. Query for sys.dm_db_missing_index_columns
SELECT column_id
,column_name
,column_usage
FROM sys.dm_db_missing_index_columns(44)
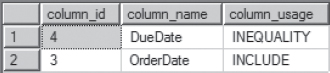
Figure 7-1. Sample output for sys.dm_db_missing_index_columns
To help you understand the recommendations you can retrieve from the missing index DMOs, we'll review the following two scenarios that create missing index recommendations:
- Equality Columns
- Inequality Columns
In the equality scenario, we want to look at the recommendation generated when there are specific value queries from the database. In this scenario, we'll look at the missing index recommendations for three queries, included in Listing 7-3. The first query selects and filters a date on the DueDate column. The second selects the OrderDate column and filters a date on the DueDate column. Finally, the third selects the AccountNumber column while filtering a value on both the DueDate and AccountNumber columns.
After running the query in Listing 7-1 to obtain the missing index recommendations, we see that there are two recommendations based on these three queries, shown in Figure 7-2. The first two queries resulted in the first recommendation, which is evident by the inclusion of two user seeks on the recommendation. This recommendation is for an index with the DueDate column as the index key. The second recommendation includes two columns for the index. This recommendation correlates to the third query in the script, which has two columns (DueDate and AccountNumber) as predicates.
Listing 7-3. Equality Columns Scenario
USE AdventureWorks2012
GO
SELECT DueDate FROM Sales.SalesOrderHeader
WHERE DueDate = '2005-07-13 00:00:00.000'
GO
SELECT OrderDate FROM Sales.SalesOrderHeader
WHERE DueDate = '2010-07-15 00:00:00.000'
GO
SELECT AccountNumber FROM Sales.SalesOrderHeader
WHERE DueDate = '2005-07-13 00:00:00.000'
AND AccountNumber = '10-4020-000676'
GO
Figure 7-2. Missing index recommendations for the Equality Columns scenario
An important aspect to missing index recommendations can be discovered while looking at the second of the recommendations from the first scenario. In that recommendation, the columns for the equality are DueDate and AccountNumber, and it appears they are recommended in that order. The order of the columns in the recommendation does not have any bearing on the most useful order of the columns in the index. As you might already know, indexes should be designed with the most unique columns at the leftmost side of the index. In this case, using the code in Listing 7-4, we are able to determine that there are 1,124 unique DueDate values and 19,119 unique AccountNumber values. The index would be better served with the AccountNumber column leading on the left side of the index. While the index recommendations provide value, you must always check to verify the most useful order of the columns in the index.
Listing 7-4. Column Uniqueness
USE AdventureWorks2012
GO
SELECT COUNT(DISTINCT DueDate) AS UniquenessDueDate
FROM Sales.SalesOrderHeader
SELECT COUNT(DISTINCT AccountNumber) AS UniquenessAccountNumber
FROM Sales.SalesOrderHeader
The second scenario with indexes found in the recommendations is for those that include inequality columns. These are situations where a range of values or multiple values are used in the predicate of a query. In this scenario, we'll examine the effect on missing indexes for four more queries, shown in Listing 7-5. The first query in the list executes on a range of values for the OrderDate and the DueDate columns, and returns the DueDate column. The second query is the same as the first, except the select portion also includes the CustomerID column. The third filters on range of dates on the DueDate column, and returns the DueDate and OrderDate columns. The last query is identical to the third with the exception that it also returns the SalesOrderID, which is the clustered index key column for the table.
Listing 7-5. Inequality Columns Scenario
USE AdventureWorks2012
GO
SELECT DueDate FROM Sales.SalesOrderHeader
WHERE OrderDate Between '20010701' AND '20010731'
AND DueDate Between '20010701' AND '20010731'
GO
SELECT CustomerID, OrderDate FROM Sales.SalesOrderHeader
WHERE DueDate Between '20010701' AND '20010731'
AND OrderDate Between '20010701' AND '20010731'
GO
SELECT DueDate, OrderDate FROM Sales.SalesOrderHeader
WHERE DueDate Between '20010701' AND '20010731'
GO
SELECT SalesOrderID, OrderDate, DueDate FROM Sales.SalesOrderHeader
WHERE DueDate Between '20010701' AND '20010731'
GO
To analyze the recommendations for these queries, execute the missing index query from Listing 7-1. Similar to the equality scenario results, the results for the inequality scenario, included in Figure 7-3, provide some valuable suggestions. Even so, they cannot be taken at face value and require further analysis.
To begin with, the recommendations include two recommendations in which the inequality columns are OrderDate and DueDate. The difference between the two is the inclusion of the CustomerID in the second recommendation. If you were implementing these recommendations, the two would be better consolidated into a single index, since it would cover both queries.
The second item to note is the similarity between the third and fourth suggestions. In these, the only difference is the addition of the SalesOrderID in the fourth index as an included column. Because the SalesOrderID column is the clustering key for the table, there is no reason to include it in the index; it is already there.

Figure 7-3. Missing index recommendations for Inequality Columns scenario
Through both of these scenarios, it should be evident that the missing index recommendations do have an opportunity to provide value. While the recommendations will not always be perfect, they provide a starting point that gives an advantage over those starting from scratch to index the database.
Plan Cache
The second method for identifying missing index recommendations is to retrieve them from cached execution plans. For many readers, it is probably somewhat common to see a missing index recommendation at the top of execution plans (see the example in Figure 7-4). These happen to be the same missing index recommendations as those that appear in the missing index DMOs. The chief difference is that these are associated with specific execution plans and T-SQL statements.

Figure 7-4. Missing index recommendation in a query plan
As is to be expected, it isn't practical to collect all of the execution plans as they are created and used on your SQL Server instance to look for missing index recommendations. Fortunately, that activity isn't required to obtain the information. Instead, the information can be found in the execution plans that are stored in the plan cache. Within these plans, the T-SQL statements that would benefit from missing index recommendations have a MissingIndex node stored in the SHOWPLAN XML for the execution plan, similar to Figure 7-5.

Figure 7-5. Missing index node in SHOWPLAN XML
With the MissingIndex node, you are able to retrieve missing indexes suggestions from the plan cache and associate them with the T-SQL statements that would be directly impacted with the creation of the index. Retrieving the missing index information requires the use of an xquery SQL statement, similar to the one provided in Listing 7-6. In this query, the plans with missing index nodes from the plan cache are identified. With this list, the plans are parsed to retrieve the SQL statements and the database, schema, and table names. Along with that, the impact, equality, inequality, and included columns are retrieved. Since the plan cache is being accessed, the use counts for the plan and the execution plan can also be included, such as in the example script. When executed after the queries from Listing 7-6, the results from Figure 7-6 should be returned.
Listing 7-6. Query for Missing Index from Plan Cache
WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
,PlanMissingIndexes
AS (
SELECT query_plan, cp.usecounts
FROM sys.dm_exec_cached_plans cp
OUTER APPLY sys.dm_exec_query_plan(cp.plan_handle) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
)
SELECT
stmt.value('(//MissingIndex/@Database)[1]', 'sysname') AS database_name
,stmt.value('(//MissingIndex/@Schema)[1]', 'sysname') AS [schema_name]
,stmt.value('(//MissingIndex/@Table)[1]', 'sysname') AS [table_name]
,stmt.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text
,pmi.usecounts
,stmt.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact
,stmt.query('for $group in //ColumnGroup
for $column in $group/Column
where $group/@Usage="EQUALITY"
return string($column/@Name)
').value('.', 'varchar(max)') AS equality_columns
,stmt.query('for $group in //ColumnGroup
for $column in $group/Column
where $group/@Usage="INEQUALITY"
return string($column/@Name)
').value('.', 'varchar(max)') AS inequality_columns
,stmt.query('for $group in //ColumnGroup
for $column in $group/Column
where $group/@Usage="INCLUDE"
return string($column/@Name)
').value('.', 'varchar(max)') AS include_columns
,pmi.query_plan
FROM PlanMissingIndexes pmi
CROSS APPLY pmi.query_plan.nodes('//StmtSimple') AS p(stmt)

Figure 7-6. Missing index nodes obtained from plan cache
In many respects, the results returned from the plan cache for missing indexes is identical to querying the missing index DMOs. There are, of course, a few key and important differences between the two. With the missing index DMOs, you have information on whether the query would have used a seek or scan with the missing index. On the other hand, using the plan cache provides the actual plan and T-SQL statement that generate the missing index recommendation. Where the DMOs help you know how a new index will be used, the plan cache is where you want to go to determine what will be affected. And by knowing what code will be affected, you know what the testers need to test, where the performance improvements will be, and have the opportunity to consider whether an index is really the best way to mitigate the performance issue uncovered by the missing index recommendation.
![]() Note Since the plan cache is critical to the performance of queries in your SQL Server instances, be cautious when querying the plan cache. While there will often be no impact when it is queried, be careful when using any plan cache query in a production environment and be on alert for unexpected behavior.
Note Since the plan cache is critical to the performance of queries in your SQL Server instances, be cautious when querying the plan cache. While there will often be no impact when it is queried, be careful when using any plan cache query in a production environment and be on alert for unexpected behavior.
Index Tuning a Workload
After looking at the missing indexes recommendations, the next place to look for index suggestions is to use the Database Engine Tuning Advisor (DTA). The DTA is an indexing tool included with SQL Server that can be used to evaluate a workload, or collection of queries, to determine what indexes would be useful for those queries. This activity goes beyond the recommendations made by the missing index processes discussed in previous sections. Where the missing index processes can identify statistics that would be best materialized as indexes, the DTA can do much more. As examples, the DTA is capable of the following:
- Suggesting changes to clustered indexes
- Identifying when partitioning would be of value
- Recommending nonclustered indexes
By using the DTA with some automation, you can start identifying early when to make changes to more than just missing nonclustered indexes. Instead, you can begin to dig deep into indexing with minimal effort. Instead of time spent imagining new indexes, you can shift your focus to validating suggestions and digging into more complicated performance issues that are outside the boundaries of where DTA functions.
![]() Note The Database Engine Tuning Advisor (DTA) is often shunned by senior-level database administrators and developers. For various reasons, it is seen as an unwelcomed crutch to indexing and performance tuning. While not all recommendations will make it to production environments, the work that it can do and effort that it replaces is of high value. Ignoring the value of DTA is akin to the stories from American folklore of the railroad workers trying to beat the steam powered tools. In the end, this tool frees us from menial work so we can expand our horizons and skills.
Note The Database Engine Tuning Advisor (DTA) is often shunned by senior-level database administrators and developers. For various reasons, it is seen as an unwelcomed crutch to indexing and performance tuning. While not all recommendations will make it to production environments, the work that it can do and effort that it replaces is of high value. Ignoring the value of DTA is akin to the stories from American folklore of the railroad workers trying to beat the steam powered tools. In the end, this tool frees us from menial work so we can expand our horizons and skills.
Collecting a Workload
In order to test a series of queries, to determine whether they are in need of additional indexes, you must first collect the queries in which you wish to discover indexing opportunities. There are a few ways that a workload can be gathered. In many situations, you could ask peers what queries they think need performance improvements, you could check with developers to see what they believe the applications are using most frequently, or you could ask the business to identify the most important queries in the database.
The chief issue with all of these methods is that they often bear relationship to the queries that the SQL Server instance is actually processing. Your peers will know what they think the problems are, but what about the smaller, more frequently run queries that are bleeding the server with small performance issues? While application developers know what an application does, they don't necessarily know what the users are using and how often. Also, the features and functionality important to the business users might not be the activity on the database that needs the most assistance or should be the primary focus.
An alternative method to using the resources already discussed is to have the SQL Server instance or database tell you the queries that are most often used. In that way, you can look at those queries and determine what indexes, through DTA, are needed on the database. Ideally, you will want to collect a sample of queries from times in which the applications are generating activity that matches common portions of the application life cycle. If the business's peak activity occurs from noon to 5 P.M., then you will want to capture the workload from that time period. Capturing activity overnight or in the morning won't provide the information necessary to adequately build indexes for your databases.
There are a few ways to collect your workload. In this chapter, we'll look at two of the most common methods. These methods are by using SQL Profiler and Extended Events. With each of these methods, we'll look at how the process for collecting information can be set up and configured, and then how the workload collection itself can be automated.
SQL Trace
The most often recommended approach for collecting a workload for DTA is to use the Tuning template from SQL Profiler (see Figure 7-7) and launching it as a SQL Trace session. The Tuning template is specifically designed for use with the Database Engine Tuning Advisor to provide the queries necessary for a workload. Within the template are the following three events, shown in Figure 7-8:
- RPC: Completed
- SP: Completed
- SQL: Batch Completed
For these events, information on the SQL statements, SPID, DatabaseName, DatabaseID, and others are collected. This template provides all of the information necessary for DTA to be able to provide recommendations.
Figure 7-7. Select the Tuning SQL Profiler template
Figure 7-8. Tuning template configuration
One piece not included in the Tuning template is a filter for the workload export. In some cases, you might want to only examine a single database at a time with the DTA. If that is the case, you'll also want to limit the workload collected down to that database. You can do so by adding a filter to the Profiler session. For example, in the upcoming scenario, the DTA will be used against AdventureWorks2012. To filter the workload, add a filter to the DatabaseName column in the Like category, as shown in Figure 7-9.
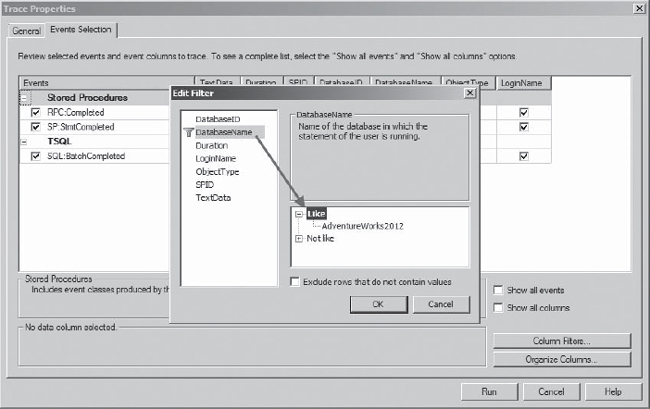
Figure 7-9. Filtering the workload export to a single database
If you are familiar with SQL Profiler, you'll likely already know that collecting a workload using SQL Profiler can be burdensome. With SQL Profiler, all of the events need to be passed from SQL Server to the workstation running the trace. Also, the information is stored only in the GUI, which can't be used by DTA when running the workload.
To get around these issues, you will want to create a SQL Trace session identical to the Tuning temple. Using the code in Listing 7-7, you can create this session. Alternatively, you can also export a SQL Profiler session to a file and obtain a script similar to the one provided. The primary difference between the script provided and the one available through SQL Profiler is the variable for the trace file and increased size (50 MB) for the trace files in the provided script.
Listing 7-7. SQL Trace Session for Tuning Template
-- Create a Queue
declare @rcint
declare @TraceIDint
declare @maxfilesize BIGINT
DECLARE @tracefileNVARCHAR(255) = 'c: empindex_workload'
set @maxfilesize = 50
exec @rc = sp_trace_create @TraceID output, 0, @tracefile, @maxfilesize, NULL
if (@rc != 0) goto error
-- Set the events
declare @on bit
set @on = 1
execsp_trace_setevent @TraceID, 10, 1, @on
execsp_trace_setevent @TraceID, 10, 3, @on
execsp_trace_setevent @TraceID, 10, 11, @on
execsp_trace_setevent @TraceID, 10, 12, @on
execsp_trace_setevent @TraceID, 10, 13, @on
execsp_trace_setevent @TraceID, 10, 35, @on
execsp_trace_setevent @TraceID, 45, 1, @on
execsp_trace_setevent @TraceID, 45, 3, @on
execsp_trace_setevent @TraceID, 45, 11, @on
execsp_trace_setevent @TraceID, 45, 12, @on
execsp_trace_setevent @TraceID, 45, 13, @on
execsp_trace_setevent @TraceID, 45, 28, @on
execsp_trace_setevent @TraceID, 45, 35, @on
execsp_trace_setevent @TraceID, 12, 1, @on
execsp_trace_setevent @TraceID, 12, 3, @on
execsp_trace_setevent @TraceID, 12, 11, @on
execsp_trace_setevent @TraceID, 12, 12, @on
execsp_trace_setevent @TraceID, 12, 13, @on
execsp_trace_setevent @TraceID, 12, 35, @on
-- Set the Filters
declare @intfilter int
declare @bigintfilter bigint
execsp_trace_setfilter @TraceID, 35, 0, 6, N'AdventureWorks2012'
-- Set the trace status to start
execsp_trace_setstatus @TraceID, 1
-- display trace id for future references
selectTraceID=@TraceID
goto finish
error:
selectErrorCode=@rc
finish:
go
When you're ready, run the script to start collecting the workload. After a while, you will need to stop the trace session so that you can use the trace data that is output. Be certain to run the workload long enough to collect enough queries to represent a worthwhile workload from your environment. To stop the session you can use the sp_trace_setstatus stored procedure.
Extended Events
One of the possible sources for the DTA is a table that contains SQL statements; you can also use extended events to collect your workload. Generally, this will provide the same information as the SQL Trace session. There are a few differences that make the use of extended events a bit more appealing.
First, you have more control on what is collected for the event. Each event comes with a number of base columns, but you can add more to fit your needs. Of course, you can add more events to use the session for additional activities. Second, you have more control over the targets, such as being able to determine whether you want all events, no matter what, or some events can be dropped to just capture a sample of the events. Finally, many events within extended events perform substantially better than the similar event does in SQL Trace. Through the lower overhead, you are able to investigate more often with less concern over the impact of your activities.
As already mentioned, to use extended events with the DTA, the events will need to be stored in a table. The table definition, provided in Listing 7-8, matches the definition of a table that would be created when saving the SQL Profiler session based on the Tuning template. The table contains a RowNumber column and then a column for each of the attributes of the trace being collected.
Listing 7-8. Table for Extended Events Workload
CREATE TABLE dbo.indexing_workload(
RowNumberintIDENTITY(0,1) NOT NULL,
EventClassint NULL,
TextDatanvarchar(max) NULL,
Duration bigint NULL,
SPID int NULL,
DatabaseIDint NULL,
DatabaseNamenvarchar(128) NULL,
ObjectTypeint NULL,
LoginNamenvarchar(128) NULL,
BinaryDatavarbinary(max) NULL,
PRIMARY KEY CLUSTERED (RowNumber ASC))
With the table in place, the next step is to create the extended event session. To start, we'll build the session through SQL Server Management Studio (SSMS), and then script out the session to allow it to be customized as you require. Begin by browsing through SSMS to the Management à Extended Events node in the Object Explorer. From here right-click on Sessions and select the option for New Session Wizard, as shown in Figure 7-10.
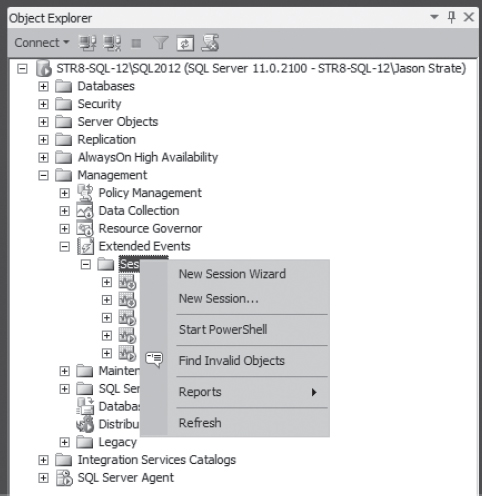
Figure 7-10. Browse Object Explorer for extended events
The session wizard will launch an introduction screen. From this screen, select the Next option. If you would like, you can select the “Do not show this page again” option to avoid this screen in the future.
The next screen in the wizard is the Set Session Properties screen, which is shown in Figure 7-11. Here, you will name the extended events session. For this example, type indexing_workload; this matches the activities that you are planning to perform. Also, select “Start the event session at server startup” to make certain that when the server stops for maintenance or a instance failover that the data is still collected. This functionality of extended events makes using extended events as the workload source superior to SQL Trace, because a SQL Trace session will have to be re-created to be used after a SQL Server instance restart. Click Next to continue.
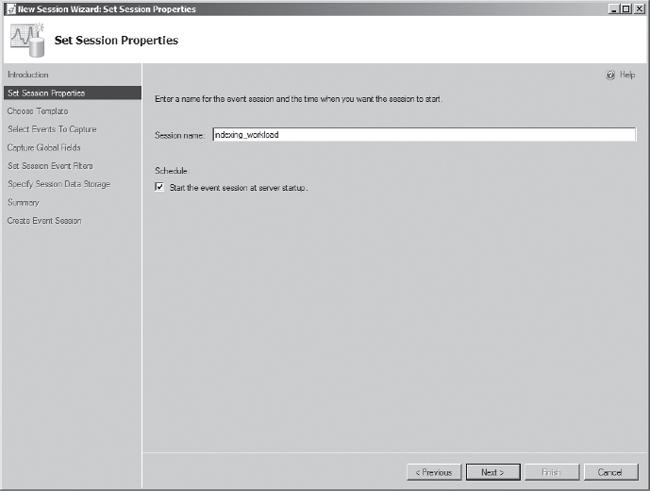
Figure 7-11. Extended events wizard Set Session Properties screen
The next screen of the wizard contains the options for choosing a template, as shown in Figure 7-12. There are a number of templates available, but we are looking for specific events in our trace and will not use a template. Select the option “Do not use a template” and then select Next.
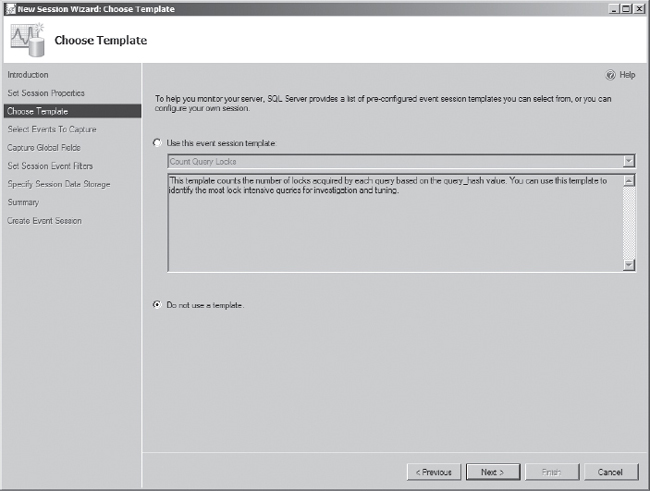
Figure 7-12. Extended events wizard Choose Template screen
The next step is to select the events that will be captured through the extended events session. These are configured on the Select Events To Capture screen of the wizard. To configure the session similar to the SQL Profiler Tuning session, you need to select the events in extended events that match the RPC: Completed, SP: Completed, and SQL: Batch Completed events. The easiest way to discover these events is to use the event filter and retrieve all of the events with the word completed in their names, as shown in Figure 7-13. The events to select are rpc_completed, sp_statement_completed, and sql_statement_completed. After you've selected these events, click the Next button to continue.
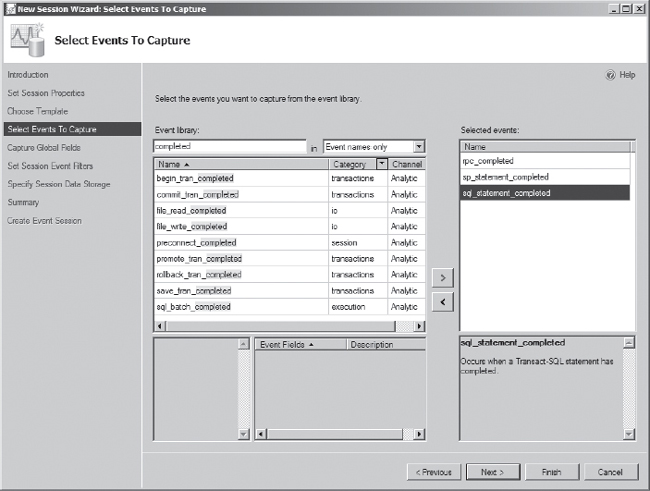
Figure 7-13. Extended events wizard Select Events To Capture screen
Each extended event has its own set of columns, but these don't cover all of the columns required for matching the extended event session to the SQL trace session. To accomplish this, you need to add some additional columns to the session on the Capture Global Fields screen of the wizard. The additional fields to include, which are shown in Figure 7-14, are as follows:
database_iddatabase_namesession_idusername
After selecting the global fields, click the Next button to continue to the next screen of the wizard.
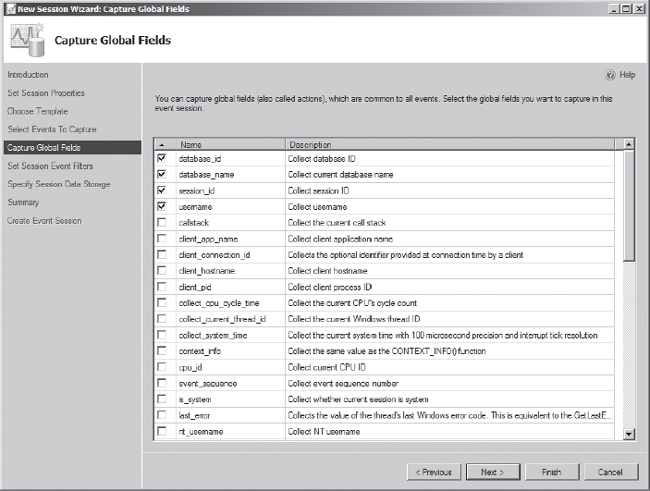
Figure 7-14. Extended events wizard Capture Global Fields screen
The next step in building the session is adding filter criteria to the session via the Set Session Event Filters screen, shown in Figure 7-15. There are two filters that will be worthwhile for most loads. The first removes system activity using the is_systemfield filter, since we won't be indexing any system tables. The second limits the events only to those that are occurring in the database in which we want to look at improving indexing. In this case, it is only the AdventureWorks2012 database, which has the database ID of 18 on the demonstration server used for this chapter.
You can use either the database_name or database_id columns for the filtering. It is typically preferred to use the database_id column because the data types for the filtering are smaller. On the other hand, using the database_name for the filter is easier to port between servers, which would likely not have identical database_id values. When building filters, it is important to configure them in the order of highest selectivity, as extended events filtering supports short-circuiting.
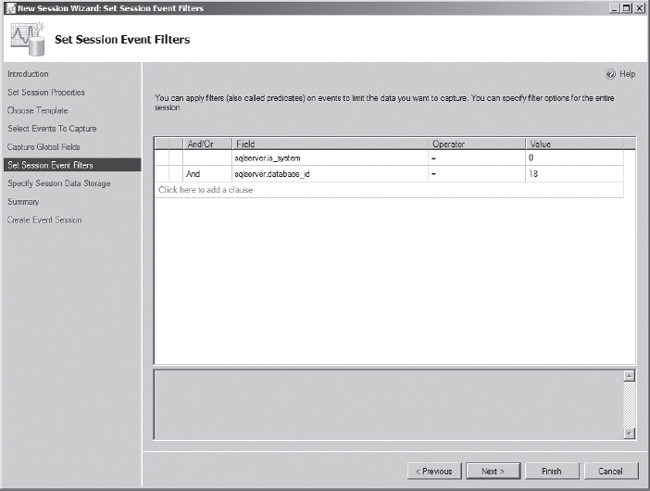
Figure 7-15. Extended events wizard Set Session Event Filters screen
The last step in configuring the extended events session is to configure the target for the events. On the Specify Session Data Storage screen, shown in Figure 7-16, select the option for “Save data to a file for later analysis (event_file target).” You can use the default file location, but you should be certain that it is a location that will not conflict with other more important I/O activity, such as tempdb and transaction files. Click Next to continue, or Finish to build and start the session. The next screen in the wizard summarizes the session and builds the session.
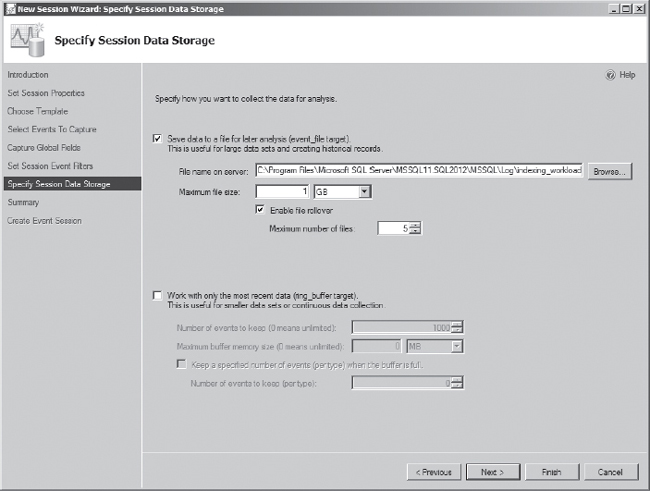
Figure 7-16. Extended events wizard Specify Session Data Storage screen
Alternatively to building the extended event session through the wizard, you can also build the session through T-SQL DDL commands. To do this, you will use the CREATE EVENT SESSION statement, provided in Listing 7-9, which includes event, action, predicate, and target information in a single statement.
Using DDL is much easier when you want to build and create the sessions on many servers, and allows you to avoid using the wizard time and again. One difference between the wizard-created session and the one provided in Listing 7-9 is the inclusion of the EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS option in the session. The use of this option is advised, as it will allow the extended event session to drop events in situations where the server is taxed with other activities. In general, this should be the case, but you will likely want to allow for this.
Listing 7-9. Create Extended Events Session
CREATE EVENT SESSION [indexing_workload] ON SERVER
ADD EVENT sqlserver.rpc_completed(
SET collect_data_stream=(1),collect_statement=(1)
ACTION(sqlserver.database_id,sqlserver.database_name
,sqlserver.session_id,sqlserver.username)
WHERE (([sqlserver].[is_system]=(0))
AND ([sqlserver].[database_id]=(18)))),
ADD EVENT sqlserver.sp_statement_completed(
ACTION(sqlserver.database_id,sqlserver.database_name
,sqlserver.session_id,sqlserver.username)
WHERE (([sqlserver].[is_system]=(0))
AND ([sqlserver].[database_id]=(18)))),
ADD EVENT sqlserver.sql_statement_completed(
ACTION(sqlserver.database_id,sqlserver.database_name
,sqlserver.session_id,sqlserver.username)
WHERE (([sqlserver].[is_system]=(0))
AND ([sqlserver].[database_id]=(18))))
ADD TARGET package0.event_file(
SET filename=N'C: empindexing_workload.xel')
WITH (STARTUP_STATE=ON,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS)
GO
After the session has been created, you will need to start the session for it to begin collecting events. The session should be run for the period that was determined at the start of this section. The code provided in Listing 7-10 can be used to start and stop the session.
Listing 7-10. Start and Stop the Session
--Start Session
ALTER EVENT SESSION indexing_workload ON SERVER STATE = START
GO
--Stop Session
ALTER EVENT SESSION indexing_workload ON SERVER STATE = STOP
GO
When the extended event session has been stopped, the data from the session will need to be inserted into the table dbo.indexing_workload, which was created in Listing 7-8. Listing 7-11 shown how we accomplish this. Because the extended event session was output to a file target, the function sys.fn_xe_file_target_read_file is used to read the data back into SQL Server. One of the benefits of using the file target in this scenario, is that the files can be read into any server; this means you can perform the analysis on any server and, specifically, not on the production server.
Listing 7-11. Insert Extended Event Session into dbo.indexing_workload
WITH indexing_workload AS (
SELECT object_name as event
,CONVERT(xml, event_data) as XMLData
FROMsys.fn_xe_file_target_read_file
('C: empindexing_workload*.xel'
, 'C: empindexing_workload*.xem'
, null, null))
INSERT INTO dbo.indexing_workload
(
EventClass
, TextData
, Duration
, SPID
, DatabaseID
, DatabaseName
, ObjectType
, LoginName
, BinaryData
)
SELECT
CASE event
WHEN 'sp_statement_completed' THEN 43
WHEN 'sql_statement_completed' THEN 12
WHEN 'rpc_completed' THEN 10
END
, XMLData.value('(/event/data[@name=''statement'']/value)[1]','nvarchar(max)')
, XMLData.value('(/event/data[@name=''duration'']/value)[1]','bigint')
, XMLData.value('(/event/action[@name=''session_id'']/value)[1]','int')
, XMLData.value('(/event/action[@name=''database_id'']/value)[1]','int')
, XMLData.value('(/event/action[@name=''database_name'']/value)[1]','nvarchar(128)')
, XMLData.value('(/event/data[@name=''object_type'']/value)[1]','bigint')
, XMLData.value('(/event/action[@name=''username'']/value)[1]','nvarchar(128)')
, XMLData.value('xs:hexBinary((/event/data[@name=''data_stream'']/value)[1])'
,'varbinary(max)')
FROM indexing_workload
ORDER BY XMLData.value('(/event/@timestamp)[1]','datetime') ASC
GO
With all of the steps in this section complete, you will have the information collected for your indexing workload. The next steps will be to prepare a database for the workload to analyze indexes against and then to run the Database Engine Tuning Advisor.
Sample Workload
We'll next look at a sample workload that will help demonstrate some the value of using the Database Engine Tuning Advisor. Prior to running the workload, we'll make one change to the AdventureWorks2012 database to allow DTA to identify a clustering index issue. We'll change the clustering key on Sales.SalesOrderDetail from SalesOrderID and SalesOrderDetailID to just SalesOrderDetailID. The code in Listing 7-12 will perform this change.
Listing 7-12. Change the Clustering Key on Sales.SalesOrderDetail
ALTER TABLE Sales.SalesOrderDetail
DROP CONSTRAINT PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID
GO
ALTER TABLE Sales.SalesOrderDetail ADD CONSTRAINT
PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID PRIMARY KEY NONCLUSTERED
(
SalesOrderID,
SalesOrderDetailID
)
GO
CREATE CLUSTERED INDEX CLUS_SalesOrderDetail ON Sales.SalesOrderDetail
(
SalesOrderDetailID
)
GO
The workload, provided in Listing 7-13, contains scripts that accomplish the following:
- Query
Sales.SalesOrderHeaderfiltering onDueDate.- Query
Sales.SalesOrderHeaderfiltering onDueDateandAccountNumber.- Query
Sales.SalesOrderHeaderfiltering onDueDateandOrderDate.- Execute stored procedure
dbo.uspGetBillOfMaterials.- Query
Sales.SalesOrderDetailfiltering onSalesOrderDetailID.
Listing 7-13. Sample AdventureWorks2012 Query
USE AdventureWorks2012
GO
SELECT DueDate FROM Sales.SalesOrderHeader
WHERE DueDate = '2005-07-13 00:00:00.000'
GO 10
SELECT OrderDate FROM Sales.SalesOrderHeader
WHERE DueDate = '2010-07-15 00:00:00.000'
GO 10
SELECT AccountNumber FROM Sales.SalesOrderHeader
WHERE DueDate = '2005-07-13 00:00:00.000'
AND AccountNumber = '10-4020-000676'
GO 15
SELECT DueDate FROM Sales.SalesOrderHeader
WHERE OrderDateBetween '20010701' AND '20010731'
AND DueDateBetween '20010701' AND '20010731'
GO 10
SELECT CustomerID, OrderDate FROM Sales.SalesOrderHeader
WHERE DueDateBetween '20010701' AND '20010731'
AND OrderDateBetween '20010701' AND '20010731'
GO 10
SELECT DueDate, OrderDate FROM Sales.SalesOrderHeader
WHERE DueDateBetween '20010701' AND '20010731'
GO 10
SELECT SalesOrderID, OrderDate, DueDate FROM Sales.SalesOrderHeader
WHERE DueDateBetween '20010701' AND '20010731'
GO 10
EXEC [dbo].[uspGetBillOfMaterials] 893, '2004-06-26'
GO 10
EXEC [dbo].[uspGetBillOfMaterials] 271, '2004-04-04'
GO 10
EXEC [dbo].[uspGetBillOfMaterials] 34, '2004-06-04'
GO 10
SELECT sod.*
FROM Sales.SalesOrderHeadersoh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE OrderDateBetween '20010701' AND '20010731'
GO 100
Preparing the Database
In an ideal world, you will have unlimited space and servers for testing that exactly match your production environment. We don't all live in an ideal world, and that means that when it comes to finding a database that is identical to production for indexing, we are often left with a server that has significantly less space in it than the production database has. For this reason, there needs to be a method to test a workload against a database as similar as possible to production so that the recommendations will match the same recommendations that you would received if the test were run in production.
We can find a solution to the problem through a process commonly referred to as cloning the database. A cloned database is one that contains the exact schema of the source database on the destination, along with the statistics and histogram information from the source in the destination. In this case, the execution plans generated in the destination database will be identical to those generated in the source database. Because the same execution plans will be generated in both databases, the indexes used or needed will be the same.
There are various means to clone a database. You can use the generate scripts wizard in SSMS. You can restore a database, disable stats updates, and then delete all of the data. Or you can leverage PowerShell and Server Management Objects (SMO) to build a script. The advantage to using a PowerShell script is the ability to build the process once and run it over and over again. Because you will want to run multiple workloads over time, the best option is to use a solution that is easily repeatable.
Using PowerShell to clone a database takes just a few steps. These steps are as follows:
- Connect to source instance and database.
- Connect to destination instance and validate that database does not exist.
- Create destination database.
- Set database scripting options on the source database.
- Create clone script from source database.
- Execute clone script on destination database.
While there are various ways to accomplish each of these steps, the script in Listing 7-14 provides one means of doing so. The script executes each of the steps and includes variables that can be used to change the SQL Server instance and database names.
Listing 7-14. PowerShell Script to Clone Database
$version = [System.Reflection.Assembly]::LoadWithPartialName( "Microsoft.SqlServer.SMO")
if ((($version.FullName.Split(','))[1].Split('='))[1].Split('.')[0] -ne '9') {
[System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SMOExtended") |
out-null}
$SourceServer = 'STR8-SQL-12SQL2012'
$SourceDatabase= 'AdventureWorks2012'
$DestinationServer= 'STR8-SQL-12'
$DestinationDatabase = 'AdventureWorks2012'
$SourceServerObj = new-object("Microsoft.SqlServer.Management.SMO.Server") $SourceServer
if ($SourceServerObj.Version -eq $null ){Throw "Can't find source SQL Server instance:
$SourceServer"}
$SourceDatabaseObj = $SourceServerObj.Databases[$SourceDatabase]
if ($SourceDatabaseObj.name -ne $SourceDatabase){
Throw "Can't find the source database '$SourceDatabase' on $SourceServer"};
$DestinationServerObj = new-object ("Microsoft.SqlServer.Management.SMO.Server")
$DestinationServer
if ($DestinationServerObj.Version -eq $null ){
Throw "Can't find destination SQL Server instance: $DestinationServer"}
$DestinationDatabaseObj = $DestinationServerObj.Databases[$DestinationDatabase]
if ($DestinationDatabaseObj.name -eq $DestinationDatabase){
Throw "Destination database '$DestinationDatabase' exists on $DestinationServer"};
$DestinationDatabaseObj = new-object
('Microsoft.SqlServer.Management.Smo.Database')($DestinationServerObj,
$DestinationDatabase)
$DestinationDatabaseObj.Create()
#Required options per http://support.microsoft.com/kb/914288
$Options = new-object ("Microsoft.SqlServer.Management.SMO.ScriptingOptions")
$Options.DriAll = $true
$Options.ScriptDrops = $false
$Options.Indexes = $true
$Options.FullTextCatalogs = $true
$Options.FullTextIndexes = $true
$Options.FullTextStopLists = $true
$Options.ClusteredIndexes = $true
$Options.PrimaryObject = $true
$Options.SchemaQualify = $true
$Options.Triggers = $true
$Options.NoCollation = $false
$Options.NoIndexPartitioningSchemes = $false
$Options.NoFileGroup = $false
$Options.DriPrimaryKey = $true
$Options.DriChecks = $true
$Options.DriAllKeys = $true
$Options.AllowSystemObjects = $false
$Options.IncludeIfNotExists = $false
$Options.DriForeignKeys = $true
$Options.DriAllConstraints = $true
$Options.DriIncludeSystemNames = $true
$Options.AnsiPadding = $true
$Options.IncludeDatabaseContext = $false
$Options.AppendToFile = $true
$Options.OptimizerData = $true
$Options.Statistics = $true
$transfer = new-object ("Microsoft.SqlServer.Management.SMO.Transfer") $SourceDatabaseObj
$transfer.options=$Options
$output = $transfer.ScriptTransfer()
$DestinationDatabaseObj.ExecuteNonQuery($output)
Performing Analysis
At this point, you will have the sample workload from your database environment and a cloned database to use with the Database Engine Tuning Advisor. The next step is to pull these together into a tuning session and review the results. There are two basic methods to execute a workload against a database. You can use the GUI that comes with DTA, which is probably the most familiar method for using DTA; or you can use the same tool, but through a command-line interface. We will use the command-line interface with dta.exe in this chapter. The primary reason is that it easily ties into the theme of scriptable actions that have been used for the previous activities.
![]() Note More information on indexing and using DTA can be found in Expert Performance Indexing for SQL Server 2012 by Jason Strate and Ted Krueger (Apress, 2012).
Note More information on indexing and using DTA can be found in Expert Performance Indexing for SQL Server 2012 by Jason Strate and Ted Krueger (Apress, 2012).
Through dta.exe, you'll provide the tool with an XML configuration file which will provide all of the information needed to run the workload against the database. The XML configuration files provided in Listings 7-15 and 7-16 can be used to configure dta.exe to run against either SQL Profiler .trc files or the dbo.indexing_workload table, respectively. The other options in the XML input file configure the following attributes:
- SQL Server instance name set to STR8-SQL-12
- Database name set to AdventureWorks2012
- Workload set to either files or table
- Tune clustered and nonclustered indexes
- Do not consider additional partitioning
- Keep none of the existing clustered and nonclustered indexes
Through these options, the DTA will be able to do more than what is possible through the missing indexes feature. Where missing indexes provide suggestions for where statistics could be made into nonclustered indexes that will improve performance, the DTA can suggest when to consider partitioning or, even, when to move the clustered index.
Listing 7-15. Sample XML Input File for DTA Using .trc Files
<?xml version="1.0" encoding="utf-16" ?>
<DTAXML xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://schemas.microsoft.com/sqlserver/2004/07/dta">
<DTAInput>
<Server>
<Name>STR8-SQL-12</Name>
<Database>
<Name>AdventureWorks2012</Name>
</Database>
</Server>
<Workload>
<File>c: empindex_workload.trc</File>
</Workload>
<TuningOptions>
<StorageBoundInMB>3000</StorageBoundInMB>
<FeatureSet>IDX</FeatureSet>
<Partitioning>NONE</Partitioning>
<KeepExisting>NONE</KeepExisting>
</TuningOptions>
</DTAInput>
</DTAXML>
Listing 7-16. Sample XML Input File for DTA Using dbo.indexing_workload Table
<?xml version="1.0" encoding="utf-16" ?>
<DTAXML xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://schemas.microsoft.com/sqlserver/2004/07/dta">
<DTAInput>
<Server>
<Name>STR8-SQL-12</Name>
<Database>
<Name>AdventureWorks2012</Name>
</Database>
</Server>
<Workload>
<Database>
<Name>tempdb</Name>
<Schema>
<Name>dbo</Name>
<Table>
<Name>indexing_workload</Name>
</Table>
</Schema>
</Database>
</Workload>
<TuningOptions>
<StorageBoundInMB>3000</StorageBoundInMB>
<FeatureSet>IDX</FeatureSet>
<Partitioning>NONE</Partitioning>
<KeepExisting>NONE</KeepExisting>
</TuningOptions>
</DTAInput>
</DTAXML>
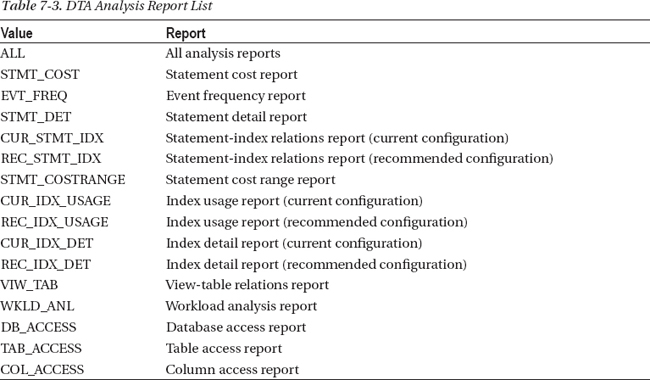
After building the XML input file for the tuning session, save the file as WorkloadConfig.xml, or any other appropriate name that you can remember. The next step is to execute the session against dta.exe using command-line arguments, such as those provided in Listing 7-17. To pass in the input file, you will use the ix argument. For the report outputs, you will need to use the ox argument to determine where to place the reports and the rl argument output format. Table 7-3 shows a list of available report outputs. Along with those arguments, you will also need the s argument to specify a name for the session. Session names must always be unique.
Listing 7-17. DTA Command with XML Input File
dta -ix "c: empWorkloadConfig.xml" -ox "c: empOutput.xml" -rl ALL -s Workload
When the execution completes, you will be presented with an XML report that details the indexing recommendations. You can use these to identify potential new indexes to add, along with information on indexes that can be removed from the database. From a high level, the output report will contain all of the individual reports that are requested from tuning sessions. This will look like the XML document shown in Figure 7-17. Examining the individual recommendations, the results will include items such as the index recommendation that is shown in Figure 7-18.
While there is still work to be done to validate the results, the key with using the DTA is that the heavy lifting has already been done. You aren't going to be using your time to consider and test new index configurations; rather, you'll be spending your time validating and applying the indexes. The heavy lifting can be done with minimal effort.

Figure 7-17. DTA output report sample
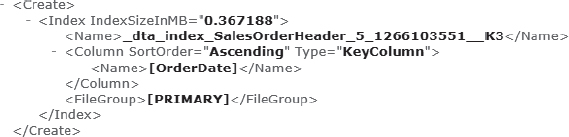
Figure 7-18. DTA index recommendation
![]() Caution Never run DTA on a production server. When evaluating a workload, the tool uses algorithms that will, in essence, use a brute-force process to investigate as many indexing options as possible on the database. While no physical indexes or database changes will be made, there are hypothetical objects created that the tool uses to make its recommendations.
Caution Never run DTA on a production server. When evaluating a workload, the tool uses algorithms that will, in essence, use a brute-force process to investigate as many indexing options as possible on the database. While no physical indexes or database changes will be made, there are hypothetical objects created that the tool uses to make its recommendations.
The Business Bubble
Besides the overall impact on the total performance of an index on a table and the queries that utilize the table, there is another area and reason that helps dictate whether an index is of value to a database. In the context of this chapter, we refer to this other reason as the business bubble. The business bubble is all of the nonstatistical reasons to index a table that can dictate the need for an index. Sometimes supporting the most important queries in a database defines the queries that are run most often. At times, they will be supporting the queries that are important because of the business value that they provide.
Index Business Usage
Probably the most often overlooked part of indexing is investigating the purpose or use of an index. There are not many easy ways to identify why an index is used. While that might be the case, there is one method you can use that will tell you how an index has been recently used—this is by querying the plan cache. Within the SHOWPLAN XML for every cached plan, all of the indexes and tables used are documented. Because of this, by querying the plan cache for index use, you can identify where an index is being used.
While the use of an index can be determined through the plan cache, what is the point of determining where an index is used? The point of this is to be able to identify the reasons in which an index is providing value. By knowing this, you can determine which business process that the index supports and, thus, know whether the index is being used to populate value lists or to calculate your next quarter bonus. When you know what is being supported, you will best be able to identify where the impact of changing or dropping an index will occur and know how and where to test for the changes made to the index.
As an example, we'll investigate the demonstration server from this chapter to see what queries are using the PK_SalesOrderHeader_SalesOrderID index. Using the code in Listing 7-18, we can see that by investigating the Object node of the SHOWPLAN XML, the index is stored in the attribute @IndexName. We can query for this directly or through a variable, which is used in the query. The results of this query, shown in Figure 7-19, show you that there are eight plans in the cache that are using the index, along with the counts of use and the execution plan that you'd use to further investigate how it is being used.
Listing 7-18. Query Plan Cache for Index Usage
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
GO
DECLARE @IndexName sysname = 'PK_SalesOrderHeader_SalesOrderID';
SET @IndexName = QUOTENAME(@IndexName,'['),
WITH XMLNAMESPACES (DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
,IndexSearch
AS (
SELECT qp.query_plan
,cp.usecounts
,ix.query('.') AS StmtSimple
FROM sys.dm_exec_cached_plans cp
OUTER APPLY sys.dm_exec_query_plan(cp.plan_handle) qp
CROSS APPLY qp.query_plan.nodes('//StmtSimple') AS p(ix)
WHERE query_plan.exist('//Object[@Index = sql:variable("@IndexName")]') = 1
)
SELECT StmtSimple.value('StmtSimple[1]/@StatementText', 'VARCHAR(4000)') AS sql_text
,obj.value('@Database','sysname') AS database_name
,obj.value('@Schema','sysname') AS schema_name
,obj.value('@Table','sysname') AS table_name
,obj.value('@Index','sysname') AS index_name
,ixs.query_plan
FROM IndexSearch ixs
CROSS APPLY StmtSimple.nodes('//Object') AS o(obj)
WHERE obj.exist('.[@Index = sql:variable("@IndexName")]') = 1

Figure 7-19. Results from plan cache query
![]() Note In one situation, I worked with a database that had indexes on a number of tables. These indexes were used on average once or twice a week. During an indexing assessment, it was determined that these weren't used often enough to justify keeping the indexes. Once removed, the import process that they supported degraded substantially and the import time went from under an hour to many hours. This is a near perfect example of why it is critical to know how your indexes are used, and what they are used for. Had the research into the purpose of the indexes been done, then the process using the indexes would not have regressed in performance.
Note In one situation, I worked with a database that had indexes on a number of tables. These indexes were used on average once or twice a week. During an indexing assessment, it was determined that these weren't used often enough to justify keeping the indexes. Once removed, the import process that they supported degraded substantially and the import time went from under an hour to many hours. This is a near perfect example of why it is critical to know how your indexes are used, and what they are used for. Had the research into the purpose of the indexes been done, then the process using the indexes would not have regressed in performance.
Data Integrity
The other piece of the business value for an index relates to the data integrity, or rather the rules that are placed on the database to validate and ensure data integrity. The chief method for this is the use of foreign keys. With foreign keys, we are able to ensure that a value placed on one table is a value that is in another table, which contains reference information. While it might not seem important to index this information, it is often critical to do so. The reason for this need is that if the column being validated is not indexed, then any validation check will require a scan of the column. If the column has thousands or millions of rows, this scan can cause performance issues, and could lead to deadlocks.
The best way to determine whether there are missing indexes on foreign keys is to check the metadata for the foreign keys against and indexes. All of the information needed is included and can be easily queried. The key thing to remember is to be certain the that indexes and foreign keys are compared from the left edge of the index. If the foreign key does not match to that edge, then it cannot be used to validate values in the index. Using the query shown in Listing 7-19 provides the list of foreign keys that are not indexed in a database. The results from this query, shown in Figure 7-20, show that there are 33 foreign keys in the AdventureWorks2012 database that are not indexed.
After the unindexed foreign keys are identified, the next step is to create indexes that cover those foreign keys. The table that the index needs to be built on is in the fk_table_name column in Figure 7-20; the key columns for the index will be from the fk_columns column. As an example, the index to cover the missing foreign key index for FK_BillOfMaterials_Product_ComponentID would use the code in Listing 7-20.
Listing 7-19. Query for Unindexed Foreign Keys
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
;WITHcIndexes
AS (
SELECT i.object_id
,i.name
,(SELECT QUOTENAME(ic.column_id,'(')
FROM sys.index_columnsic
WHERE i.object_id = ic.object_id
AND i.index_id = ic.index_id
AND is_included_column = 0
ORDER BY key_ordinal ASC
FOR XML PATH('')) AS indexed_compare
FROM sys.indexesi
), cForeignKeys
AS (
SELECT fk.name AS foreign_key_name
,fkc.parent_object_id AS object_id
,STUFF((SELECT ', ' + QUOTENAME(c.name)
FROM sys.foreign_key_columnsifkc
INNER JOIN sys.columns c ON ifkc.parent_object_id = c.object_id
AND ifkc.parent_column_id = c.column_id
WHERE fk.object_id = ifkc.constraint_object_id
ORDER BY ifkc.constraint_column_id
FOR XML PATH('')), 1, 2, '') AS fk_columns
,(SELECT QUOTENAME(ifkc.parent_column_id,'(')
FROM sys.foreign_key_columnsifkc
WHERE fk.object_id = ifkc.constraint_object_id
ORDER BY ifkc.constraint_column_id
FOR XML PATH('')) AS fk_columns_compare
FROM sys.foreign_keysfk
INNER JOIN sys.foreign_key_columnsfkc ON fk.object_id = fkc.constraint_object_id
WHERE fkc.constraint_column_id = 1
), cRowCount
AS (
SELECT object_id, SUM(row_count) AS row_count
FROM sys.dm_db_partition_statsps
WHERE index_id IN (1,0)
GROUP BY object_id
)
SELECT fk.foreign_key_name
,OBJECT_SCHEMA_NAME(fk.object_id) AS fk_schema_name
,OBJECT_NAME(fk.object_id) AS fk_table_name
,fk.fk_columns
,rc.row_count AS row_count
FROM cForeignKeysfk
INNER JOIN cRowCountrc ON fk.object_id = rc.object_id
LEFT OUTER JOIN cIndexesi ON fk.object_id = i.object_id AND i.indexed_compare
LIKE fk.fk_columns_compare + '%'
WHERE i.name IS NULL
ORDER BY OBJECT_NAME(fk.object_id), fk.fk_columns
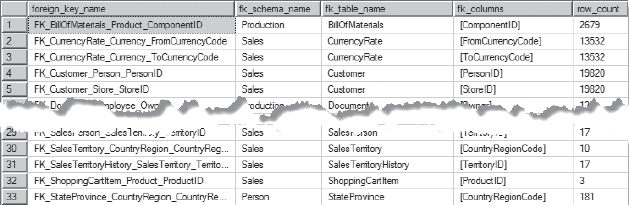
Figure 7-20. Results from foreign key query
Listing 7-20. Example Foreign Key Index
CREATE INDEX FIX_BillOfMaterials_ComponentID ON Production.BillOfMaterials (ComponentID)
Conclusion
Indexing your databases is an important aspect of maintaining performance for your applications. While we often build our indexes by hand and make decisions on their value based on their frequency of use, there are other things to consider. The totality of the indexing for a table and the purposes of those indexes often outweigh the value in adding one index for one purpose. Though, sometimes the one index for one purpose is needed to to support a business process.
In this chapter we looked at how to use the missing index DMOs and DTA to perform some of the heavy lifting with indexes and get a head start with less manual work. We also looked at a few reasons outside statistics that can necessitate an index. When going forward with your indexing strategies, it will be important to consider all of these facets to index your databases as a whole.